Quand une autre année fructueuse se termine, je veux regarder en arrière, faire le point et montrer ce que nous avons pu faire pendant cette période. La bibliothèque #DeepPavlov, depuis une minute, a déjà deux ans, et nous sommes heureux que notre communauté grandisse chaque jour.Au cours de l'année de travail sur la bibliothèque, nous avons réalisé:- Les téléchargements de bibliothèques ont augmenté d'un tiers par rapport à l'année dernière. Désormais, DeepPavlov compte plus de 100 000 installations et plus de 10 000 installations de conteneurs.
- Le nombre de solutions commerciales a augmenté en raison des technologies de pointe mises en œuvre dans DeepPavlov, dans diverses industries, de la vente au détail à l'industrie.
- La première version de DeepPavlov Agent a été publiée .
- Le nombre de membres actifs de la communauté a été multiplié par 5.
- Notre équipe d'étudiants de premier cycle et des cycles supérieurs a été sélectionnée pour participer au Alexa Prize Socialbot Grand Challenge 3 .
- La bibliothèque est devenue lauréate du concours de la société Google «Powered by TensorFlow Challenge».
Qu'est-ce qui a aidé à obtenir de tels résultats et pourquoi DeepPavlov est- il le meilleur open source pour créer une IA conversationnelle? Nous le dirons dans notre article.
#DeepPavlov vise le résultat
Récemment, les systèmes de dialogue sont devenus la norme pour l'interaction homme-machine. Les chatbots sont utilisés dans presque toutes les industries, ce qui simplifie l'interaction entre les personnes et les ordinateurs. Ils s'intègrent parfaitement aux sites Web, aux plates-formes de messagerie et aux appareils. De nombreuses entreprises préfèrent aujourd'hui déléguer des tâches de routine à des systèmes interactifs qui peuvent gérer plusieurs demandes d'utilisateurs en même temps, ce qui réduit les coûts de main-d'œuvre.Cependant, les entreprises ne savent souvent pas par où commencer lorsqu'elles développent un bot pour répondre aux besoins de leur entreprise. Historiquement, les chatbots peuvent être divisés en deux grands groupes: basés sur des règles et basés sur des données. Le premier type repose sur des commandes et des modèles prédéfinis. Chacune de ces commandes doit être écrite par le développeur du chatbot en utilisant des expressions régulières et une analyse des données de texte. En revanche, les robots de discussion basés sur les données s'appuient sur des modèles d'apprentissage automatique qui ont été pré-formés sur les données de dialogue.Bibliothèque Open Source - DeepPavlovoffre une solution gratuite et facile à utiliser pour la construction de systèmes interactifs. DeepPavlov est livré avec plusieurs composants pré-formés pour résoudre les problèmes associés au traitement du langage naturel (NLP). DeepPavlov résout des problèmes tels que: classification de texte, correction de fautes de frappe, reconnaissance d'entités nommées, réponses à des questions sur la base de connaissances et bien d'autres. Et vous pouvez installer DeepPavlov sur une seule ligne en exécutant:pip install -q deeppavlov
* Le cadre vous permet de former et de tester des modèles, ainsi que de personnaliser leurs hyperparamètres. La bibliothèque prend en charge les plates-formes Linux et Windows. Vous pouvez essayer ceci et d'autres modèles dans la version de démonstration de la bibliothèque .Actuellement, des résultats modernes dans de nombreuses tâches ont été obtenus grâce à l'utilisation de modèles basés sur BERT. L'équipe DeepPavlov a intégré BERT dans les trois tâches suivantes: classification de texte, reconnaissance des entités nommées et réponses aux questions. En conséquence, nous avons apporté des améliorations significatives à toutes ces tâches.1. Modèles BERT DeepPavlov
BERT pour la classification de texte Un
modèle de classification de texte basé sur BERT DeepPavlov sert, par exemple, à résoudre le problème de détection des insultes. Le modèle comprend la prédiction si un commentaire publié dans une discussion publique est considéré comme offensant pour l'un des participants. Dans ce cas, le classement s'effectue uniquement en deux classes: insulte et non insulte.Tout modèle pré-formé peut être utilisé pour la sortie à la fois via l'interface de ligne de commande (CLI) et via Python. Avant d'utiliser le modèle, assurez-vous que tous les packages nécessaires sont installés à l'aide de la commande:python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
BERT pour la reconnaissance d'entités nommées
En plus des modèles de classification de texte, DeepPavlov inclut un modèle basé sur BERT pour la reconnaissance d'entités nommées (NER). C'est l'une des tâches les plus courantes en PNL et le modèle le plus utilisé de notre bibliothèque. Dans le même temps, NER a de nombreuses applications commerciales. Par exemple, un modèle peut extraire des informations importantes d'un curriculum vitae pour faciliter le travail des spécialistes des ressources humaines. En outre, NER peut être utilisé pour identifier les entités pertinentes dans les demandes des clients, telles que les spécifications des produits, les noms des entreprises ou les informations sur les succursales de l'entreprise.L'équipe DeepPavlov a formé le modèle NER au package OntoNotes de langue anglaise, qui comprend 19 types de balisage, y compris PER (personne), LOC (emplacement), ORG (organisation) et bien d'autres. Pour interagir avec, vous devez l'installer avec la commande:python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
BERT pour répondre aux questions Une
réponse contextuelle à une question consiste à trouver une réponse à une question dans un contexte donné (par exemple, un paragraphe de Wikipedia), où la réponse à chaque question est un segment de contexte. Par exemple, le triple de contexte, question et réponse ci-dessous forme le triplet correct pour la tâche de répondre à la question.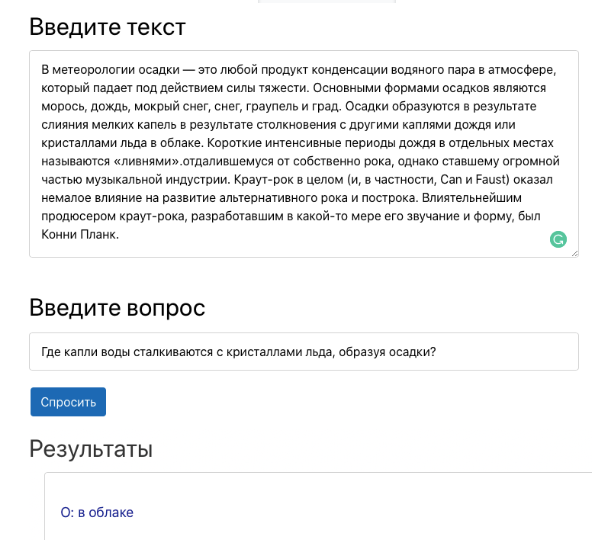 Présentation du travail du système question-réponse dans une démo.Un système de réponses aux questions peut automatiser de nombreux processus dans une entreprise. Par exemple, cela peut aider les employeurs à obtenir des réponses basées sur la documentation interne de l'entreprise. De plus, le modèle aidera à tester la capacité des élèves à comprendre le texte dans le processus d'apprentissage. Récemment, cependant, la tâche de répondre aux questions en fonction du contexte a attiré une grande attention des scientifiques. L'un des principaux tournants dans ce domaine a été la sortie du Stanford Question Answer Set (SQuAD). L'ensemble de données SQuAD a conduit à d'innombrables approches pour résoudre le problème du système question-réponse. L'un des plus réussis est le modèle DeepPavlov BERT. Il surpasse tous les autres et produit actuellement des résultats à la limite des caractéristiques humaines.Pour utiliser le modèle d'assurance qualité basé sur BERT avec DeepPavlov, vous devez:
Présentation du travail du système question-réponse dans une démo.Un système de réponses aux questions peut automatiser de nombreux processus dans une entreprise. Par exemple, cela peut aider les employeurs à obtenir des réponses basées sur la documentation interne de l'entreprise. De plus, le modèle aidera à tester la capacité des élèves à comprendre le texte dans le processus d'apprentissage. Récemment, cependant, la tâche de répondre aux questions en fonction du contexte a attiré une grande attention des scientifiques. L'un des principaux tournants dans ce domaine a été la sortie du Stanford Question Answer Set (SQuAD). L'ensemble de données SQuAD a conduit à d'innombrables approches pour résoudre le problème du système question-réponse. L'un des plus réussis est le modèle DeepPavlov BERT. Il surpasse tous les autres et produit actuellement des résultats à la limite des caractéristiques humaines.Pour utiliser le modèle d'assurance qualité basé sur BERT avec DeepPavlov, vous devez:python -m deeppavlov install squad_bert
python -m deeppavlov interact squad_bert -d
Plus de modèles peuvent être trouvés dans la documentation . Et si vous avez besoin de didacticiels sur l'utilisation des composants de bibliothèque, recherchez-les sur notre blog officiel .2. Agent DeepPavlov - une plate-forme pour créer des robots de discussion multitâches
Aujourd'hui, il existe plusieurs approches pour le développement d'agents interactifs. Lors du développement d'agents de conversation, l'architecture modulaire est principalement utilisée pour un dialogue ciblé dans lequel le script se déroule. Cependant, souvent, l'utilisateur doit combiner un dialogue ciblé, par exemple, avec une autre fonctionnalité - répondre à des questions ou rechercher des informations, ainsi que maintenir une conversation. Ainsi, l'agent de dialogue idéal est un assistant personnel qui combine différents types d'agents, bascule entre ses fonctionnalités et ses personnages, selon la tâche dans laquelle il est utilisé. Dans le même temps, l'agent doit accumuler des informations sur son essence, adapter ses algorithmes à un utilisateur spécifique. En revanche, il devrait pouvoir s'intégrer aux services externes. Par exemple,faire des requêtes vers des bases de données externes, obtenir des informations à partir de là, les traiter, mettre en évidence l'important et les transmettre à l'utilisateur. Pour résoudre ce problème, en octobre 2019, la première version de DeepPavlov Agent 1.0, une plate-forme pour créer des robots de discussion multitâches, a été publiée. L'agent aide les développeurs de chatbots de production à organiser plusieurs modèles NLP dans un même pipeline.En savoir plus sur la plateforme et les fonctionnalités dans la documentation .3. Implémentation de DeepPavlov NLP SaaS
Pour simplifier le travail avec des modèles de PNL pré-formés de DeepPavlov, en septembre 2019, un service SaaS a été lancé. DeepPavlov Cloud vous permet d'analyser du texte, ainsi que de stocker des documents dans le cloud. Pour utiliser les modèles, vous devez vous inscrire à notre service et obtenir un jeton dans la section Jetons de votre compte personnel. À l'heure actuelle, le service prend en charge plusieurs modèles de PNL pré-formés en russe et est en train de tester le système.4. Participation au DSCT8 ou système de dialogue ciblé
L'utilisation d'assistants virtuels tels qu'Amazon Alexa et Google Assistant a ouvert des possibilités de développement d'applications qui nous permettent de simplifier la mise en œuvre de nombreuses tâches quotidiennes, telles que la commande d'un taxi, la réservation d'une table dans un restaurant, et bien d'autres. Pour résoudre ces problèmes, des systèmes de dialogue ciblés sont utilisés.Dialogue State Traking (DST) est un élément clé de ces systèmes de dialogue. Le DST est chargé de traduire les énoncés en langage humain en une représentation sémantique du langage, en particulier, d'extraire les intentions et les paires de valeurs de créneau correspondant au but de l'utilisateur.Pendant la participation de l'équipe à DSTC8Le modèle GOLOMB (GOaL-Oriented Multi-task BERT-based dialog state tracker) a été développé - un modèle multi-tâche orienté objectif basé sur BERT pour suivre l'état du dialogue. Pour prédire l'état du dialogue, le modèle résout plusieurs problèmes de classification et la tâche de trouver une sous-chaîne. Bientôt, ce modèle apparaîtra dans la bibliothèque DeepPavlov. En attendant, vous pouvez lire l'article complet ici . Présentation de l'affiche à la conférence AAAI-20 à New York (USA).
Présentation de l'affiche à la conférence AAAI-20 à New York (USA).
5. Participation au Alexa Prize Socialbot Grand Challenge
L'équipe de DeepPavlov, composée d'étudiants et d'étudiants diplômés de l'Institut de physique et de technologie de Moscou, a été sélectionnée pour participer au Alexa Prize Socialbot Grand Challenge 3 - un concours international dédié au développement de la technologie de l'IA conversationnelle. Le but du concours est de créer un bot capable de communiquer librement avec les gens sur des sujets pertinents. Sur les 375 candidatures, le comité Alexa Prize a sélectionné 10 finalistes, dont notre équipe - DREAM. À l'heure actuelle, l'équipe est passée aux quarts de finale de la compétition et se bat pour atteindre les demi-finales. Vous pouvez suivre l'actualité et encourager la nôtre sur la page officielle , et n'oubliez pas de vous abonner à Twitter . Composition de l'équipe Dream Team.
Composition de l'équipe Dream Team.
6. Participation au Powered by TF Challenge
Comme indiqué précédemment, DeepPavlov est livré avec plusieurs composants pré-formés alimentés par TensorFlow et Keras. Et cette année, l'équipe DeepPavlov a remporté le concours Google Powered by TF Challenge pour le meilleur projet d'apprentissage automatique utilisant la bibliothèque TensorFlow. Sur plus de 600 participants au concours, Google a choisi les cinq meilleurs projets, dont l'un était la bibliothèque DeepPavlov. Le projet a été présenté sur le blog officiel de TensorFlow . Il convient de noter que la flexibilité de TensorFlow nous permet de créer n'importe quelle architecture de réseau neuronal à laquelle nous pouvons penser. Et en particulier, nous utilisons TensorFlow pour une intégration transparente avec les modèles basés sur BERT.
7. Développement communautaire
L'objectif global de notre projet est de permettre aux développeurs et aux chercheurs dans le domaine de l'intelligence artificielle conversationnelle d'utiliser les outils les plus avancés pour créer des systèmes interactifs de nouvelle génération, ainsi que de devenir une plate-forme d'importance internationale dans le domaine de l'IA pour l'échange d'expérience et l'enseignement de technologies de pointe.Pour ce faire, les employés de DeepPavlovorganiser des cours de formation semestriels gratuits pour les étudiants et le personnel impliqués dans l'informatique. L'un d'eux est le cours: «Deep learning in natural language processing» », qui comprend des séminaires et des ateliers. Les cours comprennent des sujets tels que: la construction de systèmes de dialogue, les méthodes d'évaluation d'un système de dialogue capable de générer une réponse, divers cadres pour les systèmes de dialogue, les méthodes d'estimation du montant de la rémunération due à l'optimisation des politiques de dialogue, les types de demandes des utilisateurs, la prise en compte de la modélisation des appels du centre d'appels. En 2020, nous avons lancé un nouveau recrutement et déjà 900 étudiants et employés suivent une formation gratuite. Vous pouvez suivre les actualités et l'ensemble de ce cours et d'autres sur notre site Web . Et si vous avez manqué les cours, mais que vous voulez en savoir plus - alors sur notrechaîne youtube , vous pouvez toujours les trouver dans l'enregistrement.Aujourd'hui, la bibliothèque DeepPavlov fournit des composants prêts pour l'IA pour travailler avec du texte, qui sont utilisés dans 92 pays du monde. En février 2020, le nombre de téléchargements de la bibliothèque atteignait 100 000 000 et la dynamique des installations s'accélère. En outre, plus de 30 entreprises en Russie ont déjà mis en œuvre et utilisent avec succès des solutions basées sur DeepPavlov. Cela montre que ces solutions sont très populaires dans le monde entier.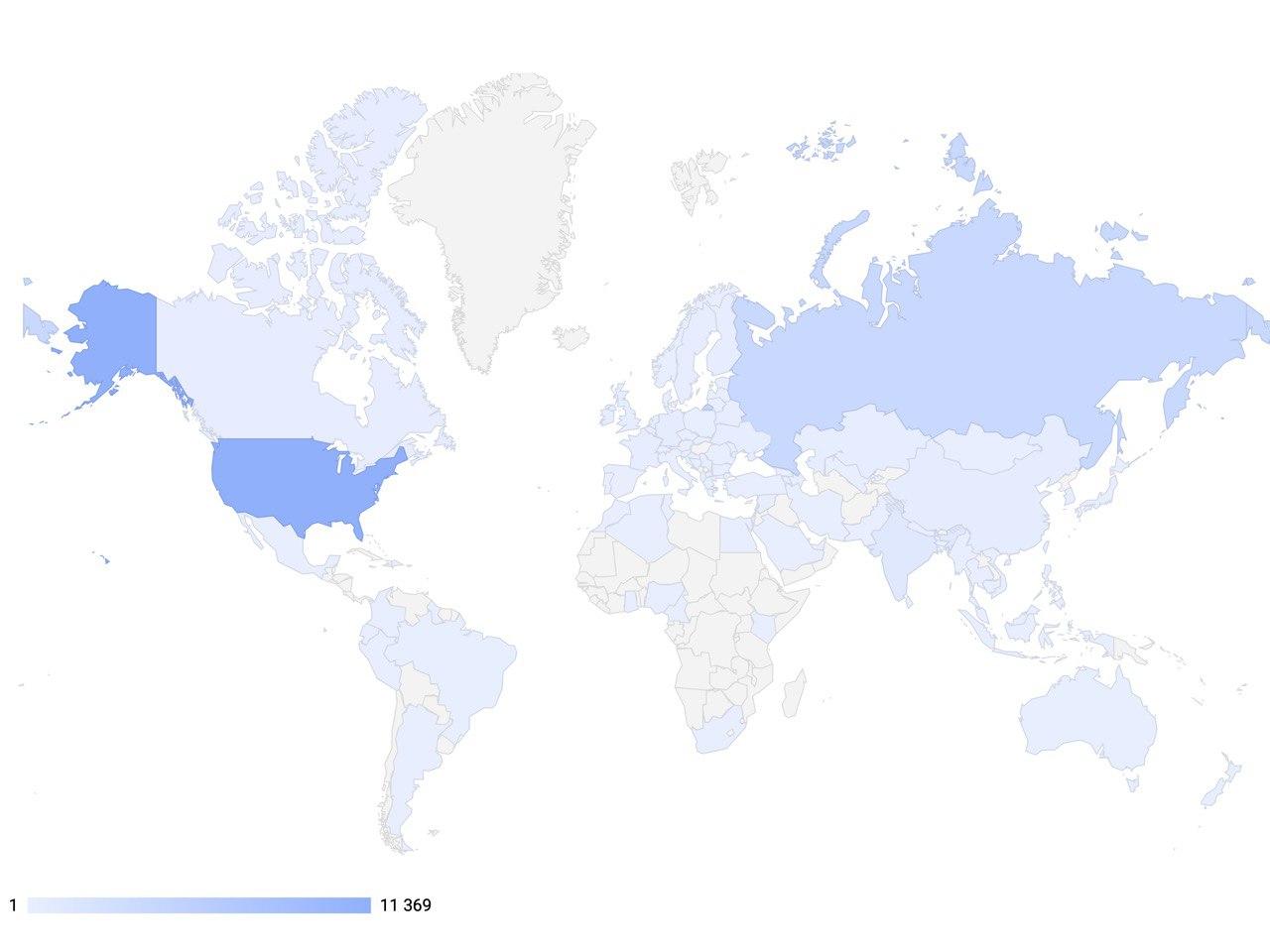
Et après?
Nous sommes heureux de partager nos succès avec vous, nous avons donc préparé un événement pour notre communauté. Nous voulons partager l'expérience et les connaissances de projets de production réels sur la façon de créer les meilleurs assistants IA. Rejoignez la réunion des utilisateurs et des développeurs de la bibliothèque ouverte DeepPavlov le 28 février pour parler de l'intelligence artificielle et de son application, ainsi que rencontrer d'autres membres de la communauté. L'événement se tiendra dans le cadre de la semaine de l' IA du 25 au 28 février. Nous attendons tous ceux qui utilisent DeepPavlov ou veulent découvrir notre technologie.Toutes les informations sur les intervenants et le programme sont disponibles sur le site, l'inscription est obligatoire pour assister à l'événement.Rejoignez: DeepPavlov 2 ans
L'industrie de l'IA continuera d'évoluer et nous pensons que DeepPavlov deviendra une technologie de pointe que chaque développeur utilisera pour comprendre le langage naturel. L'année prochaine, nous travaillerons à doubler notre communauté, à augmenter les outils open source et à améliorer la recherche sur l'apprentissage automatique. Et n'oubliez pas que DeepPavlov a un forum - posez vos questions concernant la bibliothèque et les modèles. Merci pour l'attention!