 Nous continuons l'histoire de la façon dont, à l'intérieur d'Odnoklassniki, avec l'aide de GraalVM, nous avons réussi à nous lier d'amitié avec Java et JavaScript et à commencer à migrer vers un énorme système avec beaucoup de code hérité.Dans la deuxième partie de l'article, nous parlerons en détail du lancement, de l'assemblage et de l'intégration des applications sur la nouvelle pile, plongerons dans les spécificités de leur travail à la fois sur le client et sur le serveur, ainsi que discuter des difficultés rencontrées sur notre chemin et décrire des solutions pour les aider à surmonter .Si vous n'avez pas lu la première partieJe recommande fortement de le faire. De là, vous en apprendrez plus sur l'histoire du frontend à Odnoklassniki et vous familiariserez avec ses caractéristiques historiques, passerez par la voie de la recherche d'une solution aux problèmes qui se sont accumulés au cours de nos 13 années de projet, et à la toute fin vous plongerez dans les caractéristiques techniques de la mise en œuvre du serveur de la décision que nous avons prise.
Nous continuons l'histoire de la façon dont, à l'intérieur d'Odnoklassniki, avec l'aide de GraalVM, nous avons réussi à nous lier d'amitié avec Java et JavaScript et à commencer à migrer vers un énorme système avec beaucoup de code hérité.Dans la deuxième partie de l'article, nous parlerons en détail du lancement, de l'assemblage et de l'intégration des applications sur la nouvelle pile, plongerons dans les spécificités de leur travail à la fois sur le client et sur le serveur, ainsi que discuter des difficultés rencontrées sur notre chemin et décrire des solutions pour les aider à surmonter .Si vous n'avez pas lu la première partieJe recommande fortement de le faire. De là, vous en apprendrez plus sur l'histoire du frontend à Odnoklassniki et vous familiariserez avec ses caractéristiques historiques, passerez par la voie de la recherche d'une solution aux problèmes qui se sont accumulés au cours de nos 13 années de projet, et à la toute fin vous plongerez dans les caractéristiques techniques de la mise en œuvre du serveur de la décision que nous avons prise.Configuration de l'interface utilisateur
Pour écrire le code de l'interface utilisateur, nous avons choisi les outils les plus avancés: React avec MobX, les modules CSS, ESLint, TypeScript, Lerna. Tout cela est collecté à l'aide de Webpack.
Architecture d'application
Comme cela a été écrit dans la partie précédente de cet article, afin d'implémenter une migration progressive, nous allons insérer de nouveaux composants sur le site dans des éléments DOM avec des noms personnalisés qui fonctionneront à l'intérieur de la nouvelle pile d'interface utilisateur, tandis que pour le reste du site, il ressemblera à un élément DOM avec son API. Le contenu de ces éléments peut être rendu sur le serveur.Qu'Est-ce que c'est? À l'intérieur, il y a une application MVC cool, à la mode et moderne fonctionnant sur React et fournissant l'extérieur de l'API DOM standard: attributs, méthodes sur cet élément DOM et événements. Pour exécuter de tels composants, nous avons développé un mécanisme spécial. Que fait-il? Tout d'abord, il initialise l'application en fonction de sa description. Deuxièmement, il lie le composant au nœud DOM spécifique dans lequel il démarre. Il existe également deux moteurs (pour le client et pour le serveur) qui peuvent rechercher et rendre ces composants.
Pour exécuter de tels composants, nous avons développé un mécanisme spécial. Que fait-il? Tout d'abord, il initialise l'application en fonction de sa description. Deuxièmement, il lie le composant au nœud DOM spécifique dans lequel il démarre. Il existe également deux moteurs (pour le client et pour le serveur) qui peuvent rechercher et rendre ces composants. Pourquoi est-ce nécessaire? Le fait est que lorsque l'ensemble du site est créé sur React, le composant site est généralement rendu dans l'élément racine de la page, et ce composant n'a pas d'importance ce qui est à l'extérieur, mais seul ce qui est à l'intérieur est intéressant.Dans notre cas, tout est plus compliqué: un certain nombre d'applications ont besoin de pouvoir dire à notre page sur le site "Je suis, et quelque chose change en moi". Par exemple, le calendrier doit lancer un événement sur lequel l'utilisateur a cliqué sur le bouton, et la date a changé, ou à l'extérieur, vous avez besoin de la possibilité pour qu'à l'intérieur du calendrier vous puissiez changer la date. Pour cela, le moteur d'application implémente des façades dans les fonctionnalités de base de l'application.Lors de la livraison d'un composant à un client, il est nécessaire que le moteur de l'ancien site puisse lancer ce composant. Pour ce faire, lors de la construction, les informations nécessaires à son lancement sont collectées.
Pourquoi est-ce nécessaire? Le fait est que lorsque l'ensemble du site est créé sur React, le composant site est généralement rendu dans l'élément racine de la page, et ce composant n'a pas d'importance ce qui est à l'extérieur, mais seul ce qui est à l'intérieur est intéressant.Dans notre cas, tout est plus compliqué: un certain nombre d'applications ont besoin de pouvoir dire à notre page sur le site "Je suis, et quelque chose change en moi". Par exemple, le calendrier doit lancer un événement sur lequel l'utilisateur a cliqué sur le bouton, et la date a changé, ou à l'extérieur, vous avez besoin de la possibilité pour qu'à l'intérieur du calendrier vous puissiez changer la date. Pour cela, le moteur d'application implémente des façades dans les fonctionnalités de base de l'application.Lors de la livraison d'un composant à un client, il est nécessaire que le moteur de l'ancien site puisse lancer ce composant. Pour ce faire, lors de la construction, les informations nécessaires à son lancement sont collectées.{
"events-calendar": {
"bundleName": "events-calendar",
"js": "events-calendar-h4h5m.js",
"css": "events-calendar-h4h5m.css"
}
}
Des marqueurs spéciaux sont ajoutés aux attributs de la balise du composant, qui indiquent que cette application est d'un nouveau type, son code peut être extrait d'un fichier JS spécifique. En même temps, il a ses propres attributs qui sont nécessaires pour initialiser ce composant: ils forment l'état initial du composant dans le magasin.<events-calendar data-module="react-loader"
data-bundle="events-calendar.js"
date=".."
marks="[{..}]"
…
/>
Pour la réhydratation, ce n'est pas une conversion de l'état d'application qui est utilisée, mais des attributs, qui permet d'économiser sur le trafic. Ils se présentent sous une forme normalisée et, en règle générale, sont plus petits que le magasin créé par l'application. Dans le même temps, le temps de recréer le magasin à partir des attributs sur le client est court, donc ils peuvent généralement être négligés.Par exemple, pour le calendrier, les attributs n'ont qu'une date en surbrillance et le magasin a déjà une matrice avec des informations complètes pour le mois. Évidemment, il est inutile de le transférer depuis le serveur.Comment exécuter le code?
Le concept a été testé sur des fonctions simples qui donnent une ligne pour le serveur ou écrivent innerHTML pour le client. Mais dans le vrai code, il existe des modules et TypeScript.Il existe des solutions standard pour le client, par exemple, la collecte de code à l'aide de Webpack, qui lui-même broie tout et le donne au client sous la forme d'un ensemble de lots. Et que faire pour le serveur lors de l'utilisation de GraalVM? Prenons deux options. La première consiste à taper TypeScript en JavaScript, comme ils le font pour Node.js. Cette option, malheureusement, ne fonctionne pas dans notre configuration lorsque JavaScript est le langage invité dans GraalVM. Dans ce cas, JavaScript n'a pas de système modulaire, ni même asynchrone. Parce que la modularité et le travail avec asynchronie fournissent un runtime spécifique: NodeJS ou un navigateur. Et dans notre cas, le serveur dispose de JavaScript qui ne peut exécuter le code que de manière synchrone.La deuxième option - vous pouvez simplement exécuter le code du serveur à partir des mêmes fichiers qui ont été collectés pour le client. Et cette option fonctionne. Mais il y a un problème que le serveur a besoin d'autres implémentations pour un certain nombre de méthodes. Par exemple, la fonction renderToString () sera appelée sur le serveur pour rendre le composant et ReactDOM.render () sur le client. Ou un autre exemple de l'article précédent: pour obtenir des textes et des paramètres sur le serveur, la fonction fournie par Java sera appelée, et sur le client ce sera une implémentation en JS.Pour résoudre ce problème, vous pouvez utiliser des alias de Webpack. Ils vous permettent de créer deux implémentations de la classe dont nous avons besoin: pour le client et le serveur. Ensuite, dans les fichiers de configuration pour le client et le serveur, spécifiez l'implémentation appropriée.
Prenons deux options. La première consiste à taper TypeScript en JavaScript, comme ils le font pour Node.js. Cette option, malheureusement, ne fonctionne pas dans notre configuration lorsque JavaScript est le langage invité dans GraalVM. Dans ce cas, JavaScript n'a pas de système modulaire, ni même asynchrone. Parce que la modularité et le travail avec asynchronie fournissent un runtime spécifique: NodeJS ou un navigateur. Et dans notre cas, le serveur dispose de JavaScript qui ne peut exécuter le code que de manière synchrone.La deuxième option - vous pouvez simplement exécuter le code du serveur à partir des mêmes fichiers qui ont été collectés pour le client. Et cette option fonctionne. Mais il y a un problème que le serveur a besoin d'autres implémentations pour un certain nombre de méthodes. Par exemple, la fonction renderToString () sera appelée sur le serveur pour rendre le composant et ReactDOM.render () sur le client. Ou un autre exemple de l'article précédent: pour obtenir des textes et des paramètres sur le serveur, la fonction fournie par Java sera appelée, et sur le client ce sera une implémentation en JS.Pour résoudre ce problème, vous pouvez utiliser des alias de Webpack. Ils vous permettent de créer deux implémentations de la classe dont nous avons besoin: pour le client et le serveur. Ensuite, dans les fichiers de configuration pour le client et le serveur, spécifiez l'implémentation appropriée.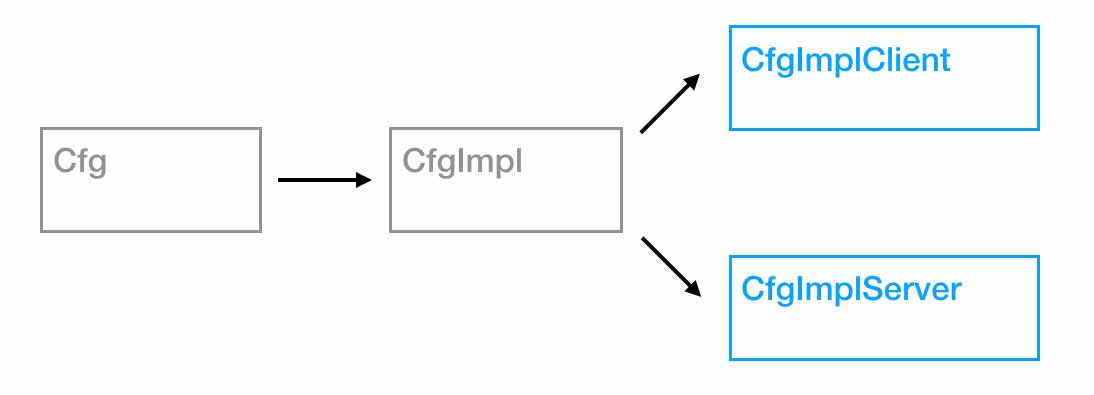 Mais deux fichiers de configuration sont deux assemblys. Chaque fois, tout collecter séparément pour le serveur et pour le client est long et difficile à gérer.Vous devez proposer une telle configuration afin que tout soit collecté en une seule fois.
Mais deux fichiers de configuration sont deux assemblys. Chaque fois, tout collecter séparément pour le serveur et pour le client est long et difficile à gérer.Vous devez proposer une telle configuration afin que tout soit collecté en une seule fois.Configuration de Webpack pour exécuter JS sur le serveur et le client
Pour trouver une solution à ce problème, voyons de quelles parties le projet se compose: Premièrement, le projet a un runtime tiers (fournisseurs), le même pour le client et pour le serveur. Cela ne change presque jamais. Rantime peut être donné à l'utilisateur et il sera mis en cache sur le client jusqu'à ce que nous mettions à jour la version de la bibliothèque tierce.Deuxièmement, il y a notre runtime (core), qui assure le lancement de l'application. Il a des méthodes avec différentes implémentations pour le client et le serveur. Par exemple, obtenir des textes de localisation, des paramètres, etc. Ce runtime change également rarement.Troisièmement, il existe un code de composant. C'est la même chose pour le client et pour le serveur, ce qui vous permet de déboguer le code d'application dans le navigateur sans démarrer le serveur du tout. Si quelque chose s'est mal passé sur le client, vous pouvez voir les erreurs dans la console du navigateur, tout garder à l'esprit et être sûr qu'il n'y aura pas d'erreurs lors du démarrage sur le serveur.Au total, trois pièces sont obtenues qui doivent être assemblées. Nous voulons:
Premièrement, le projet a un runtime tiers (fournisseurs), le même pour le client et pour le serveur. Cela ne change presque jamais. Rantime peut être donné à l'utilisateur et il sera mis en cache sur le client jusqu'à ce que nous mettions à jour la version de la bibliothèque tierce.Deuxièmement, il y a notre runtime (core), qui assure le lancement de l'application. Il a des méthodes avec différentes implémentations pour le client et le serveur. Par exemple, obtenir des textes de localisation, des paramètres, etc. Ce runtime change également rarement.Troisièmement, il existe un code de composant. C'est la même chose pour le client et pour le serveur, ce qui vous permet de déboguer le code d'application dans le navigateur sans démarrer le serveur du tout. Si quelque chose s'est mal passé sur le client, vous pouvez voir les erreurs dans la console du navigateur, tout garder à l'esprit et être sûr qu'il n'y aura pas d'erreurs lors du démarrage sur le serveur.Au total, trois pièces sont obtenues qui doivent être assemblées. Nous voulons:- Configurez séparément l'assemblage de chaque pièce.
- Réduisez les dépendances entre elles afin que chaque partie ne tombe pas dans ce qui est dans l'autre.
- Rassemblez tout en un seul passage.
Comment décrire séparément les pièces dont l'assemblage sera composé? Il existe une multiconfiguration dans webpack: vous donnez simplement un tableau d'exportations des modules inclus dans chaque partie.module.exports = [{
entry: './vendors.js',
}, {
entry: './core.js'
}, {
entry: './app.js'
}];
Tout irait bien, mais dans chacune de ces parties, le code des modules dont cette partie dépend sera dupliqué: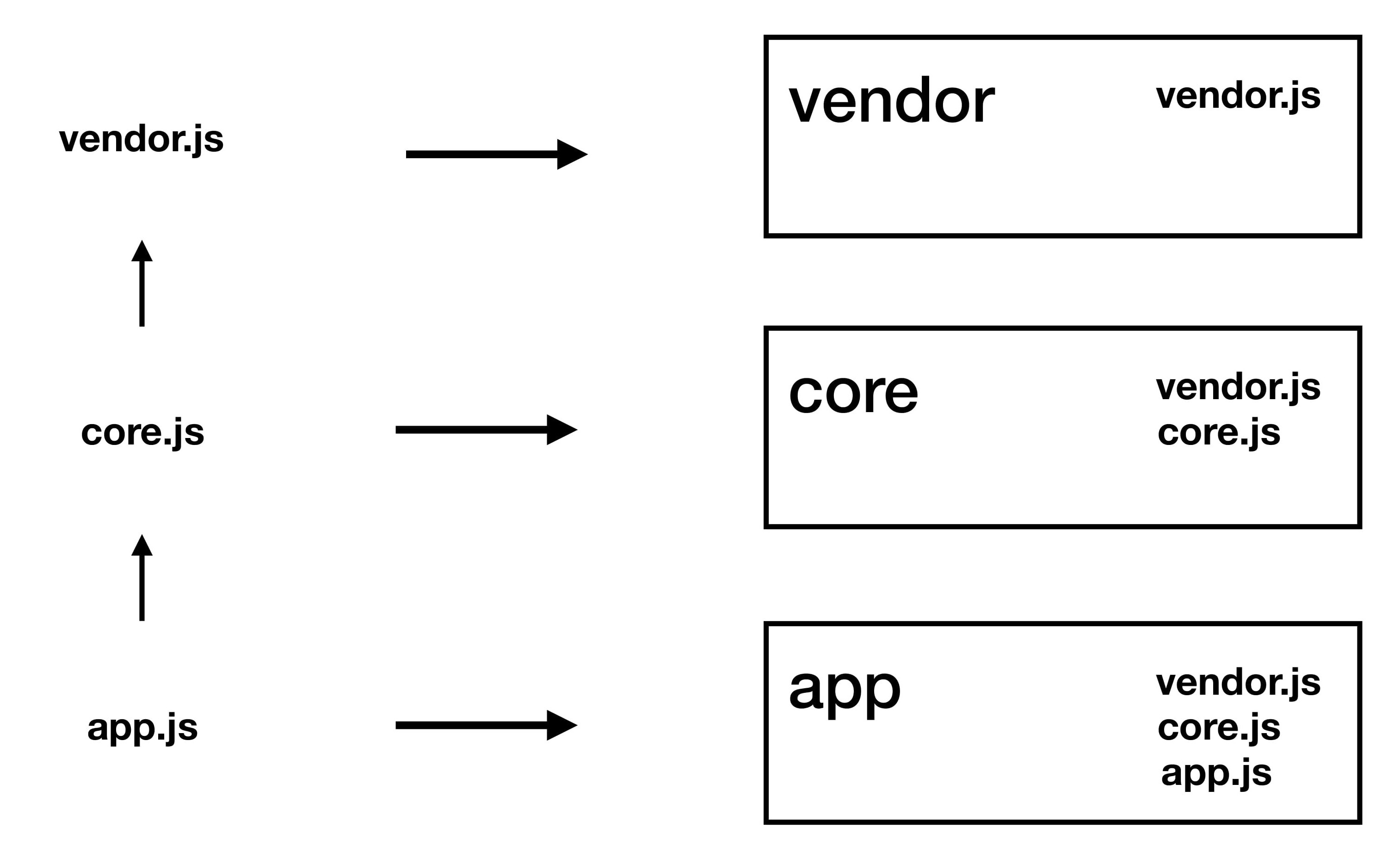 Heureusement, dans l'ensemble de base des plugins webpack , il y a DllPlugin , qui vous permet d'obtenir une liste des modules inclus dans chaque partie assemblée. Par exemple, pour le fournisseur, vous pouvez savoir quels modules spécifiques sont inclus dans cette partie.Lors de la construction d'une autre partie, par exemple des bibliothèques de base, nous pouvons dire qu'elles dépendent de la partie fournisseur.
Heureusement, dans l'ensemble de base des plugins webpack , il y a DllPlugin , qui vous permet d'obtenir une liste des modules inclus dans chaque partie assemblée. Par exemple, pour le fournisseur, vous pouvez savoir quels modules spécifiques sont inclus dans cette partie.Lors de la construction d'une autre partie, par exemple des bibliothèques de base, nous pouvons dire qu'elles dépendent de la partie fournisseur.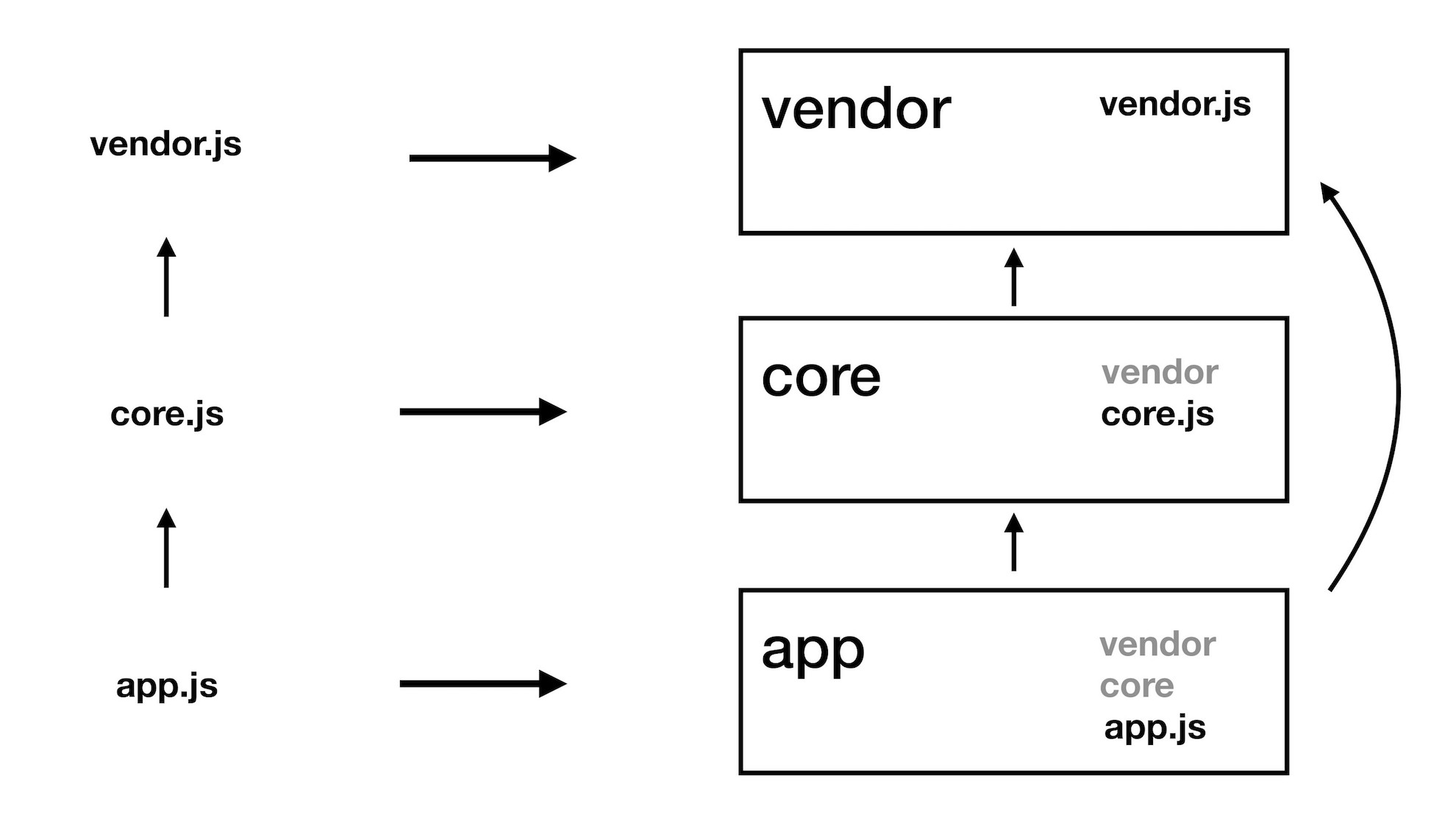 Ensuite, pendant l'assemblage du webpack, DllPlugin verra le noyau en fonction d'une bibliothèque qui est déjà chez le fournisseur, et ne l'ajoutera pas au noyau, mais y mettra simplement un lien.En conséquence, trois pièces sont assemblées à la fois et dépendent les unes des autres. Lorsque la première application est téléchargée sur le client, les bibliothèques d'exécution et de base seront enregistrées dans le cache du navigateur. Et comme Odnoklassniki est un site, l'onglet avec lequel l'utilisateur peut ouvrir «pour toujours», l'éviction se produira assez rarement. Dans la plupart des cas, avec les versions des nouvelles versions du site, seul le code d'application sera mis à jour.
Ensuite, pendant l'assemblage du webpack, DllPlugin verra le noyau en fonction d'une bibliothèque qui est déjà chez le fournisseur, et ne l'ajoutera pas au noyau, mais y mettra simplement un lien.En conséquence, trois pièces sont assemblées à la fois et dépendent les unes des autres. Lorsque la première application est téléchargée sur le client, les bibliothèques d'exécution et de base seront enregistrées dans le cache du navigateur. Et comme Odnoklassniki est un site, l'onglet avec lequel l'utilisateur peut ouvrir «pour toujours», l'éviction se produira assez rarement. Dans la plupart des cas, avec les versions des nouvelles versions du site, seul le code d'application sera mis à jour.Livraison des ressources
Considérez le problème par l'exemple de l'utilisation de textes localisés qui sont stockés dans une base de données distincte.Si plus tôt, quelque part sur le serveur, vous aviez besoin de texte dans le composant, vous pouvez appeler la fonction pour obtenir le texte.const pkg = l10n('smiles');
<div>
: { pkg.getText('title') }
</div>
Obtenir du texte sur le serveur n'est pas difficile, car l'application serveur peut faire une demande rapide à la base de données ou même mettre en cache tous les textes en mémoire.Comment obtenir des textes dans des composants sur une réaction qui sont rendus sur un serveur dans GraalVM?Comme indiqué dans la première partie de l'article, dans le contexte JS, vous pouvez ajouter des méthodes à l'objet global auquel vous souhaitez accéder à partir de JavaScript. Il a été décidé de créer une classe avec toutes les méthodes disponibles pour JavaScript.public class ServerMethods {
…
public String getText(String pkg, String key) {
…
}
…
}
Ensuite, placez une instance de cette classe dans le contexte JavaScript global:
js.putMember("serverMethods", serverMethods);
Par conséquent, à partir de JavaScript dans l'implémentation du serveur, nous appelons simplement la fonction:function getText(pkg: string, key: string): string {
return global.serverMethods.getText(pkg, key);
}
En fait, ce sera un appel de fonction en Java qui renverra le texte demandé. Interaction synchrone directe et aucun appel HTTP.Sur le client, malheureusement, il faut très longtemps pour parcourir HTTP et recevoir des textes pour chaque appel à la fonction d'insertion de texte dans les composants. Vous pouvez pré-télécharger tous les textes sur le client, mais les textes à eux seuls pèsent des dizaines de mégaoctets, et il existe d'autres types de ressources. L'utilisateur sera fatigué d'attendre que tout soit téléchargé avant de démarrer l'application. Par conséquent, cette méthode ne convient pas.Je souhaite recevoir uniquement les textes nécessaires à une application particulière. Nos textes sont divisés en paquets. Par conséquent, vous pouvez collecter les packages nécessaires à l'application et les télécharger avec l'ensemble. Lorsque l'application démarre, tous les textes seront déjà dans le cache client.Comment savoir de quels textes une application a besoin?Nous avons conclu un accord selon lequel les packages de textes du code sont obtenus en appelant la fonction l10n (), dans laquelle le nom du package est transmis UNIQUEMENT sous la forme d'une chaîne littérale:
L'utilisateur sera fatigué d'attendre que tout soit téléchargé avant de démarrer l'application. Par conséquent, cette méthode ne convient pas.Je souhaite recevoir uniquement les textes nécessaires à une application particulière. Nos textes sont divisés en paquets. Par conséquent, vous pouvez collecter les packages nécessaires à l'application et les télécharger avec l'ensemble. Lorsque l'application démarre, tous les textes seront déjà dans le cache client.Comment savoir de quels textes une application a besoin?Nous avons conclu un accord selon lequel les packages de textes du code sont obtenus en appelant la fonction l10n (), dans laquelle le nom du package est transmis UNIQUEMENT sous la forme d'une chaîne littérale:const pkg = l10n('smiles');
<div>
{ pkg.getLMsg('title') }
</div>
Nous avons écrit un plugin webpack qui, en analysant l'arborescence AST du code des composants, trouve tous les appels à la fonction l10n () et collecte les noms des packages à partir des arguments. De même, le plugin collecte des informations sur d'autres types de ressources nécessaires à l'application.En sortie après assemblage pour chaque application, nous obtenons une configuration avec ses ressources:{
"events-calendar": {
"pkg": [
"calendar",
"dates"
],
"cfg": [
"config1",
"config2"
],
"bundleName": "events-calendar",
"js": "events-calendar.js",
"css": "events-calendar.css",
}
}
Et bien sûr, nous ne devons pas oublier de mettre à jour les textes. Parce que sur le serveur, tous les textes sont toujours à jour et que le client a besoin d'un mécanisme de mise à jour du cache distinct, par exemple, watcher ou push.Ancien code dans le nouveau
Avec une transition en douceur, le problème se pose de réutiliser l'ancien code dans de nouveaux composants, car il existe des composants grands et complexes (par exemple, un lecteur vidéo), une réécriture qui prendra beaucoup de temps, et vous devez les utiliser dans la nouvelle pile maintenant. Quels sont les problèmes?
Quels sont les problèmes?- L'ancien site et les nouvelles applications React ont des cycles de vie complètement différents.
- Si vous collez le code de l'ancien exemple dans l'application React, ce code ne démarrera pas, car React ne sait pas comment l'activer.
- En raison de cycles de vie différents, React et l'ancien moteur peuvent simultanément essayer de modifier le contenu de l'ancien code, ce qui peut provoquer des effets secondaires désagréables.
Pour résoudre ces problèmes, une classe de base commune a été allouée aux composants contenant l'ancien code. La classe permet aux héritiers de coordonner les cycles de vie des applications React et à l'ancienne.export class OldCodeBase<T> extends React.Component<T> {
ref: React.RefObject<HTMLElement> = React.createRef();
componentDidMount() {
this.props.activate(this.ref.current!);
}
componentWillUnmount() {
this.props.deactivate(this.ref.current!);
}
shouldComponentUpdate() {
return false;
}
render() {
return (
<div ref={this.ref}></div>
);
}
}
La classe vous permet soit de créer des morceaux de code qui fonctionnent à l'ancienne, soit de les détruire, alors qu'il n'y aura pas d'interaction simultanée avec eux.Coller l'ancien code sur le serveur
Dans la pratique, il existe un besoin de composants de wrapper (par exemple, des fenêtres contextuelles), dont le contenu peut être quelconque, y compris ceux créés à l'aide d'anciennes technologies. Vous devez comprendre comment incorporer n'importe quel code sur le serveur à l'intérieur de ces composants.Dans un article précédent, nous avons parlé de l'utilisation d'attributs pour transmettre des paramètres à de nouveaux composants sur le client et le serveur.<cool-app users="[1,2,3]" />
Et maintenant, nous voulons toujours y insérer un élément de balisage, qui, dans le sens, n'est pas un attribut. Pour cela, il a été décidé d'utiliser un système de slots.<cool-app>
<ui:part id="old-code">
<div>old component</div>
</ui:part>
</cool-app>
Comme vous pouvez le voir dans l'exemple ci-dessus, à l'intérieur du code du composant cool-app, un emplacement d'ancien code contenant d'anciens composants est décrit. Ensuite, à l'intérieur du composant react, l'endroit où vous souhaitez coller le contenu de cet emplacement est indiqué:render() {
return (
<div>
<UiPart id="old-code" />
</div>
);
}
Le moteur de serveur rend ce composant React et encadre le contenu de l'emplacement dans la balise <ui-part>, en lui attribuant l'attribut data-part-id = "old-code".<cool-app>
<div>
<ui-part data-part-id="old-code">
old code
</ui-part>
</div>
</cool-app>
Si le rendu côté serveur de JS dans GraalVM ne rentre pas dans le délai d'expiration, nous utilisons alors le rendu client. Pour ce faire, le moteur du serveur ne donne que des emplacements, en les encadrant dans la balise de modèle afin que le navigateur n'interagisse pas avec leur code.<cool-app>
<template>
<ui-part data-part-id="old-code">
old code
</ui-part>
</template>
</cool-app>
Que se passe-t-il sur le client? Le moteur client analyse simplement le code du composant, collecte les balises <ui-part>, reçoit leur contenu sous forme de chaînes et les transmet à la fonction de rendu avec le reste des paramètres.var tagName = 'cool-app';
var reactComponent = components[tagName];
reactComponent.render({
tagName: tagName,
attrs: attrs,
parts: parts,
node: element
});
Le code du composant qui insère les emplacements à l'emplacement souhaité est le suivant:export class UiPart extends OldCodeBase<IProps> {
render() {
const id = this.props.id;
const parts = this.props.parts;
if (!parts.hasOwnProperty(id)) {
return null;
}
return React.createElement('ui-part', {
'data-part-id': id,
ref: this.ref,
dangerouslySetInnerHTML: { __html: parts[id] }
});
}
}
En même temps, il est hérité de la classe OldCodeBase, qui résout les problèmes d'interaction entre l'ancienne et la nouvelle pile. Vous pouvez maintenant écrire une fenêtre contextuelle et la remplir à l'aide de la nouvelle pile ou de la demande du serveur en utilisant l'ancienne approche. Dans ce cas, les composants fonctionneront correctement.Cela vous permet de migrer progressivement les composants du site vers une nouvelle pile.C'était juste l'une des principales exigences du nouveau frontend.
Vous pouvez maintenant écrire une fenêtre contextuelle et la remplir à l'aide de la nouvelle pile ou de la demande du serveur en utilisant l'ancienne approche. Dans ce cas, les composants fonctionneront correctement.Cela vous permet de migrer progressivement les composants du site vers une nouvelle pile.C'était juste l'une des principales exigences du nouveau frontend.Sommaire
Tout le monde se demande à quelle vitesse GraalVM fonctionne. Les développeurs d'Odnoklassniki ont effectué divers tests avec les applications React.Une fonction simple qui renvoie une chaîne après l'échauffement prend environ 1 microseconde.Composants (à nouveau après échauffement) - de 0,5 à 6 millisecondes, selon leur taille.GraalVM accélère plus lentement que V8. Mais pour le temps de son échauffement, la situation est lissée grâce au repli du rendu client. Puisqu'il y a tellement d'utilisateurs, la machine virtuelle chauffe rapidement.Qu'avez-vous réussi à faire
- Exécutez JavaScript sur le serveur dans le monde Java de Classmates.
- Créez un code isomorphe pour l'interface utilisateur.
- Utilisez une pile moderne que tous les fournisseurs frontaux connaissent.
- Créez une plate-forme commune et une approche unique pour l'écriture de l'interface utilisateur.
- Commencez une transition en douceur sans compliquer l'opération et sans ralentir le rendu du serveur.
Nous espérons que les expériences d'Odnoklassniki et des exemples vous seront utiles et vous les trouverez à utiliser dans votre travail.