Depuis des années, des experts en C ++ discutent de la sémantique des valeurs, de l'immuabilité et du partage des ressources par la communication. À propos d'un nouveau monde sans mutex ni races, sans modèles de commandement et d'observation. En fait, tout n'est pas si simple. Le principal problème réside toujours dans nos structures de données. Les structures de données immuables ne changent pas leurs valeurs. Pour faire quelque chose avec eux, vous devez créer de nouvelles valeurs. Les anciennes valeurs restent au même endroit, donc elles peuvent être lues à partir de différents flux sans problèmes et verrous. Par conséquent, les ressources peuvent être partagées de manière plus rationnelle et ordonnée, car les anciennes et les nouvelles valeurs peuvent utiliser des données communes. Grâce à cela, ils sont beaucoup plus rapides à comparer les uns avec les autres et stockent de manière compacte l'historique des opérations avec la possibilité d'annulation. Tout cela s'intègre parfaitement sur les systèmes multi-threads et interactifs: de telles structures de données simplifient l'architecture des applications bureautiques et permettent aux services de mieux évoluer. Les structures immuables sont le secret du succès de Clojure et Scala, et même la communauté JavaScript en profite désormais, car elles ont la bibliothèque Immutable.js,écrit dans les entrailles de la société Facebook.Sous la coupe - vidéo et traduction du rapport Juan Puente de la conférence C ++ Russia 2019 Moscou. Juan parle d' Immer , une bibliothèque de structures immuables pour C ++. Dans la poste:
Les structures de données immuables ne changent pas leurs valeurs. Pour faire quelque chose avec eux, vous devez créer de nouvelles valeurs. Les anciennes valeurs restent au même endroit, donc elles peuvent être lues à partir de différents flux sans problèmes et verrous. Par conséquent, les ressources peuvent être partagées de manière plus rationnelle et ordonnée, car les anciennes et les nouvelles valeurs peuvent utiliser des données communes. Grâce à cela, ils sont beaucoup plus rapides à comparer les uns avec les autres et stockent de manière compacte l'historique des opérations avec la possibilité d'annulation. Tout cela s'intègre parfaitement sur les systèmes multi-threads et interactifs: de telles structures de données simplifient l'architecture des applications bureautiques et permettent aux services de mieux évoluer. Les structures immuables sont le secret du succès de Clojure et Scala, et même la communauté JavaScript en profite désormais, car elles ont la bibliothèque Immutable.js,écrit dans les entrailles de la société Facebook.Sous la coupe - vidéo et traduction du rapport Juan Puente de la conférence C ++ Russia 2019 Moscou. Juan parle d' Immer , une bibliothèque de structures immuables pour C ++. Dans la poste:- avantages architecturaux de l'immunité;
- création d'un type de vecteur persistant efficace basé sur des arbres RRB;
- analyse de l'architecture sur l'exemple d'un simple éditeur de texte.
La tragédie de l'architecture basée sur la valeur
Pour comprendre l'importance des structures de données immuables, nous discutons de la sémantique des valeurs. C'est une caractéristique très importante du C ++, je le considère comme l'un des principaux avantages de ce langage. Pour tout cela, il est très difficile d'utiliser la sémantique des valeurs comme on le souhaiterait. Je crois que c'est la tragédie de l'architecture basée sur la valeur, et la route vers cette tragédie est pavée de bonnes intentions. Supposons que nous devions écrire un logiciel interactif basé sur un modèle de données avec une représentation d'un document modifiable par l'utilisateur. Lorsque l' architecture basée sur les valeurs au cœur de ce modèle utilise des types de valeurs simples et pratiques qui existent déjà dans la langue: vector, map, tuple,struct. La logique d'application est créée à partir de fonctions qui prennent les documents par valeur et renvoient une nouvelle version d'un document par valeur. Ce document peut changer à l'intérieur de la fonction (comme cela se produit ci-dessous), mais la sémantique des valeurs en C ++, appliquée à l'argument par valeur et au type de retour par valeur, garantit qu'il n'y a pas d'effets secondaires.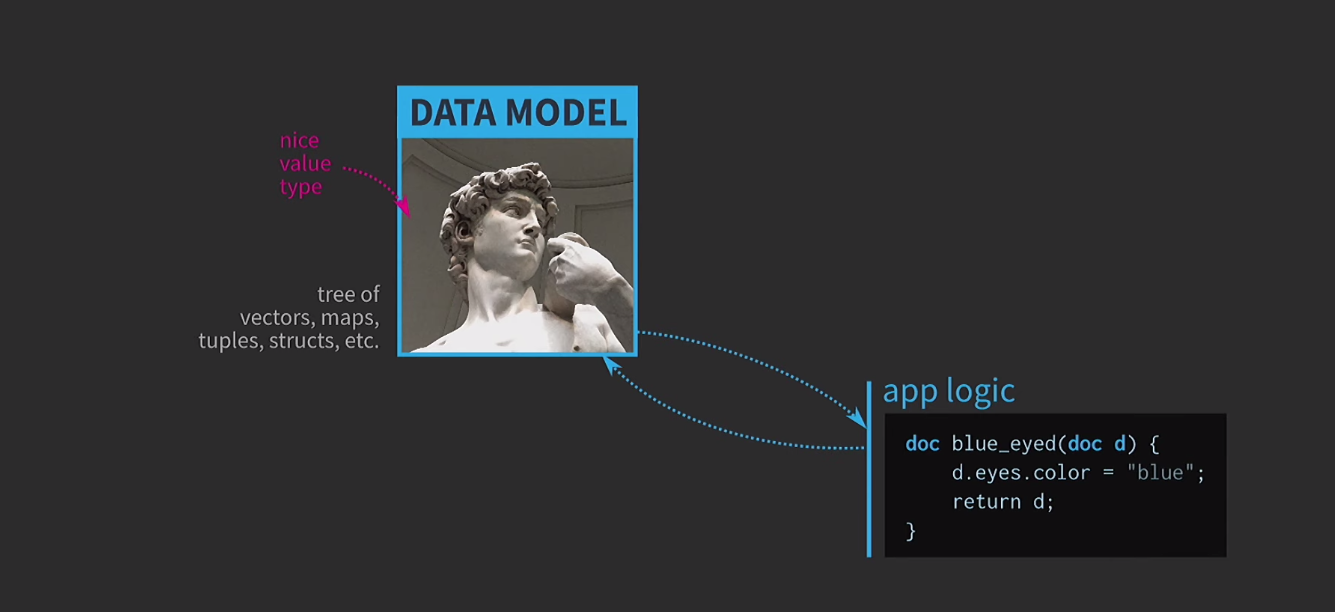 Cette fonctionnalité est très facile à analyser et à tester.
Cette fonctionnalité est très facile à analyser et à tester. Puisque nous travaillons avec des valeurs, nous allons essayer d'implémenter l'annulation de l'action. Cela peut être difficile, mais avec notre approche, c'est une tâche triviale: nous avons
Puisque nous travaillons avec des valeurs, nous allons essayer d'implémenter l'annulation de l'action. Cela peut être difficile, mais avec notre approche, c'est une tâche triviale: nous avons std::vectoravec différents états différentes copies du document.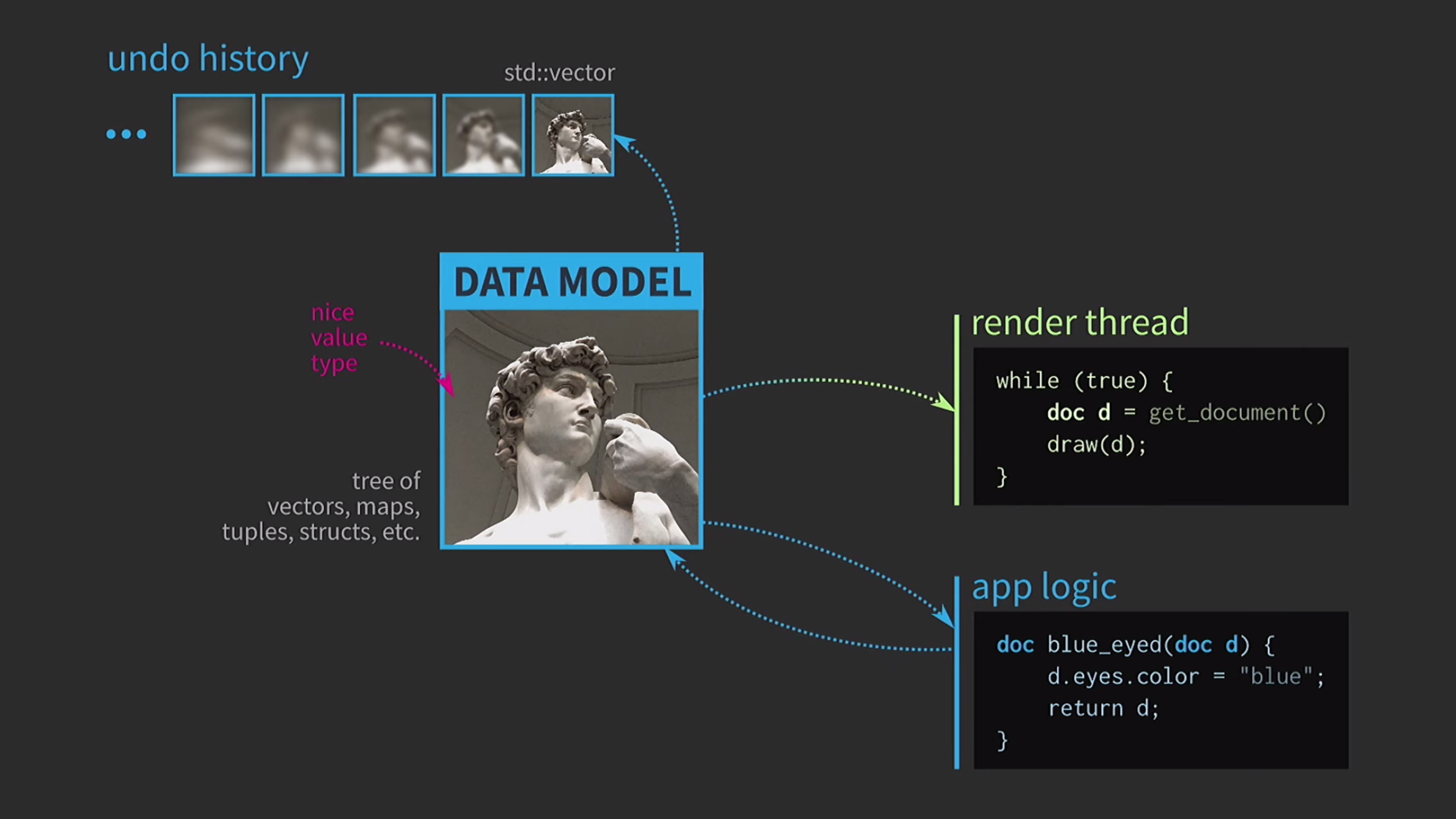 Supposons que nous ayons également une interface utilisateur et pour garantir sa réactivité, le mappage de l'interface utilisateur doit être effectué dans un thread distinct. Le document est envoyé à un autre flux par message, et l'interaction a également lieu sur la base de messages, et non via le partage d'état à l'aide
Supposons que nous ayons également une interface utilisateur et pour garantir sa réactivité, le mappage de l'interface utilisateur doit être effectué dans un thread distinct. Le document est envoyé à un autre flux par message, et l'interaction a également lieu sur la base de messages, et non via le partage d'état à l'aide mutexes. Lorsque la copie est reçue par le deuxième flux, vous pouvez y effectuer toutes les opérations nécessaires. L'enregistrement d'un document sur le disque est souvent très lent, surtout si le document est volumineux. Par conséquent, l'utilisation de
L'enregistrement d'un document sur le disque est souvent très lent, surtout si le document est volumineux. Par conséquent, l'utilisation de std::asynccette opération est effectuée de manière asynchrone. Nous utilisons un lambda, mettons un signe égal à l'intérieur pour avoir une copie, et maintenant vous pouvez enregistrer sans autres types de synchronisation primitifs.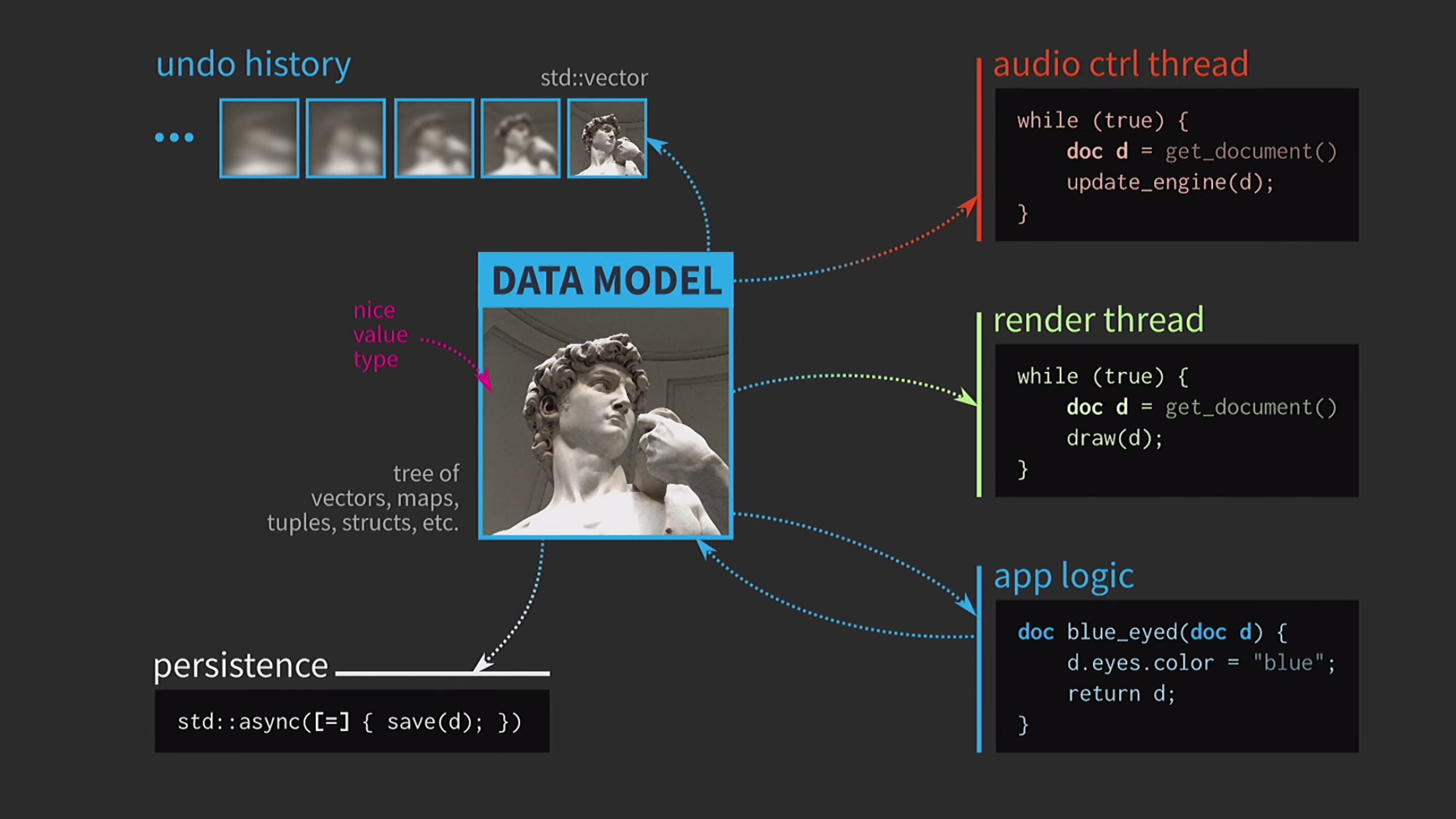 De plus, supposons que nous ayons également un flux de contrôle sonore. Comme je l'ai dit, j'ai beaucoup travaillé avec des logiciels de musique, et le son est une autre représentation de notre document, il doit être dans un flux séparé. Par conséquent, une copie du document est également requise pour ce flux.En conséquence, nous avons obtenu un schéma très beau, mais pas trop réaliste.
De plus, supposons que nous ayons également un flux de contrôle sonore. Comme je l'ai dit, j'ai beaucoup travaillé avec des logiciels de musique, et le son est une autre représentation de notre document, il doit être dans un flux séparé. Par conséquent, une copie du document est également requise pour ce flux.En conséquence, nous avons obtenu un schéma très beau, mais pas trop réaliste.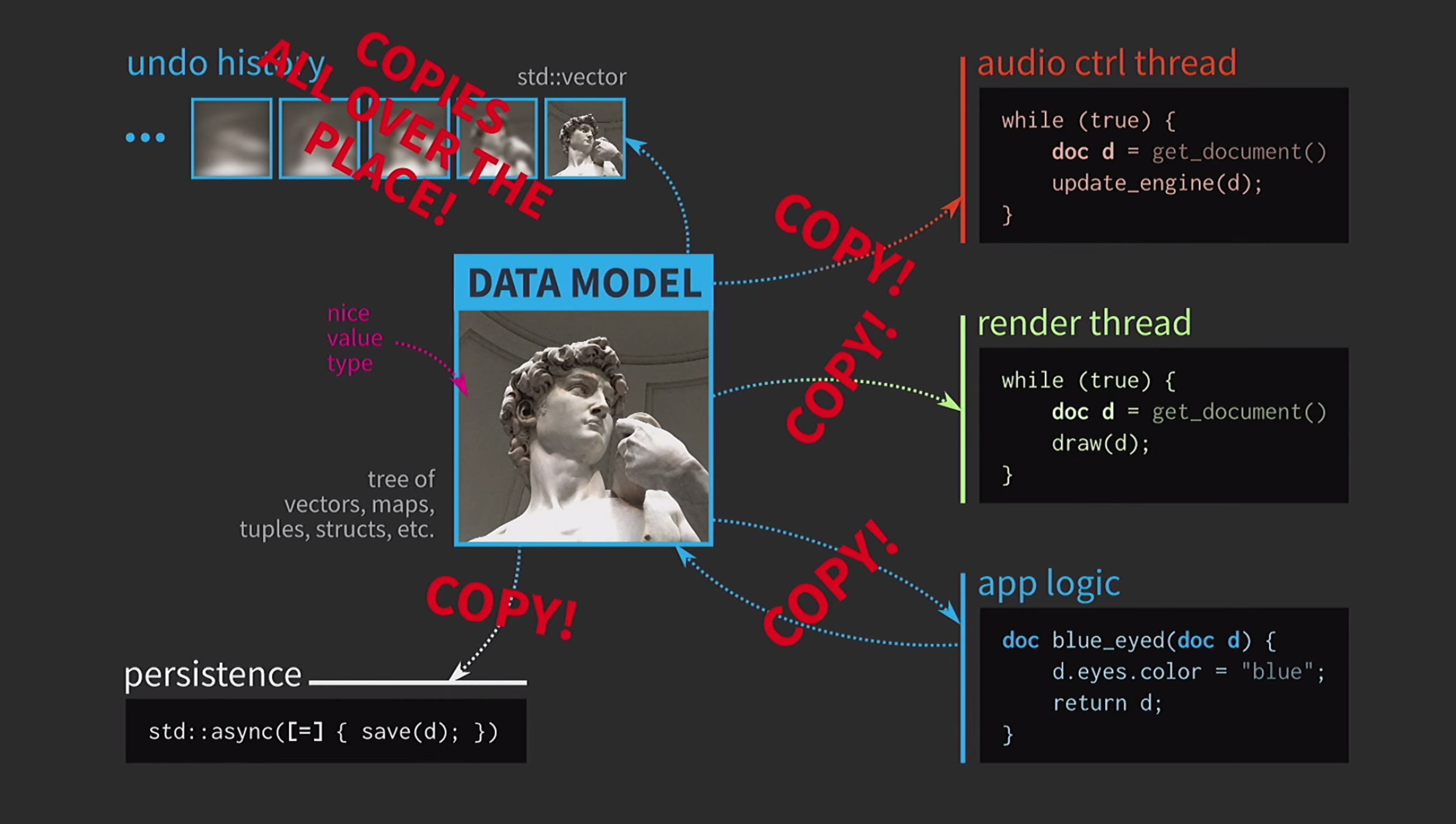 Il doit constamment copier des documents, l'historique des actions pour l'annulation prend des gigaoctets, et pour chaque rendu de l'interface utilisateur, vous devez faire une copie complète du document. En général, toutes les interactions sont trop coûteuses.
Il doit constamment copier des documents, l'historique des actions pour l'annulation prend des gigaoctets, et pour chaque rendu de l'interface utilisateur, vous devez faire une copie complète du document. En général, toutes les interactions sont trop coûteuses.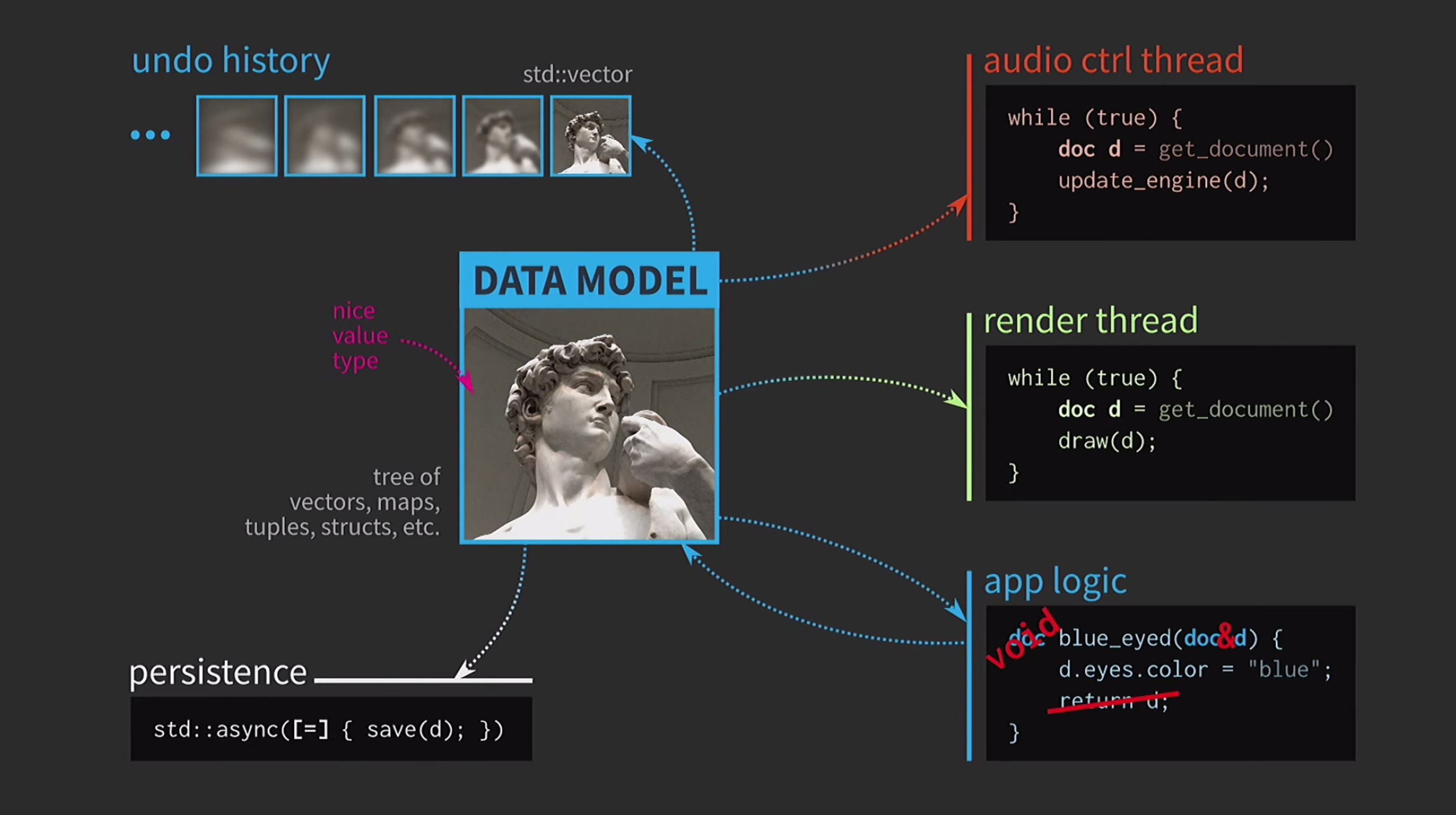 Que fait le développeur C ++ dans cette situation? Au lieu d'accepter un document par valeur, la logique d'application accepte désormais un lien vers le document et le met à jour si nécessaire. Dans ce cas, vous n'avez rien à retourner. Mais maintenant, il ne s'agit pas de valeurs, mais d'objets et d'emplacements. Cela crée de nouveaux problèmes: s'il existe un lien avec l'État avec un accès partagé, vous en avez besoin
Que fait le développeur C ++ dans cette situation? Au lieu d'accepter un document par valeur, la logique d'application accepte désormais un lien vers le document et le met à jour si nécessaire. Dans ce cas, vous n'avez rien à retourner. Mais maintenant, il ne s'agit pas de valeurs, mais d'objets et d'emplacements. Cela crée de nouveaux problèmes: s'il existe un lien avec l'État avec un accès partagé, vous en avez besoin mutex. Ceci est extrêmement coûteux, il y aura donc une certaine représentation de notre interface utilisateur sous la forme d'une arborescence extrêmement complexe à partir de divers widgets.Tous ces éléments devraient recevoir des mises à jour lorsqu'un document change, donc un mécanisme de mise en file d'attente est nécessaire pour les signaux de changement. De plus, l'historique du document n'est plus un ensemble d'états, ce sera une mise en œuvre du modèle d'équipe. L'opération doit être mise en œuvre deux fois, dans un sens et dans l'autre, et assurez-vous que tout est symétrique. L'enregistrement dans un thread séparé est déjà trop difficile, il faudra donc l'abandonner.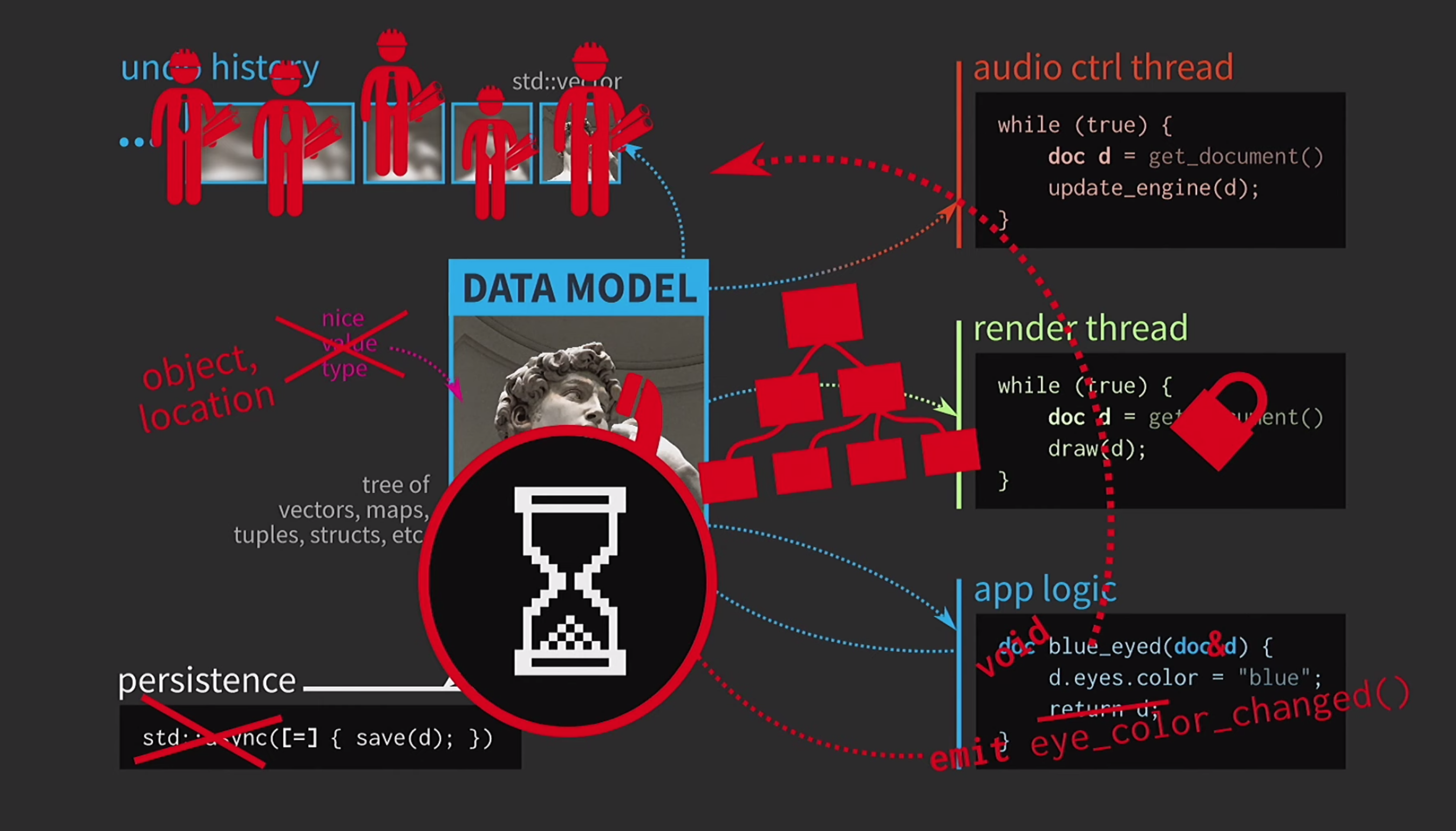 Les utilisateurs sont déjà habitués à l'image du sablier, donc ça va s'ils attendent un peu. Une autre chose fait peur - le monstre de pâtes gouverne maintenant notre code.À quel moment tout s'est-il dégradé? Nous avons très bien conçu notre code, puis nous avons dû faire des compromis à cause de la copie. Mais en C ++, la copie est requise pour passer par valeur uniquement pour les données mutables. Si l'objet est immuable, alors l'opérateur d'affectation peut être implémenté de sorte qu'il ne copie que le pointeur vers la représentation interne et rien de plus.
Les utilisateurs sont déjà habitués à l'image du sablier, donc ça va s'ils attendent un peu. Une autre chose fait peur - le monstre de pâtes gouverne maintenant notre code.À quel moment tout s'est-il dégradé? Nous avons très bien conçu notre code, puis nous avons dû faire des compromis à cause de la copie. Mais en C ++, la copie est requise pour passer par valeur uniquement pour les données mutables. Si l'objet est immuable, alors l'opérateur d'affectation peut être implémenté de sorte qu'il ne copie que le pointeur vers la représentation interne et rien de plus.const auto v0 = vector<int>{};
Considérez une structure de données qui pourrait nous aider. Dans le vecteur ci-dessous, toutes les méthodes sont marquées comme constétant immuables. À l'exécution .push_back, le vecteur ne se met pas à jour; à la place, un nouveau vecteur est retourné, auquel les données transférées sont ajoutées. Malheureusement, nous ne pouvons pas utiliser de crochets avec cette approche en raison de leur définition. Au lieu de cela, vous pouvez utiliser la fonction.setqui renvoie une nouvelle version avec un élément mis à jour. Notre structure de données a maintenant une propriété qui s'appelle la persistance dans la programmation fonctionnelle. Cela ne signifie pas que nous sauvegardons cette structure de données sur le disque dur, mais le fait que lorsqu'il est mis à jour, l'ancien contenu n'est pas supprimé - à la place, une nouvelle fourchette de notre monde est créée, c'est-à-dire la structure. Grâce à cela, nous pouvons comparer les valeurs passées avec le présent - cela se fait à l'aide de deux assert.const auto v0 = vector<int>{};
const auto v1 = v0.push_back(15);
const auto v2 = v1.push_back(16);
const auto v3 = v2.set(0, 42);
assert(v2.size() == v0.size() + 2);
assert(v3[0] - v1[0] == 27);
Les modifications peuvent désormais être vérifiées directement, elles ne sont plus des propriétés cachées de la structure de données. Cette fonctionnalité est particulièrement utile dans les systèmes interactifs où nous devons constamment modifier les données.Une autre propriété importante est le partage structurel. Maintenant, nous ne copions pas toutes les données pour chaque nouvelle version de la structure de données. Même avec .push_backet.settoutes les données ne sont pas copiées, mais seulement une petite partie. Toutes nos fourches ont un accès commun à une vue compacte, proportionnelle au nombre de modifications et non au nombre de copies. Il s'ensuit également que la comparaison est très rapide: si tout est stocké dans un bloc mémoire, dans un pointeur, alors vous pouvez simplement comparer les pointeurs et ne pas examiner les éléments qui s'y trouvent, s'ils sont égaux.Puisqu'un tel vecteur, il me semble, est extrêmement utile, je l'ai implémenté dans une bibliothèque séparée: c'est immer - une bibliothèque de structures immuables, un projet open source.En l'écrivant, je voulais que son utilisation soit familière aux développeurs C ++. Il existe de nombreuses bibliothèques qui implémentent les concepts de programmation fonctionnelle en C ++, mais cela donne l'impression que les développeurs écrivent pour Haskell, et non pour C ++. Cela crée des inconvénients. De plus, j'ai réalisé de bonnes performances. Les gens utilisent C ++ lorsque les ressources disponibles sont limitées. Enfin, je voulais que la bibliothèque soit personnalisable. Cette exigence est liée à l'exigence de performance.A la recherche d'un vecteur magique
Dans la deuxième partie du rapport, nous verrons comment est structuré ce vecteur immuable. La façon la plus simple de comprendre les principes d'une telle structure de données est de commencer par une liste régulière. Si vous êtes un peu familier avec la programmation fonctionnelle (en utilisant Lisp ou Haskell comme exemple), vous savez que les listes sont les structures de données immuables les plus courantes.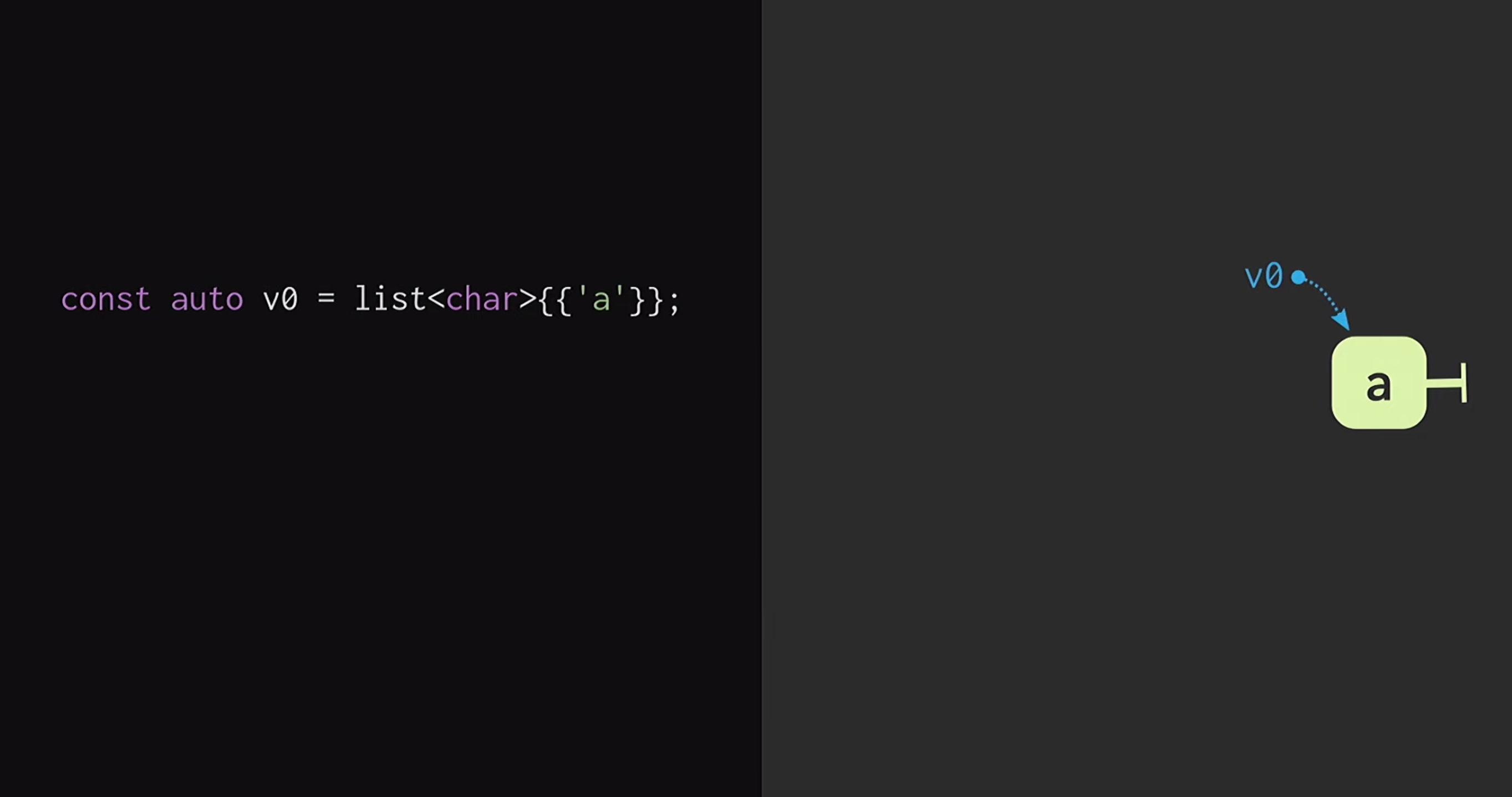 Pour commencer, supposons que nous avons une liste avec un seul nœud
Pour commencer, supposons que nous avons une liste avec un seul nœud v1qu'ils v0indiquent des éléments différents.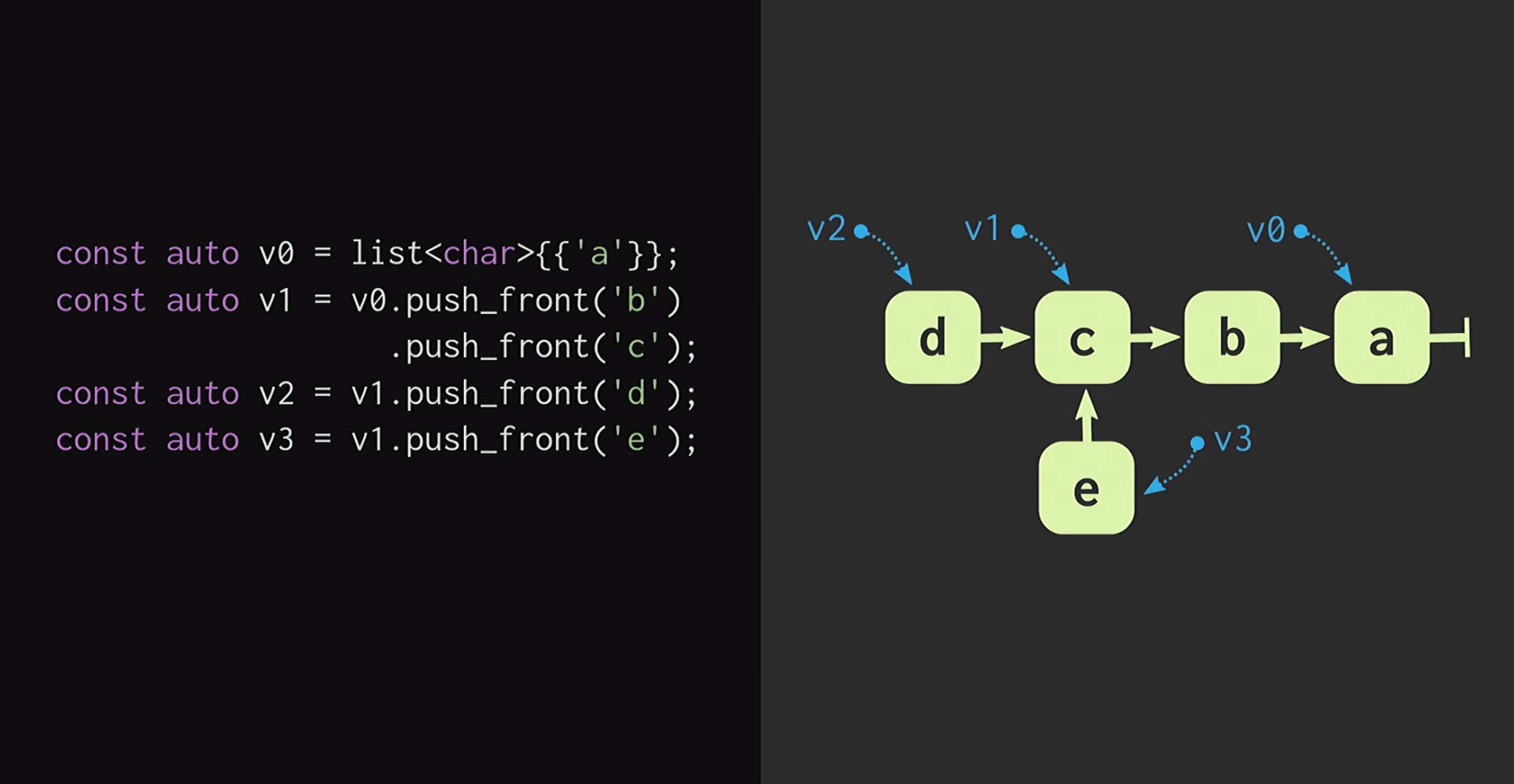 Nous pouvons également créer une fourchette de réalité, c'est-à-dire créer une nouvelle liste qui a la même fin, mais un début différent.De telles structures de données sont étudiées depuis longtemps: Chris Okasaki a écrit le travail fondamental des structures de données purement fonctionnelles . De plus, la structure de données de Finger Tree proposée par Ralf Hinze et Ross Paterson est très intéressante . Mais pour C ++, ces structures de données ne fonctionnent pas bien. Ils utilisent de petits nœuds, et nous savons qu'en C ++, les petits nœuds signifient un manque d'efficacité de la mise en cache.De plus, ils s'appuient souvent sur des propriétés que C ++ ne possède pas, comme la paresse. Par conséquent, le travail de Phil Bagwell sur les structures de données immuables nous est beaucoup plus utile - un lien écrit au début des années 2000, ainsi que le travail de Rich Hickey - lien, auteur de Clojure. Rich Hickey a créé une liste, qui n'est en fait pas une liste, mais basée sur des structures de données modernes: vecteurs et cartes de hachage. Ces structures de données ont une efficacité de mise en cache et interagissent bien avec les processeurs modernes, pour lesquels il n'est pas souhaitable de travailler avec de petits nœuds. De telles structures peuvent être utilisées en C ++.Comment construire un vecteur immunitaire? Au cœur de toute structure, même à distance ressemblant à un vecteur, il doit y avoir un tableau. Mais la baie n'a pas de partage structurel. Pour modifier un élément du tableau, sans perdre la propriété de persistance, vous devez copier le tableau entier. Afin de ne pas faire cela, le tableau peut être divisé en morceaux séparés.Maintenant, lors de la mise à jour d'un élément vectoriel, nous devons copier une seule pièce, et non le vecteur entier. Mais ces éléments eux-mêmes ne sont pas une structure de données; ils doivent être combinés d'une manière ou d'une autre. Mettez-les dans un autre tableau. Une fois de plus, le problème se pose que la matrice peut être très grande, puis la recopier prendra trop de temps.Nous divisons ce tableau en morceaux, les plaçons à nouveau dans un tableau séparé et répétons cette procédure jusqu'à ce qu'il n'y ait qu'un seul tableau racine. La structure résultante est appelée arbre résiduel. Cet arbre est décrit par la constante M = 2B, c'est-à-dire le facteur de ramification de l'arbre. Cet indicateur de branche devrait être une puissance de deux, et nous saurons très bientôt pourquoi. Dans l'exemple de la diapositive, des blocs de quatre caractères sont utilisés, mais en pratique, des blocs de 32 caractères sont utilisés. Il existe des expériences avec lesquelles vous pouvez trouver la taille de bloc optimale pour une architecture particulière. Cela vous permet d'obtenir le meilleur ratio de partage structurel et de temps d'accès: plus l'arbre est bas, moins le temps d'accès est important.En lisant ceci, les développeurs écrivant en C ++ pensent probablement: mais toutes les structures arborescentes sont très lentes! Les arbres poussent avec une augmentation du nombre d'éléments en eux, et à cause de cela, les temps d'accès sont dégradés. C'est pourquoi les programmeurs préfèrent
Nous pouvons également créer une fourchette de réalité, c'est-à-dire créer une nouvelle liste qui a la même fin, mais un début différent.De telles structures de données sont étudiées depuis longtemps: Chris Okasaki a écrit le travail fondamental des structures de données purement fonctionnelles . De plus, la structure de données de Finger Tree proposée par Ralf Hinze et Ross Paterson est très intéressante . Mais pour C ++, ces structures de données ne fonctionnent pas bien. Ils utilisent de petits nœuds, et nous savons qu'en C ++, les petits nœuds signifient un manque d'efficacité de la mise en cache.De plus, ils s'appuient souvent sur des propriétés que C ++ ne possède pas, comme la paresse. Par conséquent, le travail de Phil Bagwell sur les structures de données immuables nous est beaucoup plus utile - un lien écrit au début des années 2000, ainsi que le travail de Rich Hickey - lien, auteur de Clojure. Rich Hickey a créé une liste, qui n'est en fait pas une liste, mais basée sur des structures de données modernes: vecteurs et cartes de hachage. Ces structures de données ont une efficacité de mise en cache et interagissent bien avec les processeurs modernes, pour lesquels il n'est pas souhaitable de travailler avec de petits nœuds. De telles structures peuvent être utilisées en C ++.Comment construire un vecteur immunitaire? Au cœur de toute structure, même à distance ressemblant à un vecteur, il doit y avoir un tableau. Mais la baie n'a pas de partage structurel. Pour modifier un élément du tableau, sans perdre la propriété de persistance, vous devez copier le tableau entier. Afin de ne pas faire cela, le tableau peut être divisé en morceaux séparés.Maintenant, lors de la mise à jour d'un élément vectoriel, nous devons copier une seule pièce, et non le vecteur entier. Mais ces éléments eux-mêmes ne sont pas une structure de données; ils doivent être combinés d'une manière ou d'une autre. Mettez-les dans un autre tableau. Une fois de plus, le problème se pose que la matrice peut être très grande, puis la recopier prendra trop de temps.Nous divisons ce tableau en morceaux, les plaçons à nouveau dans un tableau séparé et répétons cette procédure jusqu'à ce qu'il n'y ait qu'un seul tableau racine. La structure résultante est appelée arbre résiduel. Cet arbre est décrit par la constante M = 2B, c'est-à-dire le facteur de ramification de l'arbre. Cet indicateur de branche devrait être une puissance de deux, et nous saurons très bientôt pourquoi. Dans l'exemple de la diapositive, des blocs de quatre caractères sont utilisés, mais en pratique, des blocs de 32 caractères sont utilisés. Il existe des expériences avec lesquelles vous pouvez trouver la taille de bloc optimale pour une architecture particulière. Cela vous permet d'obtenir le meilleur ratio de partage structurel et de temps d'accès: plus l'arbre est bas, moins le temps d'accès est important.En lisant ceci, les développeurs écrivant en C ++ pensent probablement: mais toutes les structures arborescentes sont très lentes! Les arbres poussent avec une augmentation du nombre d'éléments en eux, et à cause de cela, les temps d'accès sont dégradés. C'est pourquoi les programmeurs préfèrent std::unordered_map, plutôt que std::map. Je m'empresse de vous rassurer: notre arbre pousse très lentement. Un vecteur contenant toutes les valeurs possibles d'un entier 32 bits n'a que 7 niveaux de haut. Il peut être démontré expérimentalement qu'avec cette taille de données, le rapport du cache au volume de chargement affecte considérablement les performances que la profondeur de l'arborescence.Voyons comment s'effectue l'accès à un élément d'une arborescence. Supposons que vous deviez passer à l'élément 17. Nous prenons une représentation binaire de l'index et la divisons en groupes de la taille d'un facteur de branchement. Dans chaque groupe, nous utilisons la valeur binaire correspondante et descendons ainsi l'arbre.Supposons ensuite que nous devons modifier cette structure de données, c'est-à-dire exécuter la méthode
Dans chaque groupe, nous utilisons la valeur binaire correspondante et descendons ainsi l'arbre.Supposons ensuite que nous devons modifier cette structure de données, c'est-à-dire exécuter la méthode .set.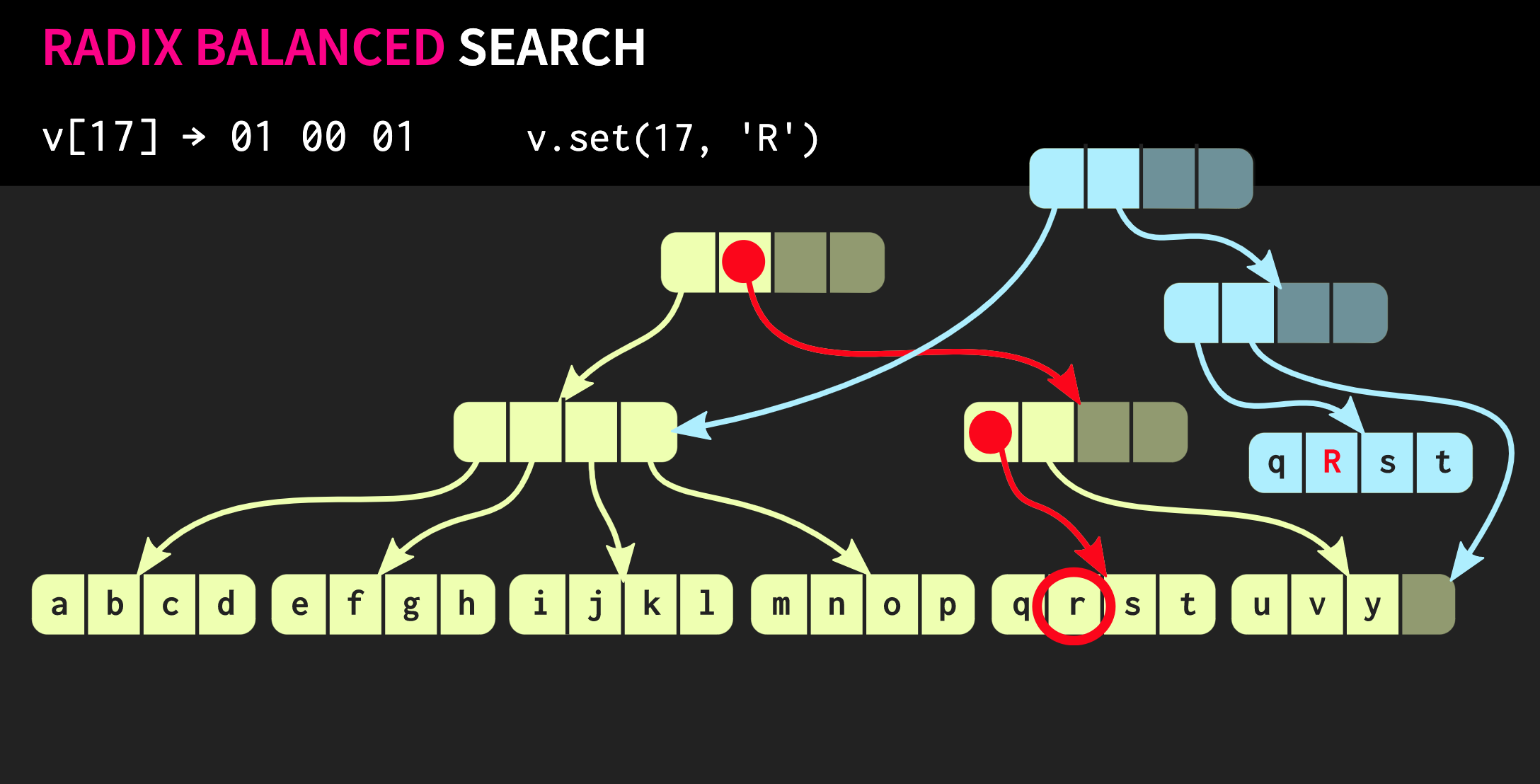 Pour ce faire, vous devez d'abord copier le bloc dans lequel se trouve l'élément, puis copier chaque nœud interne sur le chemin de l'élément. D'une part, beaucoup de données doivent être copiées, mais en même temps une partie importante de ces données est commune, cela compense leur volume.Soit dit en passant, il existe une structure de données beaucoup plus ancienne qui est très similaire à celle que j'ai décrite. Ce sont des pages de mémoire avec une arborescence de tableaux de pages. Sa gestion s'effectue également par appel
Pour ce faire, vous devez d'abord copier le bloc dans lequel se trouve l'élément, puis copier chaque nœud interne sur le chemin de l'élément. D'une part, beaucoup de données doivent être copiées, mais en même temps une partie importante de ces données est commune, cela compense leur volume.Soit dit en passant, il existe une structure de données beaucoup plus ancienne qui est très similaire à celle que j'ai décrite. Ce sont des pages de mémoire avec une arborescence de tableaux de pages. Sa gestion s'effectue également par appel fork.Essayons d'améliorer notre structure de données. Supposons que nous devons connecter deux vecteurs. La structure de données décrite jusqu'à présent présente les mêmes limites std::vector:qu'elle a des cellules vides dans sa partie la plus à droite. La structure étant parfaitement équilibrée, ces cellules vides ne peuvent pas se trouver au milieu de l'arbre. Par conséquent, s'il y a un deuxième vecteur que nous voulons combiner avec le premier, nous devrons copier les éléments dans des cellules vides, ce qui créera des cellules vides dans le deuxième vecteur, et à la fin, nous devrons copier le deuxième vecteur entier. Une telle opération a une complexité de calcul O (n), où n est la taille du deuxième vecteur.Nous essaierons d'obtenir un meilleur résultat. Il existe une version modifiée de notre structure de données appelée arbre équilibré radix détendu. Dans cette structure, les nœuds qui ne sont pas sur le chemin le plus à gauche peuvent avoir des cellules vides. Par conséquent, dans de tels nœuds incomplets (ou détendus), il est nécessaire de calculer la taille du sous-arbre. Vous pouvez maintenant effectuer une opération de jointure complexe mais logarithmique. Cette opération de complexité temporelle constante est O (log (32)). Les arbres étant peu profonds, le temps d'accès est constant, quoique relativement long. En raison du fait que nous avons une telle opération d'union, une version détendue de cette structure de données est appelée confluente: en plus d'être persistante, et vous pouvez la bifurquer, deux de ces structures peuvent être combinées en une seule.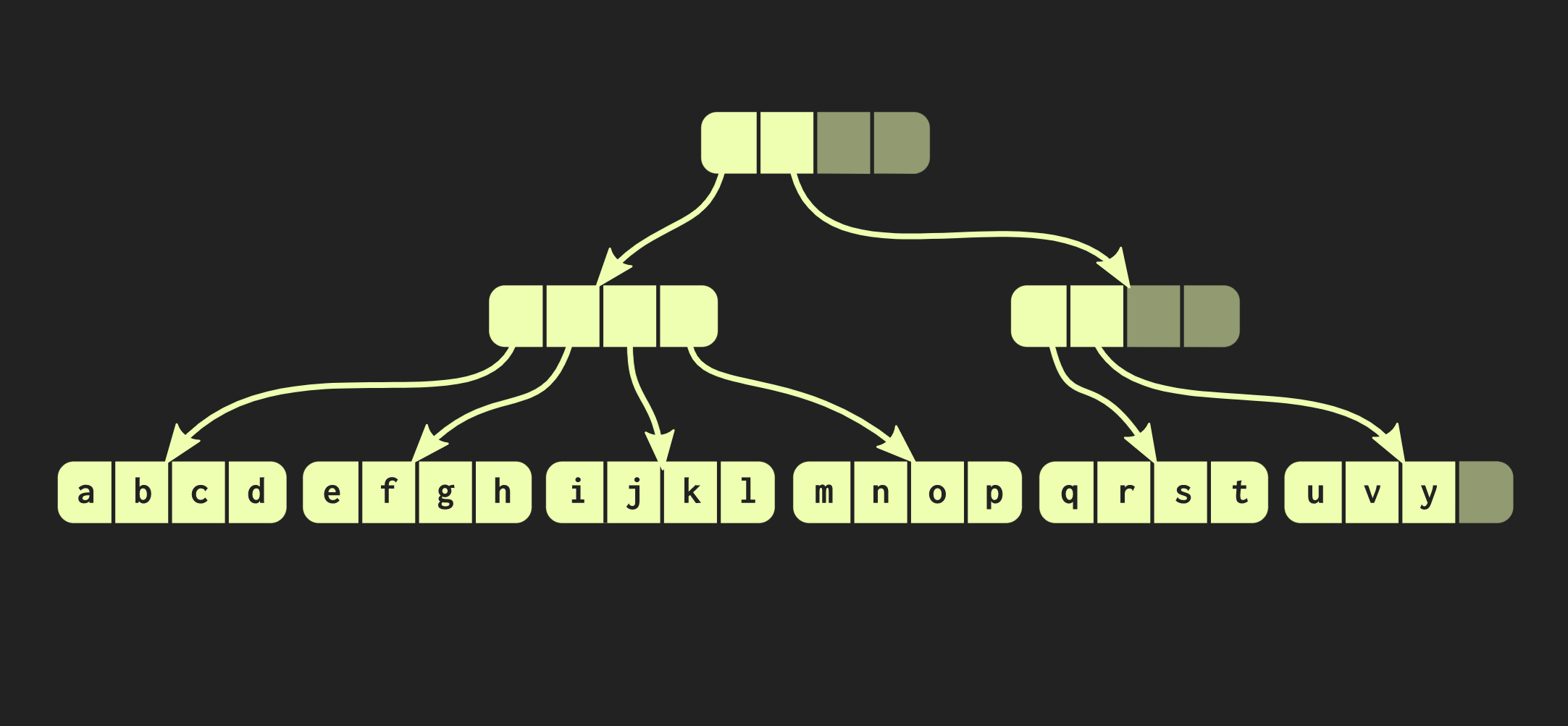 Dans l'exemple avec lequel nous avons travaillé jusqu'à présent, la structure des données est très soignée, mais dans la pratique, les implémentations dans Clojure et d'autres langages fonctionnels sont différentes. Ils créent des conteneurs pour chaque valeur, c'est-à-dire que chaque élément du vecteur se trouve dans une cellule distincte, et les nœuds terminaux contiennent des pointeurs vers ces éléments. Mais cette approche est extrêmement inefficace, en C ++ ne place généralement pas toutes les valeurs dans un conteneur. Par conséquent, il serait préférable que ces éléments soient situés directement dans les nœuds. Un autre problème se pose alors: différents éléments ont des tailles différentes. Si l'élément a la même taille que le pointeur, notre structure ressemblera à celle illustrée ci-dessous:
Dans l'exemple avec lequel nous avons travaillé jusqu'à présent, la structure des données est très soignée, mais dans la pratique, les implémentations dans Clojure et d'autres langages fonctionnels sont différentes. Ils créent des conteneurs pour chaque valeur, c'est-à-dire que chaque élément du vecteur se trouve dans une cellule distincte, et les nœuds terminaux contiennent des pointeurs vers ces éléments. Mais cette approche est extrêmement inefficace, en C ++ ne place généralement pas toutes les valeurs dans un conteneur. Par conséquent, il serait préférable que ces éléments soient situés directement dans les nœuds. Un autre problème se pose alors: différents éléments ont des tailles différentes. Si l'élément a la même taille que le pointeur, notre structure ressemblera à celle illustrée ci-dessous: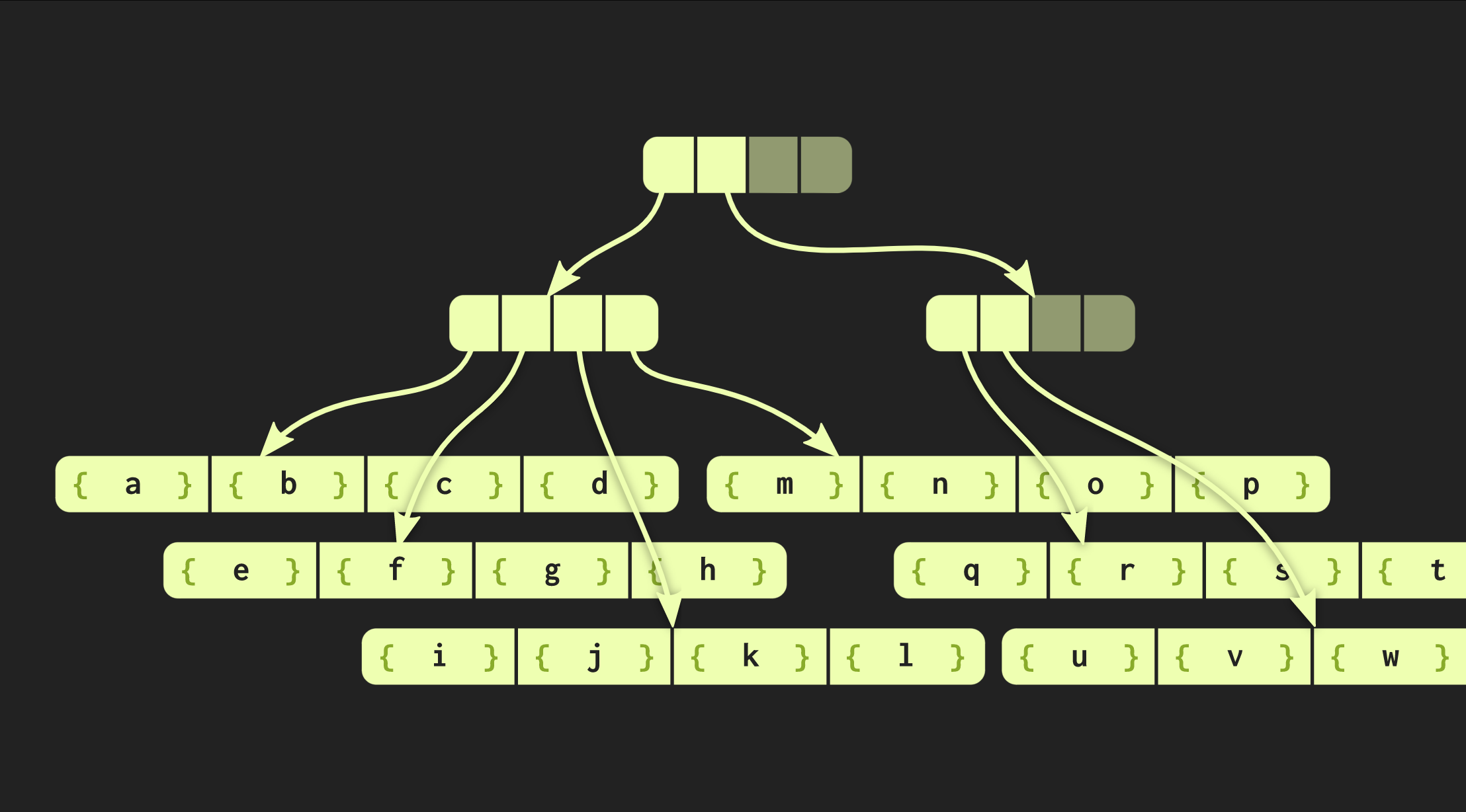 Mais si les éléments sont volumineux, la structure de données perd les propriétés que nous avons mesurées (temps d'accès O (log (32) ()), car la copie de l'une des feuilles prend maintenant plus de temps. Par conséquent, j'ai modifié cette structure de données de sorte que lorsque la taille augmente le nombre d'éléments qu'il contient a diminué le nombre de ces éléments dans les nœuds foliaires.Au contraire, si les éléments sont petits, ils peuvent désormais s'adapter davantage.La nouvelle version de l'arbre est appelée arbre équilibré radix incorporé.Elle n'est pas décrite par une constante, mais par deux: l'un d'eux décrit nœuds internes, et le second - feuillu. L'implémentation de l'arbre en C ++ permet de calculer la taille optimale de l'élément feuille en fonction de la taille des pointeurs et des éléments eux-mêmes.Notre arbre fonctionne déjà assez bien, mais il peut encore être amélioré. Jetez un oeil à une fonction similaire à une fonction
Mais si les éléments sont volumineux, la structure de données perd les propriétés que nous avons mesurées (temps d'accès O (log (32) ()), car la copie de l'une des feuilles prend maintenant plus de temps. Par conséquent, j'ai modifié cette structure de données de sorte que lorsque la taille augmente le nombre d'éléments qu'il contient a diminué le nombre de ces éléments dans les nœuds foliaires.Au contraire, si les éléments sont petits, ils peuvent désormais s'adapter davantage.La nouvelle version de l'arbre est appelée arbre équilibré radix incorporé.Elle n'est pas décrite par une constante, mais par deux: l'un d'eux décrit nœuds internes, et le second - feuillu. L'implémentation de l'arbre en C ++ permet de calculer la taille optimale de l'élément feuille en fonction de la taille des pointeurs et des éléments eux-mêmes.Notre arbre fonctionne déjà assez bien, mais il peut encore être amélioré. Jetez un oeil à une fonction similaire à une fonction iota:vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = v.push_back(i);
return v;
}
Il prend une entrée vector, s'exécute push_backà la fin du vecteur pour chaque entier entre firstet last, et renvoie ce qui s'est passé. Tout est en ordre avec l'exactitude de cette fonction, mais cela fonctionne de manière inefficace. Chaque appel push_backcopie inutilement le bloc le plus à gauche: l'appel suivant pousse un autre élément et la copie est répétée à nouveau et les données copiées par la méthode précédente sont supprimées.Vous pouvez essayer une autre implémentation de cette fonction, dans laquelle nous abandonnons la persistance au sein de la fonction. Peut être utilisé transient vectoravec une API mutable compatible avec l'API standard vector. Au sein d'une telle fonction, chaque appel push_backchange la structure des données.vector<int> myiota(vector<int> v, int first, int last)
{
auto t = v.transient();
for (auto i = first; i < last; ++i)
t.push_back(i);
return t.persistent();
}
Cette implémentation est plus efficace et vous permet de réutiliser de nouveaux éléments sur le bon chemin. À la fin de la fonction, un appel .persistent()est effectué qui renvoie immuable vector. Les effets secondaires possibles restent invisibles de l'extérieur de la fonction. L'original vectorétait et reste immuable, seules les données créées à l'intérieur de la fonction sont modifiées. Comme je l'ai dit, un avantage important de cette approche est que vous pouvez utiliser std::back_inserterdes algorithmes standard qui nécessitent des API mutables.Prenons un autre exemple.vector<char> say_hi(vector<char> v)
{
return v.push_back('h')
.push_back('i')
.push_back('!');
}
La fonction n'accepte pas et retourne vector, mais une chaîne d'appel est exécutée à l'intérieur push_back. Ici, comme dans l'exemple précédent, une copie inutile à l'intérieur de l'appel peut se produire push_back. Notez que la première valeur qui est exécutée push_backest la valeur nommée et le reste est une valeur r, c'est-à-dire des liens anonymes. Si vous utilisez le comptage de références, la méthode push_backpeut faire référence à des compteurs de référence pour les nœuds auxquels la mémoire est allouée dans l'arborescence. Et dans le cas de la valeur r, si le nombre de liens est un, il devient clair qu'aucune autre partie du programme n'accède à ces nœuds. Ici, les performances sont exactement les mêmes que dans le cas avec transient.vector<char> say_hi(vector<char> v)
{
return v.push_back('h') ⟵ named value: v
.push_back('i') ⟵ r-value value
.push_back('!'); ⟵ r-value value
}
De plus, pour aider le compilateur, nous pouvons l'exécuter move(v), car il vn'est utilisé nulle part ailleurs dans la fonction. Nous avions un avantage important, qui n'était pas dans la transientvariante: si nous transmettons la valeur retournée d'un autre say_hi à la fonction say_hi, alors il n'y aura pas de copies supplémentaires. Dans le cas de c, transientil existe des limites auxquelles une copie excessive peut se produire. En d'autres termes, nous avons une structure de données persistante et immuable, dont les performances dépendent de la quantité réelle d'accès partagé lors de l'exécution. S'il n'y a pas de partage, les performances seront les mêmes que celles d'une structure de données mutable. Il s'agit d'une propriété extrêmement importante. L'exemple que je vous ai déjà montré ci-dessus peut être réécrit avec une méthode move(v).vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = std::move(v).push_back(i);
return v;
}
Jusqu'à présent, nous avons parlé de vecteurs, et en plus d'eux, il y a aussi des cartes de hachage. Ils sont dédiés à un rapport très utile de Phil Nash: Le Saint Graal. Un tri mappé de tableau de hachage pour C ++ . Il décrit des tables de hachage implémentées sur la base des mêmes principes que je viens de parler.Je suis sûr que beaucoup d'entre vous ont des doutes sur les performances de ces structures. Fonctionnent-ils rapidement dans la pratique? J'ai fait de nombreux tests, et en bref ma réponse est oui. Si vous voulez en savoir plus sur les résultats des tests, ils sont publiés dans mon article pour la Conférence internationale de programmation fonctionnelle 2017. Maintenant, je pense qu'il vaut mieux discuter non pas de valeurs absolues, mais de l'effet que cette structure de données a sur le système dans son ensemble. Bien sûr, la mise à jour de notre vecteur est plus lente car vous devez copier plusieurs blocs de données et allouer de la mémoire pour d'autres données. Mais le contournement de notre vecteur s'effectue presque à la même vitesse qu'un vecteur normal. Il était très important pour moi d'y parvenir, car la lecture des données est effectuée beaucoup plus souvent que leur modification.De plus, en raison de la mise à jour plus lente, il n'est pas nécessaire de copier quoi que ce soit, seule la structure des données est copiée. Par conséquent, le temps consacré à la mise à jour du vecteur est, pour ainsi dire, amorti pour toutes les copies effectuées dans le système. Par conséquent, si vous appliquez cette structure de données dans une architecture similaire à celle que j'ai décrite au début du rapport, les performances augmenteront considérablement.Ewig
Je ne serai pas infondé et démontrerai ma structure de données à l'aide d'un exemple. J'ai écrit un petit éditeur de texte. Il s'agit d'un outil interactif appelé ewig , dans lequel les documents sont représentés par des vecteurs immuables. J'ai une copie de la totalité de la Wikipédia en espéranto sur mon disque, elle pèse 1 gigaoctet (au début, je voulais télécharger la version anglaise, mais elle est trop grande). Quel que soit l'éditeur de texte que vous utilisez, je suis sûr qu'il n'aimera pas ce fichier. Et lorsque vous téléchargez ce fichier dans ewig , vous pouvez immédiatement le modifier, car le téléchargement est asynchrone. La navigation dans les fichiers fonctionne, rien ne se bloque, non mutex, pas de synchronisation. Comme vous pouvez le voir, le fichier téléchargé prend 20 millions de lignes de code.Avant de considérer les propriétés les plus importantes de cet outil, prêtons attention à un détail amusant. Au début de la ligne, surlignée en blanc au bas de l'image, vous voyez deux tirets. Cette interface utilisateur est probablement familière aux utilisateurs d'emacs; les traits d'union signifient que le document n'a été modifié d'aucune façon. Si vous apportez des modifications, des astérisques s'affichent à la place des tirets. Mais, contrairement à d'autres éditeurs, si vous supprimez ces modifications dans ewig (ne les annulez pas, supprimez-les simplement), les traits d'union réapparaîtront à la place des astérisques, car toutes les versions précédentes du texte sont enregistrées dans ewig . Grâce à cela, un indicateur spécial n'est pas nécessaire pour indiquer si le document a été modifié: la présence de modifications est déterminée par comparaison avec le document d'origine.Considérez une autre propriété intéressante de l'outil: copiez le texte entier et collez-le plusieurs fois au milieu du texte existant. Comme vous pouvez le voir, cela se produit instantanément. La jonction de vecteurs ici est une opération logarithmique, et le logarithme de plusieurs millions n'est pas une opération aussi longue. Si vous essayez d'enregistrer cet énorme document sur votre disque dur, cela prendra beaucoup plus de temps, car le texte n'est plus présenté comme un vecteur obtenu à partir de la version précédente de ce vecteur. Lors de l'enregistrement sur le disque, la sérialisation se produit, donc la persistance est perdue.
Au début de la ligne, surlignée en blanc au bas de l'image, vous voyez deux tirets. Cette interface utilisateur est probablement familière aux utilisateurs d'emacs; les traits d'union signifient que le document n'a été modifié d'aucune façon. Si vous apportez des modifications, des astérisques s'affichent à la place des tirets. Mais, contrairement à d'autres éditeurs, si vous supprimez ces modifications dans ewig (ne les annulez pas, supprimez-les simplement), les traits d'union réapparaîtront à la place des astérisques, car toutes les versions précédentes du texte sont enregistrées dans ewig . Grâce à cela, un indicateur spécial n'est pas nécessaire pour indiquer si le document a été modifié: la présence de modifications est déterminée par comparaison avec le document d'origine.Considérez une autre propriété intéressante de l'outil: copiez le texte entier et collez-le plusieurs fois au milieu du texte existant. Comme vous pouvez le voir, cela se produit instantanément. La jonction de vecteurs ici est une opération logarithmique, et le logarithme de plusieurs millions n'est pas une opération aussi longue. Si vous essayez d'enregistrer cet énorme document sur votre disque dur, cela prendra beaucoup plus de temps, car le texte n'est plus présenté comme un vecteur obtenu à partir de la version précédente de ce vecteur. Lors de l'enregistrement sur le disque, la sérialisation se produit, donc la persistance est perdue.Retour à une architecture basée sur la valeur
 Commençons par la façon dont vous ne pouvez pas revenir à cette architecture: en utilisant le contrôleur, le modèle et la vue de style Java habituels, qui sont le plus souvent utilisés pour les applications interactives en C ++. Il n'y a rien de mal avec eux, mais ils ne conviennent pas à notre problème. D'une part, le modèle Model-View-Controller permet la séparation des tâches, mais d'autre part, chacun de ces éléments est un objet, à la fois d'un point de vue orienté objet et du point de vue de C ++, c'est-à-dire que ce sont des zones de mémoire avec mutable état. View connaît Model; ce qui est bien pire - le modèle connaît indirectement la vue, car il y a presque certainement un rappel par lequel la vue est notifiée lorsque le modèle change. Même avec la meilleure implémentation de principes orientés objet, nous obtenons beaucoup de dépendances mutuelles.
Commençons par la façon dont vous ne pouvez pas revenir à cette architecture: en utilisant le contrôleur, le modèle et la vue de style Java habituels, qui sont le plus souvent utilisés pour les applications interactives en C ++. Il n'y a rien de mal avec eux, mais ils ne conviennent pas à notre problème. D'une part, le modèle Model-View-Controller permet la séparation des tâches, mais d'autre part, chacun de ces éléments est un objet, à la fois d'un point de vue orienté objet et du point de vue de C ++, c'est-à-dire que ce sont des zones de mémoire avec mutable état. View connaît Model; ce qui est bien pire - le modèle connaît indirectement la vue, car il y a presque certainement un rappel par lequel la vue est notifiée lorsque le modèle change. Même avec la meilleure implémentation de principes orientés objet, nous obtenons beaucoup de dépendances mutuelles.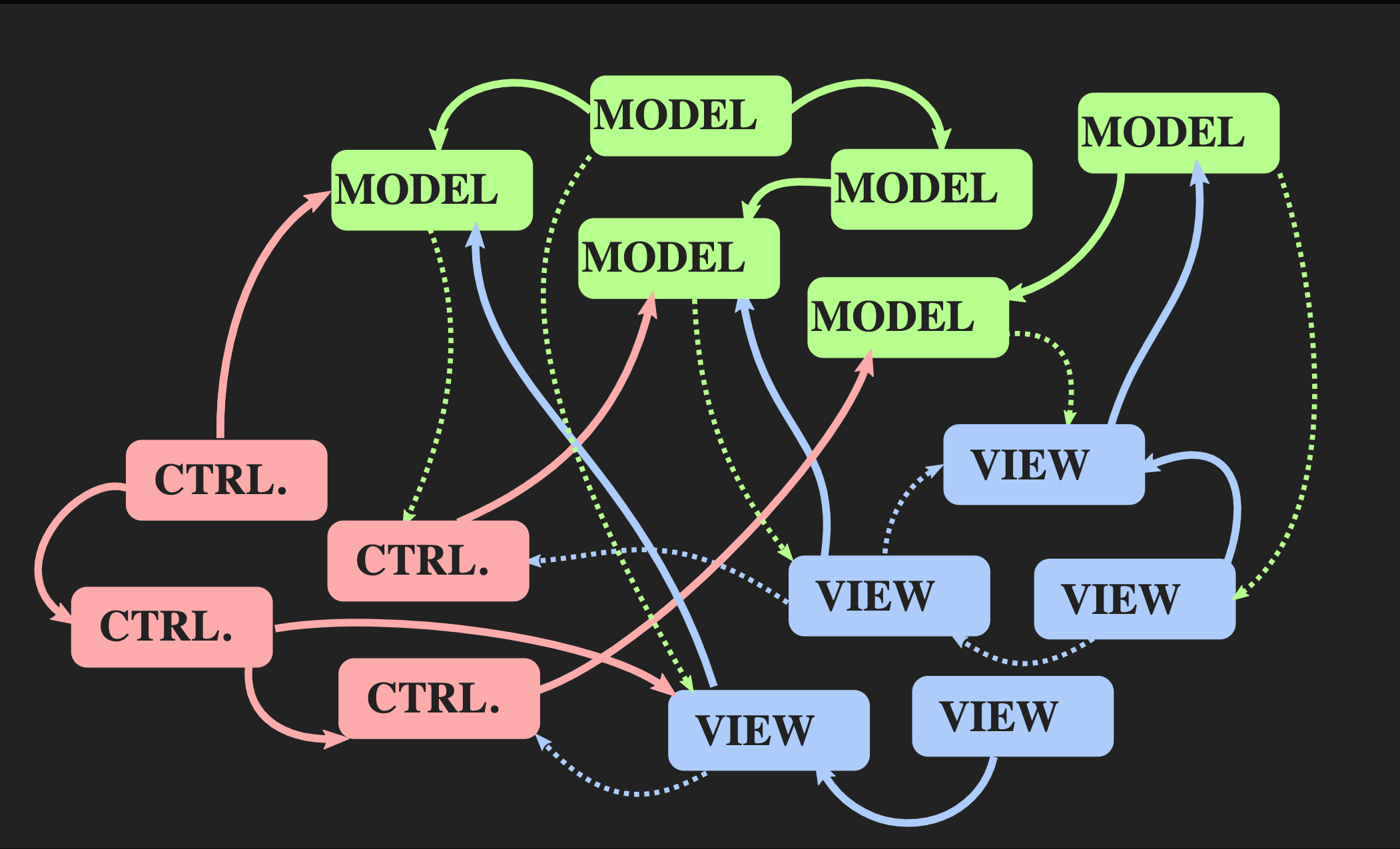 Au fur et à mesure que l'application se développe et que de nouveaux modèles, contrôleurs et vues sont ajoutés, une situation se produit lorsque, pour modifier un segment du programme, vous devez connaître toutes les parties qui lui sont associées, toutes les vues qui reçoivent des alertes
Au fur et à mesure que l'application se développe et que de nouveaux modèles, contrôleurs et vues sont ajoutés, une situation se produit lorsque, pour modifier un segment du programme, vous devez connaître toutes les parties qui lui sont associées, toutes les vues qui reçoivent des alertes callback, etc. En conséquence, tout le monde le monstre familier des pâtes commence à scruter ces dépendances.Une autre architecture est-elle possible? Il existe une approche alternative au modèle Model-View-Controller appelée «Architecture de flux de données unidirectionnelle». Ce concept n'a pas été inventé par moi, il est utilisé assez souvent dans le développement web. Sur Facebook, cela s'appelle l'architecture Flux, mais en C ++, elle n'est pas encore appliquée.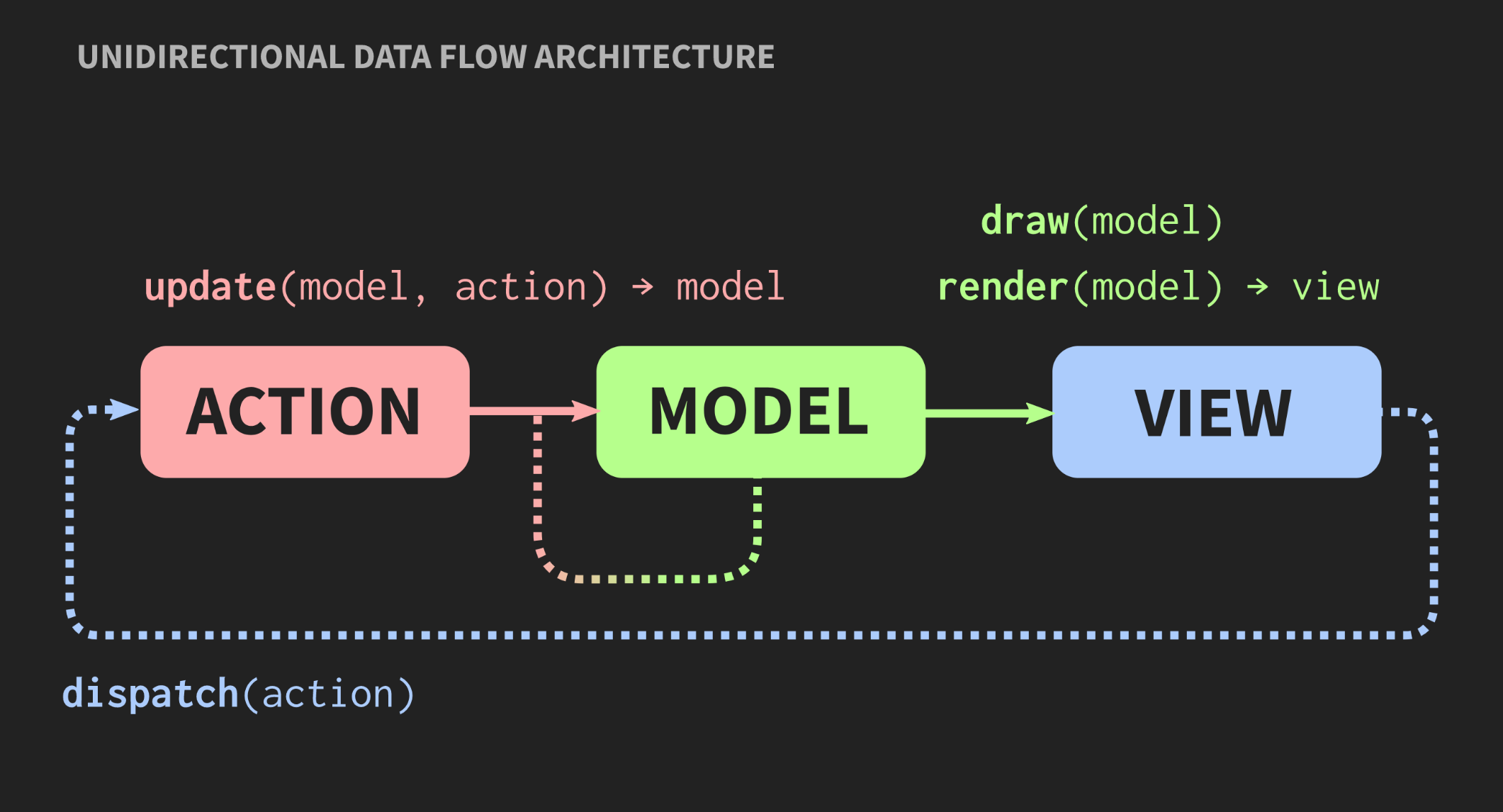 Les éléments d'une telle architecture nous sont déjà familiers: action, modèle et vue, mais la signification des blocs et des flèches est différente. Les blocs sont des valeurs, pas des objets et pas des régions avec des états mutables. Cela s'applique même à View. De plus, les flèches ne sont pas des liens, car sans objets il ne peut y avoir de liens. Ici, les flèches sont des fonctions. Entre Action et Modèle, il existe une fonction de mise à jour qui accepte le Modèle actuel, c'est-à-dire l'état actuel du monde, et Action, qui est une représentation d'un événement, par exemple, un clic de souris, ou un événement d'un autre niveau d'abstraction, par exemple, l'insertion d'un élément ou d'un symbole dans un document. La fonction de mise à jour met à jour le document et renvoie le nouvel état du monde. Le modèle se connecte au rendu de la fonction Vue, qui prend le modèle et renvoie la vue. Cela nécessite un cadre dans lequel View peut être représenté sous forme de valeurs.Dans le développement Web, React fait cela, mais en C ++, il n'y a encore rien de tel, même si qui sait, s'il y a des gens qui veulent me payer pour écrire quelque chose comme ça, cela pourrait bientôt apparaître. En attendant, vous pouvez utiliser l'API en mode immédiat, dans laquelle la fonction de dessin vous permet de créer une valeur comme effet secondaire.Enfin, la vue doit avoir un mécanisme qui permet à l'utilisateur ou à d'autres sources d'événements d'envoyer une action. Il existe un moyen simple de mettre en œuvre cela, il est présenté ci-dessous:
Les éléments d'une telle architecture nous sont déjà familiers: action, modèle et vue, mais la signification des blocs et des flèches est différente. Les blocs sont des valeurs, pas des objets et pas des régions avec des états mutables. Cela s'applique même à View. De plus, les flèches ne sont pas des liens, car sans objets il ne peut y avoir de liens. Ici, les flèches sont des fonctions. Entre Action et Modèle, il existe une fonction de mise à jour qui accepte le Modèle actuel, c'est-à-dire l'état actuel du monde, et Action, qui est une représentation d'un événement, par exemple, un clic de souris, ou un événement d'un autre niveau d'abstraction, par exemple, l'insertion d'un élément ou d'un symbole dans un document. La fonction de mise à jour met à jour le document et renvoie le nouvel état du monde. Le modèle se connecte au rendu de la fonction Vue, qui prend le modèle et renvoie la vue. Cela nécessite un cadre dans lequel View peut être représenté sous forme de valeurs.Dans le développement Web, React fait cela, mais en C ++, il n'y a encore rien de tel, même si qui sait, s'il y a des gens qui veulent me payer pour écrire quelque chose comme ça, cela pourrait bientôt apparaître. En attendant, vous pouvez utiliser l'API en mode immédiat, dans laquelle la fonction de dessin vous permet de créer une valeur comme effet secondaire.Enfin, la vue doit avoir un mécanisme qui permet à l'utilisateur ou à d'autres sources d'événements d'envoyer une action. Il existe un moyen simple de mettre en œuvre cela, il est présenté ci-dessous:application update(application state, action ev);
void run(const char* fname)
{
auto term = terminal{};
auto state = application{load_buffer(fname), key_map_emacs};
while (!state.done) {
draw(state);
auto act = term.next();
state = update(state, act);
}
}
À l'exception de l'enregistrement et du chargement asynchrones, c'est le code utilisé dans l'éditeur qui vient d'être présenté. Il y a un objet ici terminalqui vous permet de lire et d'écrire à partir de la ligne de commande. De plus, applicationc'est la valeur de Model, il stocke tout l'état de l'application. Comme vous pouvez le voir en haut de l'écran, il existe une fonction qui renvoie une nouvelle version application. Le cycle à l'intérieur de la fonction est exécuté jusqu'à ce que l'application doive se fermer, c'est-à-dire jusqu'à ce que !state.done. Dans la boucle, un nouvel état est tracé, puis l'événement suivant est demandé. Enfin, l'état est stocké dans une variable locale stateet la boucle recommence. Ce code présente un avantage très important: une seule variable mutable existe tout au long de l'exécution du programme, c'est un objet state.Les développeurs de Clojure appellent cette architecture à atome unique: il y a un seul point à travers l'application entière à travers lequel toutes les modifications sont apportées. La logique d'application ne participe en aucune façon à la mise à jour de ce point, ce qui en fait un cycle spécialement conçu. Grâce à cela, la logique d'application est entièrement constituée de fonctions pures, comme des fonctions update.Avec cette approche de l'écriture d'applications, la façon de penser les logiciels évolue. Le travail commence maintenant non pas avec le diagramme UML des interfaces et des opérations, mais avec les données elles-mêmes. Il existe certaines similitudes avec la conception orientée données. Certes, la conception orientée données est généralement utilisée pour obtenir des performances maximales, ici, en plus de la vitesse, nous nous efforçons de simplicité et d'exactitude. L'accent est légèrement différent, mais il existe d'importantes similitudes dans la méthodologie.using index = int;
struct coord
{
index row = {};
index col = {};
};
using line = immer::flex_vector<char>;
using text = immer::flex_vector<line>;
struct file
{
immer::box<std::string> name;
text content;
};
struct snapshot
{
text content;
coord cursor;
};
struct buffer
{
file from;
text content;
coord cursor;
coord scroll;
std::optional<coord> selection_start;
immer::vector<snapshot> history;
std::optional<std::size_t> history_pos;
};
struct application
{
buffer current;
key_map keys;
key_seq input;
immer::vector<text> clipboard;
immer::vector<message> messages;
};
struct action { key_code key; coord size; };
Ci-dessus sont les principaux types de données de notre application. Le corps principal de l'application se compose de line, qui est flex_vector, et flex_vector est vectorcelui pour lequel vous pouvez effectuer une opération de jointure. Vient ensuite textle vecteur dans lequel il est stocké line. Comme vous pouvez le voir, il s'agit d'une représentation très simple du texte. Textstocké à l'aide filede qui a un nom, c'est-à-dire une adresse dans le système de fichiers, et en fait text. Comme fileutilisé un autre type, simple mais très utile: box. Il s'agit d'un conteneur à élément unique. Il vous permet de placer un tas et de déplacer un objet, la copie pouvant être trop gourmande en ressources.Un autre type important: snapshot. Sur la base de ce type, une fonction d'annulation est active. Il contient un document (sous la formetext) et la position du curseur (coord). Cela vous permet de ramener le curseur à la position dans laquelle il se trouvait lors de l'édition.Le type suivant est buffer. C'est un terme de vim et emacs, car les documents ouverts y sont appelés. Il buffery a un fichier à partir duquel le texte a été téléchargé, ainsi que le contenu du texte - cela vous permet de vérifier les modifications dans le document. Pour mettre en évidence une partie du texte, une variable facultative selection_startindique le début de la sélection. Le vecteur snapshotest l'histoire du texte. Notez que nous n'utilisons pas le modèle d'équipe; l'historique se compose uniquement d'états. Enfin, si l'annulation vient de se terminer, nous avons besoin d'un indice de position dans l'historique de l'état history_pos.Le type suivant: application. Il contient un document ouvert (tampon), key_mapetkey_seqpour les raccourcis clavier, ainsi qu'un vecteur de textpour le presse-papiers et un autre vecteur pour les messages affichés en bas de l'écran. Jusqu'à présent, dans la première version de l'application, il n'y aura qu'un seul thread et un type d'action qui prend en entrée key_codeet coord.Très probablement, beaucoup d'entre vous réfléchissent déjà à la façon de mettre en œuvre ces opérations. Si elles sont prises par valeur et retournées par valeur, alors dans la plupart des cas, les opérations sont assez simples. Le code de mon éditeur de texte est publié sur github , vous pouvez donc voir à quoi il ressemble réellement. Maintenant, je m'attarderai en détail uniquement sur le code qui implémente la fonction d'annulation.Annuler
Écrire correctement une annulation sans l'infrastructure appropriée n'est pas si simple. Dans mon éditeur, je l'ai implémenté sur le modèle d'emacs, donc d'abord quelques mots sur ses principes de base. La commande de retour manque ici, et grâce à cela, vous ne pouvez pas perdre de travail. Si un retour est nécessaire, toute modification est apportée au texte, puis toutes les actions d'annulation font à nouveau partie de l'historique d'annulation. Ce principe est décrit ci-dessus. Le losange rouge montre ici une position dans l'histoire: si une annulation n'a tout simplement pas été effectuée, le losange rouge est toujours à la toute fin. Si vous annulez, le losange ramènera un état en arrière, mais en même temps, un autre état sera ajouté à la fin de la file d'attente - le même que celui que l'utilisateur voit actuellement (S3). Si vous annulez à nouveau et revenez à l'état S2, l'état S2 est ajouté à la fin de la file d'attente. Si maintenant l'utilisateur fait une sorte de changement, il sera ajouté à la fin de la file d'attente en tant que nouvel état de S5, et un losange y sera déplacé. Désormais, lors de l'annulation des actions passées, les actions d'annulation précédentes défileront en premier. Pour implémenter un tel système d'annulation, le code suivant suffit:
Ce principe est décrit ci-dessus. Le losange rouge montre ici une position dans l'histoire: si une annulation n'a tout simplement pas été effectuée, le losange rouge est toujours à la toute fin. Si vous annulez, le losange ramènera un état en arrière, mais en même temps, un autre état sera ajouté à la fin de la file d'attente - le même que celui que l'utilisateur voit actuellement (S3). Si vous annulez à nouveau et revenez à l'état S2, l'état S2 est ajouté à la fin de la file d'attente. Si maintenant l'utilisateur fait une sorte de changement, il sera ajouté à la fin de la file d'attente en tant que nouvel état de S5, et un losange y sera déplacé. Désormais, lors de l'annulation des actions passées, les actions d'annulation précédentes défileront en premier. Pour implémenter un tel système d'annulation, le code suivant suffit:buffer record(buffer before, buffer after)
{
if (before.content != after.content) {
after.history = after.history.push_back({before.content, before.cursor});
if (before.history_pos == after.history_pos)
after.history_pos = std::nullopt;
}
return after;
}
buffer undo(buffer buf)
{
auto idx = buf.history_pos.value_or(buf.history.size());
if (idx > 0) {
auto restore = buf.history[--idx];
buf.content = restore.content;
buf.cursor = restore.cursor;
buf.history_pos = idx;
}
return buf;
}
Il y a deux actions, recordet undo. Recordeffectué au cours de toute opération. C'est très pratique car nous n'avons pas besoin de savoir si une modification du document a eu lieu. La fonction est transparente pour la logique d'application. Après toute action, la fonction vérifie si le document a changé. Si un changement s'est produit, le push_backcontenu et la position du curseur pour sont exécutés history. Si l'action n'a pas conduit à une modification history_pos(c'est-à-dire que l'entrée reçue n'est bufferpas provoquée par l'action d'annulation), alors history_posune valeur est affectée null. Si nécessaire undo, nous vérifions history_pos. S'il n'a pas de sens, nous le considérons history_posà la fin de l'histoire. Si l'historique d'annulation n'est pas vide (c.-à-d.history_pospas au tout début de l'histoire), l'annulation est effectuée. Le contenu et le curseur actuels sont remplacés et modifiés history_pos. L'irrévocabilité d'une opération d'annulation est obtenue par une fonction recordqui est également appelée pendant l'opération d'annulation.Nous avons donc une opération undoqui prend 10 lignes de code et qui, sans modifications (ou avec des modifications minimes), peut être utilisée dans presque toutes les autres applications.Voyage dans le temps
À propos du voyage dans le temps. Comme nous le verrons maintenant, il s'agit d'un sujet lié à l'annulation. Je vais démontrer le travail d'un framework qui ajoutera des fonctionnalités utiles à toute application avec une architecture similaire. Le cadre ici est appelé ewig-debug . Cette version d' ewig inclut des fonctionnalités de débogage. À partir du navigateur, vous pouvez maintenant ouvrir le débogueur, dans lequel vous pouvez examiner l'état de l'application. Nous voyons que la dernière action a été redimensionnée, car j'ai ouvert une nouvelle fenêtre et mon gestionnaire de fenêtres a automatiquement redimensionné la fenêtre déjà ouverte. Bien sûr, pour la sérialisation automatique en JSON, j'ai dû ajouter une annotation pour struct à partir de la bibliothèque de réflexion spéciale. Mais le reste du système est assez universel, il peut être connecté à n'importe quelle application similaire. Maintenant, dans le navigateur, vous pouvez voir toutes les actions terminées. Bien sûr, il y a un état initial qui n'a aucune action. Il s'agit de l'état qui était avant le téléchargement. De plus, en double-cliquant, je peux ramener l'application à son état précédent. Il s'agit d'un outil de débogage très utile qui vous permet de suivre l'occurrence d'un dysfonctionnement dans l'application.Si vous êtes intéressé, vous pouvez écouter mon rapport sur CPPCON 19, Les valeurs les plus précieuses, là j'examinerai ce débogueur en détail.De plus, l'architecture basée sur les valeurs y est discutée plus en détail. Dans ce document, je vous explique également comment mettre en œuvre des actions et les organiser de manière hiérarchique. Cela garantit la modularité du système et élimine la nécessité de tout garder dans une seule grande fonction de mise à jour. En outre, ce rapport parle de téléchargements de fichiers asynchrones et multithreads. Il existe une autre version de ce rapport dans laquelle une demi-heure de matériel supplémentaire est constituée de structures de données immuables postmodernes.
Nous voyons que la dernière action a été redimensionnée, car j'ai ouvert une nouvelle fenêtre et mon gestionnaire de fenêtres a automatiquement redimensionné la fenêtre déjà ouverte. Bien sûr, pour la sérialisation automatique en JSON, j'ai dû ajouter une annotation pour struct à partir de la bibliothèque de réflexion spéciale. Mais le reste du système est assez universel, il peut être connecté à n'importe quelle application similaire. Maintenant, dans le navigateur, vous pouvez voir toutes les actions terminées. Bien sûr, il y a un état initial qui n'a aucune action. Il s'agit de l'état qui était avant le téléchargement. De plus, en double-cliquant, je peux ramener l'application à son état précédent. Il s'agit d'un outil de débogage très utile qui vous permet de suivre l'occurrence d'un dysfonctionnement dans l'application.Si vous êtes intéressé, vous pouvez écouter mon rapport sur CPPCON 19, Les valeurs les plus précieuses, là j'examinerai ce débogueur en détail.De plus, l'architecture basée sur les valeurs y est discutée plus en détail. Dans ce document, je vous explique également comment mettre en œuvre des actions et les organiser de manière hiérarchique. Cela garantit la modularité du système et élimine la nécessité de tout garder dans une seule grande fonction de mise à jour. En outre, ce rapport parle de téléchargements de fichiers asynchrones et multithreads. Il existe une autre version de ce rapport dans laquelle une demi-heure de matériel supplémentaire est constituée de structures de données immuables postmodernes.Résumer
Je pense qu'il est temps de faire le point. Je vais citer Andy Wingo - c'est un excellent développeur, il a consacré beaucoup de temps à la V8 et aux compilateurs en général, enfin il est engagé dans le support de Guile, implémentant Scheme for GNU. Récemment, il a écrit sur son Twitter: «Pour réaliser une légère accélération du programme, nous mesurons chaque petit changement et ne laissons que ceux qui donnent un résultat positif. Mais nous réalisons vraiment une accélération significative, à l'aveugle, en investissant beaucoup d'efforts, sans avoir 100% de confiance et guidés uniquement par l'intuition. Quelle étrange dichotomie. »Il me semble que les développeurs C ++ réussissent dans le premier genre. Donnez-nous un système fermé, et nous, armés de nos outils, nous en retirerons tout ce qui est possible. Mais dans le deuxième genre, nous n'avons pas l'habitude de travailler. Bien entendu, la deuxième approche est plus risquée et conduit souvent à un gaspillage de gros efforts. D'autre part, en réécrivant complètement un programme, il peut souvent être rendu plus facile et plus rapide. J'espère avoir réussi à vous convaincre d'essayer au moins cette deuxième approche.Juan Puente a pris la parole lors de la conférence C ++ Russia 2019 à Moscou et a parlé des structures de données qui vous permettent de faire des choses intéressantes. Une partie de la magie de ces structures réside dans l'élision de la copie - c'est ce dont Anton Polukhin et Roman Rusyaev parleront lors de la prochaine conférence . Suivez les mises à jour du programme sur le site.