Kafka Streams est une bibliothèque Java pour l'analyse et le traitement des données stockées dans Apache Kafka. Comme toute autre plate-forme de traitement en streaming, il est capable d'effectuer un traitement de données avec et / ou sans conservation d'état en temps réel. Dans cet article, je vais essayer de décrire pourquoi la haute disponibilité (99,99%) est problématique dans Kafka Streams et ce que nous pouvons faire pour y parvenir.Qu'est-ce qu'on a besoin de savoir
Avant de décrire le problème et les solutions possibles, regardons les concepts de base de Kafka Streams. Si vous avez travaillé avec les API Kafka pour les consommateurs / producteurs, la plupart de ces paradigmes vous sont familiers. Dans les sections suivantes, je vais essayer de décrire en quelques mots le stockage des données dans les partitions, le rééquilibrage des groupes de consommateurs et comment les concepts de base des clients Kafka s'intègrent dans la bibliothèque Kafka Streams.Kafka: Partitionnement des données
Dans le monde de Kafka, les applications de producteurs envoient des données sous forme de paires clé-valeur à un sujet spécifique. Le sujet lui-même est divisé en une ou plusieurs partitions dans les courtiers Kafka. Kafka utilise une clé de message pour indiquer dans quelle partition les données doivent être écrites. Par conséquent, les messages avec la même clé finissent toujours dans la même partition.Les applications grand public sont organisées en groupes de consommateurs, et chaque groupe peut avoir une ou plusieurs instances de consommateurs.Chaque instance d'un consommateur dans le groupe de consommateurs est responsable du traitement des données à partir d'un ensemble unique de partitions de la rubrique d'entrée.
Les instances de consommateur sont essentiellement un moyen de développer le traitement dans votre groupe de consommateurs.Kafka: Rebalancing Consumer Group
Comme nous l'avons dit précédemment, chaque instance du groupe de consommateurs reçoit un ensemble de partitions uniques à partir desquelles il consomme des données. Chaque fois qu'un nouveau consommateur rejoint un groupe, un rééquilibrage doit avoir lieu afin qu'il obtienne une partition. La même chose se produit lorsque le consommateur décède, le reste du consommateur doit prendre ses partitions pour s'assurer que toutes les partitions sont traitées.Kafka Streams: Streams
Au début de cet article, nous avons pris connaissance du fait que la bibliothèque Kafka Streams est construite sur la base des API des producteurs et des consommateurs et le traitement des données est organisé de la même manière que la solution standard sur Kafka. Dans la configuration de Kafka Streams, le champ application.id est équivalent à group.iddans l'API grand public. Kafka Streams pré-crée un certain nombre de threads et chacun d'eux effectue le traitement des données à partir d'une ou plusieurs partitions de rubriques d'entrée. S'exprimant dans la terminologie de l'API Consumer, les flux coïncident essentiellement avec les instances de Consumer du même groupe. Les threads sont le principal moyen de faire évoluer le traitement des données dans Kafka Streams, cela peut être fait verticalement en augmentant le nombre de threads pour chaque application Kafka Streams sur une machine, ou horizontalement en ajoutant une machine supplémentaire avec le même application.id.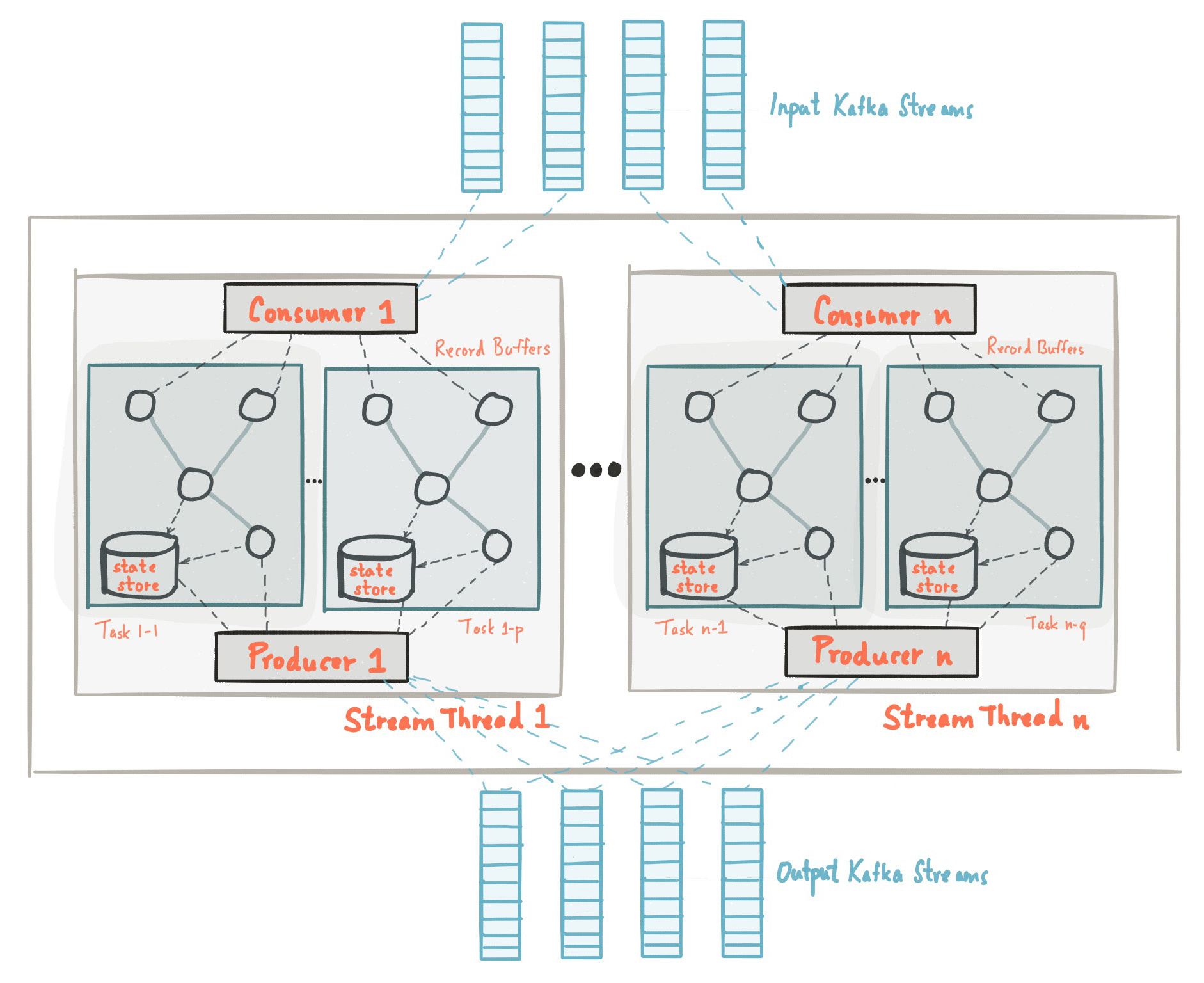 Source: kafka.apache.org/21/documentation/streams/architectureIl y a beaucoup plus d'éléments dans Kafka Streams, tels que les tâches, la topologie de traitement, le modèle de thread, etc., dont nous ne parlerons pas dans ce post. Plus d'informations peuvent être trouvées ici.
Source: kafka.apache.org/21/documentation/streams/architectureIl y a beaucoup plus d'éléments dans Kafka Streams, tels que les tâches, la topologie de traitement, le modèle de thread, etc., dont nous ne parlerons pas dans ce post. Plus d'informations peuvent être trouvées ici.Kafka Streams: Stockage d'état
Dans le traitement de flux, il existe des opérations avec et sans conservation de l'état. L'état est ce qui permet à l'application de se souvenir des informations nécessaires qui vont au-delà de la portée de l'enregistrement en cours de traitement.Les opérations d'état, telles que le comptage, tout type d'agrégation, les jointures, etc., sont beaucoup plus compliquées. Cela est dû au fait que n'ayant qu'un seul enregistrement, vous ne pouvez pas déterminer le dernier état (par exemple, le nombre) pour une clé donnée, vous devez donc stocker l'état de votre flux dans votre application. Comme nous l'avons vu précédemment, chaque thread traite un ensemble de partitions uniques; par conséquent, un thread ne traite qu'un sous-ensemble de l'ensemble de données. Cela signifie que chaque thread d'application Kafka Streams avec le même application.id conserve son propre état isolé. Nous n'entrerons pas dans les détails sur la façon dont l'état est formé dans Kafka Streams, mais il est important de comprendre que l'état est restauré à l'aide de la rubrique du journal des modifications et est enregistré non seulement sur le disque local, mais aussi dans Kafka Broker.L'enregistrement du journal des changements d'état dans Kafka Broker en tant que rubrique distincte est effectué non seulement pour la tolérance aux pannes, mais également pour que vous puissiez facilement déployer de nouvelles instances de Kafka Streams avec le même application.id. Étant donné que l'état est stocké en tant que rubrique de journal des modifications du côté du courtier, une nouvelle instance peut charger son propre état à partir de cette rubrique.Pour plus d'informations sur le stockage d'état, cliquez ici .Pourquoi la haute disponibilité pose-t-elle problème avec les flux Kafka?
Nous avons examiné les concepts et principes de base du traitement des données avec Kafka Streams. Essayons maintenant de combiner toutes les pièces ensemble et analysons pourquoi la haute disponibilité peut être problématique. Dans les sections précédentes, nous devons nous rappeler:- Les données de la rubrique Kafka sont divisées en partitions, qui sont réparties entre les flux Kafka Streams.
- Les applications Kafka Streams avec la même application.id sont, en fait, un groupe de consommateurs, et chacun de ses threads est une instance isolée distincte du consommateur.
- Pour les opérations d'état, le thread conserve son propre état, qui est «réservé» par le sujet Kafka sous la forme d'un journal des modifications.
- , Kafka , .
TransferWise SPaaS (Stream Processing as a Service)
Avant de souligner l'essence de cet article, permettez-moi d'abord de vous dire ce que nous avons créé dans TransferWise et pourquoi la haute disponibilité est très importante pour nous.Dans TransferWise, nous avons plusieurs nœuds pour le traitement en streaming, et chaque nœud contient plusieurs instances de Kafka Streams pour chaque équipe de produits. Les instances de Kafka Streams conçues pour une équipe de développement spécifique ont un application.id spécial et ont généralement plus de 5 threads. En général, les équipes ont généralement 10 à 20 threads (équivalent au nombre d'instances de consommateurs) dans le cluster. Les applications déployées sur les nœuds écoutent les rubriques d'entrée et effectuent plusieurs types d'opérations avec et sans état sur les données d'entrée et fournissent des mises à jour de données en temps réel pour les microservices en aval ultérieurs.Les équipes de produits doivent mettre à jour les données agrégées en temps réel. Cela est nécessaire pour offrir à nos clients la possibilité de transférer instantanément de l'argent. Notre SLA habituel:Chaque jour, 99,99% des données agrégées doivent être disponibles en moins de 10 secondes.
Pour vous donner une idée, pendant les tests de résistance, Kafka Streams a pu traiter et agréger 20 085 messages d'entrée par seconde. Ainsi, 10 secondes de SLA sous charge normale semblaient tout à fait réalisables. Malheureusement, notre SLA n'a pas été atteint lors de la mise à jour continue des nœuds sur lesquels les applications sont déployées, et ci-dessous, je vais expliquer pourquoi cela s'est produit.Mise à jour du nœud coulissant
Chez TransferWise, nous croyons fermement à la livraison continue de nos logiciels et publions généralement de nouvelles versions de nos services deux fois par jour. Examinons un exemple de mise à jour de service continue simple et voyons ce qui se passe pendant le processus de publication. Encore une fois, nous devons nous rappeler que:- Les données de la rubrique Kafka sont divisées en partitions, qui sont réparties entre les flux Kafka Streams.
- Les applications Kafka Streams avec la même application.id sont, en fait, un groupe de consommateurs, et chacun de ses threads est une instance isolée distincte du consommateur.
- Pour les opérations d'état, le thread conserve son propre état, qui est «réservé» par le sujet Kafka sous la forme d'un journal des modifications.
- , Kafka , .
Un processus de publication sur un seul nœud prend généralement de huit à neuf secondes. Pendant la version, les instances de Kafka Streams sur le nœud «redémarrent doucement». Ainsi, pour un seul nœud, le temps requis pour redémarrer correctement le service est d'environ huit à neuf secondes. De toute évidence, l'arrêt d'une instance de Kafka Streams sur un nœud entraîne un rééquilibrage du groupe de consommateurs. Étant donné que les données sont partitionnées, toutes les partitions qui appartenaient à l'instance amorçable doivent être réparties entre les applications Kafka Streams actives avec le même application.id. Cela s'applique également aux données agrégées qui ont été enregistrées sur le disque. Jusqu'à la fin de ce processus, les données ne seront pas traitées.Répliques de secours
Pour réduire le temps de rééquilibrage des applications Kafka Streams, il existe un concept de réplicas de sauvegarde, qui sont définis dans la configuration comme num.standby.replicas. Les réplicas de sauvegarde sont des copies du magasin d'état local. Ce mécanisme permet de répliquer le magasin d'état d'une instance de Kafka Streams à une autre. Lorsque le thread Kafka Streams meurt pour une raison quelconque, la durée du processus de récupération d'état peut être réduite. Malheureusement, pour les raisons que j'expliquerai ci-dessous, même les réplicas de sauvegarde n'aideront pas à une mise à jour continue du service.Supposons que nous ayons deux instances de Kafka Streams sur deux machines différentes: node-a et node-b. Pour chacune des instances de Kafka Streams, num.standby.replicas = 1 est indiqué sur ces 2 nœuds. Avec cette configuration, chaque instance de Kafka Streams conserve sa propre copie du référentiel sur un autre nœud. Lors d'une mise à jour continue, nous avons la situation suivante:- La nouvelle version du service a été déployée sur le nœud-a.
- L'instance Kafka Streams sur le nœud-a est désactivée.
- Le rééquilibrage a commencé.
- Le référentiel de node-a a déjà été répliqué sur node-b, car nous avons spécifié la configuration num.standby.replicas = 1.
- node-b a déjà un cliché instantané de node-a, donc le processus de rééquilibrage se déroule presque instantanément.
- node-a redémarre.
- node-a rejoint un groupe de consommateurs.
- Le courtier Kafka voit une nouvelle instance de Kafka Streams et commence le rééquilibrage.
Comme nous pouvons le voir, num.standby.replicas n'aide que dans les scénarios d'arrêt complet d'un nœud. Cela signifie que si le nœud-a tombait en panne, le nœud-b pourrait continuer à fonctionner correctement presque instantanément. Mais dans une situation de mise à jour continue, après la déconnexion, le noeud-a rejoindra le groupe, et cette dernière étape entraînera un rééquilibrage. Lorsque le nœud-a rejoint le groupe de consommateurs après un redémarrage, il sera considéré comme une nouvelle instance du consommateur. Encore une fois, nous devons nous rappeler que le traitement des données en temps réel s'arrête jusqu'à ce qu'une nouvelle instance restaure son état à partir de la rubrique du journal des modifications.Veuillez noter que le rééquilibrage des partitions lorsqu'une nouvelle instance est jointe à un groupe ne s'applique pas à l'API Kafka Streams, car c'est exactement ainsi que fonctionne le protocole du groupe de consommateurs Apache Kafka.Réalisation: haute disponibilité avec les flux Kafka
Malgré le fait que les bibliothèques clientes Kafka ne fournissent pas de fonctionnalité intégrée pour le problème mentionné ci-dessus, il existe certaines astuces qui peuvent être utilisées pour obtenir une haute disponibilité du cluster lors d'une mise à jour continue. L'idée derrière les réplicas de sauvegarde reste valide, et disposer de machines de sauvegarde au moment opportun est une bonne solution que nous utilisons pour garantir une haute disponibilité en cas de défaillance de l'instance.Le problème avec notre configuration initiale était que nous avions un groupe de consommateurs pour toutes les équipes sur tous les nœuds. Maintenant, au lieu d'un groupe de consommateurs, nous en avons deux, et le second agit comme un cluster «chaud». Dans prod, les nœuds ont une variable spéciale CLUSTER_ID, qui est ajoutée à l'application.id des instances de Kafka Streams. Voici un exemple de configuration Spring Boot application.yml:application.ymlspring.profiles: production
streaming-pipelines:
team-a-stream-app-id: "${CLUSTER_ID}-team-a-stream-app"
team-b-stream-app-id: "${CLUSTER_ID}-team-b-stream-app"
À un moment donné, un seul des clusters est en mode actif, respectivement, le cluster de sauvegarde n'envoie pas de messages en temps réel aux microservices en aval. Lors de la publication de la version, le cluster de sauvegarde devient actif, ce qui permet une mise à jour continue sur le premier cluster. Puisqu'il s'agit d'un groupe de consommateurs complètement différent, nos clients ne remarquent même aucune violation dans le traitement, et les services ultérieurs continuent de recevoir des messages du cluster récemment actif. L'un des inconvénients évidents de l'utilisation d'un groupe de sauvegarde de consommateurs est la surcharge supplémentaire et la consommation de ressources, mais, néanmoins, cette architecture offre des garanties, un contrôle et une tolérance aux pannes supplémentaires de notre système de traitement en streaming.Outre l'ajout d'un cluster supplémentaire, il existe également des astuces qui peuvent atténuer le problème avec un rééquilibrage fréquent.Augmentez group.initial.rebalance.delay.ms
À partir de Kafka 0.11.0.0, la configuration group.initial.rebalance.delay.ms a été ajoutée. Selon la documentation, ce paramètre est responsable de:Durée en millisecondes pendant laquelle GroupCoordinator retardera le rééquilibrage initial du consommateur du groupe.
Par exemple, si nous définissons 60 000 millisecondes dans ce paramètre, alors avec une mise à jour continue, nous pouvons avoir une fenêtre d'une minute pour la publication de la version. Si l'instance de Kafka Streams redémarre avec succès dans cette fenêtre de temps, aucun rééquilibrage ne sera appelé. Veuillez noter que les données dont l'instance Kafka Streams redémarrée était responsable resteront indisponibles jusqu'à ce que le nœud revienne en mode en ligne. Par exemple, si le redémarrage d'une instance prend environ huit secondes, vous disposerez de huit secondes d'indisponibilité pour les données dont cette instance est responsable.Il convient de noter que le principal inconvénient de ce concept est qu'en cas de défaillance d'un nœud, vous recevrez un délai supplémentaire d'une minute pendant la restauration, en tenant compte de la configuration actuelle.Réduction de la taille des segments dans les rubriques du journal des modifications
Le gros retard dans le rééquilibrage de Kafka Stream est dû à la restauration des magasins d'État à partir des rubriques du journal des modifications. Les rubriques du journal des modifications sont des rubriques compressées, ce qui vous permet de stocker le dernier enregistrement d'une clé particulière dans la rubrique. Je décrirai brièvement ce concept ci-dessous.Les sujets de Kafka Broker sont organisés en segments. Lorsqu'un segment atteint la taille de seuil configurée, un nouveau segment est créé et le précédent est compressé. Par défaut, ce seuil est défini sur 1 Go. Comme vous le savez probablement, la structure de données principale sous-jacente aux rubriques Kafka et à leurs partitions est la structure de journal avec une écriture en avant, c'est-à-dire que lorsque des messages sont envoyés à la rubrique, ils sont toujours ajoutés au dernier segment «actif» et la compression n'est pas passe.Par conséquent, la plupart des états de stockage stockés dans le journal des modifications se trouvent toujours dans le fichier «segment actif» et ne sont jamais compressés, ce qui entraîne des millions de messages de journal des modifications non compressés. Pour Kafka Streams, cela signifie que lors du rééquilibrage, lorsque l'instance de Kafka Streams restaure son état à partir de la rubrique du journal des modifications, elle doit lire un grand nombre d'entrées redondantes à partir de la rubrique du journal des modifications. Étant donné que les magasins d'État ne se soucient que du dernier état, et non de l'historique, ce temps de traitement est perdu. La réduction de la taille du segment entraînera une compression des données plus agressive, de sorte que les nouvelles instances d'applications Kafka Streams peuvent récupérer beaucoup plus rapidement.Conclusion
Même si Kafka Streams ne fournit pas de capacité intégrée pour fournir une haute disponibilité lors d'une mise à jour de service continue, cela peut toujours être fait au niveau de l'infrastructure. Nous devons nous rappeler que Kafka Streams n'est pas un «framework de cluster» contrairement à Apache Flink ou Apache Spark. Il s'agit d'une bibliothèque Java légère qui permet aux développeurs de créer des applications évolutives pour le streaming de données. Malgré cela, il fournit les éléments de base nécessaires pour atteindre des objectifs de streaming aussi ambitieux que la disponibilité à «99,99%».