Optimisation massive des requêtes PostgreSQL. Kirill Borovikov (Tenseur)
Le rapport présente quelques approches qui vous permettent de surveiller les performances des requêtes SQL lorsqu'elles sont des millions par jour et des centaines de serveurs PostgreSQL contrôlés.Quelles solutions techniques nous permettent de traiter efficacement un tel volume d'informations et comment elles facilitent la vie d'un développeur ordinaire.Qui s'intéresse à l' analyse de problèmes spécifiques et à diverses techniques pour optimiser les requêtes SQL et résoudre les problèmes DBA typiques dans PostgreSQL ? Vous pouvez également lire une série d'articles sur ce sujet. Je m'appelle Kirill Borovikov, je représente la société "Tensor" . Plus précisément, je me spécialise dans le travail avec les bases de données de notre entreprise.Aujourd'hui, je vais vous expliquer comment nous procédons à l'optimisation des requêtes, lorsque vous n'avez pas besoin de «récupérer» les performances d'une seule demande, mais de résoudre le problème en masse. Lorsqu'il y a des millions de demandes et que vous devez trouver des approches pour résoudre ce gros problème.En général, «Tensor» pour notre million de clients est VLSI - notre application : un réseau social d'entreprise, des solutions de communication vidéo, pour la gestion interne et externe des documents, des systèmes comptables pour la comptabilité et le stockage ... C'est-à-dire une telle «méga-combinaison» pour une gestion d'entreprise intégrée, ce qui représente plus de 100 projets internes différents.Pour s'assurer qu'ils fonctionnent et se développent tous normalement, nous avons 10 centres de développement à travers le pays, ils ont plus de 1000 développeurs .Nous travaillons avec PostgreSQL depuis 2008 et avons accumulé une grande partie de ce que nous traitons - il s'agit de données clients, statistiques, analytiques, de données provenant de systèmes d'information externes - plus de 400 To . Seulement «en production», il y a environ 250 serveurs, et au total les serveurs de base de données que nous surveillons sont environ 1000.
Je m'appelle Kirill Borovikov, je représente la société "Tensor" . Plus précisément, je me spécialise dans le travail avec les bases de données de notre entreprise.Aujourd'hui, je vais vous expliquer comment nous procédons à l'optimisation des requêtes, lorsque vous n'avez pas besoin de «récupérer» les performances d'une seule demande, mais de résoudre le problème en masse. Lorsqu'il y a des millions de demandes et que vous devez trouver des approches pour résoudre ce gros problème.En général, «Tensor» pour notre million de clients est VLSI - notre application : un réseau social d'entreprise, des solutions de communication vidéo, pour la gestion interne et externe des documents, des systèmes comptables pour la comptabilité et le stockage ... C'est-à-dire une telle «méga-combinaison» pour une gestion d'entreprise intégrée, ce qui représente plus de 100 projets internes différents.Pour s'assurer qu'ils fonctionnent et se développent tous normalement, nous avons 10 centres de développement à travers le pays, ils ont plus de 1000 développeurs .Nous travaillons avec PostgreSQL depuis 2008 et avons accumulé une grande partie de ce que nous traitons - il s'agit de données clients, statistiques, analytiques, de données provenant de systèmes d'information externes - plus de 400 To . Seulement «en production», il y a environ 250 serveurs, et au total les serveurs de base de données que nous surveillons sont environ 1000. SQL est un langage déclaratif. Vous ne décrivez pas «comment» quelque chose devrait fonctionner, mais «ce que» vous voulez recevoir. Le SGBD sait mieux comment faire JOIN - comment connecter vos tablettes, quelles conditions imposer, ce qui se passera par index, quoi ne pas ...Certains SGBD acceptent des indices: «Non, connectez ces deux tablettes dans telle ou telle file d'attente», mais PostgreSQL ne le fait pas. Telle est la position consciente des principaux développeurs: "Mieux vaut terminer l'optimiseur de requête que laisser les développeurs utiliser une sorte d'indice."Mais, malgré le fait que PostgreSQL ne permet pas à "l'extérieur" de se contrôler, il vous permet parfaitement de voir ce qui se passe "à l'intérieur" lorsque vous exécutez votre requête et où elle a des problèmes.
SQL est un langage déclaratif. Vous ne décrivez pas «comment» quelque chose devrait fonctionner, mais «ce que» vous voulez recevoir. Le SGBD sait mieux comment faire JOIN - comment connecter vos tablettes, quelles conditions imposer, ce qui se passera par index, quoi ne pas ...Certains SGBD acceptent des indices: «Non, connectez ces deux tablettes dans telle ou telle file d'attente», mais PostgreSQL ne le fait pas. Telle est la position consciente des principaux développeurs: "Mieux vaut terminer l'optimiseur de requête que laisser les développeurs utiliser une sorte d'indice."Mais, malgré le fait que PostgreSQL ne permet pas à "l'extérieur" de se contrôler, il vous permet parfaitement de voir ce qui se passe "à l'intérieur" lorsque vous exécutez votre requête et où elle a des problèmes. En général, avec quels problèmes classiques le développeur [arrive-t-il à DBA] habituellement? "Ici, nous avons rempli la demande, et tout est lent , tout se bloque, quelque chose se passe ... Une sorte de problème!"Les raisons sont presque toujours les mêmes:
En général, avec quels problèmes classiques le développeur [arrive-t-il à DBA] habituellement? "Ici, nous avons rempli la demande, et tout est lent , tout se bloque, quelque chose se passe ... Une sorte de problème!"Les raisons sont presque toujours les mêmes:
: « SQL 10 JOIN...» — , «», . , (10 FROM) - . []
PostgreSQL, «» , — «» . 10 , 10 , PostgreSQL , . []- «»
, , , . … - , .
, (INSERT, UPDATE, DELETE) — .
... Et pour tout le reste, nous avons besoin d'un plan ! Nous devons voir ce qui se passe à l'intérieur du serveur. Le plan d'exécution des requêtes pour PostgreSQL est un arbre de l'algorithme d'exécution des requêtes dans une représentation textuelle. C'est l'algorithme qui, à la suite de l'analyse du planificateur, a été reconnu comme le plus efficace.Chaque nœud d'arborescence est une opération: extraire des données d'une table ou d'un index, créer une image bitmap, joindre deux tables, joindre, croiser ou éliminer des échantillons. La satisfaction de la demande est un passage à travers les nœuds de cet arbre.Pour obtenir un plan de requête, le moyen le plus simple consiste à exécuter l'instruction
Le plan d'exécution des requêtes pour PostgreSQL est un arbre de l'algorithme d'exécution des requêtes dans une représentation textuelle. C'est l'algorithme qui, à la suite de l'analyse du planificateur, a été reconnu comme le plus efficace.Chaque nœud d'arborescence est une opération: extraire des données d'une table ou d'un index, créer une image bitmap, joindre deux tables, joindre, croiser ou éliminer des échantillons. La satisfaction de la demande est un passage à travers les nœuds de cet arbre.Pour obtenir un plan de requête, le moyen le plus simple consiste à exécuter l'instruction EXPLAIN. Pour obtenir tous les attributs réels, c'est-à-dire exécuter réellement une requête basée sur - EXPLAIN (ANALYZE, BUFFERS) SELECT ....Le mauvais point: lorsque vous l'exécutez, cela se produit «ici et maintenant», il ne convient donc qu'au débogage local. Si vous prenez un serveur très chargé, qui subit un flux important de modifications de données, et que vous voyez: «Ay! Ici, nous sommes plus lents à Xia une demande. " Il y a une demi-heure, il y a une heure - pendant que vous exécutiez et récupériez cette demande des journaux, en la transportant à nouveau sur le serveur, votre ensemble de données et vos statistiques ont changé. Vous l'exécutez pour déboguer - et il s'exécute rapidement! Et vous ne pouvez pas comprendre pourquoi, pourquoi c'était lent. Afin de comprendre ce qui se passait exactement au moment où la requête est exécutée sur le serveur, des gens intelligents ont écrit le module auto_explain. Il est présent dans presque toutes les distributions PostgreSQL les plus courantes, et vous pouvez simplement l'activer dans le fichier de configuration.S'il comprend qu'une demande est en cours d'exécution plus longtemps que la frontière que vous lui avez indiquée, il prend un «instantané» du plan de cette demande et les écrit ensemble dans un journal .
Afin de comprendre ce qui se passait exactement au moment où la requête est exécutée sur le serveur, des gens intelligents ont écrit le module auto_explain. Il est présent dans presque toutes les distributions PostgreSQL les plus courantes, et vous pouvez simplement l'activer dans le fichier de configuration.S'il comprend qu'une demande est en cours d'exécution plus longtemps que la frontière que vous lui avez indiquée, il prend un «instantané» du plan de cette demande et les écrit ensemble dans un journal . Tout semble aller bien maintenant, nous allons dans le journal et voyons là ... [pas de texte]. Mais nous ne pouvons rien dire sur lui, à part le fait que c'est un excellent plan, car il a fallu 11 ms pour terminer.Tout semble aller bien - mais rien n'est clair sur ce qui s'est réellement passé. En plus du temps total, on ne voit pas grand-chose. Parce que regarder un tel texte en clair "latuha" est généralement apprécié.Mais même s'il est aimé, certes inconfortable, mais il y a des problèmes plus importants:
Tout semble aller bien maintenant, nous allons dans le journal et voyons là ... [pas de texte]. Mais nous ne pouvons rien dire sur lui, à part le fait que c'est un excellent plan, car il a fallu 11 ms pour terminer.Tout semble aller bien - mais rien n'est clair sur ce qui s'est réellement passé. En plus du temps total, on ne voit pas grand-chose. Parce que regarder un tel texte en clair "latuha" est généralement apprécié.Mais même s'il est aimé, certes inconfortable, mais il y a des problèmes plus importants:- . , Index Scan — , - . , «» , CTE — « ».
- : , , — . , , , , loops — . . , , , — - « ».
Dans ces circonstances, comprenez "Qui est le maillon le plus faible?" presque irréaliste. Par conséquent, même les développeurs eux-mêmes dans le "manuel" écrivent que "Comprendre le plan est un art qui doit être appris, expérimenté ..." .Mais nous avons 1000 développeurs, et chacun d'eux ne passera pas cette expérience dans leur tête. Moi, vous, il - ils le savent, et quelqu'un là-bas - n'est plus là. Peut-être qu'il apprendra, ou peut-être pas, mais il doit travailler maintenant - et où obtiendrait-il cette expérience.Visualisation du plan
Par conséquent, nous avons réalisé que pour faire face à ces problèmes, nous avons besoin d'une bonne visualisation du plan . [article]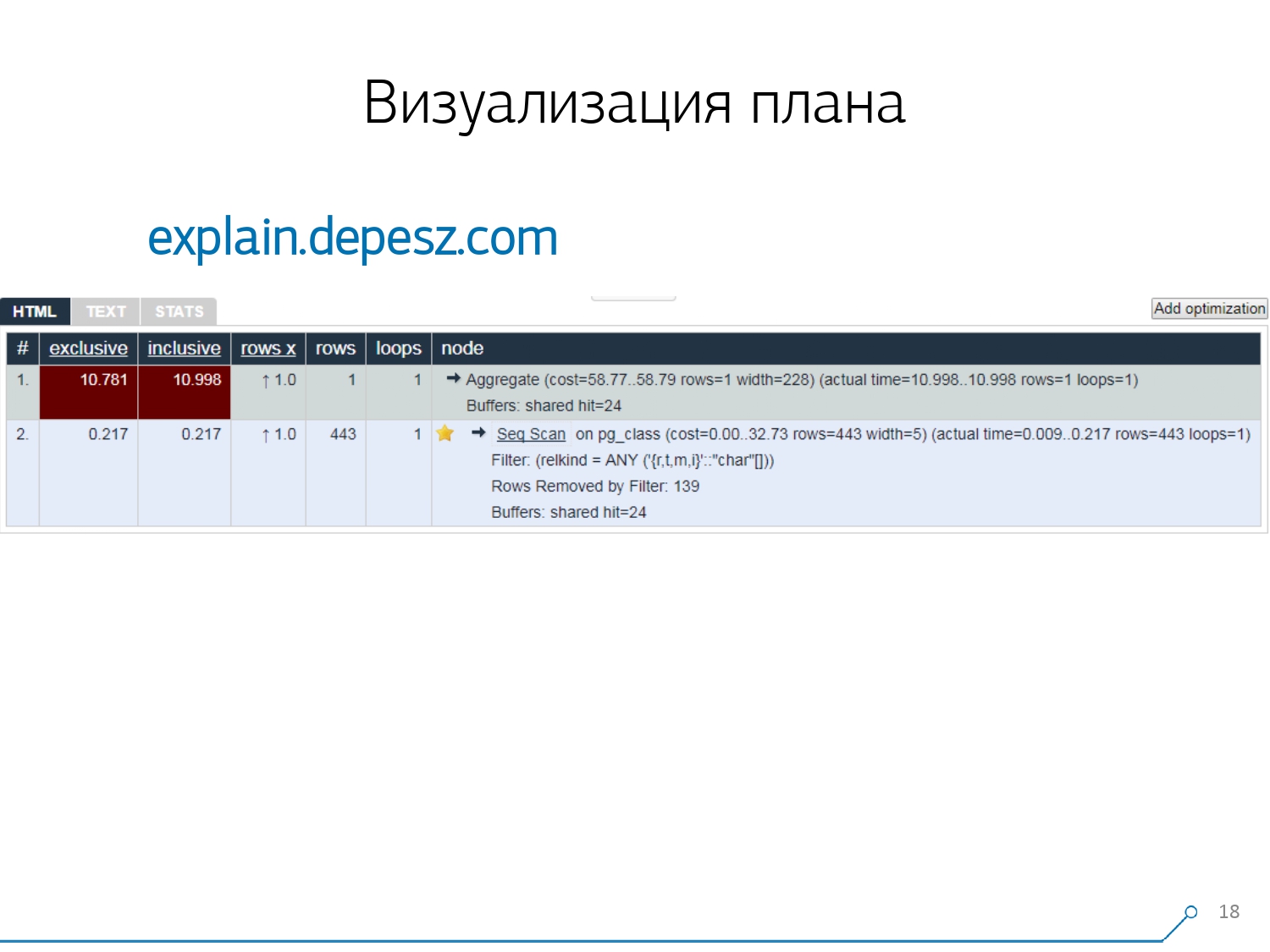 Nous avons d'abord fait le tour du marché - regardons sur Internet ce qui existe en général.Mais, il s'est avéré que des solutions relativement «live» qui sont plus ou moins développées, il y en a très peu - littéralement, une chose: expliquez.depesz.com d'Hubert Lubaczewski. A l'entrée du champ "nourrir" une représentation textuelle du plan, il vous montre une plaque avec les données analysées:
Nous avons d'abord fait le tour du marché - regardons sur Internet ce qui existe en général.Mais, il s'est avéré que des solutions relativement «live» qui sont plus ou moins développées, il y en a très peu - littéralement, une chose: expliquez.depesz.com d'Hubert Lubaczewski. A l'entrée du champ "nourrir" une représentation textuelle du plan, il vous montre une plaque avec les données analysées:- temps de travail du nœud approprié
- temps total sur tout le sous-arbre
- le nombre d'enregistrements qui ont été récupérés et qui était statistiquement attendu
- le corps du nœud lui-même
Ce service a également la possibilité de partager l'archive de liens. Vous avez lancé votre plan là-bas et dit: "Hé, Vasya, voici un lien pour toi, quelque chose ne va pas là-bas." Mais il y a quelques problèmes mineurs.Tout d'abord, une énorme quantité de copier-coller. Vous prenez un morceau du journal, vous le mettez là, et encore et encore.Deuxièmement, il n'y a pas d'analyse de la quantité de données lues - les tampons mêmes qu'elle affiche
Mais il y a quelques problèmes mineurs.Tout d'abord, une énorme quantité de copier-coller. Vous prenez un morceau du journal, vous le mettez là, et encore et encore.Deuxièmement, il n'y a pas d'analyse de la quantité de données lues - les tampons mêmes qu'elle affiche EXPLAIN (ANALYZE, BUFFERS), ici nous ne les voyons pas. Il ne sait tout simplement pas comment les démonter, les comprendre et travailler avec eux. Lorsque vous lisez beaucoup de données et comprenez que vous pouvez "décomposer" de manière incorrecte sur un disque et un cache en mémoire, ces informations sont très importantes.Le troisième point négatif est le très faible développement de ce projet. Les commits sont très petits, c'est bon tous les six mois, et le code en Perl.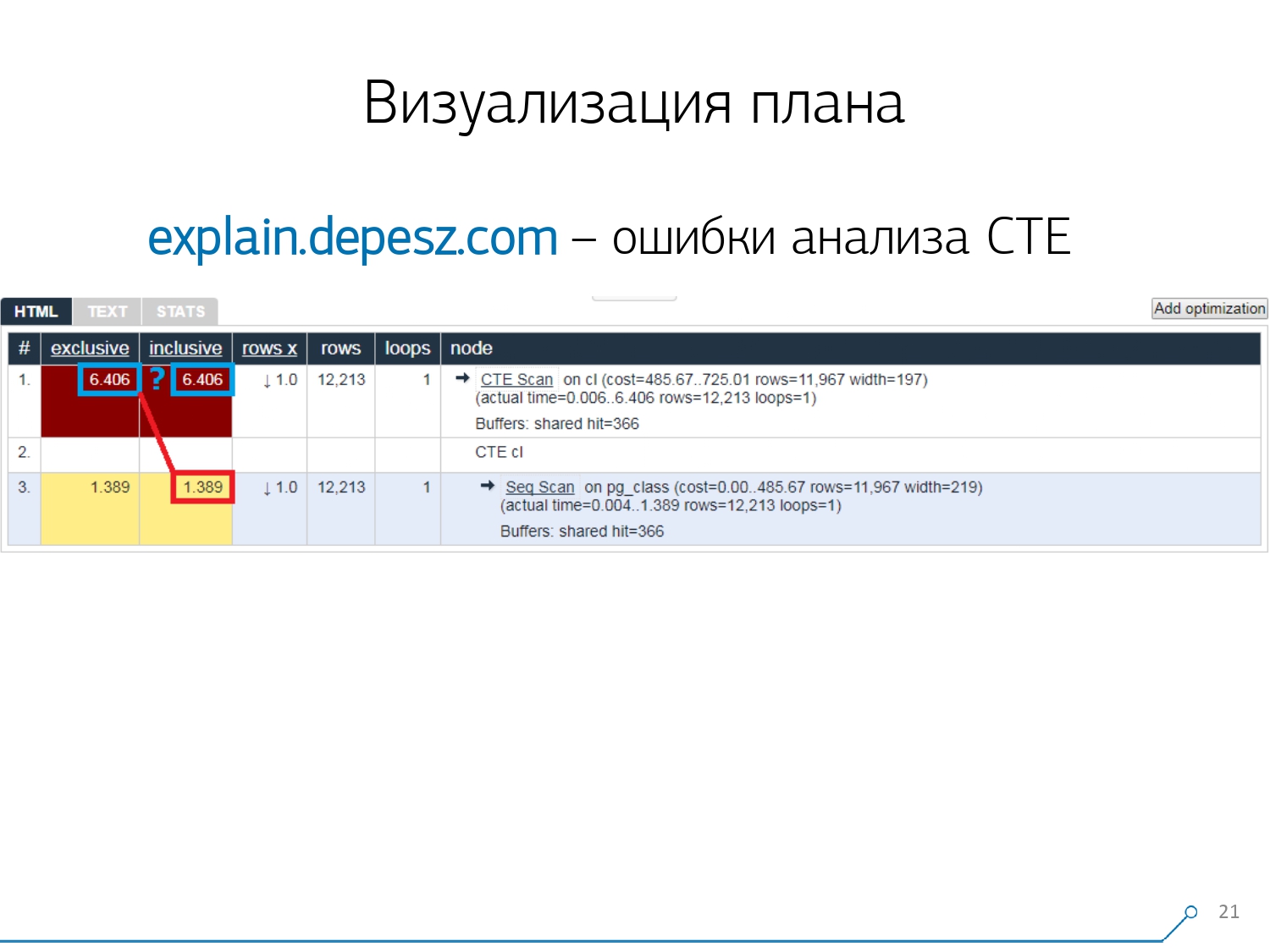 Mais ce ne sont que des «paroles», on pourrait en quelque sorte vivre avec, mais il y a une chose qui nous a détournés de ce service. Ce sont des erreurs d'analyse Common Table Expression (CTE) et divers nœuds dynamiques comme InitPlan / SubPlan.Si vous croyez cette image, nous avons alors le temps d'exécution total de chaque nœud individuel est supérieur au temps d'exécution total de la demande entière. C'est simple - le temps de génération de ce CTE n'a pas été soustrait du nœud CTE Scan . Par conséquent, nous ne connaissons plus la bonne réponse, combien a pris l'analyse CTE elle-même.
Mais ce ne sont que des «paroles», on pourrait en quelque sorte vivre avec, mais il y a une chose qui nous a détournés de ce service. Ce sont des erreurs d'analyse Common Table Expression (CTE) et divers nœuds dynamiques comme InitPlan / SubPlan.Si vous croyez cette image, nous avons alors le temps d'exécution total de chaque nœud individuel est supérieur au temps d'exécution total de la demande entière. C'est simple - le temps de génération de ce CTE n'a pas été soustrait du nœud CTE Scan . Par conséquent, nous ne connaissons plus la bonne réponse, combien a pris l'analyse CTE elle-même. Ensuite, nous avons réalisé qu'il était temps d'écrire le nôtre - hourra! Chaque développeur dit: "Maintenant, nous allons écrire le nôtre, ce sera juste super!"Ils ont pris une pile de services Web typique: le noyau sur Node.js + Express, tiré Bootstrap et pour de beaux diagrammes - D3.js. Et nos attentes étaient justifiées - nous avons reçu le premier prototype en 2 semaines:
Ensuite, nous avons réalisé qu'il était temps d'écrire le nôtre - hourra! Chaque développeur dit: "Maintenant, nous allons écrire le nôtre, ce sera juste super!"Ils ont pris une pile de services Web typique: le noyau sur Node.js + Express, tiré Bootstrap et pour de beaux diagrammes - D3.js. Et nos attentes étaient justifiées - nous avons reçu le premier prototype en 2 semaines:- propre analyseur de plan
C'est-à-dire que maintenant nous pouvons généralement analyser n'importe quel plan à partir de ceux générés par PostgreSQL. - analyse correcte des nœuds dynamiques - CTE Scan, InitPlan, SubPlan
- analyse de la distribution des tampons - où les pages de données de la mémoire sont lues, d'où du cache local, d'où du disque
- a reçu une visibilité
Pour qu'il ne soit pas «dans le journal» qu'il «creuse», mais que vous voyez le «maillon le plus faible» immédiatement sur l'image.
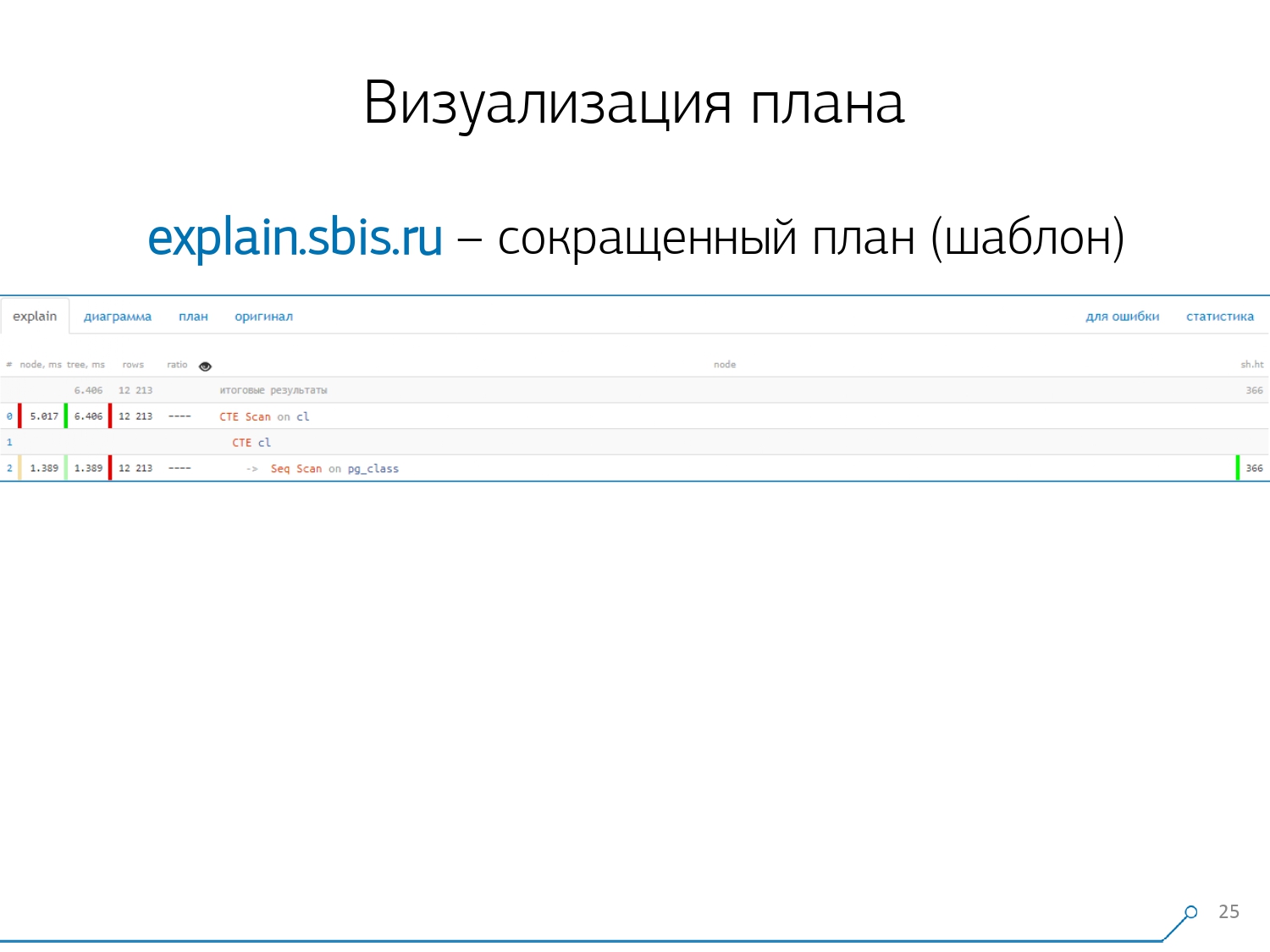 Nous avons obtenu quelque chose comme ça - immédiatement avec la coloration syntaxique. Mais généralement, nos développeurs ne travaillent plus avec une présentation complète du plan, mais avec une présentation plus courte. Après tout, nous avons déjà analysé tous les chiffres et les avons jetés à gauche et à droite, et au milieu, nous n'avons laissé que la première ligne: de quel type de nœud il s'agit: CTE Scan, génération CTE ou Seq Scan par un certain type d'étiquette.Cette vue abrégée est ce que nous appelons le modèle de plan .
Nous avons obtenu quelque chose comme ça - immédiatement avec la coloration syntaxique. Mais généralement, nos développeurs ne travaillent plus avec une présentation complète du plan, mais avec une présentation plus courte. Après tout, nous avons déjà analysé tous les chiffres et les avons jetés à gauche et à droite, et au milieu, nous n'avons laissé que la première ligne: de quel type de nœud il s'agit: CTE Scan, génération CTE ou Seq Scan par un certain type d'étiquette.Cette vue abrégée est ce que nous appelons le modèle de plan .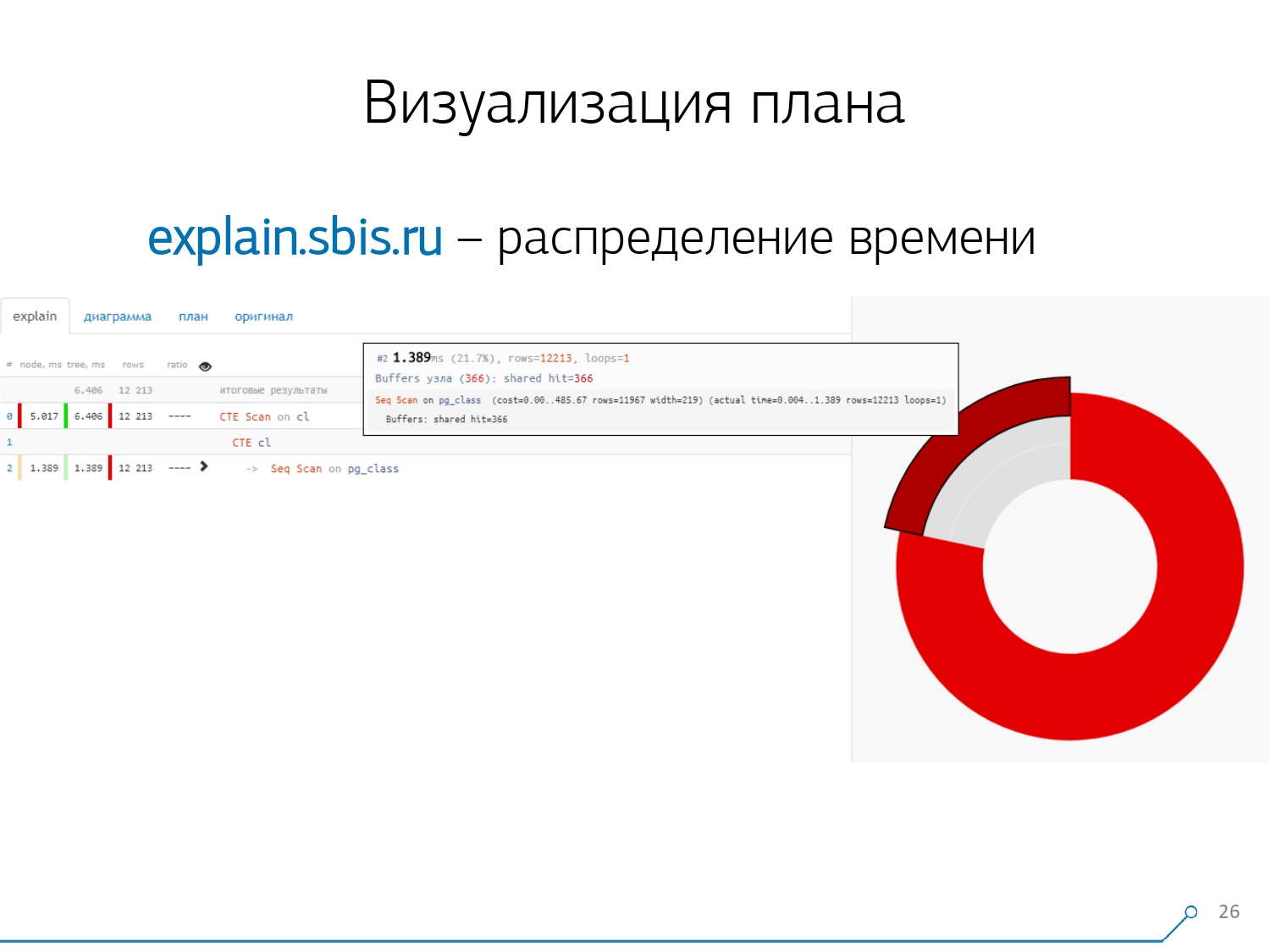 Quoi d'autre serait pratique? Il serait commode de voir quelle proportion de quel nœud du temps total nous est alloué - et de simplement «coller» le graphique circulaire sur le côté .Nous pointons le nœud et voyons - avec nous, il s'avère que Seq Scan a pris moins d'un quart du temps, et les 3/4 restants ont pris CTE Scan. Horreur! Ceci est une petite remarque sur la «cadence de tir» de CTE Scan, si vous les utilisez activement dans vos requêtes. Ils ne sont pas très rapides - ils perdent même avec le scan de table habituel. [article] [article]Mais généralement, de tels diagrammes sont plus intéressants, plus compliqués lorsque nous pointons immédiatement vers un segment, et nous voyons, par exemple, que plus de la moitié du temps certains Seq Scan «mangeaient». De plus, il y avait une sorte de filtre à l'intérieur, un tas d'enregistrements ont été déposés dessus ... Vous pouvez directement lancer cette image au développeur et dire: «Vasya, tout va mal avec toi ici! Comprenez, regardez - quelque chose ne va pas! "
Quoi d'autre serait pratique? Il serait commode de voir quelle proportion de quel nœud du temps total nous est alloué - et de simplement «coller» le graphique circulaire sur le côté .Nous pointons le nœud et voyons - avec nous, il s'avère que Seq Scan a pris moins d'un quart du temps, et les 3/4 restants ont pris CTE Scan. Horreur! Ceci est une petite remarque sur la «cadence de tir» de CTE Scan, si vous les utilisez activement dans vos requêtes. Ils ne sont pas très rapides - ils perdent même avec le scan de table habituel. [article] [article]Mais généralement, de tels diagrammes sont plus intéressants, plus compliqués lorsque nous pointons immédiatement vers un segment, et nous voyons, par exemple, que plus de la moitié du temps certains Seq Scan «mangeaient». De plus, il y avait une sorte de filtre à l'intérieur, un tas d'enregistrements ont été déposés dessus ... Vous pouvez directement lancer cette image au développeur et dire: «Vasya, tout va mal avec toi ici! Comprenez, regardez - quelque chose ne va pas! " Naturellement, il y avait un «râteau».La première chose sur laquelle ils «ont marché» est le problème de l'arrondissement. Le temps de nœud de chaque individu dans le plan est indiqué avec une précision de 1 μs. Et lorsque le nombre de cycles de nœuds dépasse, par exemple, 1000 - après l'exécution, PostgreSQL l'a divisé «jusqu'à», puis dans le calcul inverse, nous obtenons le temps total «quelque part entre 0,95 ms et 1,05 ms». Lorsque le compte est dépensé en microsecondes - rien pour le moment, mais déjà pendant [milli] secondes - il est nécessaire de prendre en compte ces informations lors du «déliement» des ressources sur les nœuds du plan «qui a combien consommé qui».
Naturellement, il y avait un «râteau».La première chose sur laquelle ils «ont marché» est le problème de l'arrondissement. Le temps de nœud de chaque individu dans le plan est indiqué avec une précision de 1 μs. Et lorsque le nombre de cycles de nœuds dépasse, par exemple, 1000 - après l'exécution, PostgreSQL l'a divisé «jusqu'à», puis dans le calcul inverse, nous obtenons le temps total «quelque part entre 0,95 ms et 1,05 ms». Lorsque le compte est dépensé en microsecondes - rien pour le moment, mais déjà pendant [milli] secondes - il est nécessaire de prendre en compte ces informations lors du «déliement» des ressources sur les nœuds du plan «qui a combien consommé qui». Le deuxième point, plus complexe, est la répartition des ressources (ces mêmes tampons) entre les nœuds dynamiques. Cela nous a coûté les 2 premières semaines sur le prototype plus le plus de la semaine 4.Pour obtenir ce problème est assez simple - nous faisons un CTE et nous y lisons quelque chose. En fait, PostgreSQL est intelligent et ne lira rien ici. Ensuite, nous en prenons le premier enregistrement, et les cent premiers du même CTE.
Le deuxième point, plus complexe, est la répartition des ressources (ces mêmes tampons) entre les nœuds dynamiques. Cela nous a coûté les 2 premières semaines sur le prototype plus le plus de la semaine 4.Pour obtenir ce problème est assez simple - nous faisons un CTE et nous y lisons quelque chose. En fait, PostgreSQL est intelligent et ne lira rien ici. Ensuite, nous en prenons le premier enregistrement, et les cent premiers du même CTE.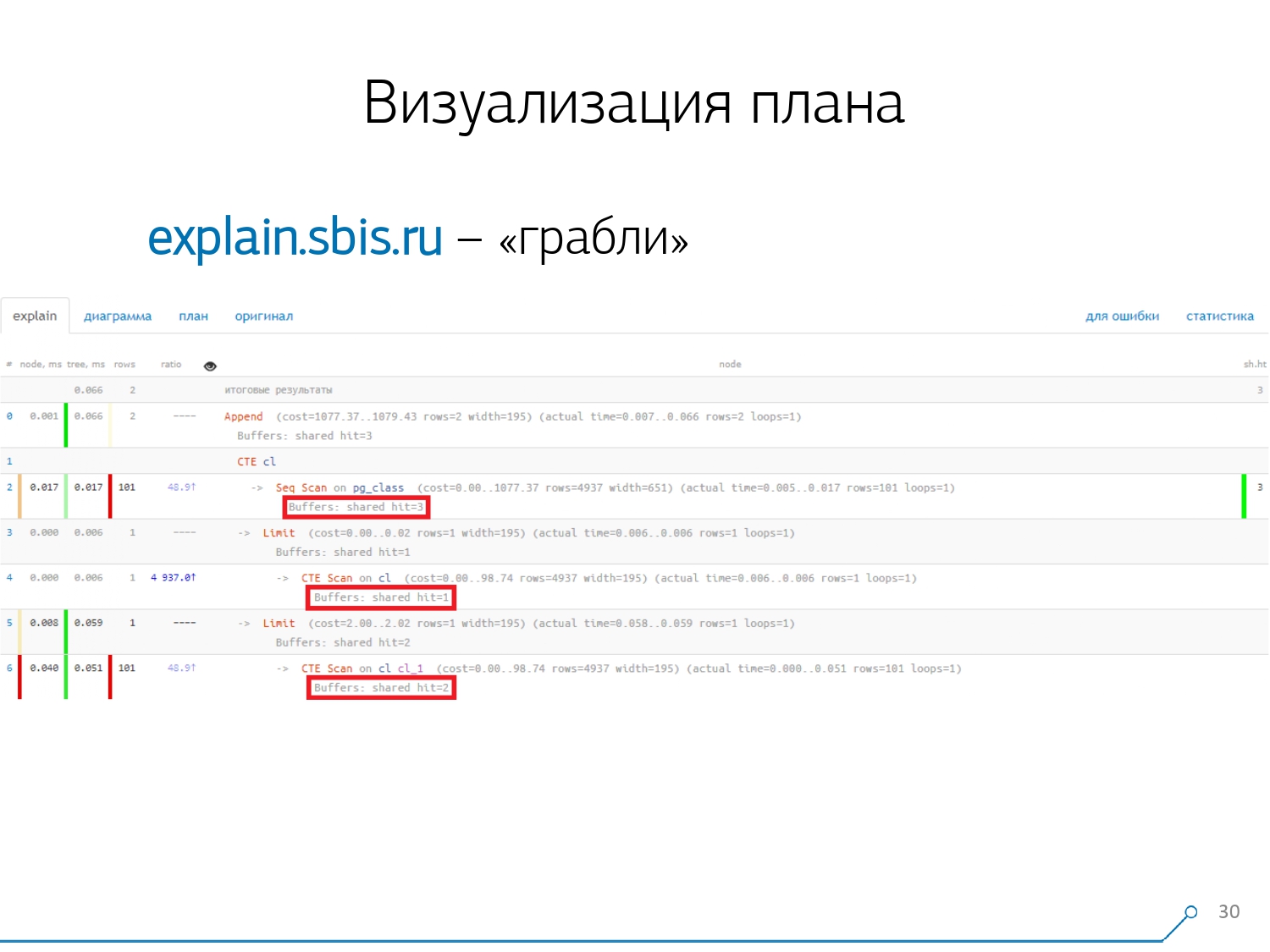 Nous regardons le plan et comprenons - étrange, nous avons 3 tampons (pages de données) qui ont été "consommés" dans Seq Scan, 1 autre dans CTE Scan et 2 autres dans le deuxième CTE Scan. Autrement dit, si tout est simplement résumé, nous obtenons 6, mais de la plaque, nous n'en lisons que 3! CTE Scan ne lit rien de n'importe où, mais fonctionne directement avec la mémoire de processus. Autrement dit, il y a clairement quelque chose de mal ici!En fait, il s'avère qu'ici toutes ces 3 pages de données qui ont été demandées à Seq Scan, 1 d'abord demandé le 1er CTE Scan, puis le 2e, et ils en lisent encore 2. Autrement dit, 3 pages ont été lues au total données, pas 6.
Nous regardons le plan et comprenons - étrange, nous avons 3 tampons (pages de données) qui ont été "consommés" dans Seq Scan, 1 autre dans CTE Scan et 2 autres dans le deuxième CTE Scan. Autrement dit, si tout est simplement résumé, nous obtenons 6, mais de la plaque, nous n'en lisons que 3! CTE Scan ne lit rien de n'importe où, mais fonctionne directement avec la mémoire de processus. Autrement dit, il y a clairement quelque chose de mal ici!En fait, il s'avère qu'ici toutes ces 3 pages de données qui ont été demandées à Seq Scan, 1 d'abord demandé le 1er CTE Scan, puis le 2e, et ils en lisent encore 2. Autrement dit, 3 pages ont été lues au total données, pas 6.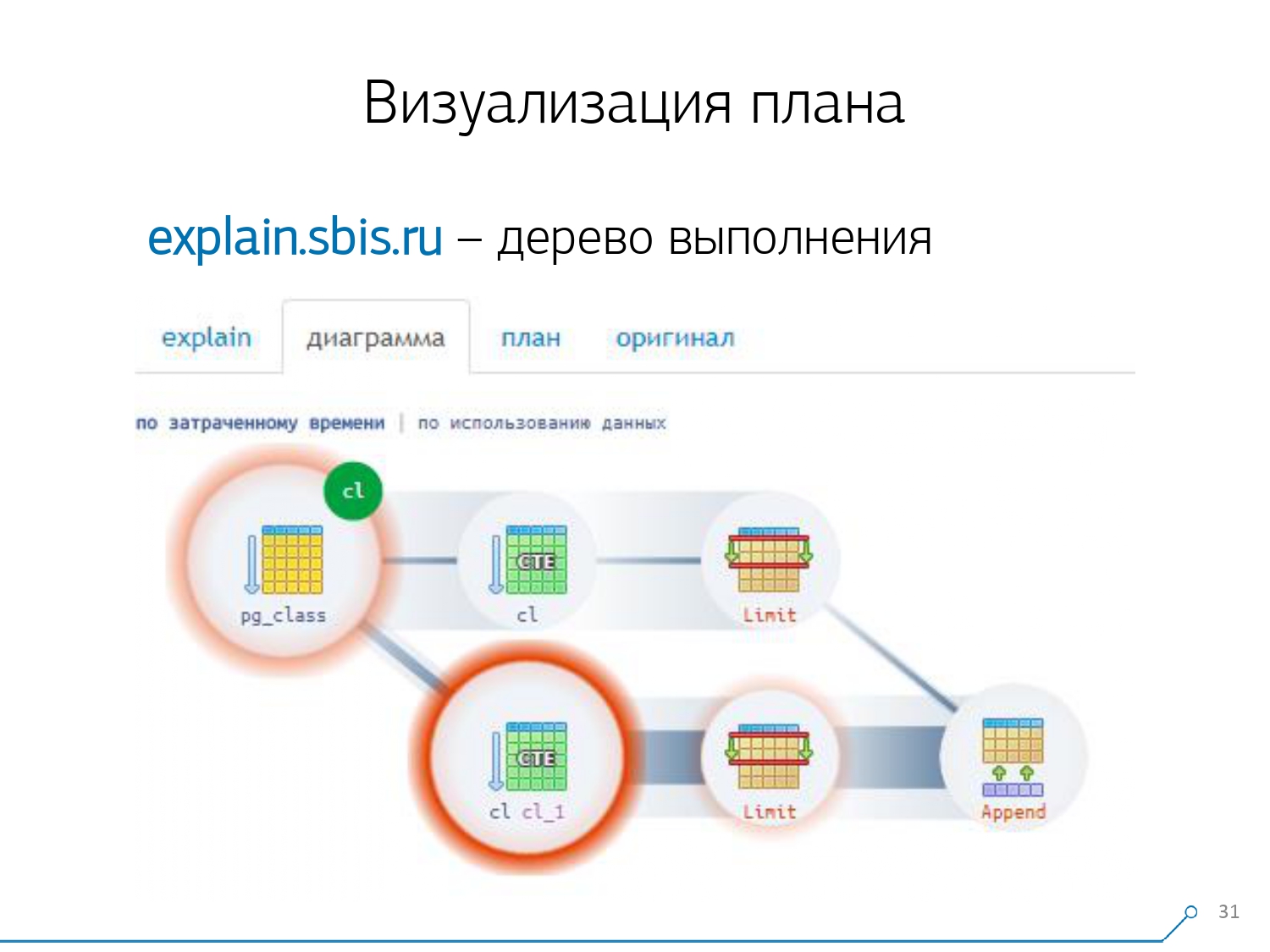 Et cette image nous a fait comprendre que la mise en œuvre du plan n'est plus un arbre, mais juste une sorte de graphique acyclique. Et nous avons obtenu un tableau comme celui-ci pour que nous comprenions "d'où-il vient du tout". Autrement dit, ici, nous avons créé un CTE à partir de pg_class, et l'avons demandé deux fois, et presque tout le temps qu'il nous a fallu jusqu'à la branche lorsque nous l'avons demandé la deuxième fois. Il est clair que la lecture du 101e record est beaucoup plus chère que le 1er de la tablette.
Et cette image nous a fait comprendre que la mise en œuvre du plan n'est plus un arbre, mais juste une sorte de graphique acyclique. Et nous avons obtenu un tableau comme celui-ci pour que nous comprenions "d'où-il vient du tout". Autrement dit, ici, nous avons créé un CTE à partir de pg_class, et l'avons demandé deux fois, et presque tout le temps qu'il nous a fallu jusqu'à la branche lorsque nous l'avons demandé la deuxième fois. Il est clair que la lecture du 101e record est beaucoup plus chère que le 1er de la tablette. Nous avons expiré pendant un moment. Ils ont dit: «Maintenant, Neo, tu connais le kung-fu! Maintenant, notre expérience est directement sur votre écran. Maintenant, vous pouvez l'utiliser. " [article]
Nous avons expiré pendant un moment. Ils ont dit: «Maintenant, Neo, tu connais le kung-fu! Maintenant, notre expérience est directement sur votre écran. Maintenant, vous pouvez l'utiliser. " [article]Consolidation des journaux
Nos 1000 développeurs ont poussé un soupir de soulagement. Mais nous avons compris que nous n'avons que des centaines de serveurs «de combat», et tout ce «copier-coller» par les développeurs n'est pas du tout pratique. Nous avons réalisé que nous devions le récupérer nous-mêmes. En général, il existe un module régulier qui peut collecter des statistiques, mais il doit également être activé dans la configuration - c'est le module pg_stat_statements . Mais il ne nous convenait pas.Tout d'abord, il attribue différents QueryId aux mêmes requêtes sur différents schémas au sein de la même base de données . Autrement dit, si vous faites d'abord
En général, il existe un module régulier qui peut collecter des statistiques, mais il doit également être activé dans la configuration - c'est le module pg_stat_statements . Mais il ne nous convenait pas.Tout d'abord, il attribue différents QueryId aux mêmes requêtes sur différents schémas au sein de la même base de données . Autrement dit, si vous faites d'abord SET search_path = '01'; SELECT * FROM user LIMIT 1;, puis SET search_path = '02';la même demande, les statistiques de ce module auront des entrées différentes, et je ne serai pas en mesure de collecter des statistiques générales précisément dans le contexte de ce profil de demande, sans prendre en compte les schémas.Le deuxième point qui nous a empêché de l'utiliser est le manque de plans . Autrement dit, il n'y a pas de plan, il n'y a que la demande elle-même. Nous voyons ce qui ralentissait, mais nous ne comprenons pas pourquoi. Et nous revenons ici au problème d'un ensemble de données en évolution rapide.Et le dernier point est le manque de «faits» . Autrement dit, il est impossible de traiter une instance spécifique d'exécution de requête - elle n'est pas là, il n'y a que des statistiques agrégées. Bien qu'il soit possible de travailler avec, c'est juste très difficile.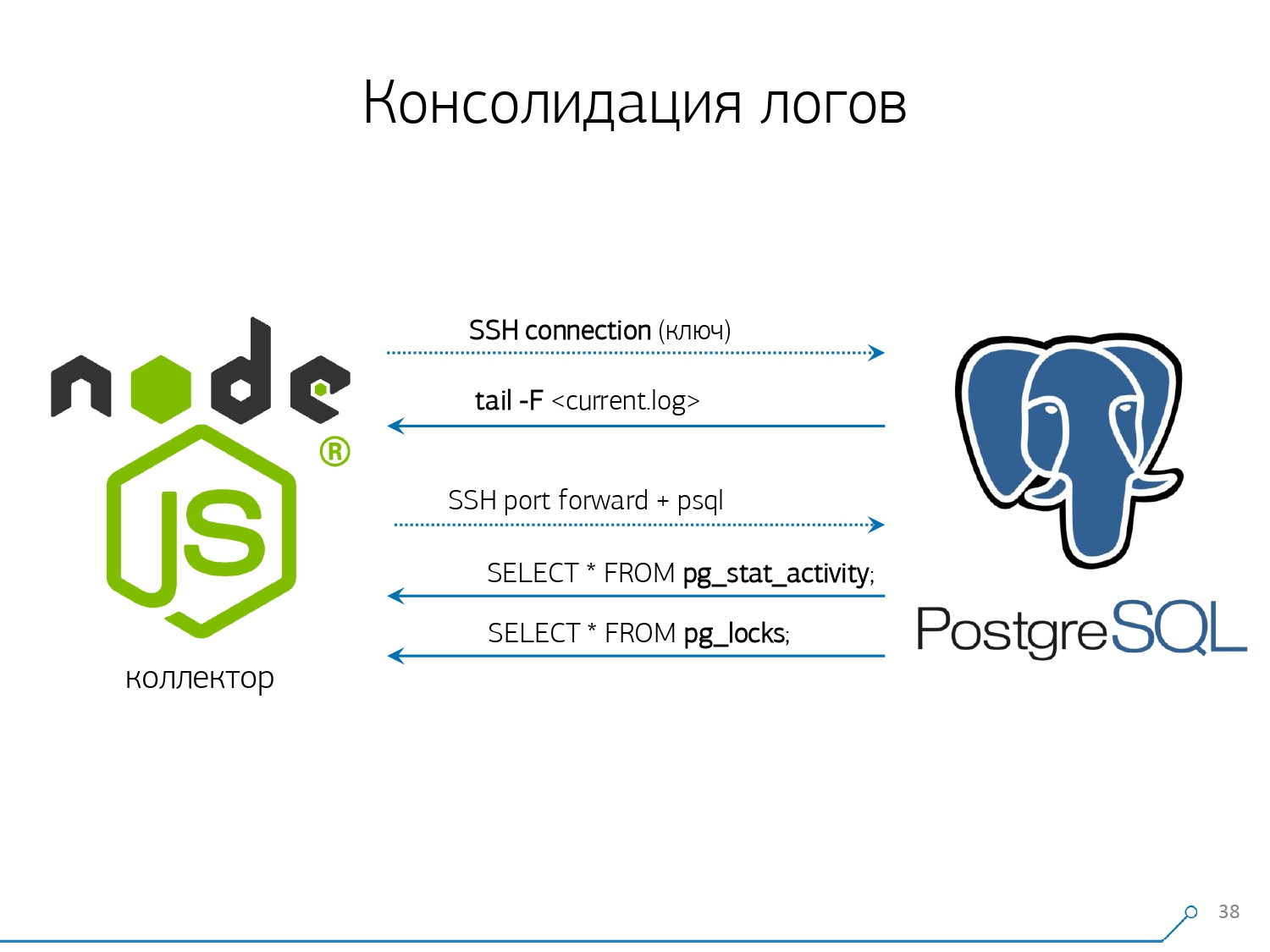 Par conséquent, nous avons décidé de lutter contre le «copier-coller» et avons commencé à écrire un collectionneur .Le collecteur est connecté via SSH, «tire» une connexion sécurisée au serveur avec la base de données à l'aide du certificat et
Par conséquent, nous avons décidé de lutter contre le «copier-coller» et avons commencé à écrire un collectionneur .Le collecteur est connecté via SSH, «tire» une connexion sécurisée au serveur avec la base de données à l'aide du certificat et tail -F«s'y accroche» au fichier journal. Donc, dans cette sessionnous obtenons un «miroir» complet de tout le fichier journal généré par le serveur. La charge sur le serveur lui-même est minime, car nous n'y analysons rien, nous reflétons simplement le trafic.Comme nous avons déjà commencé à écrire l'interface sur Node.js, nous avons continué à écrire le collecteur dessus. Et cette technologie a porté ses fruits, car il est très pratique d'utiliser JavaScript pour travailler avec des données texte mal formatées, qui est le journal. Et l'infrastructure Node.js elle-même en tant que plate-forme backend vous permet de travailler facilement et de manière pratique avec des connexions réseau, et en fait avec une sorte de flux de données.En conséquence, nous «tirons» deux connexions: la première consiste à «écouter» le journal lui-même et à le prendre pour nous-mêmes, et la seconde consiste à demander périodiquement la base de données. "Mais dans le journal, il est arrivé que la plaque contenant l’oid 123 était bloquée", mais cela ne dit rien au développeur, et ce serait bien de demander à la base de données "Qu'est-ce que OID = 123 après tout?" Et donc nous demandons périodiquement à la base quelque chose que nous ne savons pas encore chez nous. "Vous n'avez tout simplement pas pris en compte, il y a une sorte d'abeilles ressemblant à des éléphants! ..." Nous avons commencé à développer ce système lorsque nous voulions surveiller 10 serveurs. Le plus critique dans notre compréhension, sur lequel il y avait des problèmes qui étaient difficiles à traiter. Mais au cours du premier trimestre, nous en avons eu une centaine à surveiller - parce que le système «est entré», tout le monde le voulait, tout le monde était à l'aise.Tout cela doit être ajouté, le flux de données est volumineux, actif. En fait, nous surveillons ce que nous sommes capables de gérer - puis nous l'utilisons. Nous utilisons également PostgreSQL comme entrepôt de données. Mais rien n'est plus rapide pour «y verser» des données qu'il
"Vous n'avez tout simplement pas pris en compte, il y a une sorte d'abeilles ressemblant à des éléphants! ..." Nous avons commencé à développer ce système lorsque nous voulions surveiller 10 serveurs. Le plus critique dans notre compréhension, sur lequel il y avait des problèmes qui étaient difficiles à traiter. Mais au cours du premier trimestre, nous en avons eu une centaine à surveiller - parce que le système «est entré», tout le monde le voulait, tout le monde était à l'aise.Tout cela doit être ajouté, le flux de données est volumineux, actif. En fait, nous surveillons ce que nous sommes capables de gérer - puis nous l'utilisons. Nous utilisons également PostgreSQL comme entrepôt de données. Mais rien n'est plus rapide pour «y verser» des données qu'il COPYn'y a encore aucun opérateur .Mais «verser» les données n'est pas vraiment notre technologie. Parce que si vous avez environ 50 000 requêtes par seconde sur une centaine de serveurs, cela générera pour vous 100 à 150 Go de journaux par jour. Par conséquent, nous avons dû soigneusement «voir» la base.Premièrement, nous avons fait le partitionnement tous les jours , car, dans l'ensemble, personne n'est intéressé par la corrélation entre les jours. Quelle est la différence que vous aviez hier, si ce soir vous déployez une nouvelle version de l'application - et déjà quelques nouvelles statistiques.Deuxièmement, nous avons appris (ont été contraints) à écrire très, très rapidement en utilisantCOPY . Ce n'est pas seulement COPYparce qu'il est plus rapide que INSERT, mais encore plus rapide. Le troisième point - j'ai dû abandonner les déclencheurs, respectivement, et des clés étrangères . Autrement dit, nous n'avons pas d'intégrité absolument référentielle. Parce que si vous avez une table sur laquelle il y a une paire de FK, et que vous dites dans la structure de la base de données que "voici une entrée de journal fait référence à FK, par exemple, un groupe d'enregistrements", alors lorsque vous l'insérez, PostgreSQL n'a rien d'autre à faire que comment prendre et exécuter honnêtement
Le troisième point - j'ai dû abandonner les déclencheurs, respectivement, et des clés étrangères . Autrement dit, nous n'avons pas d'intégrité absolument référentielle. Parce que si vous avez une table sur laquelle il y a une paire de FK, et que vous dites dans la structure de la base de données que "voici une entrée de journal fait référence à FK, par exemple, un groupe d'enregistrements", alors lorsque vous l'insérez, PostgreSQL n'a rien d'autre à faire que comment prendre et exécuter honnêtement SELECT 1 FROM master_fk1_table WHERE ...avec l'identifiant que vous essayez d'insérer - juste pour vérifier que cette entrée est là, que vous ne "cassez" pas cette clé étrangère avec votre insert.Nous obtenons au lieu d'un enregistrement dans la table cible et ses indices, un autre avantage de la lecture de toutes les tables auxquelles il se réfère. Et nous n'en avons pas du tout besoin - notre tâche est d'écrire autant que possible et le plus rapidement possible avec le moins de charge possible. Alors FK - vers le bas!Le point suivant est l'agrégation et le hachage. Initialement, ils ont été implémentés dans notre base de données - après tout, il est pratique de faire immédiatement, quand un enregistrement arrive, «plus un» dans une sorte de plaque directement dans le déclencheur . C'est bien, c'est pratique, mais la même chose est mauvaise - insérez un enregistrement, mais vous êtes obligé de lire et d'écrire autre chose à partir d'une autre table. De plus, non seulement cela, lisez et écrivez - et faites-le à chaque fois.Imaginez maintenant que vous disposez d'une plaque dans laquelle vous comptez simplement le nombre de demandes transmises à un hôte particulier:+1, +1, +1, ..., +1. Et vous, en principe, n'en avez pas besoin - tout cela peut être résumé dans la mémoire du collecteur et envoyé à la base de données à la fois +10.Oui, votre intégrité logique peut «s'effondrer» en cas de problèmes, mais c'est presque un cas irréaliste - parce que vous avez un serveur normal, il a une batterie dans le contrôleur, vous avez un journal des transactions, un journal sur le système de fichiers ... En général, non ça vaut le coup. Cela ne vaut pas la perte de productivité que vous obtenez en raison du travail des déclencheurs / FK, les coûts que vous encourez en même temps.Même chose avec le hachage. Une certaine demande vous parvient, vous calculez un certain identifiant à partir de la base de données, vous écrivez dans la base de données, puis vous le dites à tout le monde. Tout va bien, jusqu'à ce qu'au moment de l'enregistrement une deuxième personne vienne à vous qui veut l'enregistrer - et vous avez un verrou, et c'est déjà mauvais. Par conséquent, si vous pouvez supprimer la génération de certains ID sur le client (par rapport à la base de données), il est préférable de le faire.Nous étions juste idéalement adaptés pour utiliser MD5 à partir du texte - une demande, un plan, un modèle, ... Nous le calculons du côté du collecteur et «versons» l'ID prêt à l'emploi dans la base de données. La longueur du MD5 et le partitionnement quotidien nous permettent de ne pas nous inquiéter d'éventuelles collisions.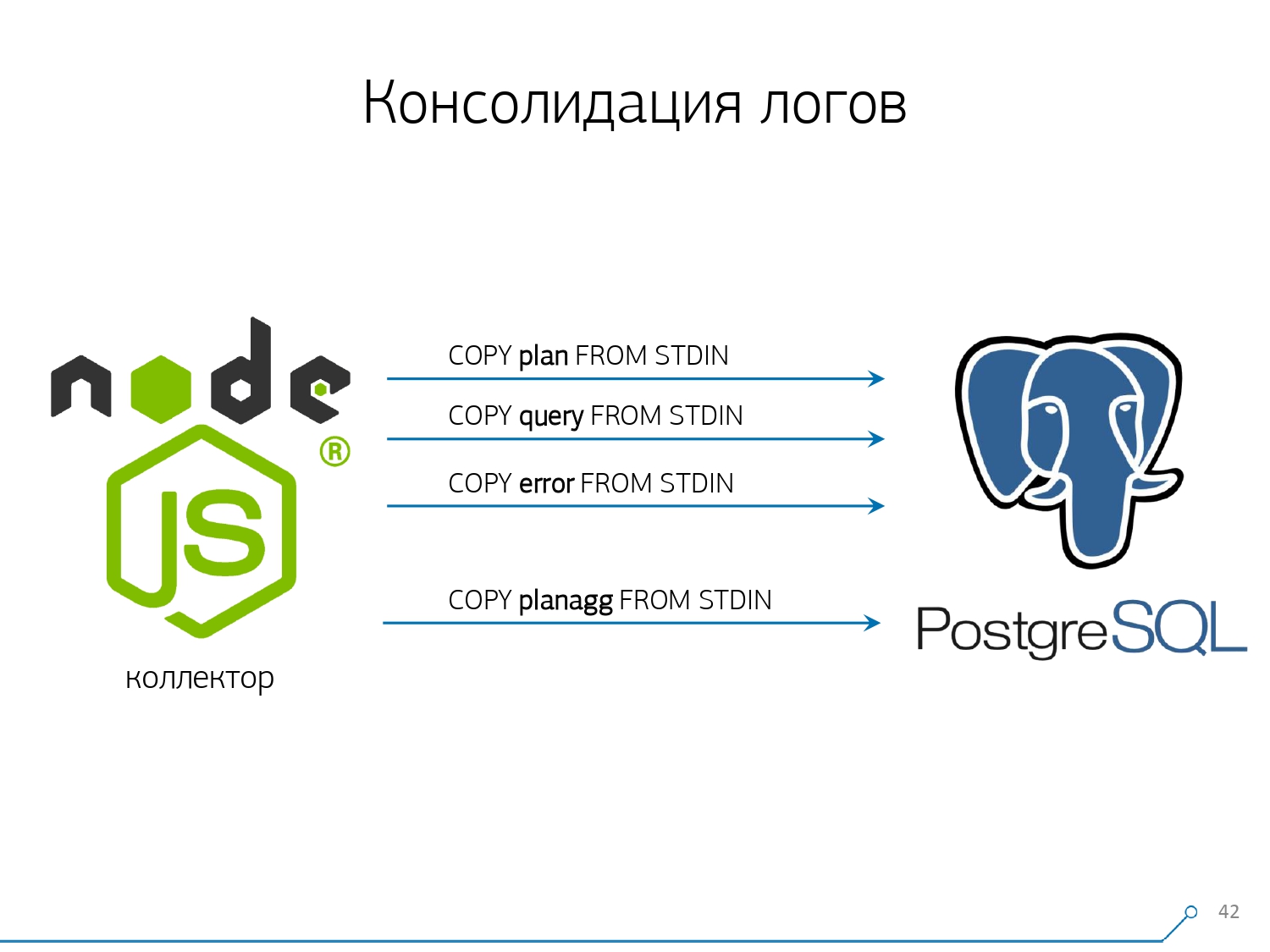 Mais pour enregistrer tout cela rapidement, nous devions modifier la procédure d'enregistrement elle-même.Comment écrivez-vous habituellement les données? Nous avons une sorte de jeu de données, nous le décomposons en plusieurs tableaux, puis COPY - d'abord dans le premier, puis dans le second, dans le troisième ... C'est gênant, car nous écrivons un flux de données en trois étapes de manière séquentielle. Désagréable. Est-il possible de faire plus vite? Pouvez!Pour ce faire, il suffit de décomposer ces flux en parallèle les uns avec les autres. Il s'avère que nous avons des erreurs, des requêtes, des modèles, des verrous, des vols dans des flux séparés ... - et nous écrivons tout cela en parallèle. Pour ce faire, il suffit de laisser le canal COPY ouvert en permanence sur chaque table cible individuelle .
Mais pour enregistrer tout cela rapidement, nous devions modifier la procédure d'enregistrement elle-même.Comment écrivez-vous habituellement les données? Nous avons une sorte de jeu de données, nous le décomposons en plusieurs tableaux, puis COPY - d'abord dans le premier, puis dans le second, dans le troisième ... C'est gênant, car nous écrivons un flux de données en trois étapes de manière séquentielle. Désagréable. Est-il possible de faire plus vite? Pouvez!Pour ce faire, il suffit de décomposer ces flux en parallèle les uns avec les autres. Il s'avère que nous avons des erreurs, des requêtes, des modèles, des verrous, des vols dans des flux séparés ... - et nous écrivons tout cela en parallèle. Pour ce faire, il suffit de laisser le canal COPY ouvert en permanence sur chaque table cible individuelle . Autrement dit, le collecteur a toujours un fluxdans lequel je peux écrire les données dont j'ai besoin. Mais pour que la base de données voit ces données, et que quelqu'un ne se bloque pas dans les verrous, en attendant que ces données soient écrites, la COPIE doit être interrompue à une certaine fréquence . Pour nous, une période de l'ordre de 100 ms s'est avérée être la plus efficace - fermez-la et ouvrez-la immédiatement à nouveau sur la même table. Et si nous n’avons pas un flux à certains pics, nous mettons en commun à une certaine limite.De plus, nous avons découvert que pour un tel profil de charge, toute agrégation lorsque les enregistrements sont collectés en paquets est mauvaise. Le mal classique
Autrement dit, le collecteur a toujours un fluxdans lequel je peux écrire les données dont j'ai besoin. Mais pour que la base de données voit ces données, et que quelqu'un ne se bloque pas dans les verrous, en attendant que ces données soient écrites, la COPIE doit être interrompue à une certaine fréquence . Pour nous, une période de l'ordre de 100 ms s'est avérée être la plus efficace - fermez-la et ouvrez-la immédiatement à nouveau sur la même table. Et si nous n’avons pas un flux à certains pics, nous mettons en commun à une certaine limite.De plus, nous avons découvert que pour un tel profil de charge, toute agrégation lorsque les enregistrements sont collectés en paquets est mauvaise. Le mal classique INSERT ... VALUESdépasse les 1000 records. Parce qu'à ce moment, vous avez un pic d'enregistrement sur le support, et tous ceux qui essaient d'écrire quelque chose sur le disque attendront.Pour se débarrasser de telles anomalies, il suffit de ne rien agréger, de ne pas du tout tamponner . Et si la mise en mémoire tampon sur le disque se produit (heureusement, l'API Stream dans Node.js vous permet de le savoir) - reporter cette connexion. C'est alors que l'événement vient à vous qu'il est à nouveau gratuit - écrivez-le à partir de la file d'attente accumulée. En attendant, c'est occupé - prenez le prochain gratuit de la piscine et écrivez-y.Avant de mettre en œuvre cette approche de l'enregistrement des données, nous avions environ 4K opérations d'écriture, et de cette façon, nous avons réduit la charge de 4 fois. Maintenant, ils ont augmenté encore 6 fois en raison de nouvelles bases observables - jusqu'à 100 Mo / s. Et maintenant, nous stockons des journaux pour les 3 derniers mois pour un montant d'environ 10 à 15 To, en espérant qu'en seulement trois mois, tout développeur puisse résoudre n'importe quel problème.Nous comprenons les problèmes
Mais la collecte de toutes ces données est bonne, utile, appropriée, mais pas suffisante - vous devez la comprendre. Parce que c'est des millions de plans différents par jour. Mais des millions sont incontrôlables, vous devez d'abord faire «moins». Et, tout d'abord, il est nécessaire de décider comment vous allez organiser ce "plus petit".Nous avons identifié pour nous-mêmes trois points clés:
Mais des millions sont incontrôlables, vous devez d'abord faire «moins». Et, tout d'abord, il est nécessaire de décider comment vous allez organiser ce "plus petit".Nous avons identifié pour nous-mêmes trois points clés:- qui a envoyé cette demande,
c'est-à-dire à partir de quelle application il a "volé": interface web, backend, système de paiement ou autre. - où est-ce arrivé
sur quel serveur particulier. Parce que si vous avez plusieurs serveurs sous une seule application, et soudain un "émoussé" (parce que "le disque a pourri", "la fuite de mémoire", un autre problème), alors vous devez vous adresser spécifiquement au serveur. - comment le problème s'est manifesté d'une manière ou d'une autre
Pour comprendre «qui» nous a envoyé la demande, nous utilisons un outil régulier - définir une variable de session: SET application_name = '{bl-host}:{bl-method}';- envoyer le nom d'hôte de la logique métier à partir de laquelle la demande est faite, et le nom de la méthode ou de l'application qui l'a initiée.Après avoir passé le «propriétaire» de la demande, elle doit être affichée dans le journal - pour cela, nous configurons la variable log_line_prefix = ' %m [%p:%v] [%d] %r %a'. Toute personne intéressée peut voir dans le manuel ce que tout cela signifie. Il s'avère que nous voyons dans le journal:- temps
- identificateurs de processus et de transaction
- nom de base
- IP de la personne qui a envoyé cette demande
- et nom de la méthode
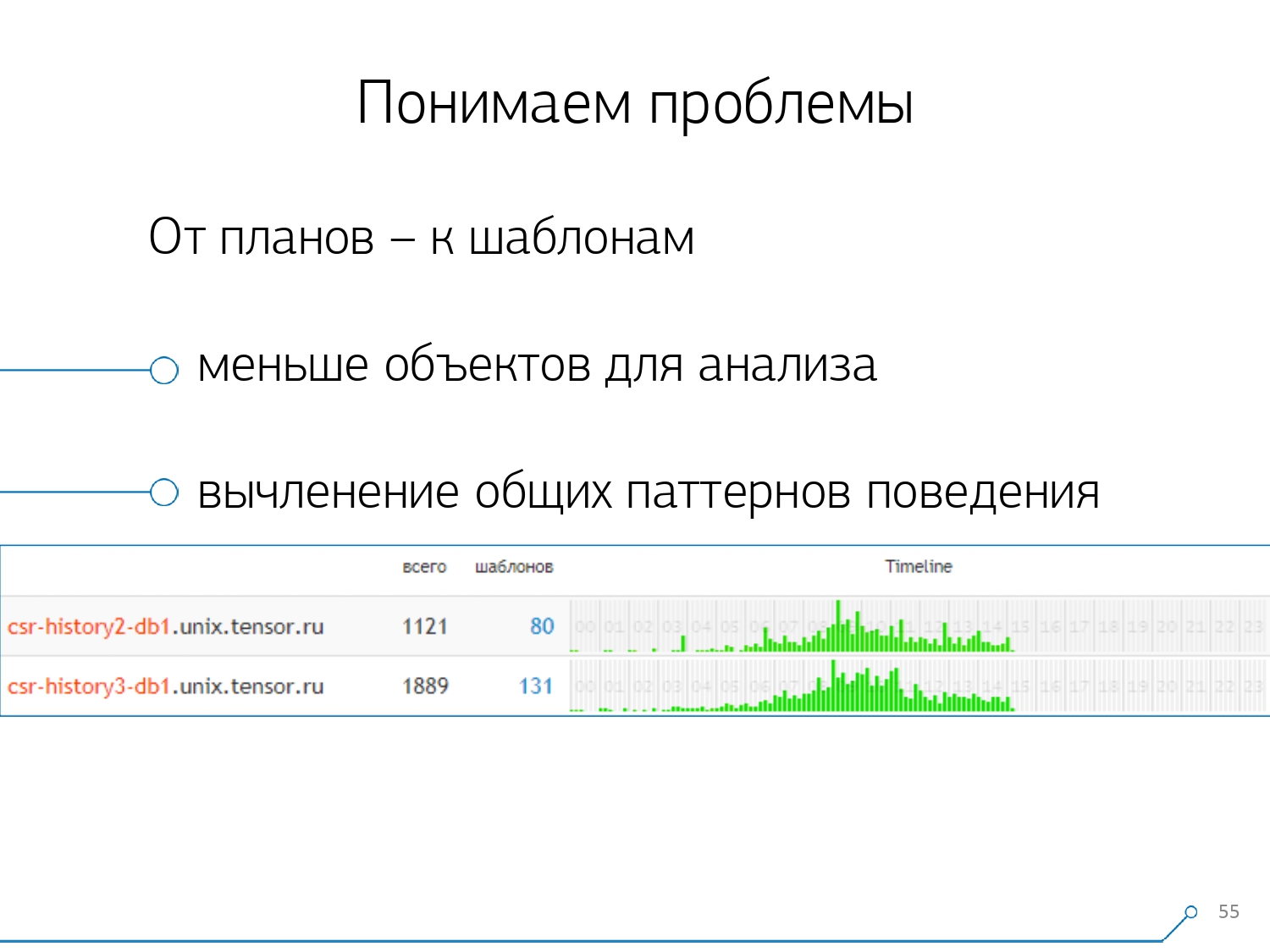 Nous avons alors réalisé qu'il n'était pas très intéressant de regarder la corrélation d'une requête entre différents serveurs. Cela arrive rarement lorsque vous avez une application qui craque également ici et là. Mais même si c'est la même chose, regardez n'importe lequel de ces serveurs.Ainsi, la section «un serveur - un jour» s'est avérée suffisante pour toute analyse.La première section analytique est le très «modèle» - une forme abrégée de présentation du plan, débarrassée de tous les indicateurs numériques. La deuxième section est l'application ou la méthode, et la troisième est le nœud spécifique du plan qui nous a causé des problèmes.Lorsque nous sommes passés d'instances spécifiques à des modèles, nous avons immédiatement reçu deux avantages:
Nous avons alors réalisé qu'il n'était pas très intéressant de regarder la corrélation d'une requête entre différents serveurs. Cela arrive rarement lorsque vous avez une application qui craque également ici et là. Mais même si c'est la même chose, regardez n'importe lequel de ces serveurs.Ainsi, la section «un serveur - un jour» s'est avérée suffisante pour toute analyse.La première section analytique est le très «modèle» - une forme abrégée de présentation du plan, débarrassée de tous les indicateurs numériques. La deuxième section est l'application ou la méthode, et la troisième est le nœud spécifique du plan qui nous a causé des problèmes.Lorsque nous sommes passés d'instances spécifiques à des modèles, nous avons immédiatement reçu deux avantages:
, .
, «» - , . , - , , , — , , — , , . , , .
 Les méthodes restantes sont basées sur les indicateurs que nous extrayons du plan: combien de fois un tel modèle s'est produit, le temps total et moyen, combien de données ont été lues sur le disque et combien de la mémoire ...Parce que, par exemple, vous accédez à la page d'analyse par hôte, voir - quelque chose de trop sur le disque pour lire le début. Le disque du serveur ne résiste pas - et qui en lit?Et vous pouvez trier par n'importe quelle colonne et décider de ce que vous allez traiter en ce moment - avec la charge sur le processeur ou le disque, ou avec le nombre total de demandes ... Trié, semblé "top", réparé - a déployé une nouvelle version de l'application.[conférence vidéo]Et tout de suite, vous pouvez voir différentes applications qui viennent avec le même modèle à partir d'une demande comme
Les méthodes restantes sont basées sur les indicateurs que nous extrayons du plan: combien de fois un tel modèle s'est produit, le temps total et moyen, combien de données ont été lues sur le disque et combien de la mémoire ...Parce que, par exemple, vous accédez à la page d'analyse par hôte, voir - quelque chose de trop sur le disque pour lire le début. Le disque du serveur ne résiste pas - et qui en lit?Et vous pouvez trier par n'importe quelle colonne et décider de ce que vous allez traiter en ce moment - avec la charge sur le processeur ou le disque, ou avec le nombre total de demandes ... Trié, semblé "top", réparé - a déployé une nouvelle version de l'application.[conférence vidéo]Et tout de suite, vous pouvez voir différentes applications qui viennent avec le même modèle à partir d'une demande commeSELECT * FROM users WHERE login = 'Vasya'. Frontend, backend, processing ... Et vous vous demandez pourquoi l'utilisateur devrait lire le traitement s'il n'interagit pas avec lui.La façon opposée est de voir immédiatement à partir de l'application ce qu'elle fait. Par exemple, un frontend est ceci, ceci, ceci et ceci une fois par heure (seule la chronologie aide). Et immédiatement la question se pose - il semble que ce ne soit pas l'affaire du front-end de faire quelque chose une fois par heure ... Après un certain temps, nous avons réalisé que nous manquions de statistiques agrégées en termes de nœuds de plan . Nous n'avons isolé des plans que les nœuds qui font quelque chose avec les données des tables elles-mêmes (les lire / écrire par index ou non). En fait, par rapport à l'image précédente, un seul aspect est ajouté: le nombre d'enregistrements que ce nœud nous a apporté et le nombre qu'il a supprimé (lignes supprimées par filtre).Vous n'avez pas d'index approprié sur la plaque, vous en faites la demande, il passe devant l'index, tombe dans Seq Scan ... vous avez filtré tous les enregistrements sauf un. Et pourquoi avez-vous besoin de 100 millions d'enregistrements filtrés par jour, est-il préférable de rouler l'index?
Après un certain temps, nous avons réalisé que nous manquions de statistiques agrégées en termes de nœuds de plan . Nous n'avons isolé des plans que les nœuds qui font quelque chose avec les données des tables elles-mêmes (les lire / écrire par index ou non). En fait, par rapport à l'image précédente, un seul aspect est ajouté: le nombre d'enregistrements que ce nœud nous a apporté et le nombre qu'il a supprimé (lignes supprimées par filtre).Vous n'avez pas d'index approprié sur la plaque, vous en faites la demande, il passe devant l'index, tombe dans Seq Scan ... vous avez filtré tous les enregistrements sauf un. Et pourquoi avez-vous besoin de 100 millions d'enregistrements filtrés par jour, est-il préférable de rouler l'index? Après avoir examiné tous les plans par nœuds, nous nous sommes rendu compte que certaines structures typiques des plans semblaient très suspectes. Et ce serait bien de dire au développeur: "Ami, ici tu lis d'abord par index, puis tu le tries, puis tu le coupes" - en règle générale, il y a un enregistrement.Tous ceux qui ont écrit des requêtes avec un tel modèle sont probablement tombés sur: "Donnez-moi la dernière commande pour Vasya, sa date" Et si vous n'avez pas d'index par date, ou que l'index utilisé n'a pas de date, alors allez exactement sur un tel "râteau" et marchez dessus .Mais nous savons que c'est un "rake" - alors pourquoi ne pas dire immédiatement au développeur ce qu'il doit faire. En conséquence, ouvrant le plan maintenant, notre développeur voit immédiatement une belle image avec des invites, où on lui dit immédiatement: "Vous avez des problèmes ici et ici, mais ils sont résolus de cette façon et cela."En conséquence, la quantité d'expérience qui était nécessaire pour résoudre les problèmes au début et a maintenant considérablement diminué. Ici, nous avons un tel outil.
Après avoir examiné tous les plans par nœuds, nous nous sommes rendu compte que certaines structures typiques des plans semblaient très suspectes. Et ce serait bien de dire au développeur: "Ami, ici tu lis d'abord par index, puis tu le tries, puis tu le coupes" - en règle générale, il y a un enregistrement.Tous ceux qui ont écrit des requêtes avec un tel modèle sont probablement tombés sur: "Donnez-moi la dernière commande pour Vasya, sa date" Et si vous n'avez pas d'index par date, ou que l'index utilisé n'a pas de date, alors allez exactement sur un tel "râteau" et marchez dessus .Mais nous savons que c'est un "rake" - alors pourquoi ne pas dire immédiatement au développeur ce qu'il doit faire. En conséquence, ouvrant le plan maintenant, notre développeur voit immédiatement une belle image avec des invites, où on lui dit immédiatement: "Vous avez des problèmes ici et ici, mais ils sont résolus de cette façon et cela."En conséquence, la quantité d'expérience qui était nécessaire pour résoudre les problèmes au début et a maintenant considérablement diminué. Ici, nous avons un tel outil.
Source: https://habr.com/ru/post/undefined/
All Articles