Dans cet article, je vais vous expliquer comment configurer un environnement d'apprentissage automatique en 30 minutes, créer un réseau neuronal pour la reconnaissance d'images, puis exécuter le même réseau sur un processeur graphique (GPU).Définissons d'abord ce qu'est un réseau neuronal.Dans notre cas, il s'agit d'un modèle mathématique, ainsi que de sa mise en œuvre logicielle ou matérielle, construit sur le principe d'organisation et de fonctionnement des réseaux neuronaux biologiques - réseaux de cellules nerveuses d'un organisme vivant. Ce concept est apparu dans l'étude des processus se produisant dans le cerveau et dans une tentative de simuler ces processus.Les réseaux de neurones ne sont pas programmés au sens habituel du terme, ils sont formés. La capacité d'apprentissage est l'un des principaux avantages des réseaux de neurones par rapport aux algorithmes traditionnels. Techniquement, l'entraînement consiste à trouver les coefficients de connexions entre les neurones. Dans le processus d'apprentissage, le réseau neuronal est capable d'identifier des relations complexes entre l'entrée et la sortie, ainsi que d'effectuer une généralisation.Du point de vue de l'apprentissage automatique, un réseau neuronal est un cas particulier des méthodes de reconnaissance de formes, d'analyse discriminante, de méthodes de clustering et d'autres méthodes.Équipement
Commençons d'abord par l'équipement. Nous avons besoin d'un serveur sur lequel le système d'exploitation Linux est installé. Les équipements pour le fonctionnement des systèmes d'apprentissage automatique nécessitent un appareil suffisamment puissant et, par conséquent, coûteux. Pour ceux qui n'ont pas une bonne voiture à portée de main, je recommande de prêter attention à l'offre des fournisseurs de cloud. Le serveur nécessaire peut être loué rapidement et ne payer que pour le temps d'utilisation.Dans les projets où il est nécessaire de créer des réseaux de neurones, j'utilise les serveurs d'un des fournisseurs de cloud russes. La société propose des serveurs cloud de location spécifiquement pour l'apprentissage automatique avec les puissantes unités de traitement graphique (GPU) Tesla V100 de NVIDIA. En bref: l'utilisation d'un serveur avec un GPU peut être des dizaines de fois plus efficace (rapide) par rapport à un serveur de même coût, où un CPU (un processeur central bien connu) est utilisé pour les calculs. Cela est dû aux spécificités de l'architecture GPU, qui gère les calculs plus rapidement.Pour effectuer les exemples décrits ci-dessous, nous avons acheté le serveur suivant pendant plusieurs jours:- SSD 150 Go
- RAM 32 Go
- Processeur Tesla V100 16 Go avec 4 cœurs
Ubuntu 18.04 a été installé sur la machine.Définissez l'environnement
Maintenant, installez sur le serveur tout ce dont vous avez besoin pour travailler. Étant donné que notre article s'adresse principalement aux débutants, j'y parlerai de quelques points qui leur seront utiles.Beaucoup de travail lors de la configuration de l'environnement se fait via la ligne de commande. La plupart des utilisateurs utilisent Windows comme système d'exploitation fonctionnel. La console standard de cet OS laisse beaucoup à désirer. Par conséquent, nous utiliserons l'outil / Cmder pratique . Téléchargez la version mini et exécutez Cmder.exe. Ensuite, vous devez vous connecter au serveur via SSH:ssh root@server-ip-or-hostname
Au lieu de server-ip-or-hostname, spécifiez l'adresse IP ou le nom DNS de votre serveur. Ensuite, entrez le mot de passe et après une connexion réussie, nous devrions obtenir quelque chose comme ça.Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)
Le langage principal pour développer des modèles ML est Python. Et la plate-forme la plus populaire pour l'utiliser sur Linux est Anaconda .Installez-le sur notre serveur.Nous commençons par mettre à jour le gestionnaire de paquets local:sudo apt-get update
Installez curl (utilitaire de ligne de commande):sudo apt-get install curl
Téléchargez la dernière version d'Anaconda Distribution:cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh
Nous commençons l'installation:bash Anaconda3-2019.10-Linux-x86_64.sh
Pendant le processus d'installation, vous devrez confirmer l'accord de licence. En cas d'installation réussie, vous devriez voir ceci:Thank you for installing Anaconda3!
Pour développer des modèles ML, de nombreux frameworks sont maintenant créés, nous travaillons avec les plus populaires: PyTorch et Tensorflow .L'utilisation du framework vous permet d'augmenter la vitesse de développement et d'utiliser des outils prêts à l'emploi pour les tâches standard.Dans cet exemple, nous travaillerons avec PyTorch. Installez-le:conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
Nous devons maintenant lancer Jupyter Notebook - un outil de développement populaire parmi les spécialistes ML. Il vous permet d'écrire du code et de voir immédiatement les résultats de son exécution. Jupyter Notebook fait partie d'Anaconda et est déjà installé sur notre serveur. Vous devez vous y connecter depuis notre système de bureau.Pour ce faire, nous exécutons d'abord Jupyter sur le serveur en spécifiant le port 8080:jupyter notebook --no-browser --port=8080 --allow-root
Ensuite, en ouvrant un autre onglet dans notre console Cmder (le menu supérieur est la boîte de dialogue Nouvelle console), connectez-vous sur le port 8080 au serveur via SSH:ssh -L 8080:localhost:8080 root@server-ip-or-hostname
Lorsque vous entrez la première commande, des liens nous seront proposés pour ouvrir Jupyter dans notre navigateur:To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Or copy and paste one of these URLs:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
or http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Utilisez le lien pour localhost: 8080. Copiez le chemin complet et collez-le dans la barre d'adresse du navigateur local de votre PC. Le bloc-notes Jupyter s'ouvre.Créons un nouvel ordinateur portable: Nouveau - Notebook - Python 3.Vérifiez le bon fonctionnement de tous les composants que nous avons installés. Nous introduisons un exemple de code PyTorch dans Jupyter et commençons l'exécution (bouton Exécuter):from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
Le résultat devrait être quelque chose comme ceci: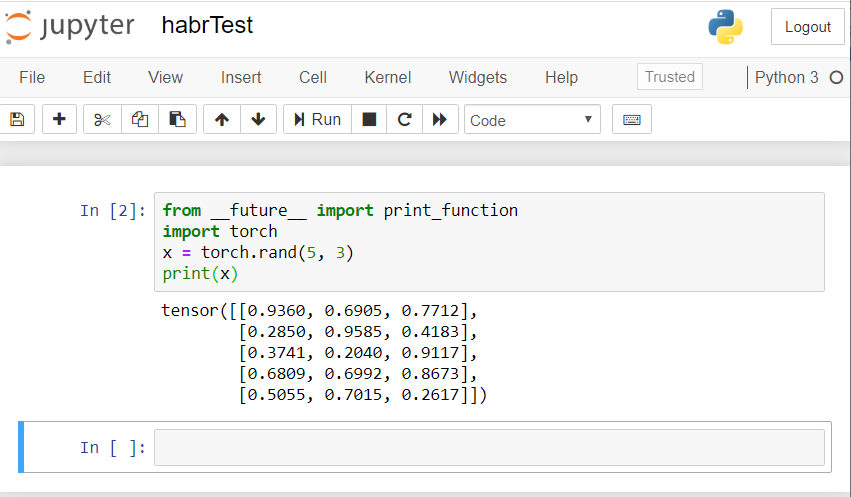 si vous avez un résultat similaire, alors nous nous sommes tous installés correctement et pouvons commencer à développer un réseau de neurones!
si vous avez un résultat similaire, alors nous nous sommes tous installés correctement et pouvons commencer à développer un réseau de neurones!Créer un réseau de neurones
Nous allons créer un réseau neuronal pour la reconnaissance d'images. Nous prenons ce guide comme base .Pour former le réseau, nous utiliserons l'ensemble de données CIFAR10 accessible au public. Il a des cours: "avion", "voiture", "oiseau", "chat", "cerf", "chien", "grenouille", "cheval", "bateau", "camion". Les images dans CIFAR10 ont une taille de 3x32x32, c'est-à-dire des images couleur à 3 canaux de 32x32 pixels.Pour le travail, nous utiliserons le package PyTorch créé pour travailler avec des images - torchvision.Nous prendrons les mesures suivantes dans l'ordre:- Téléchargez et normalisez les ensembles de données de formation et de test
- Définition du réseau neuronal
- Formation réseau sur les données de formation
- Test du réseau avec des données de test
- Répéter la formation et les tests GPU
Tout le code ci-dessous sera exécuté dans le bloc-notes Jupyter.Téléchargez et normalisez CIFAR10
Copiez et exécutez le code suivant dans Jupyter:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
La réponse devrait être comme ceci:Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
Nous allons dériver plusieurs images de formation pour vérifier:
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Définition du réseau neuronal
Examinons d'abord le fonctionnement d'un réseau de neurones pour la reconnaissance d'images. Il s'agit d'un simple réseau de connexion directe. Il prend une entrée, la passe à travers plusieurs couches une par une, puis donne finalement la sortie.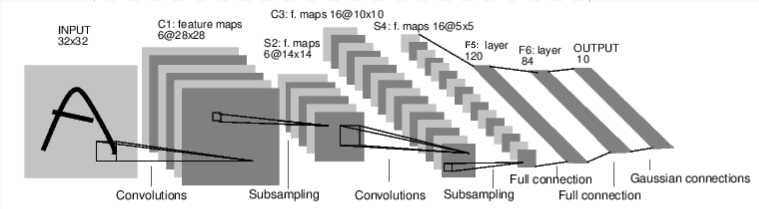 Créons un réseau similaire dans notre environnement:
Créons un réseau similaire dans notre environnement:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
Nous définissons également la fonction de perte et l'optimiseur
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Formation réseau sur les données de formation
Nous commençons à former notre réseau neuronal. J'attire votre attention sur le fait qu'après cela, pendant que vous exécutez ce code, vous devrez attendre un certain temps jusqu'à ce que le travail soit terminé. Cela m'a pris 5 minutes. Le réseautage prend du temps. for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Nous obtenons le résultat suivant: Nous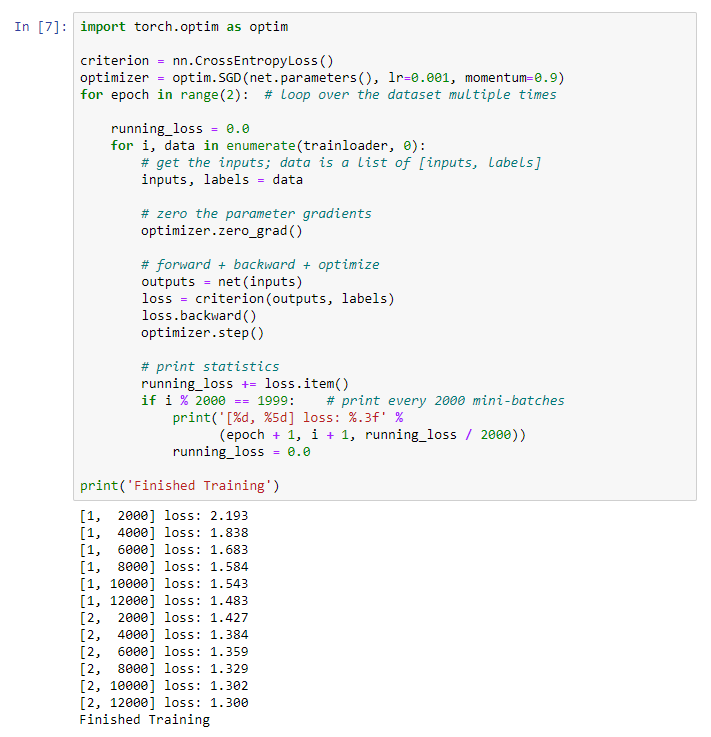 sauvegardons notre modèle formé:
sauvegardons notre modèle formé:PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
Test du réseau avec des données de test
Nous avons formé le réseau à l'aide d'un ensemble de données de formation. Mais nous devons vérifier si le réseau a appris quoi que ce soit.Nous allons vérifier cela en prédisant l'étiquette de classe que le réseau neuronal produit et en vérifiant la vérité. Si la prévision est correcte, nous ajoutons l'échantillon à la liste des prévisions correctes.Montrons l'image de la suite de tests:dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
 Maintenant, demandez au réseau neuronal de nous dire ce qu'il y a dans ces images:
Maintenant, demandez au réseau neuronal de nous dire ce qu'il y a dans ces images:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
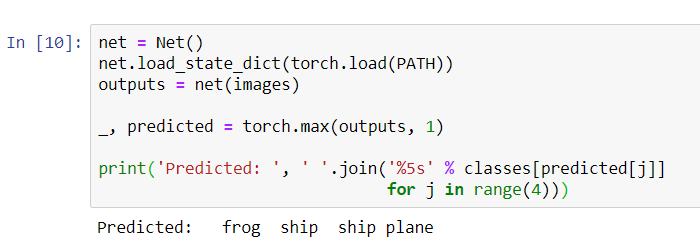 Les résultats semblent plutôt bons: le réseau a correctement identifié trois des quatre images.Voyons comment fonctionne le réseau dans l'ensemble des données.
Les résultats semblent plutôt bons: le réseau a correctement identifié trois des quatre images.Voyons comment fonctionne le réseau dans l'ensemble des données.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
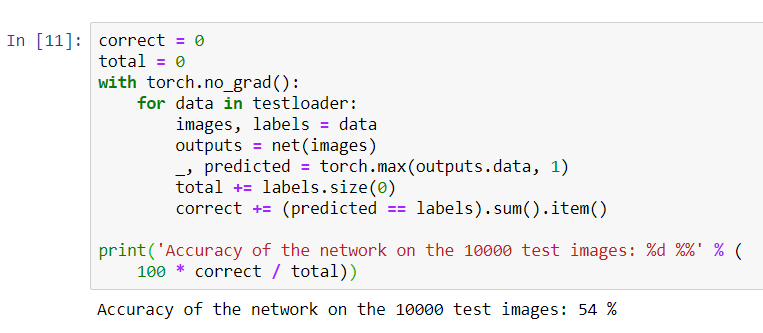 Il semble que le réseau connaisse et fonctionne. S'il définissait des classes au hasard, la précision serait de 10%.Voyons maintenant quelles classes le réseau définit mieux:
Il semble que le réseau connaisse et fonctionne. S'il définissait des classes au hasard, la précision serait de 10%.Voyons maintenant quelles classes le réseau définit mieux:class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
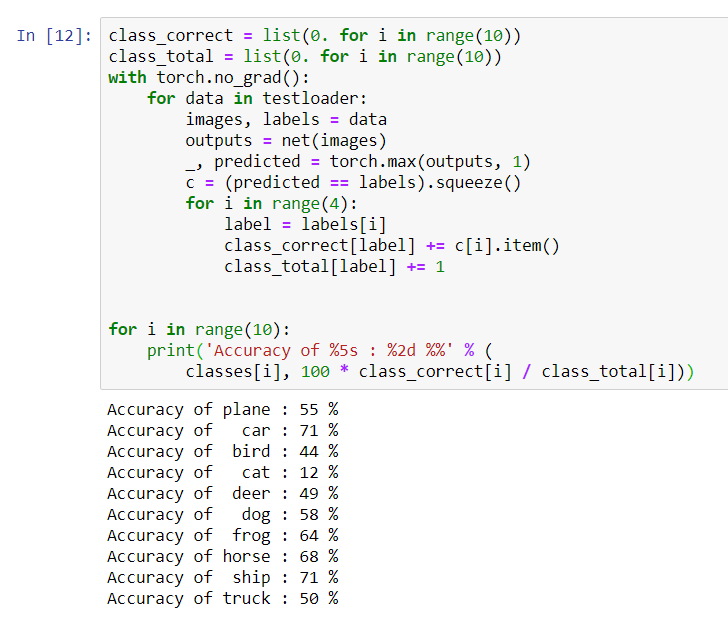 Il semble que le réseau détermine le mieux les voitures et les navires: précision de 71%.Donc, le réseau fonctionne. Essayons maintenant de transférer son travail sur le processeur graphique (GPU) et de voir quels changements.
Il semble que le réseau détermine le mieux les voitures et les navires: précision de 71%.Donc, le réseau fonctionne. Essayons maintenant de transférer son travail sur le processeur graphique (GPU) et de voir quels changements.Formation au réseau neuronal GPU
Tout d'abord, je vais expliquer brièvement ce qu'est CUDA. CUDA (Compute Unified Device Architecture) est une plate-forme informatique parallèle développée par NVIDIA pour le calcul général sur GPU. Avec CUDA, les développeurs peuvent accélérer considérablement les applications informatiques en utilisant les capacités des GPU. Sur notre serveur que nous avons acheté, cette plateforme est déjà installée.Définissons d'abord notre GPU comme le premier appareil cuda visible.device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
print ( device )
 Envoyez le réseau au GPU:
Envoyez le réseau au GPU:net.to(device)
Nous devrons également envoyer des entrées et des objectifs à chaque étape et au GPU:inputs, labels = data[0].to(device), data[1].to(device)
Exécutez le recyclage du réseau déjà sur le GPU:import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Cette fois, la formation réseau a duré environ 3 minutes. Rappelons que la même étape sur un processeur régulier a duré 5 minutes. La différence n'est pas significative, c'est parce que notre réseau n'est pas si grand. Lorsque vous utilisez de grandes baies pour la formation, la différence entre la vitesse du GPU et le processeur traditionnel augmentera.Cela semble être tout. Ce que nous avons réussi à faire:- Nous avons examiné ce qu'est le GPU et choisi le serveur sur lequel il est installé;
- Nous avons mis en place un environnement logiciel pour créer un réseau neuronal;
- Nous avons créé un réseau de neurones pour la reconnaissance d'images et l'avons formé;
- Nous avons répété la formation du réseau à l'aide du GPU et avons reçu une augmentation de vitesse.
Je me ferai un plaisir de répondre aux questions dans les commentaires.