Bonjour à tous. Le 26 février, les cours ont commencé dans OTUS dans un nouveau groupe sur le cours "MS SQL Server Developer" . À cet égard, je souhaite partager avec vous ma publication sur les fonctions des fenêtres. Au fait, dans la semaine à venir, vous pourrez toujours rejoindre le groupe ;-).
Les fonctions de fenêtre sont bien établies dans notre pratique, mais peu de gens savent comment fonctionnent les cadres RANGE et ROWS.C'est peut-être pourquoi ils sont un peu moins courants. Le but de cet article est de fournir des exemples d'utilisation afin que vous n'ayez définitivement pas de questions "Qui est qui?" et "Comment l'appliquer?". La question "Pourquoi?" L'article restera éteint.Voyons ce qu'est un cadre et comment obtenir un effet similaire en utilisant ORDER By dans la clause OVER ().Pour la démonstration, nous utiliserons un tableau simple afin que vous puissiez calculer des exemples sans utiliser de compilateur. En général, je le recommande vivement - regardez et réfléchissez au résultat de l'exécution, puis vérifiez par vous-même - vous trouverez donc des points blancs dans la perception des fonctions de la fenêtre, ce qui peut ne pas être évident lorsque vous lisez les résultats finaux.TableCreate table sales
(sales_id INT PRIMARY KEY, sales_dt DATETIME2 DEFAULT GETUTCDATE(), customer_id INT, item_id INT, cnt INT, price_per_item DECIMAL(19,4));
INSERT INTO sales
(sales_id, sales_dt, customer_id, item_id, cnt, price_per_item)
VALUES
(1, '2020-01-10T10:00:00', 100, 200, 2, 30.15),
(2, '2020-01-11T11:00:00', 100, 311, 1, 5.00),
(3, '2020-01-12T14:00:00', 100, 400, 1, 50.00),
(4, '2020-01-12T20:00:00', 100, 311, 5, 5.00),
(5, '2020-01-13T10:00:00', 150, 311, 1, 5.00),
(6, '2020-01-13T11:00:00', 100, 315, 1, 17.00),
(7, '2020-01-14T10:00:00', 150, 200, 2, 30.15),
(8, '2020-01-14T15:00:00', 100, 380, 1, 8.00),
(9, '2020-01-14T18:00:00', 170, 380, 3, 8.00),
(10, '2020-01-15T09:30:00', 100, 311, 1, 5.00),
(11, '2020-01-15T12:45:00', 150, 311, 5, 5.00),
(12, '2020-01-15T21:30:00', 170, 200, 1, 30.15);
Commençons par un moment simple - les différences dans la fonction SUM avec et sans triSELECT sales_id, customer_id, count,
SUM(count) OVER () as total,
SUM(count) OVER (ORDER BY customer_id) AS cum,
SUM(count) OVER (ORDER BY customer_id, sales_id) AS cum_uniq
FROM sales
ORDER BY customer_id, sales_id;
 Regardons le premier râteau discret, comment pensez-vous combien de développeurs penseront que cum et cum_uniq sont les mêmes lors de la lecture du code? Pensez un peu? Peut-être, mais parce qu'ici c'est évident, et est-ce si évident lors de la lecture du code dans l'application, et même avec la non-unicité pas si évidente du champ de tri.Ouvrez maintenant notre merveilleuse fenêtre.La fenêtre, ou plutôt le cadre est composé de 2 types de RANGS et de GAMME, commencez par connaître les RANGS.Options de restriction de trame:
Regardons le premier râteau discret, comment pensez-vous combien de développeurs penseront que cum et cum_uniq sont les mêmes lors de la lecture du code? Pensez un peu? Peut-être, mais parce qu'ici c'est évident, et est-ce si évident lors de la lecture du code dans l'application, et même avec la non-unicité pas si évidente du champ de tri.Ouvrez maintenant notre merveilleuse fenêtre.La fenêtre, ou plutôt le cadre est composé de 2 types de RANGS et de GAMME, commencez par connaître les RANGS.Options de restriction de trame:- Tout ce qui précède la ligne / plage actuelle et la valeur réelle de la ligne actuelle
ENTRE LA PRÉCÉDENCE NON LIMITÉE
ENTRE LA PRÉCÉDENCE NON LIMITÉE ET LA LIGNE ACTUELLE
- Ligne / plage actuelle et tout ce qui suit
ENTRE LA LIGNE ACTUELLE ET SANS LIMITE SUIVANT - Spécification du nombre de lignes avant et après à inclure (non pris en charge pour RANGE)
ENTRE N Précédente ET N Suivante
ENTRE LIGNE ACTUELLE ET N Suivante
ENTRE N Précédente ET LIGNE ACTUELLE
Mais voyons le cadre en action.On ouvre la "fenêtre" sur la ligne courante et toutes les précédentes, pour la fonction SUM, comme vous pouvez le voir, cela coïncide avec le tri ASCSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY customer_id, sales_id;
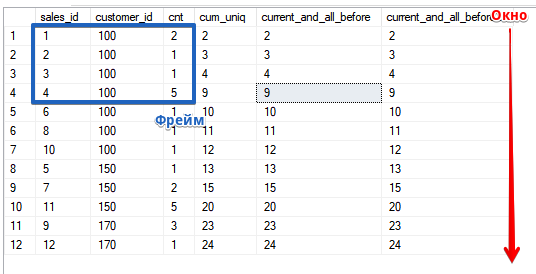 Dans le même temps, je tiens à vous rappeler que l'ordre de tri dans la fenêtre (dans la clause OVER ()) n'est pas lié à l'ordre de tri dans la requête elle-même, dans l'exemple, il est le même afin de simplifier le calcul si vous décidez de vérifier le calcul et votre compréhension du fonctionnement de la fonction
Dans le même temps, je tiens à vous rappeler que l'ordre de tri dans la fenêtre (dans la clause OVER ()) n'est pas lié à l'ordre de tri dans la requête elle-même, dans l'exemple, il est le même afin de simplifier le calcul si vous décidez de vérifier le calcul et votre compréhension du fonctionnement de la fonctionSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY cnt;
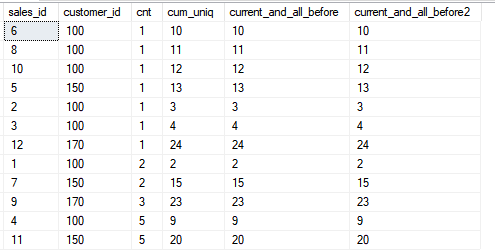 Examinons maintenant la fonctionnalité du cadre lorsque nous incluons toutes les lignes suivantes.
Examinons maintenant la fonctionnalité du cadre lorsque nous incluons toutes les lignes suivantes.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_frame,
SUM(cnt) OVER (ORDER BY customer_id DESC, sales_id DESC) AS current_and_all_order_desc
FROM sales
ORDER BY customer_id, sales_id;
 Comme vous pouvez le voir ici, vous pouvez également obtenir le même résultat pour une fonction d'agrégation, si vous utilisez le tri inverse - mais ROWS est un peu plus stable, car si vos champs de tri ne sont pas uniques, vous pouvez obtenir une surprise sous la forme des mêmes valeurs.Et enfin, une option qui ne peut plus être imitée par sortes, lorsque nous spécifions un nombre spécifique de lignes qui doivent être incluses dans le cadre
Comme vous pouvez le voir ici, vous pouvez également obtenir le même résultat pour une fonction d'agrégation, si vous utilisez le tri inverse - mais ROWS est un peu plus stable, car si vos champs de tri ne sont pas uniques, vous pouvez obtenir une surprise sous la forme des mêmes valeurs.Et enfin, une option qui ne peut plus être imitée par sortes, lorsque nous spécifions un nombre spécifique de lignes qui doivent être incluses dans le cadreSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS before_and_current,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS current_and_1_next,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS before2_and_2_next
FROM sales
ORDER BY customer_id, sales_id;
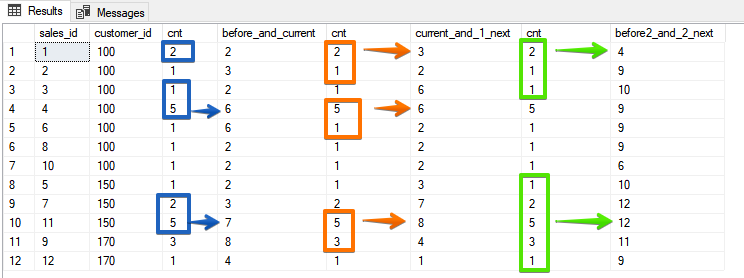 Dans cette option, vous indiquez déjà spécifiquement quelles lignes se trouvent dans la plage et, à mon avis, cela ressort le plus clairement des résultats.
Dans cette option, vous indiquez déjà spécifiquement quelles lignes se trouvent dans la plage et, à mon avis, cela ressort le plus clairement des résultats.La différence entre ROWS et RANGE
La différence est que ROWS fonctionne sur une ligne et RANGE sur une plage. Certes, cela est évident d'après le nom, mais explique peu dans la pratique?Regardons l'image (source au bas de l'article)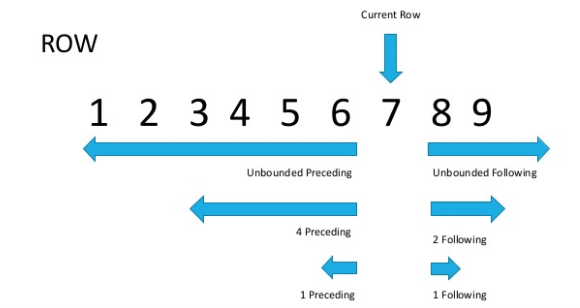
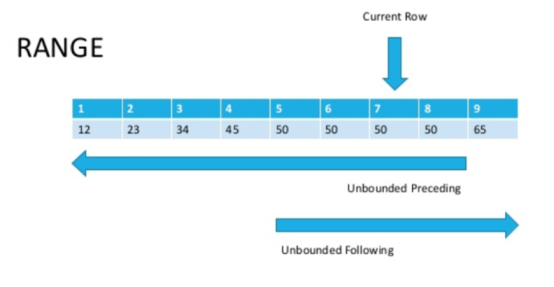 Maintenant, si nous regardons attentivement, il deviendra évident que les lignes avec la même valeur de paramètre de tri sont appelées une plage.Comme déjà mentionné ci-dessus, ROWS est limité à une chaîne, tandis que RANGE capture toute la plage de valeurs correspondantes que vous spécifiez dans la fonction de fenêtre ORDER BY.
Maintenant, si nous regardons attentivement, il deviendra évident que les lignes avec la même valeur de paramètre de tri sont appelées une plage.Comme déjà mentionné ci-dessus, ROWS est limité à une chaîne, tandis que RANGE capture toute la plage de valeurs correspondantes que vous spécifiez dans la fonction de fenêtre ORDER BY.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, sales_id;
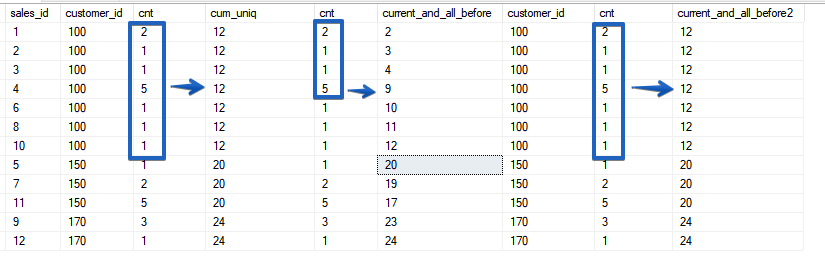 ROWS - fonctionne toujours avec une ligne spécifique, même si le tri n'est pas unique, mais RANGE combine simplement les périodes en plages avec les valeurs correspondantes des champs de tri. En ce sens, la fonctionnalité est très similaire au comportement de la fonction SUM () avec le tri par un champ non unique. Voyons un autre exemple.
ROWS - fonctionne toujours avec une ligne spécifique, même si le tri n'est pas unique, mais RANGE combine simplement les périodes en plages avec les valeurs correspondantes des champs de tri. En ce sens, la fonctionnalité est très similaire au comportement de la fonction SUM () avec le tri par un champ non unique. Voyons un autre exemple.SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item;
 Il y a déjà 2 champs et la plage est déterminée par une plage avec des valeurs correspondantes pour les deux champs.Et l'option est lorsque nous incluons dans le calcul toutes les lignes suivantes de la ligne actuelle, qui dans le cas de la fonction SUM coïncide avec la valeur qui peut être obtenue en utilisant le tri inverse:
Il y a déjà 2 champs et la plage est déterminée par une plage avec des valeurs correspondantes pour les deux champs.Et l'option est lorsque nous incluons dans le calcul toutes les lignes suivantes de la ligne actuelle, qui dans le cas de la fonction SUM coïncide avec la valeur qui peut être obtenue en utilisant le tri inverse:SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id DESC, price_per_item DESC) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item, sales_id desc;
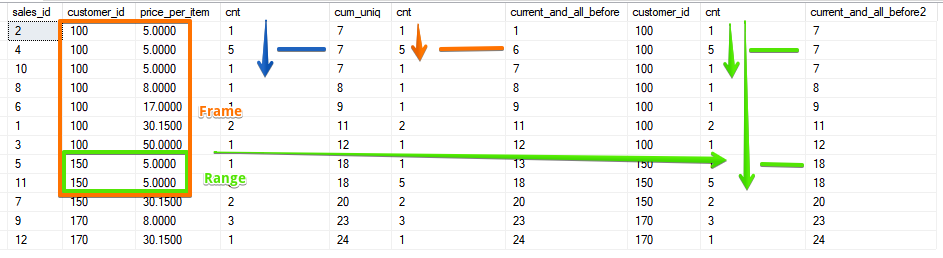 Comme vous pouvez le voir, RANGE capture à nouveau toute la gamme de paires correspondantes.Malgré le fait que la fonctionnalité de ROWS et de RANGE soit loin d'être nouvelle à chaque fois, des questions se posent sur la façon de l'utiliser. J'espère que cet article a ajouté la compréhension de la différence entre ROWS et RANGE, et maintenant vous ne douterez plus dans quel cas tel ou tel cadre est nécessaire.Illustration Source GAMME sur la différence et les RANGSles fonctions de la fenêtre Avec le SQL Server 2016, Mark Tabladillosoit à temps pour le cours
Comme vous pouvez le voir, RANGE capture à nouveau toute la gamme de paires correspondantes.Malgré le fait que la fonctionnalité de ROWS et de RANGE soit loin d'être nouvelle à chaque fois, des questions se posent sur la façon de l'utiliser. J'espère que cet article a ajouté la compréhension de la différence entre ROWS et RANGE, et maintenant vous ne douterez plus dans quel cas tel ou tel cadre est nécessaire.Illustration Source GAMME sur la différence et les RANGSles fonctions de la fenêtre Avec le SQL Server 2016, Mark Tabladillosoit à temps pour le cours