HighLoad ++, Anastasia Tsymbalyuk, Stanislav Tselovalnikov (Sberbank): comment nous sommes devenus MDA
La prochaine conférence HighLoad ++ se tiendra les 6 et 7 avril 2020 à Saint-Pétersbourg,détails et billets ici . HighLoad ++ Siberia 2019. Salle "Krasnoyarsk". 25 juin, 14 h Résumés et présentation .Développer un système de gestion et de diffusion de données industrielles à partir de zéro n'est pas une tâche facile. Surtout quand il y a un arriéré complet, le temps de travail est d'un quart et les exigences du produit sont des turbulences perpétuelles. Nous dirons sur l'exemple de la construction d'un système de gestion des métadonnées, comment construire un système évolutif industriel dans un court laps de temps, qui comprend le stockage et la diffusion des données.Notre approche tire pleinement parti des métadonnées, du code SQL dynamique et de la génération de code basée sur Swagger codegen et les guidons. Cette solution réduit le temps de développement et de reconfiguration du système et l'ajout de nouveaux objets de gestion ne nécessite pas une seule ligne de nouveau code.Nous vous expliquerons comment cela fonctionne dans notre équipe: à quelles règles nous adhérons, quels outils nous utilisons, quelles difficultés nous avons rencontrées et comment nous les avons héroïquement surmontées.Anastasia Tsymbalyuk (ci-après - AC): - Mon nom est Nastya, et voici Stas!Stas Tselovalnikov (ci-après - SC): - Bonjour à tous!AC: - Aujourd'hui, nous allons vous parler de MDA et comment, en utilisant cette approche, nous avons réduit le temps de développement et introduit le monde à un système de gestion de métadonnées évolutif industriel. Hourra!SC: - Nastya, qu'est-ce que le MDA?AC: - Stas, je pense que nous allons passer à cela maintenant. Plus précisément, je vais en parler un peu à la fin de la présentation. Parlons d'abord de nous:
Nous dirons sur l'exemple de la construction d'un système de gestion des métadonnées, comment construire un système évolutif industriel dans un court laps de temps, qui comprend le stockage et la diffusion des données.Notre approche tire pleinement parti des métadonnées, du code SQL dynamique et de la génération de code basée sur Swagger codegen et les guidons. Cette solution réduit le temps de développement et de reconfiguration du système et l'ajout de nouveaux objets de gestion ne nécessite pas une seule ligne de nouveau code.Nous vous expliquerons comment cela fonctionne dans notre équipe: à quelles règles nous adhérons, quels outils nous utilisons, quelles difficultés nous avons rencontrées et comment nous les avons héroïquement surmontées.Anastasia Tsymbalyuk (ci-après - AC): - Mon nom est Nastya, et voici Stas!Stas Tselovalnikov (ci-après - SC): - Bonjour à tous!AC: - Aujourd'hui, nous allons vous parler de MDA et comment, en utilisant cette approche, nous avons réduit le temps de développement et introduit le monde à un système de gestion de métadonnées évolutif industriel. Hourra!SC: - Nastya, qu'est-ce que le MDA?AC: - Stas, je pense que nous allons passer à cela maintenant. Plus précisément, je vais en parler un peu à la fin de la présentation. Parlons d'abord de nous: je peux me décrire comme un chercheur de synergie dans les solutions informatiques industrielles.SC: - Et moi?
je peux me décrire comme un chercheur de synergie dans les solutions informatiques industrielles.SC: - Et moi?Que fait l'équipe SberData?
AC: - Et vous n'êtes qu'un mastodonte industriel, car vous avez apporté plus d'une solution au bal!SC: - En fait, nous travaillons ensemble à Sberbank dans la même équipe et gérons les métadonnées SberData: AC: - SberData, si c'est simple - c'est une plateforme analytique où toutes les pistes numériques de chaque client circulent. Si vous êtes un client de Sberbank, toutes les informations vous concernant y circulent exactement. De nombreux ensembles de données y sont stockés, mais nous comprenons que la quantité de données ne signifie pas leur qualité. Et les données sans contexte sont parfois totalement inutiles, car nous ne pouvons pas les appliquer, les interpréter, les protéger, les enrichir.Seules ces tâches sont résolues par des métadonnées. Ils nous montrent le contexte commercial et la composante technique des données, c'est-à-dire où elles sont apparues, comment elles ont été transformées, à quel point la description minimale, le balisage est maintenant. C'est déjà suffisant pour commencer à utiliser les données et à leur faire confiance. C'est précisément la tâche que les métadonnées résolvent.SC: - En d'autres termes, la mission de notre équipe est d'augmenter l'efficacité de la plateforme d'analyse d'informations Sberbank car les informations dont vous venez de parler doivent être livrées aux bonnes personnes, au bon moment et au bon endroit. Et rappelez-vous, vous avez également dit que si les données sont du pétrole moderne, les métadonnées sont une carte des gisements de ce pétrole.AC:- En effet, c'est une de mes brillantes déclarations, dont je suis très fier. Techniquement, cette tâche a été réduite au fait que nous devions créer un outil de gestion des métadonnées au sein de notre plateforme et assurer son cycle de vie complet.Mais pour plonger dans les problèmes de notre sujet et comprendre où nous en sommes, je vous suggère de revenir en arrière il y a 9 mois.Alors, imaginez: à l'extérieur de la fenêtre est le mois de novembre, les oiseaux ont tous volé vers le sud, nous sommes tristes ... Et à ce moment-là, nous avions un pilote réussi avec l'équipe, il y avait des clients - nous sommes tous restés dans la zone de confort jusqu'au point même de non-retour.
AC: - SberData, si c'est simple - c'est une plateforme analytique où toutes les pistes numériques de chaque client circulent. Si vous êtes un client de Sberbank, toutes les informations vous concernant y circulent exactement. De nombreux ensembles de données y sont stockés, mais nous comprenons que la quantité de données ne signifie pas leur qualité. Et les données sans contexte sont parfois totalement inutiles, car nous ne pouvons pas les appliquer, les interpréter, les protéger, les enrichir.Seules ces tâches sont résolues par des métadonnées. Ils nous montrent le contexte commercial et la composante technique des données, c'est-à-dire où elles sont apparues, comment elles ont été transformées, à quel point la description minimale, le balisage est maintenant. C'est déjà suffisant pour commencer à utiliser les données et à leur faire confiance. C'est précisément la tâche que les métadonnées résolvent.SC: - En d'autres termes, la mission de notre équipe est d'augmenter l'efficacité de la plateforme d'analyse d'informations Sberbank car les informations dont vous venez de parler doivent être livrées aux bonnes personnes, au bon moment et au bon endroit. Et rappelez-vous, vous avez également dit que si les données sont du pétrole moderne, les métadonnées sont une carte des gisements de ce pétrole.AC:- En effet, c'est une de mes brillantes déclarations, dont je suis très fier. Techniquement, cette tâche a été réduite au fait que nous devions créer un outil de gestion des métadonnées au sein de notre plateforme et assurer son cycle de vie complet.Mais pour plonger dans les problèmes de notre sujet et comprendre où nous en sommes, je vous suggère de revenir en arrière il y a 9 mois.Alors, imaginez: à l'extérieur de la fenêtre est le mois de novembre, les oiseaux ont tous volé vers le sud, nous sommes tristes ... Et à ce moment-là, nous avions un pilote réussi avec l'équipe, il y avait des clients - nous sommes tous restés dans la zone de confort jusqu'au point même de non-retour.Modèle de système de gestion des métadonnées
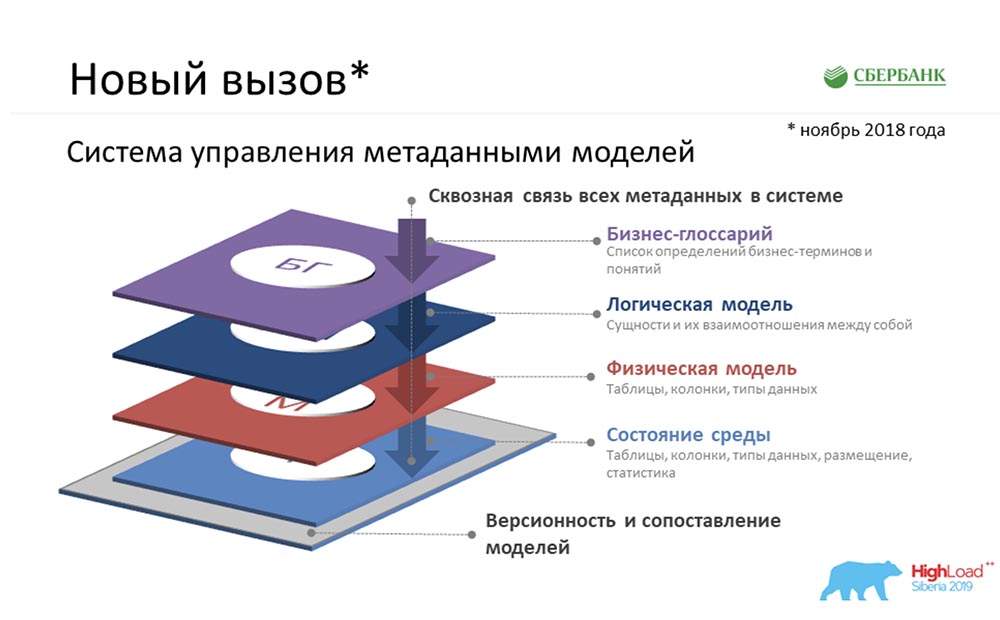 SC: - Il y avait autre chose que vous aviez dans une zone de confort ... En fait, nous avions pour mission de créer Metadata Broker, qui était censé donner la possibilité de communiquer avec nos clients, nos programmes, nos systèmes. Nos clients auraient dû avoir la possibilité au niveau du backend d'envoyer un type de package de métadonnées ou de le recevoir. Et nous, en fournissant cette fonction, à notre niveau avons dû accumuler les informations les plus cohérentes et pertinentes sur les métadonnées à quatre niveaux logiques:
SC: - Il y avait autre chose que vous aviez dans une zone de confort ... En fait, nous avions pour mission de créer Metadata Broker, qui était censé donner la possibilité de communiquer avec nos clients, nos programmes, nos systèmes. Nos clients auraient dû avoir la possibilité au niveau du backend d'envoyer un type de package de métadonnées ou de le recevoir. Et nous, en fournissant cette fonction, à notre niveau avons dû accumuler les informations les plus cohérentes et pertinentes sur les métadonnées à quatre niveaux logiques:- Niveau du glossaire métier.
- Le niveau du modèle logique.
- Le niveau du modèle physique.
- L'état de l'environnement que nous avons reçu en raison de l'inverse des environnements industriels.
Et tout cela doit être cohérent.AC: - Oui, vraiment. Mais ici, j'expliquerais aussi d'une manière simple, car je n'exclue pas que le sujet soit peu clair et incompréhensible ... Unglossaire d'entreprise parle de ce que les gens intelligents en costume proposent pendant des heures ... comment nommer un terme, comment trouver une formule calcul. Ils réfléchissent depuis longtemps, et finalement ils n'ont qu'un glossaire commercial.Le modèle logique concerne la façon dont l'analyste se voit dans le monde, qui est capable de communiquer avec ces personnes intelligentes en costume-cravate, mais qui comprend en même temps comment il serait possible d'atterrir. Loin des détails de la réalisation physique.Le modèle physique concerne le moment où les programmeurs sévères, les architectes qui comprennent vraiment comment poser ces objets - dans quelle table mettre, quels champs créer, quels index accrocher ... L'état de l'environnement est une sorte de distribution. C'est comme le témoignage d'une voiture. Un programmeur veut parfois dire une chose à la machine, mais elle se méprend. Seul l'état de l'environnement nous montre l'état réel des choses, et nous comparons constamment tout; et nous comprenons qu'il y a une différence entre ce que le programmeur a dit et l'état réel de l'environnement.Cas pour décrire les métadonnées
SC: - Expliquons-le avec un exemple concret. Par exemple, nous avons quatre de ces niveaux désignés. Supposons que nous ayons ces gens sérieux dans des liens qui travaillent au niveau d'un glossaire commercial - ils ne comprennent pas du tout comment et ce qui est organisé à l'intérieur. Mais ils comprennent qu'ils doivent faire une forme de déclaration obligatoire, ils doivent obtenir, disons, le solde moyen sur les comptes personnels: à ce niveau, une personne devrait déjà avoir son propre glossaire d'entreprise (conditions de déclaration obligatoire) ou l'avoir (solde moyen sur un compte personnel). Vient ensuite l'analyste qui le comprend parfaitement, peut parler le même langage avec lui, mais il peut également parler le même langage avec les programmeurs.Il dit: "Écoutez, ici vous avez toute l'histoire divisée en comptes séparés en tant qu'entités, et ils ont un attribut - le solde moyen."Vient ensuite l'architecte et déclare: «Nous ferons cette vitrine des prêts aux personnes morales. En conséquence, nous ferons un tableau physique des comptes personnels, nous ferons un tableau physique des soldes quotidiens sur les comptes personnels (car ils sont reçus tous les jours à la clôture du jour de bourse). Et une fois par mois à la date limite, nous calculerons la moyenne (tableau des soldes mensuels), comme demandé. »À peine dit que c'était fait. Et puis notre analyseur est venu, qui est allé sur le circuit industriel et a dit: "Oui, je vois - il y a des tables nécessaires ..." Qu'est-ce qui a enrichi cette table? Ici (à titre d'exemple) - partitions et index, même si, à proprement parler, les partitions et les index peuvent être au niveau de la conception du modèle physique, mais il peut y avoir autre chose (par exemple, le volume de données).
à ce niveau, une personne devrait déjà avoir son propre glossaire d'entreprise (conditions de déclaration obligatoire) ou l'avoir (solde moyen sur un compte personnel). Vient ensuite l'analyste qui le comprend parfaitement, peut parler le même langage avec lui, mais il peut également parler le même langage avec les programmeurs.Il dit: "Écoutez, ici vous avez toute l'histoire divisée en comptes séparés en tant qu'entités, et ils ont un attribut - le solde moyen."Vient ensuite l'architecte et déclare: «Nous ferons cette vitrine des prêts aux personnes morales. En conséquence, nous ferons un tableau physique des comptes personnels, nous ferons un tableau physique des soldes quotidiens sur les comptes personnels (car ils sont reçus tous les jours à la clôture du jour de bourse). Et une fois par mois à la date limite, nous calculerons la moyenne (tableau des soldes mensuels), comme demandé. »À peine dit que c'était fait. Et puis notre analyseur est venu, qui est allé sur le circuit industriel et a dit: "Oui, je vois - il y a des tables nécessaires ..." Qu'est-ce qui a enrichi cette table? Ici (à titre d'exemple) - partitions et index, même si, à proprement parler, les partitions et les index peuvent être au niveau de la conception du modèle physique, mais il peut y avoir autre chose (par exemple, le volume de données).Enregistrement et stockage au niveau des métadonnées
AC: - Comment tout est stocké chez nous? Ceci est une forme super simplifiée de l'exemple que Stas a peint plus tôt! Comment tout cela nous appartiendra-t-il?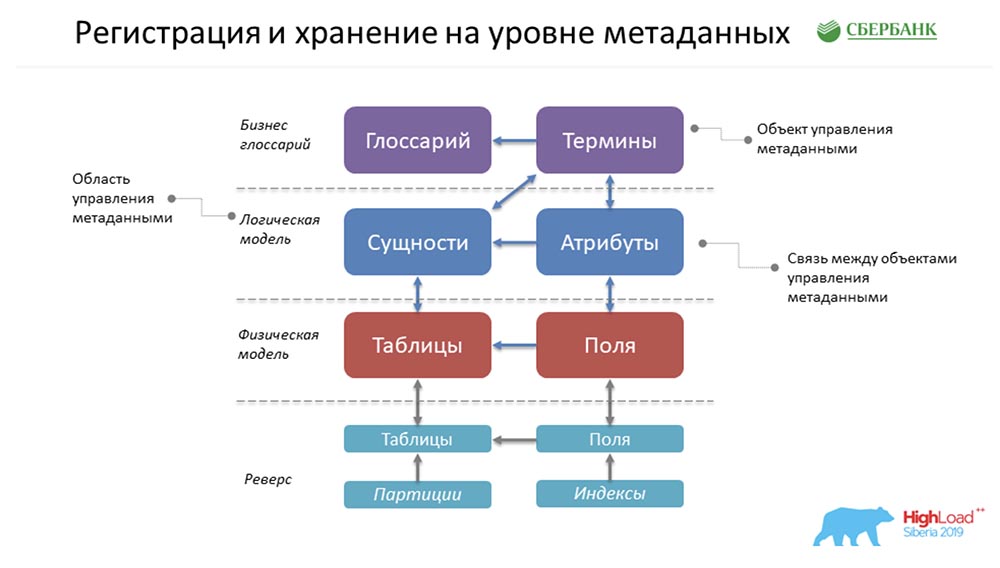 En fait, ce sera une ligne dans l'objet Glossaire, une dans l'objet Termes, une dans les Entités, une dans les Attributs, etc. Dans la figure ci-dessus, chaque rectangle est un objet de notre système de contrôle, qui représente telle ou telle information qui y est stockée.Afin de vous présenter lentement la terminologie, je vous demande de noter ce qui suit ... Qu'est-ce qu'un objet de gestion des métadonnées? Physiquement, cela est présenté sous la forme d'un tableau, mais en fait, certaines informations y sont stockées sous forme de termes, glossaires, entités, attributs, etc. Ce terme, «objet», nous continuerons à l'utiliser dans notre présentation.CAROLINE DU SUD: - Ici, il faut dire que chaque cube est juste une table dans notre système où nous stockons des métadonnées, et nous appelons cela l'objet de contrôle.
En fait, ce sera une ligne dans l'objet Glossaire, une dans l'objet Termes, une dans les Entités, une dans les Attributs, etc. Dans la figure ci-dessus, chaque rectangle est un objet de notre système de contrôle, qui représente telle ou telle information qui y est stockée.Afin de vous présenter lentement la terminologie, je vous demande de noter ce qui suit ... Qu'est-ce qu'un objet de gestion des métadonnées? Physiquement, cela est présenté sous la forme d'un tableau, mais en fait, certaines informations y sont stockées sous forme de termes, glossaires, entités, attributs, etc. Ce terme, «objet», nous continuerons à l'utiliser dans notre présentation.CAROLINE DU SUD: - Ici, il faut dire que chaque cube est juste une table dans notre système où nous stockons des métadonnées, et nous appelons cela l'objet de contrôle.Exigences relatives aux métadonnées
Qu'avions-nous à l'entrée? A l'entrée, nous avons reçu des exigences assez intéressantes. Il y en avait beaucoup, mais ici nous voulons en montrer trois principales: La première exigence est assez classique. On nous dit: "Les gars, tout ce qui vous est arrivé une fois doit arriver pour toujours." L'historisation est terminée, et toute modification de votre système de métadonnées qui vous est venue (peu importe si un paquet de 100 champs est arrivé (100 modifications) ou si un champ a changé dans une table) nécessite un nouvel enregistrement des métadonnées. Ils nécessitent également le retour d'une réponse:
La première exigence est assez classique. On nous dit: "Les gars, tout ce qui vous est arrivé une fois doit arriver pour toujours." L'historisation est terminée, et toute modification de votre système de métadonnées qui vous est venue (peu importe si un paquet de 100 champs est arrivé (100 modifications) ou si un champ a changé dans une table) nécessite un nouvel enregistrement des métadonnées. Ils nécessitent également le retour d'une réponse:- par défaut - état actuel;
- par date;
- par numéro de révision.
La deuxième exigence était plus intéressante: on nous a dit qu’ils pouvaient travailler avec nous sur des objets, mais qu’ils devaient beaucoup programmer en Java, mais qu’ils ne le voulaient pas. Ils ont suggéré de mélanger 100 objets (ou 10) à la fois, et nous devrions gérer cette activité (car nous le pouvons). Que signifie le mélange? Par exemple, 10 colonnes sont arrivées. Ils ont un lien vers l'identifiant de la table, mais nous n'avons pas la table elle-même - elle est venue à la fin de JSON. "Vous pensez et traitez - il faut que vous puissiez"!Par ordre d'intérêt croissant - le troisième: «Nous voulons être en mesure non seulement d'utiliser l'API que vous allez nous fabriquer, mais aussi de nous comprendre ...» Et dans un ordre arbitraire dire: «Donnez-nous l'union de cet objet à celui via le troisième objet. Et laissez votre système lui-même comprendre comment tout faire, demandez à la base de données et renvoyez le résultat en JSON. »Nous avions une telle histoire à l'entrée.Estimations estimées
 AC: - Selon nos calculs approximatifs, afin de mettre en œuvre tout ce concept, chaque objet de contrôle devait participer à sept interfaces: simple (simple), pour objet par écriture / lecture et suppression ...Trois autres - pour écriture / lecture / suppression universelle, t Autrement dit, que nous pouvons jeter tout cela dans n'importe quel ordre et comment transférer l'ensemble de soupe au système, et elle trouvera dans quel ordre supprimer, mettre, lire.Encore une chose - pour construire une hiérarchie afin que nous puissions indiquer au système - «Rendez-nous d’objet en objet»; et il retourne un arbre d'objets imbriqués.
AC: - Selon nos calculs approximatifs, afin de mettre en œuvre tout ce concept, chaque objet de contrôle devait participer à sept interfaces: simple (simple), pour objet par écriture / lecture et suppression ...Trois autres - pour écriture / lecture / suppression universelle, t Autrement dit, que nous pouvons jeter tout cela dans n'importe quel ordre et comment transférer l'ensemble de soupe au système, et elle trouvera dans quel ordre supprimer, mettre, lire.Encore une chose - pour construire une hiérarchie afin que nous puissions indiquer au système - «Rendez-nous d’objet en objet»; et il retourne un arbre d'objets imbriqués.Complexité de la mise en œuvre
SC: - En plus des exigences techniques qui nous sont venues au moment du début de cette histoire, nous avons eu des difficultés supplémentaires. Tout d'abord, il s'agit d'une certaine incertitude des exigences. Toutes les équipes ne pouvaient pas toujours exprimer clairement ce dont elles avaient besoin du service, et souvent le moment de vérité est né au moment de prototyper une histoire sur le circuit de la déf. Et pendant qu'il atteignait le bal, il pouvait y avoir plusieurs cycles.AC: - C'est la turbulence même qui a été annoncée au début.SC: - Ensuite ...Il y avait un délai prohibitif, car même au moment du lancement, plus de cinq équipes dépendaient de nous. Classiques du genre: le résultat était nécessaire hier. L'option de travail est en mode cheval échaudé, c'est ce que nous avons fait.Le troisième est un grand développement. Nastya sur sa diapositive a montré que lorsque nous avons examiné les exigences de quoi et comment faire, nous avons réalisé: 1 objet nécessite sept API (soit pour lui, soit une participation à sept API). Cela signifie que si nous avons un patch (6 objets, modèle, 42 API) va dans une semaine ...
Tout d'abord, il s'agit d'une certaine incertitude des exigences. Toutes les équipes ne pouvaient pas toujours exprimer clairement ce dont elles avaient besoin du service, et souvent le moment de vérité est né au moment de prototyper une histoire sur le circuit de la déf. Et pendant qu'il atteignait le bal, il pouvait y avoir plusieurs cycles.AC: - C'est la turbulence même qui a été annoncée au début.SC: - Ensuite ...Il y avait un délai prohibitif, car même au moment du lancement, plus de cinq équipes dépendaient de nous. Classiques du genre: le résultat était nécessaire hier. L'option de travail est en mode cheval échaudé, c'est ce que nous avons fait.Le troisième est un grand développement. Nastya sur sa diapositive a montré que lorsque nous avons examiné les exigences de quoi et comment faire, nous avons réalisé: 1 objet nécessite sept API (soit pour lui, soit une participation à sept API). Cela signifie que si nous avons un patch (6 objets, modèle, 42 API) va dans une semaine ...Approche standard
AC: - Oui, en fait 42 API par semaine ne sont que la pointe de l'iceberg. Nous savons bien que pour garantir le fonctionnement de ces 42 API, nous avons besoin de:- tout d'abord, créez une structure de stockage pour l'objet;
- deuxièmement, assurer la logique de son traitement;
- troisièmement, écrivez l'API même à laquelle l'objet participe (ou est configuré spécifiquement pour lui);
- quatrièmement, ce serait bien de couvrir idéalement tout cela avec les contours des tests, tester et dire que tout va bien;
- cinquièmement (la même cerise sur le gâteau), pour documenter toute cette histoire.
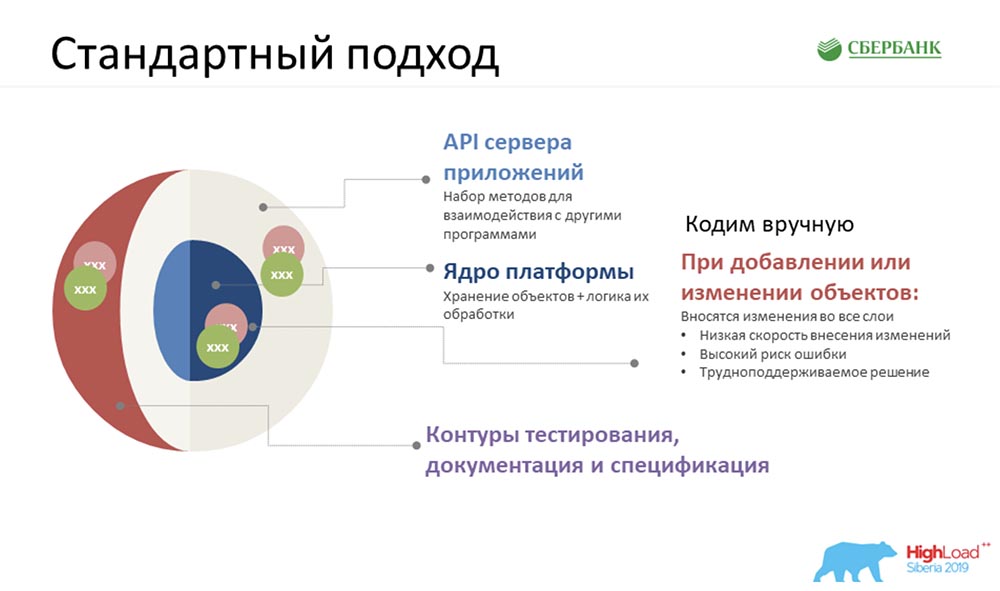 Naturellement, la première chose qui nous est venue à l'esprit (au début, nous vous avons montré un diagramme approximatif) - nous avions environ 35 objets. Il fallait en faire quelque chose, tout cela devait être déduit, et il y avait très peu de temps. Et la première idée qui nous est venue a été de nous asseoir, de retrousser nos manches et de commencer à coder.Même après avoir travaillé dans ce mode pendant quelques jours (nous avions trois équipes), nous avons atteint une température aussi éclatante ... Tout le monde était nerveux ... Et nous avons réalisé que nous devions chercher une approche différente.
Naturellement, la première chose qui nous est venue à l'esprit (au début, nous vous avons montré un diagramme approximatif) - nous avions environ 35 objets. Il fallait en faire quelque chose, tout cela devait être déduit, et il y avait très peu de temps. Et la première idée qui nous est venue a été de nous asseoir, de retrousser nos manches et de commencer à coder.Même après avoir travaillé dans ce mode pendant quelques jours (nous avions trois équipes), nous avons atteint une température aussi éclatante ... Tout le monde était nerveux ... Et nous avons réalisé que nous devions chercher une approche différente.Approche personnalisée
Nous avons commencé à prêter attention à ce que nous faisons. L'idée de cette approche a toujours été sous nos yeux, car nous sommes engagés dans les métadonnées depuis très longtemps. D'une certaine manière, tout de suite, cela ne nous est pas venu à l'esprit ...Comme vous pouvez le deviner, l'essence de cette idée est d'utiliser des métadonnées. Cela consiste dans le fait que nous collectons la structure de notre référentiel (il s'agit de certaines métadonnées), une fois que nous avons créé un modèle pour du code (par exemple, plusieurs API ou procédures pour le traitement de la logique, des scripts pour créer des structures). Une fois que nous avons créé ce modèle, puis parcouru toutes les métadonnées. Par des balises, les propriétés sont substituées dans le code (noms d'objets, champs, caractéristiques importantes) et le code résultant est prêt. Autrement dit, il suffit de se confondre une fois - créez un modèle, puis utilisez toutes ces informations pour les objets existants et nouveaux. Ici, nous introduisons un autre concept - #META_META. Je vais vous expliquer pourquoi, afin de ne pas vous confondre.Notre système est engagé dans la gestion des métadonnées, et l'approche que nous utilisons décrit un système de gestion des métadonnées, c'est-à-dire deux métas. «MetaMeta» - nous l'avons appelé à la maison, à l'intérieur de l'équipe. Afin de ne pas confondre davantage les autres, nous utiliserons ce terme même.
Autrement dit, il suffit de se confondre une fois - créez un modèle, puis utilisez toutes ces informations pour les objets existants et nouveaux. Ici, nous introduisons un autre concept - #META_META. Je vais vous expliquer pourquoi, afin de ne pas vous confondre.Notre système est engagé dans la gestion des métadonnées, et l'approche que nous utilisons décrit un système de gestion des métadonnées, c'est-à-dire deux métas. «MetaMeta» - nous l'avons appelé à la maison, à l'intérieur de l'équipe. Afin de ne pas confondre davantage les autres, nous utiliserons ce terme même.Mécanisme pour assurer l'historisation et la révision
SC: - Vous avez résumé le reste de notre discours. Nous le dirons plus en détail.Je dois dire que lors de la préparation du discours, on nous a demandé de fournir des informations techniques qui pourraient intéresser mes collègues. Nous le ferons. De plus, les diapositives deviendront plus techniques - peut-être que quelqu'un verra quelque chose d'intéressant pour lui-même.Premièrement, comment nous avons résolu le problème de l'historisation et de la révision. Peut-être que cela ressemble à combien. Considérez ceci en utilisant des métadonnées comme exemple, qui décrivent un seul champ dans la table de publication (comme exemple):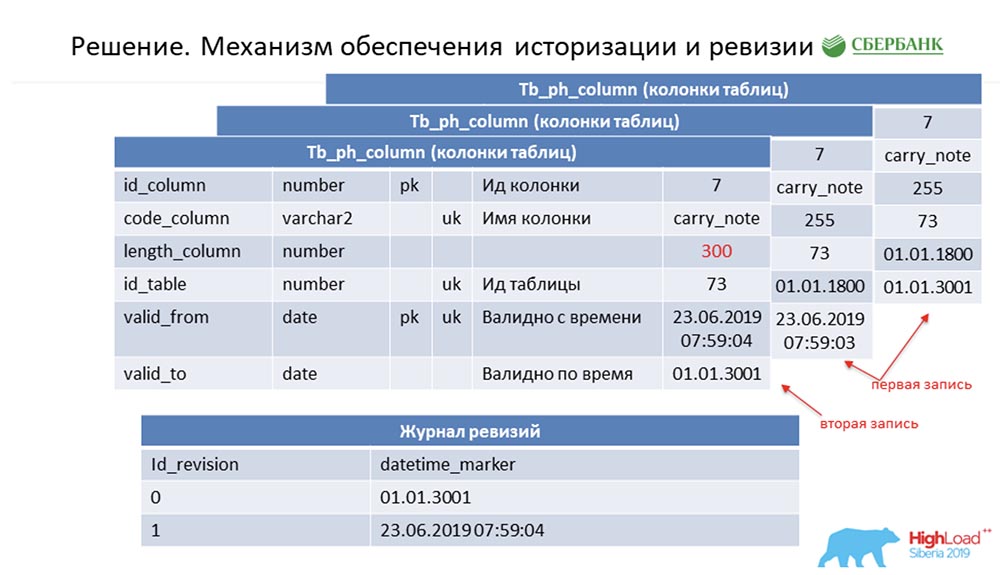 Il a un id - "7", un nom - carry_note, un lien id_table 73 et un champ - 255. Nous entrons dans la clé primaire et alternative un champ (de type date) à partir du moment où cette entrée devient valide - valid_from. Et un autre champ - à quelle date cet enregistrement est valide (valid_to). Dans ce cas, ils sont remplis par défaut - il est clair que cette entrée est toujours valable en principe. Et cela se produit jusqu'à ce que nous voulions changer, disons, la longueur du champ.Dès que nous voulons le faire, nous fermons l'enregistrement valid_to (nous fixons l'horodatage auquel l'événement s'est produit). En même temps, nous faisons un nouveau record ("300"). Il est facile de remarquer que dans cette situation, si vous regardez la base de données à un moment donné par la «bataille» (entre) entre valid_from et valid_to, nous obtiendrons un enregistrement unique, mais pertinent à ce moment-là. Et en même temps, nous avons simultanément gardé un journal de révision:
Il a un id - "7", un nom - carry_note, un lien id_table 73 et un champ - 255. Nous entrons dans la clé primaire et alternative un champ (de type date) à partir du moment où cette entrée devient valide - valid_from. Et un autre champ - à quelle date cet enregistrement est valide (valid_to). Dans ce cas, ils sont remplis par défaut - il est clair que cette entrée est toujours valable en principe. Et cela se produit jusqu'à ce que nous voulions changer, disons, la longueur du champ.Dès que nous voulons le faire, nous fermons l'enregistrement valid_to (nous fixons l'horodatage auquel l'événement s'est produit). En même temps, nous faisons un nouveau record ("300"). Il est facile de remarquer que dans cette situation, si vous regardez la base de données à un moment donné par la «bataille» (entre) entre valid_from et valid_to, nous obtiendrons un enregistrement unique, mais pertinent à ce moment-là. Et en même temps, nous avons simultanément gardé un journal de révision: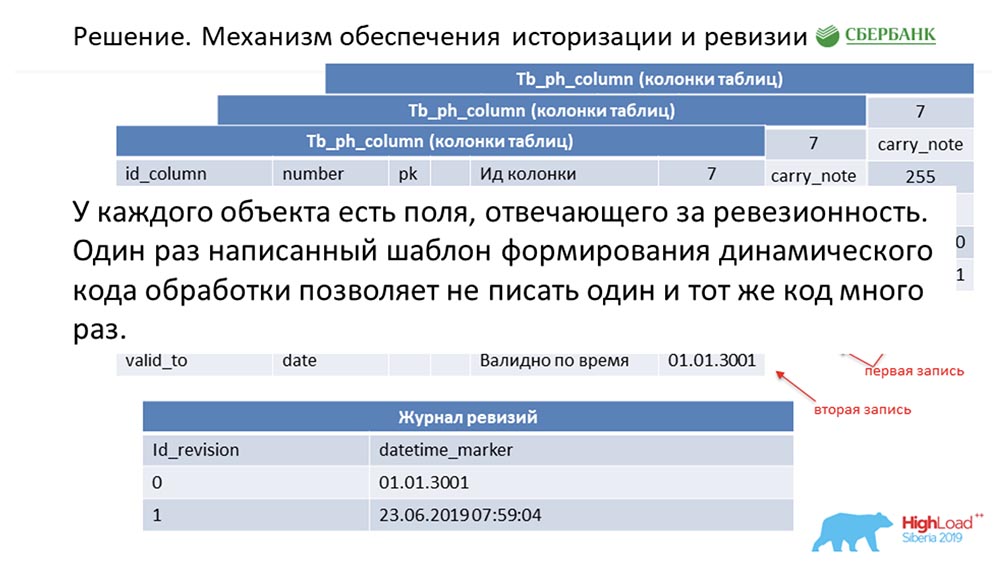 nous y avons enregistré des révisions qui augmentent en séquence (séquence) id, et le point temporel qui correspond à cet id de révision. Nous avons donc pu clôturer la première demande.AC:- Je suppose oui! Ici, l'approche est la même. Nous comprenons que chaque objet dans le système a ces deux champs obligatoires, et une fois que nous nous sommes trompés - avons codé la logique de traitement de ce modèle, puis (lors de la génération du code dynamique) nous substituons simplement les noms des objets correspondants. Ainsi, chaque objet de notre système devient une révision, et tout cela peut être traité - nous n'écrivons généralement pas une seule ligne de code.
nous y avons enregistré des révisions qui augmentent en séquence (séquence) id, et le point temporel qui correspond à cet id de révision. Nous avons donc pu clôturer la première demande.AC:- Je suppose oui! Ici, l'approche est la même. Nous comprenons que chaque objet dans le système a ces deux champs obligatoires, et une fois que nous nous sommes trompés - avons codé la logique de traitement de ce modèle, puis (lors de la génération du code dynamique) nous substituons simplement les noms des objets correspondants. Ainsi, chaque objet de notre système devient une révision, et tout cela peut être traité - nous n'écrivons généralement pas une seule ligne de code.Mise à jour par lots
SC: - La deuxième exigence pour moi était un peu plus intéressante. Honnêtement, en ce qui concerne l'entrée, au début, je suis juste tombé dans la stupeur. Mais la décision est venue!Je vous rappelle que c'est le même cas lorsque, disons, JSON avec un paquet nous est parvenu pour le nième nombre d'objets qui doivent être insérés dans le système. Dans le même temps, au début, nous avons 10 colonnes faisant référence à une table inexistante, et la table est allée dans la queue JSON. Que faire? Nous avons trouvé un moyen d'utiliser le mécanisme des requêtes hiérarchiques récursives - c'est à coup sûr la connexion bien connue par construction antérieure. Nous l'avons fait comme suit: voici un fragment de notre code de production:
Nous avons trouvé un moyen d'utiliser le mécanisme des requêtes hiérarchiques récursives - c'est à coup sûr la connexion bien connue par construction antérieure. Nous l'avons fait comme suit: voici un fragment de notre code de production: À ce stade (une section de code entourée d'un ovale rouge) est le point principal qui donne une idée. Et ici, l'objet est lié à un autre objet lié par une clé étrangère, qui est dans le système.Pour comprendre: si quelqu'un écrit du code dans Oracle, il y a All_columns, All_all_ tables, All_constraint tables - c'est le dictionnaire qui est traité par les scripts (comme ceux montrés sur la diapositive ci-dessus).À la sortie, nous obtenons des champs qui nous donnent la priorité de traitement des objets, et donnons en plus un descripteur - c'est essentiellement un identifiant de chaîne unique pour tout enregistrement de métadonnées. Le code par lequel le descripteur est reçu est également indiqué sur la diapositive ci-dessus.Par exemple, un champ - à quoi pourrait-il ressembler? Voici le code de la plateforme: oracle KP., Production. KP, my_scheme. KP, my_table. KP, etc., où KP est le code de champ. Il y aura donc un tel descripteur.AC: - Quels sont les problèmes ici? Nous avons des objets dans le système et l'ordre de leur insertion est très important pour nous. Par exemple, nous ne pouvons pas insérer de colonnes devant des tables, car une colonne doit faire référence à une table spécifique. Comme nous le faisons en standard: d'abord nous insérons les tables, en réponse nous obtenons un tableau d'id, par ces ID nous lançons les colonnes et faisons la deuxième opération d'insertion.En réalité, comme l'a montré Stas, la longueur de cette chaîne atteint 8 à 9 objets. L'utilisateur, en utilisant l'approche standard, doit effectuer toutes ces opérations à tour de rôle (toutes ces 9 opérations) et comprendre clairement leur ordre afin qu'aucune erreur ne se produise.Pour autant que j'interprète correctement Stas, nous pouvons transférer tous ces objets dans le système dans n'importe quel ordre et ne nous soucions pas de la façon dont nous devons effectuer cette insertion - nous venons de jeter un ensemble de soupe dans le système, et tout cela a déterminé dans quel ordre insérer.La seule chose que j'ai est la question: que se passe-t-il si nous insérons l'objet pour la première fois? Nous avons inséré la table avant, nous ne connaissons pas son identifiant. Comment indiquer (un exemple purement hypothétique) que nous devons insérer deux tableaux, chacun ayant une colonne? Comment pouvons-nous indiquer que dans cette colonne JSON se réfère à table1, pas table2?SC: - Un descripteur! La poignée que nous avons indiquée sur cette diapositive (précédente).Et sur cette diapositive, la solution même est donnée:
À ce stade (une section de code entourée d'un ovale rouge) est le point principal qui donne une idée. Et ici, l'objet est lié à un autre objet lié par une clé étrangère, qui est dans le système.Pour comprendre: si quelqu'un écrit du code dans Oracle, il y a All_columns, All_all_ tables, All_constraint tables - c'est le dictionnaire qui est traité par les scripts (comme ceux montrés sur la diapositive ci-dessus).À la sortie, nous obtenons des champs qui nous donnent la priorité de traitement des objets, et donnons en plus un descripteur - c'est essentiellement un identifiant de chaîne unique pour tout enregistrement de métadonnées. Le code par lequel le descripteur est reçu est également indiqué sur la diapositive ci-dessus.Par exemple, un champ - à quoi pourrait-il ressembler? Voici le code de la plateforme: oracle KP., Production. KP, my_scheme. KP, my_table. KP, etc., où KP est le code de champ. Il y aura donc un tel descripteur.AC: - Quels sont les problèmes ici? Nous avons des objets dans le système et l'ordre de leur insertion est très important pour nous. Par exemple, nous ne pouvons pas insérer de colonnes devant des tables, car une colonne doit faire référence à une table spécifique. Comme nous le faisons en standard: d'abord nous insérons les tables, en réponse nous obtenons un tableau d'id, par ces ID nous lançons les colonnes et faisons la deuxième opération d'insertion.En réalité, comme l'a montré Stas, la longueur de cette chaîne atteint 8 à 9 objets. L'utilisateur, en utilisant l'approche standard, doit effectuer toutes ces opérations à tour de rôle (toutes ces 9 opérations) et comprendre clairement leur ordre afin qu'aucune erreur ne se produise.Pour autant que j'interprète correctement Stas, nous pouvons transférer tous ces objets dans le système dans n'importe quel ordre et ne nous soucions pas de la façon dont nous devons effectuer cette insertion - nous venons de jeter un ensemble de soupe dans le système, et tout cela a déterminé dans quel ordre insérer.La seule chose que j'ai est la question: que se passe-t-il si nous insérons l'objet pour la première fois? Nous avons inséré la table avant, nous ne connaissons pas son identifiant. Comment indiquer (un exemple purement hypothétique) que nous devons insérer deux tableaux, chacun ayant une colonne? Comment pouvons-nous indiquer que dans cette colonne JSON se réfère à table1, pas table2?SC: - Un descripteur! La poignée que nous avons indiquée sur cette diapositive (précédente).Et sur cette diapositive, la solution même est donnée: Les descripteurs sont utilisés dans le système comme une sorte de champ mnémonique qui n'existe pas, mais remplace id. A ce moment, quand au début le système comprend qu'il est nécessaire d'insérer la table - insert, il recevra id; et déjà au stade de la génération de la requête SQL pour l'insertion et la colonne, il fonctionnera sur id. L'utilisateur ne peut pas prendre un bain de vapeur: «Donnez la poignée et exécutez!». Le système fera l'affaire.
Les descripteurs sont utilisés dans le système comme une sorte de champ mnémonique qui n'existe pas, mais remplace id. A ce moment, quand au début le système comprend qu'il est nécessaire d'insérer la table - insert, il recevra id; et déjà au stade de la génération de la requête SQL pour l'insertion et la colonne, il fonctionnera sur id. L'utilisateur ne peut pas prendre un bain de vapeur: «Donnez la poignée et exécutez!». Le système fera l'affaire.Requête universelle sur un groupe d'objets associés
Peut-être mon cas préféré. C'est l'exigence technique préférée que nous avions. Ils sont venus vers nous et ont dit: «Les gars, faites-le pour que le système puisse tout faire! D'objet en objet, s'il vous plaît. Devinez comment tout cela se joint entre eux. Rendez-nous, JSON, s'il vous plaît. Nous ne voulons pas programmer beaucoup en utilisant votre service "...Question:" Comment?! "Nous avons fait de même. Exactement la même construction: il a été utilisé pour résoudre ce problème. La seule différence est qu'il y avait un filtre valide, qui déroulait cet arbre hiérarchique uniquement pour les histoires où un descripteur était requis. Relativement parlant, il était unique pour chaque objet. Ici, toutes les connexions possibles dans le système sont sans torsion (nous avons environ 50 objets).Toutes les connexions possibles entre les objets sont préparées à l'avance. Si nous avons un objet impliqué dans trois relations, respectivement, trois lignes seront préparées pour que l'algorithme puisse comprendre. Et dès que la demande JSON nous parvient, nous nous rendons à l'endroit où cette histoire a été préparée à l'avance dans MeteMet, nous recherchons la façon dont nous avons besoin. Si nous ne trouvons pas, c'est une histoire, si nous la trouvons, nous formons une requête dans la base de données. En cours d'exécution - retour de JSON (comme demandé).AC: - En conséquence, nous pouvons transférer au système de quel objet nous voulons recevoir. Et si vous pouvez définir une connexion claire entre deux objets, le système lui-même déterminera le niveau d'imbrication de l'objet qui vous reviendra dans l'arborescence:C'est très flexible! Une fois de plus, nos utilisateurs sont dans un état de «turbulence»: aujourd'hui ils ont besoin d'une chose, demain ils en ont besoin d'une autre. Et cette solution nous permet d'adapter la structure de manière très flexible. Ce sont trois cas clés qui ont été utilisés de notre côté central.SC: - Résumons certains. Il est clair que maintenant nous ne dirons pas tous les jetons à cause du temps limité. À notre avis, trois cas, nous avons effectué et raconté. Nous avons réussi, nous avons pu mettre toutes les logiques les plus complexes, et celle qui devrait fonctionner uniformément pour chaque objet de gestion des métadonnées, dans le code du noyau.Nous ne pouvions pas rendre ce code 100% dynamique, ce qui signifie qu'avec des objets créés (peu importe s'ils ont déjà été créés ou qui seront créés plus tard; l'essentiel est d'être créé selon les règles), le système peut fonctionner - rien n'a besoin d'être ajouté, réécrit. Il suffit de tester. Nous avons garé toute cette histoire dans trois méthodes universelles. À mon avis, il y en a suffisamment pour résoudre presque tous les problèmes commerciaux:
il a été utilisé pour résoudre ce problème. La seule différence est qu'il y avait un filtre valide, qui déroulait cet arbre hiérarchique uniquement pour les histoires où un descripteur était requis. Relativement parlant, il était unique pour chaque objet. Ici, toutes les connexions possibles dans le système sont sans torsion (nous avons environ 50 objets).Toutes les connexions possibles entre les objets sont préparées à l'avance. Si nous avons un objet impliqué dans trois relations, respectivement, trois lignes seront préparées pour que l'algorithme puisse comprendre. Et dès que la demande JSON nous parvient, nous nous rendons à l'endroit où cette histoire a été préparée à l'avance dans MeteMet, nous recherchons la façon dont nous avons besoin. Si nous ne trouvons pas, c'est une histoire, si nous la trouvons, nous formons une requête dans la base de données. En cours d'exécution - retour de JSON (comme demandé).AC: - En conséquence, nous pouvons transférer au système de quel objet nous voulons recevoir. Et si vous pouvez définir une connexion claire entre deux objets, le système lui-même déterminera le niveau d'imbrication de l'objet qui vous reviendra dans l'arborescence:C'est très flexible! Une fois de plus, nos utilisateurs sont dans un état de «turbulence»: aujourd'hui ils ont besoin d'une chose, demain ils en ont besoin d'une autre. Et cette solution nous permet d'adapter la structure de manière très flexible. Ce sont trois cas clés qui ont été utilisés de notre côté central.SC: - Résumons certains. Il est clair que maintenant nous ne dirons pas tous les jetons à cause du temps limité. À notre avis, trois cas, nous avons effectué et raconté. Nous avons réussi, nous avons pu mettre toutes les logiques les plus complexes, et celle qui devrait fonctionner uniformément pour chaque objet de gestion des métadonnées, dans le code du noyau.Nous ne pouvions pas rendre ce code 100% dynamique, ce qui signifie qu'avec des objets créés (peu importe s'ils ont déjà été créés ou qui seront créés plus tard; l'essentiel est d'être créé selon les règles), le système peut fonctionner - rien n'a besoin d'être ajouté, réécrit. Il suffit de tester. Nous avons garé toute cette histoire dans trois méthodes universelles. À mon avis, il y en a suffisamment pour résoudre presque tous les problèmes commerciaux:- tout d'abord, ce même «updater» universel est une méthode qui permet de mettre à jour / insérer / supprimer (supprimer c'est fermer un enregistrement) sur un ou un groupe d'objets transférés dans un ordre aléatoire.
- la seconde est une méthode qui peut renvoyer des informations universelles sur un seul objet;
- la troisième est la même méthode qui peut renvoyer des informations de jointure connectées par des groupes d'objets.
Voilà comment cela s'est avéré, et nous avons fait le noyau. Et puis nous passerons à votre partie préférée.Point d'entrée de l'application
AC: - Oui, c'est ma partie préférée, car c'est mon domaine de responsabilité - Application Server. Pour comprendre dans quelle situation j'étais, je vais essayer de vous replonger dans un problème.Stas a fait du bon travail et m'a transmis ces trois méthodes standard qui manipulaient ces objets. Il s'agit d'une description purement sommaire - en réalité, il y en a beaucoup plus: Revenons au tout début pour vous plonger ... Comment les métadonnées du système seront-elles présentées ici?
Revenons au tout début pour vous plonger ... Comment les métadonnées du système seront-elles présentées ici?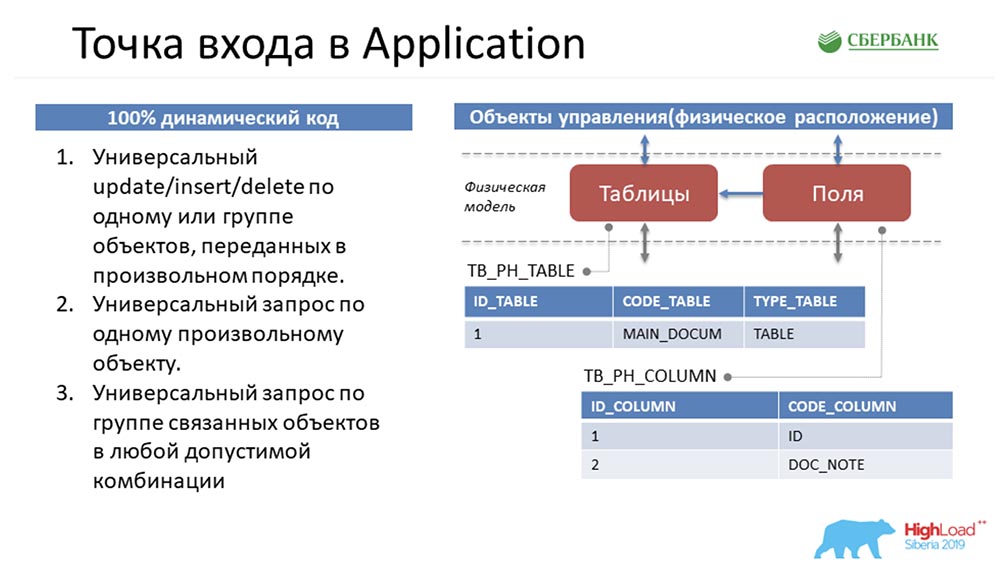 Si nous voyons qu'il y a une table dans l'environnement, elle tombera dans notre système comme un enregistrement dans l'objet table et deux enregistrements dans l'objet champ. Essentiellement, nous avons mis en place une structure.On peut remarquer que la quantité de ces objets est différente. Ensuite, afin de manipuler ces objets, de tout amener à une structure universelle, afin que les trois méthodes comprennent ce qui est discuté, Stas fait un pas avec le cheval. Il prend et retourne tous les objets, c'est-à-dire qu'il représente n'importe quel objet de notre système de gestion des métadonnées en quatre lignes:
Si nous voyons qu'il y a une table dans l'environnement, elle tombera dans notre système comme un enregistrement dans l'objet table et deux enregistrements dans l'objet champ. Essentiellement, nous avons mis en place une structure.On peut remarquer que la quantité de ces objets est différente. Ensuite, afin de manipuler ces objets, de tout amener à une structure universelle, afin que les trois méthodes comprennent ce qui est discuté, Stas fait un pas avec le cheval. Il prend et retourne tous les objets, c'est-à-dire qu'il représente n'importe quel objet de notre système de gestion des métadonnées en quatre lignes: Étant donné que tout objet de notre système de gestion des métadonnées est physiquement une table, tout objet peut être décomposé selon ces quatre signes: numéro de ligne , table, champ et valeur de champ. C'est Stas qui est venu avec tout cela, et j'avais besoin de l'implémenter et de le donner aux utilisateurs.CAROLINE DU SUD:- Désolé, mais comment puis-je vous donner des colonnes dans une sorte de réponse plate, par exemple, qui n'ont pas encore été créées, seront créées un jour, et Dieu sait ce qu'elles peuvent être? .. Par conséquent, la seule option dans les conditions du code dynamique est de configurer l'interaction entre noyau et application, pour vous transmettre ces informations - uniquement telles que nous les voyons. Je pense que de mon point de vue, cette décision a été ingénieuse, car elle vient uniquement de vous.AC: - Maintenant, nous ne discuterons pas de cela. Deux semaines avant la fin du délai, je suis resté avec le fait que j'avais ces trois méthodes sur les mains (à gauche sur la diapositive précédente) qui manipulaient la structure universelle (à droite sur la même diapositive).Ma première pensée a été de tout simplement boucler tout au niveau de l'API et d'aller à l'utilisateur avec ceci, en disant: «Regardez, quelle chose brillante! Tu peux faire n'importe quoi! Transférez tous les objets, ou même ceux qui n'existent pas. Cool, ouais "?!
Étant donné que tout objet de notre système de gestion des métadonnées est physiquement une table, tout objet peut être décomposé selon ces quatre signes: numéro de ligne , table, champ et valeur de champ. C'est Stas qui est venu avec tout cela, et j'avais besoin de l'implémenter et de le donner aux utilisateurs.CAROLINE DU SUD:- Désolé, mais comment puis-je vous donner des colonnes dans une sorte de réponse plate, par exemple, qui n'ont pas encore été créées, seront créées un jour, et Dieu sait ce qu'elles peuvent être? .. Par conséquent, la seule option dans les conditions du code dynamique est de configurer l'interaction entre noyau et application, pour vous transmettre ces informations - uniquement telles que nous les voyons. Je pense que de mon point de vue, cette décision a été ingénieuse, car elle vient uniquement de vous.AC: - Maintenant, nous ne discuterons pas de cela. Deux semaines avant la fin du délai, je suis resté avec le fait que j'avais ces trois méthodes sur les mains (à gauche sur la diapositive précédente) qui manipulaient la structure universelle (à droite sur la même diapositive).Ma première pensée a été de tout simplement boucler tout au niveau de l'API et d'aller à l'utilisateur avec ceci, en disant: «Regardez, quelle chose brillante! Tu peux faire n'importe quoi! Transférez tous les objets, ou même ceux qui n'existent pas. Cool, ouais "?! Et ils disent: «Mais vous comprenez que votre service n'est pas du tout spécialisé? En tant qu'utilisateur, je ne comprends pas quels objets je peux transférer vers le système, comment je peux les manipuler ... Pour moi, c'est une boîte noire, j'ai généralement peur de soumettre des données; Je peux me tromper - j'ai peur. Faites en sorte que je puisse suivre clairement les instructions et voir quels objets se trouvent dans le système et quelles méthodes de manipulation je peux utiliser. »
Et ils disent: «Mais vous comprenez que votre service n'est pas du tout spécialisé? En tant qu'utilisateur, je ne comprends pas quels objets je peux transférer vers le système, comment je peux les manipuler ... Pour moi, c'est une boîte noire, j'ai généralement peur de soumettre des données; Je peux me tromper - j'ai peur. Faites en sorte que je puisse suivre clairement les instructions et voir quels objets se trouvent dans le système et quelles méthodes de manipulation je peux utiliser. »Grain. Une approche
Ensuite, il est devenu clair pour nous que c'était cool de faire une spécification pour notre service. Bref, faire une liste d'objets de notre système, une liste de points, de manipulations et quels objets ils jonglent entre eux. Il se trouve que dans notre entreprise, nous utilisons Swagger à ces fins comme une sorte de solution architecturale. Après avoir examiné la structure Swagger, j'ai réalisé que je devais prendre quelque part la structure des objets qui se trouvent dans le système. Du noyau, je n'ai reçu que trois méthodes standard et un changeur de table. Rien d'autre. Pour moi, il semblait alors impossible de récupérer toute la structure qui se trouve dans le référentiel à partir de ces quatre champs standard. Je n'ai sincèrement pas compris où me procurer toutes les descriptions d'objets, toutes les valeurs autorisées, toute la logique ...SC:- Qu'est-ce que cela signifie où? Vous et moi avons MetaMeta, qui fournit le noyau en mode temps réel. Le noyau en exécution en temps réel génère une requête SQL qui communique avec la base de données. Tout est là, pas seulement ce dont vous avez besoin. Il existe également des liens entre les objets.AC: - Sur les conseils de Stas, je suis ensuite allé chez MetaMetu et j'ai été surpris, car tout le kit de gentleman nécessaire pour générer des spécifications standard était là. Puis l'idée est venue que vous devez créer un modèle et tout peindre selon sept scénarios possibles - 7 API standard pour chaque objet.
Après avoir examiné la structure Swagger, j'ai réalisé que je devais prendre quelque part la structure des objets qui se trouvent dans le système. Du noyau, je n'ai reçu que trois méthodes standard et un changeur de table. Rien d'autre. Pour moi, il semblait alors impossible de récupérer toute la structure qui se trouve dans le référentiel à partir de ces quatre champs standard. Je n'ai sincèrement pas compris où me procurer toutes les descriptions d'objets, toutes les valeurs autorisées, toute la logique ...SC:- Qu'est-ce que cela signifie où? Vous et moi avons MetaMeta, qui fournit le noyau en mode temps réel. Le noyau en exécution en temps réel génère une requête SQL qui communique avec la base de données. Tout est là, pas seulement ce dont vous avez besoin. Il existe également des liens entre les objets.AC: - Sur les conseils de Stas, je suis ensuite allé chez MetaMetu et j'ai été surpris, car tout le kit de gentleman nécessaire pour générer des spécifications standard était là. Puis l'idée est venue que vous devez créer un modèle et tout peindre selon sept scénarios possibles - 7 API standard pour chaque objet.Grain. OAS + Guidon
Donc, il est facile de remarquer en quoi consiste la spécification: vous pouvez aller sur le site Web de l'OEA et sur le guidon (au bas de la diapositive) et voir en quoi cela devrait consister - il y a un ensemble de points de terminaison, un ensemble de méthodes et à la fin il y a des modèles. Le code est répété de temps en temps. Pour chaque objet, nous devons écrire get, put. supprimer; pour un groupe d'objets, nous devons écrire ceci et ainsi de suite.L'astuce était d'écrire toute l'histoire une fois et de ne plus se baigner. La diapositive montre un exemple de code réel. Les objets bleus sont des balises dans le guidon, il s'agit d'un moteur de modèle; assez flexible, je conseille à tout le monde - vous pouvez le personnaliser pour vous-même, écrire des gestionnaires de balises personnalisés ...Au lieu de ces balises bleues, lorsque ce modèle est exécuté sur toutes les métadonnées, toutes les propriétés significatives sont substituées - le nom de l'objet, sa description, une sorte de logique (par exemple, que nous devons ajouter un paramètre supplémentaire, selon la propriété) et ainsi de suite. À la fin se trouve un lien vers le modèle qu'il interprète.
vous pouvez aller sur le site Web de l'OEA et sur le guidon (au bas de la diapositive) et voir en quoi cela devrait consister - il y a un ensemble de points de terminaison, un ensemble de méthodes et à la fin il y a des modèles. Le code est répété de temps en temps. Pour chaque objet, nous devons écrire get, put. supprimer; pour un groupe d'objets, nous devons écrire ceci et ainsi de suite.L'astuce était d'écrire toute l'histoire une fois et de ne plus se baigner. La diapositive montre un exemple de code réel. Les objets bleus sont des balises dans le guidon, il s'agit d'un moteur de modèle; assez flexible, je conseille à tout le monde - vous pouvez le personnaliser pour vous-même, écrire des gestionnaires de balises personnalisés ...Au lieu de ces balises bleues, lorsque ce modèle est exécuté sur toutes les métadonnées, toutes les propriétés significatives sont substituées - le nom de l'objet, sa description, une sorte de logique (par exemple, que nous devons ajouter un paramètre supplémentaire, selon la propriété) et ainsi de suite. À la fin se trouve un lien vers le modèle qu'il interprète.Code d'application. Swagger Codegen + Guidon
Tout cela, nous l'avons encodé, enregistré, constitué une spécification. Tout était très cool et bon. Nous avons obtenu les 7 scénarios possibles pour chaque objet.Donné à l'utilisateur. Il a dit: «Wow! Cool! Maintenant, nous voulons l'utiliser! " Quel est le problème, encore une fois?Nous avons une spécification qui décrit chaque méthode en détail, que faire avec elle, quels objets manipuler. Et il existe trois méthodes de noyau standard qui prennent en entrée le tableau inversé décrit ci-dessus.Ensuite, il suffisait de croiser l'un avec l'autre (maintenant cela me semble facile). Autrement dit, lorsqu'un utilisateur appelle une méthode dans l'interface, nous avons dû la transmettre correctement et correctement au noyau, en transformant le modèle (où nous avons de belles spécifications) en ces quatre champs standard. C'était tout ce qu'il fallait faire. Pour mettre tout cela en pratique, il nous fallait des transformations «nominatives» ...
Pour mettre tout cela en pratique, il nous fallait des transformations «nominatives» ...Conversions
Swagger a initialement un tel outil - Swagger Codegen. Si vous êtes déjà entré dans les spécifications, faites, il y a un bouton "Générer une partie serveur". Cliquez sur, choisissez une langue - un projet terminé est généré pour vous.Il est généré de façon remarquable: il y a toutes les descriptions de classe, toutes les descriptions de points de terminaison ... - cela fonctionne. Vous pouvez l'exécuter localement - cela fonctionnera. Le problème est un: il renvoie des talons - chaque méthode n'est pas incrémentée.L'idée était d'ajouter une logique basée sur ces sept scénarios dans le générateur de code - «gâcher» l'un des modèles standard, configurez-le par vous-même. Voici juste un exemple de code réel que nous utilisons dans le moteur de modèle et une liste des actions que nous devions effectuer pour configurer ce générateur de code pour nous-mêmes: La chose la plus importante qu'ils ont faite a été de connecter les bibliothèques nécessaires, d'écrire des classes pour communiquer avec le noyau et d'interpréter (selon le scénario) l'appel d'une ou plusieurs méthodes côté noyau. Le modèle a également été retourné: du beau indiqué dans le cahier des charges à quatre champs, puis retransformé.Le cas probablement le plus difficile ici était de donner à l'utilisateur un arbre, car le noyau nous renvoie également quatre lignes - allez voir à quel niveau se trouve la hiérarchie. Nous avons utilisé le mécanisme des relations extérieures, qui est dans l'IDE, c'est-à-dire que nous sommes allés à MetaMetu, regardé tous les chemins les uns des autres et généré dynamiquement un arbre à travers eux. L'utilisateur peut nous demander à n'importe quel objet ce qu'il veut - un bel arbre lui sera rendu à la sortie, dans lequel tout est déjà structuré.SC: - Je vais vous arrêter une seconde, car je commence déjà à me perdre. Je vais vous demander dans le style "Est-ce que je comprends bien" ...Vous voulez dire que nous avons calculé tout le code le plus compliqué et le plus complexe qui devrait être écrit pour un nouvel objet. Et pour gagner du temps, pas pour le faire, nous avons réussi à tout mettre dans le noyau et à rendre cette histoire dynamique ... Mais cette API (comme ils plaisantaient, "têtue") est si "peut faire n'importe quoi" qu'il est effrayant de la donner à l'extérieur: avec lui, vous pouvez corrompre les métadonnées. C'est d'une part.D'autre part, nous avons réalisé que nous ne pouvons pas communiquer avec nos clients clients à moins que nous ne leur donnions une API, qui sera une projection unique de ces objets de gestion des métadonnées qui sont intégrés dans le système (en fait, exécuter un certain contrat pour notre service). Il semblerait que tout - on frappe: si l'objet n'est pas là - il n'est pas encore là, et quand il apparaît - l'extension de contrat apparaît, déjà un nouveau code.Nous semblons être entrés dans le codage manuel évitable, mais ici vous proposez de faire ce code par bouton. Encore une fois, nous parvenons à sortir de l'histoire lorsque nous devons écrire quelque chose avec nos mains. C'est vrai?AC: - Oui, ça l'est vraiment. En général, mon idée était de commencer la programmation une fois pour toutes, au moins à l'aide de moteurs de modèles. Écrivez le code une fois, puis détendez-vous. Et même si un nouvel objet apparaît dans le système - par le bouton on démarre la mise à jour, tout se resserre, on a une nouvelle structure, de nouvelles méthodes sont générées, tout va bien.
La chose la plus importante qu'ils ont faite a été de connecter les bibliothèques nécessaires, d'écrire des classes pour communiquer avec le noyau et d'interpréter (selon le scénario) l'appel d'une ou plusieurs méthodes côté noyau. Le modèle a également été retourné: du beau indiqué dans le cahier des charges à quatre champs, puis retransformé.Le cas probablement le plus difficile ici était de donner à l'utilisateur un arbre, car le noyau nous renvoie également quatre lignes - allez voir à quel niveau se trouve la hiérarchie. Nous avons utilisé le mécanisme des relations extérieures, qui est dans l'IDE, c'est-à-dire que nous sommes allés à MetaMetu, regardé tous les chemins les uns des autres et généré dynamiquement un arbre à travers eux. L'utilisateur peut nous demander à n'importe quel objet ce qu'il veut - un bel arbre lui sera rendu à la sortie, dans lequel tout est déjà structuré.SC: - Je vais vous arrêter une seconde, car je commence déjà à me perdre. Je vais vous demander dans le style "Est-ce que je comprends bien" ...Vous voulez dire que nous avons calculé tout le code le plus compliqué et le plus complexe qui devrait être écrit pour un nouvel objet. Et pour gagner du temps, pas pour le faire, nous avons réussi à tout mettre dans le noyau et à rendre cette histoire dynamique ... Mais cette API (comme ils plaisantaient, "têtue") est si "peut faire n'importe quoi" qu'il est effrayant de la donner à l'extérieur: avec lui, vous pouvez corrompre les métadonnées. C'est d'une part.D'autre part, nous avons réalisé que nous ne pouvons pas communiquer avec nos clients clients à moins que nous ne leur donnions une API, qui sera une projection unique de ces objets de gestion des métadonnées qui sont intégrés dans le système (en fait, exécuter un certain contrat pour notre service). Il semblerait que tout - on frappe: si l'objet n'est pas là - il n'est pas encore là, et quand il apparaît - l'extension de contrat apparaît, déjà un nouveau code.Nous semblons être entrés dans le codage manuel évitable, mais ici vous proposez de faire ce code par bouton. Encore une fois, nous parvenons à sortir de l'histoire lorsque nous devons écrire quelque chose avec nos mains. C'est vrai?AC: - Oui, ça l'est vraiment. En général, mon idée était de commencer la programmation une fois pour toutes, au moins à l'aide de moteurs de modèles. Écrivez le code une fois, puis détendez-vous. Et même si un nouvel objet apparaît dans le système - par le bouton on démarre la mise à jour, tout se resserre, on a une nouvelle structure, de nouvelles méthodes sont générées, tout va bien.Tuning MetaMeta
Afin de rendre notre service encore meilleur, nous avons enrichi la MetaMeta standard. A l'entrée, nous avions ce qui restait du noyau. Nous avons également ajouté une description supplémentaire aux objets, les objets sont regroupés en zones. Nous affichons tout cela dans la spécification afin que l'utilisateur comprenne ce qu'il manipule et avec quel objet il communique actuellement.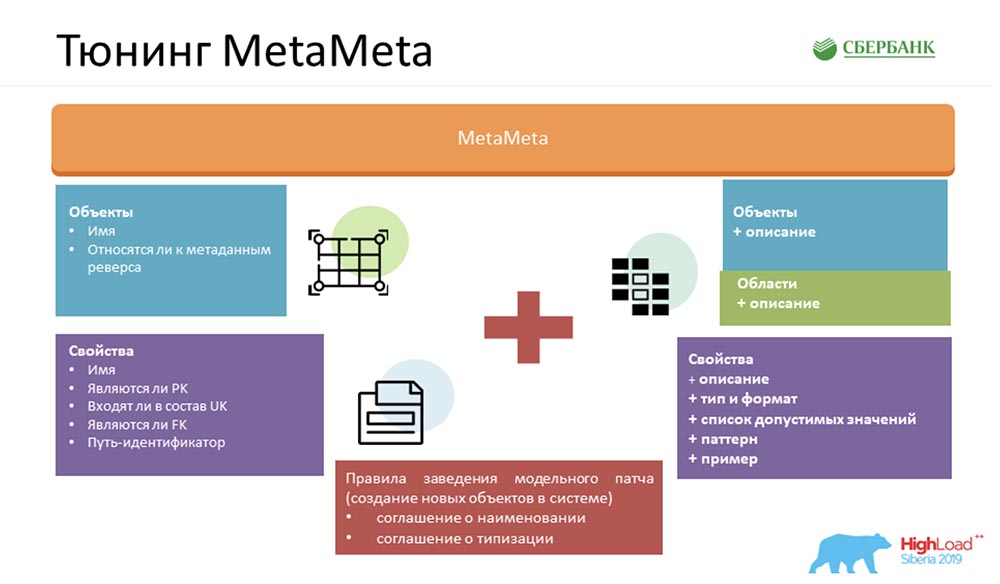 Seulement, nous y avons ajouté quelques petites choses - types, formats, listes de valeurs acceptables, modèles, exemples. Cela plaît également aux utilisateurs - ils comprennent déjà clairement ce qui peut être inséré, ce qui ne peut pas. Nous fournissons également un artefact client à l'utilisateur, ce qui nous permet de détecter les erreurs lors de la communication avec notre service (précisément par format, déjà au stade de la compilation).Mais le plus important, pour que toute cette magie fonctionne, nous devions nous mettre d'accord sur l'intérieur: créer un ensemble de certaines règles. Il n'y en a pas beaucoup - j'en ai compté trois (il y en a deux sur la diapositive, donc il faudra s'en souvenir):
Seulement, nous y avons ajouté quelques petites choses - types, formats, listes de valeurs acceptables, modèles, exemples. Cela plaît également aux utilisateurs - ils comprennent déjà clairement ce qui peut être inséré, ce qui ne peut pas. Nous fournissons également un artefact client à l'utilisateur, ce qui nous permet de détecter les erreurs lors de la communication avec notre service (précisément par format, déjà au stade de la compilation).Mais le plus important, pour que toute cette magie fonctionne, nous devions nous mettre d'accord sur l'intérieur: créer un ensemble de certaines règles. Il n'y en a pas beaucoup - j'en ai compté trois (il y en a deux sur la diapositive, donc il faudra s'en souvenir):- Convention de dénomination. Nous nommons spécifiquement les objets dans le système afin de faciliter la reconnaissance des scénarios pour leur utilisation ultérieure.
- Accord de dactylographie. C'est pour déterminer correctement les types, les formats et qu'ils se sont battus entre le noyau et le serveur d'applications, nous utilisons le système de vérification, par lequel nous comprenons à quel format appartient une propriété particulière.
- Clés étrangères valides. Si l'objet reçoit un lien non valide vers un autre objet, alors toute cette magie ne fonctionnera pas correctement.
Résultat
SC: - C'est cool, mais beaucoup de théorie. Pouvez-vous donner un exemple pratique?AC: - Oui, je l'ai spécialement préparé. Avant de partir pour la conférence, vendredi soir, littéralement 5 minutes avant la fin de la journée de travail, Stas m'a dit: «Oh, regarde! J'ai publié un patch de modèle - comme c'est cool! Ce serait bien de mettre à jour notre service. " Le patch ne contenait que deux objets, mais je comprends qu'avec l'ancienne approche, je devrais être confus et écrire ou ajouter 7 API.Immédiatement, j'ai juste eu le clic d'un bouton pour faire fonctionner toute cette magie. J'ai spécialement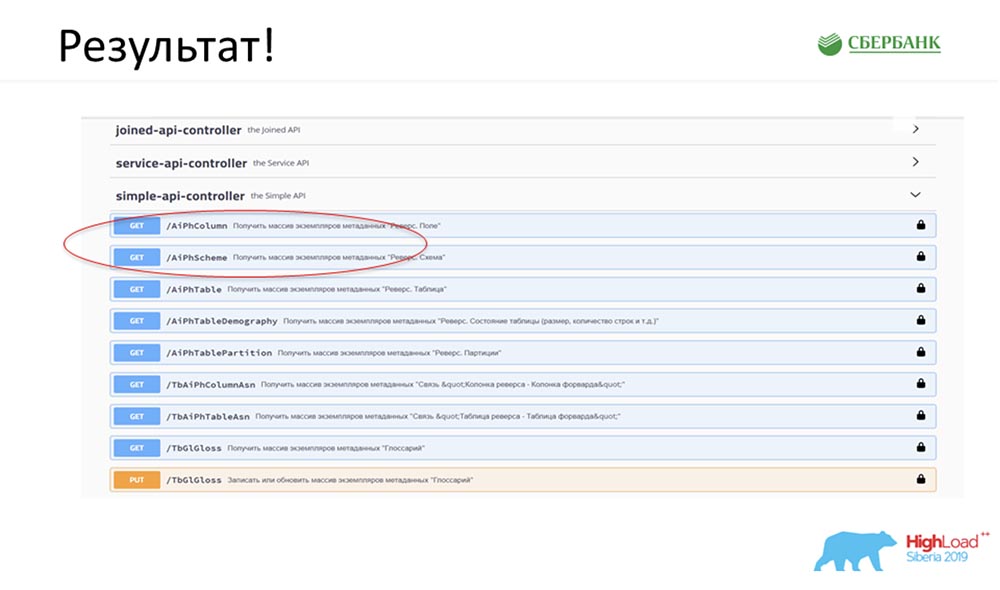 encerclé en rouge l' endroit où la magie est sur le point de se produire: je clique sur le bouton ... Ce sont bien sûr des captures d'écran, mais en réalité tout fonctionne comme ceci:
encerclé en rouge l' endroit où la magie est sur le point de se produire: je clique sur le bouton ... Ce sont bien sûr des captures d'écran, mais en réalité tout fonctionne comme ceci: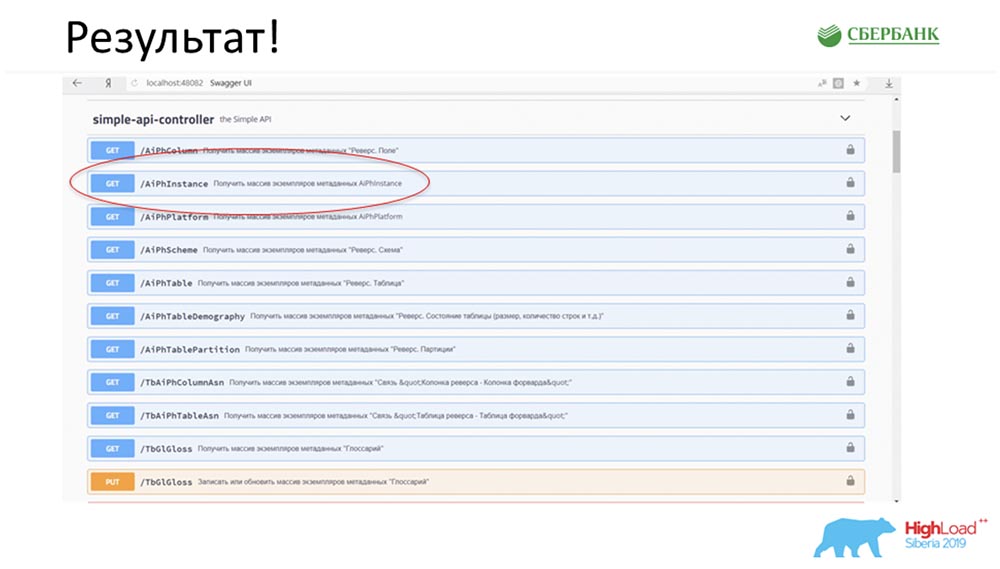 Nous avons une nouvelle méthode (entre les deux), qui donne déjà des données, par laquelle nous, dans la hiérarchie, pouvons interroger la structure entière, tous les objets imbriqués:
Nous avons une nouvelle méthode (entre les deux), qui donne déjà des données, par laquelle nous, dans la hiérarchie, pouvons interroger la structure entière, tous les objets imbriqués: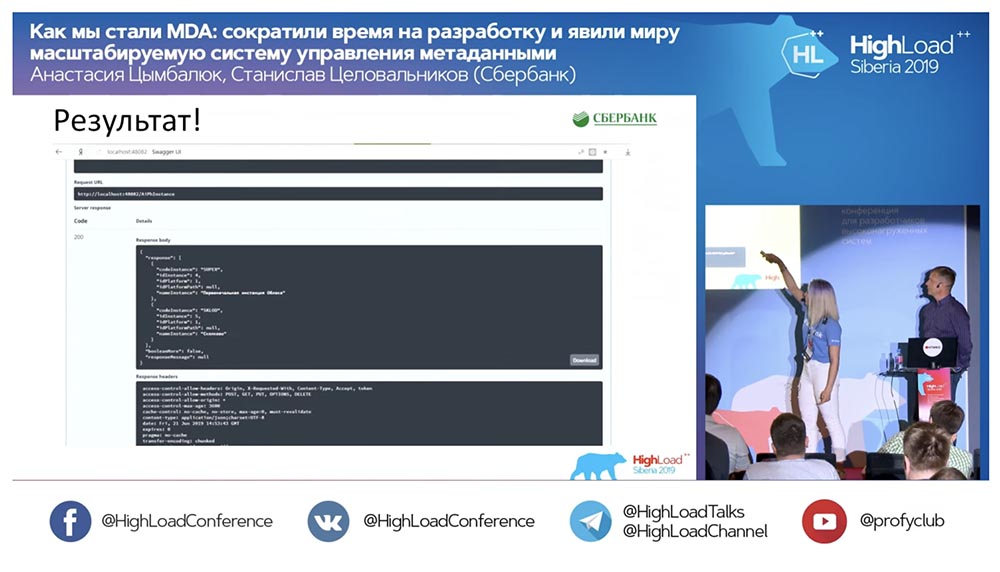
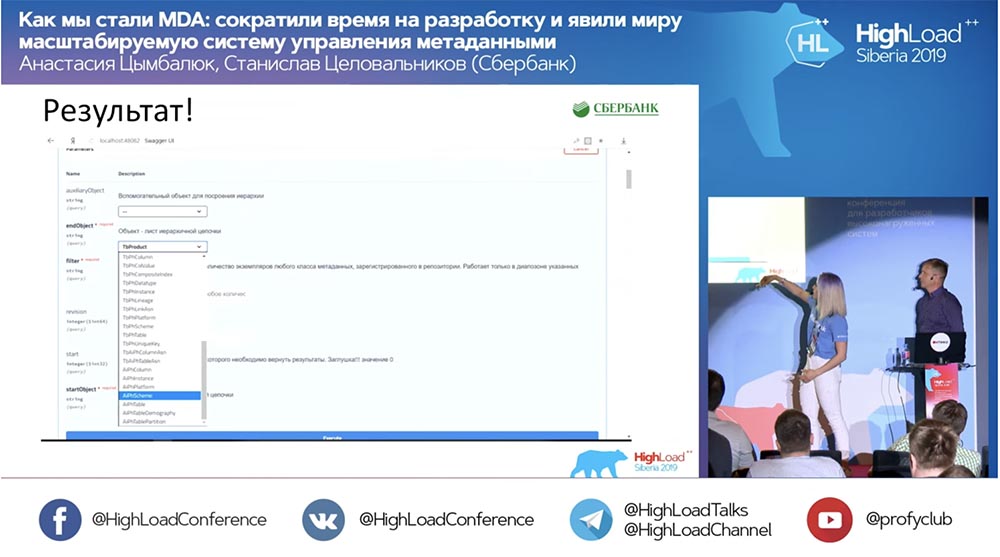
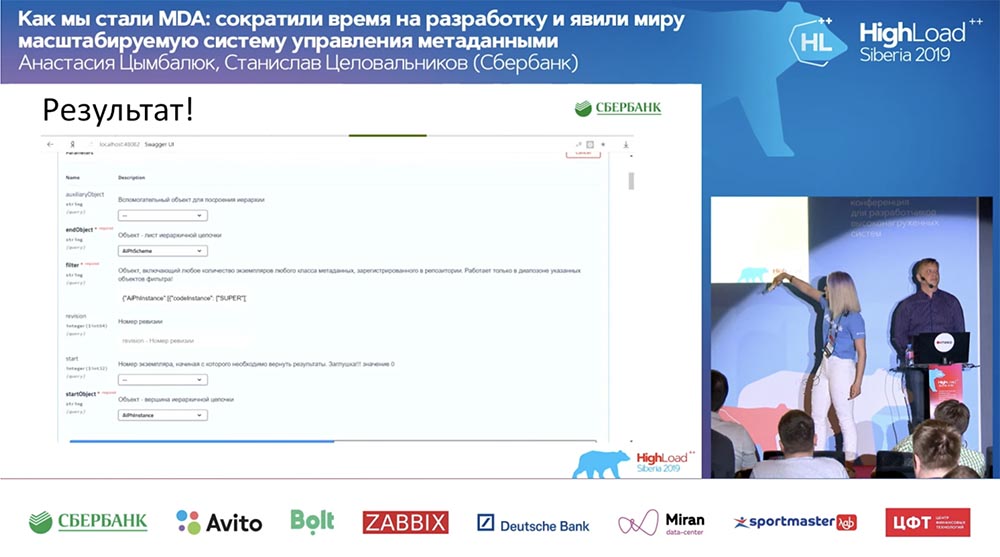 Et tout fonctionne! Je n'ai pas du tout écrit une seule ligne de code.
Et tout fonctionne! Je n'ai pas du tout écrit une seule ligne de code.Sommaire
SC: - Premièrement, quel est le fait? Nous avons géré la logique la plus complexe, ce qui prendrait le plus de temps à nos programmeurs, pour emballer du code de noyau 100% dynamique qui peut fonctionner avec des objets - ceux qui le sont et ceux qui le seront: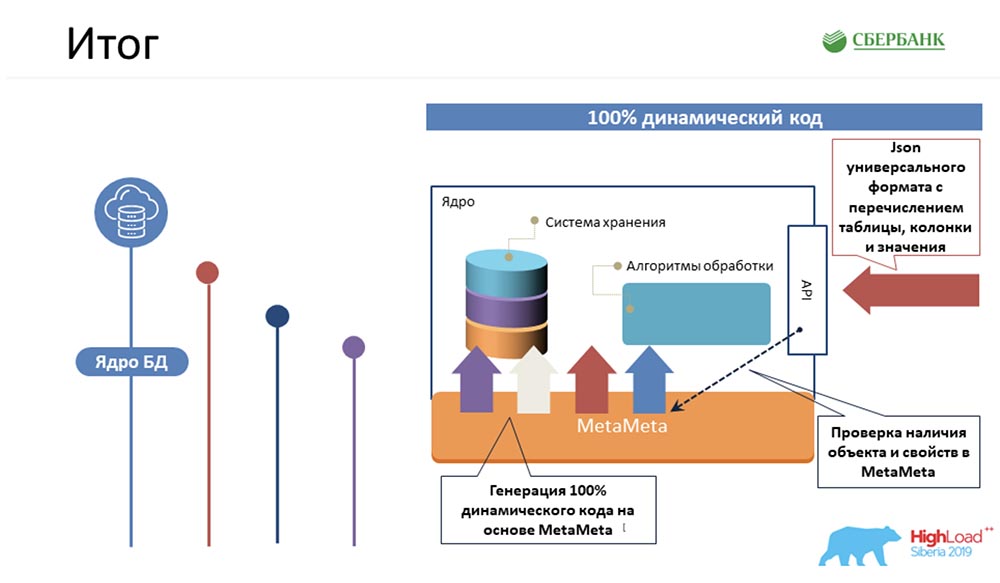 Deuxièmement, nous avons réussi au niveau du serveur d'applications (où ce n'est pas possible) pour éviter également la programmation en raison de la génération de code - le même bouton que vous avez démontré:
Deuxièmement, nous avons réussi au niveau du serveur d'applications (où ce n'est pas possible) pour éviter également la programmation en raison de la génération de code - le même bouton que vous avez démontré: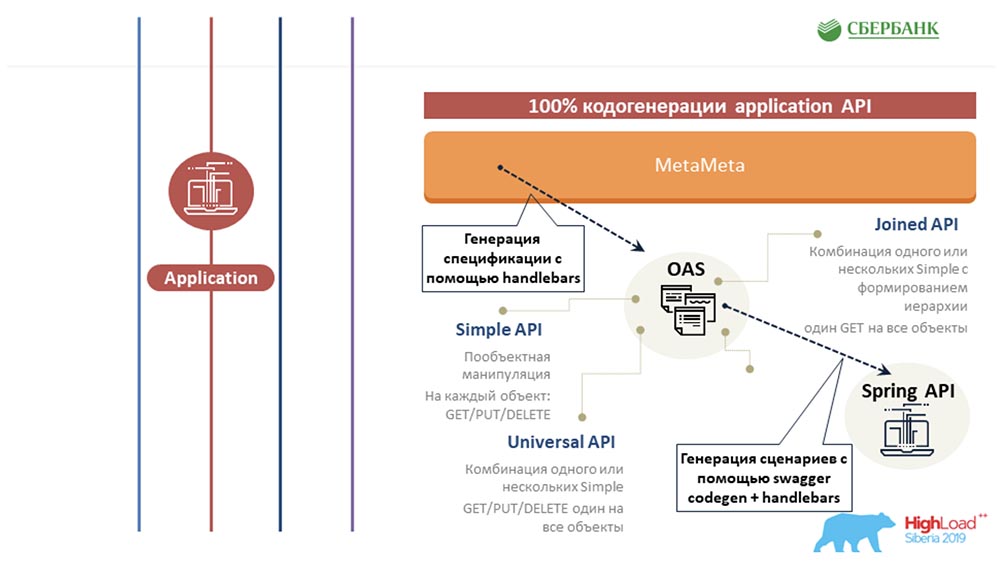 AC: - Nous avons essayé d'étendre la même approche basée sur les métadonnées à d'autres zones, à la zone de test. Nous écrivons également un modèle une fois pour certains objets, y insérons des balises. Et lorsque ce modèle est exécuté le long des métadonnées, il génère une feuille finie avec tous les scénarios de test, c'est-à-dire que nous couvrons tous les objets avec des tests.
AC: - Nous avons essayé d'étendre la même approche basée sur les métadonnées à d'autres zones, à la zone de test. Nous écrivons également un modèle une fois pour certains objets, y insérons des balises. Et lorsque ce modèle est exécuté le long des métadonnées, il génère une feuille finie avec tous les scénarios de test, c'est-à-dire que nous couvrons tous les objets avec des tests.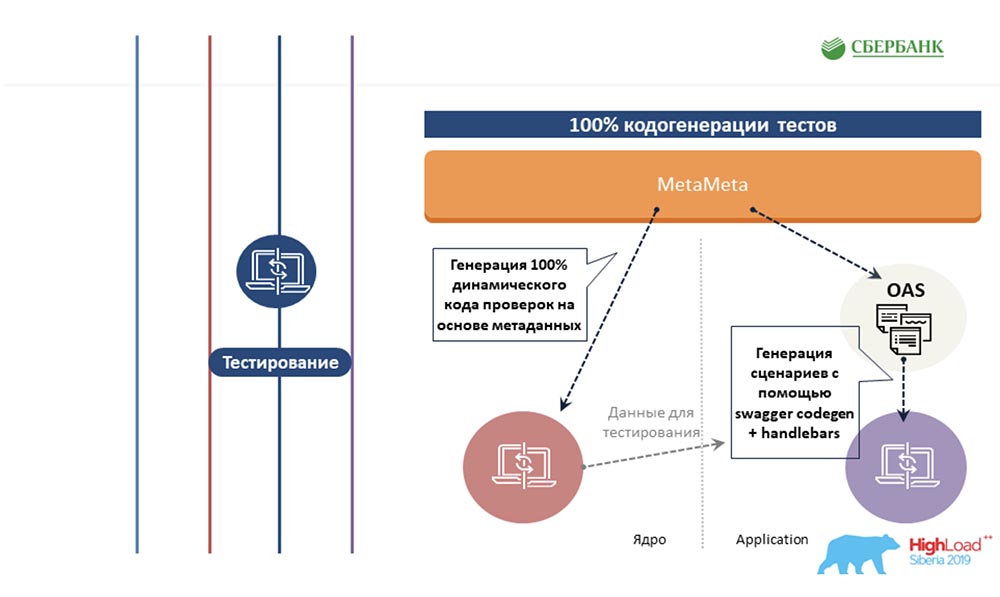 Ensuite, la cerise sur le gâteau. Je sais que peu de gens aiment documenter ce qu'ils font. Nous avons également résolu cette douleur en fonction des métadonnées. Une fois que nous avons préparé un modèle avec un balisage html, nous l'avons marqué. Et lorsque nous passons en revue les métadonnées, toutes ces balises sont remplacées par leurs propriétés correspondant aux objets.
Ensuite, la cerise sur le gâteau. Je sais que peu de gens aiment documenter ce qu'ils font. Nous avons également résolu cette douleur en fonction des métadonnées. Une fois que nous avons préparé un modèle avec un balisage html, nous l'avons marqué. Et lorsque nous passons en revue les métadonnées, toutes ces balises sont remplacées par leurs propriétés correspondant aux objets. La sortie est une belle page html terminée. Ensuite, nous publions dans Confluence, et nous pouvons donner à nos utilisateurs dans un format lisible par l'homme afin qu'ils puissent voir ce que nous avons dans le système, comment travailler avec lui, une description minimale, des valeurs acceptables, des propriétés requises, des clés ... Ils peuvent tous le faire voir et peut le comprendre assez facilement.En conséquence, nous avons quatre points principaux, et cette approche est appelée MDA (Model Driven Architecture). Pour une raison quelconque, cela se traduit par une «architecture pilotée par les modèles», même si je l'appellerais une «méthode de développement logiciel».
La sortie est une belle page html terminée. Ensuite, nous publions dans Confluence, et nous pouvons donner à nos utilisateurs dans un format lisible par l'homme afin qu'ils puissent voir ce que nous avons dans le système, comment travailler avec lui, une description minimale, des valeurs acceptables, des propriétés requises, des clés ... Ils peuvent tous le faire voir et peut le comprendre assez facilement.En conséquence, nous avons quatre points principaux, et cette approche est appelée MDA (Model Driven Architecture). Pour une raison quelconque, cela se traduit par une «architecture pilotée par les modèles», même si je l'appellerais une «méthode de développement logiciel». Dans quel but? Vous créez un modèle, convenez de certaines règles. Ensuite, vous créez des modèles de transformation uniques de ce modèle dans un langage de programmation à votre disposition. Tout cela fonctionne pour changer d'anciens objets, pour en ajouter de nouveaux. Vous écrivez le code une fois et ne vous embêtez plus.SC: - Honnêtement, j'ai attendu l'intégralité du rapport lorsque vous répondez à cette question. Passons à mes diapositives préférées.
Dans quel but? Vous créez un modèle, convenez de certaines règles. Ensuite, vous créez des modèles de transformation uniques de ce modèle dans un langage de programmation à votre disposition. Tout cela fonctionne pour changer d'anciens objets, pour en ajouter de nouveaux. Vous écrivez le code une fois et ne vous embêtez plus.SC: - Honnêtement, j'ai attendu l'intégralité du rapport lorsque vous répondez à cette question. Passons à mes diapositives préférées.Décision. Processus. Avant
AC: - «Le processus. Avant »- c'est notre fierté, parce que nous programmions beaucoup, ne mangions presque rien - nous étions très mauvais. J'ai dû effectuer toutes ces 5 étapes pour chaque objet: c'était très triste et cela nous a pris beaucoup de temps. Nous avons maintenant réduit cette chaîne alimentaire à trois maillons, dont le plus important est simplement de créer correctement l'objet, et rien de plus:
c'était très triste et cela nous a pris beaucoup de temps. Nous avons maintenant réduit cette chaîne alimentaire à trois maillons, dont le plus important est simplement de créer correctement l'objet, et rien de plus: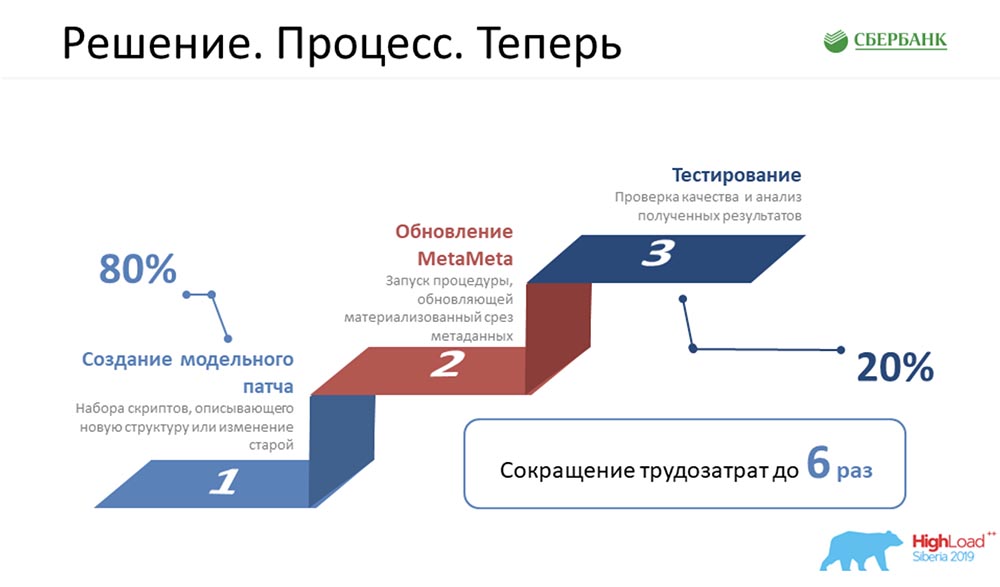 MetaMeta est lancé par un bouton (mise à jour), puis en test. Nous cherchons actuellement à nous assurer que rien ne nous échappe, puisque nous avons récemment commencé à appliquer cette approche. Nous essayons de contrôler tout ce processus.Selon les estimations, tous nos coûts de main-d'œuvre pour le développement de tous nos logiciels ont été réduits de 6 fois.CAROLINE DU SUD:- De ma part, je tiens à dire sincèrement que le chiffre 6 n'est pas soufflé, il est même conservateur. En fait, l'efficacité est encore plus élevée.
MetaMeta est lancé par un bouton (mise à jour), puis en test. Nous cherchons actuellement à nous assurer que rien ne nous échappe, puisque nous avons récemment commencé à appliquer cette approche. Nous essayons de contrôler tout ce processus.Selon les estimations, tous nos coûts de main-d'œuvre pour le développement de tous nos logiciels ont été réduits de 6 fois.CAROLINE DU SUD:- De ma part, je tiens à dire sincèrement que le chiffre 6 n'est pas soufflé, il est même conservateur. En fait, l'efficacité est encore plus élevée.Plans futurs
Vous avez demandé à la fin du rapport de vous attarder sur nos plans. Tout d'abord, il semble que nous devons parvenir non seulement à une solution complète, mais aliénée et en boîte. Ces technologies peuvent être appliquées quelque part à proximité, le cas échéant. J'aimerais obtenir un produit fini qui sera développé et que nous pourrons proposer au nom de Sberbank.Bien sûr, si nous parlons de tâches immédiates, elles sont toutes affichées sur les diapositives avec des puces. Malgré l'optimisation que nous avons reçue, la charge sur l'équipe est encore assez sérieuse. Je ne peux pas dire avec certitude à partir de quel trimestre nous pouvons passer à la mise en œuvre de ces étapes.Numéro 6 et le cas que Nastya a apporté - ils sont honnêtes. C'était vraiment vendredi, lorsque nous devions obtenir des documents (avion, voyage, etc.). L'équipe adjacente était prévue pour des tests lundi, et nous devions publier ce correctif, pas pour configurer les gars. Ça a marché! C'est un vrai cas.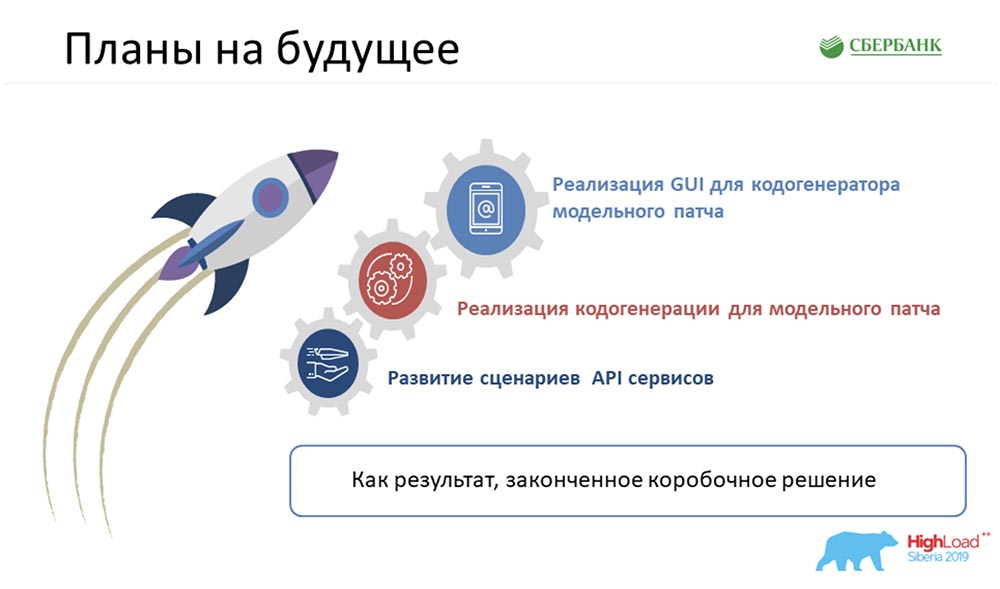 Je serais heureux si cela pouvait être utile pour n'importe lequel d'entre vous. Si vous avez des questions, nous sommes disponibles. Et après le rapport, ici aussi pendant un certain temps. Demander. Nous serons heureux de pouvoir vous aider!AC:- En effet, cette approche, je pense, peut commencer à être utilisée par tout le monde. Pas nécessairement sous notre forme (nous sommes engagés dans la gestion des métadonnées). Cela peut être un système de contrôle de n'importe quoi. Tout ce que vous devez avoir à portée de main est une vue relationnelle des choses, prendre des métadonnées à partir de là, comprendre certains moteurs de modèle et comprendre un langage de programmation (comment cela fonctionne).Tous ces outils sont dans le domaine public - vous pouvez déjà commencer à googler et comprendre comment les utiliser. Je suis sûr que leur utilisation vous rendra la vie plus facile, meilleure et libère généralement du temps pour de nouvelles tâches ambitieuses et cool. Remercier!
Je serais heureux si cela pouvait être utile pour n'importe lequel d'entre vous. Si vous avez des questions, nous sommes disponibles. Et après le rapport, ici aussi pendant un certain temps. Demander. Nous serons heureux de pouvoir vous aider!AC:- En effet, cette approche, je pense, peut commencer à être utilisée par tout le monde. Pas nécessairement sous notre forme (nous sommes engagés dans la gestion des métadonnées). Cela peut être un système de contrôle de n'importe quoi. Tout ce que vous devez avoir à portée de main est une vue relationnelle des choses, prendre des métadonnées à partir de là, comprendre certains moteurs de modèle et comprendre un langage de programmation (comment cela fonctionne).Tous ces outils sont dans le domaine public - vous pouvez déjà commencer à googler et comprendre comment les utiliser. Je suis sûr que leur utilisation vous rendra la vie plus facile, meilleure et libère généralement du temps pour de nouvelles tâches ambitieuses et cool. Remercier!Des questions
Question du public (ci-après - A): - Dois-je bien comprendre que tout est empilé parce que vous utilisez une base de données relationnelle? Il me semble que si vous regardiez vers la base de données orientée document, toute cette solution serait beaucoup plus facile pour vous que je ne le vois maintenant.SC: - Pas vraiment. Ce que nous avons commencé quand nous avons parlé des personnes travaillant au niveau du glossaire et de l'araignée qui va au bal, lit ces histoires et vérifie - en effet, la table avec le champ qui est responsable de ce terme du glossaire a lieu au bal . Ils ont dit de notre service: «Les gars, vous devriez avoir une API REST. Comment vous le faites est votre problème. Voici une liste des technologies autorisées - utilisez quelque chose de cette liste (c'est ce que nous pouvons utiliser dans Sberbank). »C'est le niveau de notre solution, l'architecture appliquée. Pour nous, au contraire, il était plus facile de faire cela non pas au niveau relationnel. Pourquoi? Je vais donner un exemple, l'un des nombreux ... Par exemple, je dois m'assurer, lorsque j'écris un champ, qu'il ne fait référence nulle part à une table qui n'existe pas. Je fais juste une clé étrangère dans la base de données et je ne suis pas inquiet. Je n'écris pas de ligne - elle ne me laissera pas faire ce disque. Et il en existe de nombreux exemples!Ici, nous devrions plutôt parler d'autre chose. Une histoire plus compliquée: nous publierons un correctif de modèle avec un ensemble de données d'ajustement / certification, et il y a 6 objets. Et inévitablement, pour que vous puissiez fournir cet ensemble gentleman d'API, vous avez besoin de trois mois pour travailler (à la main). Cela nous prendra une semaine et demie. Sans l'application de ces technologies, il était tout simplement impossible de survivre dans ces conditions. Nous ne donnerions tout simplement pas un tel niveau de service!Ceci est possible si vous avez construit la production de telle manière que vous avez un patch de modèle (nouvel objet), un bouton «Tout faire bien» et un logiciel qui testera en mode d'émulation client. A gagné un nouveau, l'ancien ne tombait pas - cela devait être réalisé, mais comment - c'était le choix de l'équipe. R: - J'ai une deuxième question. Et quel est un exemple d'utilisation de la vie? Je comprends que théoriquement il semble que vous pouvez au moins décrire le monde entier avec votre objet META_META ... Mais dans la vie, comment l'utilisez-vous? A en juger par la façon dont il est mis en œuvre (tout doit être mis les uns dans les autres), il devrait ralentir!CAROLINE DU SUD:- Au fait, non (étonnamment)! Une autre application de cette histoire est les générateurs de code. C'est là que certaines vitrines, stockages sont construits, et vous êtes ETL, vous essayez de garer toutes les options possibles sur neuf modèles, neuf moteurs de modèles qui sont décrits à l'avance. À l'aide de métadonnées, vous décrivez cette transformation en utilisant ces modèles comme stubs. De plus, cette machine sans programmation donne un code ETL, génère du code basé sur des métadonnées. Je crois qu'il existe également de telles technologies, les approches seront appropriées et correctes.R: - Je comptais sur un exemple plus précis.R: - Dites-moi, s'il vous plaît, il a été écrit dans vos exigences que vous devez effectuer des requêtes structurelles complexes (Join et similaires). Dans quelle langue est-il implémenté ou le décrivez-vous de façon logique?CAROLINE DU SUD:- Accès via l'API REST, le plus souvent c'est Java, bien qu'il puisse s'agir de n'importe quel langage. Notre service a été publié (dhttps, demandez https - vous obtiendrez JSON). Ces morceaux de code que nous avons montrés sont SQL. Afin de comprendre dans quel ordre il doit être traité, nous avons effectué un réglage SQL sur les dictionnaires SGBD et l'avons placé dans un schéma séparé sous la forme de représentations matérialisées. En conséquence, lorsqu'un patch de modèle est publié, le bouton «Actualiser la vue matérialisée» est cliqué (les champs + apparaissent). Mais vraiment notre code est Java et Oracle.AC:- Il convient de noter ici que nous avons décidé de diviser les domaines de responsabilité. Nous avons délibérément transféré toute la magie au noyau, et Application interprète simplement correctement ces réponses. Autrement dit, le mécanisme Join lui-même se produit dans le noyau, et Java diffuse tout simplement avec compétence tout dans l'arborescence et donne à l'utilisateur le résultat final.R: - Et que fait Code Gens - y écrivez-vous déjà la logique des requêtes complexes? Ou est-ce fait du côté client? Nous devons comprendre quel côté est décrit ... Ils ont présenté, il s'avère, Code Gen, sur lequel il est nécessaire de décrire avec précision dans une certaine structure: par exemple, je veux que mon API apprenne telle ou telle Join, parcourez la liste; alors dites s'il y a dedans ou pas ... - des requêtes complexes suffisent. À quel stade est-ce écrit?CAROLINE DU SUD:- Si je comprends bien votre question, c'est exactement l'histoire quand nos clients, nos clients (c'est une équipe à l'intérieur du noyau, de la plateforme) disent: "Écoutez, nous ne voulons pas programmer - donnez-nous cela." «Ça y est» tout a été fait dans le noyau. Le noyau - essentiellement quoi? 80 pour cent, peut-être 90 - c'est la génération de code dynamique, le texte qui sera appelé sous PL / SQL, mais tourné vers la base de données. Là, même dans le temps, cette ligne est générée plus longtemps, puis la base de données est accédée (par exemple, la demande Join), la retourne, l'enveloppe en JSON et l'affiche à l'envers. De plus, Java transforme tout cela en un contrat, qui dépend de la structure.ET:- Révélé une solution de mise à jour par lots. Et comment se déroule la garantie de livraison - le colis est-il arrivé en totalité ou en partie? Ont-ils un certain cachend? Et comment s'assurer que ni le service ne tombe, ni les structures de données n'ont aucune sorte de cohérence, afin qu'il n'y ait pas d'erreurs?SC: - Nous avons un protocole - il existe deux modes de mise à jour. Dans l'un d'eux, vous pouvez définir le drapeau "Appliquer tout ce que vous pouvez." Il existe certains logiciels qu'Excel convertit en JSON - il peut y avoir 10 000 lignes. Et vous, à proprement parler, deux lignes peuvent être invalides (erreur). Et soit vous dites: «Appliquez tout ce que vous pouvez»; ou "Appliquer uniquement si toute l'histoire n'aura pas une seule erreur." Là, le statut intégral sera par exemple la restauration. En fait, une insertion est effectuée dans la base de données, mais la validation n'est pas appelée.En cas d'erreur - il appelle un rollback, c'est dans le protocole; vous obtenez le protocole de toute façon. Vous obtenez un statut sur chaque ligne et vous avez un identifiant dans un champ séparé - soit un nombre (identifiant d'objet), soit une autre clé, soit les deux. Le protocole permet de comprendre ce qui est arrivé à ma demande.AC: - L'utilisateur lui-même indique dans laquelle des options il doit se déplacer. Nous passons ce paramètre au côté du noyau, et le noyau produit déjà toute la magie, nous donne la réponse et nous l'interprétons.ET:"Pourquoi n'avez-vous pas utilisé de compilateur d'expressions intégré qui aiderait à définir la règle?" Supposons que nous ayons un modèle, je blogue dans une langue (langage de script tapé / non tapé); a écrit: "Je veux une liste." Passé ce fragment pour qu'un processeur de code mâche tout cela, le mette dans une base de données NoSQL, comme suggéré dans la première question ... Pourtant, il n'est pas clair pourquoi une base de données relationnelle et pourquoi et comment gérer la redondance des données? Un homme vous envoie un modèle avec un milliard de déchets ... Comment ces accords sont-ils conclus quand une personne en a besoin?
R: - J'ai une deuxième question. Et quel est un exemple d'utilisation de la vie? Je comprends que théoriquement il semble que vous pouvez au moins décrire le monde entier avec votre objet META_META ... Mais dans la vie, comment l'utilisez-vous? A en juger par la façon dont il est mis en œuvre (tout doit être mis les uns dans les autres), il devrait ralentir!CAROLINE DU SUD:- Au fait, non (étonnamment)! Une autre application de cette histoire est les générateurs de code. C'est là que certaines vitrines, stockages sont construits, et vous êtes ETL, vous essayez de garer toutes les options possibles sur neuf modèles, neuf moteurs de modèles qui sont décrits à l'avance. À l'aide de métadonnées, vous décrivez cette transformation en utilisant ces modèles comme stubs. De plus, cette machine sans programmation donne un code ETL, génère du code basé sur des métadonnées. Je crois qu'il existe également de telles technologies, les approches seront appropriées et correctes.R: - Je comptais sur un exemple plus précis.R: - Dites-moi, s'il vous plaît, il a été écrit dans vos exigences que vous devez effectuer des requêtes structurelles complexes (Join et similaires). Dans quelle langue est-il implémenté ou le décrivez-vous de façon logique?CAROLINE DU SUD:- Accès via l'API REST, le plus souvent c'est Java, bien qu'il puisse s'agir de n'importe quel langage. Notre service a été publié (dhttps, demandez https - vous obtiendrez JSON). Ces morceaux de code que nous avons montrés sont SQL. Afin de comprendre dans quel ordre il doit être traité, nous avons effectué un réglage SQL sur les dictionnaires SGBD et l'avons placé dans un schéma séparé sous la forme de représentations matérialisées. En conséquence, lorsqu'un patch de modèle est publié, le bouton «Actualiser la vue matérialisée» est cliqué (les champs + apparaissent). Mais vraiment notre code est Java et Oracle.AC:- Il convient de noter ici que nous avons décidé de diviser les domaines de responsabilité. Nous avons délibérément transféré toute la magie au noyau, et Application interprète simplement correctement ces réponses. Autrement dit, le mécanisme Join lui-même se produit dans le noyau, et Java diffuse tout simplement avec compétence tout dans l'arborescence et donne à l'utilisateur le résultat final.R: - Et que fait Code Gens - y écrivez-vous déjà la logique des requêtes complexes? Ou est-ce fait du côté client? Nous devons comprendre quel côté est décrit ... Ils ont présenté, il s'avère, Code Gen, sur lequel il est nécessaire de décrire avec précision dans une certaine structure: par exemple, je veux que mon API apprenne telle ou telle Join, parcourez la liste; alors dites s'il y a dedans ou pas ... - des requêtes complexes suffisent. À quel stade est-ce écrit?CAROLINE DU SUD:- Si je comprends bien votre question, c'est exactement l'histoire quand nos clients, nos clients (c'est une équipe à l'intérieur du noyau, de la plateforme) disent: "Écoutez, nous ne voulons pas programmer - donnez-nous cela." «Ça y est» tout a été fait dans le noyau. Le noyau - essentiellement quoi? 80 pour cent, peut-être 90 - c'est la génération de code dynamique, le texte qui sera appelé sous PL / SQL, mais tourné vers la base de données. Là, même dans le temps, cette ligne est générée plus longtemps, puis la base de données est accédée (par exemple, la demande Join), la retourne, l'enveloppe en JSON et l'affiche à l'envers. De plus, Java transforme tout cela en un contrat, qui dépend de la structure.ET:- Révélé une solution de mise à jour par lots. Et comment se déroule la garantie de livraison - le colis est-il arrivé en totalité ou en partie? Ont-ils un certain cachend? Et comment s'assurer que ni le service ne tombe, ni les structures de données n'ont aucune sorte de cohérence, afin qu'il n'y ait pas d'erreurs?SC: - Nous avons un protocole - il existe deux modes de mise à jour. Dans l'un d'eux, vous pouvez définir le drapeau "Appliquer tout ce que vous pouvez." Il existe certains logiciels qu'Excel convertit en JSON - il peut y avoir 10 000 lignes. Et vous, à proprement parler, deux lignes peuvent être invalides (erreur). Et soit vous dites: «Appliquez tout ce que vous pouvez»; ou "Appliquer uniquement si toute l'histoire n'aura pas une seule erreur." Là, le statut intégral sera par exemple la restauration. En fait, une insertion est effectuée dans la base de données, mais la validation n'est pas appelée.En cas d'erreur - il appelle un rollback, c'est dans le protocole; vous obtenez le protocole de toute façon. Vous obtenez un statut sur chaque ligne et vous avez un identifiant dans un champ séparé - soit un nombre (identifiant d'objet), soit une autre clé, soit les deux. Le protocole permet de comprendre ce qui est arrivé à ma demande.AC: - L'utilisateur lui-même indique dans laquelle des options il doit se déplacer. Nous passons ce paramètre au côté du noyau, et le noyau produit déjà toute la magie, nous donne la réponse et nous l'interprétons.ET:"Pourquoi n'avez-vous pas utilisé de compilateur d'expressions intégré qui aiderait à définir la règle?" Supposons que nous ayons un modèle, je blogue dans une langue (langage de script tapé / non tapé); a écrit: "Je veux une liste." Passé ce fragment pour qu'un processeur de code mâche tout cela, le mette dans une base de données NoSQL, comme suggéré dans la première question ... Pourtant, il n'est pas clair pourquoi une base de données relationnelle et pourquoi et comment gérer la redondance des données? Un homme vous envoie un modèle avec un milliard de déchets ... Comment ces accords sont-ils conclus quand une personne en a besoin? CAROLINE DU SUD:"Je vais essayer de répondre si j'ai bien compris la question." La plupart du programme communique avec nous maintenant. Lorsque le mécanisme d'interaction d'intégration est mis en place, peu de gens communiquent avec nous en tant que programmes. Il y a, bien sûr, des cas où les gens envoient des exelniks pour le déversement principal: nous en faisons des JSON, les téléchargeons, mais il s'agit plus d'un paramètre principal.Et nous avons un mode lorsque vous avez envoyé 5 000 lignes, dont 4 900 sont retournées avec le statut "J'ai traité, je n'ai trouvé aucun changement, je n'ai rien fait". Mais cela se reflète dans le protocole et il n'y a pas d'erreur. Il s'agit d'une part de redondance.Nous avons toute cette histoire stockée dans une forme approximative à la troisième, normale, ce qui n'implique pas de redondance, contrairement à certaines structures dénormalisées qui sont utilisées, par exemple, pour les vitrines.Pourquoi relationnel? Les générateurs de code fonctionnent pour nous et la sensibilité à la qualité des métadonnées dans le système est très élevée. Et lorsque nous avons la possibilité de configurer une clé étrangère en utilisant des relations et de nous assurer ... Le dossier ne se couche tout simplement pas - il y aura une erreur si quelque chose ne va pas dans le système, en cas de défaillance. Et nous voulons, mais nous ne cherchons pas de travail supplémentaire ...Nous ne sommes pas mesurés à cause du nombre de lignes de code que nous avons écrit: "Avez-vous résolu la question du service et de sa stabilité ou non?" Vous n'écrivez peut-être pas du tout - l'essentiel est que cela fonctionne. En ce sens, c'était tout simplement plus rapide et plus pratique pour nous de le faire.Je ne prends pas de fournisseur spécifique, mais les bases de données relationnelles se développent depuis 20 ans! Ce n'est pas juste comme ça. Prenez, par exemple, Word ou Excel sous Windows - vous n'y programmez pas le code qui, à l'aide de "Assembleur", accède et déplace les têtes du disque dur pour écrire un fichier ... La même chose est ici! Nous venons d'utiliser les développements qui étaient dans le SGBDR, et c'était pratique.AC:- Pour garantir toutes nos exigences, l'intégrité des métadonnées était importante pour nous. Et ici, nous voulions probablement aussi dire que nous n'avons pas du tout à nous accrocher - nous utilisons du relationnel, pas du relationnel ... L'essence du rapport est que vous pouvez également commencer à l'utiliser. Pas nécessairement sur une base relationnelle, car à coup sûr, d'autres ont également une sorte de métadonnées qui peuvent être collectées: au moins, quelles tables, quels champs, et tout cela est programmé.R: - Le système implique une certaine utilisation. Comment prévoyez-vous (ou avez-vous déjà fait) la livraison des données à votre système? Il est clair qu'une sorte de mise à jour de la structure des données est en cours à l'épicerie. Comment tout cela vous vient-il? Automatiquement, ou votre agent est debout, ou pliez-vous toutes les équipes de développement pour recevoir des mises à jour?AC:- Nous avons deux modes de fonctionnement. L'une est lorsque les développeurs eux-mêmes ou les équipes elles-mêmes sont obligés de diffuser des métadonnées dans le système via les services REST. Le deuxième mode de fonctionnement est le même «aspirateur»: nous allons nous-mêmes dans l'environnement et en prenons toutes les métadonnées possibles. Nous le faisons une fois par jour et vérifions simplement ce que les développeurs nous ont envoyé.
CAROLINE DU SUD:"Je vais essayer de répondre si j'ai bien compris la question." La plupart du programme communique avec nous maintenant. Lorsque le mécanisme d'interaction d'intégration est mis en place, peu de gens communiquent avec nous en tant que programmes. Il y a, bien sûr, des cas où les gens envoient des exelniks pour le déversement principal: nous en faisons des JSON, les téléchargeons, mais il s'agit plus d'un paramètre principal.Et nous avons un mode lorsque vous avez envoyé 5 000 lignes, dont 4 900 sont retournées avec le statut "J'ai traité, je n'ai trouvé aucun changement, je n'ai rien fait". Mais cela se reflète dans le protocole et il n'y a pas d'erreur. Il s'agit d'une part de redondance.Nous avons toute cette histoire stockée dans une forme approximative à la troisième, normale, ce qui n'implique pas de redondance, contrairement à certaines structures dénormalisées qui sont utilisées, par exemple, pour les vitrines.Pourquoi relationnel? Les générateurs de code fonctionnent pour nous et la sensibilité à la qualité des métadonnées dans le système est très élevée. Et lorsque nous avons la possibilité de configurer une clé étrangère en utilisant des relations et de nous assurer ... Le dossier ne se couche tout simplement pas - il y aura une erreur si quelque chose ne va pas dans le système, en cas de défaillance. Et nous voulons, mais nous ne cherchons pas de travail supplémentaire ...Nous ne sommes pas mesurés à cause du nombre de lignes de code que nous avons écrit: "Avez-vous résolu la question du service et de sa stabilité ou non?" Vous n'écrivez peut-être pas du tout - l'essentiel est que cela fonctionne. En ce sens, c'était tout simplement plus rapide et plus pratique pour nous de le faire.Je ne prends pas de fournisseur spécifique, mais les bases de données relationnelles se développent depuis 20 ans! Ce n'est pas juste comme ça. Prenez, par exemple, Word ou Excel sous Windows - vous n'y programmez pas le code qui, à l'aide de "Assembleur", accède et déplace les têtes du disque dur pour écrire un fichier ... La même chose est ici! Nous venons d'utiliser les développements qui étaient dans le SGBDR, et c'était pratique.AC:- Pour garantir toutes nos exigences, l'intégrité des métadonnées était importante pour nous. Et ici, nous voulions probablement aussi dire que nous n'avons pas du tout à nous accrocher - nous utilisons du relationnel, pas du relationnel ... L'essence du rapport est que vous pouvez également commencer à l'utiliser. Pas nécessairement sur une base relationnelle, car à coup sûr, d'autres ont également une sorte de métadonnées qui peuvent être collectées: au moins, quelles tables, quels champs, et tout cela est programmé.R: - Le système implique une certaine utilisation. Comment prévoyez-vous (ou avez-vous déjà fait) la livraison des données à votre système? Il est clair qu'une sorte de mise à jour de la structure des données est en cours à l'épicerie. Comment tout cela vous vient-il? Automatiquement, ou votre agent est debout, ou pliez-vous toutes les équipes de développement pour recevoir des mises à jour?AC:- Nous avons deux modes de fonctionnement. L'une est lorsque les développeurs eux-mêmes ou les équipes elles-mêmes sont obligés de diffuser des métadonnées dans le système via les services REST. Le deuxième mode de fonctionnement est le même «aspirateur»: nous allons nous-mêmes dans l'environnement et en prenons toutes les métadonnées possibles. Nous le faisons une fois par jour et vérifions simplement ce que les développeurs nous ont envoyé. SC: - Sur les quatre niveaux que nous avons examinés, les trois premiers niveaux (glossaire, modèles logiques, modèles physiques) sont l'histoire qui nous vient par défaut en mode Metadata Broker, et nous sommes un participant passif. Ils nous appellent, nous passent quelque chose, demandent; notre tâche est de nous garer de manière cohérente. Bien qu'il y ait des cas où nous mettons en place quelques histoires avec les ressources de l'équipe, si nous sommes très intéressés à avoir ces métadonnées.Comme l'a dit Nastya, concernant l'histoire à l'envers (dans le jargon technique, nous l'appelons «aspirateur»), nous allons dans l'environnement industriel et lisons quelques données. Il existe différents cas - nous sommes prêts à discuter plus tard, nous sommes prêts à raconter de nombreuses histoires intéressantes.R: - Je viens du centre de la technologie financière. J'y ai vu un mot familier - DACUM principal. Notre plateforme a ses propres métadonnées. Comment êtes-vous amis - directement avec les tables Oracle ou avec nos métadonnées dans ce cas? Parce que dans notre cas, être ami avec les tables Oracle n'est pas entièrement indicatif.CAROLINE DU SUD:- Il existe une telle table DACUM principale, qui contient le câblage. Ce n'est pas un secret: il y avait et il y a des produits qui travaillent sur cette histoire. Ce sont l'une des sources d'informations dans le référentiel. Il existe une sorte de système qui est un fournisseur de données. Naturellement, c'est au centre de notre attention en termes de métadonnées, parce que l'une des histoires que nous devrions montrer et que nous n'avons pas du tout touchées ici (en raison du sujet du rapport) est la lignée des données. Vous devez montrer d'où provient l'historique des données de ce champ. En ce sens, s'il existe une table DACUM principale, nous le savons.
SC: - Sur les quatre niveaux que nous avons examinés, les trois premiers niveaux (glossaire, modèles logiques, modèles physiques) sont l'histoire qui nous vient par défaut en mode Metadata Broker, et nous sommes un participant passif. Ils nous appellent, nous passent quelque chose, demandent; notre tâche est de nous garer de manière cohérente. Bien qu'il y ait des cas où nous mettons en place quelques histoires avec les ressources de l'équipe, si nous sommes très intéressés à avoir ces métadonnées.Comme l'a dit Nastya, concernant l'histoire à l'envers (dans le jargon technique, nous l'appelons «aspirateur»), nous allons dans l'environnement industriel et lisons quelques données. Il existe différents cas - nous sommes prêts à discuter plus tard, nous sommes prêts à raconter de nombreuses histoires intéressantes.R: - Je viens du centre de la technologie financière. J'y ai vu un mot familier - DACUM principal. Notre plateforme a ses propres métadonnées. Comment êtes-vous amis - directement avec les tables Oracle ou avec nos métadonnées dans ce cas? Parce que dans notre cas, être ami avec les tables Oracle n'est pas entièrement indicatif.CAROLINE DU SUD:- Il existe une telle table DACUM principale, qui contient le câblage. Ce n'est pas un secret: il y avait et il y a des produits qui travaillent sur cette histoire. Ce sont l'une des sources d'informations dans le référentiel. Il existe une sorte de système qui est un fournisseur de données. Naturellement, c'est au centre de notre attention en termes de métadonnées, parce que l'une des histoires que nous devrions montrer et que nous n'avons pas du tout touchées ici (en raison du sujet du rapport) est la lignée des données. Vous devez montrer d'où provient l'historique des données de ce champ. En ce sens, s'il existe une table DACUM principale, nous le savons.Un peu de publicité :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en recommandant à vos amis, le cloud VPS pour les développeurs à partir de 4,99 $ , un analogue unique de serveurs d'entrée de gamme que nous avons inventé pour vous: Toute la vérité sur VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbit / s à partir de 19 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! En savoir plus sur la création d'un bâtiment d'infrastructure. classe c utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou? Source: https://habr.com/ru/post/undefined/
All Articles