 Illustration par melmagazine.com (Source: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Actuellement, les réseaux publics avec des canaux qui ne sont pas protégés contre l'intrus sont largement utilisés pour l'échange d'informations. La messagerie dans un tel réseau connecté et les utilisateurs d'ordinateurs sont obligés de se protéger. Étant donné que l'utilisateur ne peut pas protéger lui-même les canaux de message, il protège le message.Qu'est-ce qui est protégé dans le message? Premièrement, la syntaxe (intégrité) à cette fin utilise lecodage(codage et analyse des codes) et, deuxièmement, la sémantique (confidentialité) pour laquelle lacryptologie estutilisée.(cryptographie et analyse cryptographique), troisièmement, indirectement, le contrevenant peut limiter la disponibilité du message en cachant le fait de sa transmission, pour laquelle la stéganologie est utilisée (stéganographie et stéganalyse).Les possibilités énumérées sont théoriquement et pratiquement fournies à des degrés divers, et bien que chaque direction se développe depuis assez longtemps, elles sont encore loin d'être complètes. Dans le présent travail, nous n'aborderons qu'une seule question particulière: l'analyse des codes de message.
Illustration par melmagazine.com (Source: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Actuellement, les réseaux publics avec des canaux qui ne sont pas protégés contre l'intrus sont largement utilisés pour l'échange d'informations. La messagerie dans un tel réseau connecté et les utilisateurs d'ordinateurs sont obligés de se protéger. Étant donné que l'utilisateur ne peut pas protéger lui-même les canaux de message, il protège le message.Qu'est-ce qui est protégé dans le message? Premièrement, la syntaxe (intégrité) à cette fin utilise lecodage(codage et analyse des codes) et, deuxièmement, la sémantique (confidentialité) pour laquelle lacryptologie estutilisée.(cryptographie et analyse cryptographique), troisièmement, indirectement, le contrevenant peut limiter la disponibilité du message en cachant le fait de sa transmission, pour laquelle la stéganologie est utilisée (stéganographie et stéganalyse).Les possibilités énumérées sont théoriquement et pratiquement fournies à des degrés divers, et bien que chaque direction se développe depuis assez longtemps, elles sont encore loin d'être complètes. Dans le présent travail, nous n'aborderons qu'une seule question particulière: l'analyse des codes de message.introduction
Le code génétique (HA) a été choisi comme objet d'analyse. Vous pouvez vous familiariser avec un exemple curieux de l'utilisation du Code civil dans le domaine de la sécurité de l'information (apparemment non professionnel et donc sans succès) ici.Dans la théorie du codage, deux directions importantes peuvent être distinguées: le codage de la source d'information et le codage de canal. Le premier d'entre eux est implémenté, en règle générale, par la partie émettrice et a pour objectif d'éliminer la redondance des messages (par exemple, le code Morse), le second a pour but de détecter et d'éliminer les erreurs dans les messages. Avant l'apparition des codes correcteurs, le problème de l'élimination des erreurs était résolu par la retransmission du fragment déformé du message à la demande du destinataire.Nous notons ici le fait qu'il est impossible pour le côté récepteur de déchiffrer correctement le chiffrement si des erreurs se produisent dans son texte. Les chiffrements ne permettent pas de détecter les erreurs, ni même de les corriger. Pour cette raison, du côté émission du système de communication, le cryptogramme de message est codé avec un code de correction et du côté réception, le décodeur du message reçu détecte (le cas échéant) et corrige les erreurs.Après cela, le cryptosystème entre en jeu et le destinataire légitime reçoit un message déchiffré. Il s'agit, en termes généraux, du fonctionnement des réseaux échangeant des messages sécurisés.Dans ce travail, nous analyserons en détail le code génétique très important, qui a été créé non pas par l'esprit humain, mais par la nature elle-même (un cas rare).L'histoire d'une découverte et le prix Nobel
Nous nous demandons comment, au niveau de la génétique et du métabolisme des organismes (cellules), la nature met-elle en œuvre de telles dispositions d'échange d'informations dans la vie des espèces et de leurs représentants individuels?Avant la Seconde Guerre mondiale, le monde scientifique savait que dans les organismes vivants, la transmission des caractères héréditaires de génération en génération s'effectue par le biais d'unités chimiques (gènes) relativement simples, qui comprennent une énorme quantité d'informations nécessaires à la poursuite et à la reproduction de la vie.Tous les gènes (et non les protéines) se lient en chaînes (chromosomes) et se matérialisent en acide désoxyribonucléique (ADN). Les experts ne savaient pas comment tout se passe et comment l'ADN lui-même est structuré.De jeunes chercheurs, le physicien britannique F. Crick et le biologiste américain J. Watson, ont publié en 1953 (25,4) un article dans la revue Nature sur la structure de l'acide désoxyribonucléique. Au début de leur travail en 1949, James Watson avait 23 ans, Francis Crick et Maurice Wilkins, 33 ans chacun.Dans l'article, les auteurs décrivaient un modèle de la structure spatiale de l'ADN sous la forme d'une double hélice, dont deux brins étaient torsadés à droite. Les brins eux-mêmes se sont avérés être reliés par des "marches" transversales formées de nucléotides.Définition . Les nucléotides sont des composés constitués de sucre, de bases azotées (purine ou pyrimidine) et d'acide phosphorique. Les nucléotides sont les «éléments constitutifs» de l'ADN et de l'ARN.
Cette hélice d'ADN est porteuse du code génétique - le code d'hérédité des traits des organismes des animaux et des plantes. Il s'agissait d'un nouveau travail complètement inhabituel sur la structure et les propriétés d'une molécule d'acide désoxyribonucléique.Le modèle d'ADN de jeunes auteurs a été confirmé en le comparant à un diagramme de diffraction des rayons X de la structure cristalline de l'ADN du biophysicien anglais Maurice Wilkins. Plus tard, un code génétique a été découvert contenant et transmettant des informations sur la synthèse de la structure et de la composition des protéines - les principaux composants de chaque cellule d'organismes vivants qui mettent en œuvre le cycle cellulaire.Définition . Le cycle cellulaire est l'alternance correcte de périodes de repos relatif avec des périodes de division cellulaire.
La même année, les auteurs ont publié plus tard un autre article décrivant un mécanisme possible pour copier l'ADN par synthèse matricielle dans la division des cellules vivantes. La double hélice d'ADN a été comparée à un «verrou de foudre».Chaque fil de la spirale, après avoir «défait le verrou» et dilué les fils, est devenu une matrice de synthèse et a été complété par un deuxième fil de matière du cytoplasme de la cellule selon le principe de complémentarité pour compléter l'ADN. Il a également déclaré qu'une certaine séquence de bases (codons, triplets) est un code qui contient des informations génétiques.L'idée de mathématiser le code a été exprimée pour la première fois par G. Gamov dans un article de 1954 comme le problème de la traduction de mots d'un alphabet à quatre lettres (système) en mots d'un alphabet à vingt lettres. Il a présenté le problème du codage des phénomènes de la vie non pas comme un problème biochimique, mais comme un problème mathématique combinatoire. Les efforts préliminaires de longue durée des auteurs de ce travail sont bien décrits dans le livre de D. Watson, The Thread of Life.En 1962, Watson, Crick et Wilkins ont reçu le prix Nobel de physiologie ou médecine "pour leurs découvertes dans la structure moléculaire des acides nucléiques et pour déterminer leur rôle dans le transfert d'informations dans la matière vivante".Ils avaient des informations sur les faits suivants:- En 1866, Gregor Mendel a formulé les dispositions selon lesquelles les "éléments", appelés plus tard gènes, déterminent l'héritage des propriétés physiques des individus de l'espèce.
- , , () , , .
- 1869 . , . . () (). . 4- ( ): (), (), (G), (); (), (U) , (G), (), ( ) .
- , , – , .
- 1950 . , 4- .
- , , .
- , 20- , (), .
- 1944 « ? ». : « - , , ?».
- 1954 , () 4- 20- , , .
Les chercheurs ont dû passer à l'étape suivante, et elle a été prise.Les hypothèses et les hypothèses ne manquaient pas, mais quelqu'un devait vérifier leur vérité.Codes qui se chevauchent (une lettre nucléotidique fait partie de plus d'un codon): triangulaire, majeur-mineur et séquentiel, proposé par Gamov et ses collègues;codes sans chevauchement: combinaison de Gamow et Ichas, le "code sans virgule" de Scream, Griffith et Orgel. Dans le code de combinaison, les acides aminés (20) sont codés par des triplets de 4 nucléotides, mais leur ordre n'est pas important, mais seulement leur composition: les triplets TTA, TAT, ATT codent le même acide aminé dans les protéines.Le code sans virgule a expliqué comment le «cadre de lecture» est sélectionné. Une telle «fenêtre coulissante» le long du brin d'ADN, où les lettres se succèdent sans séparateurs (virgules) en mots, suggère que les mots sont en quelque sorte différents. Selon le modèle de F. Crick, une hypothèse a été émise: tous les triplets sont divisés en sens, c'est-à-dire correspondant à des acides aminés spécifiques et n'ayant pas de sens.Si seuls des triplets significatifs forment l'ADN, alors dans un autre «cadre de lecture», ces triplets se révéleront vides de sens. Les auteurs de ce code ont montré qu'il est possible de choisir des triplets qui satisfont à ces exigences et qu'il y en a exactement 20. Bien sûr, les auteurs n'avaient pas pleinement confiance en leur exactitude.En effet, après 1960, il a été démontré que les codons, considérés par Crick comme insensés, effectuaient la synthèse des protéines in vitro et, en 1965, la signification des 64 codons triplets a été établie. Il s'est également avéré qu'un certain nombre d'acides aminés sont codés par deux, trois, quatre et même six triplets différents, c'est-à-dire qu'il existe une certaine redondance, dont le but reste à déterminer.Code génétique de la vie. Informations héritées
. – , ( , G, C, T), , . ( ) – . . .
Pour coder chacun des 20 types d'acides aminés canoniques, à partir desquels presque toutes les protéines sont construites, et le signal d'arrêt terminal, un ensemble de trois nucléotides (lettres) appelé triplet (codon) est suffisant. La séquence de codon forme un gène dans le brin chromosomique et détermine la séquence d'acides aminés dans la chaîne polypeptidique de la protéine codée par ce gène. Il y avait un concept de «un gène - une enzyme».La présentation classique de l'information (la linéarité de son enregistrement) est des textes au sens large (discours, lettres, livres, images, films, musique, etc.) de ce mot dans un certain langage naturel (EY). La langue comprend un vocabulaire étendu (vocabulaire), et si elle a une langue écrite en dehors de la langue parlée, alors l'alphabet avec une grammaire.Pour conserver les informations pendant longtemps et en transférer des copies, une mémoire et un système d'écriture solides et bien protégés sont nécessaires. L'information héréditaire des organismes vivants est écrite par l'EY de la nature dans de longs textes avec des mots dans un certain alphabet «moléculaire», qui sont stockés sous forme de chromosomes dans les noyaux de toutes les cellules des organismes vivants.Les processus et les moyens de transfert des informations enregistrées sur ses molécules porteuses naturelles sont formulés par F. Crick (1958) sous la forme du dogme central de la biologie moléculaire . Trois processus principaux permettent de contrôler tous les autres processus de fonctionnement cellulaire et la vie des organismes dans leur ensemble.Ces processus sont: la réplication , la transcription et la traduction. De plus, ils seront discutés plus en détail. L'information dans les organismes n'est transmise que dans une seule direction des acides nucléiques (ADN → ARN → protéine) à une protéine; la transmission inverse n'existe pas. Des cas particuliers ADN → protéine, ARN → ARN, ARN → ADN sont possibles.La lecture d'informations le long des chaînes moléculaires n'est autorisée que dans une seule direction. Le terme «cadre de lecture» est utilisé.Définition . Un cadre de lecture (ouvert) est une séquence de codons non chevauchants capables de synthétiser une protéine, commençant par un codon de départ et se terminant par un codon d'arrêt. La trame est déterminée par le tout premier triplet à partir duquel la diffusion commence.
Pour commencer la diffusion, un codon de démarrage ne suffit pas, vous avez également besoin d'un codon d'initiation (il y en a trois: AUG, GUG, UUG). Après sa lecture, la traduction a lieu en lisant séquentiellement les codons de l'ARNr ribosomique et en fixant les acides aminés les uns aux autres par le ribosome jusqu'à ce que le codon d'arrêt soit atteint.Pendant la traduction, les codons sont toujours «lus» à partir d'un symbole initiateur de départ (AUG) et ne se chevauchent pas. La lecture après le début du triplet après le triplet va jusqu'au codon d'arrêt de l'achèvement de la synthèse de la chaîne polypeptidique protéique.Ces faits sont résumés dans un tableau des méthodes de transmission des informations génétiques.Tableau 1 - Le dogme central de la biologie moléculaire L'histoire de l'étude des textes de l'hérédité des organismes, leur compréhension, longue, riche en découvertes, réalisations, délires et déceptions. La liste des événements de l'histoire de la compréhension (cognition) des textes de la nature présente un intérêt certain, tant pour la science que pour chaque individu.Les mots des textes sont très longs, mais l'alphabet d'écriture «nature EYA» ne contient que quatre lettres - ce sont des bases moléculaires: dans l'ARN c'est A (adénine), C (cytosine), G (guanine), U (uracile) (dans l'ADN, l'uracile est remplacé sur T (thymine)). Le langage de la faune est le langage des molécules.Les biologistes ont établi que chaque mot du texte de l'hérédité est formé par une molécule d'ADN polymère (acide désoxyribonucléique, découverte en 1868 par le médecin I.F.Misher), constituée de 4 bases (nucléotides - du nucléaire - nucléaire).Les bases sont liées (connectées) les unes aux autres par paires, A ← → T, T ← → A, G ← → C, C ← → G avec des liaisons hydrogène spéciales qui mettent en œuvre le principe de complémentarité (complémentarité). Ces faits ont été établis à différents moments, par différents scientifiques et méthodes de nombreuses sciences (physique, chimie, biologie, cytologie, génétique, etc.). Les difficultés à connaître ce NJ se sont constamment rencontrées.Les molécules d'ADN ne se sont pas cristallisées, mais lorsque cela a été fait, la tâche d'établir la structure de l'ADN a été réduite à résoudre le problème inverse de l'analyse de diffraction des rayons X (transformée de Fourier du diagramme de diffraction du cristal créé à l'écran par les rayons X).Le modèle calculé et assemblé à la main par J. Watson et Francis Crick en 1953 est similaire au jeu pour enfants LEGO, où les éléments étaient des bases moléculaires et les distances interatomiques et les angles de pivotement étaient très précisément maintenus, la structure chromosomique était reproduite à grande échelle.Ce modèle a pratiquement confirmé les diverses hypothèses des théoriciens et prouvé de manière convaincante l'absence de divergences avec les expériences pratiques et les résultats de l'analyse de diffraction des rayons X de l'ADN cristallin.Les principales données détaillées sur la structure chimique de l'ADN et les caractéristiques numériques du modèle ont été obtenues par Rosalinda Franklin et M. Wilkins plus tôt en 1953 dans le laboratoire d'analyse aux rayons X. Le conflit des scientifiques est décrit dans le roman "Loneliness on the Net" de Janusz Leon Wisniewski.La présence de la structure visuelle de l'ADN et de ses caractéristiques quantitatives a donné une impulsion au développement de la génétique et de toutes les biosciences, dont l'idée du projet du génome humain est née en 2000. Watson est devenu le premier chef de file de ce projet, l'ensemble chromosomique de l'Homo sapiens humain a été entièrement déchiffré au sein du projet. La carte génétique complète du 1er chromosome a été achevée en 2006. La carte contient 3141 gènes et 991 pseudogènes.Du point de vue des mathématiques, quatre éléments de l'alphabet peuvent être attribués à quatre éléments d'un champ de Galois étendu fini GF (2 2 ) = ( 0, 1, α, β ), les opérations avec lesquelles sont effectuées modulo le polynôme irréductible p (x) = x 2 + x + 1 . Alors α + β = 1, α ∙ β = 1et la cartographie des éléments de champ en lettres prend la forme
L'histoire de l'étude des textes de l'hérédité des organismes, leur compréhension, longue, riche en découvertes, réalisations, délires et déceptions. La liste des événements de l'histoire de la compréhension (cognition) des textes de la nature présente un intérêt certain, tant pour la science que pour chaque individu.Les mots des textes sont très longs, mais l'alphabet d'écriture «nature EYA» ne contient que quatre lettres - ce sont des bases moléculaires: dans l'ARN c'est A (adénine), C (cytosine), G (guanine), U (uracile) (dans l'ADN, l'uracile est remplacé sur T (thymine)). Le langage de la faune est le langage des molécules.Les biologistes ont établi que chaque mot du texte de l'hérédité est formé par une molécule d'ADN polymère (acide désoxyribonucléique, découverte en 1868 par le médecin I.F.Misher), constituée de 4 bases (nucléotides - du nucléaire - nucléaire).Les bases sont liées (connectées) les unes aux autres par paires, A ← → T, T ← → A, G ← → C, C ← → G avec des liaisons hydrogène spéciales qui mettent en œuvre le principe de complémentarité (complémentarité). Ces faits ont été établis à différents moments, par différents scientifiques et méthodes de nombreuses sciences (physique, chimie, biologie, cytologie, génétique, etc.). Les difficultés à connaître ce NJ se sont constamment rencontrées.Les molécules d'ADN ne se sont pas cristallisées, mais lorsque cela a été fait, la tâche d'établir la structure de l'ADN a été réduite à résoudre le problème inverse de l'analyse de diffraction des rayons X (transformée de Fourier du diagramme de diffraction du cristal créé à l'écran par les rayons X).Le modèle calculé et assemblé à la main par J. Watson et Francis Crick en 1953 est similaire au jeu pour enfants LEGO, où les éléments étaient des bases moléculaires et les distances interatomiques et les angles de pivotement étaient très précisément maintenus, la structure chromosomique était reproduite à grande échelle.Ce modèle a pratiquement confirmé les diverses hypothèses des théoriciens et prouvé de manière convaincante l'absence de divergences avec les expériences pratiques et les résultats de l'analyse de diffraction des rayons X de l'ADN cristallin.Les principales données détaillées sur la structure chimique de l'ADN et les caractéristiques numériques du modèle ont été obtenues par Rosalinda Franklin et M. Wilkins plus tôt en 1953 dans le laboratoire d'analyse aux rayons X. Le conflit des scientifiques est décrit dans le roman "Loneliness on the Net" de Janusz Leon Wisniewski.La présence de la structure visuelle de l'ADN et de ses caractéristiques quantitatives a donné une impulsion au développement de la génétique et de toutes les biosciences, dont l'idée du projet du génome humain est née en 2000. Watson est devenu le premier chef de file de ce projet, l'ensemble chromosomique de l'Homo sapiens humain a été entièrement déchiffré au sein du projet. La carte génétique complète du 1er chromosome a été achevée en 2006. La carte contient 3141 gènes et 991 pseudogènes.Du point de vue des mathématiques, quatre éléments de l'alphabet peuvent être attribués à quatre éléments d'un champ de Galois étendu fini GF (2 2 ) = ( 0, 1, α, β ), les opérations avec lesquelles sont effectuées modulo le polynôme irréductible p (x) = x 2 + x + 1 . Alors α + β = 1, α ∙ β = 1et la cartographie des éléments de champ en lettres prend la forme , et le nucléotide supplémentaire (complémentaire) est calculé selon la règle ¬ → x + 1 , d'où T → A + 1, C → G + 1.Structurellement, le modèle d'ADN représente deux chaînes polymères équidistantes de nucléotides connectés par paires (par le principe d'une échelle de corde) et torsadé en une double spirale droite. Ci-dessous dans le texte, des paires de lettres écrites verticalement correspondent aux étapes de "l'échelle":T A GGTTCG T ...
, et le nucléotide supplémentaire (complémentaire) est calculé selon la règle ¬ → x + 1 , d'où T → A + 1, C → G + 1.Structurellement, le modèle d'ADN représente deux chaînes polymères équidistantes de nucléotides connectés par paires (par le principe d'une échelle de corde) et torsadé en une double spirale droite. Ci-dessous dans le texte, des paires de lettres écrites verticalement correspondent aux étapes de "l'échelle":T A GGTTCG T ...
ATCCAAGCA ...Deux chaînes répètent la séquence de lettres, mais le début de l'une est situé en face de la fin de l'autre. Les informations contenues dans les molécules d'ADN sont enregistrées avec un haut degré de redondance, ce qui, bien sûr, offre un haut niveau de fiabilité lors de la lecture et de la copie d'informations (réplication: ADN → ADN). Un mot de plus est attribué au mot d'origine, mais en code supplémentaire.Tous les chromosomes contiennent des gènes dans leur composition et sont contenus dans chaque cellule dans un très petit volume (dans le noyau cellulaire) et sont courts et très longs. La distance entre les brins d'ADN est de 2 nm, entre les «étapes» - 0,31 nm, une révolution complète de «l'hélice» toutes les 10 paires. La longueur totale de tout l'ADN étiré en un brin atteint 2 m. Des informations héréditaires humaines sont enregistrées sur 23 chromosomes. La longueur du chromosome est d'environ 10 9nucléotides, et le diamètre du noyau est inférieur à un micromètre. Ainsi, l'ADN dans la cellule est compacté.Définition . Gène (grec.γενοζ - genre). L'unité structurelle et fonctionnelle de l'hérédité des organismes vivants. Les gènes (plus précisément les allèles) déterminent les traits héréditaires des organismes transmis des parents à la progéniture pendant la reproduction.
Dans les mots de l'ADN, il est possible d'isoler et de considérer des sous-parties individuelles (gènes) qui portent des informations intégrales sur la structure d'une molécule de protéine ou d'une molécule d'ARN. De plus, les gènes sont caractérisés par des séquences régulatrices (promoteurs).Les promoteurs peuvent être situés à proximité d'un cadre de lecture ouvert codant pour une protéine ou du début d'une séquence d'ARN, et à une distance de plusieurs millions de paires de bases (nucléotides), par exemple, dans les cas avec des amplificateurs, des isolants et des suppresseurs.Chaque gène est conçu et responsable de la création d'une protéine spécifique nécessaire à la vie du corps. Le concept de génotype désigne la constitution héréditaire des gamètes (cellules germinales) et des zygotes (cellules somatiques), contrairement au phénotype décrivant des caractères acquis qui ne sont pas hérités.Codes de blocage
Le code est un concept à valeurs multiples. Tout d'abord, un code peut être appelé un ensemble de codes de mots de code qui forment le code lui-même. Ce sont ces mots que le décodeur reconnaît du côté réception lors de la transmission des messages, et du côté émission, le codeur les forme.Lors de la génération de mots de code, un mappage unique d'un ensemble de caractères ordonné fini appartenant à un certain alphabet fini à un autre, pas nécessairement ordonné, généralement un ensemble de caractères plus étendu pour coder la transmission, le stockage ou la transformation des informations est utilisé. Nousénumérons les propriétés du code génétique considéré:- . . in Vitro ( ). () () .
- . , .
- . . ( ) – , , .
. . 4- , , 20 , , ( ) .
, (), 4; 2- (), 42 =16 ; () 43 = 64 > 20 . .
- . . , -, , - . .
. 64 1965 . , . , (). .
2 —

20 61 , . , . AUG – .
. . AGC, GCU, CUA,… , . , . .
- . - .
, . ( ) ( ) .
- . - , . : AUG ( ) , – .
- . . . 1961 . .
- – ;
- – ( ) .
Considérons deux ensembles discrets X et n contenant respectivement | X | et | n | éléments et cartographie φ : n → X . Lorsque nous représentons des mappages arbitraires d'ensembles avec des mots dans l'alphabet X, nous obtenons un ensemble de X n mots, chacun de n caractères de la longueur q = | X | disponible, qui forme l'alphabet des messages texte. Il est commode de disposer tous les mots X n dans l'ordre lexicographique dans une liste générale.Notre objectif dans cette partie du travail est de générer un code qui fournit le codage (conversion) des données transmises sous une forme pratique pour la transmission dans l'espace et le temps et la diffusion (traduction) d'une langue à une autre compréhensible pour le destinataire du message.La génération d'un code implique le choix de l'alphabet, la détermination de la régularité et lors du choix d'un code régulier, la détermination de la longueur du mot de code, la détermination du nombre de mots de code, la détermination de la composition lettre par mot de chaque mot.Tableau 3 - Le code génétique se compose de 64 mots de code de 3 lettres chacun Tableau 4 - Valeurs inverses de la séquence de code des triplets d'ARN
Tableau 4 - Valeurs inverses de la séquence de code des triplets d'ARN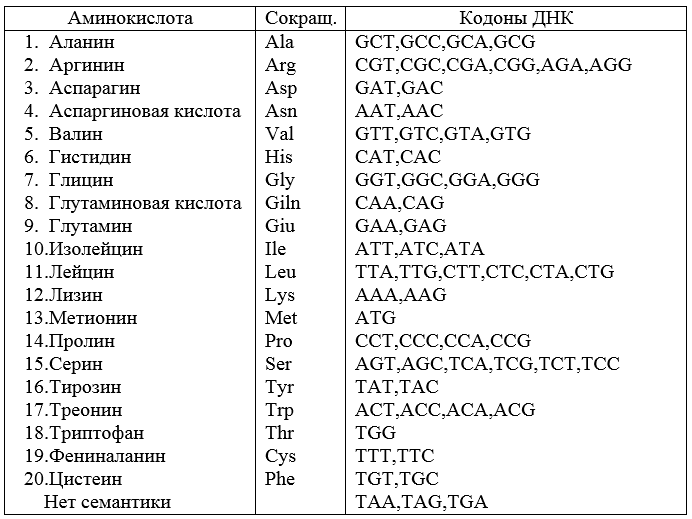 Les propriétés supplémentaires du code, par exemple, le code ne doit pas avoir de virgule, sont déterminées par des exigences plus strictes pour les paramètres de code nommés. Un code sans virgule doit avoir des mots avec une période maximale. Ces exigences sont axées sur la commodité de la synthèse ultérieure du codec. Le codage de l'information et son décodage sont étroitement liés à ces dispositions de synthèse de code.
Les propriétés supplémentaires du code, par exemple, le code ne doit pas avoir de virgule, sont déterminées par des exigences plus strictes pour les paramètres de code nommés. Un code sans virgule doit avoir des mots avec une période maximale. Ces exigences sont axées sur la commodité de la synthèse ultérieure du codec. Le codage de l'information et son décodage sont étroitement liés à ces dispositions de synthèse de code.Analyse de code
La tâche de l'analyse de code semble complètement différente lorsque le code existe déjà et est utilisé, mais on en sait peu sur lui-même. Les messages codés sont disponibles pour visualisation et étude, mais ils sont si divers et nombreux que le principe de leur création n'est pas visible même avec une analyse très approfondie.En fait, le système de codage lui-même est également disponible pour l'observation et l'étude, mais le niveau de complexité de sa construction et de son fonctionnement ne permet pas d'obtenir une description qualitative et fiable complète.Les informations (données) sont un message, c'est-à-dire une chaîne de caractères de l'alphabet, qui à partir d'une position de départ peut être divisée en segments (blocs) de longueur n caractères, et chacun de ces segments est un mot de code. Dans ce cas, le code est bloc.Du côté de la réception du canal de message, le destinataire doit être en mesure de diviser correctement la chaîne continue de caractères du message en mots séparés. L'utilisation de délimiteurs de mots (virgules) n'est pas souhaitable car elle nécessite des ressources.Synchronisation . Sans synchronisation, la traduction correcte du message est impossible. Cela implique l'une des exigences pour le code généré - le code doit être conçu de manière à ce que la synchronisation soit uniquement fournie par les moyens (propriétés) du code lui-même et par le dispositif de réception des informations.Définition . Le processus d'établissement d'une position contenant le caractère de début (initial) d'un mot de code est appelé synchronisation.
La tâche de synchronisation est simplement résolue si l'alphabet utilise un caractère de séparation de mots spécial, par exemple une virgule. Le cadre de lecture du mot de code suivant est défini immédiatement après le séparateur.
Un tel séparateur est pratique, mais indésirable pour plusieurs raisons.- Premièrement, le code doit être tel qu'au point d'arrivée du message il ait exactement la même forme qu'au point de départ (garantissant l'intégrité);
- Deuxièmement, le temps de codage, de décodage et de transmission devrait être aussi court que possible, car cela réduit la possibilité de distorsion des influences environnementales sur le texte du message;
- Troisièmement, il est souhaitable d'avoir une petite quantité de support de message, car elle nécessite moins de stockage, de protection et d'autres ressources.
Pour une meilleure distinction des mots de code, ils doivent être séparés les uns des autres d'une certaine distance dans la liste complète des mots possibles, c'est-à-dire diffèrent dans la composition des significations des symboles, car les vecteurs de l'espace vectoriel sont des composants.Par conséquent, les mots de code peuvent ne pas être tous et pas tous les mots de l'ensemble X n , mais seulement un sous-ensemble d'entre eux D є X n . Le choix de la composition symbolique des mots de code représente la tâche principale de sa formation, car c'est la composition des mots de code qui doit assurer la satisfaction des exigences formulées pour le code. Ainsi, nous examinerons plus en détail le code sans virgule.. , . = (1, 2, …, n) = (1, 2, …, n). || = (1, 2, …, n, 1, 2, …, n). n – 1 n n . .
. (2, …, n, 1), (3, …, n, 1, 2)…( n, 1,…, n-2, n-1), .
Si tous les chevauchements en concaténation pour une paire de mots de code ne sont pas des mots de code, alors le mécanisme du côté de réception (décodeur) du canal de transmission d'informations a la capacité de définir une position de départ unique. Ceci est possible si le décodeur de la liste D possède tous les mots de code et la possibilité de les faire correspondre avec n caractères lus du message reçu.Nous montrons comment cela se fait. Laissez un symbole être sélectionné et fixé dans la séquence de caractères reçue. Après avoir compté n caractères à partir du caractère fixe, le décodeur compare le mot qui s'est avéré avec les mots de la liste de codes. En cas de correspondance avec l'un des mots de la liste de codes, la synchronisation est établie. Le symbole fixe et sa position commencent.S'il n'y a aucune correspondance avec l'un des mots de la liste de codes, c'est-à-dire, appuyez sur le mot qui se chevauche, cela signifie que la position de départ est située à gauche de la position fixe.Nous nous déplaçons à la position gauche de la position fixe et répétons les actions de l'étape précédente jusqu'à ce que nous obtenions à une étape une correspondance avec l'un des mots de code. Ce processus a nécessairement abouti dans la position de départ correcte, c'est-à-dire que la synchronisation est établie en moyenne pour le nombre de n / 2 étapes.. () D є n n , , єD .
Nous avons déjà établi qu'un tel code assure une synchronisation correcte dans de longues chaînes de mots de code sans séparateurs entre eux. Quels mots de l'ensemble X n sont inclus dans le sous-ensemble D є X n ? Si la cardinalité de l'ensemble X n est divisée par des entiers, alors la cardinalité D peut être l'un de ces diviseurs (le théorème de groupe de Lagrange) et le code est appelé code de bloc de groupe sans virgule ., , D. , D n ( n D), . , D.
Passons à la question du nombre de mots dans le code généré.Codez le pouvoir sans virgule. Nous trouverons le plus grand nombre possible de mots dans le code D , que nous désignons par | D | = W n ( q) . Il n'est pas possible d'obtenir la signification exacte, mais une estimation supérieure du nombre de mots peut être obtenue en utilisant le concept de période de mots. Notons T k x le décalage cyclique d'un mot de longueur n par k pas, k < n .. d ( ) k, k = d ≤ n, d | n. d = n (). .
, = (1, 2, 3, 1, 2, 3 ) d < n. || . || = (1, 2, 3 ; 1, 2, 3 , 1, 2, 3 ; 1, 2, 3). , (;) , . , n.
n(q) q . D Wn(q) ≤ n(q)/n .


 Ainsi, pour les données source de l'exemple 1, à partir d'un ensemble de 64 mots arbitraires d'une longueur de 3 caractères, vous pouvez créer un code contenant 20 mots et assurant la synchronisation. Ce code n'est pas sans défauts. Si une erreur est introduite dans l'un des mots d'un seul caractère, le code ne sera pas synchronisé. En d'autres termes, le code est instable contre les erreurs.L'exemple numérique donné peut être utilisé pour illustrer et expliquer le code génétique des organismes vivants, qui a été créé par la nature sur un long chemin d'évolution et complètement déchiffré par la science moderne en 1966. Il est établi que le code génétique ne se chevauche pas et la signification (interprétation) de chaque codon est révélée.Le tableau final est le suivant (Fig. 2).Il résulte du tableau que le code est dégénéré. Cela signifie qu'il y a des synonymes dans le code, par exemple, GUU = GUC = Val, CGG = AGA = Arg , etc. Trois codons UAA, UAG, UGA n'ont pas de sens. Ce sont des codons de terminaison; l'apparition de l'un d'eux dans une séquence de caractères signifie la fin de la traduction (transmission). Un organisme meurt si, à la suite d'une erreur, la lettre du codon sémantique est changée en codon de terminaison.De tels changements sont possibles et sont appelés mutations.
Ainsi, pour les données source de l'exemple 1, à partir d'un ensemble de 64 mots arbitraires d'une longueur de 3 caractères, vous pouvez créer un code contenant 20 mots et assurant la synchronisation. Ce code n'est pas sans défauts. Si une erreur est introduite dans l'un des mots d'un seul caractère, le code ne sera pas synchronisé. En d'autres termes, le code est instable contre les erreurs.L'exemple numérique donné peut être utilisé pour illustrer et expliquer le code génétique des organismes vivants, qui a été créé par la nature sur un long chemin d'évolution et complètement déchiffré par la science moderne en 1966. Il est établi que le code génétique ne se chevauche pas et la signification (interprétation) de chaque codon est révélée.Le tableau final est le suivant (Fig. 2).Il résulte du tableau que le code est dégénéré. Cela signifie qu'il y a des synonymes dans le code, par exemple, GUU = GUC = Val, CGG = AGA = Arg , etc. Trois codons UAA, UAG, UGA n'ont pas de sens. Ce sont des codons de terminaison; l'apparition de l'un d'eux dans une séquence de caractères signifie la fin de la traduction (transmission). Un organisme meurt si, à la suite d'une erreur, la lettre du codon sémantique est changée en codon de terminaison.De tels changements sont possibles et sont appelés mutations.Définition . Les mutations sont des changements relativement stables de la substance héréditaire.
Chaque chromosome contient les gènes x1, x2, ..., xn , qui forment un trait complexe X du corps. Une paire de chromosomes dans une cellule obtenue par fusion de cellules germinales paternelles et maternelles se forme lors de la reproduction: un chromosome est obtenu du père, l'autre de la mère (paire diploïde de chromosomes).Dans les chromosomes homologues, tous les gènes coïncident dans leur fonction, mais peuvent différer de plusieurs nucléotides. Ces différences sont souvent le résultat de mutations, qui peuvent être causées par des produits chimiques, des rayonnements, une exposition radioactive, la température, des rayonnements ionisants.Les maladies héréditaires sont causées par des mutations similaires, fixées dans l'ensemble chromosomique des cellules germinales de l'un des parents. Un exemple connu d'un gène humain codant pour l'hémoglobine. Lors du remplacement de la lettre T par la lettre A , une autre forme d'hémoglobine apparaît dans une position du gène. Cela se manifeste dans une maladie appelée anémie falciforme.Lorsque la valeur du trait coïncide dans les deux chromosomes homologues, l'individu est appelé homozygote pour ce gène. Dans d'autres cas, une hétérozygotie se produit. L'homozygosité est caractérisée par des paires diploïdes de type a), et l'hétérozygosité par des paires de type b) (Fig.3) Figure 3 - paires diploïdes d'homozygotes et d'hétérozygotesAu lieu d'une paire diploïde, quatre chromosomes homologues A, A, a, a, sont forméset ils sont répartis également entre les quatre gamètes formés. Chaque gamète reçoit également l'un des chromosomes B, B, b, b, correspondant à un trait complexe. Cette distribution se produit pour les chromosomes indépendamment entre quatre gamètes et entre différents personnages. Ces faits ont été établis par Mendel et en 1865, il a publié.La caractéristique la plus impressionnante du code génétique est sa polyvalence. Le schéma donné (Fig. 1) peut être utilisé avec succès pour décoder l'ARN d'animaux et de plantes. En 1979, des résultats sont apparus sur le code génétique mitochondrial, qui diffère des valeurs de certains codons du tableau et des autres règles de reconnaissance des codons.La traduction est effectuée par le ribosome - un organe spécial de la cellule. La synchronisation (définition du cadre de lecture) s'effectue à l'aide du préfixe AGGAGGU , appelé séquence Shine-Dolgarno. Cette séquence purine est présente dans le mot au singulier, et la probabilité de sa distorsion est faible. Mais si une distorsion se produit, le corps sera en catastrophe.Figure 1 - Correspondance du mot de code avec les acides aminés Figure 2– ADN, ARNm et hélice protéique La
Figure 3 - paires diploïdes d'homozygotes et d'hétérozygotesAu lieu d'une paire diploïde, quatre chromosomes homologues A, A, a, a, sont forméset ils sont répartis également entre les quatre gamètes formés. Chaque gamète reçoit également l'un des chromosomes B, B, b, b, correspondant à un trait complexe. Cette distribution se produit pour les chromosomes indépendamment entre quatre gamètes et entre différents personnages. Ces faits ont été établis par Mendel et en 1865, il a publié.La caractéristique la plus impressionnante du code génétique est sa polyvalence. Le schéma donné (Fig. 1) peut être utilisé avec succès pour décoder l'ARN d'animaux et de plantes. En 1979, des résultats sont apparus sur le code génétique mitochondrial, qui diffère des valeurs de certains codons du tableau et des autres règles de reconnaissance des codons.La traduction est effectuée par le ribosome - un organe spécial de la cellule. La synchronisation (définition du cadre de lecture) s'effectue à l'aide du préfixe AGGAGGU , appelé séquence Shine-Dolgarno. Cette séquence purine est présente dans le mot au singulier, et la probabilité de sa distorsion est faible. Mais si une distorsion se produit, le corps sera en catastrophe.Figure 1 - Correspondance du mot de code avec les acides aminés Figure 2– ADN, ARNm et hélice protéique La figure 2 montre comment la séquence d'acides aminés dans une molécule de protéine est codée par une séquence de codon dans une molécule d'ADN. Ici, l'ARNm matriciel est une molécule intermédiaire. Ses chaînes divergent selon le principe de la «fermeture éclair», dans lequel le rôle de la serrure est joué par une enzyme qui rompt la molécule par les liaisons hydrogène.Dans les cellules, le code génétique est réalisé par trois processus matriciels: la réplication (se produit dans le noyau), la transcription et la traduction .La transcription (enregistrement alphabétique de l'ADN → ARNm) est un processus biologique dans les cellules eucaryotes qui se déroule dans le noyau cellulaire (séparé par une membrane nucléaire du cytoplasme) et est une synthèse de molécules d'i-ARN dans les régions d'ADN correspondantes. La séquence nucléotidique d'ADN est "réécrite" dans la même séquence d'ARN.Traduction (lecture et traduction de l'ARN → protéine) le processus biologique dans les cellules procaryotes est combiné avec le processus de transcription, se produit dans le cytoplasme cellulaire, sur les ribosomes; la séquence de nucléotides d'ARNm est transportée du noyau et traduite en séquence d'acides aminés (synthèse de la chaîne polypeptidique sur la matrice d'ARNm): cette étape se déroule avec la participation de l'ARN de transport (ARNt) et des enzymes correspondantes.Ainsi, la traduction est une synthèse protéique par le ribosome basée sur des informations enregistrées dans l'ARNm de la matrice. Pour obtenir 20 acides aminés, ainsi qu'un signal d'arrêt, signifiant la fin d'une séquence protéique, trois nucléotides consécutifs, appelés triplets, suffisent.Les organismes vivants sont répartis entre les plantes et les animaux par espèce.
figure 2 montre comment la séquence d'acides aminés dans une molécule de protéine est codée par une séquence de codon dans une molécule d'ADN. Ici, l'ARNm matriciel est une molécule intermédiaire. Ses chaînes divergent selon le principe de la «fermeture éclair», dans lequel le rôle de la serrure est joué par une enzyme qui rompt la molécule par les liaisons hydrogène.Dans les cellules, le code génétique est réalisé par trois processus matriciels: la réplication (se produit dans le noyau), la transcription et la traduction .La transcription (enregistrement alphabétique de l'ADN → ARNm) est un processus biologique dans les cellules eucaryotes qui se déroule dans le noyau cellulaire (séparé par une membrane nucléaire du cytoplasme) et est une synthèse de molécules d'i-ARN dans les régions d'ADN correspondantes. La séquence nucléotidique d'ADN est "réécrite" dans la même séquence d'ARN.Traduction (lecture et traduction de l'ARN → protéine) le processus biologique dans les cellules procaryotes est combiné avec le processus de transcription, se produit dans le cytoplasme cellulaire, sur les ribosomes; la séquence de nucléotides d'ARNm est transportée du noyau et traduite en séquence d'acides aminés (synthèse de la chaîne polypeptidique sur la matrice d'ARNm): cette étape se déroule avec la participation de l'ARN de transport (ARNt) et des enzymes correspondantes.Ainsi, la traduction est une synthèse protéique par le ribosome basée sur des informations enregistrées dans l'ARNm de la matrice. Pour obtenir 20 acides aminés, ainsi qu'un signal d'arrêt, signifiant la fin d'une séquence protéique, trois nucléotides consécutifs, appelés triplets, suffisent.Les organismes vivants sont répartis entre les plantes et les animaux par espèce.. – , . , , .
La division cellulaire est de deux types: l'une pour la formation de cellules somatiques (cellules du corps), l'autre pour la formation de cellules germinales (gamètes). Le type d'organisme est déterminé par la présence, le nombre et la composition des chromosomes dans les cellules des organismes inchangés (constants). La croissance et le développement normaux du corps sont assurés par la formation et la croissance de cellules somatiques à la suite de la mitose. Dans la mitose, tous les chromosomes situés dans le noyau cellulaire doublent avant le début de la division cellulaire (réplication de l'ADN) et sont répartis également entre deux cellules filles. L'ensemble des chromosomes 2n2c dans chaque cellule somatique est exactement le même. La mitose maintient un nombre diploïde constant de chromosomes dans les cellules.Un autre processus de méiose est la formation de gamètes, nécessaires à la continuation du genre des organismes. Dans la méiose, chaque cellule se divise deux fois et le nombre de chromosomes double une fois. La méiose conduit à la formation de cellules diploïdes avec des gamètes haploïdes avec un ensemble de n2c . Avec la fécondation ultérieure, les gamètes forment un organisme de nouvelle génération avec un caryotype diploïde (nc + nc = 2n2c) .Ce mécanisme est réalisé chez toutes les espèces qui se reproduisent sexuellement. La méiose assure la constance des ensembles de chromosomes (caryotypes) - l'hérédité et la création de nouvelles combinaisons de variabilité génotypique des gènes paternels et maternels.Le travail proposé ouvre la possibilité d'utiliser le code génétique pour résoudre les tâches de protection de l'information. Une compréhension correcte du phénomène de la nature et de son utilisation n'est possible qu'avec la dépense d'effort de la part du chercheur, qui n'est pas arrêté par des difficultés dans la voie d'une connaissance profonde de la nature qui nous entoure et de ses manifestations.
La croissance et le développement normaux du corps sont assurés par la formation et la croissance de cellules somatiques à la suite de la mitose. Dans la mitose, tous les chromosomes situés dans le noyau cellulaire doublent avant le début de la division cellulaire (réplication de l'ADN) et sont répartis également entre deux cellules filles. L'ensemble des chromosomes 2n2c dans chaque cellule somatique est exactement le même. La mitose maintient un nombre diploïde constant de chromosomes dans les cellules.Un autre processus de méiose est la formation de gamètes, nécessaires à la continuation du genre des organismes. Dans la méiose, chaque cellule se divise deux fois et le nombre de chromosomes double une fois. La méiose conduit à la formation de cellules diploïdes avec des gamètes haploïdes avec un ensemble de n2c . Avec la fécondation ultérieure, les gamètes forment un organisme de nouvelle génération avec un caryotype diploïde (nc + nc = 2n2c) .Ce mécanisme est réalisé chez toutes les espèces qui se reproduisent sexuellement. La méiose assure la constance des ensembles de chromosomes (caryotypes) - l'hérédité et la création de nouvelles combinaisons de variabilité génotypique des gènes paternels et maternels.Le travail proposé ouvre la possibilité d'utiliser le code génétique pour résoudre les tâches de protection de l'information. Une compréhension correcte du phénomène de la nature et de son utilisation n'est possible qu'avec la dépense d'effort de la part du chercheur, qui n'est pas arrêté par des difficultés dans la voie d'une connaissance profonde de la nature qui nous entoure et de ses manifestations.