Investigation et conversion en triant les séquences pseudo-aléatoires Desalgorithmes en C # et qbasic et un tableau compatible Excel ont été créés, prouvant la capacité d'examiner les séquences pseudo-aléatoires pour le caractère aléatoire et capable de déterminer des séquences non aléatoires ou de faible puissance.Coque graphique: tableau Excel compatible pour la recherche de plus de 50 000. éléments de 2 types:1. Etude d'une séquence de nombres;2. L'étude de la séquence des chiffres 0 et 1. Recherche de séquence de nombres: le tableau définit les caractéristiques binaires, par exemple, moins / plus et pair / impair.L'enveloppe graphique d'un tableau compatible Excel utilise les formules: Le
Recherche de séquence de nombres: le tableau définit les caractéristiques binaires, par exemple, moins / plus et pair / impair.L'enveloppe graphique d'un tableau compatible Excel utilise les formules: Le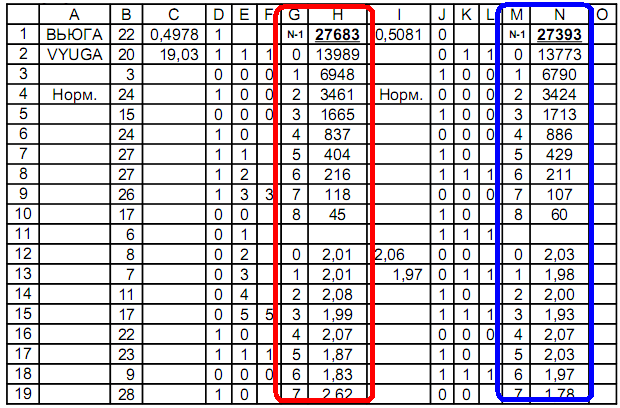 nombre de correspondances dans une ligne est calculé par la formule N = log (1-C) / log (1-P),où N est l'étape, P est la probabilité, C est la fiabilité de la probabilité.Numéro d'étape de distribution:à C = P = 0,5; N = 1 = log0,5 / log0,5 = log (1-1 / 2) / log (1-1 / 2) = 1à C = 0,25; P = 0,5; N = 2 = log0,75 / log0,5 = log (1-1 / 4) / log (1-1 / 2) = 2, etc.La colonne A est le nom de la séquence;Colonne B - séquence;Colonne D - 1ère distribution: moins / plus;Colonnes E, F - définition de lignes identiques dans une rangée;Colonnes G, H - comptage du nombre de signes identiques dans une rangée;Colonne J - 2e distribution: pair / impair;Colonnes K, L - définition de signes identiques dans une rangée;Colonnes M, N - comptage du nombre de signes identiques dans une rangée.Formules utilisées dans le tableau:
nombre de correspondances dans une ligne est calculé par la formule N = log (1-C) / log (1-P),où N est l'étape, P est la probabilité, C est la fiabilité de la probabilité.Numéro d'étape de distribution:à C = P = 0,5; N = 1 = log0,5 / log0,5 = log (1-1 / 2) / log (1-1 / 2) = 1à C = 0,25; P = 0,5; N = 2 = log0,75 / log0,5 = log (1-1 / 4) / log (1-1 / 2) = 2, etc.La colonne A est le nom de la séquence;Colonne B - séquence;Colonne D - 1ère distribution: moins / plus;Colonnes E, F - définition de lignes identiques dans une rangée;Colonnes G, H - comptage du nombre de signes identiques dans une rangée;Colonne J - 2e distribution: pair / impair;Colonnes K, L - définition de signes identiques dans une rangée;Colonnes M, N - comptage du nombre de signes identiques dans une rangée.Formules utilisées dans le tableau:Cellule
| Formule
| Explication
|
C1
| = MOYENNE (D1: D55000)
| La valeur moyenne des numéros de séquence
|
C2
| = MOYENNE (B1: B55000)
| Moyenne de distribution 1
|
D1
| = SI (B1 <2 $; 0; 1)
| Si le nombre est inférieur à la moyenne, alors 0, sinon 1
|
D2
| = SI (B2 <C $ 2; 0; 1)
| Si le nombre est inférieur à moy, alors 0, sinon 1, etc.
|
E2
| = SI (D2 = D1; E1 + 1; 0)
| Si les signes de distribution sont les mêmes, alors le compteur du même dans une rangée est +1, sinon le compteur est remis à zéro
|
F2
| = SI (E3 = 0; E2; "")
| Si le compteur est réinitialisé, le compteur le plus élevé est enregistré.
|
G2-g19
| 0 ... 7
| Des chiffres pour comparer
|
H1
| = SOMME (H2: H10)
| Somme des comparaisons
|
H2
| =(F$1:F$55000;G2)
| 1
|
H3
| =(F$1:F$55000;G3)
| 2 ..
|
H12
| =H2/H3
|
|
I12
| =(H12:H19)
|
|
I13
| =(N12:N19)
| ..
|
I1
| =(J1:J55000)
| 2
|
J1
| =(B1/2=(B1/2);0;1)
| , 0, 1
|
J2
| =(B2/2=(B2/2);0;1)
| , 0, 1 ..
|
K2
| =(J2=J1;K1+1;0)
| , +1,
|
L2
| =(K3=0;K2;" ")
| ,
|
M2-M19
| 0…7
|
|
N1
| =(N2:N10)
|
|
N2
| =(L$1:L$55000;M2)
| 1
|
N3
| =(L$1:L$55000;M3)
| 2 ..
|
N12
| =H2/H3
|
|
D'autres fonctions de surveillance peuvent être programmées dans le tableau.Dans le tableau, il est possible de créer des graphiques des valeurs de n'importe quelle cellule.La suite du tableau explore les permutations aléatoires de la séquence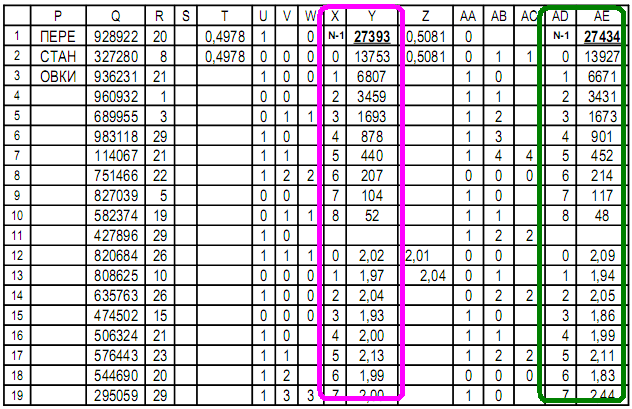 Colonne Q - aléatoire pour les permutations: nombres entiers jusqu'à 10 ^ 6,pour minimiser la répétition des permutations aléatoires;Colonne R - initialement une copie de la colonne B, puis modifiée;Les colonnes T ... AE sont les mêmes que les colonnes C ... N.
Colonne Q - aléatoire pour les permutations: nombres entiers jusqu'à 10 ^ 6,pour minimiser la répétition des permutations aléatoires;Colonne R - initialement une copie de la colonne B, puis modifiée;Les colonnes T ... AE sont les mêmes que les colonnes C ... N.Cellule
| Formule
| Explication
|
Q1
| = CAS ENTRE (0; 1 000 000)
| Aléatoire pour réorganiser
|
Q2
| = CAS ENTRE (0; 1 000 000)
| Aléatoire pour permutation, etc.
|
La permutation se fait en triant 2 colonnes Q et R: lacolonne Q est en tête et la colonne R est esclave.Résultat: permutation de la colonne R et nouvelle séquence.Les études PRNG basées sur le PRNG intégré montrent la normalité de l'algorithme.Avant la permutation de 500 cellules: Après la permutation de 500 cellules: La
Après la permutation de 500 cellules: La vérification montre une bonne distribution, en comparant les signes: petit / grand et pair / impair.Le tableau examine le PRNG trigonométrique, en utilisant les chiffres décimaux des fonctions trigonométriques, sans utiliser le PRNG standard.
vérification montre une bonne distribution, en comparant les signes: petit / grand et pair / impair.Le tableau examine le PRNG trigonométrique, en utilisant les chiffres décimaux des fonctions trigonométriques, sans utiliser le PRNG standard.
OPEN "rndsin.txt" FOR OUTPUT AS #1
c = 0: a = SIN(TIMER) * 100 + 200
PRINT #1, "a= ", a
FOR k = 1 TO 10 ^ 3 + a * 10 ^ 3: NEXT
FOR i = 1 TO 100
FOR j = 1 TO a
x = SIN(TIMER) * 1000 + 2000
b = COS(x): c = c + b
LOCATE 1, 1: PRINT j
NEXT
d = (ABS(c)) - INT(ABS(c))
PRINT #1, d
FOR k = 1 TO 10000 + a * b * c * 10 ^ 2: NEXT
NEXT
Avant la permutation de 500 cellules: insatisfaisant Evidemment, la distribution est médiocre, révélant la fréquence et la dispersion des valeurs, comparant les signes: petit / grand et pair / impair.Après réarrangement de 500 cellules: normal
Evidemment, la distribution est médiocre, révélant la fréquence et la dispersion des valeurs, comparant les signes: petit / grand et pair / impair.Après réarrangement de 500 cellules: normal But: exclure le PRNG intégré.Méthode de réarrangement: la séquence d'origine est triée, la même séquence qui est inversée ou inversée de quelque façon que ce soit est acceptée comme aléatoire pour le réarrangement.Par exemple, dans Excel, 2 copies des colonnes d'une séquence ont été créées à distance, et une ligne de tête de 1 ... 55000 dans une ligne est construite sur une colonne à gauche et 2 colonnes sont triées du maximum au minimum, inversant les données d'origine.Ensuite, 2 colonnes de la séquence sont mappées côte à côte et triées, où la colonne de tête est la colonne inverse et la colonne esclave est la colonne initiale.Avant la permutation de 500 cellules: insatisfaisant
But: exclure le PRNG intégré.Méthode de réarrangement: la séquence d'origine est triée, la même séquence qui est inversée ou inversée de quelque façon que ce soit est acceptée comme aléatoire pour le réarrangement.Par exemple, dans Excel, 2 copies des colonnes d'une séquence ont été créées à distance, et une ligne de tête de 1 ... 55000 dans une ligne est construite sur une colonne à gauche et 2 colonnes sont triées du maximum au minimum, inversant les données d'origine.Ensuite, 2 colonnes de la séquence sont mappées côte à côte et triées, où la colonne de tête est la colonne inverse et la colonne esclave est la colonne initiale.Avant la permutation de 500 cellules: insatisfaisant Après la permutation de 500 cellules: normal
Après la permutation de 500 cellules: normal Résultat: la séquence est devenue normale sans le PRNG intégré.Conclusions: le vrai hasard n'est pas naturel pour les gens et il est possible de synthétiser des séquences de faible puissance ou fausses qui sont acceptées par les gens et les ordinateurs comme des séquences aléatoires.Toutes les séquences peuvent vraiment être synthétisées dans des langages de programmation et dans des tableaux compatibles Excel.Le problème de surmonter le caractère aléatoire est résolu en reconnaissant le caractère aléatoire comme normal ou faux dans une feuille de calcul Excel avec des graphiques.Q.E.D.Poursuite de l'approbation:programmes de permutation en langues qbasic et C #.Enquête sur les chiffres pi.Falsification de l'aléatoire.Développement 2020 de personnes aux vues similaires.
Résultat: la séquence est devenue normale sans le PRNG intégré.Conclusions: le vrai hasard n'est pas naturel pour les gens et il est possible de synthétiser des séquences de faible puissance ou fausses qui sont acceptées par les gens et les ordinateurs comme des séquences aléatoires.Toutes les séquences peuvent vraiment être synthétisées dans des langages de programmation et dans des tableaux compatibles Excel.Le problème de surmonter le caractère aléatoire est résolu en reconnaissant le caractère aléatoire comme normal ou faux dans une feuille de calcul Excel avec des graphiques.Q.E.D.Poursuite de l'approbation:programmes de permutation en langues qbasic et C #.Enquête sur les chiffres pi.Falsification de l'aléatoire.Développement 2020 de personnes aux vues similaires.