Comprendre le modèle d'apprentissage automatique qui brise CAPTCHA
Bonjour à tous! Ce mois-ci, OTUS recrute un nouveau groupe sur le cours Machine Learning . Selon la tradition établie, à la veille du début du cours, nous partageons avec vous la traduction de matériel intéressant sur le sujet. La vision par ordinateur est l'un des sujets les plus pertinents et les plus recherchés de l'IA [1], cependant, les méthodes actuelles de résolution de problèmes utilisant des réseaux de neurones convolutifs sont sérieusement critiquées en raison du fait que de tels réseaux sont facilement trompés. Pour ne pas être infondé, je vais vous expliquer plusieurs raisons: les réseaux de ce type donnent un résultat incorrect avec une grande confiance pour les images naturelles qui ne contiennent pas de signaux statistiques [2], sur lesquels les réseaux de neurones convolutionnels s'appuient, pour les images qui étaient auparavant correctement classées, mais dans lequel un pixel [3] ou des images avec des objets physiques qui ont été ajoutés à la scène mais n'ont pas eu à changer le résultat de la classification [4] a changé. Le fait est que si nous voulons créer des machines vraiment intelligentes,il nous semble raisonnable d'investir dans l'étude de nouvelles idées.L’une de ces nouvelles idées est l’application par Vicarious du réseau cortical récursif (RCN), qui s’inspire des neurosciences. Ce modèle prétendait être extrêmement efficace pour briser le captcha de texte, provoquant ainsi beaucoup de discussions autour de lui . J'ai donc décidé d'écrire plusieurs articles, chacun expliquant un certain aspect de ce modèle. Dans cet article, nous parlerons de sa structure et de la façon dont la génération d'images présentées dans les matériaux de l'article principal sur RCN [5] est générée.Cet article suppose que vous êtes déjà familier avec les réseaux de neurones convolutionnels, je vais donc en tirer de nombreuses analogies.Pour se préparer à la connaissance des RCN, vous devez comprendre que les RCN sont basés sur l'idée de séparer la forme (esquisse de l'objet) de l'apparence (sa texture) et qu'il s'agit d'un modèle génératif, et non discriminant, afin que nous puissions générer des images en l'utilisant, comme dans un générateur réseaux antagonistes. De plus, une structure hiérarchique parallèle est utilisée, similaire à l'architecture des réseaux de neurones convolutionnels, qui commence par l'étape de détermination de la forme de l'objet cible dans les couches inférieures, puis son apparence est ajoutée sur la couche supérieure. Contrairement aux réseaux de neurones convolutifs, le modèle que nous envisageons repose sur une riche base théorique de modèles graphiques, au lieu de sommes pondérées et de descente de gradient. Examinons maintenant les caractéristiques de la structure RCN.
La vision par ordinateur est l'un des sujets les plus pertinents et les plus recherchés de l'IA [1], cependant, les méthodes actuelles de résolution de problèmes utilisant des réseaux de neurones convolutifs sont sérieusement critiquées en raison du fait que de tels réseaux sont facilement trompés. Pour ne pas être infondé, je vais vous expliquer plusieurs raisons: les réseaux de ce type donnent un résultat incorrect avec une grande confiance pour les images naturelles qui ne contiennent pas de signaux statistiques [2], sur lesquels les réseaux de neurones convolutionnels s'appuient, pour les images qui étaient auparavant correctement classées, mais dans lequel un pixel [3] ou des images avec des objets physiques qui ont été ajoutés à la scène mais n'ont pas eu à changer le résultat de la classification [4] a changé. Le fait est que si nous voulons créer des machines vraiment intelligentes,il nous semble raisonnable d'investir dans l'étude de nouvelles idées.L’une de ces nouvelles idées est l’application par Vicarious du réseau cortical récursif (RCN), qui s’inspire des neurosciences. Ce modèle prétendait être extrêmement efficace pour briser le captcha de texte, provoquant ainsi beaucoup de discussions autour de lui . J'ai donc décidé d'écrire plusieurs articles, chacun expliquant un certain aspect de ce modèle. Dans cet article, nous parlerons de sa structure et de la façon dont la génération d'images présentées dans les matériaux de l'article principal sur RCN [5] est générée.Cet article suppose que vous êtes déjà familier avec les réseaux de neurones convolutionnels, je vais donc en tirer de nombreuses analogies.Pour se préparer à la connaissance des RCN, vous devez comprendre que les RCN sont basés sur l'idée de séparer la forme (esquisse de l'objet) de l'apparence (sa texture) et qu'il s'agit d'un modèle génératif, et non discriminant, afin que nous puissions générer des images en l'utilisant, comme dans un générateur réseaux antagonistes. De plus, une structure hiérarchique parallèle est utilisée, similaire à l'architecture des réseaux de neurones convolutionnels, qui commence par l'étape de détermination de la forme de l'objet cible dans les couches inférieures, puis son apparence est ajoutée sur la couche supérieure. Contrairement aux réseaux de neurones convolutifs, le modèle que nous envisageons repose sur une riche base théorique de modèles graphiques, au lieu de sommes pondérées et de descente de gradient. Examinons maintenant les caractéristiques de la structure RCN.Couches d'entités
Le premier type de couche dans RCN est appelé la couche d'entités. Nous considérerons le modèle progressivement, supposons donc pour l'instant que toute la hiérarchie du modèle se compose uniquement de couches de ce type empilées les unes sur les autres. Nous passerons de concepts abstraits de haut niveau à des fonctionnalités plus spécifiques des couches inférieures, comme le montre la figure 1 . Une couche de ce type se compose de plusieurs nœuds situés dans un espace bidimensionnel, de la même manière que les cartes caractéristiques des réseaux de neurones convolutifs. Figure 1 : plusieurs couches d'entités situées l'une au-dessus de l'autre avec des nœuds dans un espace à deux dimensions. La transition de la quatrième à la première couche signifie la transition du général au particulier.Chaque nœud se compose de plusieurs canaux, chacun représentant une caractéristique distincte. Les canaux sont des variables binaires qui prennent la valeur True ou False, indiquant si un objet correspondant à ce canal existe dans l'image générée finale dans les coordonnées (x, y) du nœud. À tous les niveaux, les nœuds ont le même type de canaux.Par exemple, prenons une couche intermédiaire et parlons de ses canaux et des couches ci-dessus pour simplifier l'explication. La liste des canaux sur cette couche sera une hyperbole, un cercle et une parabole. Sur un certain parcours lors de la génération d'image, les calculs des couches sus-jacentes ont nécessité un cercle dans la coordonnée (1,1). Ainsi, le nœud (1, 1) aura un canal correspondant à l'objet «cercle» dans la valeur True. Cela affectera directement certains nœuds de la couche inférieure, c'est-à-dire que les entités de niveau inférieur associées au cercle dans le voisinage (1,1) seront définies sur True. Ces objets de niveau inférieur peuvent être, par exemple, quatre arcs d'orientations différentes. Lorsque les fonctionnalités de la couche inférieure sont activées, elles activent les canaux sur les couches encore plus bas jusqu'à ce que la dernière couche soit atteinte,génération d'images. La visualisation de l'activation est indiquée dansGraphique 2 .Vous pouvez demander, comment deviendra-t-il clair que la représentation d'un cercle est de 4 arcs? Et comment RCN sait-elle qu'elle a besoin d'un canal pour représenter le cercle? Des canaux et leurs liaisons avec d'autres couches seront formés au stade de la formation de la MRC.
Figure 1 : plusieurs couches d'entités situées l'une au-dessus de l'autre avec des nœuds dans un espace à deux dimensions. La transition de la quatrième à la première couche signifie la transition du général au particulier.Chaque nœud se compose de plusieurs canaux, chacun représentant une caractéristique distincte. Les canaux sont des variables binaires qui prennent la valeur True ou False, indiquant si un objet correspondant à ce canal existe dans l'image générée finale dans les coordonnées (x, y) du nœud. À tous les niveaux, les nœuds ont le même type de canaux.Par exemple, prenons une couche intermédiaire et parlons de ses canaux et des couches ci-dessus pour simplifier l'explication. La liste des canaux sur cette couche sera une hyperbole, un cercle et une parabole. Sur un certain parcours lors de la génération d'image, les calculs des couches sus-jacentes ont nécessité un cercle dans la coordonnée (1,1). Ainsi, le nœud (1, 1) aura un canal correspondant à l'objet «cercle» dans la valeur True. Cela affectera directement certains nœuds de la couche inférieure, c'est-à-dire que les entités de niveau inférieur associées au cercle dans le voisinage (1,1) seront définies sur True. Ces objets de niveau inférieur peuvent être, par exemple, quatre arcs d'orientations différentes. Lorsque les fonctionnalités de la couche inférieure sont activées, elles activent les canaux sur les couches encore plus bas jusqu'à ce que la dernière couche soit atteinte,génération d'images. La visualisation de l'activation est indiquée dansGraphique 2 .Vous pouvez demander, comment deviendra-t-il clair que la représentation d'un cercle est de 4 arcs? Et comment RCN sait-elle qu'elle a besoin d'un canal pour représenter le cercle? Des canaux et leurs liaisons avec d'autres couches seront formés au stade de la formation de la MRC.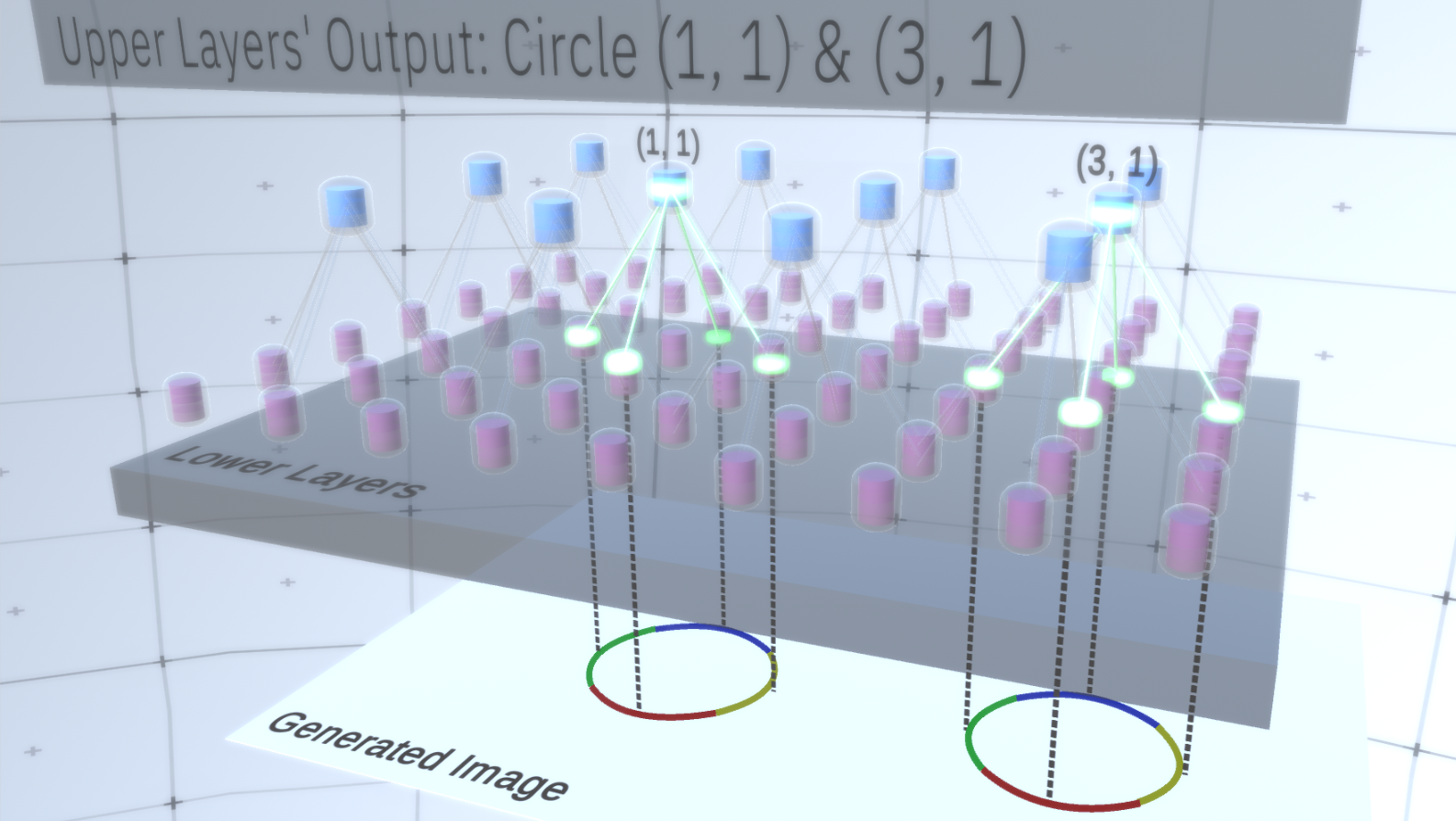 Figure 2: Flux d'informations dans les couches d'entités. Les nœuds de signes sont des capsules contenant des disques représentant des canaux. Certaines des couches supérieures et inférieures ont été présentées sous la forme d'un parallélépipède à des fins de simplification, cependant, en réalité, elles sont également constituées de nœuds caractéristiques en tant que couches intermédiaires. Veuillez noter que la couche intermédiaire supérieure se compose de 3 canaux et la deuxième couche se compose de 4 canaux.Vous pouvez indiquer une méthode très rigide et déterministe pour générer le modèle adopté, mais pour les personnes, les petites perturbations de la courbure du cercle sont toujours considérées comme un cercle, comme vous pouvez le voir sur la figure 3 .
Figure 2: Flux d'informations dans les couches d'entités. Les nœuds de signes sont des capsules contenant des disques représentant des canaux. Certaines des couches supérieures et inférieures ont été présentées sous la forme d'un parallélépipède à des fins de simplification, cependant, en réalité, elles sont également constituées de nœuds caractéristiques en tant que couches intermédiaires. Veuillez noter que la couche intermédiaire supérieure se compose de 3 canaux et la deuxième couche se compose de 4 canaux.Vous pouvez indiquer une méthode très rigide et déterministe pour générer le modèle adopté, mais pour les personnes, les petites perturbations de la courbure du cercle sont toujours considérées comme un cercle, comme vous pouvez le voir sur la figure 3 .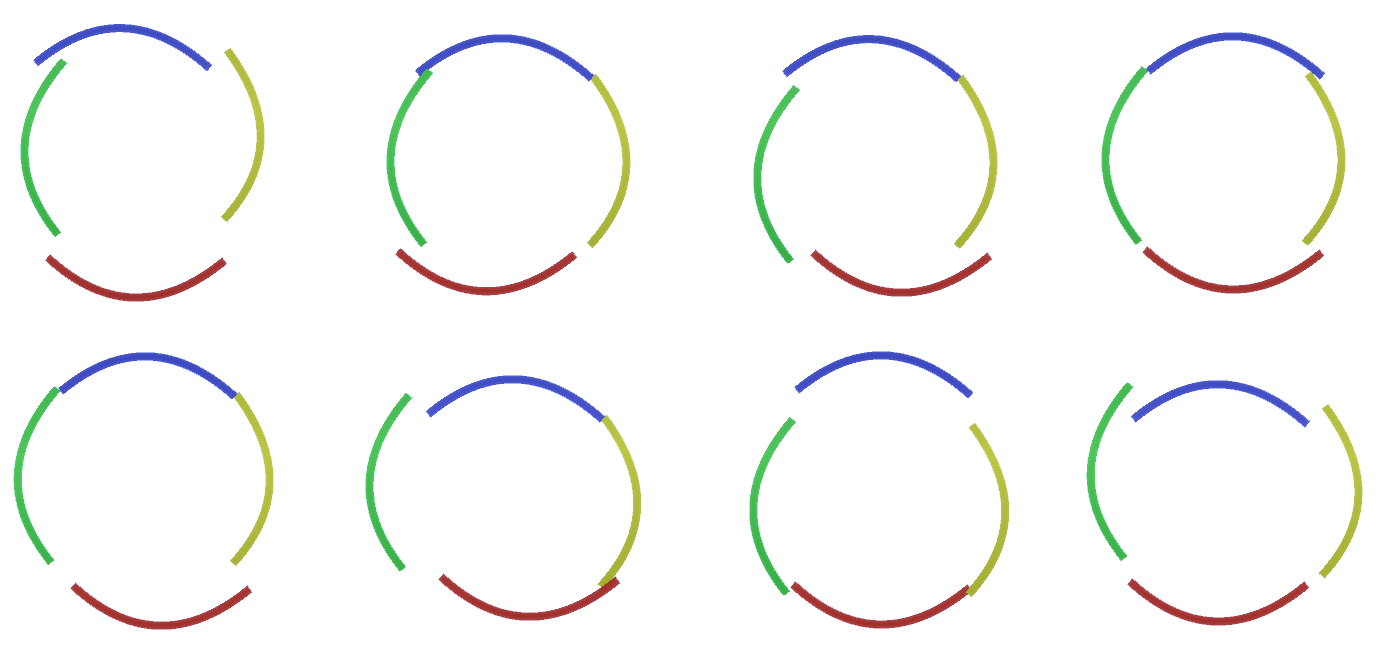 Figure 3: De nombreuses variantes de la construction d'un cercle de quatre arcs courbes de la figure 2.Il serait difficile de considérer chacune de ces variations comme un nouveau canal distinct dans la couche. De même, le regroupement des variations dans la même entité facilitera grandement la généralisation en nouvelles variations lorsque nous adapterons RCN à la classification au lieu de la génération un peu plus tard. Mais comment changer la MRC pour profiter de cette opportunité?
Figure 3: De nombreuses variantes de la construction d'un cercle de quatre arcs courbes de la figure 2.Il serait difficile de considérer chacune de ces variations comme un nouveau canal distinct dans la couche. De même, le regroupement des variations dans la même entité facilitera grandement la généralisation en nouvelles variations lorsque nous adapterons RCN à la classification au lieu de la génération un peu plus tard. Mais comment changer la MRC pour profiter de cette opportunité?Sous-échantillonnage des couches
Pour ce faire, vous avez besoin d'un nouveau type de couche - la couche de regroupement. Il est situé entre deux couches de signes et sert d'intermédiaire entre elles. Il se compose également de canaux, mais ils ont des valeurs entières, pas binaires.Pour illustrer le fonctionnement de ces calques, revenons à l'exemple du cercle. Au lieu d'exiger 4 arcs avec des coordonnées fixes de la couche d'entités au-dessus de celle-ci en tant que caractéristique d'un cercle, la recherche sera effectuée sur la couche de sous-échantillons. Ensuite, chaque canal activé dans la couche de sous-échantillon sélectionnera un nœud sur la couche sous-jacente à son voisinage pour permettre une légère distorsion de l'entité. Ainsi, si nous établissons une communication avec 9 nœuds directement en dessous du nœud de sous-échantillon, le canal de sous-échantillon, chaque fois qu'il est activé, sélectionnera uniformément l'un de ces 9 nœuds et l'activera, et l'indice du nœud sélectionné sera l'état du canal de sous-échantillon - un entier. Dans la figure 4vous pouvez voir plusieurs exécutions, où chaque exécution utilise un ensemble différent de nœuds de niveau inférieur, respectivement, vous permettant de créer un cercle de différentes manières. Figure 4: Fonctionnement des couches de sous-échantillonnage. Chaque image de cette image GIF est un lancement distinct. Les nœuds de sous-échantillonnage sont cubés. Dans cette image, les nœuds de sous-échantillon ont 4 canaux équivalents à 4 canaux de la couche d'entités en dessous. Les couches supérieures et inférieures ont été complètement supprimées de l'image.Malgré le fait que nous avions besoin de la variabilité de notre modèle, il serait préférable qu'il reste plus restreint et ciblé. Dans les deux figures précédentes, certains cercles semblent trop étranges pour vraiment les interpréter comme des cercles en raison du fait que les arcs ne sont pas interconnectés, comme le montre la figure 5. Nous aimerions éviter de les générer. Ainsi, si nous pouvions ajouter un mécanisme de sous-échantillonnage des canaux pour coordonner la sélection des nœuds d'entités et se concentrer sur les formes continues, notre modèle serait plus précis.
Figure 4: Fonctionnement des couches de sous-échantillonnage. Chaque image de cette image GIF est un lancement distinct. Les nœuds de sous-échantillonnage sont cubés. Dans cette image, les nœuds de sous-échantillon ont 4 canaux équivalents à 4 canaux de la couche d'entités en dessous. Les couches supérieures et inférieures ont été complètement supprimées de l'image.Malgré le fait que nous avions besoin de la variabilité de notre modèle, il serait préférable qu'il reste plus restreint et ciblé. Dans les deux figures précédentes, certains cercles semblent trop étranges pour vraiment les interpréter comme des cercles en raison du fait que les arcs ne sont pas interconnectés, comme le montre la figure 5. Nous aimerions éviter de les générer. Ainsi, si nous pouvions ajouter un mécanisme de sous-échantillonnage des canaux pour coordonner la sélection des nœuds d'entités et se concentrer sur les formes continues, notre modèle serait plus précis. Figure 5: Nombreuses options pour construire un cercle. Ces options que nous voulons supprimer sont marquées de croix rouges.Les auteurs du RCN ont utilisé la connexion latérale dans les couches de sous-échantillonnage à cette fin. Essentiellement, les canaux de sous-échantillonnage auront des liens avec d'autres canaux de sous-échantillonnage de l'environnement immédiat, et ces liens ne permettront pas à certaines paires d'états de coexister dans deux canaux simultanément. En fait, la zone d'échantillonnage de ces deux canaux sera simplement limitée. Dans diverses versions du cercle, ces connexions, par exemple, ne permettront pas à deux arcs adjacents de s'éloigner l'un de l'autre. Ce mécanisme est illustré à la figure 6.. Encore une fois, ces relations sont établies au stade de la formation. Il convient de noter que les réseaux neuronaux artificiels modernes de vanille n'ont pas de connexions latérales dans leurs couches, bien qu'ils existent dans les réseaux neuronaux biologiques et on suppose qu'ils jouent un rôle dans l'intégration des contours dans le cortex visuel (mais, franchement, le cortex visuel a un appareil plus complexe que cela ne pourrait paraître dans la déclaration précédente).
Figure 5: Nombreuses options pour construire un cercle. Ces options que nous voulons supprimer sont marquées de croix rouges.Les auteurs du RCN ont utilisé la connexion latérale dans les couches de sous-échantillonnage à cette fin. Essentiellement, les canaux de sous-échantillonnage auront des liens avec d'autres canaux de sous-échantillonnage de l'environnement immédiat, et ces liens ne permettront pas à certaines paires d'états de coexister dans deux canaux simultanément. En fait, la zone d'échantillonnage de ces deux canaux sera simplement limitée. Dans diverses versions du cercle, ces connexions, par exemple, ne permettront pas à deux arcs adjacents de s'éloigner l'un de l'autre. Ce mécanisme est illustré à la figure 6.. Encore une fois, ces relations sont établies au stade de la formation. Il convient de noter que les réseaux neuronaux artificiels modernes de vanille n'ont pas de connexions latérales dans leurs couches, bien qu'ils existent dans les réseaux neuronaux biologiques et on suppose qu'ils jouent un rôle dans l'intégration des contours dans le cortex visuel (mais, franchement, le cortex visuel a un appareil plus complexe que cela ne pourrait paraître dans la déclaration précédente).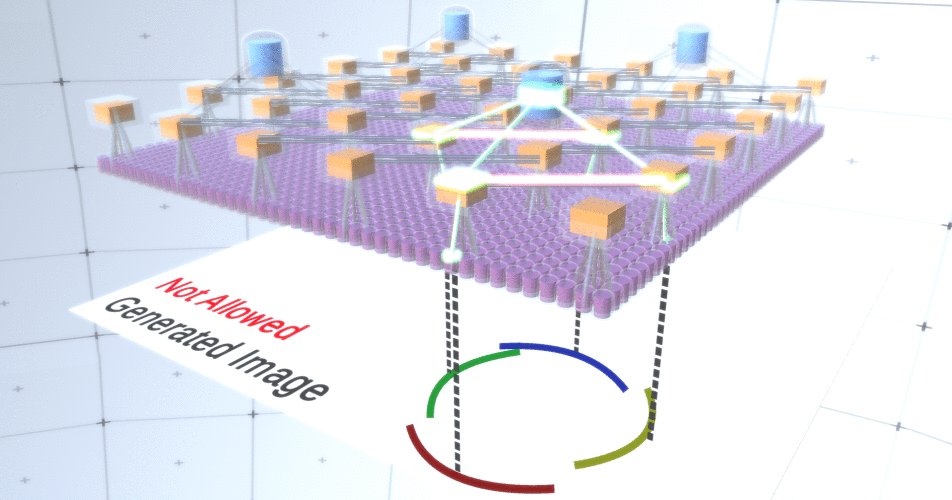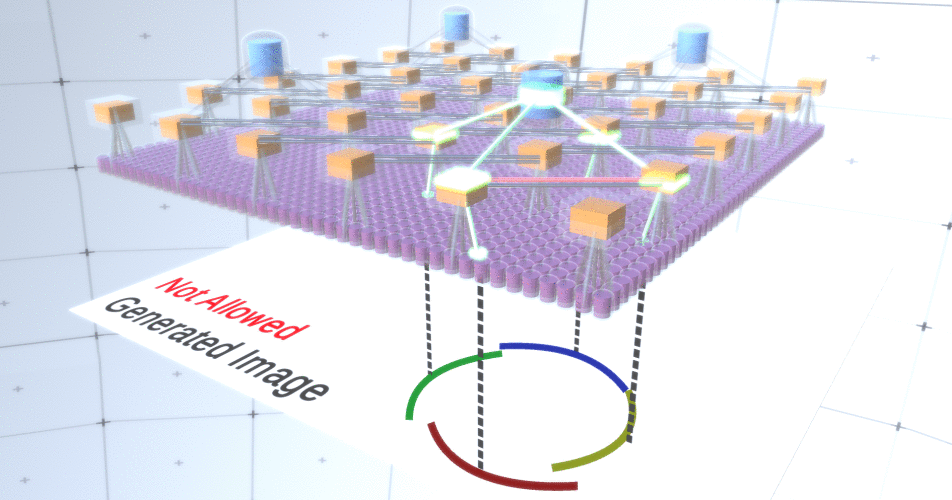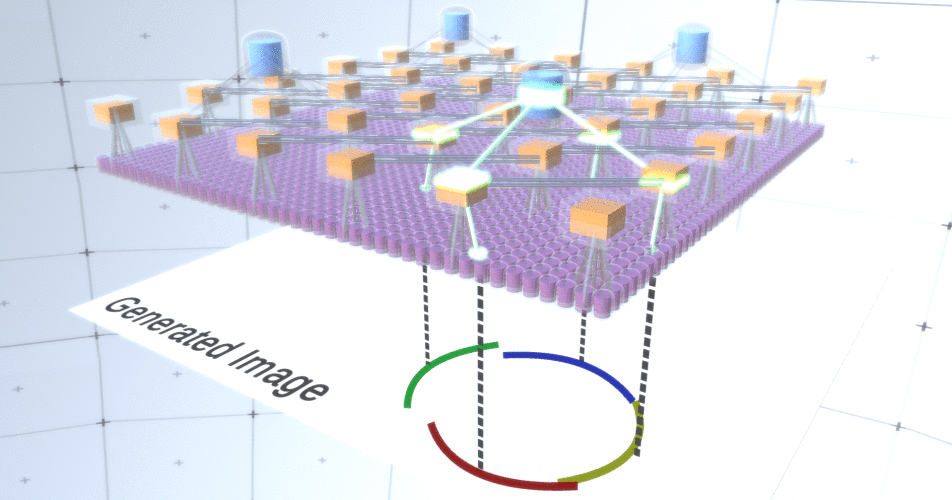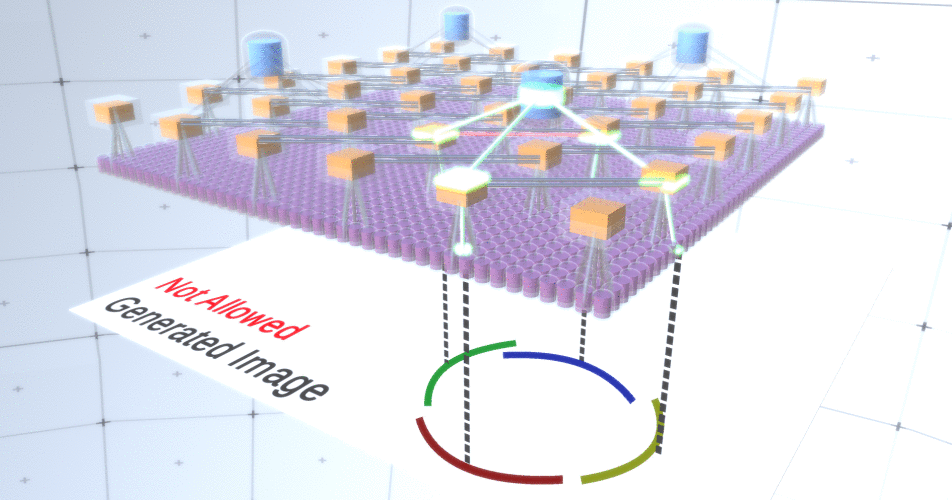 Figure 6: GIF- RCN . , . , RCN , , . .Jusqu'à présent, nous avons parlé de couches intermédiaires de RCN, nous n'avons que la couche la plus haute et la couche la plus basse qui interagissent avec les pixels de l'image générée. La couche supérieure est une couche d'entités régulière, où les canaux de chaque nœud seront des classes de notre ensemble de données étiqueté. Lors de la génération, nous sélectionnons simplement l'emplacement et la classe que nous voulons créer, allons au nœud avec l'emplacement spécifié et disons qu'il active le canal de la classe que nous avons sélectionnée. Cela active certains des canaux de la couche de sous-échantillons en dessous, puis la couche d'entités en dessous, et ainsi de suite, jusqu'à ce que nous atteignions la dernière couche d'entités. Sur la base de votre connaissance des réseaux de neurones convolutifs, vous devriez penser que la couche supérieure aura un seul nœud, mais ce n'est pas le cas, et c'est l'un des avantages du RCN,mais une discussion de ce sujet dépasse le cadre de cet article.La dernière couche d'entités sera unique. Rappelez-vous, j'ai parlé de la façon dont les MRC séparent la forme de l'apparence? C'est cette couche qui sera chargée d'obtenir la forme de l'objet généré. Ainsi, cette couche devrait fonctionner avec des caractéristiques de très bas niveau, les blocs de construction les plus élémentaires de toute forme, ce qui nous aidera à générer la forme souhaitée. Les petites bordures tournant sous différents angles conviennent parfaitement, et ce sont précisément elles que les auteurs de la technologie utilisent.Les auteurs ont sélectionné les attributs du dernier niveau pour représenter une fenêtre 3x3 qui a une bordure avec un certain angle de rotation, qu'ils appellent un descripteur de patch. Le nombre d'angles de rotation qu'ils ont choisi est 16. De plus, pour pouvoir ajouter une apparence plus tard, vous avez besoin de deux orientations pour chaque rotation afin de pouvoir dire si l'arrière-plan est à gauche ou à droite, s'il s'agit de bordures extérieures et une orientation supplémentaire dans le cas de limites internes (c'est-à-dire à l'intérieur de l'objet). La figure 7 montre les caractéristiques du dernier assemblage de couches et la figure 8 montre comment les descripteurs des correctifs peuvent générer une certaine forme.
Figure 6: GIF- RCN . , . , RCN , , . .Jusqu'à présent, nous avons parlé de couches intermédiaires de RCN, nous n'avons que la couche la plus haute et la couche la plus basse qui interagissent avec les pixels de l'image générée. La couche supérieure est une couche d'entités régulière, où les canaux de chaque nœud seront des classes de notre ensemble de données étiqueté. Lors de la génération, nous sélectionnons simplement l'emplacement et la classe que nous voulons créer, allons au nœud avec l'emplacement spécifié et disons qu'il active le canal de la classe que nous avons sélectionnée. Cela active certains des canaux de la couche de sous-échantillons en dessous, puis la couche d'entités en dessous, et ainsi de suite, jusqu'à ce que nous atteignions la dernière couche d'entités. Sur la base de votre connaissance des réseaux de neurones convolutifs, vous devriez penser que la couche supérieure aura un seul nœud, mais ce n'est pas le cas, et c'est l'un des avantages du RCN,mais une discussion de ce sujet dépasse le cadre de cet article.La dernière couche d'entités sera unique. Rappelez-vous, j'ai parlé de la façon dont les MRC séparent la forme de l'apparence? C'est cette couche qui sera chargée d'obtenir la forme de l'objet généré. Ainsi, cette couche devrait fonctionner avec des caractéristiques de très bas niveau, les blocs de construction les plus élémentaires de toute forme, ce qui nous aidera à générer la forme souhaitée. Les petites bordures tournant sous différents angles conviennent parfaitement, et ce sont précisément elles que les auteurs de la technologie utilisent.Les auteurs ont sélectionné les attributs du dernier niveau pour représenter une fenêtre 3x3 qui a une bordure avec un certain angle de rotation, qu'ils appellent un descripteur de patch. Le nombre d'angles de rotation qu'ils ont choisi est 16. De plus, pour pouvoir ajouter une apparence plus tard, vous avez besoin de deux orientations pour chaque rotation afin de pouvoir dire si l'arrière-plan est à gauche ou à droite, s'il s'agit de bordures extérieures et une orientation supplémentaire dans le cas de limites internes (c'est-à-dire à l'intérieur de l'objet). La figure 7 montre les caractéristiques du dernier assemblage de couches et la figure 8 montre comment les descripteurs des correctifs peuvent générer une certaine forme.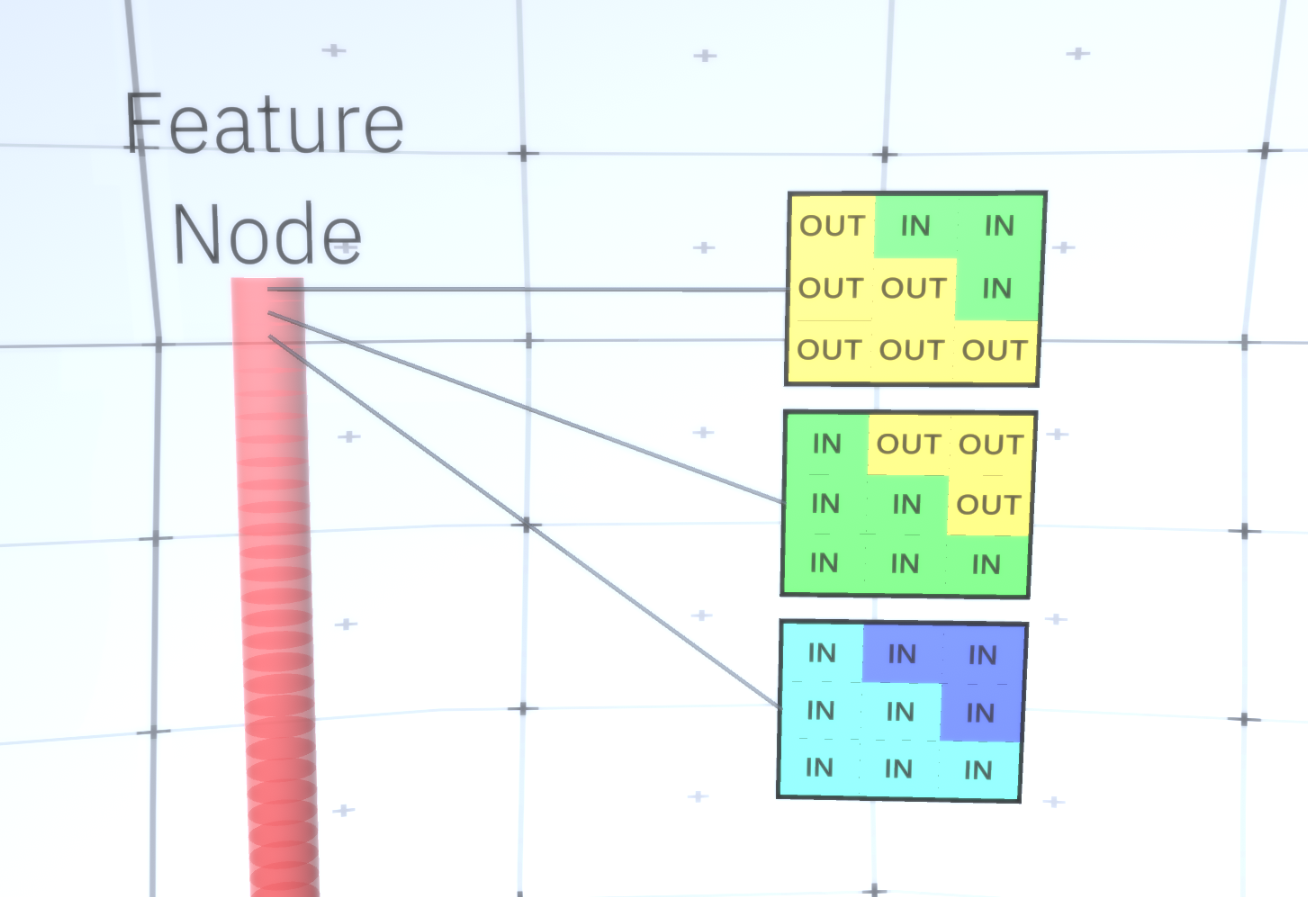 Figure 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — .
Figure 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — . 8: «i» .Maintenant que nous avons atteint la dernière couche de signes, nous avons un diagramme sur lequel les limites de l'objet sont déterminées et la compréhension de savoir si la zone est en dehors de la frontière est interne ou externe. Il reste à ajouter une apparence, désignant chaque zone restante de l'image comme IN ou OUT et peindre sur la zone. Un champ aléatoire conditionnel peut aider ici. Sans entrer dans les détails mathématiques, nous attribuons simplement à chaque pixel de l'image finale une distribution de probabilité par couleur et état (IN ou OUT). Cette distribution reflétera les informations obtenues à partir de la bordure de la carte. Par exemple, s'il y a deux pixels adjacents, dont l'un est IN et l'autre OUT, la probabilité qu'ils aient une couleur différente augmente considérablement. Si deux pixels adjacents se trouvent sur des côtés opposés de la bordure intérieure, la probabilitéqui aura une couleur différente augmentera également. Si les pixels se trouvent à l'intérieur de la bordure et ne sont séparés par rien, la probabilité qu'ils aient la même couleur augmente, mais les pixels externes peuvent avoir une légère déviation les uns des autres, etc. Pour obtenir l'image finale, il vous suffit de faire une sélection à partir de la distribution de probabilité conjointe que nous venons d'installer. Pour rendre l'image générée plus intéressante, nous pouvons remplacer les couleurs par la texture. Nous ne discuterons pas de cette couche car RCN peut effectuer la classification sans être basé sur l'apparence.Pour obtenir l'image finale, il vous suffit de faire une sélection à partir de la distribution de probabilité conjointe que nous venons d'installer. Pour rendre l'image générée plus intéressante, nous pouvons remplacer les couleurs par la texture. Nous ne discuterons pas de cette couche car RCN peut effectuer la classification sans être basé sur l'apparence.Pour obtenir l'image finale, il vous suffit de faire une sélection à partir de la distribution de probabilité conjointe que nous venons d'installer. Pour rendre l'image générée plus intéressante, nous pouvons remplacer les couleurs par la texture. Nous ne discuterons pas de cette couche car RCN peut effectuer la classification sans être basé sur l'apparence.Eh bien, nous terminerons ici pour aujourd'hui. Si vous voulez en savoir plus sur RCN, lisez cet article [5] et l'annexe avec des documents supplémentaires, ou vous pouvez lire mes autres articles sur les conclusions logiques , la formation et les résultats de l'utilisation de RCN sur divers ensembles de données .
8: «i» .Maintenant que nous avons atteint la dernière couche de signes, nous avons un diagramme sur lequel les limites de l'objet sont déterminées et la compréhension de savoir si la zone est en dehors de la frontière est interne ou externe. Il reste à ajouter une apparence, désignant chaque zone restante de l'image comme IN ou OUT et peindre sur la zone. Un champ aléatoire conditionnel peut aider ici. Sans entrer dans les détails mathématiques, nous attribuons simplement à chaque pixel de l'image finale une distribution de probabilité par couleur et état (IN ou OUT). Cette distribution reflétera les informations obtenues à partir de la bordure de la carte. Par exemple, s'il y a deux pixels adjacents, dont l'un est IN et l'autre OUT, la probabilité qu'ils aient une couleur différente augmente considérablement. Si deux pixels adjacents se trouvent sur des côtés opposés de la bordure intérieure, la probabilitéqui aura une couleur différente augmentera également. Si les pixels se trouvent à l'intérieur de la bordure et ne sont séparés par rien, la probabilité qu'ils aient la même couleur augmente, mais les pixels externes peuvent avoir une légère déviation les uns des autres, etc. Pour obtenir l'image finale, il vous suffit de faire une sélection à partir de la distribution de probabilité conjointe que nous venons d'installer. Pour rendre l'image générée plus intéressante, nous pouvons remplacer les couleurs par la texture. Nous ne discuterons pas de cette couche car RCN peut effectuer la classification sans être basé sur l'apparence.Pour obtenir l'image finale, il vous suffit de faire une sélection à partir de la distribution de probabilité conjointe que nous venons d'installer. Pour rendre l'image générée plus intéressante, nous pouvons remplacer les couleurs par la texture. Nous ne discuterons pas de cette couche car RCN peut effectuer la classification sans être basé sur l'apparence.Pour obtenir l'image finale, il vous suffit de faire une sélection à partir de la distribution de probabilité conjointe que nous venons d'installer. Pour rendre l'image générée plus intéressante, nous pouvons remplacer les couleurs par la texture. Nous ne discuterons pas de cette couche car RCN peut effectuer la classification sans être basé sur l'apparence.Eh bien, nous terminerons ici pour aujourd'hui. Si vous voulez en savoir plus sur RCN, lisez cet article [5] et l'annexe avec des documents supplémentaires, ou vous pouvez lire mes autres articles sur les conclusions logiques , la formation et les résultats de l'utilisation de RCN sur divers ensembles de données .Sources:
- [1] R. Perrault, Y. Shoham, E. Brynjolfsson, et al., The AI Index 2019 Annual Report (2019), Human-Centered AI Institute - Stanford University.
- [2] D. Hendrycks, K. Zhao, S. Basart, et al., Natural Adversarial Exemples (2019), arXiv: 1907.07174.
- [3] J. Su, D. Vasconcellos Vargas et S. Kouichi, One Pixel Attack for Fooling Deep Neural Networks (2017), arXiv: 1710.08864.
- [4] M. Sharif, S. Bhagavatula, L. Bauer, A General Framework for Adversarial Exemples with Objectives (2017), arXiv: 1801.00349.
- [5] D. George, W. Lehrach, K. Kansky, et al., A Generative Vision Model that Trains with High Data Efficiency and Break Text-based CAPTCHAs (2017), Science Mag (Vol 358 — Issue 6368).
- [6] H. Liang, X. Gong, M. Chen, et al., Interactions Between Feedback and Lateral Connections in the Primary Visual Cortex (2017), Proceedings of the National Academy of Sciences of the United States of America.
: « : ». Source: https://habr.com/ru/post/undefined/
All Articles