Qu'est-ce qu'une structure de données?En termes simples, une structure de données est un conteneur dans lequel les données sont stockées dans une disposition spécifique (format ou la façon dont elles sont organisées en mémoire). Cette «disposition» permet à la structure de données d'être efficace dans certaines opérations et inefficace dans d'autres. Votre objectif est de comprendre les structures de données afin de pouvoir choisir la structure de données la plus optimale pour le problème en question.Pourquoi avons-nous besoin de structures de données?Étant donné que les structures de données sont utilisées pour stocker des données de manière organisée et que les données sont l'élément le plus important de l'informatique, la véritable valeur des structures de données est évidente.Quel que soit le problème que vous résolvez, vous devez traiter les données d'une manière ou d'une autre - que ce soit le salaire d'un employé, les cours des actions, la liste de courses ou même un simple annuaire téléphonique.En fonction de différents scénarios, les données doivent être stockées dans un format spécifique. Nous avons plusieurs structures de données qui couvrent la nécessité de stocker des données dans différents formats.Structures de données couramment utilisées Énuméronsd'abord les structures de données les plus couramment utilisées, puis examinons-les une par une:- Tableaux - Tableaux
- Stacks - Stacks
- Files d'attente - Files d'attente
- Listes liées - Listes associées
- Arbres - Arbres
- Graphs - graphs
- Essais (ce sont essentiellement des arbres, mais il est toujours agréable de les nommer séparément). - priorité
- Tables de hachage - tables de hachage
Tableaux - TableauxUn tableau est la structure de données la plus simple et la plus utilisée. D'autres structures de données, telles que les piles et les files d'attente, sont dérivées de tableaux.Voici une image d'un simple tableau de taille 4 contenant des éléments (1, 2, 3 et 4).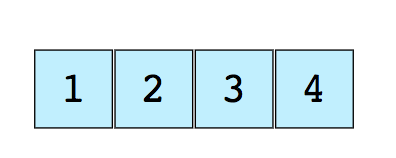 Chaque élément de données se voit attribuer une valeur numérique positive appelée index, qui correspond à la position de cet élément dans le tableau. La plupart des langues définissent l'index de départ d'un tableau comme 0.Les éléments suivants sont deux types de tableaux:
Chaque élément de données se voit attribuer une valeur numérique positive appelée index, qui correspond à la position de cet élément dans le tableau. La plupart des langues définissent l'index de départ d'un tableau comme 0.Les éléments suivants sont deux types de tableaux:- Tableaux unidimensionnels (comme indiqué ci-dessus)
- Tableaux multidimensionnels (tableaux à l'intérieur des tableaux) Tableaux multidimensionnels
Opérations de base sur les tableaux.Insérer - insère unélément à un index spécifié.Supprimer (Supprimer) - supprime un élément à un index spécifié.Taille - obtenir le nombre total d'éléments dans un tableau.Pour l'auto-apprentissage:1 Trouvez le deuxième élément minimum du tableau.2. Les premiers entiers non répétitifs du tableau.3. Fusionnez deux tableaux triés.4. Réorganisez les valeurs positives et négatives dans le tableau.PilesNous connaissons tous la fameuse option Annuler (Annuler), qui est présente dans presque toutes les applications. Vous êtes-vous déjà demandé comment cela fonctionne? L'essence du mécanisme est que vous enregistrez les états précédents de votre travail (qui sont limités par un certain nombre) en mémoire de telle sorte que la dernière action apparaisse en premier. Cela ne peut pas être fait uniquement avec des tableaux. C'est là que la pile est utile!Un exemple réel d'une pile est une pile de livres disposés verticalement. Pour obtenir un livre quelque part au milieu, vous devez supprimer tous les livres placés dessus. Voici comment fonctionne la méthode LIFO (Last In First Out) .Voici une image d'une pile contenant trois éléments de données (1, 2 et 3), où 3 est en haut et sera supprimé en premier: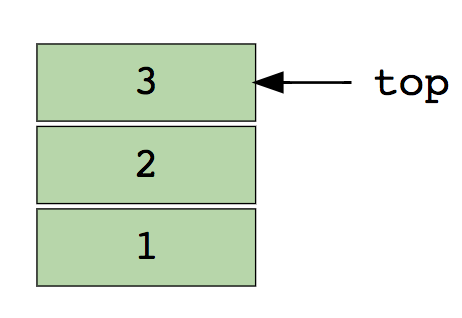 Les opérations de base avec les piles:Push - insère un élément au-dessus des autres.Pull (Pop) - renvoie l'élément supérieur après le retrait de la pile.Vide? (IsEmpty) - renvoie vrai (vrai) si la pile est vide.Top (Top) - renvoie l'élément supérieur sans le supprimer de la pile.Pour une étude indépendante:1. Évaluez l'expression du suffixe à l'aide de la pile.2. Triez les valeurs sur la pile.3. Vérifiez les crochets équilibrés dans l'expression.Files d'attenteComme une pile, une file d'attente est une autre structure de données linéaire dans laquelle les éléments sont stockés séquentiellement. La seule différence significative entre la pile et la file d'attente est qu'au lieu d'utiliser la méthode LIFO, Queue implémente une méthodeFIFO, qui est l'abréviation de First in First Out .Un bel exemple réel de ligne: plusieurs personnes attendent à la billetterie. Si une nouvelle personne vient, elle rejoint la ligne depuis la fin, pas depuis le début - et la personne debout devant sera la première à recevoir un ticket et, par conséquent, à quitter la ligne.Voici une image d'une file d'attente contenant quatre éléments de données (1, 2, 3 et 4), où 1 est en haut et sera supprimé en premier:
Les opérations de base avec les piles:Push - insère un élément au-dessus des autres.Pull (Pop) - renvoie l'élément supérieur après le retrait de la pile.Vide? (IsEmpty) - renvoie vrai (vrai) si la pile est vide.Top (Top) - renvoie l'élément supérieur sans le supprimer de la pile.Pour une étude indépendante:1. Évaluez l'expression du suffixe à l'aide de la pile.2. Triez les valeurs sur la pile.3. Vérifiez les crochets équilibrés dans l'expression.Files d'attenteComme une pile, une file d'attente est une autre structure de données linéaire dans laquelle les éléments sont stockés séquentiellement. La seule différence significative entre la pile et la file d'attente est qu'au lieu d'utiliser la méthode LIFO, Queue implémente une méthodeFIFO, qui est l'abréviation de First in First Out .Un bel exemple réel de ligne: plusieurs personnes attendent à la billetterie. Si une nouvelle personne vient, elle rejoint la ligne depuis la fin, pas depuis le début - et la personne debout devant sera la première à recevoir un ticket et, par conséquent, à quitter la ligne.Voici une image d'une file d'attente contenant quatre éléments de données (1, 2, 3 et 4), où 1 est en haut et sera supprimé en premier: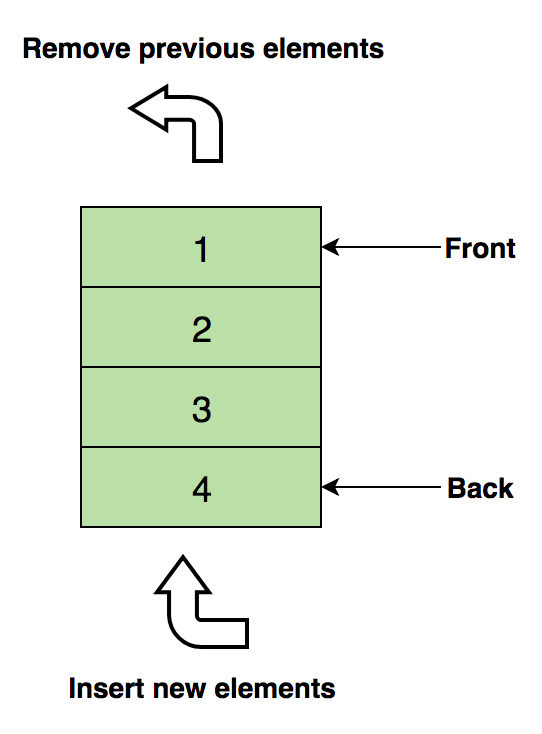 Opérations de base avec la file d'attente:Enqueue - insère un élément à la fin de la file d'attente.Dequeue - Supprime un élément depuis le début de la file d'attente.Vide? (IsEmpty) - renvoie vrai (vrai) si la file d'attente est vide.Top (Top) - renvoie le premier élément de la file d'attente.Pour une étude indépendante:1. Implémentation de la pile à l'aide de la file d'attente.2. Les k premiers éléments inverses de la file d'attente.3. Génération de nombres binaires de 1 à n en utilisant la file d'attente.Listeliée Une liste liée est une autre structure de données linéaire importante qui peut à première vue ressembler à des tableaux, mais qui diffère dans l'allocation de mémoire, la structure interne et la façon dont les opérations de base d'insertion et de suppression sont effectuées.Une liste chaînée est comme une chaîne de nœuds, où chaque nœud contient des informations telles que des données et un pointeur vers le nœud suivant de la chaîne. Il existe un pointeur d'en-tête qui pointe vers le premier élément de la liste liée, et si la liste est vide, elle pointe simplement vers zéro ou rien.Les listes liées sont utilisées pour implémenter des systèmes de fichiers, des tables de hachage et des listes de contiguïté.Voici une représentation visuelle de la structure interne d'une liste chaînée:
Opérations de base avec la file d'attente:Enqueue - insère un élément à la fin de la file d'attente.Dequeue - Supprime un élément depuis le début de la file d'attente.Vide? (IsEmpty) - renvoie vrai (vrai) si la file d'attente est vide.Top (Top) - renvoie le premier élément de la file d'attente.Pour une étude indépendante:1. Implémentation de la pile à l'aide de la file d'attente.2. Les k premiers éléments inverses de la file d'attente.3. Génération de nombres binaires de 1 à n en utilisant la file d'attente.Listeliée Une liste liée est une autre structure de données linéaire importante qui peut à première vue ressembler à des tableaux, mais qui diffère dans l'allocation de mémoire, la structure interne et la façon dont les opérations de base d'insertion et de suppression sont effectuées.Une liste chaînée est comme une chaîne de nœuds, où chaque nœud contient des informations telles que des données et un pointeur vers le nœud suivant de la chaîne. Il existe un pointeur d'en-tête qui pointe vers le premier élément de la liste liée, et si la liste est vide, elle pointe simplement vers zéro ou rien.Les listes liées sont utilisées pour implémenter des systèmes de fichiers, des tables de hachage et des listes de contiguïté.Voici une représentation visuelle de la structure interne d'une liste chaînée: Voici les types de listes chaînées:
Voici les types de listes chaînées:- Liste de liens uniques (unidirectionnelle)
- Liste doublement liée (bidirectionnelle)
Opérations de base sur une liste liéeInsertAtEnd - Insère un élément à la fin d'une liste liée.InsertB Start (InsertAtHead) - Insère un élément au début d'une liste liée.Supprimer - supprime cet élément de la liste liée.DeleteBeginning (DeleteAtHead) - supprime le premier élément de la liste liée.Rechercher - renvoie l'élément trouvé de la liste chaînée.Vide? (IsEmpty) - renvoie vrai (vrai) si la liste chaînée est vide.Pour une étude indépendante:1. Retournez la liste liée (Inverser, inverser, afficher en arrière).2. Définissez une boucle dans une liste chaînée.3. Renvoyez le Nième nœud de la fin de la liste chaînée.4. Supprimez les doublons de la liste liée.Graphs Lesgraphes sont un ensemble de nœuds connectés les uns aux autres sous la forme d'un réseau. Les nœuds sont également appelés sommets. La paire (x, y) est appelée arête, ce qui indique que le sommet x est connecté au sommet y. Une arête peut contenir du poids / coût, montrant combien il faut pour passer du sommet x à y.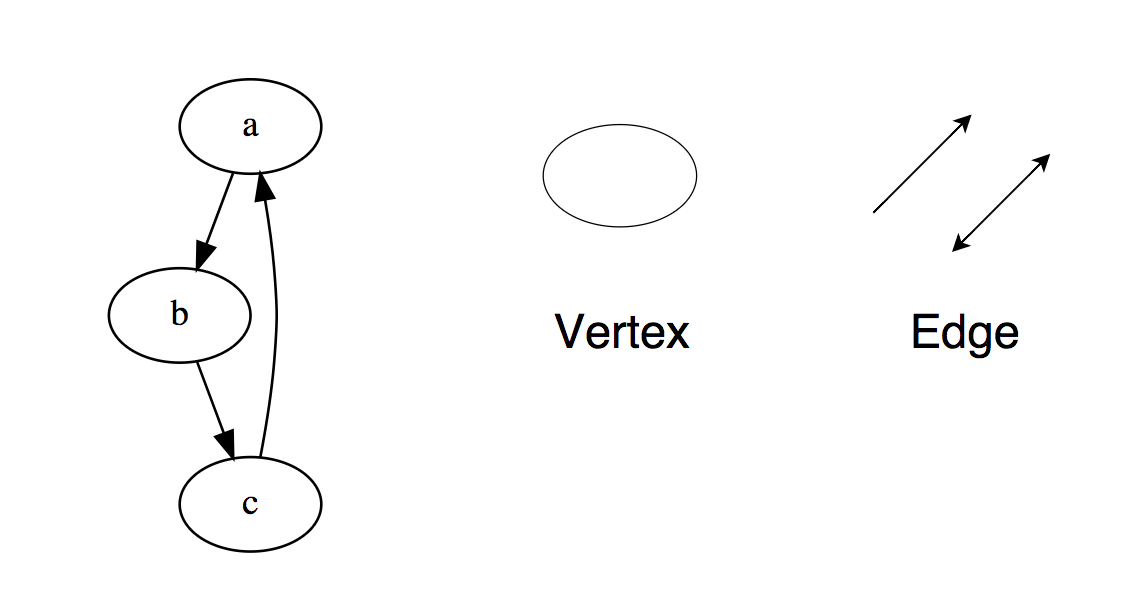 Types de graphiques:
Types de graphiques:- Graphique non orienté
- Graphique dirigé
Dans les langages de programmation, les graphiques sont représentés sous deux formes:Voici un exemple de liste contiguë d'adjacence (graphique non orienté).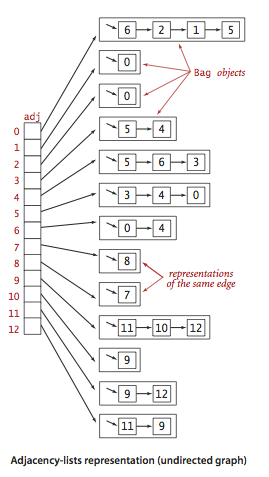 Exemples connus d'algorithmes de déplacement le long de graphiques:Pour une étude indépendante:1. Mise en œuvre de la recherche de largeur et de profondeur en premier2. Vérifiez si le graphique est un arbre ou non.3. Compter le nombre d'arêtes dans le graphique.4. Trouvez le chemin le plus court entre les pics.ArbresUn arbre est une structure de données hiérarchique composée de sommets (nœuds) et d'arêtes qui les relient. Les arbres ressemblent à des graphiques, mais le point clé qui distingue un arbre d'un graphique est qu'une boucle ne peut pas exister dans un arbre. Un arbre est un graphique déchiré.Les arbres sont largement utilisés dans l'intelligence artificielle et les algorithmes complexes pour fournir un mécanisme de stockage efficace pour les algorithmes de résolution de problèmes.Voici une image d'un arbre simple et les termes de base utilisés dans la structure de données de l'arbre:
Exemples connus d'algorithmes de déplacement le long de graphiques:Pour une étude indépendante:1. Mise en œuvre de la recherche de largeur et de profondeur en premier2. Vérifiez si le graphique est un arbre ou non.3. Compter le nombre d'arêtes dans le graphique.4. Trouvez le chemin le plus court entre les pics.ArbresUn arbre est une structure de données hiérarchique composée de sommets (nœuds) et d'arêtes qui les relient. Les arbres ressemblent à des graphiques, mais le point clé qui distingue un arbre d'un graphique est qu'une boucle ne peut pas exister dans un arbre. Un arbre est un graphique déchiré.Les arbres sont largement utilisés dans l'intelligence artificielle et les algorithmes complexes pour fournir un mécanisme de stockage efficace pour les algorithmes de résolution de problèmes.Voici une image d'un arbre simple et les termes de base utilisés dans la structure de données de l'arbre: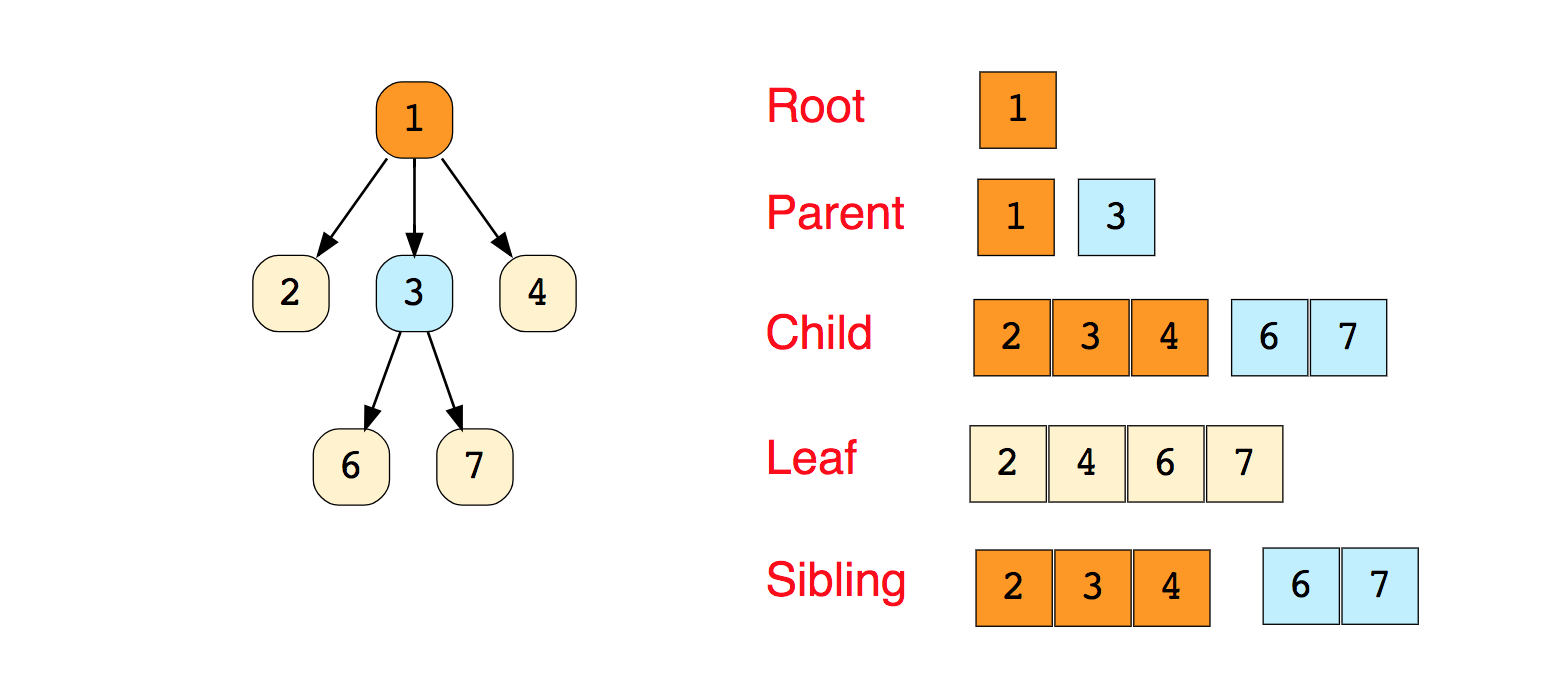 Il existe des types d'arbres:
Il existe des types d'arbres:- N-
- (Balanced Tree)
- (Binary Tree)
- (Binary Search Tree)
- AVL
- - (Red Black Tree)
- 2–3
D'après ce qui précède, l'arbre binaire et l'arbre de recherche binaire sont les arbres les plus couramment utilisés.Pour une étude indépendante:1. Trouvez la hauteur de l'arbre binaire.2. Recherchez la kième valeur maximale dans l'arborescence de recherche binaire.3. Trouvez les nœuds à une distance de "k" de la racine.4. Recherchez les ancêtres du nœud donné dans l'arbre binaire.Exemples pratiques:1. Facebook: chaque utilisateur est un sommet et deux personnes sont amis lorsqu'il y a un bord entre deux sommets. Les recommandations aux amis sont également calculées sur la base de la théorie des graphes.2. Google Maps: différents emplacements sont représentés par des pics et les routes sont représentées par des bords, la théorie des graphes est utilisée pour trouver le chemin le plus court entre deux pics.3. Réseaux de transport: en eux, les pics sont les intersections de routes et de côtes - ce sont les segments de route entre leurs intersections.4. Représentation des structures moléculaires où les sommets sont des molécules et les bords sont les liaisons entre les molécules.5. Processus de signalisation discrets dans les graphiques. ( et il y a un bon article ici aussi, et celui- ci en même temps )6. Les observations empiriques montrent que la plupart des gènes sont régulés par un petit nombre d'autres gènes, généralement moins de dix. Par conséquent, un réseau génétique peut être considéré comme un graphe clairsemé, c'est-à-dire un graphe dans lequel un nœud est connecté à plusieurs autres nœuds. Si les graphes orientés (acycliques) ou non orientés sont saturés de probabilités, le résultat est respectivement des modèles graphiques orientés probabilistes et des modèles graphiques probabilistes non orientés.7. Théorie de l'expansion du cluster Mayer de la fonction de volatilitégaz (Z) en thermodynamique nécessite le calcul de deux, trois, quatre conditions et ainsi de suite. Il existe un moyen systématique de le faire de manière combinatoire avec les graphiques, et cela permet de savoir à quel point les graphiques sont connectés. La connaissance de la théorie des graphes peut être utile lorsque vous souhaitez résumer un sous-ensemble de ces diagrammes.8. Coloration de la carte: le célèbre théorème des quatre couleurs stipule que vous pouvez toujours colorier correctement les régions de la carte de sorte qu'aucune région adjacente ne soit affectée à la même couleur en utilisant au plus quatre couleurs différentes. Dans ce modèle, les régions avec des couleurs sont des nœuds et les contiguïtés sont des bords du graphique.9. La tâche avec trois chalets est un puzzle mathématique bien connu. Il peut être formulé comme suit: Trois chalets sur un plan (ou une sphère), dont chacun doit être connecté à des sociétés de gaz, d'eau et d'électricité. Le problème est résolu à l'aide d'un graphique sur l'avion .10. Recherchez le centre du graphique: pour chaque sommet, trouvez la longueur du chemin le plus court jusqu'au sommet le plus éloigné. Le centre du graphique est le sommet pour lequel cette valeur est minimale. Ceci est important pour la planification architecturale des établissements dans lesquels un hôpital, un service d'incendie ou un poste de police doit être situé de sorte que le point le plus éloigné soit aussi proche que possible.Pour les amateurs de C #, comme moi, un lien avec des exemples de code graphique C # est ici. Pour la bibliothèque la plus avancée avec l'implémentation de graphes en C ++ ici . Pour les fans d'IA et de Skynet, piétinez ici .Séquences (Trie) Lesséquences, également appelées arbres avec préfixes (Prefix Trees), sont une structure de données semblable à un arbre qui est suffisamment efficace pour résoudre les problèmes associés aux chaînes. Ils fournissent une recherche rapide et sont principalement utilisés pour rechercher des mots dans un dictionnaire, des phrases automatiques dans un moteur de recherche et même pour le routage IP.Voici une illustration de la façon dont les trois mots «top», «ainsi» et «leur» sont stockés dans Priority: les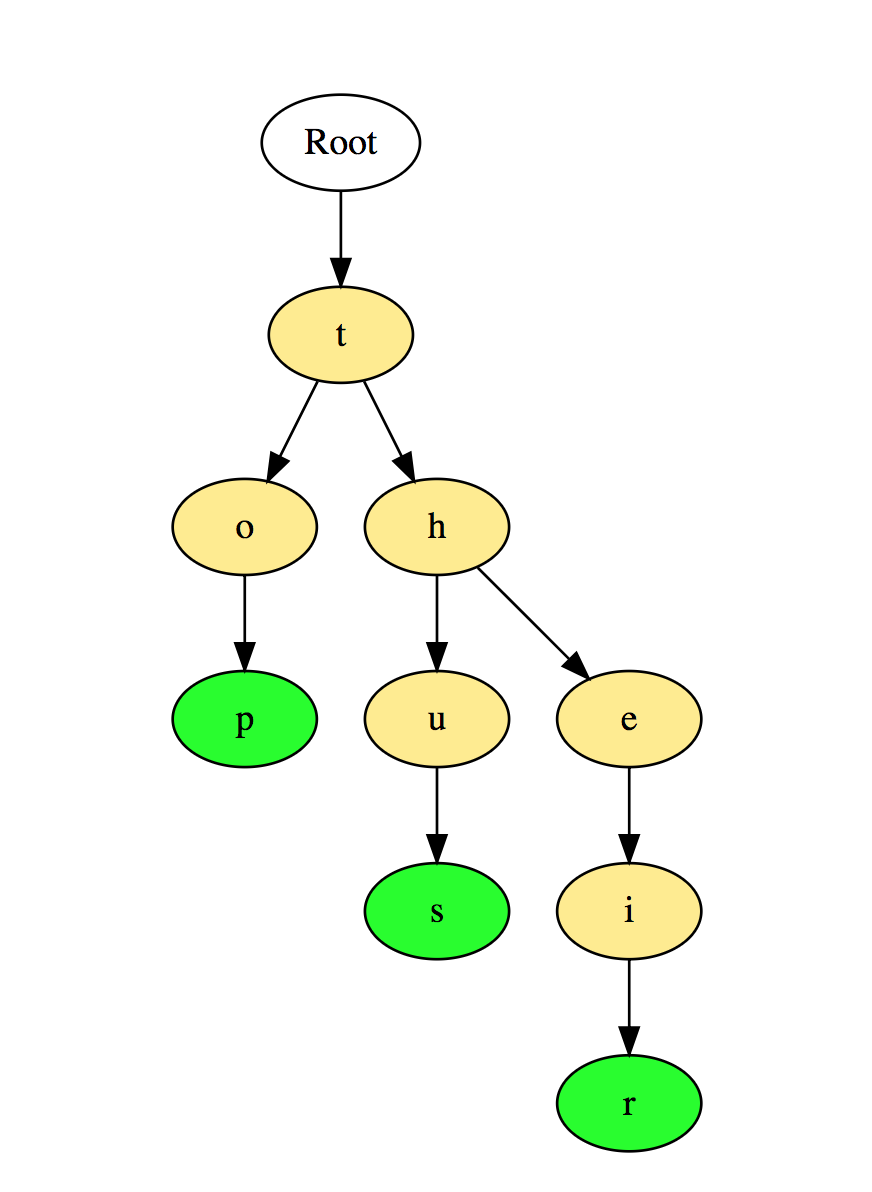 mots sont stockés de haut en bas, où les nœuds verts «p», «s» et «r» pointent vers la fin de «top», « ainsi ", et" leur ", respectivement.Pour une étude indépendante:1. Comptez le nombre total de mots dans la priorité.2. Imprimez tous les mots stockés dans la priorité.3. Tri des éléments du tableau à l'aide de Priority.4. Générez des mots à partir du dictionnaire à l'aide de files d'attente.5. Créez le dictionnaire T9.Exemples pratiques d'utilisation:1. Sélection dans le dictionnaire ou complétion lors de la frappe d'un mot.2. Recherchez dans les contacts du téléphone ou du dictionnaire téléphonique.Table de hachageLe hachage est un processus utilisé pour identifier de manière unique les objets et stocker chaque objet par un index unique pré-calculé appelé sa «clé». Ainsi, l'objet est stocké sous la forme d'une paire clé-valeur, et une collection de tels éléments est appelée un dictionnaire. Chaque objet peut être trouvé à l'aide de cette clé.Il existe différentes structures de données basées sur le hachage, mais la table de hachage est la structure de données la plus utilisée. Une table de hachage est utilisée lorsque vous devez accéder à des éléments avec une clé, et vous pouvez déterminer la valeur utile de la clé.Les tables de hachage sont généralement implémentées à l'aide de tableaux.Les performances de hachage d'une structure de données dépendent de ces trois facteurs:
mots sont stockés de haut en bas, où les nœuds verts «p», «s» et «r» pointent vers la fin de «top», « ainsi ", et" leur ", respectivement.Pour une étude indépendante:1. Comptez le nombre total de mots dans la priorité.2. Imprimez tous les mots stockés dans la priorité.3. Tri des éléments du tableau à l'aide de Priority.4. Générez des mots à partir du dictionnaire à l'aide de files d'attente.5. Créez le dictionnaire T9.Exemples pratiques d'utilisation:1. Sélection dans le dictionnaire ou complétion lors de la frappe d'un mot.2. Recherchez dans les contacts du téléphone ou du dictionnaire téléphonique.Table de hachageLe hachage est un processus utilisé pour identifier de manière unique les objets et stocker chaque objet par un index unique pré-calculé appelé sa «clé». Ainsi, l'objet est stocké sous la forme d'une paire clé-valeur, et une collection de tels éléments est appelée un dictionnaire. Chaque objet peut être trouvé à l'aide de cette clé.Il existe différentes structures de données basées sur le hachage, mais la table de hachage est la structure de données la plus utilisée. Une table de hachage est utilisée lorsque vous devez accéder à des éléments avec une clé, et vous pouvez déterminer la valeur utile de la clé.Les tables de hachage sont généralement implémentées à l'aide de tableaux.Les performances de hachage d'une structure de données dépendent de ces trois facteurs:- Fonction de hachage
- Taille de la table de hachage
- Méthode de traitement des collisions
Voici une illustration de la façon dont un hachage est affiché dans un tableau. L'index de ce tableau est calculé à l'aide d'une fonction de hachage.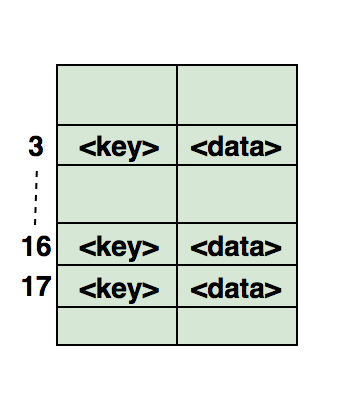 Pour une étude indépendante:1. Trouvez des paires symétriques dans le tableau.2. Suivez le parcours complet.3. Recherchez si le tableau est un sous-ensemble d'un autre tableau.4. Vérifiez si les tableaux donnés sont disjoints.Voici un exemple de code d'utilisation de table de hachage dans .Net
Pour une étude indépendante:1. Trouvez des paires symétriques dans le tableau.2. Suivez le parcours complet.3. Recherchez si le tableau est un sous-ensemble d'un autre tableau.4. Vérifiez si les tableaux donnés sont disjoints.Voici un exemple de code d'utilisation de table de hachage dans .Netstatic void Main(string[] args)
{
Hashtable ht = new Hashtable
{
{ "001", "Zara Ali" },
{ "002", "Abida Rehman" },
{ "003", "Joe Holzner" },
{ "004", "Mausam Benazir Nur" },
{ "005", "M. Amlan" },
{ "006", "M. Arif" },
{ "007", "Ritesh Saikia" }
};
if (ht.ContainsValue("Nuha Ali"))
{
Console.WriteLine(" !");
}
else
{
ht.Add("008", "Nuha Ali");
}
ICollection key = ht.Keys;
foreach (string k in key)
{
Console.WriteLine(k + ": " + ht[k]);
}
Console.ReadKey();
}
Exemples pratiques:1. Le jeu "Life". Dans ce document, un hachage est un ensemble de coordonnées de chaque cellule vivante.2. Une version primitive du moteur de recherche Google pourrait mapper tous les mots existants dans un ensemble d'URL où ils apparaissent. Dans ce cas, les tables de hachage sont utilisées deux fois: la première fois pour mapper des mots à des ensembles d'URL et, la deuxième fois, pour enregistrer chaque ensemble d'URL.3. Lors de la mise en œuvre d'une structure / algorithme d'arbre multi-voies, les tables de hachage peuvent être utilisées pour un accès rapide à tout élément enfant du nœud interne.4. Lors de l'écriture d'un programme pour jouer aux échecs, il est très important de garder une trace des positions qui ont été évaluées précédemment, afin que vous puissiez revenir quand vous en avez besoin si nécessaire.5. Tout langage de programmation doit mapper le nom de variable à son adresse en mémoire. En fait, dans les langages de script comme Javascript et Perl, des champs peuvent être ajoutés dynamiquement à l'objet, ce qui signifie que les objets eux-mêmes sont comme des cartes de hachage.