Cet article propose une méthode d'induction floue développée par l'auteur comme une combinaison des dispositions des mathématiques floues et de la théorie fractale, introduit le concept du degré de récursivité d'un ensemble flou, décrit la récursivité incomplète d'un ensemble comme sa dimension fractionnaire pour modéliser un domaine. Étant donné la portée de la méthode proposée et les modèles de connaissances créés sur la base d'ensembles flous, la gestion du cycle de vie des systèmes d'information, y compris l'élaboration de scénarios d'utilisation et de test de logiciels, est considérée.
Pertinence
Dans le processus de conception et de développement, de mise en œuvre et d'exploitation des systèmes d'information, il est nécessaire d'accumuler et de systématiser les données, informations et informations collectées de l'extérieur ou qui surviennent à chaque étape du cycle de vie du logiciel. Cela sert de support informationnel et méthodologique nécessaire pour le travail de conception et la prise de décision, et est particulièrement pertinent dans les situations d'incertitude élevée et dans les environnements mal structurés. La base de connaissances formée à la suite de l'accumulation et de la systématisation de ces ressources ne devrait pas seulement être une source d'expérience utile acquise par l'équipe de projet lors des travaux de création d'un système d'information, mais également le moyen le plus simple de modéliser de nouvelles visions, méthodes et algorithmes pour la mise en œuvre des tâches du projet. En d'autres termes,une telle base de connaissances est un dépositaire de capital intellectuel et, en même temps, un outil de gestion des connaissances [3, 10].
L'efficacité, l'utilité, la qualité de la base de connaissances en tant qu'outil sont en corrélation avec l'intensité des ressources de sa maintenance et l'efficacité de l'extraction des connaissances. Plus la collecte et la fixation des connaissances dans la base de données sont simples et rapides et plus les résultats des requêtes y sont pertinents, meilleur et fiable l'outil lui-même [1, 2]. Néanmoins, les méthodes discrètes et les outils de structuration applicables aux systèmes de gestion de base de données, y compris la normalisation des relations de base de données relationnelles, ne permettent pas de décrire ou de modéliser les composants sémantiques, les interprétations, les ensembles sémantiques d'intervalles et continus [4, 7, 10]. Pour ce faire, nous avons besoin d'une approche méthodologique qui généralise des cas particuliers d'ontologies finies et rapproche le modèle de connaissance de la continuité de la description du sujet du système d'information.
[3, 6]. ( ) ( – , , ), ( ), , – , , [5, 8, 9].
X – :
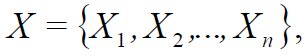 (1)
(1)
n = [N ≥ 3] – (, (0; 1) – (; )).
X = B, B = {a,b,c,...,z} – , X.
 , ( ) , X, :
, ( ) , X, :
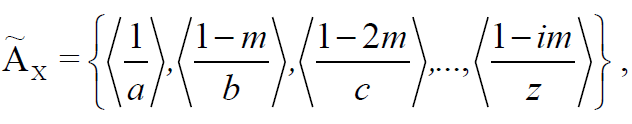 (2)
(2)
m – , i N – .
, () , , :
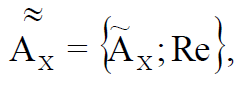 (3)
(3)
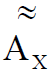 – , , X, , ; Re – .
– , , X, , ; Re – .
, 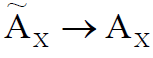 ( ) .
( ) .
Re = 1 2- , ( ), X [1, 2]:
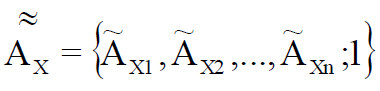 (4)
(4)
– , , – ( ) . – ( – ) [3, 9].
Re :
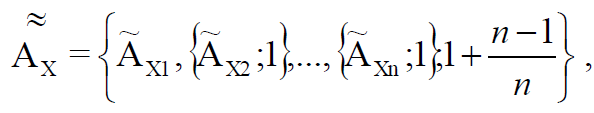 (5)
(5)
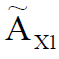 – X1,
– X1, 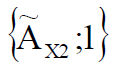 – X2 . .
– X2 . .
, – .
, , , . , , , .
, , .
: ( ), ( ), ( ).
X – , X :
 (6)
(6)
X1 – , X2 – , X3 – ,
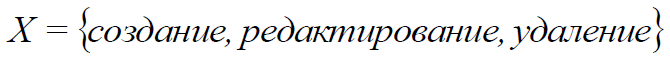 (7)
(7)
, ( – ), ( ), .
, X ( ), .
, () « » :
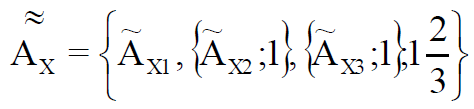 (8)
(8)
1,6(6) .
, ( , . use-case), ( , . test-case).
, , .
:
 (9)
(9)
– X;
 – X, a ( ) 1;
– X, a ( ) 1;
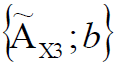 – X, b ( ) 1.
– X, b ( ) 1.
, ( ) , / .
Ux X , , ( -) , / , , :
 (10)
(10)
n – X.
Tx X . , , :
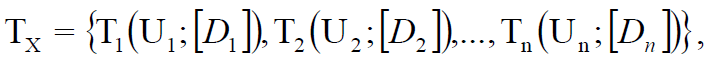 (11)
(11)
[D] – , n – X.
, . , .
, .
, « », , . , , .
« » , , .
- .., .., .., « ». .: – , 2014. – 88 .
- .., .., .., « ». .: – , 2014. – 122 .
- .., «: ». : , 2011. – 296 .
- ., « » / « ». .: «», 1974. – . 5 – 49.
- ., « ». .: , 2016. – 320 .
- .., « » / «», №54 (2/2008), http://www.delphis.ru/journal/article/fraktalnaya-matematika-i-priroda-peremen.
- ., « ». .: , 2002. – 656 .
- « : », . .., .. : - . . . -, 2003. – 24 .
- .., « ». .: -, 2017. – 622 .
- Zimmerman H. J. «Fuzzy Set Theory – and its Applications», 4th edition. Springer Seience + Business Media, New York, 2001. – 514 p.