Je rencontre régulièrement une situation où de nombreux développeurs croient sincèrement que l'index dans PostgreSQL est un couteau suisse qui aide universellement à tout problème de performance des requêtes. Il suffit d'ajouter un nouvel index à la table ou d'inclure le champ quelque part dans l'existant, puis (magie-magie!) Toutes les requêtes utiliseront cet index efficacement. Tout d'abord, bien sûr, ils ne le seront pas, ou pas efficacement, ou pas tous. Deuxièmement, les index supplémentaires ajouteront uniquement des problèmes de performances lors de l'écriture.Le plus souvent, de telles situations se produisent pendant le développement «à longue durée de jeu», lorsqu'un produit personnalisé n'est pas fabriqué selon le modèle «écrit une fois, donné, oublié», mais, comme dans notre cas, est crééservice avec un long cycle de vie .Les améliorations se produisent de manière itérative par les forces de nombreuses équipes réparties , qui sont réparties non seulement dans l'espace mais aussi dans le temps. Et puis, ne connaissant pas toute l'histoire du développement du projet ou les caractéristiques de la distribution appliquée des données dans sa base de données, vous pouvez facilement "gâcher" les indices. Mais les considérations et les demandes de test sous la coupe vous permettent de prévoir et de détecter une partie des problèmes à l'avance:
Tout d'abord, bien sûr, ils ne le seront pas, ou pas efficacement, ou pas tous. Deuxièmement, les index supplémentaires ajouteront uniquement des problèmes de performances lors de l'écriture.Le plus souvent, de telles situations se produisent pendant le développement «à longue durée de jeu», lorsqu'un produit personnalisé n'est pas fabriqué selon le modèle «écrit une fois, donné, oublié», mais, comme dans notre cas, est crééservice avec un long cycle de vie .Les améliorations se produisent de manière itérative par les forces de nombreuses équipes réparties , qui sont réparties non seulement dans l'espace mais aussi dans le temps. Et puis, ne connaissant pas toute l'histoire du développement du projet ou les caractéristiques de la distribution appliquée des données dans sa base de données, vous pouvez facilement "gâcher" les indices. Mais les considérations et les demandes de test sous la coupe vous permettent de prévoir et de détecter une partie des problèmes à l'avance:- index inutilisés
- préfixe "clones"
- horodatage «au milieu»
- booléen indexable
- tableaux dans l'index
- Corbeille nulle
Le plus simple est de trouver des indices pour lesquels il n'y a pas eu de passes du tout . Il vous suffit de vous assurer que la réinitialisation des statistiques ( pg_stat_reset()) s'est produite il y a longtemps et vous ne souhaitez pas supprimer celui utilisé «rarement, mais avec justesse». Nous utilisons la vue système pg_stat_user_indexes:SELECT * FROM pg_stat_user_indexes WHERE idx_scan = 0;
Mais même si l'index est utilisé et ne tombe pas dans cette sélection, cela ne signifie pas du tout qu'il est bien adapté à vos requêtes.Quels indices ne conviennent pas
Afin de comprendre pourquoi certaines requêtes «vont mal sur l'index», nous allons réfléchir à la structure d'un index btree normal , l'instance la plus fréquente dans la nature. Les indices d'un seul champ ne posent généralement aucun problème, par conséquent, nous considérons les problèmes qui se posent sur un composite d'une paire de champs.Une manière extrêmement simplifiée, comme on peut l'imaginer, est un «gâteau en couches», où dans chaque couche il y a des arbres ordonnés selon les valeurs du champ correspondant dans l'ordre.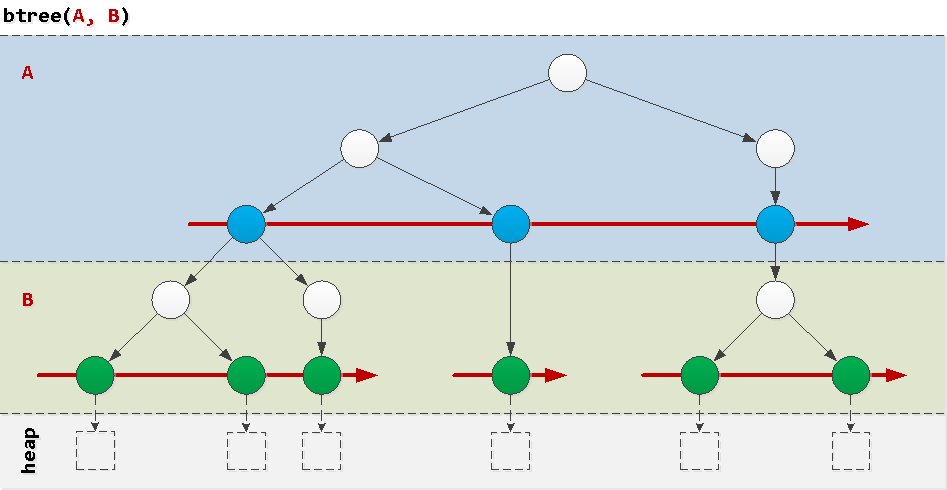 Maintenant , il est clair que le champ A l' échelle mondiale a ordonné, et B - que dans une valeur spécifique A . Examinons des exemples de conditions qui se produisent dans des requêtes réelles et comment elles "parcourent" l'index.
Maintenant , il est clair que le champ A l' échelle mondiale a ordonné, et B - que dans une valeur spécifique A . Examinons des exemples de conditions qui se produisent dans des requêtes réelles et comment elles "parcourent" l'index.Bon: état du préfixe
Notez que l'index btree(A, B)comprend un «sous-index» btree(A). Cela signifie que toutes les règles décrites ci-dessous fonctionneront pour tout index de préfixe.Autrement dit, si vous créez un index plus complexe que dans notre exemple, quelque chose du type btree(A, B, C)- vous pouvez supposer que votre base de données "apparaît" automatiquement:btree(A, B, C)btree(A, B)btree(A)
Et cela signifie que la présence «physique» de l'index des préfixes dans la base de données est redondante dans la plupart des cas. Après tout, plus une table doit écrire d'index - pire c'est pour PostgreSQL, car elle appelle Write Amplification - Uber s'en plaignait (et ici vous pouvez trouver une analyse de leurs revendications ).Et si quelque chose empêche la base de bien vivre, cela vaut la peine de la trouver et de l'éliminer. Regardons un exemple:CREATE TABLE tbl(A integer, B integer, val integer);
CREATE INDEX ON tbl(A, B)
WHERE val IS NULL;
CREATE INDEX ON tbl(A)
WHERE val IS NULL;
CREATE INDEX ON tbl(A, B, val);
CREATE INDEX ON tbl(A);
Requête de recherche d'index de préfixeWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid AND
idx.indexprs IS NULL
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, pre AS (
SELECT
nmt
, wh
, nmf$
, tpf$
, nmi
, def
FROM
fld
ORDER BY
1, 2, 3
)
SELECT DISTINCT
Y.*
FROM
pre X
JOIN
pre Y
ON Y.nmi <> X.nmi AND
(Y.nmt, Y.wh) IS NOT DISTINCT FROM (X.nmt, X.wh) AND
(
Y.nmf$[1:array_length(X.nmf$, 1)] = X.nmf$ OR
X.nmf$[1:array_length(Y.nmf$, 1)] = Y.nmf$
)
ORDER BY
1, 2, 3;
Idéalement, vous devriez obtenir une sélection vide, mais regardez - ce sont nos groupes d'index suspects:nmt | wh | nmf$ | tpf$ | nmi | def
---------------------------------------------------------------------------------------
tbl | (val IS NULL) | {a} | {int4} | tbl_a_idx | CREATE INDEX ...
tbl | (val IS NULL) | {a,b} | {int4,int4} | tbl_a_b_idx | CREATE INDEX ...
tbl | | {a} | {int4} | tbl_a_idx1 | CREATE INDEX ...
tbl | | {a,b,val} | {int4,int4,int4} | tbl_a_b_val_idx | CREATE INDEX ...
Ensuite, vous décidez vous-même pour chaque groupe s'il valait la peine de supprimer l'index le plus court ou le plus long n'était pas nécessaire du tout.Bon: toutes les constantes sauf le dernier champ
Si les valeurs de tous les champs de l'index, à l'exception du dernier, sont définies par des constantes (dans notre exemple, il s'agit du champ A), l'index peut être utilisé normalement. Dans ce cas, la valeur du dernier champ peut être définie arbitrairement: constante, inégalité, intervalle, numérotation via IN (...)ou = ANY(...). Et il peut également être trié par celui-ci.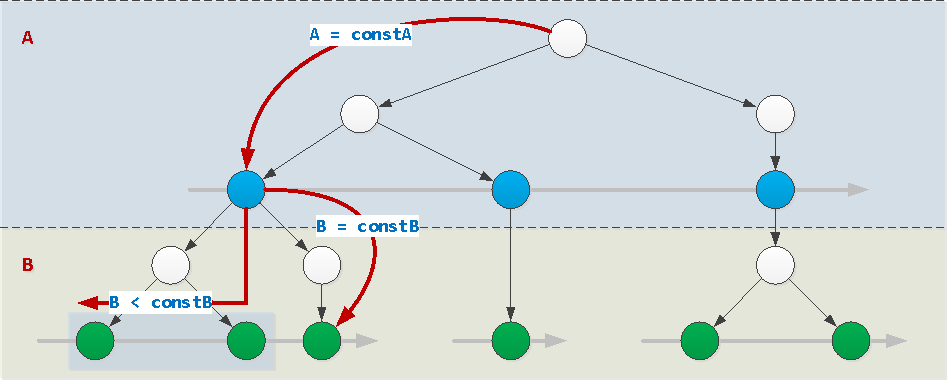
WHERE A = constA AND B [op] constB / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A = constA AND B BETWEEN constB1 AND constB2WHERE A = constA ORDER BY B
Sur la base des index de préfixes décrits ci-dessus, cela fonctionnera bien:WHERE A [op] const / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A BETWEEN const1 AND const2ORDER BY AWHERE (A, B) [op] (constA, constB) / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }ORDER BY A, B
Mauvais: énumération complète de la "couche"
Avec une partie des requêtes, la seule énumération du mouvement dans l'index devient une énumération complète de toutes les valeurs dans l'une des «couches». Il y a de la chance s'il existe une unité de telles valeurs - et s'il y en a des milliers?.Habituellement, un tel problème se produit si une inégalité est utilisée dans la requête , la condition ne détermine pas les champs qui sont précédents dans l'ordre d'index ou cet ordre est violé pendant le tri.WHERE A <> constWHERE B [op] const / = ANY(...) / IN (...)ORDER BY BORDER BY B, A
Mauvais: l'intervalle ou l'ensemble n'est pas dans le dernier champ
En conséquence de la précédente - si vous devez trouver plusieurs valeurs ou leur plage sur une «couche» intermédiaire, puis filtrer ou trier par les champs situés «plus profondément» dans l'index, il y aura des problèmes si le nombre de valeurs uniques «au milieu» de l'index est génial.WHERE A BETWEEN constA1 AND constA2 AND B BETWEEN constB1 AND constB2WHERE A = ANY(...) AND B = constWHERE A = ANY(...) ORDER BY BWHERE A = ANY(...) AND B = ANY(...)
Mauvais: expression au lieu du champ
Parfois, un développeur transforme inconsciemment une colonne d'une requête en autre chose - en une expression pour laquelle il n'y a pas d'index. Cela peut être résolu en créant un index à partir de l'expression souhaitée ou en effectuant la transformation inverse:WHERE A - const1 [op] const2
réparer: WHERE A [op] const1 + const2WHERE A::typeOfConst = const
réparer: WHERE A = const::typeOfA
Nous prenons en compte la cardinalité des champs
Supposons que vous avez besoin d' un index (A, B), et que vous voulez choisir uniquement par l' égalité : (A, B) = (constA, constB). L'utilisation d'un index de hachage serait idéale , mais ... En plus de la non-journalisation (wal logging) de ces index jusqu'à la version 10, ils ne peuvent pas non plus exister sur plusieurs champs:CREATE INDEX ON tbl USING hash(A, B);
En général, vous avez choisi btree. Alors, quelle est la meilleure façon d'organiser les colonnes en elle - (A, B)ou (B, A)? Pour répondre à cette question, il est nécessaire de prendre en compte un paramètre tel que la cardinalité des données dans la colonne correspondante - c'est-à-dire le nombre de valeurs uniques qu'il contient.Imaginons cela A = {1,2}, B = {1,2,3,4}et dessinons un contour de l'arborescence d'index pour les deux options: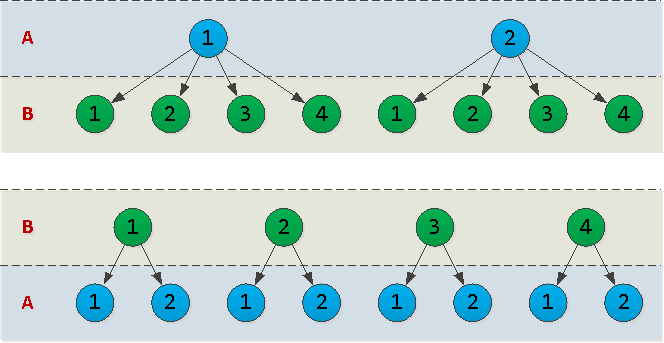 En fait, chaque nœud de l'arborescence que nous dessinons est une page de l'index. Et plus il y en a, plus l'espace disque sera occupé par l'index, plus il faudra de temps pour y lire.Dans notre exemple, l'option
En fait, chaque nœud de l'arborescence que nous dessinons est une page de l'index. Et plus il y en a, plus l'espace disque sera occupé par l'index, plus il faudra de temps pour y lire.Dans notre exemple, l'option (A, B)a 10 nœuds et (B, A)- 12. Autrement dit, il est plus rentable de mettre les "champs" avec le moins de valeurs uniques possible "en premier" .Mauvais: beaucoup et hors de propos (horodatage "au milieu")
Exactement pour cette raison, cela semble toujours suspect si un champ avec une variabilité manifestement importante comme l' horodatage [tz] n'est pas le dernier de votre index . En règle générale, les valeurs du champ d'horodatage augmentent de façon monotone et les champs d'index suivants n'ont qu'une seule valeur à chaque instant.CREATE TABLE tbl(A integer, B timestamp);
CREATE INDEX ON tbl(A, B);
CREATE INDEX ON tbl(B, A);

Requête de recherche d'index d'horodatage [tz] non finalWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
'timestamp' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamptz' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamp' = ANY(opc$[1:array_length(opc$, 1) - 1]) OR
'timestamptz' = ANY(opc$[1:array_length(opc$, 1) - 1])
ORDER BY
1, 2;
Ici, nous analysons immédiatement à la fois les types des champs d'entrée eux-mêmes et les classes d'opérateurs qui leur sont appliquées - car certaines fonctions timestamptz comme date_trunc peuvent se révéler être un champ d'index.nmt | nmi | def | nmf$ | tpf$ | opc$
----------------------------------------------------------------------------------
tbl | tbl_b_a_idx | CREATE INDEX ... | {b,a} | {timestamp,int4} | {timestamp,int4}
Mauvais: trop peu (booléen)
De l'autre côté de la même pièce, cela devient une situation où l'indice est booléen-champ , qui ne peut prendre que 3 valeurs NULL, FALSE, TRUE. Bien sûr, sa présence a un sens si vous souhaitez l'utiliser pour le tri appliqué - par exemple, en les désignant comme le type de nœud dans la hiérarchie arborescente - que ce soit un dossier ou une feuille («les dossiers d'abord»).CREATE TABLE tbl(
id
serial
PRIMARY KEY
, leaf_pid
integer
, leaf_type
boolean
, public
boolean
);
CREATE INDEX ON tbl(leaf_pid, leaf_type);
CREATE INDEX ON tbl(public, id);
Mais, dans la plupart des cas, ce n'est pas le cas et les demandes sont accompagnées d'une valeur spécifique du champ booléen. Et puis il devient possible de remplacer l'index par ce champ par sa version conditionnelle:CREATE INDEX ON tbl(id) WHERE public;
Requête de recherche booléenne dans les indexWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
(
'bool' = ANY(tpf$) OR
'bool' = ANY(opc$)
) AND
NOT(
ARRAY(
SELECT
nmf$[i:i+1]::text
FROM
generate_series(1, array_length(nmf$, 1) - 1) i
) &&
ARRAY[
'{leaf_pid,leaf_type}'
]
)
ORDER BY
1, 2;
nmt | nmi | def | nmf$ | tpf$ | opc$
------------------------------------------------------------------------------------
tbl | tbl_public_id_idx | CREATE INDEX ... | {public,id} | {bool,int4} | {bool,int4}
Tableaux dans btree
Un autre point est la tentative "d'indexer le tableau" en utilisant l'index btree. Ceci est tout à fait possible car les opérateurs correspondants s'appliquent à eux :(<, >, = . .) , B-, , . ( ). , , .
Mais le problème est que d'utiliser quelque chose qu'il veut opérateurs d'inclusion et d' intersection : <@, @>, &&. Bien sûr, cela ne fonctionne pas - car ils ont besoin d' autres types d'index . Comment un tel btree ne fonctionne pas pour la fonction d'accéder à un élément spécifique arr[i].On apprend à trouver de tels:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, pid
integer
, list
integer[]
);
CREATE INDEX ON tbl(pid);
CREATE INDEX ON tbl(list);
Recherche de tableau dans btreeWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid AND
cli.relam = (
SELECT
oid
FROM
pg_am
WHERE
amname = 'btree'
LIMIT 1
)
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, nmf$
, tpf$
, def
FROM
fld
WHERE
tpf$ && ARRAY(
SELECT
typname
FROM
pg_type
WHERE
typname ~ '^_'
)
ORDER BY
1, 2;
nmt | nmi | nmf$ | tpf$ | def
--------------------------------------------------------
tbl | tbl_list_idx | {list} | {_int4} | CREATE INDEX ...
Entrées d'index NULL
Le dernier problème assez courant est de «salir» l'index avec des entrées complètement NULL. C'est-à-dire, enregistre où l'expression indexée dans chacune des colonnes est NULL . De tels enregistrements n'ont aucun avantage pratique, mais ils ajoutent du mal à chaque insert.Ils apparaissent généralement lorsque vous créez un champ FK ou une relation de valeur avec un remplissage facultatif dans le tableau. Ensuite, lancez l'index pour que FK fonctionne rapidement ... et les voici. Moins la connexion sera remplie, plus les «déchets» tomberont dans l'index. Nous simulerons:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, fk
integer
);
CREATE INDEX ON tbl(fk);
INSERT INTO tbl(fk)
SELECT
CASE WHEN i % 10 = 0 THEN i END
FROM
generate_series(1, 1000000) i;
Dans la plupart des cas, un tel index peut être converti en index conditionnel, ce qui prend également moins:CREATE INDEX ON tbl(fk) WHERE (fk) IS NOT NULL;
_tmp=# \di+ tbl*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------+-------+----------+----------+---------+-------------
public | tbl_fk_idx | index | postgres | tbl | 36 MB |
public | tbl_fk_idx1 | index | postgres | tbl | 2208 kB |
public | tbl_pkey | index | postgres | tbl | 21 MB |
Pour trouver de tels index, nous devons connaître la distribution réelle des données - c'est-à-dire, après tout, lire tout le contenu des tableaux et les superposer en fonction des conditions WHERE de l'occurrence (nous le ferons en utilisant dblink ), ce qui peut prendre très longtemps .Requête de recherche pour les entrées NULL dans les indexWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisprimary AND
idx.indisready AND
idx.indisvalid AND
NOT EXISTS(
SELECT
NULL
FROM
pg_constraint
WHERE
conindid = cli.oid
LIMIT 1
) AND
pg_relation_size(cli.oid) > 1 << 20
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, regexp_replace(
CASE
WHEN def ~ ' USING btree ' THEN
regexp_replace(def, E'.* USING btree (.*?)($| WHERE .*)', E'\\1')
END
, E' ([a-z]*_pattern_ops|(ASC|DESC)|NULLS\\s?(?:FIRST|LAST))'
, ''
, 'ig'
) fld
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, q AS (
SELECT
nmt
, $q$
SET search_path = $q$ || quote_ident((TABLE sch)) || $q$, public;
SELECT
ARRAY[
count(*)
$q$ || string_agg(
', coalesce(sum((' || coalesce(wh, 'TRUE') || ')::integer), 0)' || E'\n' ||
', coalesce(sum(((' || coalesce(wh, 'TRUE') || ') AND (' || fld || ' IS NULL))::integer), 0)' || E'\n'
, '' ORDER BY nmi) || $q$
]
FROM
$q$ || quote_ident((TABLE sch)) || $q$.$q$ || quote_ident(nmt) || $q$
$q$ q
, array_agg(clioid ORDER BY nmi) oid$
, array_agg(nmi ORDER BY nmi) idx$
, array_agg(fld ORDER BY nmi) fld$
, array_agg(wh ORDER BY nmi) wh$
FROM
fld
WHERE
fld IS NOT NULL
GROUP BY
1
ORDER BY
1
)
, res AS (
SELECT
*
, (
SELECT
qty
FROM
dblink(
'dbname=' || current_database() || ' port=' || current_setting('port')
, q
) T(qty bigint[])
) qty
FROM
q
)
, iter AS (
SELECT
*
, generate_subscripts(idx$, 1) i
FROM
res
)
, stat AS (
SELECT
nmt table_name
, idx$[i] index_name
, pg_relation_size(oid$[i]) index_size
, pg_size_pretty(pg_relation_size(oid$[i])) index_size_humanize
, regexp_replace(fld$[i], E'^\\((.*)\\)$', E'\\1') index_fields
, regexp_replace(wh$[i], E'^\\((.*)\\)$', E'\\1') index_cond
, qty[1] table_rec_count
, qty[i * 2] index_rec_count
, qty[i * 2 + 1] index_rec_count_null
FROM
iter
)
SELECT
*
, CASE
WHEN table_rec_count > 0
THEN index_rec_count::double precision / table_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_cover_prc
, CASE
WHEN index_rec_count > 0
THEN index_rec_count_null::double precision / index_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_null_prc
FROM
stat
WHERE
index_rec_count_null * 4 > index_rec_count
ORDER BY
1, 2;
-[ RECORD 1 ]--------+--------------
table_name | tbl
index_name | tbl_fk_idx
index_size | 37838848
index_size_humanize | 36 MB
index_fields | fk
index_cond |
table_rec_count | 1000000
index_rec_count | 1000000
index_rec_count_null | 900000
index_cover_prc | 100.00 -- 100%
index_null_prc | 90.00 -- 90% NULL-""
J'espère que certaines des requêtes de cet article vous aideront.