Bonjour, je travaille dans l'équipe projet du RRP KP (registre de données distribué pour le suivi du cycle de vie des essieux montés). Ici, je veux partager l'expérience de notre équipe dans le développement d'une blockchain d'entreprise pour ce projet dans les conditions imposées par la technologie. Pour la plupart, je parlerai de Hyperledger Fabric, mais l'approche décrite ici peut être extrapolée à n'importe quelle blockchain autorisée. Le but ultime de notre recherche est de préparer des solutions de blockchain pour que le produit final soit agréable à utiliser et pas trop difficile à entretenir.Il n'y aura pas de découvertes, de solutions inattendues et aucun développement unique ne sera abordé ici (car je ne les ai pas). Je veux juste partager ma modeste expérience, montrer que «c'était possible» et, peut-être, lire les expériences des autres en prenant de bonnes et moins bonnes décisions dans les commentaires.Problème: les chaînes de blocs ne sont pas encore mises à l'échelle
Aujourd'hui, les efforts de nombreux développeurs visent à faire de la blockchain une technologie vraiment pratique, et non une bombe à retardement dans un bel emballage. Les canaux d'état, le cumul optimiste, le plasma et le sharding peuvent devenir quotidiens. Un jour. Ou peut-être que TON retardera à nouveau le lancement de six mois et que le prochain groupe Plasma cessera d'exister. Nous pouvons croire en une autre feuille de route et lire des livres blancs brillants pour la nuit, mais ici et maintenant, nous devons faire quelque chose avec ce que nous avons. Faites la merde.La tâche assignée à notre équipe dans le projet actuel ressemble à ceci en général: il existe de nombreuses entités atteignant plusieurs milliers, ne souhaitant pas établir de relations de confiance; il est nécessaire de construire une telle solution sur DLT qui fonctionnera sur des PC ordinaires sans exigences de performances spéciales et fournira une expérience utilisateur pas pire que n'importe quel système comptable centralisé. La technologie sous-jacente à la solution devrait minimiser la possibilité de manipulation malveillante des données - c'est pourquoi la blockchain est là.Les slogans des livres blancs et des médias nous promettent que le prochain développement vous permettra d'effectuer des millions de transactions par seconde. Qu'est-ce que c'est vraiment?Mainnet Ethereum fonctionne maintenant à ~ 30 tps. Déjà à cause de cela, il est difficile de le percevoir comme une blockchain adaptée aux besoins des entreprises. Parmi les solutions autorisées, les benchmarks sont connus, montrant 2000 tps ( Quorum ) ou 3000 tps ( Hyperledger Fabric , la publication est légèrement plus petite, mais vous devez considérer que le benchmark a été effectué sur l'ancien moteur de consensus). Il y a eu une tentative de révision radicale de Fabric , qui n'a pas donné les pires résultats, 20 000 tps, mais jusqu'à présent, il ne s'agit que de recherches universitaires en attente de sa mise en œuvre stable. Il est peu probable qu'une entreprise qui peut se permettre de maintenir un département de développeurs de blockchain accepte ces indicateurs. Mais le problème n'est pas seulement le débit, il y a encore de la latence.Latence
Le délai entre le moment où la transaction est initiée et son approbation finale par le système dépend non seulement de la vitesse du message passant par toutes les étapes de validation et de commande, mais également des paramètres de formation du bloc. Même si notre blockchain nous permet de nous engager à une vitesse de 1 000 000 tps, mais qu'il faut 10 minutes pour former un bloc de 488 Mo, cela deviendra-t-il plus facile pour nous?Examinons de plus près le cycle de vie des transactions dans Hyperledger Fabric pour comprendre sur quoi le temps est passé et comment il est lié aux paramètres de la formation de blocs.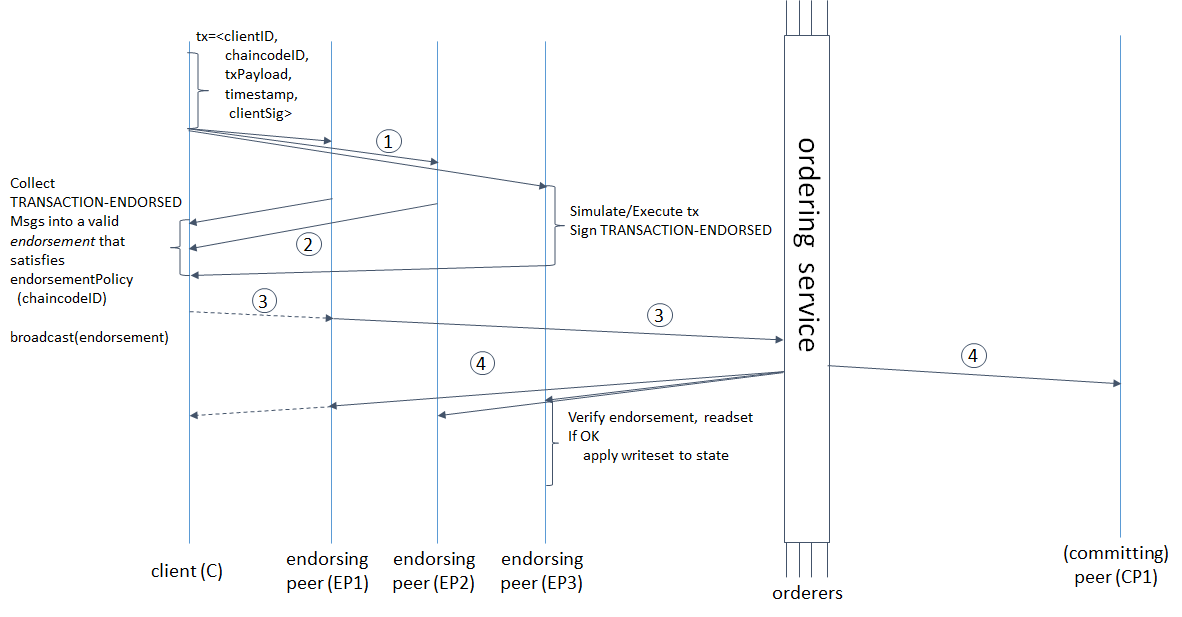 extrait d'ici : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) Le client génère une transaction, l'envoie à ses homologues endosseurs, ces derniers simulent la transaction (appliquent les modifications apportées par le code de chaîne à l'état actuel, mais ne s'engagent pas dans le grand livre) et obtiennent RWSet - noms de clés, versions et valeurs tirées de la collection dans CouchDB, ( 2) les endosseurs renvoient le RWSet signé au client, (3) le client vérifie les signatures de tous les pairs nécessaires (endosseurs), puis envoie la transaction au service de commande, ou l'envoie sans vérification (la vérification aura encore lieu plus tard), le service de commande forme un bloc et ( 4) renvoie à tous ses pairs, pas seulement aux endosseurs; les pairs vérifient que les versions clés de l'ensemble de lecture correspondent aux versions de la base de données, aux signatures de tous les endosseurs et finalement valident le bloc.Mais ce n'est pas tout. Les mots «la commande forme un bloc» cachent non seulement l'ordre des transactions, mais aussi 3 requêtes réseau consécutives du leader aux suiveurs et vice versa: le leader ajoute un message au journal, envoie aux suiveurs, ce dernier ajoute à son journal, envoie une confirmation de réplication réussie au leader, le leader valide un message , envoie une confirmation de validation aux abonnés, les abonnés s'engagent. Plus la taille et le temps de formation du bloc sont petits, plus le service de commande devra souvent établir un consensus. Hyperledger Fabric a deux paramètres de formation de bloc: BatchTimeout - heure de formation du bloc et BatchSize - taille du bloc (nombre de transactions et taille du bloc lui-même en octets). Dès qu'un des paramètres atteint la limite, un nouveau bloc est libéré. Plus il y a de nœuds justifiés, plus cela prendra de temps. Par conséquent, vous devez augmenter BatchTimeout et BatchSize. Mais puisque les RWSets sont versionnés, plus nous faisons de bloc, plus la probabilité de conflits MVCC est élevée. De plus, avec une augmentation de BatchTimeout, l'UX se dégrade de façon catastrophique. Il me semble raisonnable et évident le schéma suivant pour résoudre ces problèmes.
extrait d'ici : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) Le client génère une transaction, l'envoie à ses homologues endosseurs, ces derniers simulent la transaction (appliquent les modifications apportées par le code de chaîne à l'état actuel, mais ne s'engagent pas dans le grand livre) et obtiennent RWSet - noms de clés, versions et valeurs tirées de la collection dans CouchDB, ( 2) les endosseurs renvoient le RWSet signé au client, (3) le client vérifie les signatures de tous les pairs nécessaires (endosseurs), puis envoie la transaction au service de commande, ou l'envoie sans vérification (la vérification aura encore lieu plus tard), le service de commande forme un bloc et ( 4) renvoie à tous ses pairs, pas seulement aux endosseurs; les pairs vérifient que les versions clés de l'ensemble de lecture correspondent aux versions de la base de données, aux signatures de tous les endosseurs et finalement valident le bloc.Mais ce n'est pas tout. Les mots «la commande forme un bloc» cachent non seulement l'ordre des transactions, mais aussi 3 requêtes réseau consécutives du leader aux suiveurs et vice versa: le leader ajoute un message au journal, envoie aux suiveurs, ce dernier ajoute à son journal, envoie une confirmation de réplication réussie au leader, le leader valide un message , envoie une confirmation de validation aux abonnés, les abonnés s'engagent. Plus la taille et le temps de formation du bloc sont petits, plus le service de commande devra souvent établir un consensus. Hyperledger Fabric a deux paramètres de formation de bloc: BatchTimeout - heure de formation du bloc et BatchSize - taille du bloc (nombre de transactions et taille du bloc lui-même en octets). Dès qu'un des paramètres atteint la limite, un nouveau bloc est libéré. Plus il y a de nœuds justifiés, plus cela prendra de temps. Par conséquent, vous devez augmenter BatchTimeout et BatchSize. Mais puisque les RWSets sont versionnés, plus nous faisons de bloc, plus la probabilité de conflits MVCC est élevée. De plus, avec une augmentation de BatchTimeout, l'UX se dégrade de façon catastrophique. Il me semble raisonnable et évident le schéma suivant pour résoudre ces problèmes.Évitez d'attendre la finalisation du bloc et ne perdez pas la possibilité de suivre l'état des transactions
Plus le temps de formation et la taille du bloc sont longs, plus le débit de la blockchain est élevé. L'un des autres ne suit pas directement, mais il faut se rappeler que la recherche d'un consensus dans RAFT nécessite trois demandes de réseau du leader aux followers et vice versa. Plus il y a de nœuds de commande, plus cela prendra de temps. Plus la taille et le temps de formation du bloc sont petits, plus ces interactions sont nombreuses. Comment augmenter le temps de formation et la taille du bloc sans augmenter le temps d'attente d'une réponse système pour l'utilisateur final?Tout d'abord, vous devez résoudre en quelque sorte les conflits MVCC causés par une grande taille de bloc, qui peut inclure différents RWSets avec la même version. De toute évidence, du côté client (par rapport au réseau de blockchain, cela peut bien être le backend, et je le pense), vous avez besoin d'un gestionnaire de conflit MVCC, qui peut être soit un service distinct, soit un décorateur classique sur un appel déclenchant une transaction avec une logique de nouvelle tentative.La nouvelle tentative peut être implémentée avec une stratégie exponentielle, mais la latence se dégradera tout aussi exponentiellement. Vous devez donc utiliser soit une nouvelle tentative aléatoire dans certaines petites limites, soit une tentative permanente. Avec un œil sur les conflits possibles dans le premier mode de réalisation.L'étape suivante consiste à rendre l'interaction du client avec le système asynchrone afin qu'il n'attende pas 15, 30 ou 10 000 000 secondes, ce que nous définirons comme BatchTimeout. Mais en même temps, vous devez enregistrer l'opportunité de vous assurer que les modifications initiées par la transaction sont écrites / non écrites dans la blockchain.Vous pouvez utiliser une base de données pour stocker l'état des transactions. L'option la plus simple est CouchDB en raison de sa facilité d'utilisation: la base de données a une interface utilisateur prête à l'emploi, une API REST, et vous pouvez facilement configurer la réplication et le partitionnement pour elle. Vous pouvez créer juste une collection distincte dans la même instance CouchDB que Fabric utilise pour stocker son état mondial. Nous devons stocker des documents de ce type.{
Status string
TxID: string
Error: string
}
Ce document est écrit dans la base de données avant le transfert de la transaction aux pairs, un ID d'entité est retourné à l'utilisateur (le même ID est utilisé comme clé) s'il s'agit d'une opération pour créer quelque chose, puis les champs Statut, TxID et Erreur sont mis à jour à mesure que les informations pertinentes des pairs sont reçues. Dans ce schéma, l'utilisateur n'attend pas que le bloc se forme enfin, regardant la roue qui tourne sur l'écran pendant 10 secondes, il reçoit une réponse instantanée du système et continue de travailler.Nous avons choisi BoltDB pour stocker les statuts des transactions, car nous devons économiser de la mémoire et ne voulons pas consacrer de temps à l'interaction réseau avec un serveur de base de données autonome, en particulier lorsque cette interaction se produit à l'aide du protocole de texte brut. Soit dit en passant, vous utilisez CouchDB pour implémenter le schéma décrit ci-dessus ou simplement pour stocker l'état mondial, dans tous les cas, il est logique d'optimiser la façon dont les données sont stockées dans CouchDB. Par défaut, dans CouchDB, la taille des nœuds b-tree est de 1279 octets, ce qui est beaucoup plus petit que la taille du secteur sur le disque, ce qui signifie que la lecture et le rééquilibrage de l'arborescence nécessiteront plus d'accès au disque physique. La taille optimale est conforme à la norme Advanced Format et est de 4 kilo-octets. Pour l'optimisation, nous devons définir le paramètre btree_chunk_size sur 4096dans le fichier de configuration CouchDB. Pour BoltDB, une telle intervention manuelle n'est pas requise .
Dans ce schéma, l'utilisateur n'attend pas que le bloc se forme enfin, regardant la roue qui tourne sur l'écran pendant 10 secondes, il reçoit une réponse instantanée du système et continue de travailler.Nous avons choisi BoltDB pour stocker les statuts des transactions, car nous devons économiser de la mémoire et ne voulons pas consacrer de temps à l'interaction réseau avec un serveur de base de données autonome, en particulier lorsque cette interaction se produit à l'aide du protocole de texte brut. Soit dit en passant, vous utilisez CouchDB pour implémenter le schéma décrit ci-dessus ou simplement pour stocker l'état mondial, dans tous les cas, il est logique d'optimiser la façon dont les données sont stockées dans CouchDB. Par défaut, dans CouchDB, la taille des nœuds b-tree est de 1279 octets, ce qui est beaucoup plus petit que la taille du secteur sur le disque, ce qui signifie que la lecture et le rééquilibrage de l'arborescence nécessiteront plus d'accès au disque physique. La taille optimale est conforme à la norme Advanced Format et est de 4 kilo-octets. Pour l'optimisation, nous devons définir le paramètre btree_chunk_size sur 4096dans le fichier de configuration CouchDB. Pour BoltDB, une telle intervention manuelle n'est pas requise .Contre-pression: stratégie tampon
Mais il peut y avoir beaucoup de messages. Plus que ce que le système est capable de traiter, le partage des ressources avec une douzaine d'autres services en plus de ceux illustrés dans le diagramme - et tout cela devrait fonctionner sans faute, même sur les machines sur lesquelles le lancement d'Intellij Idea sera extrêmement fastidieux.Le problème des différents débits des systèmes communicants, producteurs et consommateurs, est résolu de différentes manières. Voyons ce que nous pourrions faire.Abandon : on peut prétendre ne pas pouvoir traiter plus de X transactions en T secondes. Toutes les demandes qui dépassent cette limite sont réinitialisées. C'est assez simple, mais vous pouvez alors oublier l'UX.Contrôle: le consommateur doit disposer d'une interface à travers laquelle, en fonction de la charge, il pourra contrôler les tps du producteur. Pas mal, mais cela impose des obligations aux développeurs du client créant la charge pour implémenter cette interface. Pour nous, cela est inacceptable, car la blockchain sera à l'avenir intégrée à un grand nombre de systèmes existants depuis longtemps.Mise en mémoire tampon: au lieu de chercher à résister au flux de données d'entrée, nous pouvons mettre en mémoire tampon ce flux et le traiter à la vitesse requise. Évidemment, c'est la meilleure solution si nous voulons offrir une bonne expérience utilisateur. Nous avons implémenté le tampon en utilisant la file d'attente dans RabbitMQ. Deux nouvelles actions ont été ajoutées au schéma: (1) après réception de la demande d'API, un message avec les paramètres nécessaires pour appeler la transaction est mis en file d'attente, et le client reçoit un message indiquant que la transaction a été acceptée par le système, (2) le backend lit les données à la vitesse spécifiée dans la configuration de la file d'attente; initie une transaction et met à jour les données dans le magasin d'état.Vous pouvez désormais augmenter le temps de formation et la capacité de blocage autant que vous le souhaitez, masquant ainsi les retards à l'utilisateur.
Deux nouvelles actions ont été ajoutées au schéma: (1) après réception de la demande d'API, un message avec les paramètres nécessaires pour appeler la transaction est mis en file d'attente, et le client reçoit un message indiquant que la transaction a été acceptée par le système, (2) le backend lit les données à la vitesse spécifiée dans la configuration de la file d'attente; initie une transaction et met à jour les données dans le magasin d'état.Vous pouvez désormais augmenter le temps de formation et la capacité de blocage autant que vous le souhaitez, masquant ainsi les retards à l'utilisateur.Autres outils
Rien n'a été dit ici sur le code de chaîne, car, en règle générale, il n'y a rien à optimiser. Le code de chaîne doit être aussi simple et sûr que possible - c'est tout ce qu'il faut. Cheynkod écrit simplement et en toute sécurité nous aide à bien structurer SSKit de S7 Techlab et l'analyseur statique Revive ^ CC .De plus, notre équipe développe un ensemble d'utilitaires pour rendre le travail avec Fabric simple et agréable: un explorateur de blockchain , un utilitaire pour changer automatiquement la configuration du réseau (ajout / suppression d'organisations, nœuds RAFT), un utilitaire pour révoquer des certificats et supprimer une identité . Si vous souhaitez contribuer - bienvenue.Conclusion
Cette approche permet de remplacer facilement Hyperledger Fabric par Quorum, d'autres réseaux privés Ethereum (PoA ou même PoW), de réduire considérablement la bande passante réelle, mais en même temps de maintenir une UX normale (à la fois pour les utilisateurs du navigateur et pour les systèmes intégrés). Lorsque vous remplacez Fabric par Ethereum dans le schéma, vous n'aurez qu'à modifier la logique du service de tentative / décorateur de traiter les conflits MVCC en nonce d'incrément atomique et de renvoyer. La mise en mémoire tampon et le stockage d'état ont permis de dissocier le temps de réponse du temps de formation du bloc. Vous pouvez maintenant ajouter des milliers de nœuds de commande et ne pas avoir peur que les blocs soient formés trop souvent et charger le service de commande.En général, c'est tout ce que je voulais partager. Je serais heureux si cela aide quelqu'un dans son travail.