Récemment, la tâche de reconnaissance des caractères dans les programmes d'application n'est pas particulièrement difficile - vous pouvez utiliser de nombreuses bibliothèques OCR prêtes à l'emploi, dont beaucoup sont presque perfectionnées. Mais néanmoins, il peut parfois arriver que vous développiez votre propre algorithme de reconnaissance sans utiliser de bibliothèques OCR «sophistiquées» tierces.
C'est exactement la tâche qui a surgi au cours de mon travail, et il y a plusieurs raisons pour lesquelles il vaut mieux ne pas utiliser de bibliothèques prêtes à l'emploi: le projet fermé, avec sa certification supplémentaire, une certaine restriction sur le nombre de lignes de code et la taille des bibliothèques connectées, d'autant plus qu'il faut en reconnaître suffisamment dans le domaine jeu de caractères spécifique.
L'algorithme de reconnaissance est simple et, bien sûr, ne prétend pas être le plus précis, le plus rapide et le plus efficace, mais fait bien face à sa petite tâche.
Supposons que nous ayons saisi sous forme d'images numérisées de documents sous une forme structurée. Ces documents ont un code spécial à un caractère situé dans le coin supérieur gauche. Notre tâche consiste à reconnaître ce symbole puis à effectuer certaines actions, par exemple classer le document source selon les règles données.

Le diagramme d'algorithme est le suivant:
 Puisque nous savons à l'avance où se trouve notre symbole, couper une certaine zone n'est pas difficile. Afin de supprimer toutes les «irrégularités» des bords du symbole, nous traduisons l'image en monochrome (noir et blanc).
Puisque nous savons à l'avance où se trouve notre symbole, couper une certaine zone n'est pas difficile. Afin de supprimer toutes les «irrégularités» des bords du symbole, nous traduisons l'image en monochrome (noir et blanc).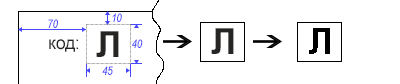
short width = 45, height = 40, offsetTop = -10, offsetLeft = -70;
BufferedImage image = ImageIO.read(file);
BufferedImage symbol = new BufferedImage(width, height, BufferedImage.TYPE_BYTE_BINARY);
Graphics2D g = symbol.createGraphics();
g.drawImage(image, offsetLeft, offsetTop, null);
Ensuite, vous devez convertir le fragment résultant «pixel par pixel» en une chaîne binaire, c'est-à-dire une chaîne où, par exemple, «*» correspond à un pixel noir et un espace au blanc.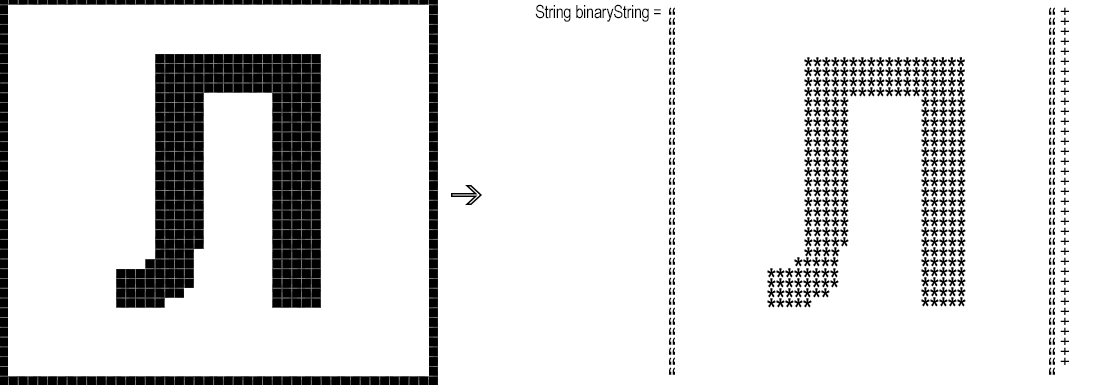
short whiteBg = -1;
StringBuilder binaryString = new StringBuilder();
for (short y = 1; y < height; y++)
for (short x = 1; x < width; x++) {
int rgb = symbol.getRGB(x, y);
binaryString.append(rgb == whiteBg ? " " : "*");
}
Ensuite, vous devez trouver la distance Levenshtein minimale entre la chaîne reçue et les chaînes de référence pré-préparées (en fait, vous pouvez prendre n'importe quelle méthode de comparaison de chaînes).int min = 1000000;
char findSymbol = "";
for (Map.Entry<Character, String> entry : originalMap.entrySet()) {
int levenshtein = levenshtein(binaryString.toString(), entry.getValue());
if (levenshtein < min) {
min = levenshtein;
findSymbol = entry.getKey();
}
}
La fonction de recherche de la distance de Levenshtein est implémentée comme une méthode selon l'algorithme standard:public static int levenshtein(String targetStr, String sourceStr) {
int m = targetStr.length(), n = sourceStr.length();
int[][] delta = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++)
delta[i][0] = i;
for (int j = 1; j <= n; j++)
delta[0][j] = j;
for (int j = 1; j <= n; j++)
for (int i = 1; i <= m; i++) {
if (targetStr.charAt(i - 1) == sourceStr.charAt(j - 1))
delta[i][j] = delta[i - 1][j - 1];
else
delta[i][j] = Math.min(delta[i - 1][j] + 1,
Math.min(delta[i][j - 1] + 1, delta[i - 1][j - 1] + 1));
}
return delta[m][n];
}
Le findSymbol résultant sera notre caractère reconnu.Cet algorithme peut être optimisé pour améliorer les performances et complété par diverses vérifications pour améliorer l'efficacité de la reconnaissance. De nombreux indicateurs dépendent du domaine spécifique du problème à résoudre (nombre de caractères, variété de polices, qualité d'image, etc.).De manière pratique, il a été constaté que la méthode résout qualitativement même les problèmes problématiques tels que la «similitude» des caractères, par exemple, «L» <-> "P", "5" <-> "S", "O" <-> "0". Puisque, par exemple, la distance entre les chaînes binaires «L» et «P» sera toujours supérieure à celle entre le «L» reconnu et la chaîne de référence «L», même avec quelques «irrégularités».En général, si vous devez résoudre un problème similaire (par exemple, la reconnaissance des cartes à jouer), avec un certain nombre de restrictions sur l'utilisation des neurones et d'autres solutions prêtes à l'emploi, vous pouvez prendre et modifier cette méthode en toute sécurité.