 Lorsque les problèmes d'analyse dépassent les outils prédéfinis, il est probablement temps pour vous de choisir une base de données pour l'analyse. Vous ne devez pas écrire de scripts de requêtes dans la base de données de travail, car vous pouvez modifier l'ordre des données et, très probablement, ralentir l'application.Vous pouvez également supprimer accidentellement des informations importantes si des analystes ou des ingénieurs y travaillent.Pour l'analyse, vous avez besoin d'un type de base de données distinct. Mais lequel est vrai?Dans cet article, nous examinerons les offres et les meilleures pratiques pour une entreprise moyenne qui commence tout juste à travailler. Quel que soit le paramètre que vous choisissez, vous pouvez trouver un compromis à l'avenir pour améliorer les performances par rapport à ce dont nous discutons ici.En travaillant avec un grand nombre de clients, nous avons constaté que les critères les plus importants à considérer sont:
Lorsque les problèmes d'analyse dépassent les outils prédéfinis, il est probablement temps pour vous de choisir une base de données pour l'analyse. Vous ne devez pas écrire de scripts de requêtes dans la base de données de travail, car vous pouvez modifier l'ordre des données et, très probablement, ralentir l'application.Vous pouvez également supprimer accidentellement des informations importantes si des analystes ou des ingénieurs y travaillent.Pour l'analyse, vous avez besoin d'un type de base de données distinct. Mais lequel est vrai?Dans cet article, nous examinerons les offres et les meilleures pratiques pour une entreprise moyenne qui commence tout juste à travailler. Quel que soit le paramètre que vous choisissez, vous pouvez trouver un compromis à l'avenir pour améliorer les performances par rapport à ce dont nous discutons ici.En travaillant avec un grand nombre de clients, nous avons constaté que les critères les plus importants à considérer sont:- Type de données analysées
- De combien de données disposez-vous?
- Le centre d'intérêt de votre équipe d'ingénieurs
- À quelle vitesse avez-vous besoin d'informations
Quels types de données analysez-vous?
Pensez aux données que vous souhaitez analyser. S'adaptent-ils bien aux lignes et aux colonnes comme une énorme feuille de calcul Excel? Ou serait-il plus logique de les mettre dans un document Word?Si vous avez répondu à Excel, une base de données relationnelle comme Postgres, MySQL, Amazon Redshift ou BigQuery répondra à vos besoins. Ces bases de données relationnelles structurées sont excellentes lorsque vous savez exactement quelles données vous allez recevoir et comment elles sont liées les unes aux autres - essentiellement, comment les lignes et les colonnes sont liées. Pour la plupart des types d'analyse d'utilisateurs, les bases de données relationnelles fonctionnent bien. Les attributs utilisateur tels que les noms, les e-mails et les plans de facturation s'intègrent parfaitement dans le tableau, comme les événements utilisateur et leurs propriétés .D'un autre côté, si vos données s'adaptent mieux sur une feuille de papier, vous devez vous référer à une base de données non relationnelle (NoSQL) telle que Hadoop ou Mongo.Les bases de données non relationnelles se caractérisent par un nombre extrêmement élevé de valeurs privées (millions) de données semi-structurées. Des exemples classiques de données semi-structurées sont des textes tels que le courrier électronique, les livres et les réseaux sociaux, les données audiovisuelles et les données géographiques. Si vous effectuez beaucoup d'exploration de texte, de traitement de la langue ou de traitement d'image, vous devrez probablement utiliser des magasins de données non relationnels.
À combien de données traitez-vous?
La prochaine question à vous poser est la quantité de données avec laquelle vous traitez. Plus vous avez de données, plus une base de données non relationnelle sera utile, car elle n'imposera pas de restrictions sur les données entrantes, ce qui vous permettra d'écrire dans la base de données plus rapidement. Ce ne sont pas des restrictions strictes, et chacun peut traiter plus ou moins de données en fonction de divers facteurs, mais nous avons constaté que chacune des bases de données fonctionne parfaitement dans ces limites.Si vous avez moins de 1 To de données, alors avec Postgres, vous obtiendrez de bonnes performances. Mais il ralentit à environ 6 To. Si vous aimez MySQL mais avez besoin d'une échelle légèrement plus grande, Aurora (la propre version d'Amazon) peut atteindre 64 To. Pour une taille de pétaoctet, Amazon Redshift est généralement un bon choix car il est optimisé pour l'analyse jusqu'à 2PB. Pour le traitement parallèle ou même les données MOAR, il est probablement temps de jeter un œil à Hadoop.Cependant, AWS nous a dit qu'ils exécutent Amazon.com sur Redshift, donc si vous avez une équipe DBA de première classe, vous pourrez peut-être évoluer au-delà de la «limite» de 2PB.
Ce ne sont pas des restrictions strictes, et chacun peut traiter plus ou moins de données en fonction de divers facteurs, mais nous avons constaté que chacune des bases de données fonctionne parfaitement dans ces limites.Si vous avez moins de 1 To de données, alors avec Postgres, vous obtiendrez de bonnes performances. Mais il ralentit à environ 6 To. Si vous aimez MySQL mais avez besoin d'une échelle légèrement plus grande, Aurora (la propre version d'Amazon) peut atteindre 64 To. Pour une taille de pétaoctet, Amazon Redshift est généralement un bon choix car il est optimisé pour l'analyse jusqu'à 2PB. Pour le traitement parallèle ou même les données MOAR, il est probablement temps de jeter un œil à Hadoop.Cependant, AWS nous a dit qu'ils exécutent Amazon.com sur Redshift, donc si vous avez une équipe DBA de première classe, vous pourrez peut-être évoluer au-delà de la «limite» de 2PB.Sur quoi votre équipe d'ingénieurs se concentre-t-elle?
C'est une autre question importante à vous poser lorsque vous discutez de la base de données. Plus votre équipe globale est petite, plus il est probable que vos ingénieurs se concentreront principalement sur la création de produits plutôt que sur le traitement et la gestion des données. Le nombre de personnes que vous pouvez consacrer à ces projets affectera grandement vos options.Avec certaines ressources d'ingénierie, vous avez plus de choix - vous pouvez accéder à une base de données relationnelle ou non relationnelle. Les bases de données relationnelles prennent moins de temps que NoSQL.Si plusieurs ingénieurs travaillent sur l'installation, mais ne peuvent amener personne au service, choisissez quelque chose comme Postgres , Google SQL (hébergement MySQL en option) ou Segment Warehouses(Hébergement Redshift) est probablement une meilleure option que Redshift, Aurora ou BigQuery, car ils nécessitent une correction périodique du traitement des données. Si vous avez plus de temps pour réparer, le choix de Redshift ou BigQuery fournira des requêtes plus rapides et à plus grande échelle.Les bases de données relationnelles ont un autre avantage: vous pouvez utiliser SQL pour les interroger. SQL est bien connu des analystes et des ingénieurs et est plus facile à apprendre que la plupart des langages de programmation.D'un autre côté, l'analyse de données semi-structurées nécessite généralement, au minimum, une expérience en programmation orientée objet, ou, mieux, une expérience en écriture de code pour travailler avec des mégadonnées. Même avec l'avènement d'outils d'analyse comme Hunkpour Hadoop ou Slamdata pour MongoDB, vous aurez besoin d'un analyste expérimenté ou d'un expert en données pour analyser ces types de bases de données.À quelle vitesse avez-vous besoin de ces données?
Alors que les «analyses en temps réel» sont très populaires pour des cas tels que la détection de fraude et la surveillance du système, la plupart des analyses ne nécessitent pas de données en temps réel ou d'analyse immédiate.Lorsque vous répondez à des questions, par exemple, ce qui provoque le flux d'utilisateurs ou comment les gens passent de votre application à votre site Web, l'accès à vos données avec un léger retard (à intervalles horaires ou quotidiens) est tout à fait acceptable. Vos données ne changent pas minute par minute.Par conséquent, si vous travaillez principalement sur l'analyse réelle, vous devez vous référer à une base de données optimisée pour l'analyse, telle que Redshift ou BigQuery. Ces bases de données sont conçues pour accueillir une grande quantité de données et lire et combiner rapidement des données, ce qui accélère les requêtes. Ils peuvent également télécharger des données assez rapidement (toutes les heures) pendant que quelqu'un effectue le processus de nettoyage, redimensionne et surveille le cluster.Si vous avez absolument besoin de données en temps réel, vous devez vous tourner vers une base de données non structurée telle que Hadoop. Vous pouvez concevoir votre base de données Hadoop pour y charger des données très rapidement, bien que l'interroger puisse prendre plus de temps en fonction de l'utilisation de la RAM, de l'espace disque disponible et de la structure des données.Postgres contre. Amazon Redshift vs. Google bigquery
Vous avez probablement déjà réalisé qu'une base de données relationnelle serait le meilleur choix pour analyser la plupart des types de comportement des utilisateurs. Les informations sur la façon dont vos utilisateurs interagissent avec votre site et vos applications peuvent facilement s'intégrer dans un format structuré.analytics.track('Completed Order') — select * from ios.completed_order
 La question est donc de savoir quelle base de données SQL utiliser? Quatre critères doivent être considérés.
La question est donc de savoir quelle base de données SQL utiliser? Quatre critères doivent être considérés.Taille vs la vitesse
Lorsque vous avez besoin de vitesse, cela vaut la peine d'envisager Postgres: pour une base de données inférieure à 1 To, Postgres est assez rapide pour charger des données et des requêtes. De plus, il est disponible. À mesure que vous approchez de 6 To (hérité d'Amazon RDS), vos requêtes s'exécutent plus lentement.Par conséquent, lorsque vous avez besoin d'une taille plus grande, nous recommandons généralement Redshift. Notre expérience montre que Redshift a le meilleur rapport qualité-prix.Surbrillance SQL
Redshift est construit sur une variante de Postgres, et les deux supportent le bon vieux SQL. Redshift ne prend pas en charge tous les types de données et fonctions pris en charge par postgres, mais il est beaucoup plus proche de la norme de l'industrie que BigQuery, qui possède son propre SQL.Contrairement à de nombreux autres systèmes basés sur SQL, BigQuery utilise une syntaxe séparée par des virgules pour indiquer les jointures de table, et non selon la documentation SQL . Cela signifie que, sans prudence, les requêtes SQL peuvent entraîner des erreurs ou des résultats inattendus. Par conséquent, bon nombre des équipes que nous avons rencontrées ne peuvent pas convaincre leurs analystes d'apprendre BigQuery SQL.Écosystème tiers
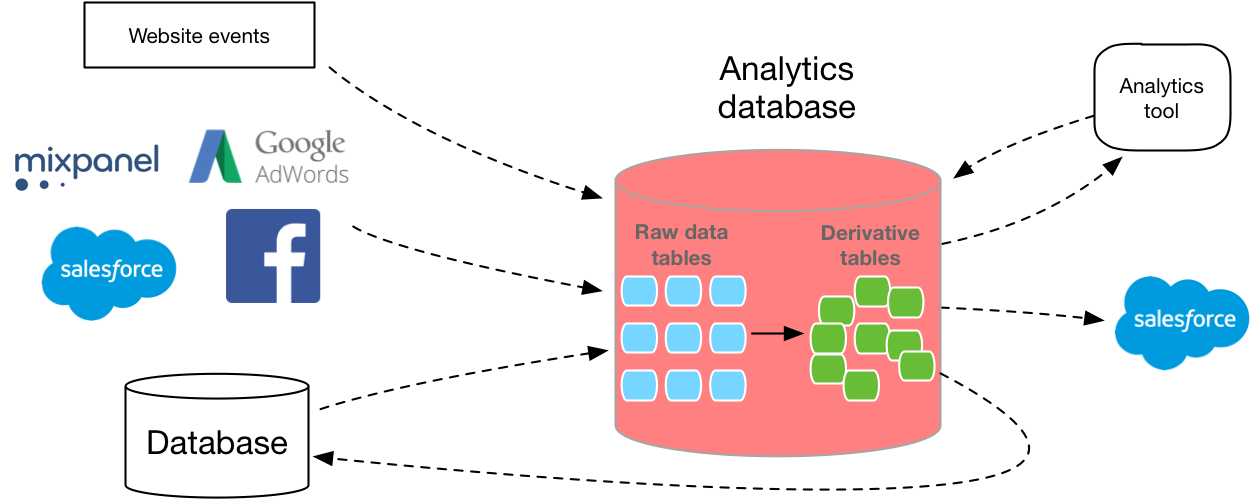
Votre entrepôt de données vit rarement seul. Vous devez mettre les données dans une base de données et, en outre, vous devez utiliser une sorte de logiciel pour l'analyser. (Sauf si vous exécutez la requête SQL à partir de la ligne de commande).Par conséquent, les gens aiment souvent que Redshift dispose d'un très vaste écosystème d'outils tiers. AWS possède des capacités telles que le Segment Data Warehouse pour charger des données dans Redshift à partir de l'API d'analyse, et elles fonctionnent également avec presque tous les outils de visualisation de données sur le marché. Moins de services tiers se connectent à Google, donc le déplacement des mêmes données vers BigQuery peut prendre plus de temps à développer, et vous n'aurez pas autant d'options pour les logiciels de BI.Vous pouvez voir les partenaires Amazonici et google ici .Cependant, si vous utilisez déjà Google Cloud Storage au lieu d'Amazon S3, il peut être avantageux pour vous de rester dans l'écosystème Google. Les deux services facilitent le téléchargement de données si elles existent déjà dans le référentiel de stockage cloud correspondant, de sorte que même si elles ne violent pas les conditions d'utilisation, ce sera beaucoup plus facile si vous cessez d'utiliser l'un de ces fournisseurs.Entraînement
Maintenant que vous avez une idée plus précise de la base de données à utiliser, l'étape suivante consiste à déterminer comment vous collecterez les données dans la base de données.De nombreux nouveaux développeurs de bases de données sous-estiment la difficulté de créer un pipeline de données évolutif. Vous devez écrire votre propre couche d'extraction, API de collecte de données, requête et couche de conversion. Et tout le monde doit évoluer. En outre, vous devez déterminer la mise en page correcte en fonction de la taille et du type de chaque colonne. MVP réplique votre base de données de production vers une nouvelle instance, mais cela signifie généralement utiliser une base de données qui n'est pas optimisée pour l'analyse.Heureusement, il existe plusieurs options sur le marché qui peuvent vous aider à contourner certains de ces obstacles et à effectuer automatiquement un ETL pour vous.Mais que ce soit votre propre développement ou achat, obtenir des données en SQL en vaut la peine.Sur la base des données utilisateur initiales, ce n'est qu'avec l'aide d'un format SQL flexible que vous pourrez répondre en détail aux questions sur ce que font vos clients, évaluer avec précision la distribution, comprendre le comportement multiplateforme, créer des tableaux de bord pour une entreprise particulière, et bien plus encore.