HighLoad ++, Mikhail Tyulenev (MongoDB): Cohérence causale: de la théorie à la pratique
La prochaine conférence HighLoad ++ se tiendra les 6 et 7 avril 2020 à Saint-Pétersbourg.Détails et billets ici . HighLoad ++ Siberia 2019. Salle "Krasnoyarsk". 25 juin, 12h00. Résumés et présentation . Il arrive que des exigences pratiques entrent en conflit avec une théorie où les aspects importants pour un produit commercial ne sont pas pris en compte. Ce rapport présente le processus de sélection et de combinaison de différentes approches pour créer des composants de cohérence causale basés sur la recherche universitaire basée sur les exigences d'un produit commercial. Les étudiants apprendront les approches théoriques existantes des horloges logiques, le suivi des dépendances, la sécurité du système, la synchronisation d'horloge et pourquoi MongoDB s'est arrêté sur telle ou telle solution.Mikhail Tyulenev (ci-après - MT): - Je vais parler de cohérence causale - c'est une fonctionnalité sur laquelle nous avons travaillé dans MongoDB. Je travaille dans un groupe de systèmes distribués, nous l'avons fait il y a environ deux ans.
Il arrive que des exigences pratiques entrent en conflit avec une théorie où les aspects importants pour un produit commercial ne sont pas pris en compte. Ce rapport présente le processus de sélection et de combinaison de différentes approches pour créer des composants de cohérence causale basés sur la recherche universitaire basée sur les exigences d'un produit commercial. Les étudiants apprendront les approches théoriques existantes des horloges logiques, le suivi des dépendances, la sécurité du système, la synchronisation d'horloge et pourquoi MongoDB s'est arrêté sur telle ou telle solution.Mikhail Tyulenev (ci-après - MT): - Je vais parler de cohérence causale - c'est une fonctionnalité sur laquelle nous avons travaillé dans MongoDB. Je travaille dans un groupe de systèmes distribués, nous l'avons fait il y a environ deux ans. Dans le processus, j'ai dû me familiariser avec beaucoup de recherches académiques, car cette fonctionnalité est bien étudiée. Il s'est avéré que pas un seul article ne correspond à ce qui est requis dans la production, la base de données compte tenu des exigences très spécifiques qui se trouvent probablement dans toutes les applications de production.Je vais parler de la façon dont nous, en tant que consommateur de recherche universitaire, en préparons quelque chose que nous pouvons ensuite présenter à nos utilisateurs comme un plat prêt à l'emploi qui est pratique, sûr à utiliser.
Dans le processus, j'ai dû me familiariser avec beaucoup de recherches académiques, car cette fonctionnalité est bien étudiée. Il s'est avéré que pas un seul article ne correspond à ce qui est requis dans la production, la base de données compte tenu des exigences très spécifiques qui se trouvent probablement dans toutes les applications de production.Je vais parler de la façon dont nous, en tant que consommateur de recherche universitaire, en préparons quelque chose que nous pouvons ensuite présenter à nos utilisateurs comme un plat prêt à l'emploi qui est pratique, sûr à utiliser.Cohérence causale. Définissons les concepts
Pour commencer, je veux décrire en termes généraux ce qu'est la cohérence causale. Il y a deux personnages - Leonard et Penny (la série "The Big Bang Theory"):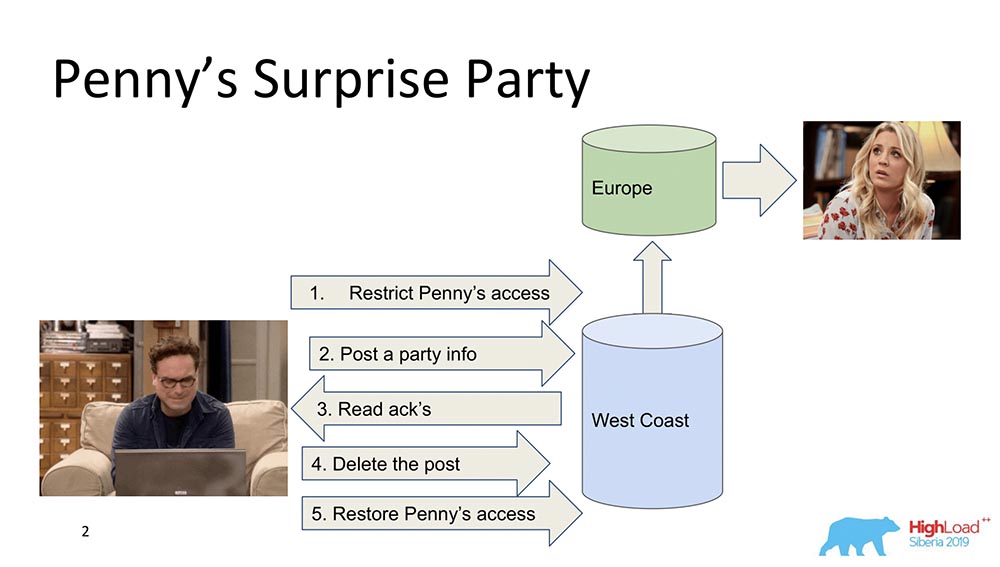 Supposons que Penny soit en Europe, et Leonard veut faire une sorte de surprise pour elle, une fête. Et il ne pense à rien de mieux que de la jeter hors de la liste d'amis, d'envoyer à tous ses amis une mise à jour sur le flux: "Rendons Penny heureuse!" (elle en Europe, pendant son sommeil, ne voit pas tout cela et ne peut pas voir, car elle n'est pas là). À la fin, il supprime ce post, l'efface du "Feed" et restaure l'accès pour qu'il ne remarque rien et qu'il n'y ait pas de scandale.Tout va bien, mais supposons que le système soit distribué et que les événements se soient un peu mal passés. Par exemple, il se peut que la restriction d'accès à Penny se soit produite après la publication de ce message, si les événements ne sont pas liés par une relation causale. En fait, il s'agit d'un exemple de cas où la cohérence causale est requise pour remplir une fonction métier (dans ce cas).En fait, ce sont des propriétés assez banales de la base de données - très peu de personnes les prennent en charge. Passons aux modèles.
Supposons que Penny soit en Europe, et Leonard veut faire une sorte de surprise pour elle, une fête. Et il ne pense à rien de mieux que de la jeter hors de la liste d'amis, d'envoyer à tous ses amis une mise à jour sur le flux: "Rendons Penny heureuse!" (elle en Europe, pendant son sommeil, ne voit pas tout cela et ne peut pas voir, car elle n'est pas là). À la fin, il supprime ce post, l'efface du "Feed" et restaure l'accès pour qu'il ne remarque rien et qu'il n'y ait pas de scandale.Tout va bien, mais supposons que le système soit distribué et que les événements se soient un peu mal passés. Par exemple, il se peut que la restriction d'accès à Penny se soit produite après la publication de ce message, si les événements ne sont pas liés par une relation causale. En fait, il s'agit d'un exemple de cas où la cohérence causale est requise pour remplir une fonction métier (dans ce cas).En fait, ce sont des propriétés assez banales de la base de données - très peu de personnes les prennent en charge. Passons aux modèles.Modèles de cohérence
Qu'est-ce qu'un modèle de cohérence dans les bases de données en général? Ce sont quelques-unes des garanties qu'un système distribué donne quant aux données et dans quel ordre le client peut recevoir.En principe, tous les modèles de cohérence se résument à la répartition du système comme un système qui fonctionne, par exemple, sur le même signe de tête sur un ordinateur portable. Et c'est à quel point le système, qui fonctionne sur des milliers de «nœuds» géo-distribués, est similaire à un ordinateur portable, dans lequel toutes ces propriétés sont exécutées automatiquement en principe.Par conséquent, les modèles de cohérence ne s'appliquent qu'aux systèmes distribués. Tous les systèmes qui existaient auparavant et fonctionnaient sur la même échelle verticale n'ont pas rencontré de tels problèmes. Il y avait une mémoire tampon, et tout était toujours lu à partir de celle-ci.Modèle solide
En fait, le tout premier modèle est Strong (ou la ligne de capacité de montée, comme on l'appelle souvent). Il s'agit d'un modèle de cohérence qui garantit que chaque modification, dès réception de la confirmation de son apparition, est visible pour tous les utilisateurs du système.Cela crée un ordre global de tous les événements de la base de données. Il s'agit d'une propriété de consistance très forte et généralement très coûteuse. Cependant, il est très bien entretenu. C'est tout simplement très cher et lent - ils sont tout simplement rarement utilisés. C'est ce qu'on appelle la capacité de montée.Il existe une autre propriété, plus puissante, prise en charge dans le "Spanner" - appelé cohérence externe. Nous parlerons de lui un peu plus tard.Causal
Ce qui suit est Causal, juste ce dont je parlais. Il y a plusieurs sous-niveaux entre Strong et Causal dont je ne parlerai pas, mais ils se résument tous à Causal. C'est un modèle important car c'est le plus fort de tous les modèles, la plus forte cohérence en présence d'un réseau ou de partitions.Les causalités sont en fait une situation dans laquelle les événements sont liés par une relation causale. Très souvent, ils sont perçus comme des droits de lecture sur le point de vue du client. Si le client a observé certaines valeurs, il ne peut pas voir les valeurs qui étaient dans le passé. Il commence déjà à voir des lectures de préfixes. Tout revient à la même chose.Les causes comme modèle de cohérence sont un ordre partiel des événements sur le serveur, dans lequel les événements de tous les clients sont observés dans la même séquence. Dans ce cas, Leonard et Penny.Éventuel
Le troisième modèle est la cohérence éventuelle. C'est ce qui prend en charge absolument tous les systèmes distribués, un modèle minimal qui a généralement du sens. Cela signifie ce qui suit: lorsque nous avons des modifications dans les données, elles deviennent cohérentes à un moment donné.À un tel moment, elle ne dit rien, sinon elle se transformerait en cohérence externe - il y aurait une histoire complètement différente. Néanmoins, il s'agit d'un modèle très populaire, le plus courant. Par défaut, tous les utilisateurs de systèmes distribués utilisent la cohérence éventuelle.Je veux donner quelques exemples comparatifs: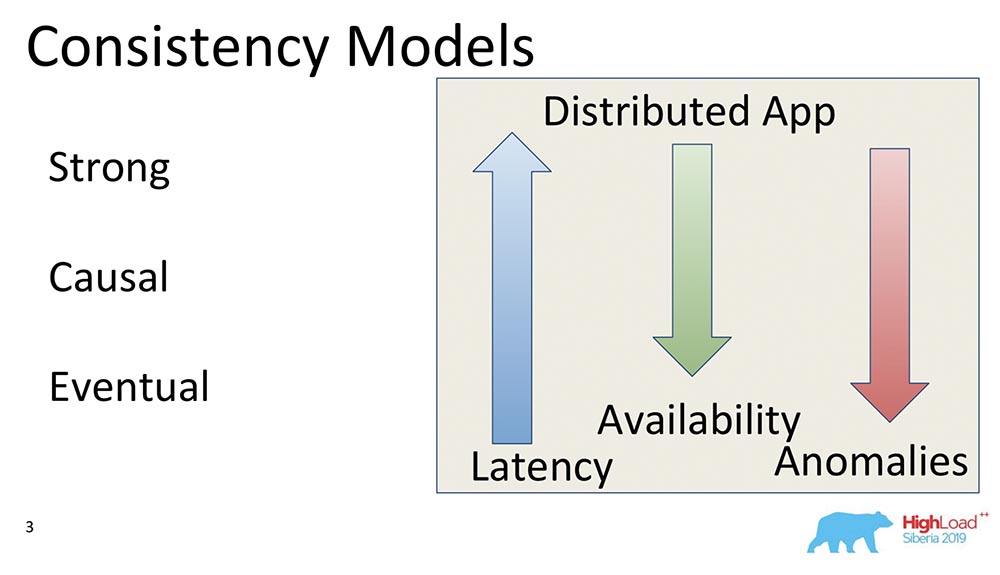 que signifient ces flèches?
que signifient ces flèches?- Latency. : , , , . Eventual Consistency , , , memory .
- Availability. , partitions, - – , , - . Eventual Consistency – , .
- Anomalies. , , . Strong Consistency , Eventual Consistency . : Eventual Consistency, ? , Eventual Consistency- , , , ; - ; . , .
CAP
Quand vous voyez les mots cohérence, disponibilité - qu'est-ce qui vous vient à l'esprit? Droite - Théorème CAP! Maintenant, je veux dissiper le mythe ... Ce n'est pas moi - il y a Martin Kleppman, qui a écrit un merveilleux article, un merveilleux livre. Le théorème de la PAC est un principe formulé dans les années 2000 selon lequel Cohérence, Disponibilité, Partitions: prenez deux, et vous ne pouvez pas en choisir trois. C'était un certain principe. Il a été prouvé comme théorème quelques années plus tard par Gilbert et Lynch. Puis il est devenu utilisé comme mantra - les systèmes ont commencé à être divisés en CA, CP, AP et ainsi de suite.Ce théorème a en fait été prouvé pour les raisons suivantes ... Premièrement, la disponibilité n'était pas considérée comme une valeur continue de zéro à des centaines (0 - le système est "mort", 100 - répond rapidement; nous sommes tellement habitués à le considérer), mais comme une propriété de l'algorithme , ce qui garantit qu'avec toutes ses exécutions, il renvoie des données.Il n'y a pas un mot sur le temps de réponse! Il existe un algorithme qui renvoie des données après 100 ans - un algorithme disponible parfaitement fin, qui fait partie du théorème CAP.Deuxièmement: un théorème a été prouvé pour les changements dans les valeurs de la même clé, malgré le fait que ces changements sont une ligne redimensionnable. Cela signifie qu'en fait, ils ne sont pratiquement pas utilisés, car les modèles sont différents Cohérence éventuelle, forte cohérence (peut-être).Pourquoi tout ça? De plus, le théorème de CAP sous la forme dans laquelle il est prouvé qu'il n'est pratiquement pas applicable est rarement utilisé. Sous une forme théorique, cela limite en quelque sorte tout. Il s'avère qu'un certain principe est intuitivement vrai, mais en aucun cas, en général, n'est prouvé.
Le théorème de la PAC est un principe formulé dans les années 2000 selon lequel Cohérence, Disponibilité, Partitions: prenez deux, et vous ne pouvez pas en choisir trois. C'était un certain principe. Il a été prouvé comme théorème quelques années plus tard par Gilbert et Lynch. Puis il est devenu utilisé comme mantra - les systèmes ont commencé à être divisés en CA, CP, AP et ainsi de suite.Ce théorème a en fait été prouvé pour les raisons suivantes ... Premièrement, la disponibilité n'était pas considérée comme une valeur continue de zéro à des centaines (0 - le système est "mort", 100 - répond rapidement; nous sommes tellement habitués à le considérer), mais comme une propriété de l'algorithme , ce qui garantit qu'avec toutes ses exécutions, il renvoie des données.Il n'y a pas un mot sur le temps de réponse! Il existe un algorithme qui renvoie des données après 100 ans - un algorithme disponible parfaitement fin, qui fait partie du théorème CAP.Deuxièmement: un théorème a été prouvé pour les changements dans les valeurs de la même clé, malgré le fait que ces changements sont une ligne redimensionnable. Cela signifie qu'en fait, ils ne sont pratiquement pas utilisés, car les modèles sont différents Cohérence éventuelle, forte cohérence (peut-être).Pourquoi tout ça? De plus, le théorème de CAP sous la forme dans laquelle il est prouvé qu'il n'est pratiquement pas applicable est rarement utilisé. Sous une forme théorique, cela limite en quelque sorte tout. Il s'avère qu'un certain principe est intuitivement vrai, mais en aucun cas, en général, n'est prouvé.Cohérence causale - le modèle le plus solide
Ce qui se passe maintenant - vous pouvez obtenir les trois choses: cohérence, disponibilité peut être obtenue en utilisant des partitions. En particulier, la cohérence causale est le modèle de cohérence le plus fort qui, en présence de partitions (coupures de réseau), fonctionne toujours. Par conséquent, il est d'un grand intérêt, et nous y sommes donc engagés. Tout d'abord, cela simplifie le travail des développeurs d'applications. En particulier, il y a beaucoup de soutien du serveur: lorsque tous les enregistrements qui se produisent à l'intérieur d'un client sont garantis pour arriver dans cet ordre sur l'autre client. Deuxièmement, il résiste aux partitions.
Tout d'abord, cela simplifie le travail des développeurs d'applications. En particulier, il y a beaucoup de soutien du serveur: lorsque tous les enregistrements qui se produisent à l'intérieur d'un client sont garantis pour arriver dans cet ordre sur l'autre client. Deuxièmement, il résiste aux partitions.Cuisine intérieure MongoDB
En souvenir de ce déjeuner, nous passons à la cuisine. Je vais parler du modèle de système, à savoir ce qu'est MongoDB pour ceux qui ont entendu parler pour la première fois d'une telle base de données.
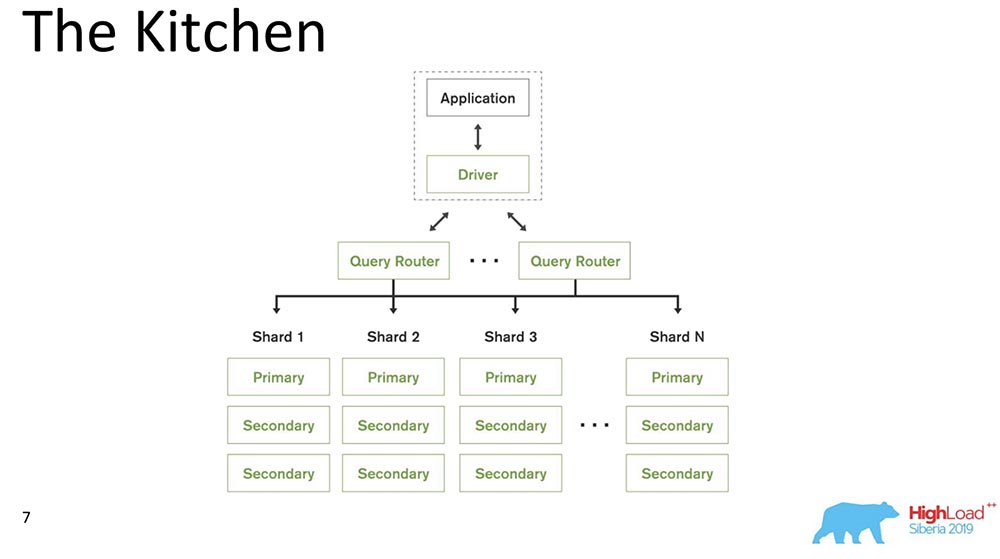 MongoDB (ci-après dénommé «MongoBD») est un système distribué qui prend en charge la mise à l'échelle horizontale, c'est-à-dire le découpage; et au sein de chaque fragment, il prend également en charge la redondance des données, c'est-à-dire la réplication.Le sharding dans «MongoBD» (base de données non relationnelle) effectue un équilibrage automatique, c'est-à-dire chaque collection de documents (ou «tableau» en termes de données relationnelles) en morceaux, et déjà le serveur les déplace automatiquement entre les fragments.Le routeur de requêtes qui distribue les requêtes pour le client est un client via lequel il fonctionne. Il sait déjà où et quelles données se trouvent, envoie toutes les demandes au bon fragment.Autre point important: MongoDB est un maître unique. Il existe un principal - il peut prendre des enregistrements qui prennent en charge les clés qu'il contient. Vous ne pouvez pas faire d'écriture multi-maître.Nous avons fait la version 4.2 - de nouvelles choses intéressantes y sont apparues. En particulier, ils ont inséré Lucene - la recherche - c'était exécutable java directement dans "Mongo", et là, il est devenu possible de rechercher à travers Lucene, la même que dans "Elastic".Et ils ont fait un nouveau produit - Graphiques, il est également disponible sur Atlas (le propre Cloud de Mongo). Ils ont un niveau gratuit - vous pouvez jouer avec. J'ai vraiment aimé les graphiques - la visualisation des données est très intuitive.
MongoDB (ci-après dénommé «MongoBD») est un système distribué qui prend en charge la mise à l'échelle horizontale, c'est-à-dire le découpage; et au sein de chaque fragment, il prend également en charge la redondance des données, c'est-à-dire la réplication.Le sharding dans «MongoBD» (base de données non relationnelle) effectue un équilibrage automatique, c'est-à-dire chaque collection de documents (ou «tableau» en termes de données relationnelles) en morceaux, et déjà le serveur les déplace automatiquement entre les fragments.Le routeur de requêtes qui distribue les requêtes pour le client est un client via lequel il fonctionne. Il sait déjà où et quelles données se trouvent, envoie toutes les demandes au bon fragment.Autre point important: MongoDB est un maître unique. Il existe un principal - il peut prendre des enregistrements qui prennent en charge les clés qu'il contient. Vous ne pouvez pas faire d'écriture multi-maître.Nous avons fait la version 4.2 - de nouvelles choses intéressantes y sont apparues. En particulier, ils ont inséré Lucene - la recherche - c'était exécutable java directement dans "Mongo", et là, il est devenu possible de rechercher à travers Lucene, la même que dans "Elastic".Et ils ont fait un nouveau produit - Graphiques, il est également disponible sur Atlas (le propre Cloud de Mongo). Ils ont un niveau gratuit - vous pouvez jouer avec. J'ai vraiment aimé les graphiques - la visualisation des données est très intuitive.Ingrédients de cohérence causale
J'ai compté environ 230 articles publiés sur ce sujet - de Leslie Lampert. Maintenant, de ma mémoire, je vais vous apporter quelques parties de ces documents. Tout a commencé avec un article de Leslie Lampert, écrit dans les années 1970. Comme vous pouvez le voir, certaines recherches sur ce sujet sont toujours en cours. Désormais, la cohérence causale connaît un intérêt pour le développement de systèmes distribués.
Tout a commencé avec un article de Leslie Lampert, écrit dans les années 1970. Comme vous pouvez le voir, certaines recherches sur ce sujet sont toujours en cours. Désormais, la cohérence causale connaît un intérêt pour le développement de systèmes distribués.Limites
Quelles sont les limitations? C'est en fait l'un des points principaux, car les restrictions que les systèmes de production imposent sont très différentes des restrictions qui existent dans les articles académiques. Ils sont souvent assez artificiels.
- Tout d'abord, "MongoDB" est un seul maître, comme je l'ai déjà dit (cela simplifie grandement).
- , 10 . - , .
- , , , binary, , .
- , Research : . «» – . , , – . , .
- , – : , performance degradation .
- Un autre point est généralement anti-académique: la compatibilité des versions précédentes et futures. Les anciens pilotes doivent prendre en charge les nouvelles mises à jour et la base de données doit prendre en charge les anciens pilotes.
En général, tout cela impose des limites.Composants de cohérence causale
Je vais maintenant parler de certains composants. Si nous considérons la cohérence causale générale, nous pouvons distinguer les blocs. Nous avons choisi parmi les œuvres appartenant à un certain bloc: le suivi des dépendances, le choix des heures, la façon dont ces montres peuvent être synchronisées entre elles et la façon dont nous assurons la sécurité - voici un plan approximatif de ce dont je vais parler:
Suivi complet des dépendances
Pourquoi est-il nécessaire? Afin que, lorsque les données sont répliquées - chaque enregistrement, chaque modification de données contienne des informations sur les modifications dont elle dépend. Le tout premier et naïf changement est lorsque chaque message qui contient un enregistrement contient des informations sur les messages précédents: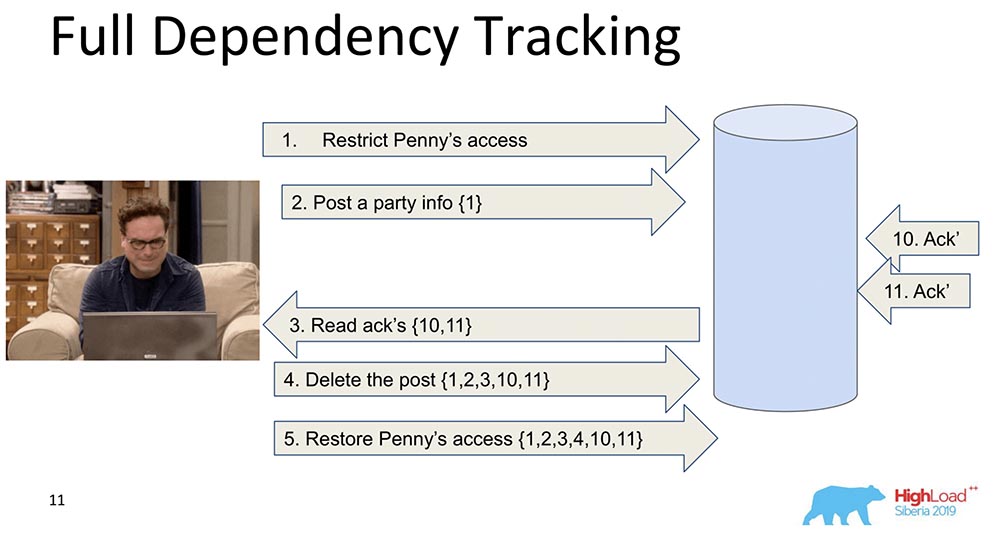 Dans cet exemple, le nombre d'accolades est le nombre d'enregistrements. Parfois, ces enregistrements avec des valeurs sont même transférés dans leur intégralité, parfois certaines versions sont transférées. L'essentiel est que chaque changement contient des informations sur le précédent (évidemment, il porte tout en soi).Pourquoi avons-nous décidé de ne pas utiliser cette approche (suivi complet)? Évidemment, parce que cette approche n'est pas pratique: tout changement dans le réseau social dépend de tous les changements précédents dans ce réseau social, transmettant, disons, Facebook ou Vkontakte à chaque mise à jour. Néanmoins, il y a beaucoup de recherches à savoir le suivi complet des dépendances - ce sont des réseaux sociaux, pour certaines situations, cela fonctionne vraiment.
Dans cet exemple, le nombre d'accolades est le nombre d'enregistrements. Parfois, ces enregistrements avec des valeurs sont même transférés dans leur intégralité, parfois certaines versions sont transférées. L'essentiel est que chaque changement contient des informations sur le précédent (évidemment, il porte tout en soi).Pourquoi avons-nous décidé de ne pas utiliser cette approche (suivi complet)? Évidemment, parce que cette approche n'est pas pratique: tout changement dans le réseau social dépend de tous les changements précédents dans ce réseau social, transmettant, disons, Facebook ou Vkontakte à chaque mise à jour. Néanmoins, il y a beaucoup de recherches à savoir le suivi complet des dépendances - ce sont des réseaux sociaux, pour certaines situations, cela fonctionne vraiment.Suivi explicite des dépendances
Le suivant est plus limité. Ici aussi, la transmission d'informations est envisagée, mais uniquement celle qui en dépend clairement. Ce qui dépend de ce qui, en règle générale, est déjà déterminé par Application. Lorsque les données sont répliquées, seules les réponses sont renvoyées lorsqu'une demande est effectuée, lorsque les dépendances précédentes ont été satisfaites, c'est-à-dire affichées. C'est l'essence même du fonctionnement de la cohérence causale.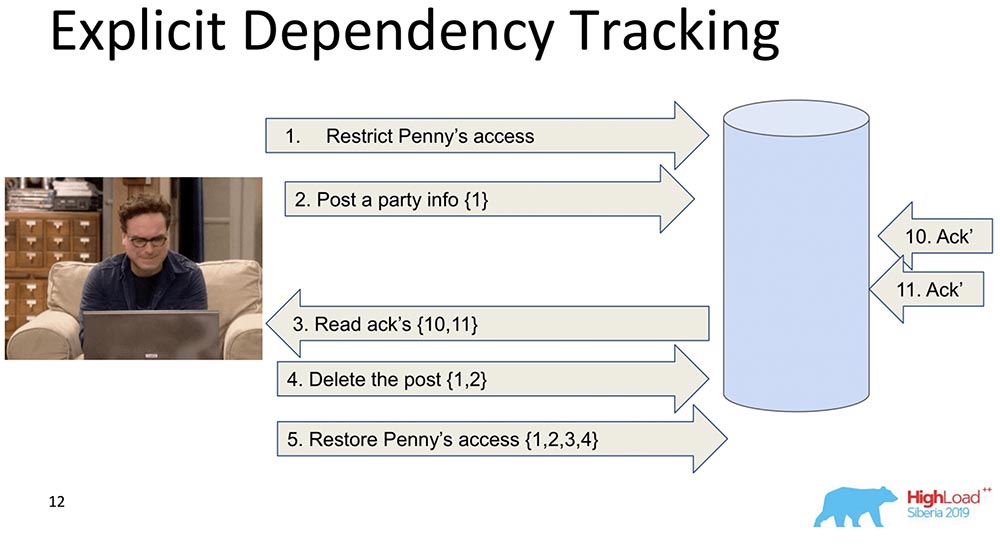 Elle voit que l'enregistrement 5 dépend des enregistrements 1, 2, 3, 4 - respectivement, elle attend que le client ait accès aux modifications apportées par le décret d'accès de Penny lorsque toutes les modifications précédentes ont déjà été transmises à la base de données.Cela ne nous convient pas non plus, car de toute façon il y a trop d'informations, et cela va ralentir. Il y a une approche différente ...
Elle voit que l'enregistrement 5 dépend des enregistrements 1, 2, 3, 4 - respectivement, elle attend que le client ait accès aux modifications apportées par le décret d'accès de Penny lorsque toutes les modifications précédentes ont déjà été transmises à la base de données.Cela ne nous convient pas non plus, car de toute façon il y a trop d'informations, et cela va ralentir. Il y a une approche différente ...Horloge Lamport
Ils sont très vieux. L'horloge Lamport implique que ces dépendances sont regroupées dans une fonction scalaire appelée horloge Lamport.Une fonction scalaire est un nombre abstrait. Souvent appelé temps logique. A chaque événement, ce compteur augmente. Le compteur, qui est actuellement connu du processus, envoie chaque message. Il est clair que les processus peuvent être désynchronisés, ils peuvent avoir des temps complètement différents. Néanmoins, le système équilibre en quelque sorte l'horloge avec une telle messagerie. Que se passe-t-il dans ce cas?J'ai divisé ce gros fragment en deux pour qu'il soit clair: les amis peuvent vivre dans un nœud qui contient un morceau de la collection, et Feed peut vivre dans un autre nœud qui contient un morceau de cette collection. C'est clair comment ils peuvent se détourner? Tout d'abord, Feed dit «Répliqué», puis Amis. Si le système ne fournit aucune garantie que Feed ne sera pas affiché jusqu'à ce que les dépendances Friends dans la collection Friends soient également livrées, alors nous aurons juste une situation que j'ai mentionnée.Vous voyez comment le temps du compteur augmente logiquement sur le flux: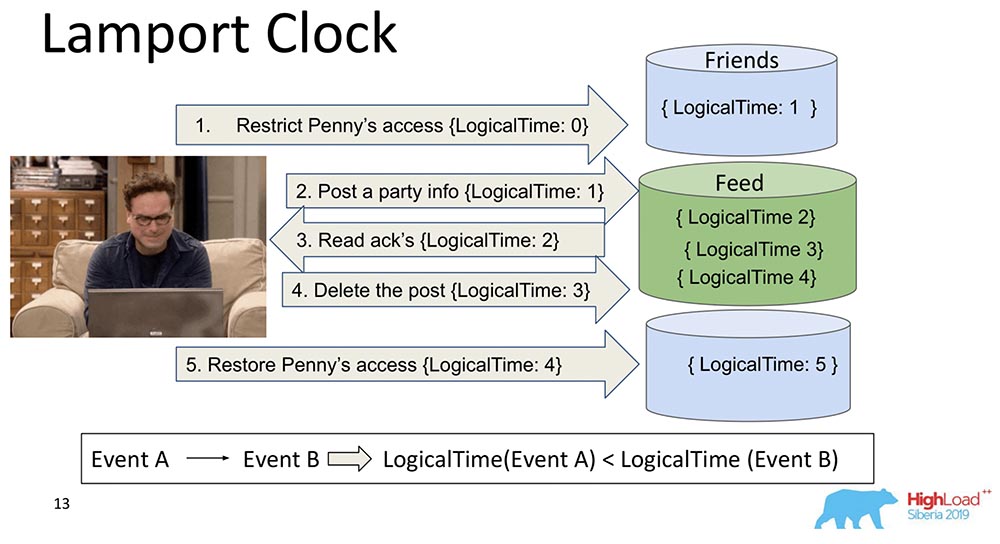 Ainsi, la propriété principale de cette horloge Lamport et de la cohérence causale (expliquée par l'horloge Lamport) est la suivante: si nous avons des événements A et B et que l'événement B dépend de l'événement A *, il s'ensuit que le LogicalTime de l'événement A est moins que LogicalTime de l'événement B.* On dit parfois que A s'est produit avant B, c'est-à-dire A s'est produit avant B - c'est une sorte de relation qui ordonne partiellement l'ensemble des événements qui se sont généralement produits.L'inverse est faux. C'est en fait l'un des principaux inconvénients de l'horloge Lamport - la commande partielle. Il y a un concept d'événements simultanés, c'est-à-dire d'événements dans lesquels ni (A ne s'est produit avant B) ni (A s'est produit avant B). Un exemple est l'ajout parallèle de Leonard à des amis de quelqu'un d'autre (pas même Leonard, mais Sheldon, par exemple).C'est la propriété qui est souvent utilisée lorsque vous travaillez avec des montres Lamport: elles regardent exactement la fonction et en tirent une conclusion - peut-être que ces événements sont dépendants. Parce que dans un sens, cela est vrai: si LogicalTime A est inférieur à LogicalTime B, alors B ne peut pas se produire avant A; et si plus, alors peut-être.
Ainsi, la propriété principale de cette horloge Lamport et de la cohérence causale (expliquée par l'horloge Lamport) est la suivante: si nous avons des événements A et B et que l'événement B dépend de l'événement A *, il s'ensuit que le LogicalTime de l'événement A est moins que LogicalTime de l'événement B.* On dit parfois que A s'est produit avant B, c'est-à-dire A s'est produit avant B - c'est une sorte de relation qui ordonne partiellement l'ensemble des événements qui se sont généralement produits.L'inverse est faux. C'est en fait l'un des principaux inconvénients de l'horloge Lamport - la commande partielle. Il y a un concept d'événements simultanés, c'est-à-dire d'événements dans lesquels ni (A ne s'est produit avant B) ni (A s'est produit avant B). Un exemple est l'ajout parallèle de Leonard à des amis de quelqu'un d'autre (pas même Leonard, mais Sheldon, par exemple).C'est la propriété qui est souvent utilisée lorsque vous travaillez avec des montres Lamport: elles regardent exactement la fonction et en tirent une conclusion - peut-être que ces événements sont dépendants. Parce que dans un sens, cela est vrai: si LogicalTime A est inférieur à LogicalTime B, alors B ne peut pas se produire avant A; et si plus, alors peut-être.Horloge vectorielle
Le développement logique des montres Lamport est l'horloge vectorielle. Ils diffèrent en ce que chaque nœud qui est ici contient sa propre horloge distincte, et ils sont transmis en tant que vecteur.Dans ce cas, vous voyez que l'index zéro du vecteur est responsable de Feed, et le premier index du vecteur est pour Friends (chacun de ces nœuds). Et maintenant, ils vont augmenter: l'indice zéro du "Feed" augmente lors de l'enregistrement - 1, 2, 3: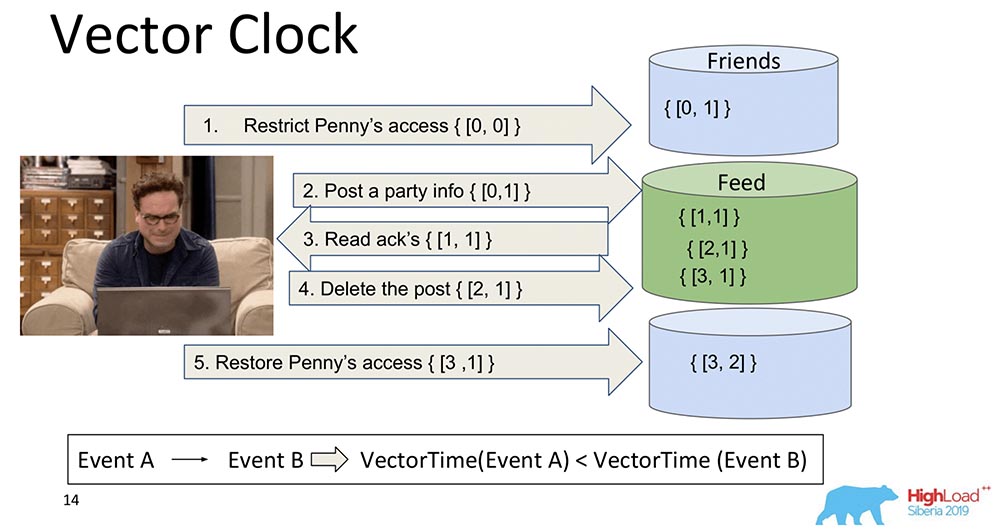 Comment l'horloge vectorielle est-elle meilleure? Le fait qu'ils peuvent déterminer quels événements sont simultanés et quand ils se produisent sur différents nœuds. Ceci est très important pour un système de partage comme le MongoBD. Cependant, nous n'avons pas choisi cela, bien que ce soit une chose merveilleuse, et cela fonctionne très bien, et cela nous conviendrait probablement ...Si nous avons 10 000 fragments, nous ne pouvons pas transférer 10 000 composants, même si nous compressons, nous pensons à autre chose - tout de même, la charge utile sera plusieurs fois inférieure au volume de ce vecteur entier. Par conséquent, broyant nos cœurs et nos dents, nous avons abandonné cette approche et sommes passés à une autre.
Comment l'horloge vectorielle est-elle meilleure? Le fait qu'ils peuvent déterminer quels événements sont simultanés et quand ils se produisent sur différents nœuds. Ceci est très important pour un système de partage comme le MongoBD. Cependant, nous n'avons pas choisi cela, bien que ce soit une chose merveilleuse, et cela fonctionne très bien, et cela nous conviendrait probablement ...Si nous avons 10 000 fragments, nous ne pouvons pas transférer 10 000 composants, même si nous compressons, nous pensons à autre chose - tout de même, la charge utile sera plusieurs fois inférieure au volume de ce vecteur entier. Par conséquent, broyant nos cœurs et nos dents, nous avons abandonné cette approche et sommes passés à une autre.Spanner TrueTime. Horloge atomique
J'ai dit qu'il y aurait une histoire à propos de Spanner. C'est une bonne chose, au 21e siècle: horloges atomiques, synchronisation GPS.Quelle idée? Spanner est un système Google qui a récemment été mis à la disposition des utilisateurs (ils y ont attaché SQL). Chaque transaction y a un horodatage. Étant donné que l'heure est synchronisée *, chaque événement peut être affecté à une heure spécifique - l'horloge atomique a un temps d'attente, après quoi il est garanti qu'un autre temps se produira. Ainsi, en écrivant simplement dans la base de données et en attendant un certain laps de temps, la sérialisation de l'événement est automatiquement garantie. Ils ont le modèle de cohérence le plus solide, qui en principe peut être imaginé - c'est la cohérence externe.* C'est le principal problème des montres Lampart - elles ne sont jamais synchrones sur les systèmes distribués. Ils peuvent diverger, même avec NTP, ils ne fonctionnent toujours pas très bien. "Spanner" a une horloge atomique et la synchronisation semble être alors microsecondes.Pourquoi n'avons-nous pas choisi? Nous ne supposons pas que nos utilisateurs ont une horloge atomique intégrée. Quand ils apparaissent, étant intégrés dans chaque ordinateur portable, il y aura une sorte de synchronisation GPS super cool - alors oui ... En attendant, le meilleur qui soit possible est Amazon, des stations de base pour les fanatiques ... Par conséquent, nous avons utilisé d'autres montres.
Ainsi, en écrivant simplement dans la base de données et en attendant un certain laps de temps, la sérialisation de l'événement est automatiquement garantie. Ils ont le modèle de cohérence le plus solide, qui en principe peut être imaginé - c'est la cohérence externe.* C'est le principal problème des montres Lampart - elles ne sont jamais synchrones sur les systèmes distribués. Ils peuvent diverger, même avec NTP, ils ne fonctionnent toujours pas très bien. "Spanner" a une horloge atomique et la synchronisation semble être alors microsecondes.Pourquoi n'avons-nous pas choisi? Nous ne supposons pas que nos utilisateurs ont une horloge atomique intégrée. Quand ils apparaissent, étant intégrés dans chaque ordinateur portable, il y aura une sorte de synchronisation GPS super cool - alors oui ... En attendant, le meilleur qui soit possible est Amazon, des stations de base pour les fanatiques ... Par conséquent, nous avons utilisé d'autres montres.Horloge hybride
C'est en fait ce qui coche le «MongoBD» tout en assurant la cohérence causale. Quels sont-ils hybrides? Un hybride est une valeur scalaire, mais il se compose de deux composants:
- Le premier est l'ère Unix (combien de secondes se sont écoulées depuis le "début du monde informatique").
- Le second est un incrément, également un entier non signé 32 bits.
C'est tout, en fait. Il existe une telle approche: la partie responsable de l'heure est synchronisée en permanence avec l'horloge; chaque fois qu'une mise à jour se produit, cette partie est synchronisée avec l'horloge et il s'avère que l'heure est toujours plus ou moins correcte, et l'incrémentation vous permet de distinguer les événements qui se sont produits en même temps.Pourquoi est-ce important pour MongoBD? Parce qu'il vous permet de créer des restaurations de sauvegarde à un certain moment, c'est-à-dire que l'événement est indexé par le temps. Ceci est important lorsque certains événements sont nécessaires; pour une base de données, les événements sont des modifications de la base de données qui se produisent à certains moments dans le temps.Je ne vous dirai que la raison la plus importante (s'il vous plaît, ne le dites à personne)! Nous l'avons fait parce que les données indexées ordonnées dans MongoDB OpLog ressemblent à ceci. OpLog est une structure de données qui contient absolument toutes les modifications dans la base de données: elles vont d'abord à OpLog, puis elles sont déjà appliquées au stockage lui-même dans le cas où il s'agit d'une date ou d'un fragment répliqué.C'était la raison principale. Néanmoins, il existe également des exigences pratiques pour développer la base de données, ce qui signifie qu'elle doit être simple - il y a peu de code, aussi peu de choses brisées que possible qui doivent être réécrites et testées. Le fait que nos oplogs aient été indexés par une montre hybride nous a beaucoup aidés et nous a permis de faire le bon choix. Cela a vraiment payé et a fonctionné comme par magie sur le tout premier prototype. C'était très cool!Synchronisation d'horloge
Il existe plusieurs méthodes de synchronisation décrites dans la littérature scientifique. Je parle de synchronisation lorsque nous avons deux fragments différents. S'il n'y a qu'un seul jeu de répliques, il n'y a pas besoin de synchronisation: c'est un «maître unique»; nous avons un OpLog dans lequel toutes les modifications entrent - dans ce cas, tout est déjà séquentiellement ordonné dans le "Oplog" lui-même. Mais si nous avons deux fragments différents, la synchronisation de l'heure est importante ici. Ici, les horloges vectorielles ont aidé davantage! Mais nous n'en avons pas. Le deuxième est Heartbeats. Vous pouvez échanger certains signaux qui se produisent à chaque unité de temps. Mais les Hartbits sont trop lents, nous ne pouvons pas fournir de latence à notre client.Le vrai temps est, bien sûr, une chose merveilleuse. Mais, encore une fois, c'est probablement l'avenir ... Bien que l'Atlas puisse déjà être fait, il existe déjà des synchroniseurs horaires "amazoniens" rapides. Mais il ne sera pas accessible à tous.Le bavardage, c'est quand tous les messages incluent du temps. C'est à peu près ce que nous utilisons. Chaque message entre les nœuds, un pilote, un routeur de nœuds de données, absolument tout pour «MongoDB» - ce sont des éléments, des composants de base de données qui contiennent une horloge qui coule. Partout où ils ont le sens du temps hybride, il se transmet. 64 bits? Cela permet, c'est possible.
Le deuxième est Heartbeats. Vous pouvez échanger certains signaux qui se produisent à chaque unité de temps. Mais les Hartbits sont trop lents, nous ne pouvons pas fournir de latence à notre client.Le vrai temps est, bien sûr, une chose merveilleuse. Mais, encore une fois, c'est probablement l'avenir ... Bien que l'Atlas puisse déjà être fait, il existe déjà des synchroniseurs horaires "amazoniens" rapides. Mais il ne sera pas accessible à tous.Le bavardage, c'est quand tous les messages incluent du temps. C'est à peu près ce que nous utilisons. Chaque message entre les nœuds, un pilote, un routeur de nœuds de données, absolument tout pour «MongoDB» - ce sont des éléments, des composants de base de données qui contiennent une horloge qui coule. Partout où ils ont le sens du temps hybride, il se transmet. 64 bits? Cela permet, c'est possible.Comment tout cela fonctionne-t-il ensemble?
Ici, je regarde un jeu de répliques pour le rendre un peu plus facile. Il y a primaire et secondaire. Le secondaire effectue la réplication et n'est pas toujours entièrement synchronisé avec le primaire.Il y a un insert (insert) dans les "Primaires" avec une certaine valeur de temps. Cet insert augmente le compteur interne de 11, s'il est maximum. Ou il vérifiera les valeurs d'horloge et se synchronisera par l'horloge si l'horloge est plus grande. Cela vous permet de trier par heure.Après avoir enregistré un disque, un moment important se produit. Les heures sont en «MongoDB» et ne sont incrémentées que si elles sont enregistrées dans «Oplog». Il s'agit d'un événement qui modifie l'état du système. Absolument dans tous les articles classiques, un événement est considéré comme un message entrant dans un nœud: un message est arrivé - cela signifie que le système a changé d'état.Cela est dû au fait qu'au cours de l'étude, il n'est pas entièrement possible de comprendre comment ce message sera interprété. Nous savons avec certitude que s'il n'est pas reflété dans l '«Oplog», il ne sera en aucun cas interprété, et seule l'entrée dans l' «Oplog» est un changement dans l'état du système. Cela simplifie tout pour nous: le modèle simplifie et nous permet d'organiser dans le cadre d'un jeu de répliques, et bien d'autres choses utiles.Il renvoie la valeur qui a déjà été enregistrée dans le «Oplog» - nous savons que dans le «Oplog» cette valeur se trouve déjà, et son heure est 12. Maintenant, disons, la lecture commence à partir d'un autre nœud (secondaire), et elle transfère déjà après ClusterTime lui-même message. Il dit: «J'ai besoin de tout ce qui s'est passé après au moins 12 ou pendant douze» (voir fig. Ci-dessus).C'est ce qu'on appelle Causal a consistent (CAT). Il existe un tel concept en théorie qu'il s'agit d'une tranche de temps, qui est cohérente en soi. Dans ce cas, nous pouvons dire que c'est l'état du système qui a été observé au moment 12.Maintenant, il n'y a rien ici, car il semble imiter la situation lorsque le secondaire a besoin de répliquer les données du primaire. Il attend ... Et maintenant, les données sont arrivées - renvoie ces valeurs.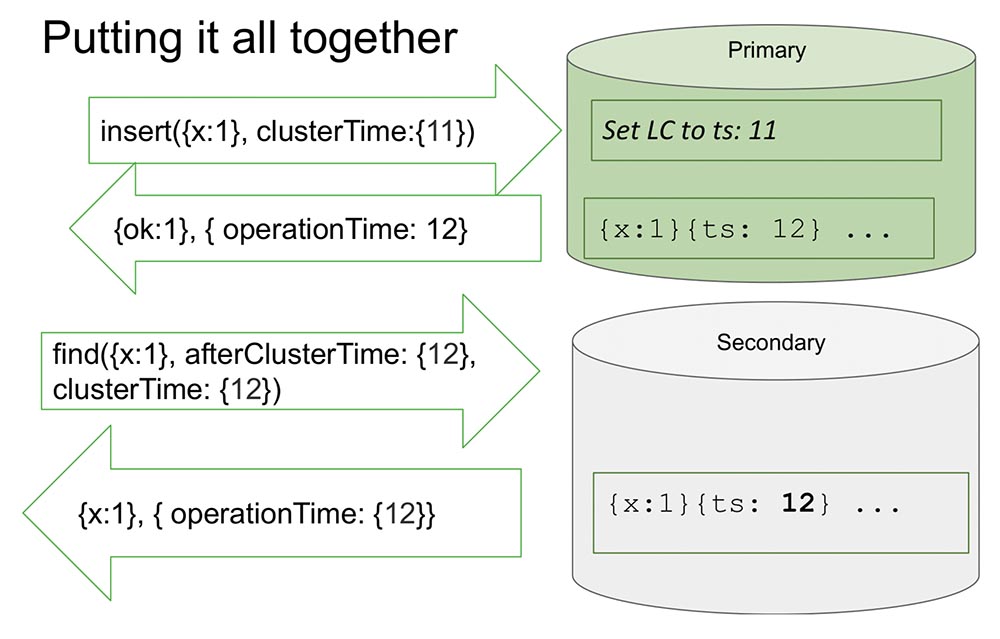 Voilà comment tout cela fonctionne. Presque.Que signifie "presque"? Supposons qu'il y ait une personne qui a lu et compris comment tout cela fonctionne. J'ai réalisé que chaque fois que ClusterTime se produit, il met à jour l'horloge logique interne, puis l'enregistrement suivant augmente d'une unité. Cette fonction occupe 20 lignes. Supposons que cette personne transmette le plus grand nombre possible de 64 bits, moins un.Pourquoi moins un? Parce que l'horloge interne est substituée à cette valeur (évidemment, c'est la plus grande possible et plus que l'heure actuelle), alors il y aura une entrée dans le "Olog", et l'horloge augmentera d'une unité de plus - et il y aura déjà une valeur maximale (il y a simplement toutes les unités, il n'y a nulle part où aller , entiers non signés).Il est clair qu'après cela, le système devient complètement inaccessible pour rien. Il ne peut être déchargé, nettoyé - beaucoup de travail manuel. Disponibilité totale:
Voilà comment tout cela fonctionne. Presque.Que signifie "presque"? Supposons qu'il y ait une personne qui a lu et compris comment tout cela fonctionne. J'ai réalisé que chaque fois que ClusterTime se produit, il met à jour l'horloge logique interne, puis l'enregistrement suivant augmente d'une unité. Cette fonction occupe 20 lignes. Supposons que cette personne transmette le plus grand nombre possible de 64 bits, moins un.Pourquoi moins un? Parce que l'horloge interne est substituée à cette valeur (évidemment, c'est la plus grande possible et plus que l'heure actuelle), alors il y aura une entrée dans le "Olog", et l'horloge augmentera d'une unité de plus - et il y aura déjà une valeur maximale (il y a simplement toutes les unités, il n'y a nulle part où aller , entiers non signés).Il est clair qu'après cela, le système devient complètement inaccessible pour rien. Il ne peut être déchargé, nettoyé - beaucoup de travail manuel. Disponibilité totale: De plus, si cela est répliqué ailleurs, le cluster entier se couche simplement. Une situation absolument inacceptable que n'importe qui peut organiser très rapidement et simplement! Par conséquent, nous avons considéré ce moment comme l'un des plus importants. Comment l'empêcher?
De plus, si cela est répliqué ailleurs, le cluster entier se couche simplement. Une situation absolument inacceptable que n'importe qui peut organiser très rapidement et simplement! Par conséquent, nous avons considéré ce moment comme l'un des plus importants. Comment l'empêcher?Notre façon est de signer clusterTime
Il est donc transmis dans le message (avant le texte bleu). Mais nous avons également commencé à générer une signature (texte bleu): la signature est générée par une clé qui est stockée à l'intérieur de la base de données, à l'intérieur du périmètre protégé; il est généré, mis à jour (les utilisateurs ne voient rien). Le hachage est généré et chaque message est signé lors de la création et validé à réception.Probablement, la question se pose chez les gens: "Combien cela ralentit-il?" J'ai dit que cela devrait fonctionner rapidement, surtout en l'absence de cette fonctionnalité.Que signifie utiliser la cohérence causale dans ce cas? Cela affichera le paramètre afterClusterTime. Et sans cela, il passera simplement des valeurs de toute façon. Le bavardage, depuis la version 3.6, fonctionne toujours.Si nous laissons la génération constante de signatures, cela ralentira le système même en l'absence de fonctionnalités, ce qui ne correspond pas à nos approches et exigences. Et qu'avons-nous fait?
signature est générée par une clé qui est stockée à l'intérieur de la base de données, à l'intérieur du périmètre protégé; il est généré, mis à jour (les utilisateurs ne voient rien). Le hachage est généré et chaque message est signé lors de la création et validé à réception.Probablement, la question se pose chez les gens: "Combien cela ralentit-il?" J'ai dit que cela devrait fonctionner rapidement, surtout en l'absence de cette fonctionnalité.Que signifie utiliser la cohérence causale dans ce cas? Cela affichera le paramètre afterClusterTime. Et sans cela, il passera simplement des valeurs de toute façon. Le bavardage, depuis la version 3.6, fonctionne toujours.Si nous laissons la génération constante de signatures, cela ralentira le système même en l'absence de fonctionnalités, ce qui ne correspond pas à nos approches et exigences. Et qu'avons-nous fait?Fais-le vite!
Une chose assez simple, mais l'astuce est intéressante - je vais la partager, peut-être que quelqu'un sera intéressé.Nous avons un hachage qui stocke les données signées. Toutes les données passent par le cache. Le cache ne signe pas spécifiquement l'heure, mais la plage. Lorsqu'une certaine valeur arrive, nous générons une plage, masquons les 16 derniers bits et nous signons cette valeur: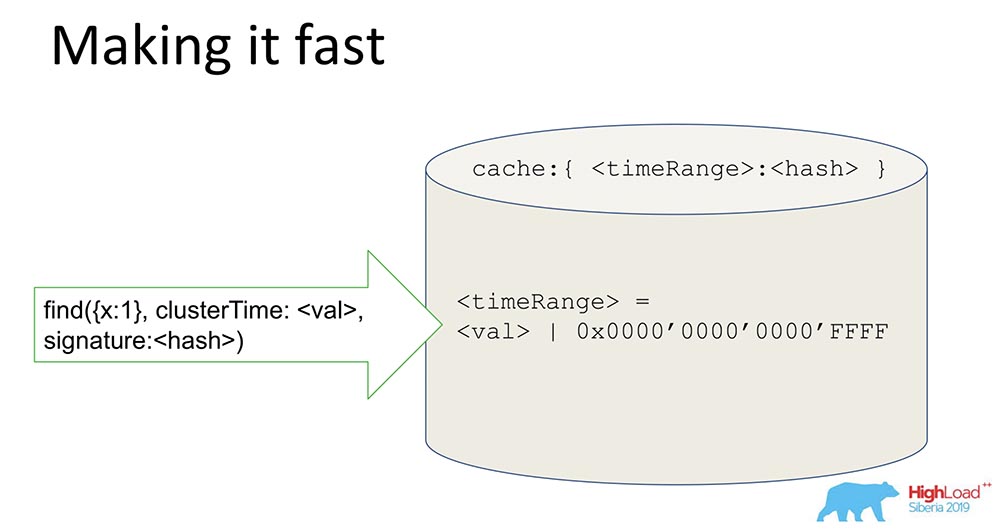 En recevant une telle signature, nous accélérons (conditionnellement) le système de 65 000 fois. Cela fonctionne très bien: quand ils ont fait les expériences, le temps où nous avions une mise à jour cohérente y était vraiment réduit de 10 mille fois. Il est clair que lorsqu'ils sont en désaccord, cela ne fonctionne pas. Mais dans la plupart des cas pratiques, cela fonctionne. La combinaison de la signature Range avec la signature a résolu le problème de sécurité.
En recevant une telle signature, nous accélérons (conditionnellement) le système de 65 000 fois. Cela fonctionne très bien: quand ils ont fait les expériences, le temps où nous avions une mise à jour cohérente y était vraiment réduit de 10 mille fois. Il est clair que lorsqu'ils sont en désaccord, cela ne fonctionne pas. Mais dans la plupart des cas pratiques, cela fonctionne. La combinaison de la signature Range avec la signature a résolu le problème de sécurité.Qu'avons-nous appris?
Leçons que nous en avons tirées:- , , , . - ( , . .), , . , , , . – .
, , («», ) – . ? . , . – , . - . , «» , , , availability, latency .
- La dernière est que nous avons dû considérer différentes idées et combiner plusieurs articles généralement différents dans une même approche. L'idée de signer, par exemple, est venue d'un article qui a examiné le protocole Paxos, qui pour les non-byzantins Faylor dans le protocole d'autorisation, pour les byzantins en dehors du protocole d'autorisation ... En général, c'est exactement ce que nous avons fait au final.
Il n'y a absolument rien de nouveau ici! Mais dès que nous avons tout mélangé ... C'est comme dire que la recette de la salade Olivier est absurde, car les œufs, la mayonnaise et les concombres ont déjà été inventés ... C'est à peu près la même histoire.
 Je terminerai là-dessus. Remercier!
Je terminerai là-dessus. Remercier!Des questions
Question du public (ci-après - B): - Merci, Michael pour le rapport! Le thème du temps est intéressant. Vous utilisez des ragots. Ils ont dit que chacun a son propre temps, tout le monde connaît son heure locale. Si je comprends bien, nous avons un pilote - il peut y avoir de nombreux clients avec des pilotes, des planificateurs de requêtes aussi, beaucoup d'éclats ... Mais à quoi va servir le système si nous avons soudainement un écart: quelqu'un décide qu'il est pour une minute devant, quelqu'un - une minute derrière? Où allons-nous nous retrouver?MT: - Grande question vraiment! Je voulais juste parler des éclats. Si je comprends bien la question, nous avons cette situation: il y a les fragments 1 et 2, la lecture se produit à partir de ces deux fragments - ils ont un écart, ils n'interagissent pas l'un avec l'autre, parce que le temps qu'ils connaissent est différent, en particulier le temps Ils existent dans les oplogs.Supposons que le fragment 1 ait enregistré un million d'enregistrements, que le fragment 2 n'a rien fait du tout et que la demande soit arrivée en deux fragments. Et le premier a AfterClusterTime plus d'un million. Dans une telle situation, comme je l'ai expliqué, le fragment 2 ne répondra jamais du tout.Q: - Je voulais savoir comment ils se synchronisent et choisissent une heure logique?MT: - Très facile à synchroniser. Shard, quand afterClusterTime vient à lui, et il ne trouve pas l'heure dans le «Catch» - ne lance pas approuvé. Autrement dit, il lève la main à cette valeur avec ses mains. Cela signifie qu'il n'a aucun événement correspondant à cette requête. Il crée cet événement artificiellement et devient ainsi le Causal Consistent.Q: - Et si après cela, d'autres événements perdus quelque part sur le réseau lui reviennent encore?MT:- Le tesson est agencé de façon à ce qu'il ne vienne plus, puisqu'il s'agit d'un seul maître. S'il a déjà enregistré, alors ils ne viendront pas, mais seront après. Il ne peut pas arriver que quelque part quelque chose soit bloqué, alors il ne fera pas d'écriture, puis ces événements sont arrivés - et la cohérence causale a été violée. Quand il n'écrit pas, ils doivent tous venir ensuite (il les attendra). À:- J'ai quelques questions concernant les lignes. La cohérence causale suppose qu'il existe une certaine file d'attente d'actions à effectuer. Que se passe-t-il si nous perdons un colis? Alors le 10 est allé, le 11 ... le 12 a disparu, et tout le monde attend qu'il se réalise. Et soudain notre voiture est morte, nous ne pouvons plus rien faire. Y a-t-il une longueur de file d'attente maximale qui s'accumule avant son exécution? Quel échec fatal survient lorsqu'un état est perdu? De plus, si nous écrivons qu'il existe une sorte d'état antérieur, alors devrions-nous en quelque sorte partir de lui? Et ils ne l'ont pas poussé!MT:- Aussi une merveilleuse question! Qu'est-ce que nous faisons? MongoDB a le concept d'enregistrements de quorum, les lectures de quorum. Quand un message peut-il disparaître? Lorsque l'enregistrement n'est pas le quorum ou lorsque la lecture n'est pas le quorum (certaines ordures peuvent également coller).En ce qui concerne la cohérence causale, nous avons effectué un grand test expérimental, qui a abouti au fait que lorsque l'enregistrement et la lecture ne sont pas du quorum, des violations de cohérence causale se produisent. Exactement ce que vous dites!Notre conseil: utilisez au moins la lecture du quorum lorsque vous utilisez la cohérence causale. Dans ce cas, rien ne sera perdu, même si l'enregistrement de quorum est perdu ... Il s'agit d'une situation orthogonale: si l'utilisateur ne veut pas que les données soient perdues, vous devez utiliser l'enregistrement de quorum. La cohérence causale ne garantit pas la durabilité. La garantie de durabilité est fournie par la réplication et les machines associées à la réplication.Q: - Lorsque nous créons une instance que le sharding fait pour nous (pas maître, mais esclave, respectivement), elle s'appuie sur l'heure unix de sa propre machine ou sur l'heure du «maître»; synchronisé pour la première fois ou périodiquement?MT:- Maintenant, je vais être clair. Éclat (c.-à-d. Partition horizontale) - il y a toujours primaire. Et dans un éclat, il peut y avoir un «maître» et il peut y avoir des répliques. Mais le fragment prend toujours en charge l'écriture, car il doit prendre en charge un certain domaine (le principal est dans le fragment).Q: - Autrement dit, tout dépend uniquement du "maître"? Toujours utiliser l'heure "maître"?MT: - Oui. On peut dire au figuré: l'horloge tourne quand il y a un enregistrement dans le "master", dans le "Oplog".Q: - Nous avons un client qui se connecte, et il n'a besoin de rien savoir du temps?MT:- En général, vous n'avez besoin de rien savoir! Si nous parlons de la façon dont cela fonctionne sur le client: chez le client, lorsqu'il veut utiliser la cohérence causale, il doit ouvrir une session. Maintenant, tout est là: à la fois les transactions dans la session et la récupération des droits ... Une session est un ordre des événements logiques se produisant avec un client.S'il ouvre cette session et dit qu'il souhaite la cohérence causale (si par défaut la session prend en charge la cohérence causale), tout fonctionne automatiquement. Le conducteur se souvient de cette heure et l'augmente lorsqu'il reçoit un nouveau message. Il se souvient de la réponse qui a renvoyé la précédente du serveur qui a renvoyé les données. La demande suivante contiendra afterCluster ("le temps est supérieur à cela").Le client n'a absolument besoin de rien savoir! C'est absolument opaque pour lui. Si les gens utilisent ces fonctionnalités, que puis-je faire? Tout d'abord, vous pouvez lire les secondaires en toute sécurité: vous pouvez écrire en primaire, lire à partir de secondaires répliqués géographiquement et être sûr que cela fonctionne. Dans le même temps, les sessions enregistrées sur Primary peuvent être transférées même sur Secondary, c'est-à-dire que vous pouvez utiliser non pas une session, mais plusieurs.Q: - Le thème de la cohérence éventuelle est étroitement lié à la nouvelle couche de science informatique - types de données CRDT (Conflict-free Replicated Data Types). Avez-vous envisagé l'intégration de ces types de données dans la base de données et que pouvez-vous en dire?MT: - Bonne question! CRDT a du sens pour les conflits d'écriture: dans MongoDB - maître unique.À:- J'ai une question des devops. Dans le monde réel, il y a de telles situations jésuites lorsque l'échec byzantin se produit et que les méchants à l'intérieur du périmètre protégé commencent à s'en tenir au protocole, à envoyer des colis d'artisanat d'une manière spéciale?
À:- J'ai quelques questions concernant les lignes. La cohérence causale suppose qu'il existe une certaine file d'attente d'actions à effectuer. Que se passe-t-il si nous perdons un colis? Alors le 10 est allé, le 11 ... le 12 a disparu, et tout le monde attend qu'il se réalise. Et soudain notre voiture est morte, nous ne pouvons plus rien faire. Y a-t-il une longueur de file d'attente maximale qui s'accumule avant son exécution? Quel échec fatal survient lorsqu'un état est perdu? De plus, si nous écrivons qu'il existe une sorte d'état antérieur, alors devrions-nous en quelque sorte partir de lui? Et ils ne l'ont pas poussé!MT:- Aussi une merveilleuse question! Qu'est-ce que nous faisons? MongoDB a le concept d'enregistrements de quorum, les lectures de quorum. Quand un message peut-il disparaître? Lorsque l'enregistrement n'est pas le quorum ou lorsque la lecture n'est pas le quorum (certaines ordures peuvent également coller).En ce qui concerne la cohérence causale, nous avons effectué un grand test expérimental, qui a abouti au fait que lorsque l'enregistrement et la lecture ne sont pas du quorum, des violations de cohérence causale se produisent. Exactement ce que vous dites!Notre conseil: utilisez au moins la lecture du quorum lorsque vous utilisez la cohérence causale. Dans ce cas, rien ne sera perdu, même si l'enregistrement de quorum est perdu ... Il s'agit d'une situation orthogonale: si l'utilisateur ne veut pas que les données soient perdues, vous devez utiliser l'enregistrement de quorum. La cohérence causale ne garantit pas la durabilité. La garantie de durabilité est fournie par la réplication et les machines associées à la réplication.Q: - Lorsque nous créons une instance que le sharding fait pour nous (pas maître, mais esclave, respectivement), elle s'appuie sur l'heure unix de sa propre machine ou sur l'heure du «maître»; synchronisé pour la première fois ou périodiquement?MT:- Maintenant, je vais être clair. Éclat (c.-à-d. Partition horizontale) - il y a toujours primaire. Et dans un éclat, il peut y avoir un «maître» et il peut y avoir des répliques. Mais le fragment prend toujours en charge l'écriture, car il doit prendre en charge un certain domaine (le principal est dans le fragment).Q: - Autrement dit, tout dépend uniquement du "maître"? Toujours utiliser l'heure "maître"?MT: - Oui. On peut dire au figuré: l'horloge tourne quand il y a un enregistrement dans le "master", dans le "Oplog".Q: - Nous avons un client qui se connecte, et il n'a besoin de rien savoir du temps?MT:- En général, vous n'avez besoin de rien savoir! Si nous parlons de la façon dont cela fonctionne sur le client: chez le client, lorsqu'il veut utiliser la cohérence causale, il doit ouvrir une session. Maintenant, tout est là: à la fois les transactions dans la session et la récupération des droits ... Une session est un ordre des événements logiques se produisant avec un client.S'il ouvre cette session et dit qu'il souhaite la cohérence causale (si par défaut la session prend en charge la cohérence causale), tout fonctionne automatiquement. Le conducteur se souvient de cette heure et l'augmente lorsqu'il reçoit un nouveau message. Il se souvient de la réponse qui a renvoyé la précédente du serveur qui a renvoyé les données. La demande suivante contiendra afterCluster ("le temps est supérieur à cela").Le client n'a absolument besoin de rien savoir! C'est absolument opaque pour lui. Si les gens utilisent ces fonctionnalités, que puis-je faire? Tout d'abord, vous pouvez lire les secondaires en toute sécurité: vous pouvez écrire en primaire, lire à partir de secondaires répliqués géographiquement et être sûr que cela fonctionne. Dans le même temps, les sessions enregistrées sur Primary peuvent être transférées même sur Secondary, c'est-à-dire que vous pouvez utiliser non pas une session, mais plusieurs.Q: - Le thème de la cohérence éventuelle est étroitement lié à la nouvelle couche de science informatique - types de données CRDT (Conflict-free Replicated Data Types). Avez-vous envisagé l'intégration de ces types de données dans la base de données et que pouvez-vous en dire?MT: - Bonne question! CRDT a du sens pour les conflits d'écriture: dans MongoDB - maître unique.À:- J'ai une question des devops. Dans le monde réel, il y a de telles situations jésuites lorsque l'échec byzantin se produit et que les méchants à l'intérieur du périmètre protégé commencent à s'en tenir au protocole, à envoyer des colis d'artisanat d'une manière spéciale? MT: - Les méchants à l'intérieur du périmètre sont comme un cheval de Troie! Les mauvaises personnes à l'intérieur du périmètre peuvent faire beaucoup de mauvaises choses.Q: - Il est clair que laisser un trou dans le serveur, à peu près, à travers lequel vous pouvez coller le zoo des éléphants et effondrer le cluster entier pour toujours ... Il faudra du temps pour une récupération manuelle ... C'est, pour le moins, mal. D'un autre côté, c'est curieux: dans la vraie vie, dans la pratique, il y a des situations où des attaques internes naturellement similaires se produisent?MT:- Comme je rencontre rarement des failles de sécurité dans la vie réelle, je ne peux pas dire - peut-être qu'elles se produisent. Mais si nous parlons de philosophie de développement, nous le pensons: nous avons un périmètre qui fournit les gars qui assurent la sécurité - c'est un château, un mur; et à l'intérieur du périmètre, vous pouvez faire tout ce que vous voulez. Il est clair qu'il y a des utilisateurs avec la possibilité de ne regarder que, et il y a des utilisateurs avec la possibilité d'effacer le répertoire.Selon les droits, les dommages que les utilisateurs peuvent faire peuvent être une souris ou un éléphant. Il est clair qu'un utilisateur disposant de tous les droits peut tout faire. Un utilisateur avec des droits de préjudice non étendus peut causer beaucoup moins. En particulier, il ne peut pas briser le système.À:- Dans le périmètre sécurisé, quelqu'un a grimpé pour former des protocoles inattendus pour le serveur afin de configurer le serveur avec un cancer, et si vous avez de la chance, alors tout le cluster ... Est-ce que ça arrive si bien?MT: - Je n'ai jamais entendu parler de telles choses. Le fait que vous puissiez ainsi remplir le serveur n'est pas un secret. Remplir à l'intérieur, être du protocole, être un utilisateur autorisé qui peut écrire quelque chose comme ça dans un message ... En fait, c'est impossible, car de toute façon ce sera vérifié. Il est possible de désactiver cette authentification pour les utilisateurs qui ne le souhaitent pas - c'est alors leur problème; grosso modo, ils ont eux-mêmes détruit les murs et vous pouvez y entasser un éléphant, qui va fouler aux pieds ... En général, vous pouvez vous habiller en réparateur, venez le chercher!À:- Merci pour le rapport. Sergey (Yandex). Dans «Mong», il existe une constante qui limite le nombre de membres votants dans le jeu de répliques, et cette constante est 7 (sept). Pourquoi est-ce une constante? Pourquoi n'est-ce pas une sorte de paramètre?MT: - Replica Set, nous avons également 40 nœuds. Il y a toujours une majorité. Je ne sais pas quelle version ...Q: - Dans le jeu de réplicas, vous pouvez exécuter des membres non votants, mais votant - un maximum de 7. Comment, dans ce cas, subir un arrêt si le jeu de réplicas est tiré vers 3 centres de données? Un centre de données peut facilement s'éteindre et une autre machine tombe en panne.MT: - C'est déjà un peu en dehors du champ d'application du rapport. C'est une question courante. Peut-être que je pourrai alors lui dire.
MT: - Les méchants à l'intérieur du périmètre sont comme un cheval de Troie! Les mauvaises personnes à l'intérieur du périmètre peuvent faire beaucoup de mauvaises choses.Q: - Il est clair que laisser un trou dans le serveur, à peu près, à travers lequel vous pouvez coller le zoo des éléphants et effondrer le cluster entier pour toujours ... Il faudra du temps pour une récupération manuelle ... C'est, pour le moins, mal. D'un autre côté, c'est curieux: dans la vraie vie, dans la pratique, il y a des situations où des attaques internes naturellement similaires se produisent?MT:- Comme je rencontre rarement des failles de sécurité dans la vie réelle, je ne peux pas dire - peut-être qu'elles se produisent. Mais si nous parlons de philosophie de développement, nous le pensons: nous avons un périmètre qui fournit les gars qui assurent la sécurité - c'est un château, un mur; et à l'intérieur du périmètre, vous pouvez faire tout ce que vous voulez. Il est clair qu'il y a des utilisateurs avec la possibilité de ne regarder que, et il y a des utilisateurs avec la possibilité d'effacer le répertoire.Selon les droits, les dommages que les utilisateurs peuvent faire peuvent être une souris ou un éléphant. Il est clair qu'un utilisateur disposant de tous les droits peut tout faire. Un utilisateur avec des droits de préjudice non étendus peut causer beaucoup moins. En particulier, il ne peut pas briser le système.À:- Dans le périmètre sécurisé, quelqu'un a grimpé pour former des protocoles inattendus pour le serveur afin de configurer le serveur avec un cancer, et si vous avez de la chance, alors tout le cluster ... Est-ce que ça arrive si bien?MT: - Je n'ai jamais entendu parler de telles choses. Le fait que vous puissiez ainsi remplir le serveur n'est pas un secret. Remplir à l'intérieur, être du protocole, être un utilisateur autorisé qui peut écrire quelque chose comme ça dans un message ... En fait, c'est impossible, car de toute façon ce sera vérifié. Il est possible de désactiver cette authentification pour les utilisateurs qui ne le souhaitent pas - c'est alors leur problème; grosso modo, ils ont eux-mêmes détruit les murs et vous pouvez y entasser un éléphant, qui va fouler aux pieds ... En général, vous pouvez vous habiller en réparateur, venez le chercher!À:- Merci pour le rapport. Sergey (Yandex). Dans «Mong», il existe une constante qui limite le nombre de membres votants dans le jeu de répliques, et cette constante est 7 (sept). Pourquoi est-ce une constante? Pourquoi n'est-ce pas une sorte de paramètre?MT: - Replica Set, nous avons également 40 nœuds. Il y a toujours une majorité. Je ne sais pas quelle version ...Q: - Dans le jeu de réplicas, vous pouvez exécuter des membres non votants, mais votant - un maximum de 7. Comment, dans ce cas, subir un arrêt si le jeu de réplicas est tiré vers 3 centres de données? Un centre de données peut facilement s'éteindre et une autre machine tombe en panne.MT: - C'est déjà un peu en dehors du champ d'application du rapport. C'est une question courante. Peut-être que je pourrai alors lui dire.
Un peu de publicité :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en recommandant à vos amis, le cloud VPS pour les développeurs à partir de 4,99 $ , un analogue unique de serveurs d'entrée de gamme que nous avons inventé pour vous: Toute la vérité sur VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbit / s à partir de 19 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! En savoir plus sur la création d'un bâtiment d'infrastructure. classe c utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou? Source: https://habr.com/ru/post/undefined/
All Articles