Mon nom est Pavel Parkhomenko, je suis développeur ML. Dans cet article, je voudrais parler de la conception du service Yandex.Zen et partager les améliorations techniques, dont l'introduction a permis d'augmenter la qualité des recommandations. De la publication, vous apprendrez à trouver le plus pertinent pour l'utilisateur parmi des millions de documents en quelques millisecondes seulement; comment décomposer en continu une grande matrice (composée de millions de colonnes et de dizaines de millions de lignes) afin que les nouveaux documents reçoivent leur vecteur en quelques dizaines de minutes; comment réutiliser la décomposition de la matrice de l'article utilisateur pour obtenir une bonne représentation vectorielle pour la vidéo. Notre base de données de recommandations contient des millions de documents de différents formats: articles de texte créés sur notre plateforme et extraits de sites externes, vidéos, récits et courts articles. Le développement d'un tel service est associé à un grand nombre de défis techniques. En voici quelques uns:
Notre base de données de recommandations contient des millions de documents de différents formats: articles de texte créés sur notre plateforme et extraits de sites externes, vidéos, récits et courts articles. Le développement d'un tel service est associé à un grand nombre de défis techniques. En voici quelques uns:- Tâches de calcul distinctes: effectuez toutes les opérations lourdes hors ligne et n'effectuez en temps réel qu'une application rapide des modèles afin d'être responsable de 100 à 200 ms.
- Envisagez rapidement les actions des utilisateurs. Pour cela, il est nécessaire que tous les événements soient instantanément livrés au recommandeur et affectent le résultat des modèles.
- Faites la bande pour que les nouveaux utilisateurs s'adaptent rapidement à leur comportement. Les personnes qui viennent d'entrer dans le système devraient sentir que leurs commentaires influencent les recommandations.
- Comprenez rapidement qui recommander un nouvel article.
- Répondez rapidement à l'émergence constante de nouveaux contenus. Des dizaines de milliers d'articles sont publiés chaque jour, et nombre d'entre eux ont une durée de vie limitée (par exemple, des nouvelles). C'est leur différence par rapport aux films, à la musique et à d'autres créations de contenu longue durée et coûteuses.
- Transférez les connaissances d'un domaine vers un autre. Si le système de recommandation a des modèles formés pour les articles de texte et que nous y ajoutons des vidéos, vous pouvez réutiliser les modèles existants afin que le nouveau type de contenu soit mieux classé.
Je vais vous expliquer comment nous avons résolu ces problèmes.Sélection des candidats
Comment en quelques millisecondes réduire mille fois l'ensemble de documents à l'étude, sans pour autant dégrader pratiquement la qualité du classement?Supposons que nous avons formé un grand nombre de modèles ML, généré des attributs en fonction d'eux et formé un autre modèle qui classe les documents pour l'utilisateur. Tout irait bien, mais vous ne pouvez pas simplement prendre et compter tous les signes pour tous les documents en temps réel, s'il existe des millions de ces documents, et les recommandations doivent être élaborées en 100-200 ms. La tâche consiste à choisir parmi des millions un certain sous-ensemble qui sera classé pour l'utilisateur. Cette étape est communément appelée sélection des candidats. Il a plusieurs exigences. Premièrement, la sélection doit se faire très rapidement, afin qu'il reste le plus de temps possible sur le classement lui-même. Deuxièmement, en réduisant considérablement le nombre de documents à classer, nous devons garder les documents pertinents pour l'utilisateur aussi complètement que possible.Notre principe de sélection des candidats a évolué de manière évolutive, et pour le moment nous sommes arrivés à un schéma en plusieurs étapes: tout d'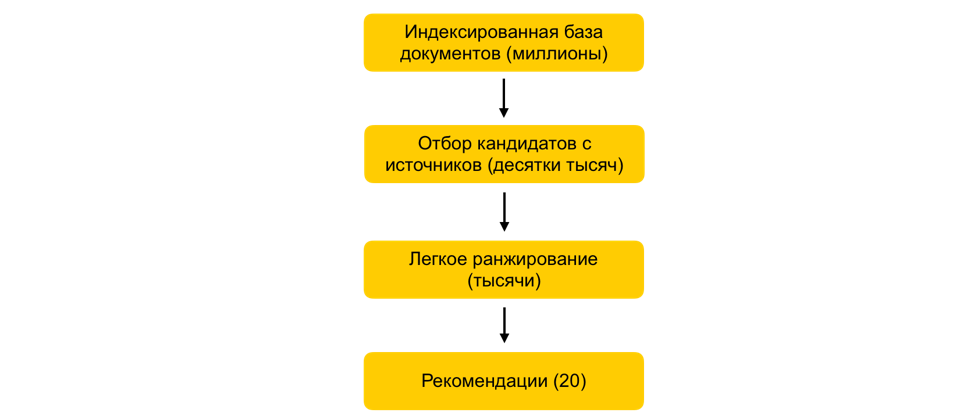 abord, tous les documents sont divisés en groupes, et les documents les plus populaires sont tirés de chaque groupe. Les groupes peuvent être des sites, des sujets, des clusters. Pour chaque utilisateur, en fonction de son histoire, les groupes les plus proches de lui sont sélectionnés et les meilleurs documents leur sont déjà extraits. Nous utilisons également l'index kNN pour sélectionner les documents les plus proches de l'utilisateur en temps réel. Il existe plusieurs méthodes pour construire l'indice kNN, nous avons le meilleur HNSW(Graphiques hiérarchiques du petit monde navigable). Il s'agit d'un modèle hiérarchique qui vous permet de trouver N vecteurs les plus proches pour un utilisateur à partir d'une millionième base de données en quelques millisecondes. Auparavant, nous indexions hors ligne l'ensemble de notre base de données de documents. Comme la recherche dans l'index fonctionne assez rapidement, s'il y a plusieurs intégrations fortes, vous pouvez créer plusieurs index (un index pour chaque incorporation) et accéder à chacun d'eux en temps réel.Nous avons encore des dizaines de milliers de documents pour chaque utilisateur. C'est encore beaucoup pour compter tous les attributs, donc à ce stade, nous appliquons un classement facile - un modèle de classement lourd léger avec moins d'attributs. La tâche consiste à prédire quels documents le modèle lourd aura en haut. Les documents avec la prédiction la plus élevée seront utilisés dans le modèle lourd, c'est-à-dire à la dernière étape du classement. Cette approche permet pendant des dizaines de millisecondes de réduire la base de données des documents considérés pour l'utilisateur de millions à plusieurs milliers.
abord, tous les documents sont divisés en groupes, et les documents les plus populaires sont tirés de chaque groupe. Les groupes peuvent être des sites, des sujets, des clusters. Pour chaque utilisateur, en fonction de son histoire, les groupes les plus proches de lui sont sélectionnés et les meilleurs documents leur sont déjà extraits. Nous utilisons également l'index kNN pour sélectionner les documents les plus proches de l'utilisateur en temps réel. Il existe plusieurs méthodes pour construire l'indice kNN, nous avons le meilleur HNSW(Graphiques hiérarchiques du petit monde navigable). Il s'agit d'un modèle hiérarchique qui vous permet de trouver N vecteurs les plus proches pour un utilisateur à partir d'une millionième base de données en quelques millisecondes. Auparavant, nous indexions hors ligne l'ensemble de notre base de données de documents. Comme la recherche dans l'index fonctionne assez rapidement, s'il y a plusieurs intégrations fortes, vous pouvez créer plusieurs index (un index pour chaque incorporation) et accéder à chacun d'eux en temps réel.Nous avons encore des dizaines de milliers de documents pour chaque utilisateur. C'est encore beaucoup pour compter tous les attributs, donc à ce stade, nous appliquons un classement facile - un modèle de classement lourd léger avec moins d'attributs. La tâche consiste à prédire quels documents le modèle lourd aura en haut. Les documents avec la prédiction la plus élevée seront utilisés dans le modèle lourd, c'est-à-dire à la dernière étape du classement. Cette approche permet pendant des dizaines de millisecondes de réduire la base de données des documents considérés pour l'utilisateur de millions à plusieurs milliers.Étape ALS lors de l'exécution
Comment prendre en compte les retours de l'utilisateur immédiatement après un clic?Un facteur important dans les recommandations est le temps de réponse aux commentaires de l'utilisateur. Ceci est particulièrement important pour les nouveaux utilisateurs: lorsqu'une personne commence tout juste à utiliser le système de recommandation, elle reçoit un flux non personnalisé de documents de divers sujets. Dès qu'il fait le premier clic, vous devez immédiatement en tenir compte et vous adapter à ses intérêts. Si tous les facteurs sont calculés hors ligne, une réponse rapide du système deviendra impossible en raison du retard. Vous devez donc traiter les actions des utilisateurs en temps réel. À ces fins, nous utilisons l'étape ALS lors de l'exécution pour créer une représentation vectorielle de l'utilisateur.Supposons que nous ayons une représentation vectorielle pour tous les documents. Par exemple, nous pouvons créer hors ligne sur la base des incorporations de texte d'article en utilisant ELMo, BERT ou d'autres modèles d'apprentissage automatique. Comment obtenir une représentation vectorielle des utilisateurs dans le même espace en fonction de leur interaction dans le système?Le principe général de la formation et de la décomposition de la matrice document utilisateurm n . . m x n: , — . , ́ , . (, , ) - — , 1, –1.
: P (m x d) Q (d x n), d — ( ). d- ( — P, — Q). . , , .

L'un des moyens possibles de décomposition matricielle est l'ALS (Alternating Least Squares). Nous optimiserons la fonction de perte suivante:
Ici r ui est l'interaction de l'utilisateur u avec le document i, q i est le vecteur du document i, p u est le vecteur de l'utilisateur u.Ensuite, le vecteur utilisateur optimal du point de vue de l'erreur quadratique moyenne (pour les vecteurs de document fixe) est trouvé analytiquement en résolvant la régression linéaire correspondante.Cela s'appelle une étape ALS. Et l'algorithme ALS lui-même consiste dans le fait que nous corrigeons alternativement l'une des matrices (utilisateurs et articles) et mettons à jour l'autre, en trouvant la solution optimale.Heureusement, la recherche de la représentation vectorielle d'un utilisateur est une opération assez rapide qui peut être effectuée lors de l'exécution à l'aide d'instructions vectorielles. Cette astuce vous permet de prendre immédiatement en compte les retours de l'utilisateur dans le classement. La même intégration peut être utilisée dans l'indice kNN pour améliorer la sélection des candidats.Filtrage collaboratif distribué
Comment faire une factorisation matricielle distribuée incrémentielle et trouver rapidement une représentation vectorielle de nouveaux articles?Le contenu n'est pas la seule source de signaux de recommandations. L'information collaborative est une autre source importante. De bons signes de classement peuvent traditionnellement être obtenus à partir de la décomposition de la matrice du document utilisateur. Mais en essayant de faire cette décomposition, nous avons rencontré des problèmes:1. Nous avons des millions de documents et des dizaines de millions d'utilisateurs. La matrice ne tient pas entièrement sur une machine et la décomposition sera très longue.2. La plupart du contenu du système a une courte durée de vie: les documents ne restent pertinents que quelques heures. Il est donc nécessaire de construire leur représentation vectorielle le plus rapidement possible.3. Si vous générez la décomposition immédiatement après la publication du document, un nombre suffisant d'utilisateurs n'auront pas le temps de l'évaluer. Par conséquent, sa représentation vectorielle n'est probablement pas très bonne.4. Si l'utilisateur aime ou n'aime pas, nous ne pourrons pas en tenir compte immédiatement dans l'extension.Pour résoudre ces problèmes, nous avons implémenté une décomposition distribuée de la matrice du document utilisateur avec une mise à jour incrémentielle fréquente. Comment ça marche exactement?Supposons que nous ayons un cluster de N machines (N par centaines) et que nous voulons faire une décomposition distribuée de la matrice sur celles-ci, qui ne rentre pas sur une machine. La question est de savoir comment effectuer cette décomposition pour que, d'une part, il y ait suffisamment de données sur chaque machine et, d'autre part, pour que les calculs soient indépendants?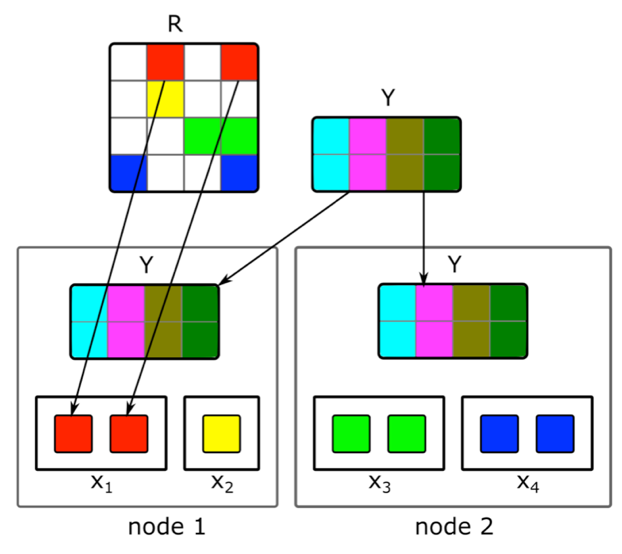 Nous utiliserons l'algorithme de décomposition ALS décrit ci-dessus. Considérez comment effectuer une étape ALS de manière distribuée - les autres étapes seront similaires. Supposons que nous ayons une matrice fixe de documents et que nous voulons construire une matrice d'utilisateurs. Pour ce faire, nous le divisons en N parties en lignes, chaque partie contiendra environ le même nombre de lignes. Nous enverrons à chaque machine des cellules non vides des lignes correspondantes, ainsi qu'une matrice de plongements de documents (en totalité). Comme elle n'est pas très grande et que la matrice des documents utilisateur est généralement très clairsemée, ces données tiendront sur une machine ordinaire.Une telle astuce peut être répétée pendant plusieurs époques jusqu'à ce que le modèle converge, changeant alternativement la matrice fixe. Mais même alors, la décomposition de la matrice peut durer plusieurs heures. Et cela ne résout pas le problème de la nécessité de recevoir rapidement les intégrations de nouveaux documents et de mettre à jour les intégrations de ceux sur lesquels il y avait peu d'informations lors de la construction du modèle.L'introduction d'une mise à jour incrémentielle rapide du modèle nous a aidés. Supposons que nous ayons un modèle formé actuel. Depuis sa formation, de nouveaux articles sont apparus avec lesquels nos utilisateurs ont interagi, ainsi que des articles qui ont eu peu d'interaction avec la formation. Pour intégrer rapidement de tels articles, nous utilisons des intégrations d'utilisateurs obtenues lors de la première formation sur les grands modèles et prenons une étape ALS pour calculer la matrice des documents avec une matrice fixe d'utilisateurs. Cela vous permet de recevoir des incorporations assez rapidement - quelques minutes après la publication d'un document - et souvent de mettre à jour les incorporations de documents récents.Afin de prendre immédiatement en compte les actions humaines pour les recommandations, lors de l'exécution, nous n'utilisons pas les intégrations utilisateur reçues hors ligne. Au lieu de cela, nous prenons l'étape ALS et obtenons le vecteur utilisateur actuel.
Nous utiliserons l'algorithme de décomposition ALS décrit ci-dessus. Considérez comment effectuer une étape ALS de manière distribuée - les autres étapes seront similaires. Supposons que nous ayons une matrice fixe de documents et que nous voulons construire une matrice d'utilisateurs. Pour ce faire, nous le divisons en N parties en lignes, chaque partie contiendra environ le même nombre de lignes. Nous enverrons à chaque machine des cellules non vides des lignes correspondantes, ainsi qu'une matrice de plongements de documents (en totalité). Comme elle n'est pas très grande et que la matrice des documents utilisateur est généralement très clairsemée, ces données tiendront sur une machine ordinaire.Une telle astuce peut être répétée pendant plusieurs époques jusqu'à ce que le modèle converge, changeant alternativement la matrice fixe. Mais même alors, la décomposition de la matrice peut durer plusieurs heures. Et cela ne résout pas le problème de la nécessité de recevoir rapidement les intégrations de nouveaux documents et de mettre à jour les intégrations de ceux sur lesquels il y avait peu d'informations lors de la construction du modèle.L'introduction d'une mise à jour incrémentielle rapide du modèle nous a aidés. Supposons que nous ayons un modèle formé actuel. Depuis sa formation, de nouveaux articles sont apparus avec lesquels nos utilisateurs ont interagi, ainsi que des articles qui ont eu peu d'interaction avec la formation. Pour intégrer rapidement de tels articles, nous utilisons des intégrations d'utilisateurs obtenues lors de la première formation sur les grands modèles et prenons une étape ALS pour calculer la matrice des documents avec une matrice fixe d'utilisateurs. Cela vous permet de recevoir des incorporations assez rapidement - quelques minutes après la publication d'un document - et souvent de mettre à jour les incorporations de documents récents.Afin de prendre immédiatement en compte les actions humaines pour les recommandations, lors de l'exécution, nous n'utilisons pas les intégrations utilisateur reçues hors ligne. Au lieu de cela, nous prenons l'étape ALS et obtenons le vecteur utilisateur actuel.Transfert vers une autre zone de domaine
Comment utiliser les commentaires d'un utilisateur sur des articles de texte pour créer une représentation vectorielle d'une vidéo?Au départ, nous ne recommandions que des articles de texte, donc beaucoup de nos algorithmes se concentrent sur ce type de contenu. Mais lors de l'ajout de contenu d'un type différent, nous avons été confrontés à la nécessité d'adapter les modèles. Comment avons-nous résolu ce problème en utilisant l'exemple de vidéo? Une option consiste à recycler tous les modèles à partir de zéro. Mais cela fait longtemps, d'ailleurs, certains des algorithmes sont exigeants sur le volume de l'échantillon d'apprentissage, qui n'est pas encore en bonne quantité pour un nouveau type de contenu dans les premiers instants de sa vie sur le service.Nous sommes allés dans l'autre sens et avons réutilisé des modèles de texte pour la vidéo. En créant des représentations vectorielles de la vidéo, la même astuce avec la SLA nous a aidés. Nous avons pris une représentation vectorielle des utilisateurs basée sur des articles de texte et avons pris l'étape ALS en utilisant des informations sur les vues vidéo. Nous avons donc facilement obtenu une représentation vectorielle de la vidéo. Et en runtime, nous calculons simplement la proximité entre le vecteur utilisateur obtenu à partir d'articles textuels et le vecteur vidéo.Conclusion
Le développement du cœur d'un système de recommandation en temps réel est chargé de nombreuses tâches. Il est nécessaire de traiter rapidement les données et d'appliquer les méthodes ML pour utiliser efficacement ces données; Construire des systèmes distribués complexes capables de traiter les signaux des utilisateurs et de nouvelles unités de contenu en un minimum de temps; et de nombreuses autres tâches.Dans le système actuel, dont j'ai décrit l'appareil, la qualité des recommandations pour l'utilisateur croît avec son activité et la durée du service. Mais bien sûr, c'est là que réside la principale difficulté: il est difficile pour le système de comprendre immédiatement les intérêts d'une personne qui interagit peu avec le contenu. L'amélioration des recommandations pour les nouveaux utilisateurs est notre principale préoccupation. Nous continuerons d'optimiser les algorithmes pour que le contenu pertinent pour la personne entre plus rapidement dans son flux et que le non pertinent n'apparaisse pas.