En prévision du début du cours Data Engineer, nous avons préparé la traduction d'un petit mais intéressant matériel.
Dans cet article, je vais parler de la façon dont Parquet compresse de grands ensembles de données dans un fichier à faible encombrement et comment nous pouvons atteindre une bande passante dépassant de loin la bande passante du flux d'E / S à l'aide de la concurrence (multithreading).Apache Parquet: meilleur en matière de données à faible entropie
Comme vous pouvez le comprendre à partir des spécifications du format Apache Parquet, il contient plusieurs niveaux de codage qui peuvent permettre une réduction significative de la taille du fichier, parmi lesquels:- Encodage (compression) à l'aide d'un dictionnaire (similaire aux pandas.Mode stratégique de présentation des données, mais les concepts eux-mêmes sont différents);
- Compression des pages de données (Snappy, Gzip, LZO ou Brotli);
- Encodage de la longueur d'exécution (pour les pointeurs nuls et les index du dictionnaire) et compression des bits entiers;
Pour vous montrer comment cela fonctionne, regardons un ensemble de données:['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']
Presque toutes les implémentations de Parquet utilisent le dictionnaire par défaut pour la compression. Ainsi, les données codées sont les suivantes:dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
Les index du dictionnaire sont en outre compressés par l'algorithme de codage à répétition:dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]
En suivant le chemin de retour, vous pouvez facilement restaurer le tableau d'origine de chaînes.Dans mon article précédent , j'ai créé un ensemble de données qui se comprime très bien de cette façon. Lorsque vous travaillez avec pyarrow, nous pouvons activer et désactiver l'encodage à l'aide du dictionnaire (qui est activé par défaut) pour voir comment cela affectera la taille du fichier:import pyarrow.parquet as pq
pq.write_table(dataset, out_path, use_dictionary=True,
compression='snappy)
Un ensemble de données qui prend 1 Go (1024 Mo) pandas.DataFrame, avec la compression Snappy et la compression à l'aide d'un dictionnaire, ne prend que 1,436 Mo, c'est-à-dire qu'il peut même être écrit sur une disquette. Sans compression à l'aide du dictionnaire, il occupera 44,4 Mo.Lecture simultanée en parquet-cpp avec PyArrow
Dans l'implémentation d'Apache Parquet en C ++ - parquet-cpp , que nous avons rendu disponible pour Python dans PyArrow, la possibilité de lire des colonnes en parallèle a été ajoutée.Pour essayer cette fonctionnalité, installez PyArrow à partir de conda-forge :conda install pyarrow -c conda-forge
Maintenant, lors de la lecture du fichier Parquet, vous pouvez utiliser l'argument nthreads:import pyarrow.parquet as pq
table = pq.read_table(file_path, nthreads=4)
Pour les données à faible entropie, la décompression et le décodage sont fortement liés au processeur. Puisque C ++ fait tout le travail pour nous, il n'y a aucun problème avec la concurrence GIL et nous pouvons atteindre une augmentation significative de la vitesse. Découvrez ce que j'ai pu réaliser en lisant un ensemble de données de 1 Go dans un DataFrame pandas sur un ordinateur portable quadricœur (Xeon E3-1505M, SSD NVMe):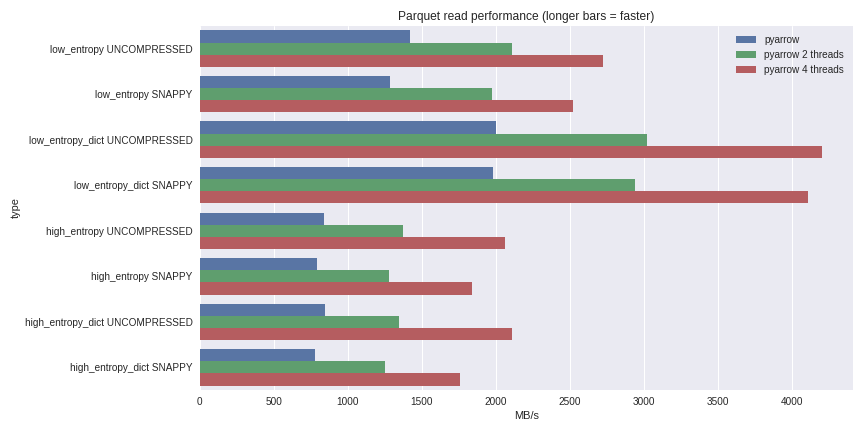 vous pouvez voir le scénario complet d'analyse comparative ici .J'ai inclus les performances ici pour les cas de compression utilisant un dictionnaire et les cas sans utiliser de dictionnaire. Pour les données à faible entropie, malgré le fait que tous les fichiers soient petits (~ 1,5 Mo à l'aide de dictionnaires et ~ 45 Mo sans), la compression à l'aide d'un dictionnaire affecte considérablement les performances. Avec 4 threads, les performances de lecture des pandas augmentent à 4 Go / s. C'est beaucoup plus rapide que le format Feather ou tout autre que je connaisse.
vous pouvez voir le scénario complet d'analyse comparative ici .J'ai inclus les performances ici pour les cas de compression utilisant un dictionnaire et les cas sans utiliser de dictionnaire. Pour les données à faible entropie, malgré le fait que tous les fichiers soient petits (~ 1,5 Mo à l'aide de dictionnaires et ~ 45 Mo sans), la compression à l'aide d'un dictionnaire affecte considérablement les performances. Avec 4 threads, les performances de lecture des pandas augmentent à 4 Go / s. C'est beaucoup plus rapide que le format Feather ou tout autre que je connaisse.Conclusion
Avec la sortie de la version 1.0 parquet-cpp (Apache Parquet en C ++), vous pouvez constater par vous-même les performances d'E / S accrues qui sont désormais disponibles pour les utilisateurs de Python.Étant donné que tous les mécanismes de base sont implémentés en C ++, dans d'autres langages (par exemple, R), vous pouvez créer des interfaces pour Apache Arrow (structures de données en colonnes) et parquet-cpp . La liaison Python est un shell léger des bibliothèques C ++ libarrow et libparquet de base .C'est tout. Si vous souhaitez en savoir plus sur notre cours, inscrivez-vous pour une journée portes ouvertes , qui aura lieu aujourd'hui!