Il y a quelques semaines lors d'une conversation au cours du dîner, un collègue s'est plaint d'une sorte de lenteur. Il a calculé le nombre d'octets générés, le nombre de cycles de traitement et, finalement, la quantité de RAM. Un collègue a déclaré qu'un GPU moderne avec une bande passante mémoire de plus de 500 Go / s mangerait sa tâche et ne s'étoufferait pas.Il me semble que c'est une approche intéressante. Personnellement, je n'ai pas évalué auparavant les objectifs de performance dans cette perspective. Oui, je connais la différence de performances du processeur et de la mémoire. Je sais écrire du code qui fait un usage intensif du cache. Je connais les chiffres approximatifs des retards. Mais cela ne suffit pas pour évaluer immédiatement la bande passante mémoire.Voici une expérience de pensée. Imaginez en mémoire un tableau continu d'un milliard d'entiers 32 bits. C'est 4 gigaoctets. Combien de temps faut-il pour parcourir ce tableau et additionner les valeurs? Combien d'octets par seconde le CPU peut-il lire à partir de la RAM? Des données continues? Accès aléatoire? Dans quelle mesure ce processus peut-il être parallélisé?Vous direz que ce sont des questions inutiles. Les vrais programmes sont trop complexes pour faire un point de repère aussi naïf. Et voici! La vraie réponse est «en fonction de la situation».Cependant, je pense que cette question mérite d'être explorée. Je n'essaie pas de trouver la réponse . Mais je pense que nous pouvons définir des limites supérieures et inférieures, des points intéressants au milieu et apprendre quelque chose dans le processus.
Je sais écrire du code qui fait un usage intensif du cache. Je connais les chiffres approximatifs des retards. Mais cela ne suffit pas pour évaluer immédiatement la bande passante mémoire.Voici une expérience de pensée. Imaginez en mémoire un tableau continu d'un milliard d'entiers 32 bits. C'est 4 gigaoctets. Combien de temps faut-il pour parcourir ce tableau et additionner les valeurs? Combien d'octets par seconde le CPU peut-il lire à partir de la RAM? Des données continues? Accès aléatoire? Dans quelle mesure ce processus peut-il être parallélisé?Vous direz que ce sont des questions inutiles. Les vrais programmes sont trop complexes pour faire un point de repère aussi naïf. Et voici! La vraie réponse est «en fonction de la situation».Cependant, je pense que cette question mérite d'être explorée. Je n'essaie pas de trouver la réponse . Mais je pense que nous pouvons définir des limites supérieures et inférieures, des points intéressants au milieu et apprendre quelque chose dans le processus.Les chiffres que chaque programmeur doit connaître
Si vous lisez des blogs de programmation, vous êtes probablement tombé sur des «chiffres que chaque programmeur devrait connaître». Ils ressemblent à ceci:Lien vers le cache L1 0,5 ns
Prédiction 5 ns incorrecte
Lien vers le cache L2 7 ns 14x vers le cache L1
Mutex Capture / Release 25 ns
Lien vers la mémoire principale 100 ns 20x vers le cache L2, 200x vers le cache L1
Compressez 1000 octets avec Zippy 3000 ns 3 μs
Envoi de 1000 octets sur un réseau à 1 Gbit / s 10000 ns 10 μs
Lecture aléatoire 4000 avec SSD 150 000 ns 150 μs ~ 1 Go / s SSD
Lecture séquentielle de 1 Mo à partir de 250 000 ns 250 μs
Paquet aller-retour à l'intérieur du centre de données 500 000 ns 500 μs
1 Mo de lecture séquentielle dans le SSD 1.000.000 ns 1.000 μs 1 ms ~ 1 Go / s SSD, 4x mémoire
Recherche de disque 10000000 ns 10000 μs 10 ms 20x vers le centre de données
Lecture séquentielle de 1 Mo à partir du disque 20 000 000 ns 20 000 μs 20 ms 80x vers la mémoire, 20x vers SSD
Envoi de colis CA-> Pays-Bas-> CA 150,000,000 ns 150,000 μs 150 ms
Source: Jonas BonerGrande liste. Il apparaît sur HackerNews au moins une fois par an. Chaque programmeur devrait connaître ces chiffres.Mais ces chiffres concernent autre chose. La latence et la bande passante ne sont pas la même chose.Retard en 2020
Cette liste a été compilée en 2012, et cet article de 2020, les temps ont changé. Voici les chiffres pour Intel i7 avec StackOverflow .Frappé dans le cache L1, ~ 4 cycles (2.1 - 1.2 ns)
Frappé dans le cache L2, ~ 10 cycles (5,3 - 3,0 ns)
Frappez dans le cache L3, pour un seul cœur ~ 40 cycles (21,4 - 12,0 ns)
Frappez dans le cache L3, ensemble pour un autre noyau ~ 65 cycles (34,8 - 19,5 ns)
Frappez le cache L3, avec un changement pour un autre noyau ~ 75 cycles (40,2 - 22,5 ns)
RAM locale ~ 60 ns
Intéressant! Qu'est ce qui a changé?- L1 est devenu plus lent;
0,5 → 1,5
- L2 plus rapide;
7 → 4,2
- Le rapport de L1 et L2 est très réduit;
2,5x 14(sensationnel!)
- Le cache L3 est désormais devenu la norme;
12 40
- La RAM est devenue plus rapide;
100 → 60
Nous ne tirerons pas de conclusions de grande portée. On ne sait pas comment les nombres originaux ont été calculés. Nous ne comparerons pas les pommes avec les oranges.Voici quelques chiffres de wikichip sur la bande passante et la taille du cache de mon processeur.Bande passante mémoire: 39,74 gigaoctets par seconde
Cache L1: 192 kilo-octets (32 Ko par cœur)
Cache L2: 1,5 mégaoctets (256 Ko par cœur)
Cache L3: 12 mégaoctets (partagé; 2 Mo par cœur)
Ce que je veux savoir:- Limite supérieure des performances de la RAM
- limite inférieure
- Limites du cache L1 / L2 / L3
Analyse comparative naïve
Faisons quelques tests. Pour mesurer la bande passante, j'ai écrit un simple programme C ++. Très approximativement, elle ressemble à ceci.
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i)
nums.push_back(rng() % 1024);
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
for (size_t thread = 0; thread < thread_count; ++thread) {
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
futures.push_back(std::async([begin, end] {
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}
Certains détails sont omis. Mais vous avez compris l'idée. Créez un large éventail continu d'éléments. Divisez le tableau en fragments séparés. Traitez chaque fragment dans un thread séparé. Accumulez les résultats.Vous devez également mesurer l'accès aléatoire. C'est très difficile. J'ai essayé plusieurs façons, j'ai finalement décidé de mélanger des index pré-calculés. Chaque index existe exactement une fois. Ensuite, la boucle interne parcourt les indices et calcule sum += nums[index].std::vector<int> nums = ;
std::vector<uint32_t> indices = ;
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;
Dans le calcul du débit, je ne considère pas la mémoire du tableau d'index. Seuls les octets qui contribuent au total sont comptés sum. Je ne compare pas mon matériel, mais j'évalue la capacité de travailler avec des ensembles de données de différentes tailles et avec différents schémas d'accès.Nous effectuerons des tests avec trois types de données:int- l'entier principal 32 bitsmatri4x4- contient int[16]; tient dans une ligne de cache de 64 octetsmatrix4x4_simd- utilise des outils intégrés__m256iGros bloc
Mon premier test fonctionne avec un gros bloc de mémoire. Un bloc d' Néléments de 1 Go est mis en surbrillance et rempli de petites valeurs aléatoires. Une boucle simple itère sur un tableau N fois, donc elle accède à la mémoire avec un volume N pour calculer la somme int64_t. Plusieurs threads divisent le tableau et chacun accède au même nombre d'éléments.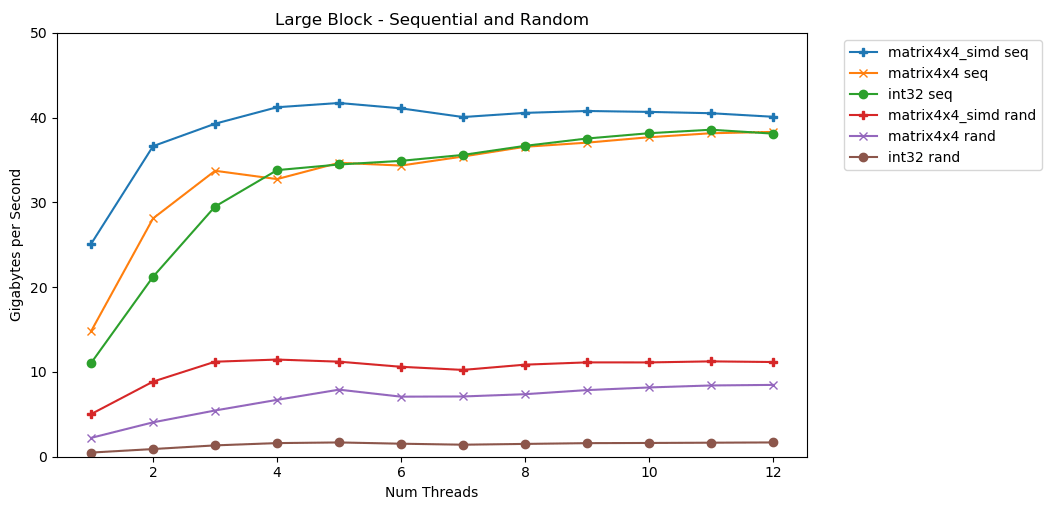 Et voilà! Dans ce graphique, nous prenons le temps d'exécution moyen de l'opération de sommation et le convertissons de
Et voilà! Dans ce graphique, nous prenons le temps d'exécution moyen de l'opération de sommation et le convertissons de runtime_in_nanosecondsà gigabytes_per_second.Très bon résultat. int32peut lire séquentiellement 11 Go / s en un seul flux. Il évolue linéairement jusqu'à atteindre 38 Go / s. Des tests matrix4x4et matrix4x4_simdplus rapides, mais reposent contre le même plafond.Il y a un plafond clair et évident sur la quantité de données que nous pouvons lire à partir de la RAM par seconde. Sur mon système, cela représente environ 40 Go / s. Ceci est conforme aux spécifications actuelles énumérées ci-dessus.À en juger par les trois derniers graphiques, l'accès aléatoire est lent. Très, très lent. Les performances sur int32un seul thread sont négligeables de 0,46 Go / s. C'est 24 fois plus lent que l'empilement séquentiel à 11,03 Go / s! Le test matrix4x4montre le meilleur résultat, car il s'exécute sur des lignes de cache complètes. Mais il est toujours quatre à sept fois plus lent que l'accès séquentiel et culmine à seulement 8 Go / s.Petit bloc: lecture séquentielle
Sur mon système, la taille du cache L1 / L2 / L3 pour chaque flux est de 32 Ko, 256 Ko et 2 Mo. Que se passe-t-il si vous prenez un bloc d'éléments de 32 kilo-octets et que vous le répétez 125 000 fois? Il s'agit de 4 Go de mémoire, mais nous irons toujours dans le cache.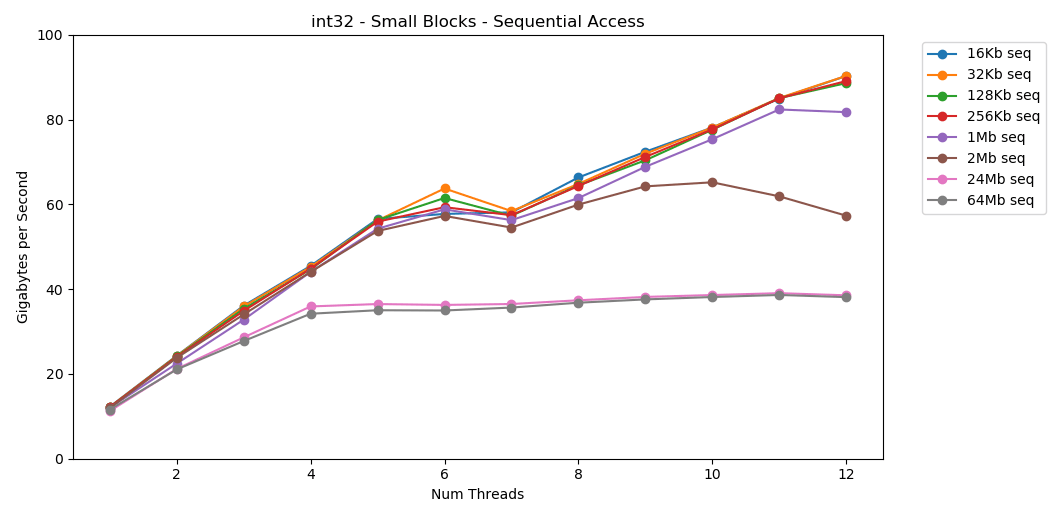 Impressionnant! Les performances monothread sont similaires à la lecture d'un gros bloc, environ 12 Go / s. Sauf que cette fois, le multithreading franchit le plafond de 40 Go / s. Ca a du sens. Les données restent dans le cache, donc le goulot d'étranglement RAM n'apparaît pas. Pour les données qui ne tenaient pas dans le cache L3, le même plafond d'environ 38 Go / s s'applique.Le test
Impressionnant! Les performances monothread sont similaires à la lecture d'un gros bloc, environ 12 Go / s. Sauf que cette fois, le multithreading franchit le plafond de 40 Go / s. Ca a du sens. Les données restent dans le cache, donc le goulot d'étranglement RAM n'apparaît pas. Pour les données qui ne tenaient pas dans le cache L3, le même plafond d'environ 38 Go / s s'applique.Le test matrix4x4montre des résultats similaires au circuit, mais encore plus rapides; 31 Go / s en mode monothread, 171 Go / s en mode multithread.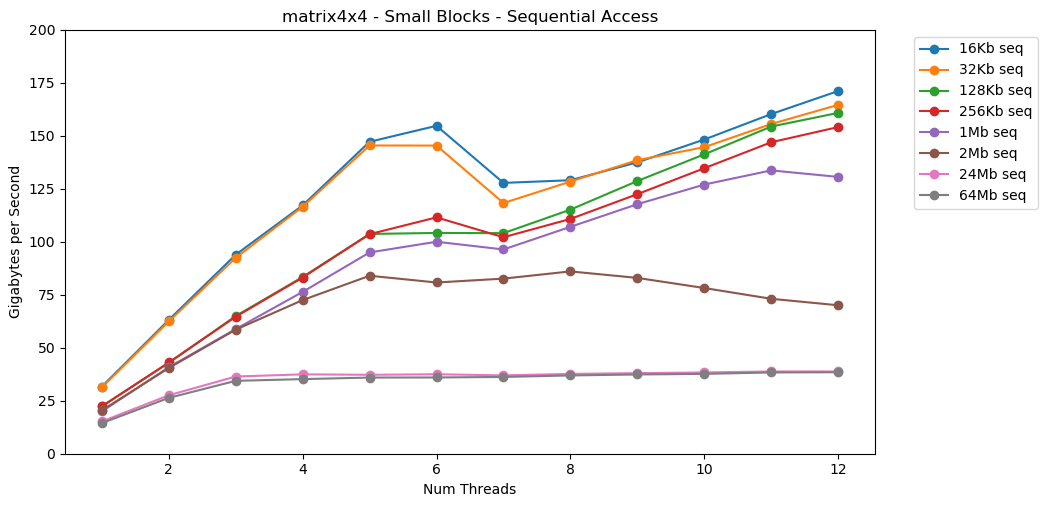 Voyons maintenant
Voyons maintenant matrix4x4_simd. Faites attention à l'axe y.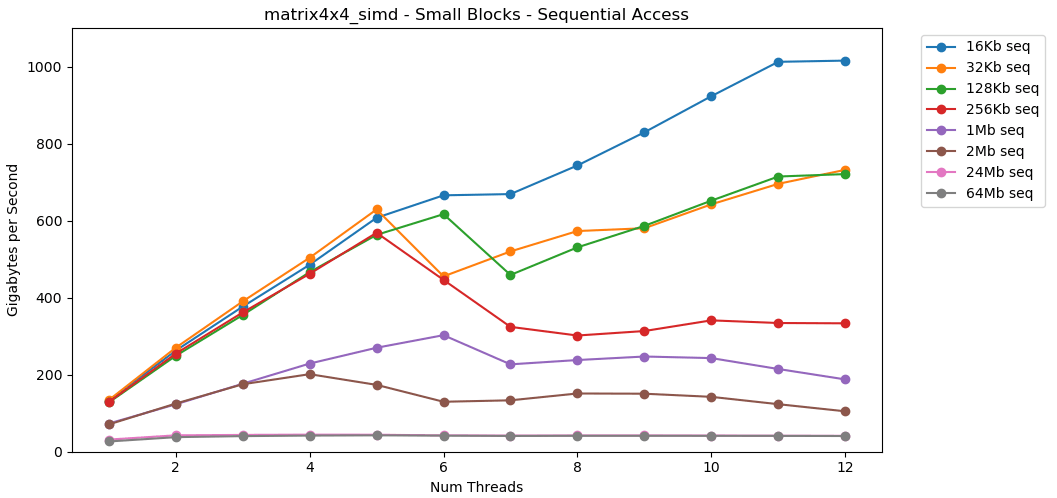
matrix4x4_simdeffectué exceptionnellement rapide. C'est 10 fois plus rapide que int32. Sur un bloc de 16 Ko, il franchit même les 1000 Go / s!Évidemment, il s'agit d'un test synthétique de surface. La plupart des applications n'effectuent pas la même opération avec les mêmes données un million de fois de suite. Le test ne montre pas les performances dans le monde réel.Mais la leçon est claire. À l'intérieur du cache, les données sont traitées rapidement . Avec un plafond très élevé lors de l'utilisation de SIMD: plus de 100 Go / s en mode mono-thread, plus de 1000 Go / s en multi-thread. L'écriture de données dans le cache est lente et avec une limite stricte d'environ 40 Go / s.Petit bloc: lecture aléatoire
Faisons de même, mais maintenant avec un accès aléatoire. Ceci est ma partie préférée de l'article.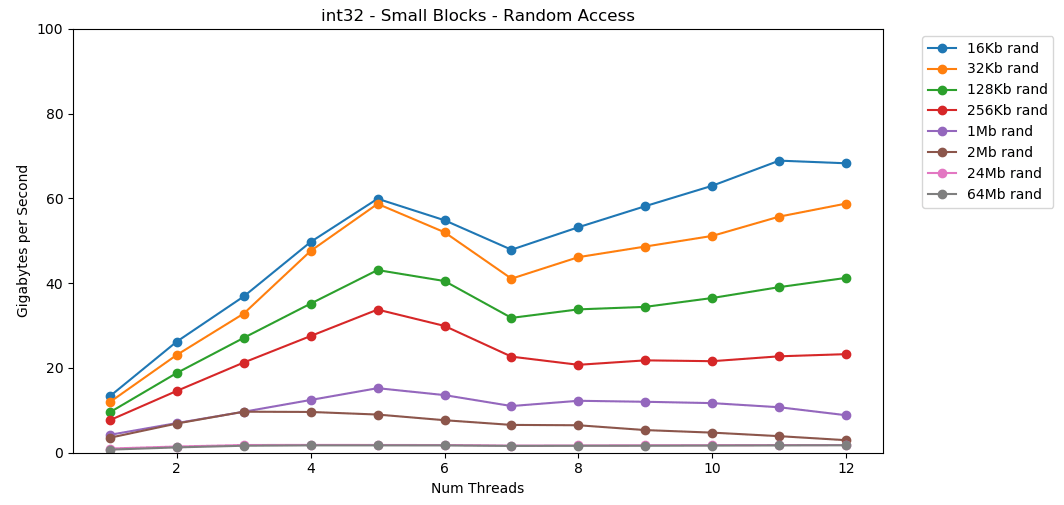 La lecture de valeurs aléatoires à partir de la RAM est lente, seulement 0,46 Go / s. La lecture de valeurs aléatoires à partir du cache L1 est très rapide: 13 Go / s. C'est plus rapide que de lire des données série
La lecture de valeurs aléatoires à partir de la RAM est lente, seulement 0,46 Go / s. La lecture de valeurs aléatoires à partir du cache L1 est très rapide: 13 Go / s. C'est plus rapide que de lire des données série int32depuis la RAM (11 Go / s).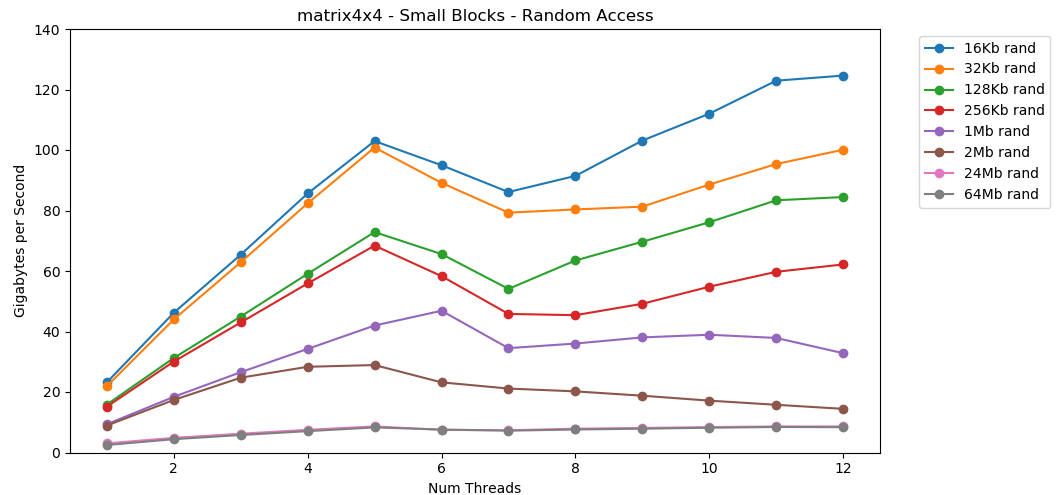 Le test
Le test matrix4x4montre un résultat similaire pour le même modèle, mais environ deux fois plus rapide que int.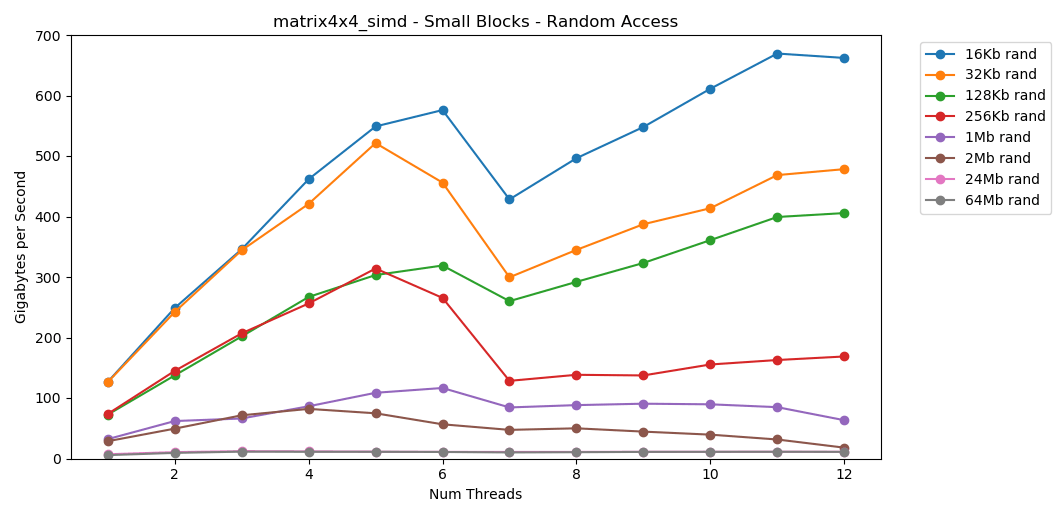 L'accès aléatoire est
L'accès aléatoire est matrix4x4_simdincroyablement rapide.Résultats d'accès aléatoire
La lecture libre de la mémoire est lente. Catastrophiquement lent. Moins de 1 Go / s pour les deux cas de test int32. Dans le même temps, les lectures aléatoires à partir du cache sont étonnamment rapides. Elle est comparable à la lecture séquentielle à partir de la RAM.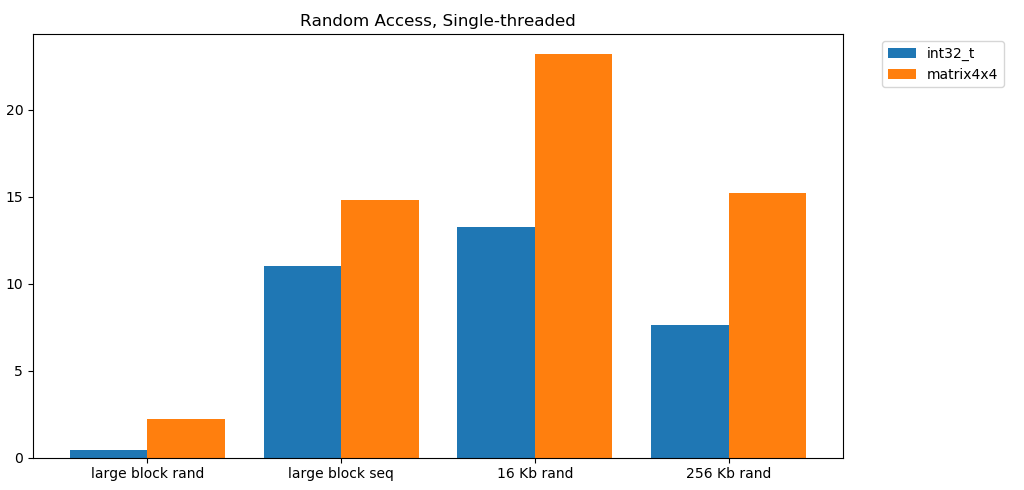 Il doit être digéré. L'accès aléatoire au cache est comparable en vitesse à l'accès séquentiel à la RAM. La baisse de L1 16 Ko à L2 256 Ko n'est que de moitié ou moins.Je pense que cela aura des conséquences profondes.
Il doit être digéré. L'accès aléatoire au cache est comparable en vitesse à l'accès séquentiel à la RAM. La baisse de L1 16 Ko à L2 256 Ko n'est que de moitié ou moins.Je pense que cela aura des conséquences profondes.Les listes liées sont considérées comme nuisibles
Chasser un pointeur (sauter sur des pointeurs) est mauvais. Très très mauvais. Combien les performances diminuent-elles? Voir par vous-même. Je l' ai fait un test supplémentaire qui enveloppe matrix4x4en std::unique_ptr. Chaque accès passe par un pointeur. Voici un résultat terrible, juste catastrophique. 1 fil | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Grand bloc - Seq | 14,8 Go / s | 0,8 Go / s | 19x |
16 Ko - Séq | 31,6 Go / s | 2,2 Go / s | 14x |
256 Ko - Séq | 22,2 Go / s | 1,9 Go / s | 12x |
Grand bloc - Rand | 2,2 Go / s | 0,1 Go / s | 22x |
16 Ko - Rand | 23,2 Go / s | 1,7 Go / s | 14x |
256 Ko - Rand | 15,2 Go / s | 0,8 Go / s | 19x |
6 fils | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Grand bloc - Seq | 34,4 Go / s | 2,5 Go / s | 14x |
16 Ko - Séq | 154,8 Go / s | 8,0 Go / s | 19x |
256 Ko - Séq | 111,6 Go / s | 5,7 Go / s | 20x |
Grand bloc - Rand | 7,1 Go / s | 0,4 Go / s | 18x |
16 Ko - Rand | 95,0 Go / s | 7,8 Go / s | 12x |
256 Ko - Rand | 58,3 Go / s | 1,6 Go / s | 36x |La sommation séquentielle des valeurs derrière le pointeur est effectuée à une vitesse inférieure à 1 Go / s. La vitesse d'accès aléatoire à double saut du cache n'est que de 0,1 Go / s.La poursuite d'un pointeur ralentit l'exécution du code 10 à 20 fois. Ne laissez pas vos amis utiliser des listes chaînées. Veuillez penser au cache.Estimation budgétaire pour les cadres
Il est courant pour les développeurs de jeux de définir une limite (budget) pour la charge sur le CPU et la mémoire. Mais je n'ai jamais vu de budget de bande passante.Dans les jeux modernes, FPS continue de croître. Il est maintenant à 60 FPS. VR fonctionne à une fréquence de 90 Hz. J'ai un moniteur de jeu 144 Hz. C'est génial, donc le 60 FPS ressemble à de la merde. Je ne reviendrai jamais sur l'ancien moniteur. Esports et streamers Twitch surveille 240 Hz. Cette année, Asus a présenté un monstre à 360 Hz au CES.Mon processeur a une limite supérieure d'environ 40 Go / s. Cela semble être un grand nombre! Cependant, à une fréquence de 240 Hz, seulement 167 Mo par trame sont obtenus. Une application réaliste peut générer un trafic de 5 Go / s à 144 Hz, soit seulement 69 Mo par trame.Voici un tableau avec quelques chiffres. | 1 | 10 | 30 | 60 | 90 | 144 | 240 | 360 |
-------- | ------- | -------- | -------- | -------- | ------ - | -------- | -------- | -------- |
40 Go / s | 40 Go | 4 Go | 1,3 Go | 667 Mo | 444 Mo | 278 Mo | 167 Mo | 111 Mo |
10 Go / s | 10 Go | 1 Go | 333 Mo | 166 Mo | 111 Mo | 69 Mo | 42 Mo | 28 Mo |
1 Go / s | 1 Go | 100 Mo | 33 Mo | 17 Mo | 11 Mo | 7 Mo | 4 Mo | 3 Mo |
Il me semble qu'il est utile d'évaluer les problèmes sous cet angle. Cela montre clairement que certaines idées ne sont pas réalisables. Atteindre 240 Hz n'est pas facile. Cela ne se fera pas tout seul.Les chiffres que chaque programmeur devrait connaître (2020)
La liste précédente est obsolète. Il doit maintenant être mis à jour et mis en conformité d'ici 2020.Voici quelques chiffres pour mon ordinateur personnel. Ceci est un mélange d'AIDA64, Sandra et mes références. Les chiffres ne donnent pas une image complète et ne sont qu'un point de départ.Latence L1: 1 ns
Délai L2: 2,5 ns
Retard L3: 10 ns
Latence RAM: 50 ns
(par fil)
Bande L1: 210 Go / s
Bande L2: 80 Go / s
Bande L3: 60 Go / s
(le système au complet)
Bande RAM: 45 Go / s
Ce serait bien de créer un petit benchmark open source simple. Certains fichiers C qui peuvent être exécutés sur des ordinateurs de bureau, des serveurs, des appareils mobiles, des consoles, etc. Mais je ne suis pas du genre à écrire un tel outil.Déni de responsabilité
La mesure de la bande passante mémoire est difficile. Très difficile. Il y a probablement des erreurs dans mon code. De nombreux facteurs non comptabilisés. Si vous critiquez ma technique, vous avez probablement raison.En fin de compte, je pense que c'est normal. Cet article ne concerne pas les performances exactes de mon bureau. Il s'agit d'une déclaration de problème d'un certain point de vue. Et comment apprendre à faire des calculs mathématiques approximatifs.Conclusion
Un collègue m'a fait part d'une opinion intéressante sur la bande passante mémoire du GPU et les performances des applications. Cela m'a incité à étudier les performances de la mémoire sur les ordinateurs modernes.Pour des calculs approximatifs, voici quelques chiffres pour un bureau moderne:- Performances RAM
- Maximum:
45 / - En moyenne, environ:
5 / - Le minimum:
1 /
- Performances du cache L1 / L2 / L3 (par cœur)
- Maximum (c simd):
210 // 80 //60 / - En moyenne, environ:
25 // 15 //9 / - Minimum:
13 // 8 //3,5 /
Les notes d'échantillon sont liées aux performances matrix4x4. Le vrai code ne sera jamais aussi simple. Mais pour les calculs sur une serviette, c'est un point de départ raisonnable. Vous devez ajuster ce chiffre en fonction des modèles d'accès à la mémoire dans votre programme, des caractéristiques de votre équipement et du code.Cependant, la chose la plus importante est une nouvelle façon de penser aux problèmes. La présentation du problème en octets par seconde ou en octets par trame est une autre lentille à regarder. C'est un outil utile au cas où.Merci d'avoir lu.La source
Benchmark C ++Python Graphdata.jsonDe plus amples recherches
Cet article n'a que légèrement abordé le sujet. Je n’y entrerai probablement pas. Mais s'il le faisait, alors il pourrait couvrir certains des aspects suivants:Spécifications du système
Des tests ont été effectués sur mon ordinateur personnel. Seuls les paramètres de stock, pas d'overclocking.- Système d'exploitation: Windows 10 v1903 build 18362
- Processeur: Intel i7-8700k à 3,70 GHz
- RAM: 2x16 GSkill Ripjaw DDR4-3200 (16-18-18-38 @ 1600 MHz)
- Carte mère: Asus TUF Z370-Plus Gaming