Remarque perev. : Dans cet article, Banzai Cloud partage un exemple d'utilisation de ses utilitaires spéciaux pour faciliter le fonctionnement de Kafka au sein de Kubernetes. Ces instructions illustrent comment vous pouvez déterminer la taille optimale de l'infrastructure et configurer Kafka lui-même pour atteindre le débit requis. Apache Kafka est une plate-forme de streaming distribuée pour créer des systèmes de streaming en temps réel fiables, évolutifs et hautes performances. Ses fonctionnalités impressionnantes peuvent être étendues avec Kubernetes. Pour ce faire, nous avons développé l' opérateur Kafka Open Source et un outil appelé Supertubes. Ils vous permettent d'exécuter Kafka dans Kubernetes et d'utiliser ses diverses fonctions, telles que le réglage fin de la configuration du courtier, la mise à l'échelle basée sur des métriques avec rééquilibrage, la connaissance du rack (connaissance des ressources matérielles), les mises à jour continues «douces» (gracieuses) , etc.
Apache Kafka est une plate-forme de streaming distribuée pour créer des systèmes de streaming en temps réel fiables, évolutifs et hautes performances. Ses fonctionnalités impressionnantes peuvent être étendues avec Kubernetes. Pour ce faire, nous avons développé l' opérateur Kafka Open Source et un outil appelé Supertubes. Ils vous permettent d'exécuter Kafka dans Kubernetes et d'utiliser ses diverses fonctions, telles que le réglage fin de la configuration du courtier, la mise à l'échelle basée sur des métriques avec rééquilibrage, la connaissance du rack (connaissance des ressources matérielles), les mises à jour continues «douces» (gracieuses) , etc.Essayez les supertubes dans votre cluster:
curl https://getsupertubes.sh | sh supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
Ou reportez-vous à la documentation . Vous pouvez également lire certaines des fonctionnalités de Kafka, qui sont automatisées avec l'aide de Supertubes et de l'opérateur Kafka. Nous en avons déjà parlé sur le blog:
Lorsque vous décidez de déployer un cluster Kafka dans Kubernetes, vous rencontrerez probablement le problème de déterminer la taille optimale de l'infrastructure sous-jacente et le besoin d'affiner la configuration Kafka pour répondre aux exigences de bande passante. Les performances maximales de chaque courtier sont déterminées par les performances des composants de l'infrastructure au cœur, tels que la mémoire, le processeur, la vitesse du disque, la bande passante du réseau, etc.Idéalement, la configuration du courtier devrait être telle que tous les éléments de l'infrastructure soient utilisés au maximum de leurs capacités. Cependant, dans la vraie vie, cette configuration est très compliquée. Il est plus probable que les utilisateurs configurent des courtiers pour maximiser l'utilisation d'un ou deux composants (disque, mémoire ou processeur). De manière générale, un courtier affiche des performances maximales lorsque sa configuration vous permet d'utiliser le composant le plus lent "dans son intégralité". Nous pouvons donc avoir une idée approximative de la charge qu'un courtier peut gérer.Théoriquement, nous pouvons également estimer le nombre de courtiers nécessaires pour travailler avec une charge donnée. Cependant, dans la pratique, il existe tellement d'options de configuration à différents niveaux qu'il est très difficile (voire impossible) d'évaluer les performances potentielles d'une certaine configuration. En d'autres termes, il est très difficile de planifier la configuration, à partir de certaines performances données.Pour les utilisateurs de Supertubes, nous adoptons généralement l'approche suivante: commencer par une configuration (infrastructure + paramètres), puis mesurer ses performances, ajuster les paramètres du courtier et répéter le processus à nouveau. Cela se produit jusqu'à ce que le potentiel du composant d'infrastructure le plus lent soit pleinement utilisé.De cette façon, nous obtenons une idée plus claire du nombre de courtiers dont un cluster a besoin pour faire face à une certaine charge (le nombre de courtiers dépend également d'autres facteurs, tels que le nombre minimum de répliques de messages pour assurer la stabilité, le nombre de chefs de partition, etc.). De plus, nous avons une idée du dimensionnement vertical des composants d'infrastructure souhaité.Cet article présentera les étapes que nous prenons pour «tout extraire» des composants les plus lents dans les configurations initiales et mesurer le débit du cluster Kafka. Une configuration hautement résiliente nécessite au moins trois courtiers actifs (min.insync.replicas=3) espacées dans trois zones d'accessibilité différentes. Pour configurer, faire évoluer et surveiller l'infrastructure Kubernetes, nous utilisons notre propre plateforme de gestion de conteneurs cloud hybride - Pipeline . Il prend en charge sur site (bare metal, VMware) et cinq types de clouds (Alibaba, AWS, Azure, Google, Oracle), ainsi que toute combinaison de ceux-ci.Réflexions sur l'infrastructure et la configuration du cluster Kafka
Pour les exemples ci-dessous, nous avons sélectionné AWS comme fournisseur de services cloud et EKS comme distribution Kubernetes. Une configuration similaire peut être implémentée à l'aide de PKE , une distribution Kubernetes de Banzai Cloud, certifiée par la CNCF.Disque
Amazon propose différents types de volumes EBS . Les SSD sont la base de gp2 et io1 , cependant, pour garantir un débit élevé, gp2 consomme des prêts accumulés ( crédits d' E / S) , c'est pourquoi nous avons préféré le type io1 , qui offre un débit élevé stable.Types d'instances
Les performances de Kafka dépendent fortement du cache de pages du système d'exploitation, nous avons donc besoin d'instances avec suffisamment de mémoire pour les courtiers (JVM) et de cache de pages. L'instance c5.2xlarge est un bon début, car elle dispose de 16 Go de mémoire et est optimisée pour fonctionner avec EBS . Son inconvénient est qu'il est capable de fournir des performances maximales pendant pas plus de 30 minutes toutes les 24 heures. Si votre charge de travail nécessite des performances maximales sur une période plus longue, examinez d'autres types d'instances. C'est exactement ce que nous avons fait, en nous arrêtant à c5.4xlarge . Il fournit un débit maximum de 593,75 Mb / s.. Le débit maximal du volume EBS io1 est supérieur à celui de l'instance c5.4xlarge , donc l'élément d'infrastructure le plus lent est probablement le débit d'E / S de ce type d'instance (qui devrait également être confirmé par les résultats de nos tests de charge).Réseau
La bande passante réseau doit être assez importante par rapport aux performances de l'instance de VM et du disque, sinon le réseau devient un goulot d'étranglement. Dans notre cas, l'interface réseau c5.4xlarge prend en charge des vitesses allant jusqu'à 10 Gb / s, ce qui est nettement supérieur à la bande passante de l'instance d'E / S de la machine virtuelle.Déploiement de courtier
Les courtiers doivent être déployés (prévu dans Kubernetes) sur des nœuds dédiés afin d'éviter la concurrence avec d'autres processus pour les ressources processeur, mémoire, réseau et disque.Version Java
Le choix logique est Java 11, car il est compatible avec Docker dans le sens où la JVM détermine correctement les processeurs et la mémoire disponibles pour le conteneur dans lequel le courtier s'exécute. Sachant que les limites du processeur sont importantes, la JVM définit en interne et de manière transparente le nombre de threads GC et de threads du compilateur JIT. Nous avons utilisé une image Kafka banzaicloud/kafka:2.13-2.4.0qui inclut la version 2.4.0 de Kafka (Scala 2.13) dans Java 11.Si vous souhaitez en savoir plus sur Java / JVM sur Kubernetes, consultez nos publications suivantes:
Paramètres de mémoire du courtier
La configuration de la mémoire du courtier comporte deux aspects clés: les paramètres de la JVM et du module Kubernetes. La limite de mémoire définie pour le pod doit être supérieure à la taille de segment maximale afin que la machine virtuelle Java dispose de suffisamment d'espace pour la métaspace Java dans sa propre mémoire et pour le cache de page du système d'exploitation que Kafka utilise activement. Lors de nos tests, nous avons exécuté des courtiers Kafka avec des paramètres -Xmx4G -Xms2Get la limite de mémoire pour le pod était 10 Gi. Veuillez noter que les paramètres de mémoire de la JVM peuvent être obtenus automatiquement à l'aide de -XX:MaxRAMPercentageet -X:MinRAMPercentage, en fonction de la limite de mémoire du module.Paramètres du processeur du courtier
De manière générale, vous pouvez augmenter la productivité en augmentant la concurrence en augmentant le nombre de threads utilisés par Kafka. Plus il y a de processeurs disponibles pour Kafka, mieux c'est. Dans notre test, nous avons commencé avec une limite de 6 processeurs et avons progressivement (itéré) augmenté leur nombre à 15. De plus, nous avons défini num.network.threads=12les paramètres du courtier pour augmenter le nombre de flux qui reçoivent des données du réseau et les envoient. Ayant immédiatement découvert que les courtiers suiveurs ne peuvent pas recevoir les répliques assez rapidement, ils ont augmenté num.replica.fetchersà 4 pour augmenter la vitesse à laquelle les courtiers suiveurs ont répliqué les messages des dirigeants.Outil de génération de charge
Assurez-vous que le potentiel du générateur de charge sélectionné ne s'épuise pas avant que le cluster Kafka (dont la référence est en cours d'exécution) n'atteigne sa charge maximale. En d'autres termes, il est nécessaire d'effectuer une évaluation préliminaire des capacités de l'outil de génération de charge, ainsi que de sélectionner des types d'instance pour celui-ci avec un nombre suffisant de processeurs et de mémoire. Dans ce cas, notre outil produira plus de charge que le cluster Kafka ne peut en digérer. Après de nombreuses expériences, nous nous sommes installés sur trois copies de c5.4xlarge , dans chacune desquelles le générateur a été lancé.Analyse comparative
La mesure du rendement est un processus itératif qui comprend les étapes suivantes:- configuration de l'infrastructure (cluster EKS, cluster Kafka, outil de génération de charge, ainsi que Prometheus et Grafana);
- génération de charge pendant une certaine période pour filtrer les écarts aléatoires dans les indicateurs de performance collectés;
- affiner l'infrastructure et la configuration du courtier en fonction des indicateurs de performance observés;
- répéter le processus jusqu'à ce que le niveau requis de bande passante du cluster Kafka soit atteint. En même temps, il doit être reproductible de manière stable et présenter des variations de bande passante minimales.
La section suivante décrit les étapes qui ont été effectuées pendant le cluster de test de référence.Outils
Les outils suivants ont été utilisés pour déployer rapidement la configuration de base, la génération de charge et la mesure des performances:- Banzai Cloud Pipeline EKS Amazon c Prometheus ( Kafka ) Grafana ( ). Pipeline , , , , , .
- Sangrenel — Kafka.
- Grafana Kafka : Kubernetes Kafka, Node Exporter.
- Supertubes CLI pour la manière la plus simple de configurer un cluster Kafka dans Kubernetes. Zookeeper, opérateur Kafka, Envoy et de nombreux autres composants sont installés et correctement configurés pour démarrer le cluster Kafka prêt à la production dans Kubernetes.
- Pour installer la supertubes CLI, utilisez les instructions fournies ici .

Cluster EKS
Préparez un cluster EKS avec des nœuds de travail c5.4xlarge dédiés dans différentes zones de disponibilité pour les pods avec les courtiers Kafka, ainsi que des nœuds dédiés pour le générateur de charge et l'infrastructure de surveillance.banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.json
Lorsque le cluster EKS est opérationnel, activez son service de surveillance intégré - il déploiera Prometheus et Grafana sur le cluster.Composants du système Kafka
Installez les composants du système Kafka (Zookeeper, kafka-operator) dans l'EKS en utilisant les supertubes CLI:supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
Cluster Kafka
Par défaut, EKS utilise des volumes gp2 EBS , vous devez donc créer une classe de stockage distincte basée sur les volumes io1 pour le cluster Kafka:kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF
Définissez un paramètre pour les courtiers min.insync.replicas=3et déployez des modules de courtier sur les nœuds dans trois zones de disponibilité différentes:supertubes cluster create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600
Les sujets
Nous avons lancé simultanément trois instances du générateur de charge. Chacun d'eux écrit dans son propre sujet, c'est-à-dire qu'il nous suffit de trois sujets:supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
Pour chaque sujet, le facteur de réplication est 3 - la valeur minimale recommandée pour les systèmes de production hautement disponibles.Outil de génération de charge
Nous avons lancé trois instances du générateur de charge (chacune écrite dans une rubrique distincte). Pour les pods du générateur de charge, vous devez enregistrer l'affinité des nœuds afin qu'ils ne soient planifiés que sur les nœuds qui leur sont alloués:apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
Quelques points à prendre en compte:- Le générateur de charge génère des messages de 512 octets et les publie sur Kafka par lots de 500 messages.
-required-acks=all , Kafka. , , , , . (consumers) , , , .- 20 worker' (
-workers=20). worker 5 producer', worker' Kafka. 100 producer', Kafka.
Surveillance de cluster
Pendant les tests de résistance du cluster Kafka, nous avons également surveillé son état de santé pour nous assurer qu'il n'y avait pas de redémarrage des pods, des répliques désynchronisées et un débit maximal avec des fluctuations minimales:Résultats de mesure
3 courtiers, taille du message - 512 octets
Avec des partitions réparties uniformément sur trois courtiers, nous avons réussi à atteindre une performance de ~ 500 Mb / s (environ 990 000 messages par seconde) :

 la consommation de mémoire de la machine virtuelle JVM ne dépassait pas 2 Go:
la consommation de mémoire de la machine virtuelle JVM ne dépassait pas 2 Go:

 la bande passante du disque atteignait la bande passante d'E / S maximale le nœud sur les trois instances sur
la bande passante du disque atteignait la bande passante d'E / S maximale le nœud sur les trois instances sur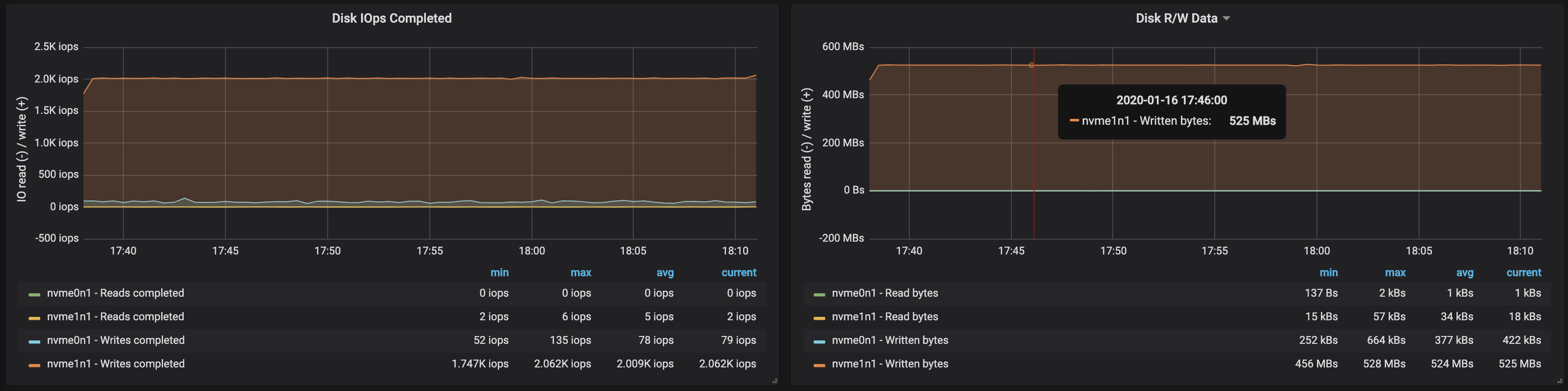

 lesquelles les courtiers ont travaillé: D'après les données sur l'utilisation de la mémoire par les nœuds, il s'ensuit que la mise en mémoire tampon et la mise en cache du système ont pris environ 10 à 15 Go:
lesquelles les courtiers ont travaillé: D'après les données sur l'utilisation de la mémoire par les nœuds, il s'ensuit que la mise en mémoire tampon et la mise en cache du système ont pris environ 10 à 15 Go:


3 courtiers, taille du message - 100 octets
Avec une diminution de la taille des messages, le débit diminue d'environ 15 à 20%: le temps consacré au traitement de chaque message est affecté. De plus, la charge du processeur a presque doublé.

 Étant donné que les nœuds de courtier ont toujours des noyaux inutilisés, vous pouvez améliorer les performances en modifiant la configuration de Kafka. Ce n'est pas une tâche facile, par conséquent, pour augmenter le débit, il est préférable de travailler avec des messages plus volumineux.
Étant donné que les nœuds de courtier ont toujours des noyaux inutilisés, vous pouvez améliorer les performances en modifiant la configuration de Kafka. Ce n'est pas une tâche facile, par conséquent, pour augmenter le débit, il est préférable de travailler avec des messages plus volumineux.4 courtiers, taille du message - 512 octets
Vous pouvez facilement augmenter les performances du cluster Kafka en ajoutant simplement de nouveaux courtiers et en maintenant l'équilibre des partitions (cela garantit une répartition uniforme de la charge entre les courtiers). Dans notre cas, après l'ajout d'un courtier, le débit du cluster est passé à ~ 580 Mb / s (~ 1,1 million de messages par seconde) . La croissance s'est avérée plus faible que prévu: cela est principalement dû au déséquilibre des partitions (tous les courtiers ne travaillent pas au plus fort des opportunités).


 La consommation de mémoire de la machine JVM reste inférieure à 2 Go: le
La consommation de mémoire de la machine JVM reste inférieure à 2 Go: le


 déséquilibre de partition a affecté le fonctionnement des courtiers avec les disques:
déséquilibre de partition a affecté le fonctionnement des courtiers avec les disques:



résultats
L'approche itérative présentée ci-dessus peut être étendue pour couvrir des scénarios plus complexes, notamment des centaines de consommateurs, le repartitionnement, les mises à jour continues, les redémarrages de pods, etc. Tout cela nous permet d'évaluer les limites des capacités du cluster Kafka dans diverses conditions, d'identifier les goulots d'étranglement dans son travail et de trouver des moyens de les surmonter.Nous avons développé des supertubes pour déployer rapidement et facilement un cluster, le configurer, ajouter / supprimer des courtiers et des rubriques, répondre aux alertes et nous assurer que Kafka fonctionne correctement dans Kubernetes dans son ensemble. Notre objectif est d'aider à se concentrer sur la tâche principale («générer» et «consommer» des messages Kafka), et de fournir tout le travail acharné aux opérateurs Supertubes et Kafka.Si vous êtes intéressé par les technologies Banzai Cloud et les projets Open Source, abonnez-vous à la société sur GitHub , LinkedIn ou Twitter .PS du traducteur
Lisez aussi dans notre blog: