Optimiser le stockage: un cas d'unification et de moindre coût de possession
L'article décrit le processus d'optimisation de l'infrastructure de stockage d'une entreprise de classe moyenne.Les justifications d'une telle transition et une brève description du processus de mise en place d'un nouveau système de stockage sont considérées. Nous donnons un exemple des avantages et des inconvénients du passage au système sélectionné.introduction
L'infrastructure de l'un de nos clients était constituée de nombreux systèmes de stockage hétérogènes de différents niveaux: des systèmes SOHO QNAP, Synology pour les données utilisateur aux systèmes de stockage d'entrée et de milieu de gamme Eternus DX90 et DX600 pour iSCSI et FC pour les données de service et les systèmes de virtualisation.Tout cela différait à la fois dans les générations et dans les disques utilisés; une partie des systèmes était un équipement hérité qui ne bénéficiait pas de l'assistance d'un fournisseur.Un problème distinct était la gestion de l'espace libre, car tout l'espace disque disponible était très fragmenté sur de nombreux systèmes. En conséquence, les inconvénients de l'administration et le coût élevé de la maintenance d'une flotte de systèmes.Nous avons été confrontés au défi d'optimiser l'infrastructure de stockage afin de réduire le coût de possession et d'unification.La tâche a été analysée de manière approfondie par les experts de notre entreprise en tenant compte des exigences des clients en matière de disponibilité des données, IOPS, RPO / RTO, ainsi que de la possibilité de mettre à niveau l'infrastructure existante.la mise en oeuvre
Les principaux acteurs du marché des systèmes de stockage de milieu de gamme (et supérieurs) sont IBM avec Storwize; Fujitsu, représenté par la ligne Eternus, et NetApp avec la série FAS. En tant que système de stockage répondant aux exigences données, ces systèmes ont été considérés, à savoir: IBM Storwize V7000U, Fujitsu Eternus DX100, NetApp FAS2620. Tous les trois sont Unified-SHD, c'est-à-dire qu'ils fournissent à la fois un accès par bloc et un accès aux fichiers, et fournissent des indicateurs de performance proches.Mais dans le cas du Storwize V7000U, l'accès aux fichiers est organisé via un contrôleur séparé - un module de fichiers qui se connecte au contrôleur de bloc principal, ce qui constitue un point de défaillance supplémentaire. De plus, ce système est relativement difficile à gérer et n'assure pas une bonne isolation des services.Le système de stockage Eternus DX100, étant également un système de stockage unifié, a de sérieuses limitations sur le nombre de systèmes de fichiers créés, sans donner l'isolement nécessaire. De plus, le processus de création d'un nouveau système de fichiers prend beaucoup de temps (jusqu'à une demi-heure). Les deux systèmes décrits ne permettent pas de partager des serveurs CIFS / NFS utilisés au niveau du réseau.En tenant compte de tous les paramètres, y compris le coût total de possession du système, NetApp FAS2620 a été choisi, composé d'une paire de contrôleurs fonctionnant en mode actif-actif, et permettant de répartir la charge entre les contrôleurs. Et lorsqu'il est combiné avec les mécanismes intégrés de déduplication et de compression en ligne, il peut considérablement économiser sur l'espace occupé par les données sur les disques. Ces mécanismes deviennent beaucoup plus efficaces lors de l'agrégation de données sur un système par rapport à la situation initiale, lorsque des données potentiellement identiques étaient localisées sur différents systèmes de stockage et qu'il était impossible de les dédupliquer entre elles.Un tel système a permis de placer tous les types de services sous le contrôle d'un seul cluster de basculement: SAN sous forme de blocs de virtualisation et NAS sous forme de CIFS, partages NFS pour les données utilisateurs Windows et systèmes * nix. Dans le même temps, il restait la possibilité d'une séparation logique sûre de ces services grâce à la technologie SVM (Storage Virtual Machine): les services responsables des différents composants n'affectent pas les «voisins» et ne leur permettent pas d'y accéder.Il est également possible d'isoler les services au niveau du disque, en évitant l'affaissement des performances sous une forte charge des "voisins".Pour les services qui nécessitent une lecture / écriture rapide, vous pouvez utiliser un type hybride de matrice RAID, en ajoutant plusieurs SSD à l'agrégat HDD. Le système lui-même y placera des données «à chaud», réduisant ainsi la latence de lecture des données fréquemment utilisées. Cela s'ajoute au cache NVRAM, qui garantit son atomicité et son intégrité en plus de la vitesse d'écriture élevée (les données seront stockées dans la NVRAM alimentée par la batterie jusqu'à ce que la confirmation de leur enregistrement complet soit reçue du système de fichiers) en cas de panne de courant soudaine.Après la migration des données vers un nouveau système de stockage, il devient possible d'utiliser plus efficacement l'espace disque du cache.Cotés positifs
Comme mentionné ci-dessus, l'utilisation de ce système a permis de résoudre deux problèmes à la fois:- Unification- , , , .
- . , LUN, .
- . , . , Ethernet Fiber Channel .
- , , . .
—- NetApp SVM (Storage Virtual Machine), , , . SVM, . /.
- .
SVM , , VLAN-. , SVM, VLAN’. , trunk-.
iSCSI-, SAN- , , « » .
- .
- RAID- ( RAID- ), Volume. Volume SVM’, SVM’ . «» , «» SVM’ .
RAID- , .
—- . RAID-, .
- (CPU, RAM). storage-, , IO-, .
- NetApp S3- , on-premise , .
- Après avoir réduit tous les services sous le contrôle d'un système, nous prévoyons un impact plus important en désactivant un composant (1 contrôleur sur 2 contre 1 sur 10+ dans l'ancienne infrastructure).- Diminution de la distribution des infrastructures de stockage. Si les systèmes de stockage antérieurs pouvaient être situés à différents étages / dans différents bâtiments, maintenant tout est concentré dans un seul rack. Cet élément peut être compensé en achetant un système moins efficace et en utilisant la réplication synchrone / asynchrone en cas de force majeure.Configuration étape par étape
En raison de la confidentialité des informations, il est impossible de faire des captures d'écran de l'environnement réel du client. Les étapes de configuration sont donc affichées dans l'environnement de test et répètent complètement les étapes effectuées dans l'environnement productif du client.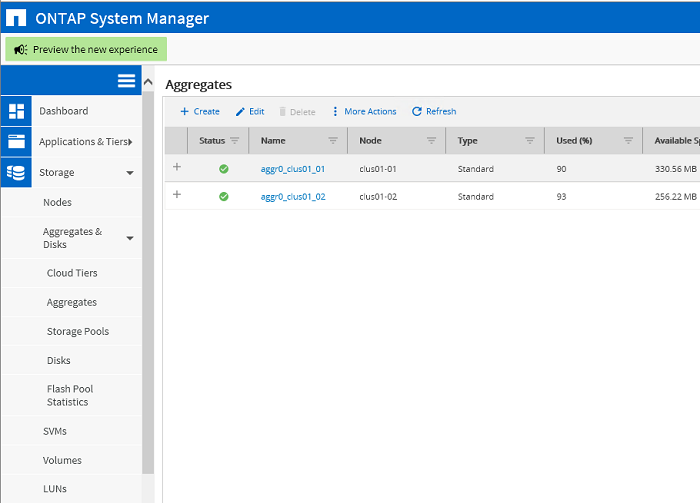 L'état initial du cluster. Deux agrégats pour les partitions racine des nœuds de cluster clus01_01 et clus01_02 correspondants
L'état initial du cluster. Deux agrégats pour les partitions racine des nœuds de cluster clus01_01 et clus01_02 correspondants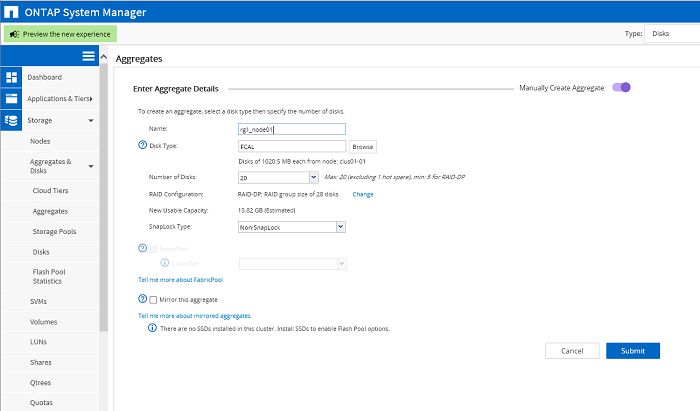 Création d'agrégats pour les données. Chaque nœud possède son propre agrégat composé d'une matrice RAID-DP.
Création d'agrégats pour les données. Chaque nœud possède son propre agrégat composé d'une matrice RAID-DP.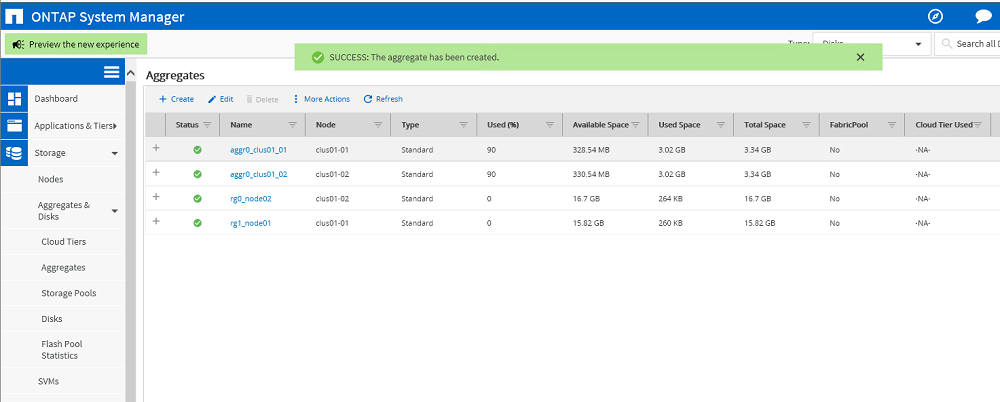 Résultat: deux agrégats ont été créés: rg0_node02, rg1_node01. Il n'y a pas encore de données les concernant.
Résultat: deux agrégats ont été créés: rg0_node02, rg1_node01. Il n'y a pas encore de données les concernant. Création de SVM en tant que serveur CIFS. Pour SVM, il est obligatoire de créer un volume racine pour lequel l'agrégat racine est sélectionné - rg1_node01. Ce volume stockera les paramètres SVM individuels.
Création de SVM en tant que serveur CIFS. Pour SVM, il est obligatoire de créer un volume racine pour lequel l'agrégat racine est sélectionné - rg1_node01. Ce volume stockera les paramètres SVM individuels.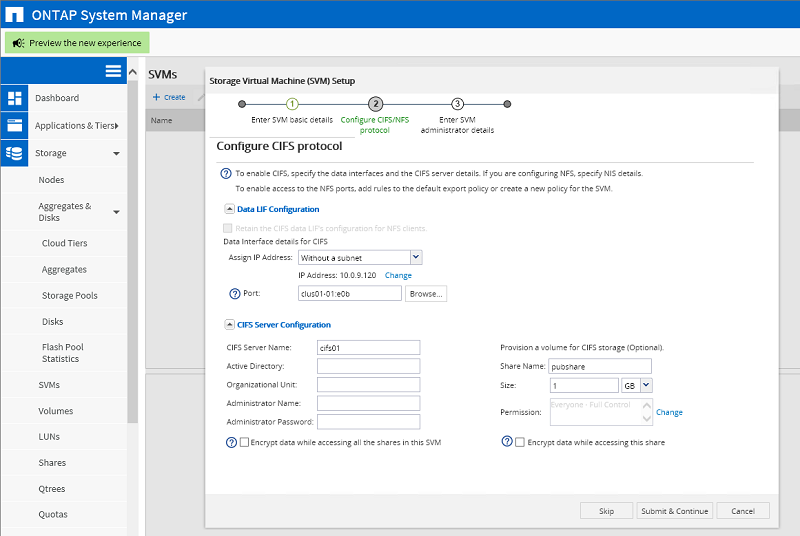 CIFS- SVM. IP- ., . VLAN-, LACP . Volume , , .
CIFS- SVM. IP- ., . VLAN-, LACP . Volume , , . , . 4,9 , . .
, . 4,9 , . .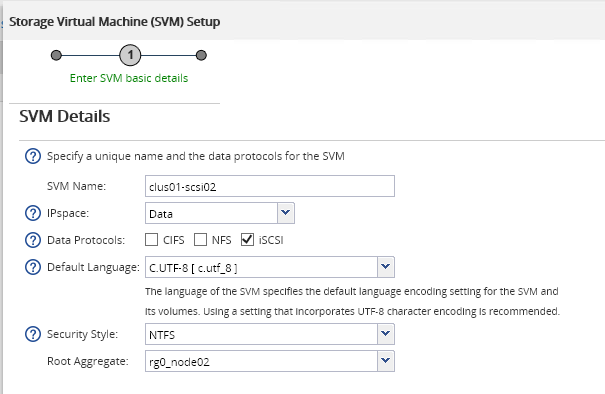 SVM iSCSI-. , Root Volume . CIFS- IP- iSCSI-, . , (LUN), .
SVM iSCSI-. , Root Volume . CIFS- IP- iSCSI-, . , (LUN), . LUN 10 . , .
LUN 10 . , . Hyper-V Server iqn.
Hyper-V Server iqn.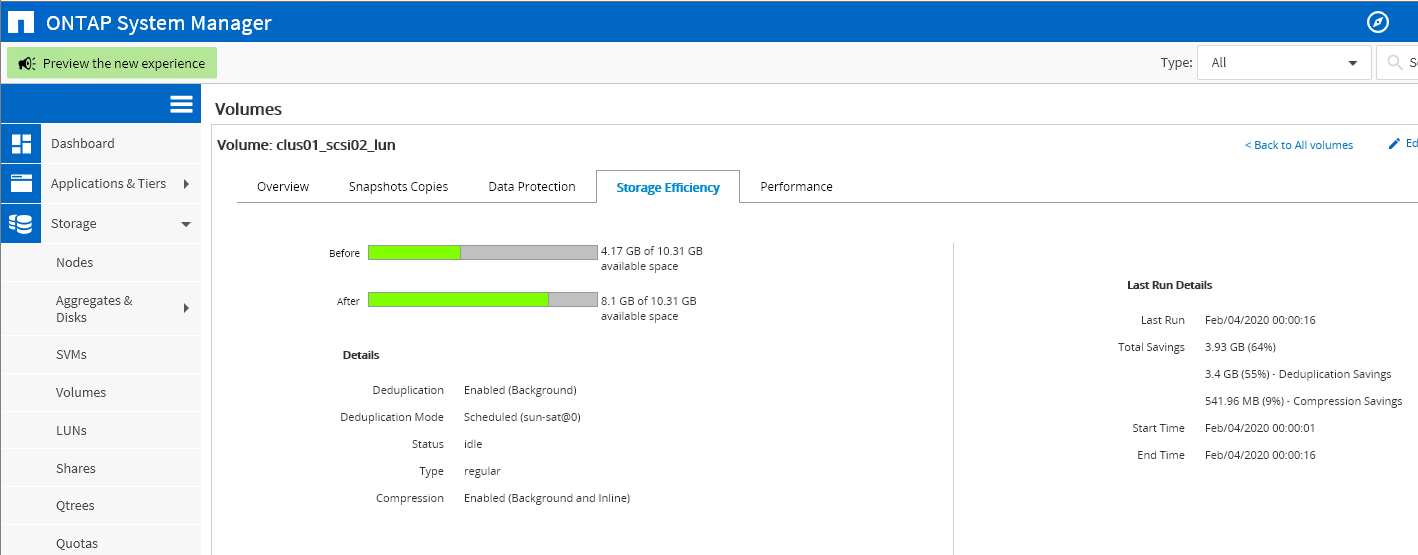 Hyper-V Server LUN Linux. Volume, , , . LUN , .
Hyper-V Server LUN Linux. Volume, , , . LUN , . Source: https://habr.com/ru/post/undefined/
All Articles