Lorsque Facebook «ment», les gens pensent que c'est à cause des pirates ou des attaques DDoS, mais ce n'est pas le cas. Toutes les «chutes» au cours des dernières années ont été causées par des changements ou des pannes internes. Afin d'enseigner aux nouveaux employés à ne pas casser Facebook avec des exemples, tous les incidents majeurs reçoivent des noms, par exemple, «Appelez les flics» ou «CAPSLOCK». Le premier a été nommé parce qu'un jour où le réseau social est tombé, les utilisateurs ont appelé la police de Los Angeles et ont demandé à le réparer, et le shérif désespéré sur Twitter a demandé de ne pas les déranger à ce sujet. Lors du deuxième incident sur les machines de cache, l'interface réseau est tombée en panne et n'a pas augmenté, et toutes les machines ont redémarré à la main.Elina Lobanovatravaille sur Facebook depuis 4 ans au sein de l'équipe Web Foundation. Les membres de l'équipe sont appelés ingénieurs de production et surveillent la fiabilité et les performances de l'ensemble du backend, éteignent Facebook lorsqu'il est allumé, écrivent la surveillance et l'automatisation pour leur faciliter la vie et celle des autres. Dans un article basé sur le rapport d'Elina sur HighLoad ++ 2019 , nous montrerons comment les ingénieurs de production surveillent le backend Facebook, quels outils ils utilisent, qui provoquent des plantages majeurs et comment y faire face.Je m'appelle Elina, il y a presque 5 ans, j'ai été appelée sur Facebook en tant que développeur ordinaire, où j'ai rencontré pour la première fois des systèmes très chargés - ce n'est pas enseigné dans les instituts. L'entreprise n'engage pas une équipe, mais un bureau, donc je suis arrivé à Londres, j'ai choisi une équipe qui surveille le travail de facebook.com et faisait partie des ingénieurs de production.
Dans un article basé sur le rapport d'Elina sur HighLoad ++ 2019 , nous montrerons comment les ingénieurs de production surveillent le backend Facebook, quels outils ils utilisent, qui provoquent des plantages majeurs et comment y faire face.Je m'appelle Elina, il y a presque 5 ans, j'ai été appelée sur Facebook en tant que développeur ordinaire, où j'ai rencontré pour la première fois des systèmes très chargés - ce n'est pas enseigné dans les instituts. L'entreprise n'engage pas une équipe, mais un bureau, donc je suis arrivé à Londres, j'ai choisi une équipe qui surveille le travail de facebook.com et faisait partie des ingénieurs de production.Ingénieurs de production
Pour commencer, je vais vous dire ce que nous faisons et pourquoi nous sommes appelés ingénieurs de production, et non SRE comme Google, par exemple.2009. SRE
Le modèle standard qui est encore utilisé dans de nombreuses entreprises est "développeurs - testeurs - exploitation". Ils sont souvent divisés: ils sont assis à différents étages, parfois même dans différents pays, et ne communiquent pas entre eux.En 2009, Facebook avait déjà SRE. Chez Google, SRE a commencé plus tôt, ils savent comment réaliser DevOps et l'ont écrit dans leur livre « Site Reliability Engineering ». Sur Facebook en 2009, il n'y avait rien de tel. Nous nous appelions SRE, mais nous avons fait le même travail que les Ops dans le reste du monde: travail manuel, pas d'automatisation, déploiement de tous les services avec vos mains, surveillance en quelque sorte, oncall pour tout, un ensemble de scripts shell.
Sur Facebook en 2009, il n'y avait rien de tel. Nous nous appelions SRE, mais nous avons fait le même travail que les Ops dans le reste du monde: travail manuel, pas d'automatisation, déploiement de tous les services avec vos mains, surveillance en quelque sorte, oncall pour tout, un ensemble de scripts shell.2010. SRO et AppOps
Tout cela n'a pas évolué, car le nombre d'utilisateurs à cette époque augmentait 3 fois par an, et le nombre de services a augmenté en conséquence. En 2010, la décision volontariste d'Ops a été divisée en deux groupes.Le premier groupe est SRO , où «O» est «opérations», engagé dans le développement, l'automatisation et la surveillance du site.Le deuxième groupe est AppOps , ils ont été intégrés en équipes, chacune pour de grands services. AppOps est déjà proche de l'idée de DevOps.La séparation pendant un certain temps a sauvé tout le monde.2012. Ingénieurs de production
En 2012, AppOps a simplement renommé les ingénieurs de production . En plus du nom, rien n'a changé, mais il est devenu plus confortable. Comme vous appelez un yacht, il naviguera et nous ne voulions pas naviguer comme Ops.Les OAR existaient toujours, Facebook se développait et surveiller tous les services à la fois était difficile. Une personne qui était sur appel n'a même pas été autorisée à aller aux toilettes: il a demandé à quelqu'un de le remplacer, car il brûlait constamment.2014. Clôture des OAR
À un moment donné, les autorités ont transféré tout le monde en appel. «Tout le monde» signifie aussi les développeurs: écrivez votre code, vous y êtes et répondez pour ce code!Les ingénieurs de production ont déjà été intégrés dans les équipes les plus importantes pour obtenir de l'aide, et les autres n'ont pas de chance. Nous avons commencé avec de grandes équipes et en quelques années, nous avons transféré tout le monde sur Facebook vers oncall. Parmi les développeurs, il y avait une grande excitation: quelqu'un a démissionné, quelqu'un a écrit de mauvais articles. Mais tout s'est calmé et en 2014, le SRO a été fermé car il n'était plus nécessaire. Nous vivons donc à ce jour.Le mot «SRE» dans l'entreprise est notoire, mais nous ressemblons à SRE sur Google. Il y a des différences.- Nous sommes toujours intégrés dans des équipes. Nous n'avons pas de recherche SRE en général, comme dans Google, c'est pour chaque service de recherche séparément.
- Nous ne sommes pas dans les produits , seulement dans l'infrastructure que le produit gère lui-même.
- Nous sommes en contact avec les développeurs.
- Nous avons un peu plus d'expérience dans les systèmes et les réseaux, nous nous concentrons donc sur la surveillance et l'extinction des services lorsqu'ils brûlent fortement. Nous corrigeons à l'avance les erreurs qui pourraient entraîner des plantages et influencer l'architecture des nouveaux services dès le début, afin qu'ils fonctionnent plus tard en douceur.
surveillance
C'est le plus important. Comment faisons-nous cela? Comme tout le monde: sans magie noire, dans leur propre maison. Mais le diable, comme d'habitude, vous en parlera en détail.UN HAUT
Commençons par le bas. Tout le monde connaît TOP sous Linux, et nous utilisons ATOP, où «A» est «avancé» - un moniteur de performances système. Le principal avantage d'ATOP est qu'il stocke l'historique: vous pouvez le configurer pour enregistrer des instantanés sur le disque. Notre ATOP fonctionne sur toutes les machines toutes les 5 secondes.Voici un exemple de serveur exécutant le backend PHP pour facebook.com. Nous avons écrit notre machine virtuelle pour exécuter du code PHP, elle s'appelle HHVM (HipHop Virtual Machine). Selon les métriques exportées, nous avons constaté que plusieurs machines ne traitaient pas presque une seule demande en une minute. Voyons pourquoi, ouvrez ATOP 30 secondes avant qu'il ne se bloque. On peut voir qu'avec les problèmes de processeur, on le charge trop. Il y a aussi des problèmes de mémoire, il ne reste que 1,5 Go dans le cache et après 5 secondes, seulement 800 Mo.
On peut voir qu'avec les problèmes de processeur, on le charge trop. Il y a aussi des problèmes de mémoire, il ne reste que 1,5 Go dans le cache et après 5 secondes, seulement 800 Mo. Après encore 5 secondes, le CPU est libéré, rien n'est exécuté. ATOP dit regardez la ligne du bas, nous écrivons sur le disque, mais quoi? Il s'avère que nous écrivons swap.
Après encore 5 secondes, le CPU est libéré, rien n'est exécuté. ATOP dit regardez la ligne du bas, nous écrivons sur le disque, mais quoi? Il s'avère que nous écrivons swap. Qui fait ça? Processus extraits de la mémoire 0,5 Go et mis en swap. À leur place, deux processus Python suspects sont apparus, qui peuvent ensuite être considérés comme une ligne de commande.
Qui fait ça? Processus extraits de la mémoire 0,5 Go et mis en swap. À leur place, deux processus Python suspects sont apparus, qui peuvent ensuite être considérés comme une ligne de commande.
ATOP est magnifique, nous l'utilisons constamment.
Si vous ne l'avez pas, je vous recommande fortement de l'utiliser. N'ayez pas peur pour le lecteur, ATOP ne mange que 200-300 Mo par jour toutes les 5 secondes.Malloc HTTP
Aux Bahamas et aux grands incidents, nous donnons des noms. Il y a un bug amusant lié à ATOP appelé Malloc HTTP. Nous l'avons fait ses débuts avec ATOP et strace.Nous utilisons Thrift partout comme RPC. Dans les premières versions de son analyseur, il y avait un bug incroyable qui fonctionnait comme ceci: un message est arrivé dans lequel les 4 premiers octets sont la taille des données, puis les données elles-mêmes et les premiers octets sont ajoutés au message suivant.Mais une fois que l' un des programmes plutôt que d'aller au service de Thrift, je suis allé à HTTP, et a reçu une réponse «HTTP Bad la demande»: HTTP/1.1 400.Après avoir pris HTTP et alloué en utilisant malloc HTTP le nombre d'octets.Thrift message
HTTP/1.1 400
"HTTP" == 0x48545450
C'est bon, nous avons un sur-engagement, allouons plus de mémoire! Nous avons alloué avec malloc, et jusqu'à ce que nous écrivions et lisions là-bas, ils ne nous donneraient pas de mémoire réelle.Mais ce n'était pas là! Si nous voulons bifurquer, le fork renverra une erreur - il n'y a pas assez de mémoire.malloc("HTTP")
pid = fork(); // errno = ENOMEM
Mais pourquoi, y a-t-il un souvenir? En comprenant les manuels, nous avons constaté que tout est très simple: la configuration actuelle de sur-engagement est telle que c'est une heuristique magique, et le noyau lui-même décide quand beaucoup et quand non:malloc("HTTP")
pid = fork(); // errno = ENOMEM
// 0: heuristic overcommit
vm.overcommit_memory = 0
Pour un processus de travail, c'est normal, vous pouvez sélectionner malloc jusqu'à TB, mais pour un nouveau processus - non. Et une partie de la surveillance chez nous était liée au fait que le processus principal a engendré de petits scripts pour la collecte de données. En conséquence, notre partie de surveillance est tombée en panne, car nous ne pouvions plus bifurquer.FB303
Le FB303 est notre système de surveillance de base. Il a été nommé d'après le synthétiseur de basse standard de 1982. Le principe est simple, il fonctionne donc toujours: chaque service implémente l'interface Thrift getCounters.
Le principe est simple, il fonctionne donc toujours: chaque service implémente l'interface Thrift getCounters.Service FacebookService {
map<string, i64> getCounters()
}
En fait, il ne l'implémente pas, car les bibliothèques sont déjà écrites, tout se fait dans le code incrementou set.incrementCounter(string& key);
setCounter(string& key, int64_t value);
Par conséquent, chaque service exporte des compteurs sur le port qu'il enregistre auprès de Service Discovery. Voici un exemple d'une machine qui génère un fil d'actualités et exporte environ 5,5 mille paires (chaîne, nombre): mémoire, production, n'importe quoi. Chaque machine exécute un processus binaire qui passe par tous les services autour, recueille ces compteurs et les met en stockage.Voici à quoi ressemble l' interface graphique de stockage .
Chaque machine exécute un processus binaire qui passe par tous les services autour, recueille ces compteurs et les met en stockage.Voici à quoi ressemble l' interface graphique de stockage . Très similaire à Prométhée et Grafana, mais ce n'est pas le cas. La première entrée du FB303 sur GitHub a eu lieu en 2009, et Prometheus en 2012. C'est une explication de tous les «bricoleurs» de Facebook: nous les avons fait quand il n'y avait rien de normal en Open Source.Par exemple, il y a une recherche des noms des compteurs.
Très similaire à Prométhée et Grafana, mais ce n'est pas le cas. La première entrée du FB303 sur GitHub a eu lieu en 2009, et Prometheus en 2012. C'est une explication de tous les «bricoleurs» de Facebook: nous les avons fait quand il n'y avait rien de normal en Open Source.Par exemple, il y a une recherche des noms des compteurs. Les graphiques eux-mêmes ressemblent à ceci.
Les graphiques eux-mêmes ressemblent à ceci. Une photo du groupe intérieur dans laquelle nous affichons de beaux graphismes.Une différence importante entre notre pile de surveillance et Prometheus et Grafana est que nous stockons les données pour toujours . Notre surveillance va rééchantillonner les données, et après 2 semaines, nous aurons un point pour toutes les 5 minutes, et après un an pour chaque heure. Par conséquent, ils peuvent être stockés tellement. Automatiquement, cela n'est configuré nulle part.Mais si nous parlons des caractéristiques de la surveillance de Facebook, je le décrirais avec un mot anglais « observabilité» .
Une photo du groupe intérieur dans laquelle nous affichons de beaux graphismes.Une différence importante entre notre pile de surveillance et Prometheus et Grafana est que nous stockons les données pour toujours . Notre surveillance va rééchantillonner les données, et après 2 semaines, nous aurons un point pour toutes les 5 minutes, et après un an pour chaque heure. Par conséquent, ils peuvent être stockés tellement. Automatiquement, cela n'est configuré nulle part.Mais si nous parlons des caractéristiques de la surveillance de Facebook, je le décrirais avec un mot anglais « observabilité» .Observabilité
Il y a une "boîte noire", il y a une "boîte blanche", et nous avons une "boîte" en verre transparent. Cela signifie que lorsque nous écrivons du code, nous écrivons tout ce qui est possible dans les journaux, et non de manière sélective. L'échantillonnage est bien réglé partout, donc le backend pour le stockage, les compteurs et tout le reste fonctionne bien.Dans le même temps, nous pouvons déjà construire nos tableaux de bord sur des compteurs existants. Dans le cas de l'étude de ces tableaux de bord, ce n'est pas le point final avec 10 graphiques, mais le premier, à partir duquel nous allons à notre interface utilisateur et y trouvons tout ce qui est possible.Scaphandre autonome
C'est le point culminant de l'idée d'observabilité. Ceci est notre pile ELK. Le principe est le même: nous écrivons en JSON sans schéma spécifique, puis nous demandons sous la forme d'un tableau , d'une série chronologique de données ou de 10 options de visualisation supplémentaires.Scuba se connecte de l'ordre de centaines de gigaoctets par seconde. Tout est demandé très rapidement, car ce n'est pas Elasticsearch, et tout est en mémoire sur des machines puissantes. Oui, de l'argent y est dépensé, mais comme c'est merveilleux!Par exemple, sous Scuba UI, une des tables les plus populaires y est ouverte, dans laquelle tous les clients de tous les services Thrift écrivent des journaux.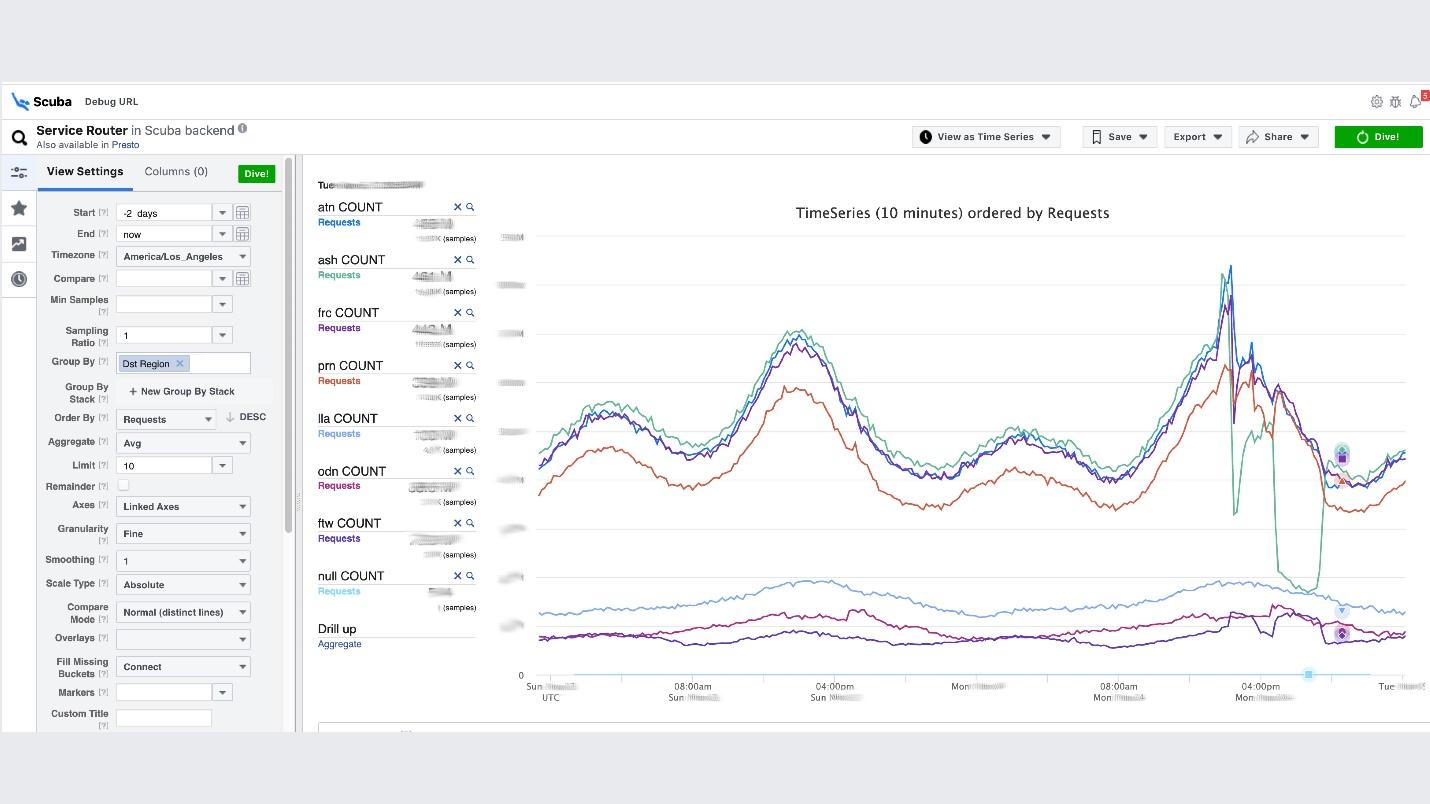 Le graphique montre qu'en fin de compte, quelque chose s'est mal passé dans le service. Pour connaître le délai, accédez à la liste des compteurs, sélectionnez le délai, l'agrégation, cliquez sur "Plongée".
Le graphique montre qu'en fin de compte, quelque chose s'est mal passé dans le service. Pour connaître le délai, accédez à la liste des compteurs, sélectionnez le délai, l'agrégation, cliquez sur "Plongée".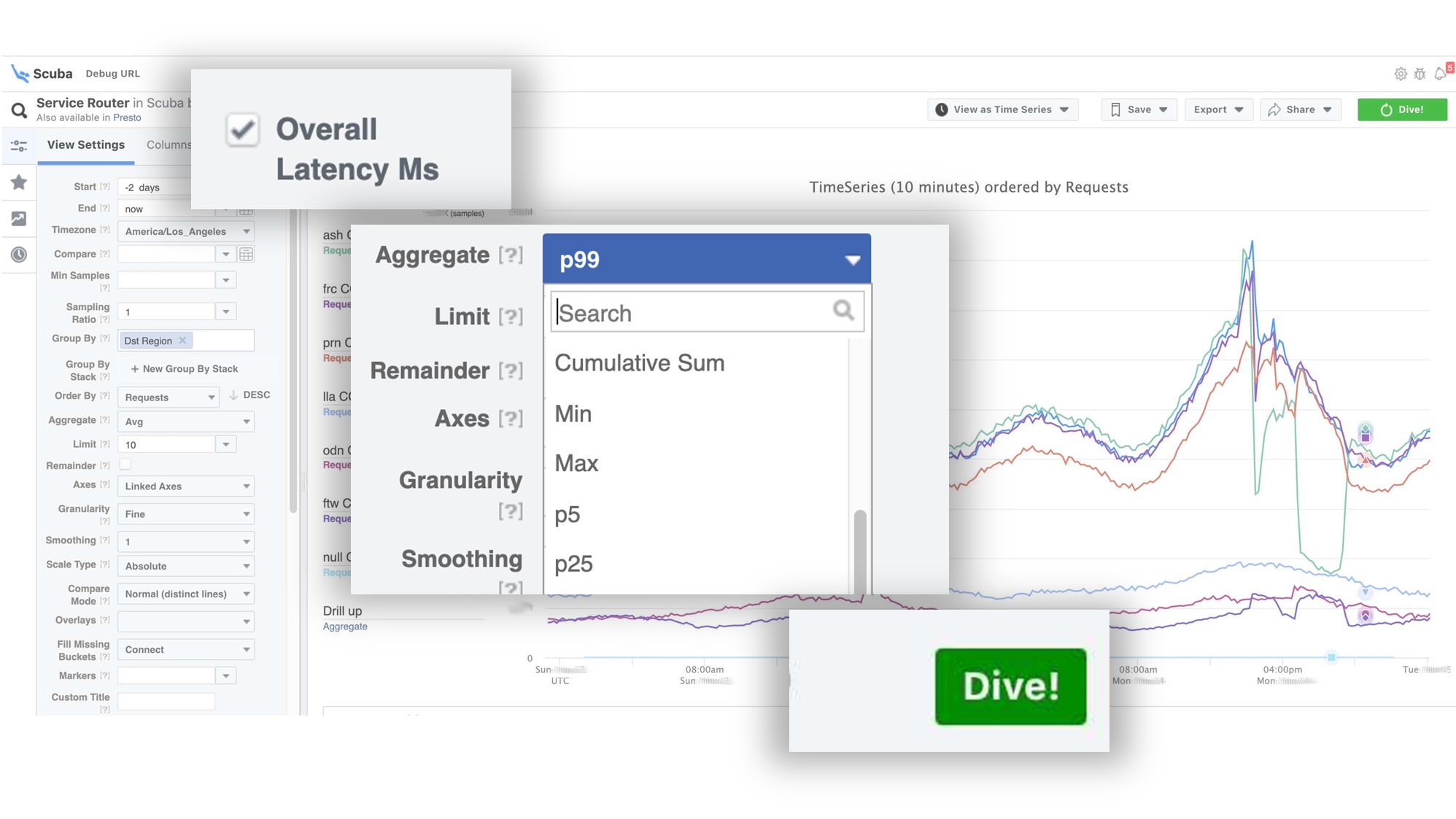 La réponse vient en 2 secondes.
La réponse vient en 2 secondes.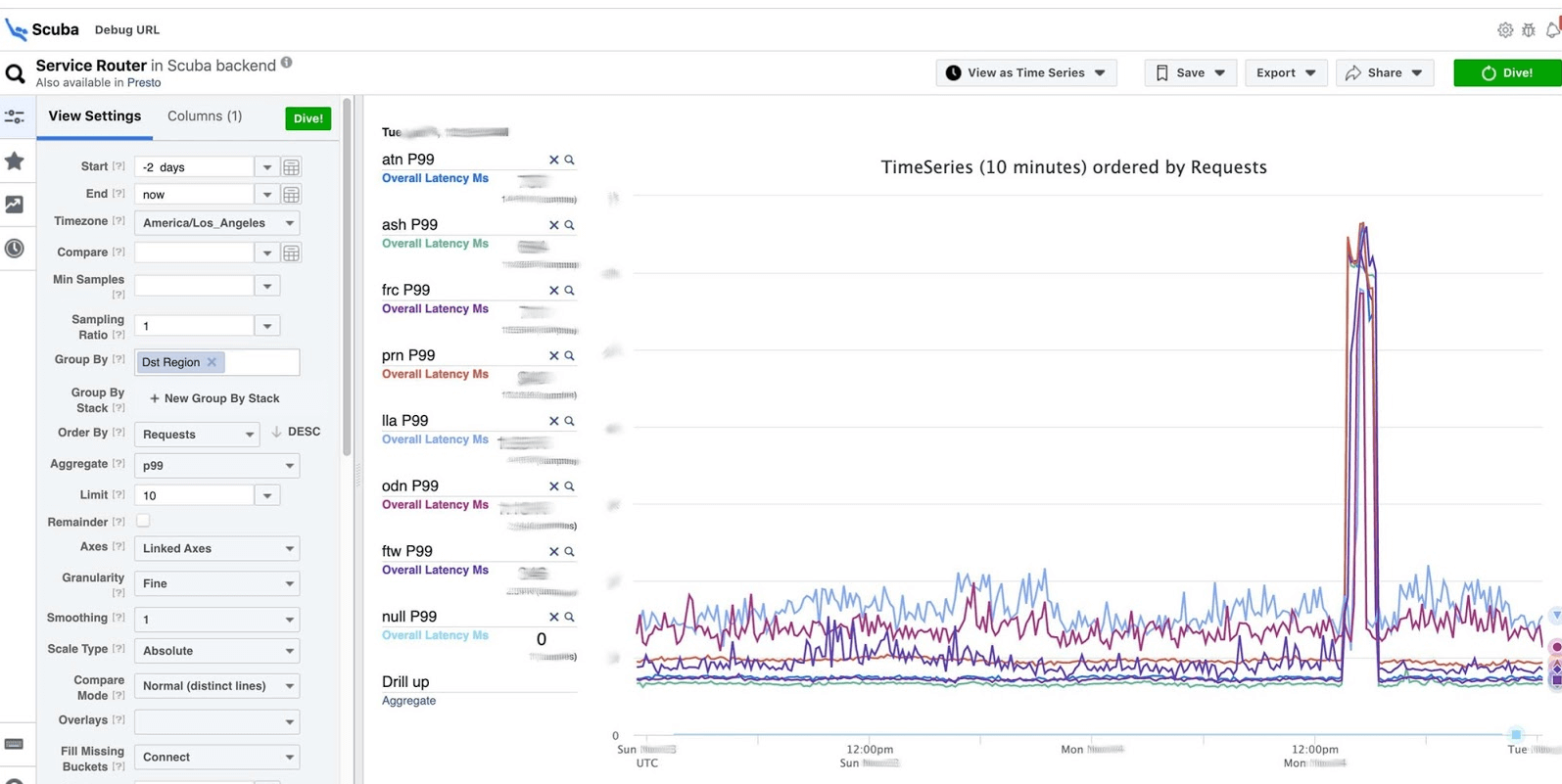 On peut voir qu'à ce moment quelque chose s'est produit et que le retard a augmenté de manière significative. Pour en savoir plus, vous pouvez regrouper selon différents paramètres.Il existe des centaines de ces tableaux.
On peut voir qu'à ce moment quelque chose s'est produit et que le retard a augmenté de manière significative. Pour en savoir plus, vous pouvez regrouper selon différents paramètres.Il existe des centaines de ces tableaux.- Un tableau qui montre les versions des fichiers binaires, des packages, la quantité de mémoire consommée sur des millions de machines. Sur chaque hôte, un PS est effectué une fois par heure et envoyé à Scuba.
- Tous les dmesg, tous les vidages de mémoire, sont envoyés à d'autres tables. Nous exécutons Perf toutes les 10 minutes sur chaque machine, nous savons donc quelles traces de pile nous avons sur le noyau et ce que le processeur global peut charger.
Débogage PHP
Scuba fournit également un backend pour notre outil de débogage PHP de base. Des milliers d'ingénieurs écrivent du code PHP et, d'une manière ou d'une autre, vous devez enregistrer le référentiel global des mauvaises choses.Comment ça marche? PHP écrit également une trace de pile dans chaque journal. Scuba (notre Elasticsearch) ne peut tout simplement pas prendre en charge la trace de pile de tous les journaux de toutes les machines. Avant de mettre le journal dans Scuba, nous convertissons la trace de la pile en hachage, échantillonnons par hachage et n'enregistrons que ceux-ci. Les traces de pile elles-mêmes sont envoyées à Memcached. Ensuite, dans l'outil interne, vous pouvez extraire une trace de pile spécifique de Memcached assez rapidement. Visualisation avec regroupement de hachage à partir des journaux et des traces de pile.Nous déboguons le code en utilisant la méthode de filtrage : ouvrez Scuba, voyez à quoi ressemble le graphique d'erreur.
Visualisation avec regroupement de hachage à partir des journaux et des traces de pile.Nous déboguons le code en utilisant la méthode de filtrage : ouvrez Scuba, voyez à quoi ressemble le graphique d'erreur.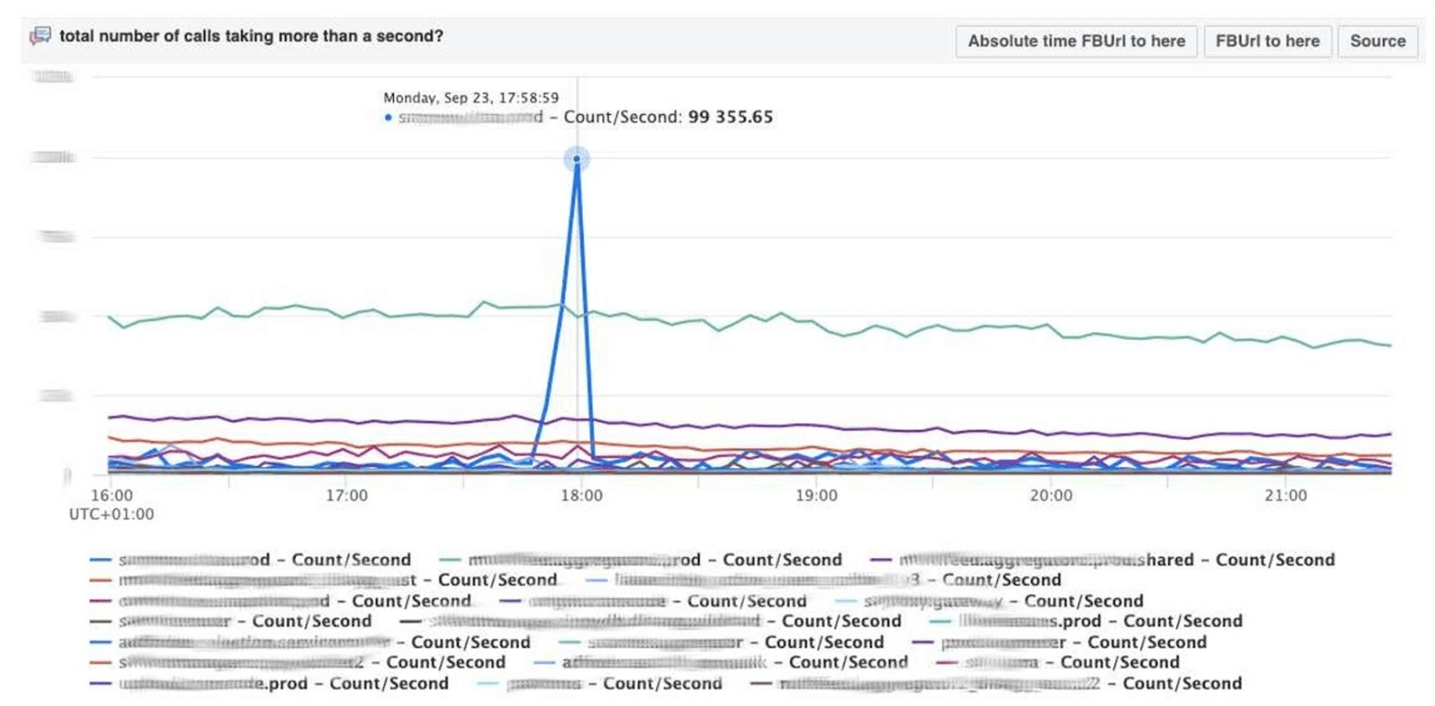 On passe à LogView, là les erreurs sont déjà regroupées par traces de pile.
On passe à LogView, là les erreurs sont déjà regroupées par traces de pile. Une trace de pile est chargée à partir de Memcached, et déjà sur celle-ci, vous pouvez trouver diff (commit dans le référentiel PHP), qui a été publié à peu près au même moment, et la restaurer. Tout le monde peut revenir en arrière et s'engager avec nous, aucune autorisation n'est nécessaire pour cela.
Une trace de pile est chargée à partir de Memcached, et déjà sur celle-ci, vous pouvez trouver diff (commit dans le référentiel PHP), qui a été publié à peu près au même moment, et la restaurer. Tout le monde peut revenir en arrière et s'engager avec nous, aucune autorisation n'est nécessaire pour cela.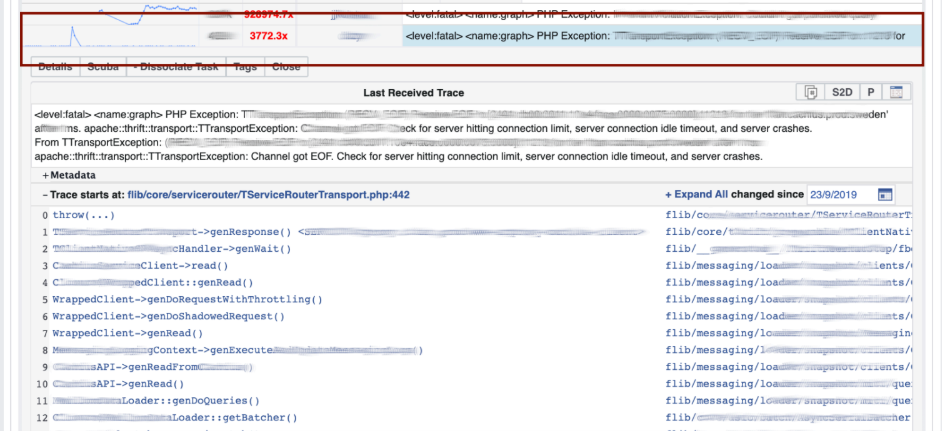
Tableaux de bord
Je terminerai le sujet de surveillance avec des tableaux de bord. Nous en avons peu - seulement deux pour trois indicateurs. Le tableau de bord lui-même est plutôt inhabituel. J'aimerais parler davantage de lui. Voici un tableau de bord standard avec un ensemble de graphiques.Malheureusement, ce n'est pas si simple avec lui. Le fait est que la ligne violette sur un graphique est le même service auquel la ligne bleue correspond sur l'autre graphique, et un autre graphique peut être en un jour et un autre en un mois.Nous utilisons notre tableau de bord basé sur Cubism - la bibliothèque Open Source JS. Il a été écrit sur Square et publié sous la licence Apache. Ils ont un support intégré pour Graphite et Cube. Mais il est facile à étendre, ce que nous avons fait.Le tableau de bord ci-dessous montre un jour à un pixel par minute. Chaque ligne est une région: des centres de données à proximité. Ils affichent le nombre de journaux que le backend Facebook écrit en octets par seconde. Ci-dessous sont des annotations pour les équipes en Amérique pour voir ce que nous avons déjà corrigé de ce qui s'est passé pendant la journée. Il est facile de rechercher une corrélation sur cette image.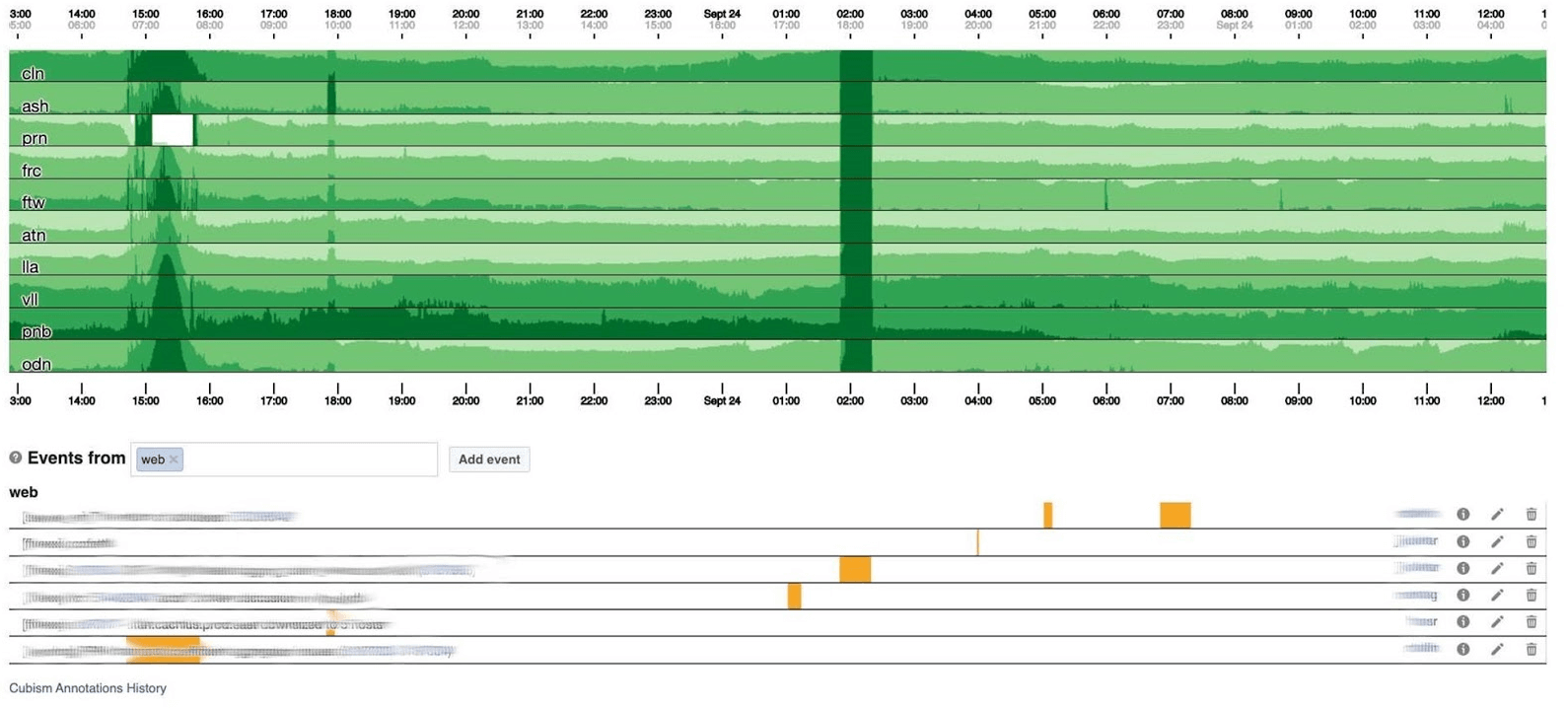 Ci-dessous, le nombre d'erreurs 500. Ce qui à gauche n'a pas d'importance pour les utilisateurs, et évidemment ils n'aimaient pas la bande vert foncé au centre.
Ci-dessous, le nombre d'erreurs 500. Ce qui à gauche n'a pas d'importance pour les utilisateurs, et évidemment ils n'aimaient pas la bande vert foncé au centre.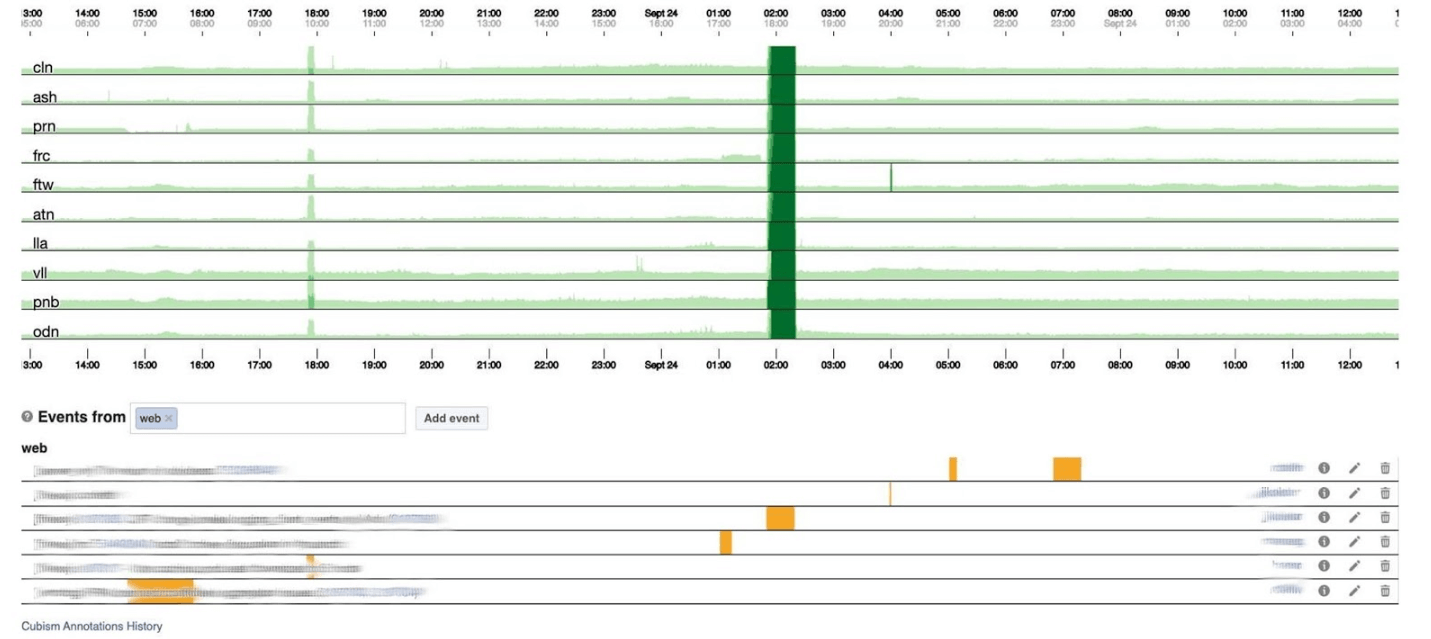 Vient ensuite la latence du 99e centile. En même temps, comme dans le graphique ci-dessus, on peut voir que la latence a baissé. Pour retourner une erreur, il n'est pas nécessaire de passer beaucoup de temps.
Vient ensuite la latence du 99e centile. En même temps, comme dans le graphique ci-dessus, on peut voir que la latence a baissé. Pour retourner une erreur, il n'est pas nécessaire de passer beaucoup de temps.
Comment ça fonctionne
Sur un graphique de 120 pixels de haut, tout est visible. Mais beaucoup d'entre eux ne peuvent pas être placés sur un seul tableau de bord, nous allons donc passer à 30. Malheureusement, nous obtenons alors une sorte de boa constrictor. Revenons en arrière et voyons ce que le cubisme en fait. Il casse le graphique en 4 parties: le plus haut, le plus sombre, puis s'effondre.
donc passer à 30. Malheureusement, nous obtenons alors une sorte de boa constrictor. Revenons en arrière et voyons ce que le cubisme en fait. Il casse le graphique en 4 parties: le plus haut, le plus sombre, puis s'effondre. Nous avons maintenant le même calendrier qu'auparavant, mais tout est clairement visible: plus le vert est sombre, pire c'est. Maintenant, ce qui se passe est beaucoup plus clair.Sur la gauche, vous pouvez voir la vague au fur et à mesure qu'elle montait, et au centre, où elle est vert foncé, tout est très mauvais.
Nous avons maintenant le même calendrier qu'auparavant, mais tout est clairement visible: plus le vert est sombre, pire c'est. Maintenant, ce qui se passe est beaucoup plus clair.Sur la gauche, vous pouvez voir la vague au fur et à mesure qu'elle montait, et au centre, où elle est vert foncé, tout est très mauvais.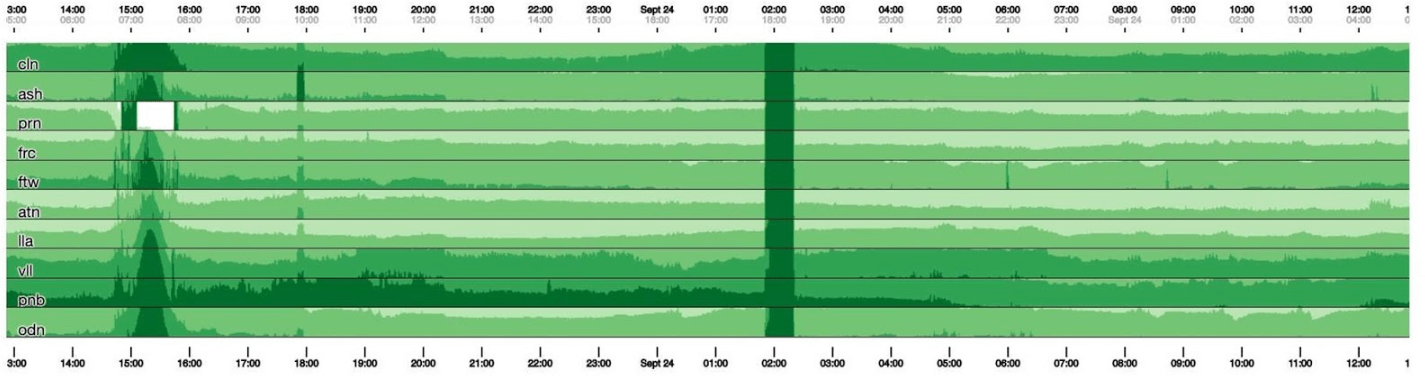 Le cubisme n'est qu'un début. Il est nécessaire pour la visualisation, afin de comprendre si tout va bien maintenant ou non. Pour chaque tableau, il existe déjà des tableaux de bord avec des graphiques détaillés.
Le cubisme n'est qu'un début. Il est nécessaire pour la visualisation, afin de comprendre si tout va bien maintenant ou non. Pour chaque tableau, il existe déjà des tableaux de bord avec des graphiques détaillés. La surveillance en elle-même aide à comprendre l'état du système et à réagir en cas de panne. Sur Facebook, chaque employé oncall doit pouvoir tout réparer. S'il brûle, alors tout s'allume, mais surtout les ingénieurs de production avec l'expérience d'un administrateur système, car ils savent comment résoudre le problème rapidement.
La surveillance en elle-même aide à comprendre l'état du système et à réagir en cas de panne. Sur Facebook, chaque employé oncall doit pouvoir tout réparer. S'il brûle, alors tout s'allume, mais surtout les ingénieurs de production avec l'expérience d'un administrateur système, car ils savent comment résoudre le problème rapidement.Quand Facebook était couché
Parfois, des incidents se produisent et Facebook ment. Habituellement, les gens pensent que Facebook ment en raison des attaques DDoS ou des pirates informatiques, mais en 5 ans, cela ne s'est jamais produit. La raison a toujours été nos ingénieurs. Ils ne sont pas intentionnels: les systèmes sont très complexes et peuvent tomber en panne là où vous n'attendez pas.Nous donnons des noms à tous les incidents majeurs afin qu'il soit commode de les mentionner et d'en parler aux nouveaux venus afin de ne pas répéter les erreurs à l'avenir. Le champion du nom le plus drôle est l'incident Call the Cops . Les gens ont appelé la police de Los Angeles et ont demandé de réparer Facebook parce qu'il mentait. Le shérif de Los Angeles en avait tellement marre qu'il a tweeté: "S'il vous plaît, ne nous appelez pas!" Nous n'en sommes pas responsables! » Mon incident préféré auquel j'ai participé s'appelait CAPSLOCK.. Il est intéressant en ce qu'il montre que tout peut arriver. Et c'est ce qui est arrivé. Elle adresse obychnyyIP:
Mon incident préféré auquel j'ai participé s'appelait CAPSLOCK.. Il est intéressant en ce qu'il montre que tout peut arriver. Et c'est ce qui est arrivé. Elle adresse obychnyyIP: fd3b:5679:92eb:9ce4::1.Facebook utilise Chef pour personnaliser le système d'exploitation. L'inventaire des services stocke la configuration de l'hôte dans sa base de données et Chef reçoit un fichier de configuration du service. Une fois que le service a changé de version, il a commencé à lire les adresses IP de la base de données immédiatement au format MySQL et à les mettre dans un fichier. La nouvelle adresse est maintenant écrit dans le capital: FD3B:5679:92EB:9CE4::1.Shef regarde le nouveau fichier et constate que l'adresse IP a «changé» car elle compare, non pas sous forme binaire, mais avec une chaîne. L'adresse IP est «nouvelle», ce qui signifie que vous devez abaisser l'interface et la relever. Sur tous les millions de voitures en 15 minutes, l'interface est montée et descendue.Il semblerait que ce soit correct - la capacité a diminué alors que le réseau reposait sur certaines machines. Mais un bug s'est soudainement ouvert dans le pilote réseau de nos cartes réseau personnalisées: au démarrage, elles nécessitaient 0,5 Go de mémoire physique séquentielle. Sur les machines de cache, ces 0,5 Go ont disparu pendant que nous baissions et augmentions l'interface. Par conséquent, sur les machines de cache, l'interface réseau est tombée en panne et n'a pas augmenté, et rien ne fonctionne sans caches. Nous nous sommes assis et avons redémarré ces machines avec nos mains. C'était amusant.Portail du gestionnaire d'incidents
Lorsque Facebook «brûle», il est nécessaire d'organiser le travail des «pompiers» et, surtout, de comprendre où il brûle, car dans une grande entreprise, il peut «sentir l'odeur de brûlé» à un endroit, mais le problème sera à un autre. L'outil d'interface utilisateur appelé Incident Manager Portal nous y aide . Il a été écrit par des ingénieurs de production et est ouvert à tous. Dès qu'il se passe quelque chose, on y déclenche un incident: nom, début, description.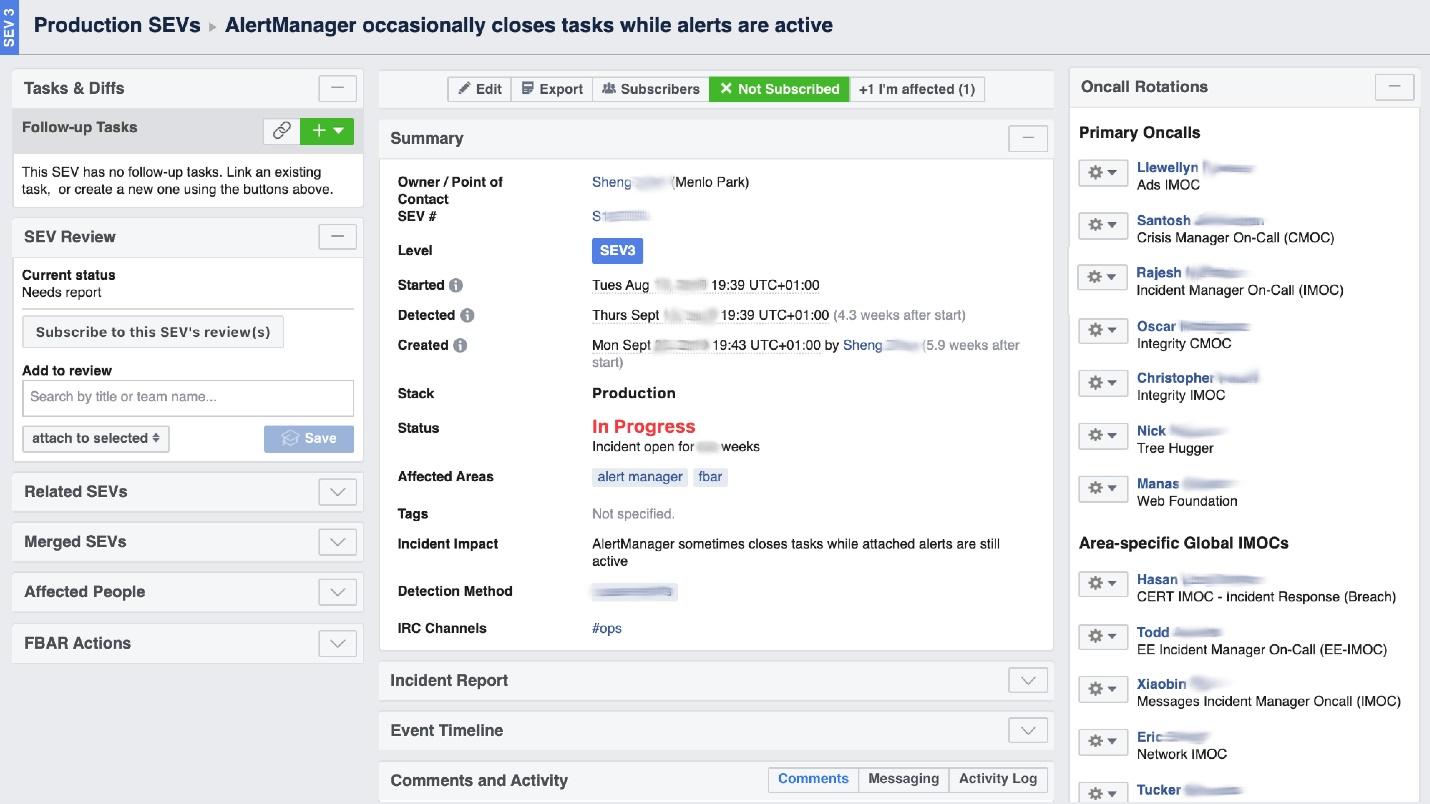 Nous avons une personne spécialement formée - Incident Manager On-Call (IMOC). Ce n'est pas un poste permanent, les managers changent régulièrement. En cas de grands incendies, IMOC organise et coordonne les personnes à réparer, mais n'a pas à les réparer elles-mêmes. Dès qu'un incident avec un haut niveau de danger est créé, IMOC reçoit un SMS et commence à aider à tout organiser. Dans un grand système, ces personnes ne peuvent être dispensées.
Nous avons une personne spécialement formée - Incident Manager On-Call (IMOC). Ce n'est pas un poste permanent, les managers changent régulièrement. En cas de grands incendies, IMOC organise et coordonne les personnes à réparer, mais n'a pas à les réparer elles-mêmes. Dès qu'un incident avec un haut niveau de danger est créé, IMOC reçoit un SMS et commence à aider à tout organiser. Dans un grand système, ces personnes ne peuvent être dispensées.La prévention
Facebook n'est pas si courant. La plupart du temps, nous n'éteignons pas et ne redémarrons pas les machines de cache, mais nous corrigeons les bogues à l'avance et, si possible, pour tout le monde à la fois.Une fois que nous avons trouvé et corrigé le «problème de file d'attente». Le nombre de demandes augmente de 50%, et les erreurs de 100%, car personne ne limite la mise en œuvre à l'avance, surtout dans les petits services.Nous avons trouvé un exemple de plusieurs services et défini grossièrement un modèle de comportement.- Sous charge normale, la demande arrive, est traitée et renvoyée au client.
- Avec une charge élevée, les demandes sont en attente dans une file d'attente car tous les threads de traitement des demandes sont occupés. Le retard augmente, mais jusqu'à présent tout va bien.
- La ligne grandit, la charge augmente. À un certain point, tout ce que le serveur exécute sur le client se termine par un délai de réponse et le client tombe avec une erreur. À ce stade, le résultat du serveur peut simplement être jeté.
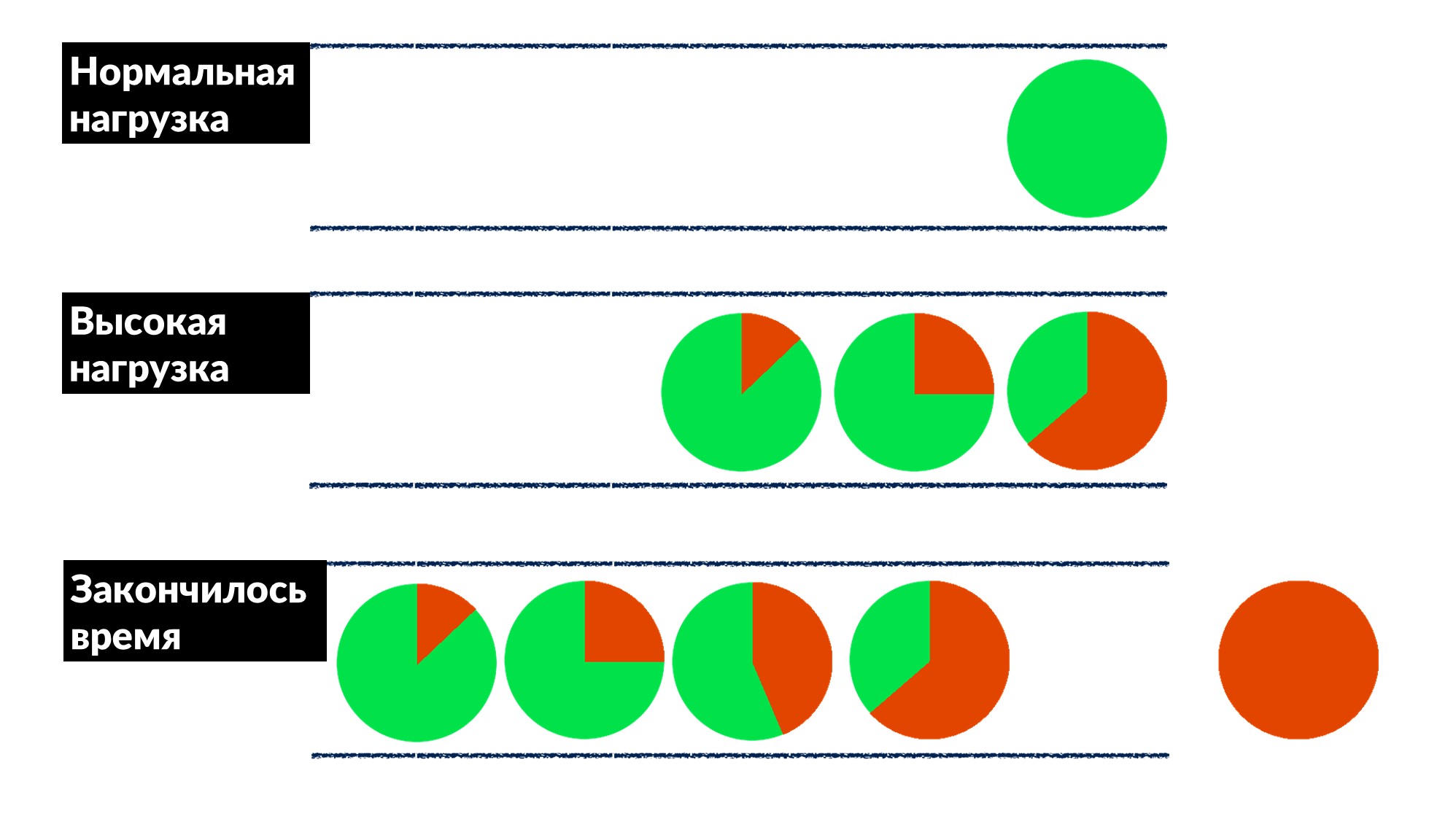 Le délai d'expiration du client est surligné en rouge.Et le client répète encore! Il s'avère que toutes les demandes que nous exécutons sont jetées à la poubelle et que personne n'en a plus besoin.Comment résoudre ce problème pour tout le monde à la fois? Introduisez une limite de délai d'attente de file d'attente. Si la demande est dans la file d'attente plus que prévu, nous la jetons et ne la traitons pas sur le serveur, nous ne gaspillons pas le processeur dessus. Nous obtenons un jeu honnête: nous jetons tout ce que nous ne pouvons pas traiter et tout ce que nous pouvons traiter.La restriction a permis, tout en augmentant la charge de 50% au-dessus du maximum, de traiter encore 66% des demandes et de ne recevoir que 33% des erreurs. Les développeurs du framework pour Dispatch l'ont implémenté côté serveur, et nous, les ingénieurs de production, avons doucement réglé le délai d'expiration de 100 ms dans la file d'attente pour tout le monde. Ainsi, tous les services ont immédiatement obtenu une limitation de base bon marché.
Le délai d'expiration du client est surligné en rouge.Et le client répète encore! Il s'avère que toutes les demandes que nous exécutons sont jetées à la poubelle et que personne n'en a plus besoin.Comment résoudre ce problème pour tout le monde à la fois? Introduisez une limite de délai d'attente de file d'attente. Si la demande est dans la file d'attente plus que prévu, nous la jetons et ne la traitons pas sur le serveur, nous ne gaspillons pas le processeur dessus. Nous obtenons un jeu honnête: nous jetons tout ce que nous ne pouvons pas traiter et tout ce que nous pouvons traiter.La restriction a permis, tout en augmentant la charge de 50% au-dessus du maximum, de traiter encore 66% des demandes et de ne recevoir que 33% des erreurs. Les développeurs du framework pour Dispatch l'ont implémenté côté serveur, et nous, les ingénieurs de production, avons doucement réglé le délai d'expiration de 100 ms dans la file d'attente pour tout le monde. Ainsi, tous les services ont immédiatement obtenu une limitation de base bon marché.Outils
L'idéologie de SRE dit que si vous avez une grande flotte de voitures, un tas de services et rien à voir avec vos mains, alors vous devez automatiser. Par conséquent, la moitié du temps, nous écrivons du code et créons des outils.- Cubisme intégré dans le système.
- Le FBAR est un «bourreau de travail» qui vient réparer, donc personne ne s'inquiète d'une voiture cassée. C'est la tâche principale du FBAR, mais maintenant il a encore plus de tâches.
- Coredumper , que nous avons écrit avec deux collègues . Il surveille les coredumps sur toutes les machines et les dépose au même endroit avec les traces de pile avec toutes les informations sur l'hôte: où il se trouve, comment trouver quelle taille. Mais surtout, les traces de pile sont gratuites, sans démarrer GDB à l'aide des programmes BPF.
Les sondages
La dernière chose que nous faisons est de parler aux gens, de les interviewer. Il nous semble que c'est très important.Un sondage utile concerne la fiabilité. Nous posons des questions sur les services déjà en cours d'exécution dans les citations clés de notre questionnaire:"La principale responsabilité du logiciel système doit être de continuer à fonctionner. La prestation de services doit être considérée comme un effet secondaire bénéfique d'une exploitation continue »
Cela signifie que le principal devoir du système est de continuer à fonctionner, et le fait qu'il fournit une sorte de service est un bonus supplémentaire.Les enquêtes ne concernent que les services moyens, les grands eux-mêmes le comprennent. Nous donnons un questionnaire dans lequel nous posons des questions de base sur l'architecture, SLO, les tests, par exemple.- "Que se passe-t-il si votre système reçoit 10% de la charge?" Quand les gens pensent: "Mais vraiment, quoi?" - des idées apparaissent et beaucoup gouvernent même leurs systèmes. Auparavant, ils n'y pensaient pas, mais après la question, il y a une raison.
- "Qui est le premier à remarquer généralement des problèmes avec votre service - vous ou vos utilisateurs?" Les développeurs commencent à se rappeler quand cela s'est produit et: "... Vous devez peut-être ajouter des alertes."
- "Quelle est votre plus grande douleur d'appel?" Ceci est inhabituel pour les développeurs, en particulier pour les nouveaux. Ils disent immédiatement: «Nous avons de nombreuses alertes! Nettoyons-les et enlevons ceux qui ne sont pas le cas. »
- "Quelle est la fréquence de vos sorties?" D'abord, ils se souviennent qu'ils le libèrent avec leurs mains, puis ils ont leur propre déploiement personnalisé.
Il n'y a pas de codage dans le questionnaire, il est standardisé et change tous les six mois. Il s'agit d'un document de deux pages que nous aidons à remplir en 2-3 semaines. Et puis nous organisons un rallye de deux heures et trouvons des solutions à de nombreuses douleurs. Cet outil simple fonctionne bien avec nous et peut vous aider.6-7 Saint HighLoad++, . (, , ).
telegram- . !