Une condition typique pour implémenter CI / CD dans Kubernetes: l'application doit être en mesure d'arrêter d'accepter de nouvelles demandes de clients avant de s'arrêter, et surtout, de terminer avec succès les demandes existantes. Le respect de cette condition vous permet de réaliser zéro temps d'arrêt pendant le déploiement. Cependant, même lorsque vous utilisez des bundles très populaires (tels que NGINX et PHP-FPM), vous pouvez rencontrer des difficultés qui entraîneront une vague d'erreurs à chaque déploiement ...
Le respect de cette condition vous permet de réaliser zéro temps d'arrêt pendant le déploiement. Cependant, même lorsque vous utilisez des bundles très populaires (tels que NGINX et PHP-FPM), vous pouvez rencontrer des difficultés qui entraîneront une vague d'erreurs à chaque déploiement ...Théorie. Comment vit pod
Nous avons déjà publié cet article en détail sur le cycle de vie des pods . Dans le cadre de cette rubrique, nous nous intéressons à ce qui suit: au moment où le pod entre dans l'état Terminating , de nouvelles requêtes lui sont envoyées (le pod est supprimé de la liste des endpoints pour le service). Ainsi, pour éviter les temps d'arrêt lors du déploiement, de notre côté, il suffit de résoudre correctement le problème de l'arrêt de l'application.Il ne faut pas oublier non plus que le délai de grâce est de 30 secondes par défaut : après cela, le pod sera arrêté et l'application devrait réussir à traiter toutes les demandes avant ce délai. Remarque: bien que toute demande qui s'exécute pendant plus de 5 à 10 secondes soit déjà problématique, et un arrêt gracieux ne l'aidera plus ...Pour mieux comprendre ce qui se passe lorsque le pod termine son travail, il suffit d'étudier le schéma suivant: A1, B1 - Obtenir des modifications état du sous
A1, B1 - Obtenir des modifications état du sous
A2: Envoi de SIGTERM
B2 - Suppression du pod des noeuds finaux
B3 - Obtention des modifications (la liste des noeuds finaux a changé)
B4 - Mise à jour des règles iptablesRemarque: la suppression du pod de noeud final et l'envoi de SIGTERM ne se produisent pas séquentiellement, mais en parallèle. Et du fait qu'Ingress ne reçoit pas immédiatement une liste mise à jour des Endpoints, les nouvelles demandes des clients seront envoyées au pod, ce qui provoquera 500 erreurs lors de la terminaison du pod(nous avons traduit des informations plus détaillées sur cette question ) . Vous devez résoudre ce problème de la manière suivante:- Envoyez les en-têtes de Connection: close response (s'il s'agit d'une application HTTP).
- S'il n'y a aucun moyen d'apporter des modifications au code, l'article décrit une solution qui vous permettra de traiter les demandes jusqu'à la fin de la période de grâce.
Théorie. Comment NGINX et PHP-FPM mettent fin à leurs processus
Nginx
Commençons par NGINX, car tout est plus ou moins évident avec lui. Immergé dans la théorie, nous apprenons que NGINX a un processus maître et plusieurs «travailleurs» - ce sont des processus enfants qui traitent les demandes des clients. Une fonctionnalité pratique est fournie: utiliser la commande pour nginx -s <SIGNAL>terminer les processus soit en mode d'arrêt rapide soit en mode d'arrêt progressif. Évidemment, nous nous intéressons précisément à cette dernière option.Ensuite, tout est simple: vous devez ajouter une commande au hook preStop qui enverra un signal d'arrêt progressif . Cela peut être fait dans Déploiement, dans le bloc conteneur: lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
Maintenant, au moment où le pod termine son travail dans les journaux de conteneur NGINX, nous allons voir ce qui suit:2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting down
Et cela signifiera ce dont nous avons besoin: NGINX attend la fin des requêtes, puis tue le processus. Cependant, un problème courant sera discuté ci-dessous, à cause duquel, même s'il existe une commande, le nginx -s quitprocessus ne se termine pas correctement.Et à ce stade, nous avons terminé avec NGINX: au moins, vous pouvez comprendre à partir des journaux que tout fonctionne comme il se doit.Et PHP-FPM? Comment gère-t-il un arrêt progressif? Faisons les choses correctement.PHP-FPM
Dans le cas de PHP-FPM, un peu moins d'informations. Si vous vous concentrez sur le manuel officiel de PHP-FPM, il vous indiquera que les signaux POSIX suivants sont reçus:SIGINT, SIGTERM- arrêt rapide;SIGQUIT - arrêt gracieux (ce dont nous avons besoin).
Les autres signaux de ce problème ne sont pas nécessaires, par conséquent, leur analyse est omise. Pour terminer le processus correctement, vous devrez écrire le hook preStop suivant: lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"
À première vue, c'est tout ce qui est nécessaire pour effectuer un arrêt progressif dans les deux conteneurs. Cependant, la tâche est plus compliquée qu'il n'y paraît. Ensuite, nous avons examiné deux cas dans lesquels l'arrêt progressif n'a pas fonctionné et a causé une inaccessibilité à court terme du projet pendant le déploiement.Entraine toi. Problèmes possibles avec un arrêt progressif
Nginx
Tout d'abord, il est utile de se souvenir: en plus d'exécuter la commande, nginx -s quitil y a une autre étape à laquelle vous devez faire attention. Nous avons rencontré un problème lorsque NGINX au lieu d'un signal SIGQUIT a quand même envoyé SIGTERM, à cause duquel les demandes ne se sont pas terminées correctement. Des cas similaires peuvent être trouvés, par exemple, ici . Malheureusement, nous n'avons pas pu établir une raison spécifique à ce comportement: il y avait un soupçon de la version NGINX, mais cela n'a pas été confirmé. La symptomatologie était que dans les journaux du conteneur NGINX les messages "socket ouvert # 10 laissé dans la connexion 5" ont été observés , après quoi le pod s'est arrêté.Nous pouvons observer un tel problème, par exemple, par les réponses à l'entrée dont nous avons besoin: Indicateurs de code d'état au moment du déploiementDans ce cas, nous obtenons uniquement le code d'erreur 503 d'Ingress lui-même: il ne peut pas accéder au conteneur NGINX, car il n'est plus disponible. Si vous regardez les journaux du conteneur avec NGINX, ils contiennent les éléments suivants:
Indicateurs de code d'état au moment du déploiementDans ce cas, nous obtenons uniquement le code d'erreur 503 d'Ingress lui-même: il ne peut pas accéder au conteneur NGINX, car il n'est plus disponible. Si vous regardez les journaux du conteneur avec NGINX, ils contiennent les éléments suivants:[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13
Après avoir modifié le signal d'arrêt, le conteneur commence à s'arrêter correctement: cela est confirmé par le fait qu'une erreur 503 n'est plus observée.Si vous rencontrez un problème similaire, il est logique de déterminer quel signal d'arrêt est utilisé dans le conteneur et à quoi ressemble exactement le crochet preStop. Il est possible que la raison réside précisément dans cela.PHP-FPM ... et plus
Le problème avec PHP-FPM est décrit de manière triviale: il n'attend pas la fin des processus enfants, les termine, à cause de quoi il y a 502 erreurs lors du déploiement et d'autres opérations. Depuis 2005, plusieurs messages d'erreur sur bugs.php.net (par exemple ici et ici ) décrivent ce problème. Mais dans les journaux, vous ne verrez probablement rien: PHP-FPM annoncera l'achèvement de son processus sans aucune erreur ou notification tierce.Il convient de préciser que le problème lui-même peut, dans une plus ou moins grande mesure, dépendre de l'application elle-même et peut ne pas apparaître, par exemple, dans la surveillance. Si vous le rencontrez toujours, une solution de contournement simple vient à l’esprit: ajoutez un crochet preStop avecsleep(30). Il vous permettra de terminer toutes les demandes précédentes (nous n'en acceptons pas de nouvelles, car le pod est déjà à l'état de fin ), et après 30 secondes, le pod se terminera avec un signal SIGTERM.Il s'avère que lifecyclepour le conteneur, il ressemblera à ceci: lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"
Cependant, en raison de l'indication de 30 secondes, sleepnous augmenterons considérablement le temps de déploiement, car chaque pod sera interrompu pendant au moins 30 secondes, ce qui est mauvais. Que peut-on faire avec ça?Passons maintenant au responsable de l'exécution directe de la demande. Dans notre cas, il s'agit de PHP-FPM , qui par défaut ne surveille pas l'exécution de ses processus enfants : le processus maître se termine immédiatement. Ce comportement peut être modifié à l'aide d'une directive process_control_timeoutqui spécifie les délais d'attente des signaux du maître par les processus enfants. Si vous définissez la valeur sur 20 secondes, cela couvrira la plupart des demandes en cours d'exécution dans le conteneur, et après leur achèvement, le processus maître sera arrêté.Avec cette connaissance, nous reviendrons sur notre dernier problème. Comme déjà mentionné, Kubernetes n'est pas une plateforme monolithique: il faut un certain temps pour l'interaction entre ses différents composants. Cela est particulièrement vrai lorsque nous considérons le travail d'Ingresss et d'autres composants connexes, car en raison d'un tel retard au moment du déploiement, il est facile d'obtenir une rafale de 500 erreurs. Par exemple, une erreur peut se produire au stade de l'envoi d'une demande en amont, mais le «décalage temporel» de l'interaction entre les composants est plutôt court - moins d'une seconde.Par conséquent, en conjonction avec la directive déjà mentionnée process_control_timeout, la construction suivante peut être utilisée pour lifecycle:lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]
Dans ce cas, nous compensons le retard de l'équipe sleepet n'augmentons pas significativement le temps de déploiement: y a-t-il une différence notable entre 30 secondes et une? .. En fait, le «travail principal» est pris en charge process_control_timeout, mais n'est lifecycleutilisé que comme «filet de sécurité» en cas de retard.De manière générale, le comportement décrit et la solution de contournement correspondante ne concernent pas uniquement PHP-FPM . Une situation similaire peut survenir d'une manière ou d'une autre lors de l'utilisation d'autres langages / frameworks. Si vous ne pouvez pas corriger l'arrêt progressif par d'autres moyens - par exemple, réécrivez le code afin que l'application traite correctement les signaux de terminaison - vous pouvez utiliser la méthode décrite. Ce n'est peut-être pas le plus beau, mais ça marche.Entraine toi. Test de charge pour vérifier les performances du pod
Le test de charge est un moyen de vérifier le fonctionnement du conteneur, car cette procédure vous rapproche des conditions de combat réelles lorsque les utilisateurs visitent le site. Vous pouvez utiliser Yandex.Tank pour tester les recommandations ci-dessus : il couvre parfaitement tous nos besoins. Ce qui suit sont des trucs et astuces pour tester avec un clair - grâce aux graphiques de Grafana et Yandex.Tank lui-même - un exemple de notre expérience.La chose la plus importante ici est de vérifier les changements par étapes.. Après avoir ajouté un nouveau correctif, exécutez le test et voyez si les résultats ont changé par rapport au lancement précédent. Sinon, il sera difficile d'identifier des solutions inefficaces et, à l'avenir, vous ne pourrez que nuire (par exemple, augmenter le temps de déploiement).Une autre mise en garde - regardez les journaux du conteneur lors de sa fermeture. Des informations sur l'arrêt progressif y sont-elles enregistrées? Y a-t-il des erreurs dans les journaux lors de l'accès à d'autres ressources (par exemple, un conteneur PHP-FPM voisin)? Erreurs de l'application elle-même (comme dans le cas de NGINX décrit ci-dessus)? J'espère que les informations d'introduction de cet article aideront à mieux comprendre ce qui arrive au conteneur lors de sa résiliation.Ainsi, le premier test a eu lieu sans lifecycleet sans directives supplémentaires pour le serveur d'applications (process_control_timeouten PHP-FPM). Le but de ce test était d'identifier le nombre approximatif d'erreurs (et si elles existent). De plus, d'après des informations supplémentaires, il faut savoir que le temps moyen de déploiement de chaque foyer était d'environ 5 à 10 secondes jusqu'à l'état de préparation complète. Les résultats sont les suivants: Une éclaboussure de 502 erreurs est visible sur le panneau d'informations Yandex.Tank, qui s'est produite au moment du déploiement et a duré jusqu'à 5 secondes en moyenne. Vraisemblablement, cela a mis fin aux demandes existantes adressées à l'ancien module lors de sa fermeture. Après cela, 503 erreurs sont apparues, ce qui était le résultat d'un conteneur NGINX arrêté, qui s'est également déconnecté en raison du backend (à cause duquel Ingress n'a pas pu s'y connecter).Voyons comment
Une éclaboussure de 502 erreurs est visible sur le panneau d'informations Yandex.Tank, qui s'est produite au moment du déploiement et a duré jusqu'à 5 secondes en moyenne. Vraisemblablement, cela a mis fin aux demandes existantes adressées à l'ancien module lors de sa fermeture. Après cela, 503 erreurs sont apparues, ce qui était le résultat d'un conteneur NGINX arrêté, qui s'est également déconnecté en raison du backend (à cause duquel Ingress n'a pas pu s'y connecter).Voyons commentprocess_control_timeouten PHP-FPM nous aidera à attendre la fin des processus enfants, c'est-à-dire corriger de telles erreurs. Déploiement répété à l'aide de cette directive: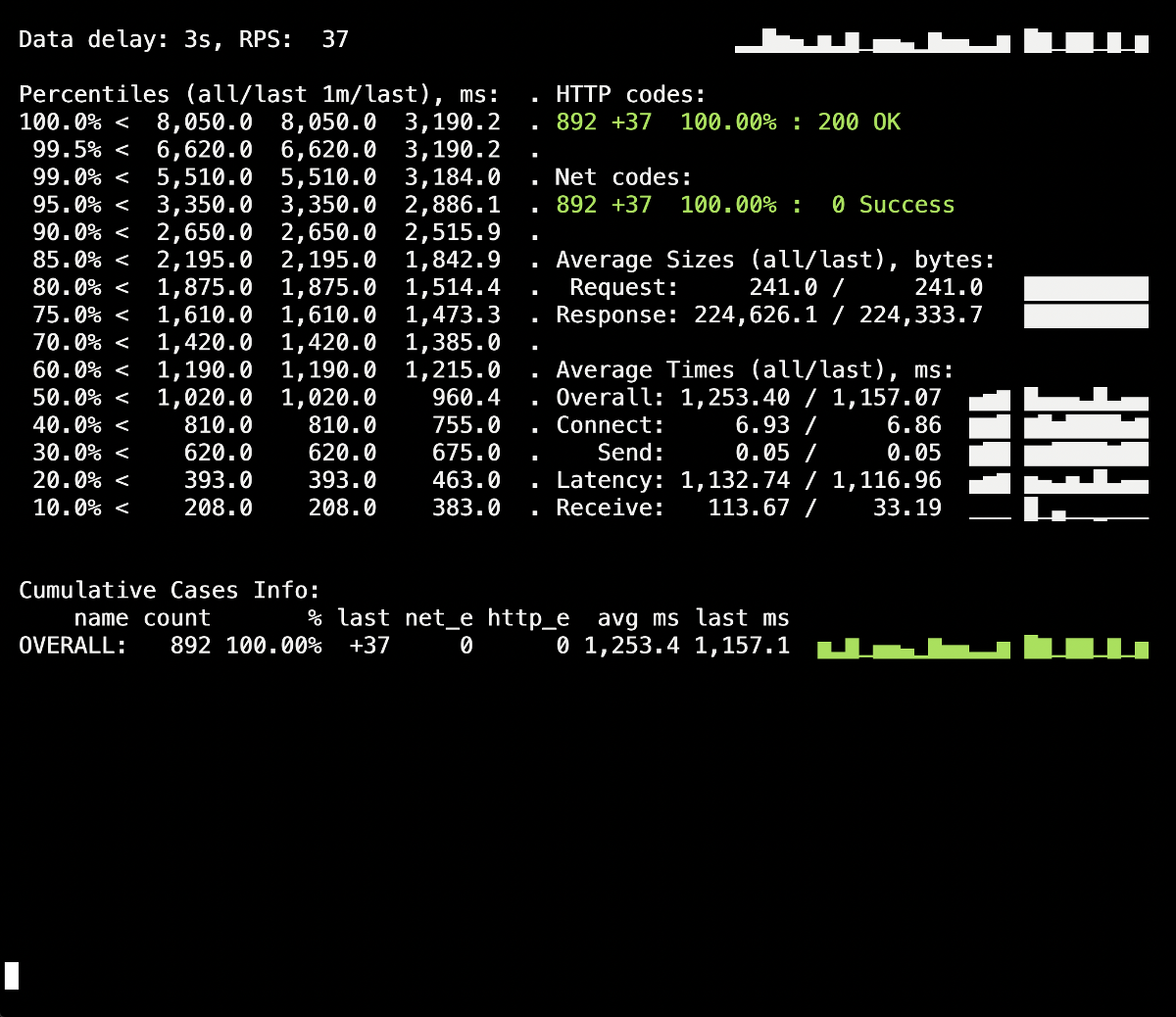 il n'y a plus d'erreurs lors du déploiement des 500! Le déploiement est réussi, l'arrêt progressif fonctionne.Cependant, il convient de se rappeler le moment avec les conteneurs Ingress, un petit pourcentage d'erreurs dans lesquelles nous pouvons obtenir en raison d'un décalage temporel. Pour les éviter, il reste à ajouter la construction avec
il n'y a plus d'erreurs lors du déploiement des 500! Le déploiement est réussi, l'arrêt progressif fonctionne.Cependant, il convient de se rappeler le moment avec les conteneurs Ingress, un petit pourcentage d'erreurs dans lesquelles nous pouvons obtenir en raison d'un décalage temporel. Pour les éviter, il reste à ajouter la construction avec sleepet à répéter le déploiement. Cependant, dans notre cas particulier, aucun changement n'était visible (pas encore d'erreurs).Conclusion
Pour l'achèvement correct du processus, nous attendons le comportement suivant de l'application:- Attendez quelques secondes, puis arrêtez d'accepter de nouvelles connexions.
- Attendez que toutes les demandes soient terminées et fermez toutes les connexions keepalive qui n'exécutent pas les demandes.
- Terminez votre processus.
Cependant, toutes les applications ne peuvent pas fonctionner de cette façon. Une solution au problème dans les réalités de Kubernetes est:- Ajout d'un crochet pré-stop qui attendra quelques secondes
- étudier le fichier de configuration de notre backend pour les paramètres pertinents.
L'exemple NGINX nous permet de comprendre que même une application qui initialement doit correctement traiter les signaux pour l'achèvement peut ne pas le faire, il est donc essentiel de vérifier 500 erreurs lors du déploiement de l'application. Il vous permet également de regarder le problème plus largement et de ne pas vous concentrer sur un pod ou un conteneur séparé, mais de regarder l'ensemble de l'infrastructure dans son ensemble.Yandex.Tank peut être utilisé comme outil de test conjointement avec tout système de surveillance (dans notre cas, les données de Grafana avec un backend sous la forme de Prométhée ont été prises pour le test). Les problèmes liés à l'arrêt progressif sont clairement visibles sous de lourdes charges que le benchmark peut générer, et la surveillance permet d'analyser la situation plus en détail pendant ou après le test.Répondre aux commentaires sur l'article: il convient de mentionner que les problèmes et les solutions sont décrits ici en relation avec NGINX Ingress. Pour d'autres cas, il existe d'autres solutions que, peut-être, nous considérerons dans les matériaux suivants du cycle.PS
Autres du cycle de trucs et astuces de K8: