Une traduction de l'article a été préparée avant le début du cours d' apprentissage automatique d'OTUS.
Tâche
Dans ce guide, nous utilisons l'ensemble de données Bitcoin vs USD .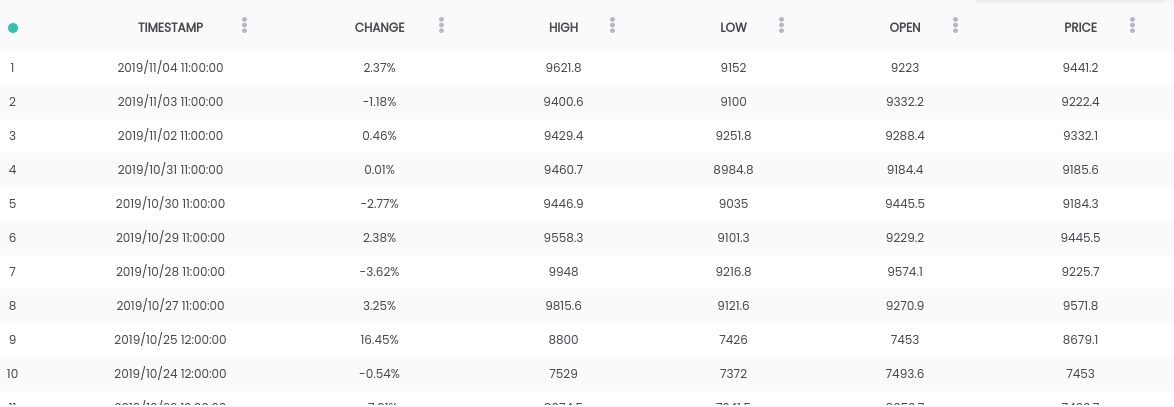 L'ensemble de données ci-dessus contient un résumé des prix quotidiens, où la colonne CHANGE est la variation du prix en pourcentage du prix du jour précédent ( PRICE ) par rapport au nouveau ( OPEN ).Objectif: Pour simplifier la tâche, nous nous concentrerons sur la prévision si le prix augmentera ( CHANGE> 0 ) ou baissera ( CHANGE <0 ) le lendemain. (Nous pouvons donc potentiellement utiliser des prédictions "dans la vraie vie").Exigences
L'ensemble de données ci-dessus contient un résumé des prix quotidiens, où la colonne CHANGE est la variation du prix en pourcentage du prix du jour précédent ( PRICE ) par rapport au nouveau ( OPEN ).Objectif: Pour simplifier la tâche, nous nous concentrerons sur la prévision si le prix augmentera ( CHANGE> 0 ) ou baissera ( CHANGE <0 ) le lendemain. (Nous pouvons donc potentiellement utiliser des prédictions "dans la vraie vie").Exigences- Python 2.6+ ou 3.1+ doit être installé sur le système
- Installer des pandas , sklearn et openblender (en utilisant pip)
$ pip install pandas OpenBlender scikit-learn
Étape 1. Obtenez des données Bitcoin
Pour commencer, importons les bibliothèques nécessaires:import OpenBlender
import pandas as pd
import json
Tirez maintenant les données via l' API OpenBlender .Tout d'abord, définissons les paramètres (dans notre cas, ce n'est que l' id du jeu de données bitcoin ):
parameters = {
'id_dataset':'5d4c3af79516290b01c83f51'
}
Remarque: vous devrez créer un compte sur openblender.io (c'est gratuit) et ajouter un jeton (vous le trouverez dans l'onglet "Compte"):parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51'
}
Maintenant, mettons les données dans le Dataframe 'df' :
def pullObservationsToDF(parameters):
action = 'API_getObservationsFromDataset'
df = pd.read_json(json.dumps(OpenBlender.call(action,parameters)['sample']), convert_dates=False,convert_axes=False) .sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
return df
df = pullObservationsToDF(parameters)
Et regardez-les: Remarque: les valeurs peuvent varier, car le jeu de données est mis à jour quotidiennement !
Remarque: les valeurs peuvent varier, car le jeu de données est mis à jour quotidiennement !Étape 2. Préparation des données
Pour commencer, nous devons créer un objectif de prévision, qui sera de savoir si « CHANGE » augmentera ou diminuera. Pour ce faire, ajoutez «success_thr_over»: 0 aux paramètres de seuil cible:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change', 'success_thr_over': 0}
}
Si nous tirons à nouveau les données de l'API:df = pullObservationsToDF(parameters)
df.head()
 L'attribut «CHANGE» a été remplacé par un nouvel attribut «change_over_0», qui devient 1 si «CHANGE» est positif et 0 sinon. Ce sera un objectif d'apprentissage automatique.Si nous voulons prédire l'observation pour "demain", nous ne pourrons pas utiliser les informations de demain, ajoutons donc un délai d'une période.
L'attribut «CHANGE» a été remplacé par un nouvel attribut «change_over_0», qui devient 1 si «CHANGE» est positif et 0 sinon. Ce sera un objectif d'apprentissage automatique.Si nous voulons prédire l'observation pour "demain", nous ne pourrons pas utiliser les informations de demain, ajoutons donc un délai d'une période.parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change','success_thr_over' : 0},
'lag_target_feature':{'feature':'change_over_0', 'periods' : 1}
}
df = pullObservationsToDF(parameters)
df.head()
 Cela aligne simplement 'change_over_0' avec les données du jour (période) précédent et change son nom en 'TARGET_change_over_0' .Regardons la dépendance:
Cela aligne simplement 'change_over_0' avec les données du jour (période) précédent et change son nom en 'TARGET_change_over_0' .Regardons la dépendance:target_variable = 'TARGET_change_over_0'
df = df.dropna()
df.corr()[target_variable].sort_values()
 Ils sont linéairement indépendants et peu susceptibles d'être utiles.
Ils sont linéairement indépendants et peu susceptibles d'être utiles.Étape 3. Obtenir des données sur les actualités commerciales
Après avoir recherché les dépendances dans OpenBlender , j'ai trouvé l'ensemble de données Fox Business News qui aidera à générer de bonnes prévisions pour notre cible. Nous devons trouver un moyen de convertir les valeurs de la colonne `` titre '' en caractéristiques numériques en comptant les répétitions de mots et de groupes de mots dans le résumé de l'actualité, et de les comparer dans le temps avec notre jeu de données bitcoin. C'est plus facile qu'il n'y paraît.Vous devez d'abord créer un TextVectorizer pour l'attribut 'title' de l'actualité:
Nous devons trouver un moyen de convertir les valeurs de la colonne `` titre '' en caractéristiques numériques en comptant les répétitions de mots et de groupes de mots dans le résumé de l'actualité, et de les comparer dans le temps avec notre jeu de données bitcoin. C'est plus facile qu'il n'y paraît.Vous devez d'abord créer un TextVectorizer pour l'attribut 'title' de l'actualité:action = 'API_createTextVectorizer'
vectorizer_parameters = {
'token' : 'your_token',
'name' : 'Fox Business TextVectorizer',
'sources':[{'id_dataset' : '5d571f9e9516293a12ad4f6d',
'features' : ['title']}],
'ngram_range' : {'min' : 1, 'max' : 2},
'language' : 'en',
'remove_stop_words' : 'on',
'min_count_limit' : 2
}
Nous allons créer un vectoriseur pour obtenir tous les signes sous forme de mots symboliques sous forme de nombres. Ci-dessus, nous avons indiqué ce qui suit:- nom : appelons-le «Fox Business TextVectorizer» ;
- ancre : identifiant de l'ensemble de données et nom des caractéristiques que nous devrons utiliser comme source (dans notre cas, uniquement la colonne «titre» );
- ngram_range : longueur minimale et maximale d'un ensemble de mots pour la tokenisation;
- langue : anglais
- remove_stop_words : pour supprimer les mots vides de la source;
- min_count_limit : le nombre minimum de répétitions qui doit être considéré comme un jeton (les occurrences simples sont rarement utiles).
Exécutez maintenant ceci:res = OpenBlender.call(action, vectorizer_parameters)
res
Réponse:{
'message' : 'TextVectorizer created successfully.'
'id_textVectorizer' : '5dc1a404951629331f6359dd',
'num_ngrams': 4270
}
TextVectorizer a
été créé , ce qui a généré 4270 n-grammes selon notre configuration. Un peu plus tard, nous aurons besoin de l'ID généré:5dc1a404951629331f6359ddÉtape 4. Résumé des nouvelles compatibles avec le jeu de données Bitcoin
Maintenant, nous devons comparer le résumé des nouvelles et les données sur le taux de change du bitcoin dans le temps. En général, cela signifie que vous devez combiner deux ensembles de données en utilisant un horodatage comme clé. Ajoutons les données combinées à nos options d'extraction de données d'origine:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'specifications':{'time_interval_size' : 3600*12 }}]
}
Ci-dessus, nous avons indiqué ce qui suit:- id_blend : id de notre textVectorizer;
- blend_type : 'text_ts' pour que Python comprenne qu'il s'agit d'un mélange de texte et d'horodatage;
- restriction : «prédictive» , de sorte qu'il n'y a pas de «mélange» des nouvelles du futur avec toutes les observations, mais uniquement avec celles qui ont été publiées plus tôt que l'heure spécifiée.
- blend_class : ' observation_la plus proche ' , de sorte que seules les observations les plus proches soient "mélangées";
- spécifications : durée maximale possible du transfert d'observation, en l'occurrence 12 heures (3600 * 12). Cela signifie que chaque observation du prix du bitcoin sera prédite en fonction de l'actualité des 12 dernières heures.
Enfin, nous ajoutons simplement un filtre par la date 'date_filter' , à partir du 20 août, car c'est à ce moment que Fox News a commencé à collecter des données, et 'drop_non_numeric' afin que nous n'obtenions que des nombres:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'blend_class' : 'closest_observation',
'specifications':{'time_interval_size' : 3600*12 }}],
'date_filter':{'start_date':'2019-08-20T16:59:35.825Z',
'end_date':'2019-11-04T17:59:35.825Z'},
'drop_non_numeric' : 1
}
Remarque : J'ai indiqué le 4 novembre comme 'end_date' , puisque c'était le jour où j'ai écrit ce code, vous pouvez changer la date.Reprenons les données:df = pullObservationsToDF(parameters)
print(df.shape)
df.head()
(57, 2115) Nous avons maintenant plus de 2000 signes avec des jetons et 57 observations.
Nous avons maintenant plus de 2000 signes avec des jetons et 57 observations.Étape 5. Appliquer ML à la cible de prédiction
Maintenant, enfin, nous avons un ensemble de données propre, et il ressemble exactement à ce dont nous avons besoin, avec un décalage temporel de la cible et des données numériques associées.Regardons les corrélations les plus élevées avec 'Target_change_over_0' : nous avons maintenant quelques attributs corrélatifs. Divisons l'ensemble de données en formation et testons par ordre chronologique afin de pouvoir entraîner le modèle dans les premières observations et tester dans les dernières.
nous avons maintenant quelques attributs corrélatifs. Divisons l'ensemble de données en formation et testons par ordre chronologique afin de pouvoir entraîner le modèle dans les premières observations et tester dans les dernières.X = df.loc[:, df.columns != target_variable].values
y = df.loc[:,[target_variable]].values
div = int(round(len(X) * 0.29))
X_test = X[:div]
y_test = y[:div]
print(X_test.shape)
print(y_test.shape)
X_train = X[div:]
y_train = y[div:]
print(X_train.shape)
print(y_train.shape)
 Nous avons 40 observations pour la formation et 17 pour les tests.Maintenant, nous importons les bibliothèques nécessaires:
Nous avons 40 observations pour la formation et 17 pour les tests.Maintenant, nous importons les bibliothèques nécessaires:from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
from sklearn import metrics
Maintenant, utilisons une forêt aléatoire (RandomForest) et faisons une prédiction:rf = RandomForestRegressor(n_estimators = 1000)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
Pour faciliter les choses, mettons les prédictions et y_test dans le Dataframe:df_res = pd.DataFrame({'y_test':y_test[:,0], 'y_pred':y_pred})
df_res.head()
Notre véritable 'y_test' est binaire, mais nos prévisions sont de type float , alors arrondissons-les, en supposant que si elles sont supérieures à 0,5, cela signifie une augmentation de prix, et si moins de 0,5 - une diminution.threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]
Maintenant, afin de mieux comprendre les résultats, nous obtenons l'AUC, la matrice d'erreur et l'indicateur de précision:print(roc_auc_score(preds, df_res['y_test']))
print(metrics.confusion_matrix(preds, df_res['y_test']))
print(accuracy_score(preds, df_res['y_test']))
 Nous avons obtenu 64,7% des prédictions correctes avec 0,65 AUC.
Nous avons obtenu 64,7% des prédictions correctes avec 0,65 AUC.- 9 fois nous avons prédit une baisse, et le prix a baissé (à droite);
- 5 fois nous avons prédit une baisse, et le prix a augmenté (incorrectement);
- 1 fois nous avons prédit une augmentation, mais le prix a baissé incorrectement);
- 2 fois, nous avons prédit une augmentation, et le prix a augmenté (vrai).
En savoir plus sur le cours .