Bonjour, Habr.Mon nom est Misha Butrimov, je voudrais parler un peu de Cassandra. Mon histoire sera utile à ceux qui n'ont jamais rencontré de bases de données NoSQL - elle a beaucoup de fonctionnalités d'implémentation et d'embûches que vous devez connaître. Et si, à part Oracle ou toute autre base relationnelle, vous n'avez rien vu, ces choses vous sauveront la vie.Qu'est-ce qui est bon avec Cassandra? Il s'agit d'une base de données NoSQL conçue sans point de défaillance unique, qui évolue bien. Si vous devez ajouter quelques téraoctets pour n'importe quelle base, il vous suffit d'ajouter des nœuds à l'anneau. L'étendre à un autre centre de données? Ajoutez des nœuds au cluster. Augmenter le RPS traité? Ajoutez des nœuds au cluster. L'autre manière fonctionne également. À quoi d'autre est-elle bonne? C'est pour traiter beaucoup de demandes. Mais combien coûte combien? 10, 20, 30, 40 000 requêtes par seconde - ce n'est pas beaucoup. 100 000 demandes d'enregistrement par seconde également. Certaines entreprises ont déclaré détenir 2 millions de demandes par seconde. Ici, ils doivent probablement croire.Et en principe, Cassandra a une grande différence avec les données relationnelles - elle ne leur ressemble pas du tout. Et c'est très important à retenir.
À quoi d'autre est-elle bonne? C'est pour traiter beaucoup de demandes. Mais combien coûte combien? 10, 20, 30, 40 000 requêtes par seconde - ce n'est pas beaucoup. 100 000 demandes d'enregistrement par seconde également. Certaines entreprises ont déclaré détenir 2 millions de demandes par seconde. Ici, ils doivent probablement croire.Et en principe, Cassandra a une grande différence avec les données relationnelles - elle ne leur ressemble pas du tout. Et c'est très important à retenir.Tout ce qui se ressemble ne fonctionne pas de la même façon
Une fois qu'un collègue est venu me voir et m'a demandé: «Voici le langage de requête CQL Cassandra, et il a une instruction select, il a où, il a et. J'écris des lettres et ça ne marche pas. Pourquoi?". Si vous traitez Cassandra comme une base de données relationnelle, c'est un moyen idéal de mettre fin à votre vie par un suicide brutal. Et je ne le préconise pas, c'est interdit en Russie. Vous concevez simplement quelque chose de mal.Par exemple, un client vient à nous et dit: «Créons une base de données pour les émissions de télévision, ou une base de données pour un répertoire de recettes. Nous y aurons des plats ou une liste de séries et d'acteurs. » Nous disons joyeusement: "Allez!". Ce sont deux octets à envoyer, quelques plaques et tout est prêt, tout fonctionnera très rapidement, de manière fiable. Et tout va bien jusqu'à ce que les clients viennent et disent que les femmes au foyer résolvent également le problème inverse: elles ont une liste de produits et elles veulent savoir quel plat elles veulent cuisiner. Tu es mort.En effet, Cassandra est une base de données hybride: elle est à la fois une valeur clé et stocke les données dans de larges colonnes. Parlant en Java ou Kotlin, il pourrait être décrit comme ceci:Map<RowKey, SortedMap<ColumnKey, ColumnValue>>Autrement dit, une carte, à l'intérieur de laquelle se trouve également une carte triée. La première clé de cette carte est la clé Row ou la clé de partition - la clé de partition. La deuxième clé, qui est la clé de la carte déjà triée, est la clé de clustering.Pour illustrer la distribution de la base de données, nous dessinons trois nœuds. Vous devez maintenant comprendre comment décomposer les données en nœuds. Parce que si nous mettons tout en un (en passant, il peut y en avoir mille, deux mille, cinq - autant que vous le souhaitez), ce n'est pas vraiment une question de distribution. Par conséquent, nous avons besoin d'une fonction mathématique qui renverra un nombre. Juste un nombre, un long int qui tombera dans une certaine plage. Et nous avons un nœud sera responsable d'une plage, le second - pour le deuxième, n-ème - pour le n-ème. Ce nombre est pris à l'aide d'une fonction de hachage qui s'applique uniquement à ce que nous appelons la clé de partition. Il s'agit de la colonne spécifiée dans la directive Clé primaire, et c'est la colonne qui sera la première et la clé de mappage la plus élémentaire. Il détermine quel nœud obtient quelles données. Une table est créée dans Cassandra avec presque la même syntaxe qu'en SQL:
Ce nombre est pris à l'aide d'une fonction de hachage qui s'applique uniquement à ce que nous appelons la clé de partition. Il s'agit de la colonne spécifiée dans la directive Clé primaire, et c'est la colonne qui sera la première et la clé de mappage la plus élémentaire. Il détermine quel nœud obtient quelles données. Une table est créée dans Cassandra avec presque la même syntaxe qu'en SQL:CREATE TABLE users (
user_id uu id,
name text,
year int,
salary float,
PRIMARY KEY(user_id)
)
Dans ce cas, la clé primaire se compose d'une colonne et il s'agit également d'une clé de partition.Comment les utilisateurs vont-ils tomber avec nous? Une partie tombera sur une note, une partie sur une autre et une partie sur une troisième. Il se révèle une table de hachage ordinaire, c'est aussi une carte, c'est aussi un dictionnaire en Python, c'est aussi une simple structure de valeurs Key à partir de laquelle on peut lire toutes les valeurs, lire et écrire par clé.
Sélectionnez: quand autoriser le filtrage se transforme en analyse complète, ou comment ne pas le faire
Écrivons une déclaration Le select: select * from users where, userid = . Il s'avère que cela ressemble à Oracle: nous écrivons select, nous spécifions les conditions et tout fonctionne, les utilisateurs l'obtiennent. Mais si vous sélectionnez, par exemple, un utilisateur avec une certaine année de naissance, Cassandra jure qu'elle ne peut pas répondre à la demande. Parce qu'elle ne sait rien sur la façon dont nous distribuons les données sur l'année de naissance - elle n'a qu'une seule colonne spécifiée comme clé. Puis elle dit: «D'accord, je peux toujours répondre à cette demande. Ajoutez autoriser le filtrage. " Nous ajoutons une directive, tout fonctionne. Et à ce moment, une chose terrible se produit.Lorsque nous conduisons sur des données de test, tout va bien. Et lorsque vous répondez à la demande en production, où, par exemple, nous avons 4 millions d'enregistrements, alors tout ne va pas très bien chez nous. Parce que permettre le filtrage est une directive qui permet à Cassandra de collecter toutes les données de cette table de tous les nœuds, de tous les centres de données (s'il y en a beaucoup dans ce cluster), puis de les filtrer uniquement. Il s'agit d'un analogue de Full Scan, et presque personne n'en est ravi.Si nous n'avions besoin d'utilisateurs que par identifiants, cela nous conviendrait. Mais parfois, nous devons écrire d'autres requêtes et imposer d'autres restrictions à la sélection. Par conséquent, nous nous souvenons: nous avons tous une carte, qui a une clé de partition, mais à l'intérieur, il y a une carte triée.Et elle a aussi une clé, que nous appelons la Clustering Key. Cette clé, qui, à son tour, se compose des colonnes que nous sélectionnons, avec lesquelles Cassandra comprend comment ses données sont triées physiquement et reposera sur chaque nœud. Autrement dit, pour une clé de partition, la clé de clustering vous dira exactement comment pousser les données dans cet arbre, quelle place elles y prendront.Il s'agit d'un véritable arbre, un comparateur est simplement appelé là, dans lequel nous passons un certain ensemble de colonnes sous la forme d'un objet, et il est également défini sous la forme d'une énumération de colonnes.CREATE TABLE users_by_year_salary_id (
user_id uuid,
name text,
year int,
salary float,
PRIMARY KEY((year), salary, user_id)
Faites attention à la directive Clé primaire, elle a le premier argument (dans notre cas l'année) est toujours la clé de partition. Il peut consister en une ou plusieurs colonnes, peu importe. S'il y a plusieurs colonnes, vous devez les supprimer à nouveau entre parenthèses afin que le préprocesseur de langue comprenne qu'il s'agit de la clé primaire et derrière toutes les autres colonnes - la clé de clustering. Dans ce cas, ils seront transmis dans le comparateur dans l'ordre dans lequel ils vont. Autrement dit, la première colonne est plus importante, la seconde est moins importante, etc. Lorsque nous écrivons pour des classes de données, par exemple, est égal à champs: nous listons les champs, et pour eux, nous écrivons ceux qui sont plus grands et ceux qui sont plus petits. Dans Cassandra, il s'agit, relativement parlant, du champ de classe de données auquel les égaux écrits pour lui seront appliqués.Nous fixons le tri, imposons des restrictions
Il ne faut pas oublier que l'ordre de tri (décroissant, croissant, peu importe) est défini en même temps que la clé est créée, et vous ne pourrez plus le modifier ultérieurement. Il détermine physiquement comment les données seront triées et comment elles se trouveront. Si vous devez modifier la clé de clustering ou l'ordre de tri, vous devrez créer une nouvelle table et y verser des données. Avec l'existant, cela ne fonctionnera pas.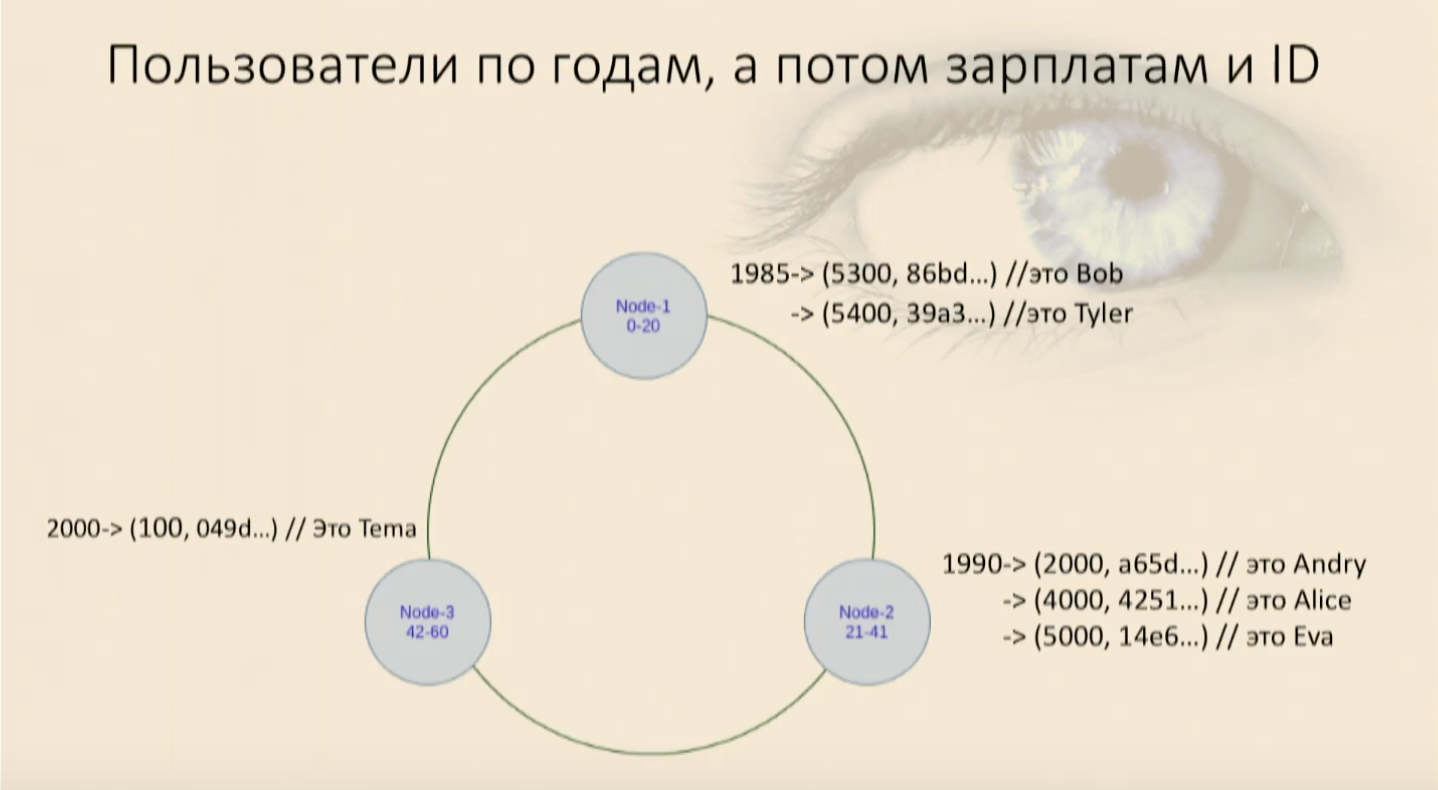 Nous avons rempli notre table d'utilisateurs et avons vu qu'ils sont entrés dans un ring, d'abord par année de naissance, puis à l'intérieur de chaque nœud par salaire et par ID utilisateur. Maintenant, nous pouvons sélectionner, imposer des restrictions.Notre travail réapparaît
Nous avons rempli notre table d'utilisateurs et avons vu qu'ils sont entrés dans un ring, d'abord par année de naissance, puis à l'intérieur de chaque nœud par salaire et par ID utilisateur. Maintenant, nous pouvons sélectionner, imposer des restrictions.Notre travail réapparaîtwhere, and, et les utilisateurs nous contactent, et tout va bien à nouveau. Mais si nous essayons d'utiliser uniquement la partie clé Clustering, la moins importante, Cassandra jurera tout de suite que nous ne pouvons pas trouver dans notre carte où cet objet a ces champs pour le comparateur null, mais celui qui vient d'être défini - où il se trouve. Je vais devoir à nouveau récupérer toutes les données de ce nœud et les filtrer. Et ceci est un analogue de Full Scan au sein du nœud, c'est mauvais.Dans toute situation incompréhensible, créez une nouvelle table
Si nous voulons pouvoir obtenir des utilisateurs par ID, par âge ou par salaire, que devons-nous faire? Rien. Utilisez simplement deux tableaux. Si vous devez obtenir des utilisateurs de trois manières différentes, il y aura trois tableaux. Il est révolu le temps où nous avons économisé de l'espace sur la vis. C'est la ressource la moins chère. Il coûte beaucoup moins cher que le temps de réponse, ce qui peut être fatal à l'utilisateur. L'utilisateur est beaucoup plus agréable d'obtenir quelque chose en une seconde qu'en 10 minutes.Nous échangeons un espace excessif, des données dénormalisées pour la capacité de bien évoluer, de travailler de manière fiable. En effet, en fait, un cluster composé de trois centres de données, chacun ayant cinq nœuds, avec un niveau de stockage de données acceptable (quand rien n'est perdu à coup sûr), est capable de survivre à la mort d'un centre de données complètement. Et deux autres nœuds dans chacun des deux restants. Et ce n'est qu'après que les problèmes commencent. C'est une assez bonne redondance, cela coûte quelques disques SSD et processeurs inutiles. Par conséquent, pour utiliser Cassandra, qui n'est jamais SQL, dans lequel il n'y a pas de relations, pas de clés étrangères, vous devez connaître des règles simples.Nous concevons tout à partir d'une demande. L'essentiel n'est pas les données, mais la façon dont l'application va fonctionner avec elles. S'il a besoin de recevoir différentes données de différentes manières ou les mêmes données de différentes manières, nous devons les mettre de la manière qui conviendra à l'application. Sinon, nous échouerons en Full Scan et Cassandra ne nous donnera aucun avantage.La dénormalisation des données est la norme. Oubliez les formulaires normaux, nous n'avons plus de bases de données relationnelles. On met quelque chose 100 fois, ça va mentir 100 fois. C’est moins cher que de l’arrêter de toute façon.Nous sélectionnons les clés pour le partitionnement afin qu'elles soient normalement distribuées. Nous n'avons pas besoin du hachage de nos clés pour tomber dans une plage étroite. Autrement dit, l'année de naissance dans l'exemple ci-dessus est un mauvais exemple. Au contraire, il est bon que nos utilisateurs soient normalement répartis par année de naissance, et mauvais si nous parlons d'élèves de 5e année - il ne sera pas très bon d'y partitionner.Le tri est sélectionné une fois lors de la création de la Clustering Key. Si vous devez le changer, vous devrez remplir notre table avec une clé différente.Et le plus important: si nous devons collecter les mêmes données de 100 manières différentes, nous aurons alors 100 tableaux différents.