Bonjour à tous!Je veux parler d'un projet très ennuyeux où la robotique, le Machine Learning (et ensemble c'est le Robot Learning), la réalité virtuelle et un peu de technologie cloud se sont croisés. Et tout cela a du sens. Après tout, il est très pratique de passer à un robot, de montrer quoi faire, puis de former des poids sur le serveur ML en utilisant les données stockées.Sous la coupe, nous dirons comment cela fonctionne maintenant, et quelques détails sur chacun des aspects qui devaient être développés.
Pourquoi
Pour commencer, cela vaut la peine d'être révélé.Il semble que des robots armés de Deep Learning soient sur le point d'évincer les gens de leur travail partout. En fait, tout n'est pas si fluide. Là où les actions sont strictement répétées, les processus sont déjà très bien automatisés. Si nous parlons de «robots intelligents», c'est-à-dire d'applications où la vision par ordinateur et les algorithmes suffisent déjà. Mais il y a aussi beaucoup d'histoires extrêmement compliquées. Les robots peuvent difficilement faire face à la variété des objets à traiter et à la diversité de l'environnement.Points clés
Il y a 3 éléments clés en termes de mise en œuvre qui ne se trouvent pas encore partout:- (data-driven learning). .. , , , . , .
- ()
- - (Human-machine collaboration)
La seconde est également importante car en ce moment, nous observerons un changement dans les approches de l'apprentissage, des algorithmes, derrière eux et des outils informatiques. Les algorithmes de perception et de contrôle deviendront plus flexibles. Une mise à niveau du robot coûte de l'argent. Et la calculatrice peut être utilisée plus efficacement si elle sert plusieurs robots à la fois. Ce concept est appelé «robotique cloud».Avec ce dernier, tout est simple - l'IA n'est pas suffisamment développée à l'heure actuelle pour fournir une fiabilité et une précision à 100% dans toutes les situations requises par les entreprises. Par conséquent, l'opérateur superviseur, qui peut parfois aider les robots des salles, ne sera pas blessé.Schème
Pour commencer, sur une plate-forme logicielle / réseau qui fournit toutes les fonctionnalités décrites: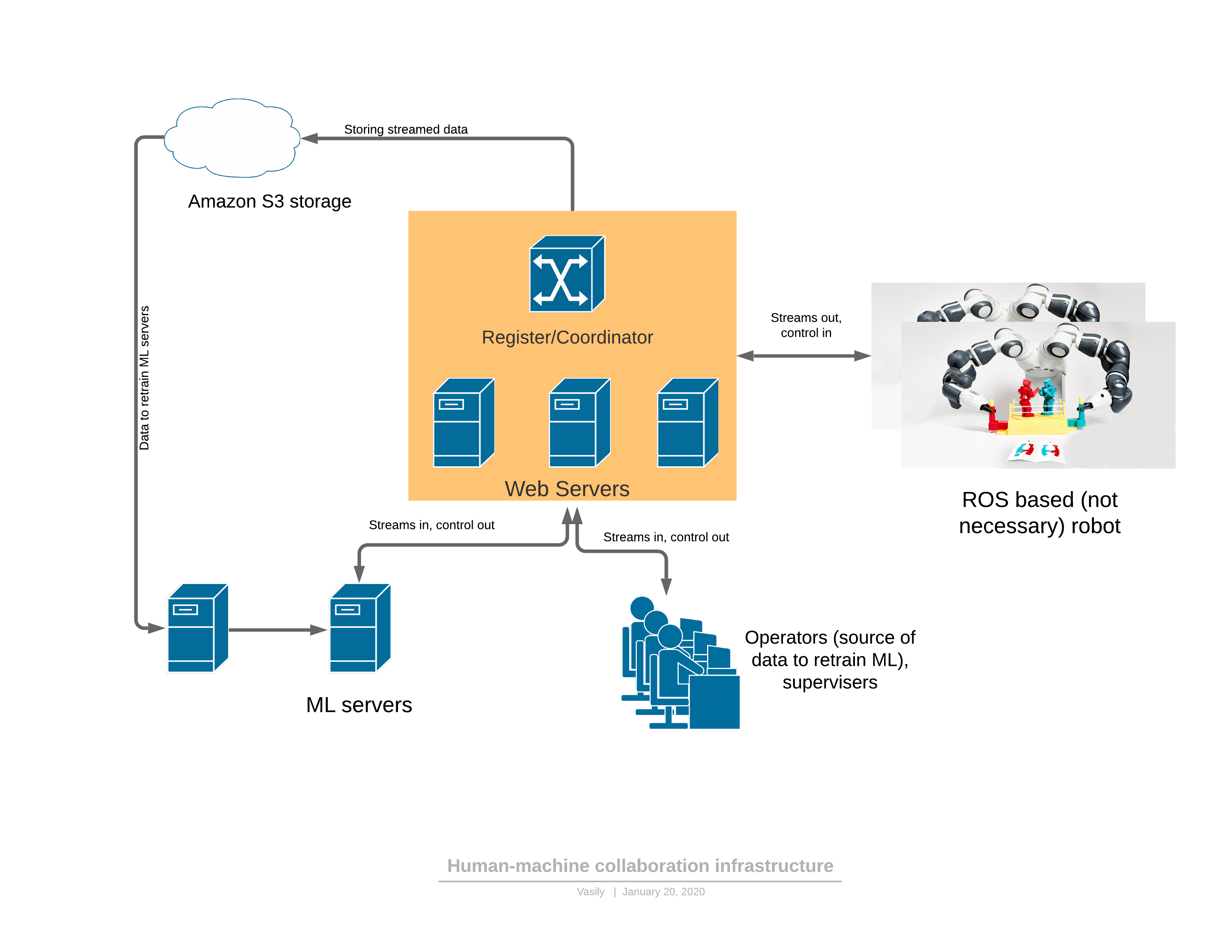 Composants:
Composants:- Le robot envoie un flux vidéo 3D au serveur et reçoit le contrôle en réponse.
- : - , (, , , )
- ML ( ), , , . — 3D , .
- - , 3D , UI . — .
Il existe 2 modes de fonctionnement du robot: automatique et manuel.En mode manuel, le robot fonctionne si le service ML n'est pas encore formé. Ensuite, le robot passe de l'automatique au manuel soit à la demande de l'opérateur (j'ai vu des comportements étranges en regardant le robot), soit lorsque les services ML eux-mêmes détectent une anomalie. À propos de la détection des anomalies sera plus tard - c'est une partie très importante, sans laquelle il est impossible d'appliquer l'approche proposée.L'évolution du contrôle est la suivante:- La tâche du robot est formulée en termes lisibles par l'homme et des indicateurs de performance sont décrits.
- L'opérateur se connecte au robot en VR et exécute la tâche dans le flux de travail existant pendant un certain temps
- La partie ML est formée sur les données reçues
- , ML
3D
Très souvent, les robots utilisent l'environnement ROS (robot operating system), qui est en fait un cadre de gestion des «nœuds» (nœuds), chacun fournissant une partie des fonctionnalités du robot. En général, il s'agit d'une façon relativement pratique de programmer des robots, qui ressemble à certains égards à l'architecture de microservices des applications Web. Le principal avantage de ROS est la norme de l'industrie et il existe déjà un grand nombre de modules nécessaires pour créer un robot. Même les bras robotiques industriels peuvent avoir un module d'interface ROS.La chose la plus simple est de créer un modèle de pont entre notre partie serveur et ROS. Par exemple, par exemple. Maintenant, notre projet utilise une version plus développée du «nœud» ROS, qui se connecte et interroge le microservice du registre auquel le serveur de relais un robot particulier peut se connecter. Le code source n'est donné qu'à titre d'exemple d'instructions pour l'installation du module ROS. Au début, lorsque vous maîtrisez ce framework (ROS), tout semble assez hostile, mais la documentation est assez bonne, et après quelques semaines, les développeurs commencent à utiliser ses fonctionnalités en toute confiance.D'intéressant - le problème de la compression du flux de données 3D, qui doit être produit directement sur le robot.Ce n'est pas si facile de compresser la carte de profondeur. Même avec un petit degré de compression du flux RVB, une distorsion locale très grave de la luminosité par rapport au vrai en pixels aux frontières ou lors du déplacement d'objets est autorisée. L'œil ne le remarque presque pas, mais dès que les mêmes distorsions sont permises dans la carte de profondeur, lors du rendu 3D tout devient très mauvais: (à partir de l' article )Ces défauts sur les bords gâchent grandement la scène 3D, car il y a juste beaucoup de déchets dans l'air.Nous avons commencé à utiliser la compression image par image - JPEG pour RVB et PNG pour une carte de profondeur avec de petits hacks. Cette méthode comprime le flux 30FPS pour une résolution de scanner 3D de 640x480 à 25 Mbps. Une meilleure compression peut également être fournie si le trafic est critique pour l'application. Il existe des codecs de flux 3D commerciaux qui peuvent également être utilisés pour compresser ce flux.
(à partir de l' article )Ces défauts sur les bords gâchent grandement la scène 3D, car il y a juste beaucoup de déchets dans l'air.Nous avons commencé à utiliser la compression image par image - JPEG pour RVB et PNG pour une carte de profondeur avec de petits hacks. Cette méthode comprime le flux 30FPS pour une résolution de scanner 3D de 640x480 à 25 Mbps. Une meilleure compression peut également être fournie si le trafic est critique pour l'application. Il existe des codecs de flux 3D commerciaux qui peuvent également être utilisés pour compresser ce flux.Contrôle de réalité virtuelle
Après avoir calibré le cadre de référence de la caméra et du robot (et nous avons déjà écrit un article sur le calibrage ), le bras du robot peut être contrôlé en réalité virtuelle. Le contrôleur définit à la fois la position en 3D XYZ et l'orientation. Pour certains roboruk, seules 3 coordonnées suffiront, mais avec un grand nombre de degrés de liberté, l'orientation de l'outil spécifiée par le contrôleur doit également être transmise. De plus, il y a suffisamment de commandes sur les contrôleurs pour exécuter les commandes du robot telles que la mise sous / hors tension de la pompe, le contrôle de la pince, etc.Initialement, il a été décidé d'utiliser le framework JavaScript pour la réalité virtuelle A-frame, basé sur le moteur WebVR. Et les premiers résultats (démonstration vidéo à la fin de l'article pour le bras à 4 coordonnées) ont été obtenus sur le cadre A.En fait, il s'est avéré que WebVR (ou A-frame) était une solution infructueuse pour plusieurs raisons:- compatibilité principalement avec FireFox , et c'est dans FireFox que le cadre A-frame n'a pas libéré de ressources de texture (le reste des navigateurs a copié) jusqu'à ce que la consommation de mémoire atteigne 16 Go.
- interaction limitée avec les contrôleurs VR et le casque. Ainsi, par exemple, il n'a pas été possible d'ajouter des marques supplémentaires avec lesquelles vous pouvez définir la position, par exemple, des coudes de l'opérateur.
- L'application nécessitait du multithreading ou plusieurs processus. Dans un thread / processus, il était nécessaire de déballer les images vidéo, dans un autre - dessiner. En conséquence, tout a été organisé par des travailleurs, mais le temps de déballage a atteint 30 ms, et le rendu en VR devrait être effectué à une fréquence de 90FPS.
Toutes ces lacunes ont entraîné le fait que le rendu du cadre n'a pas eu le temps dans les 10 ms alloués et qu'il y a eu des secousses très désagréables en VR. Probablement, tout pouvait être surmonté, mais l'identité de chaque navigateur était un peu agaçante.Nous avons maintenant décidé de partir pour le port C #, OpenTK et C # de la bibliothèque OpenVR. Il existe encore une alternative: l'unité. Ils écrivent que Unity est pour les débutants ... mais difficile.La chose la plus importante qui devait être trouvée et connue pour gagner en liberté:VRTextureBounds_t bounds = new VRTextureBounds_t() { uMin = 0, vMin = 0, uMax = 1f, vMax = 1f };
OpenVR.Compositor.Submit(EVREye.Eye_Left, ref leftTexture, ref bounds, EVRSubmitFlags.Submit_Default);
OpenVR.Compositor.Submit(EVREye.Eye_Right, ref rightTexture, ref bounds, EVRSubmitFlags.Submit_Default);
(c'est le code pour envoyer deux textures aux yeux gauche et droit du casque)i.e. dessinez dans OpenGL dans la texture ce que différents yeux voient et envoyez-le dans des verres. La joie ne connaissait pas de limites lorsqu'elle s'est avérée remplir l'œil gauche de rouge et la droite de bleu. Juste quelques jours et maintenant la profondeur et la carte RVB provenant de webSocket ont été transférées au modèle polygonal en 10 ms au lieu de 30 sur JS. Et puis il suffit d'interroger les coordonnées et les boutons des contrôleurs, d'entrer dans le système d'événements pour les boutons, de traiter les clics des utilisateurs, d'entrer dans la State Machine pour l'interface utilisateur, et maintenant vous pouvez attraper un verre de l'espresso:Maintenant, la qualité du Realsense D435 est quelque peu déprimante, mais elle passera dès que nous installerons au moins un scanner 3D aussi intéressant de Microsoft , dont le nuage de points est beaucoup plus précis.Du côté serveur
Serveur de relaisL'élément fonctionnel principal est le relais de serveur (serveur au milieu), qui reçoit un flux vidéo du robot avec des images 3D et des lectures de capteur et l'état du robot et le distribue aux consommateurs. Entrer des trames et des lectures de capteur emballées par TCP / IP. La distribution aux consommateurs est effectuée par des sockets Web (un mécanisme très pratique pour le streaming vers plusieurs consommateurs, y compris un navigateur).De plus, le serveur intermédiaire stocke le flux de données dans le stockage cloud S3 afin qu'il puisse ensuite être utilisé pour la formation.Chaque serveur relais prend en charge l'API http, qui vous permet de connaître son état actuel, ce qui est pratique pour surveiller les connexions actuelles.La tâche de relais est assez difficile, à la fois du point de vue de l'informatique et du point de vue du trafic. Par conséquent, nous avons suivi ici la logique selon laquelle les serveurs relais sont déployés sur une variété de serveurs cloud. Et cela signifie que vous devez garder une trace de qui se connecte où (en particulier si les robots et les opérateurs sont dans des régions différentes).S'inscrireLe plus fiable maintenant sera difficile de définir pour chaque robot les serveurs auxquels il peut se connecter (la redondance ne nuira pas). Le service de gestion ML est associé au robot, il interroge le serveur relais pour déterminer celui auquel le robot est connecté et est connecté à celui correspondant, à condition, bien sûr, qu'il dispose de droits suffisants pour cela. L'application de l'opérateur fonctionne de manière similaire.Le plus agréable! Du fait que la formation des robots est un service, le service n'est visible que pour nous à l'intérieur. Ainsi, son frontal peut être aussi pratique que possible pour nous! Ceux. c'est une console dans le navigateur (il y a une bibliothèque terminalJS avec une grande simplicité , qui est très facile à modifier si vous voulez des fonctions supplémentaires, telles que l'auto-complétion TAB ou la lecture de l'historique des appels) et cela ressemble à ceci: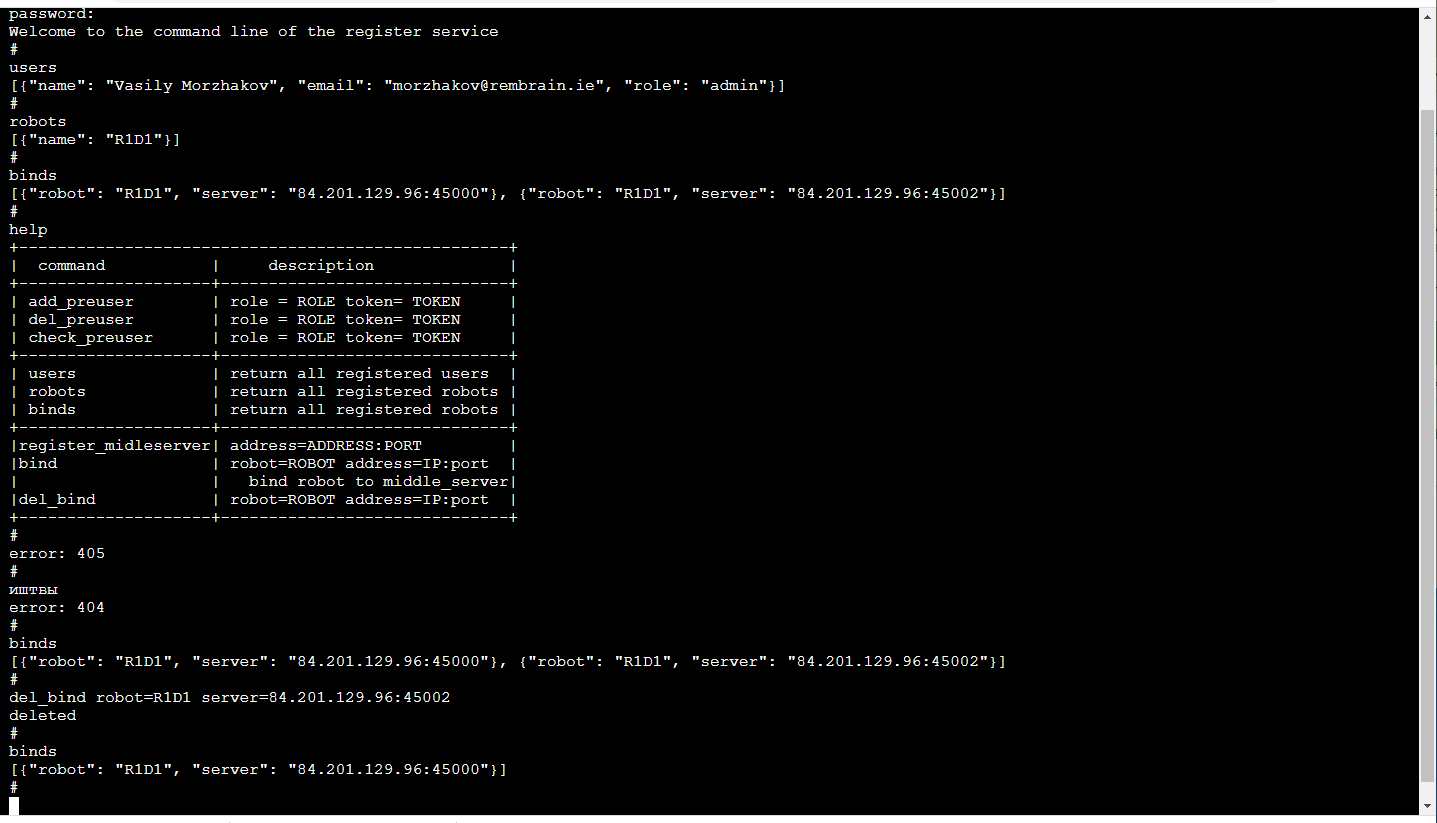 Ceci, bien sûr, est un sujet distinct pour la discussion, pourquoi la ligne de commande Tellement confortable. Soit dit en passant, il est particulièrement pratique de faire des tests unitaires d'un tel frontend.En plus de l'API http, ce service implémente un mécanisme d'enregistrement des utilisateurs avec des jetons temporaires, des opérateurs de connexion / déconnexion, des administrateurs et des robots, un support de session, des clés de cryptage de session pour le cryptage du trafic entre le serveur relais et le robot.Tout cela se fait en Python avec Flask - une pile très proche pour les développeurs ML (c'est-à-dire nous). Oui, en outre, l'infrastructure CI / CD existante pour les microservices est en bons termes avec Flask.
Ceci, bien sûr, est un sujet distinct pour la discussion, pourquoi la ligne de commande Tellement confortable. Soit dit en passant, il est particulièrement pratique de faire des tests unitaires d'un tel frontend.En plus de l'API http, ce service implémente un mécanisme d'enregistrement des utilisateurs avec des jetons temporaires, des opérateurs de connexion / déconnexion, des administrateurs et des robots, un support de session, des clés de cryptage de session pour le cryptage du trafic entre le serveur relais et le robot.Tout cela se fait en Python avec Flask - une pile très proche pour les développeurs ML (c'est-à-dire nous). Oui, en outre, l'infrastructure CI / CD existante pour les microservices est en bons termes avec Flask.Problème de retard
Si nous voulons contrôler les manipulateurs en temps réel, le délai minimum est extrêmement utile. Si le retard devient trop important (plus de 300 ms), il est alors très difficile de contrôler les manipulateurs en fonction de l'image dans le casque virtuel. Dans notre solution, en raison de la compression image par image (c'est-à-dire qu'il n'y a pas de mise en mémoire tampon) et de l'absence d'outils standard comme GStreamer, le retard, même en tenant compte du serveur intermédiaire, est d'environ 150-200 ms. Le temps de transmission sur le réseau d'entre eux est d'environ 80 ms. Le reste du retard est causé par la caméra Realsense D435 et la fréquence de capture limitée.Bien sûr, il s'agit d'un problème de pleine hauteur qui se pose en mode «tracking», lorsque le manipulateur dans sa réalité suit constamment le contrôleur de l'opérateur en réalité virtuelle. Dans le mode de déplacement vers un point XYZ donné, le retard ne pose aucun problème à l'opérateur.Partie ML
Il existe 2 types de services: la gestion et la formation.Le service de formation collecte les données stockées dans le stockage S3 et commence la ré-formation des poids du modèle. A la fin de la formation, des poids sont envoyés au service de gestion.Le service de gestion n'est pas différent en termes de données d'entrée et de sortie de l'application de l'opérateur. De même, le flux d'entrée RGBD (RGB + Depth), les lectures des capteurs et l'état du robot, les commandes de contrôle de sortie. En raison de cette identité, il semble possible de se former dans le cadre du concept de «formation par les données».L'état du robot (et les lectures des capteurs) est une histoire clé pour ML. Il définit le contexte. Par exemple, un robot aura une machine d'état qui est caractéristique de son fonctionnement, ce qui détermine en grande partie le type de contrôle nécessaire. Ces 2 valeurs sont transmises avec chaque trame: le mode de fonctionnement et le vecteur d'état du robot.Et un peu sur la formation:dans la démonstration à la fin de l'article était la tâche de trouver un objet (un cube pour enfants) sur une scène 3D. Il s'agit d'une tâche de base pour les applications pick & place.La formation était basée sur une paire de cadres «avant et après» et une désignation de cible obtenue avec un contrôle manuel: En raison de la présence de deux cartes de profondeur, il était facile de calculer le masque de l'objet déplacé dans le cadre:
En raison de la présence de deux cartes de profondeur, il était facile de calculer le masque de l'objet déplacé dans le cadre: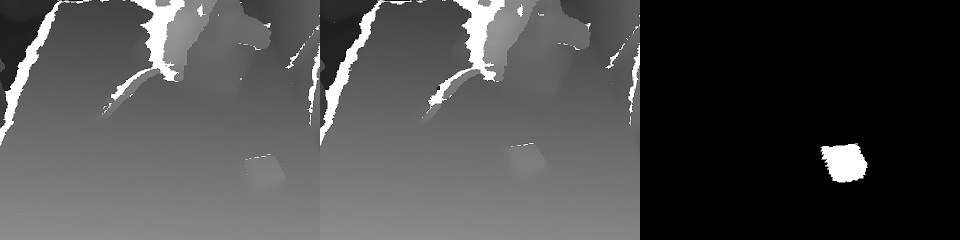 De plus, xyz sont projetés sur le plan de la caméra et vous pouvez sélectionner le voisinage de l'objet capturé:
De plus, xyz sont projetés sur le plan de la caméra et vous pouvez sélectionner le voisinage de l'objet capturé: En fait avec ce quartier et fonctionnera.Nous obtenons d'abord XY en entraînant Unet sur un réseau convolutionnel pour la segmentation des cubes.Ensuite, nous devons déterminer la profondeur et comprendre si l'image est anormale devant nous. Cela se fait en utilisant un encodeur automatique en RVB et un encodeur automatique conditionnel en profondeur.Architecture de modèle pour la formation d'encodeur automatique:
En fait avec ce quartier et fonctionnera.Nous obtenons d'abord XY en entraînant Unet sur un réseau convolutionnel pour la segmentation des cubes.Ensuite, nous devons déterminer la profondeur et comprendre si l'image est anormale devant nous. Cela se fait en utilisant un encodeur automatique en RVB et un encodeur automatique conditionnel en profondeur.Architecture de modèle pour la formation d'encodeur automatique: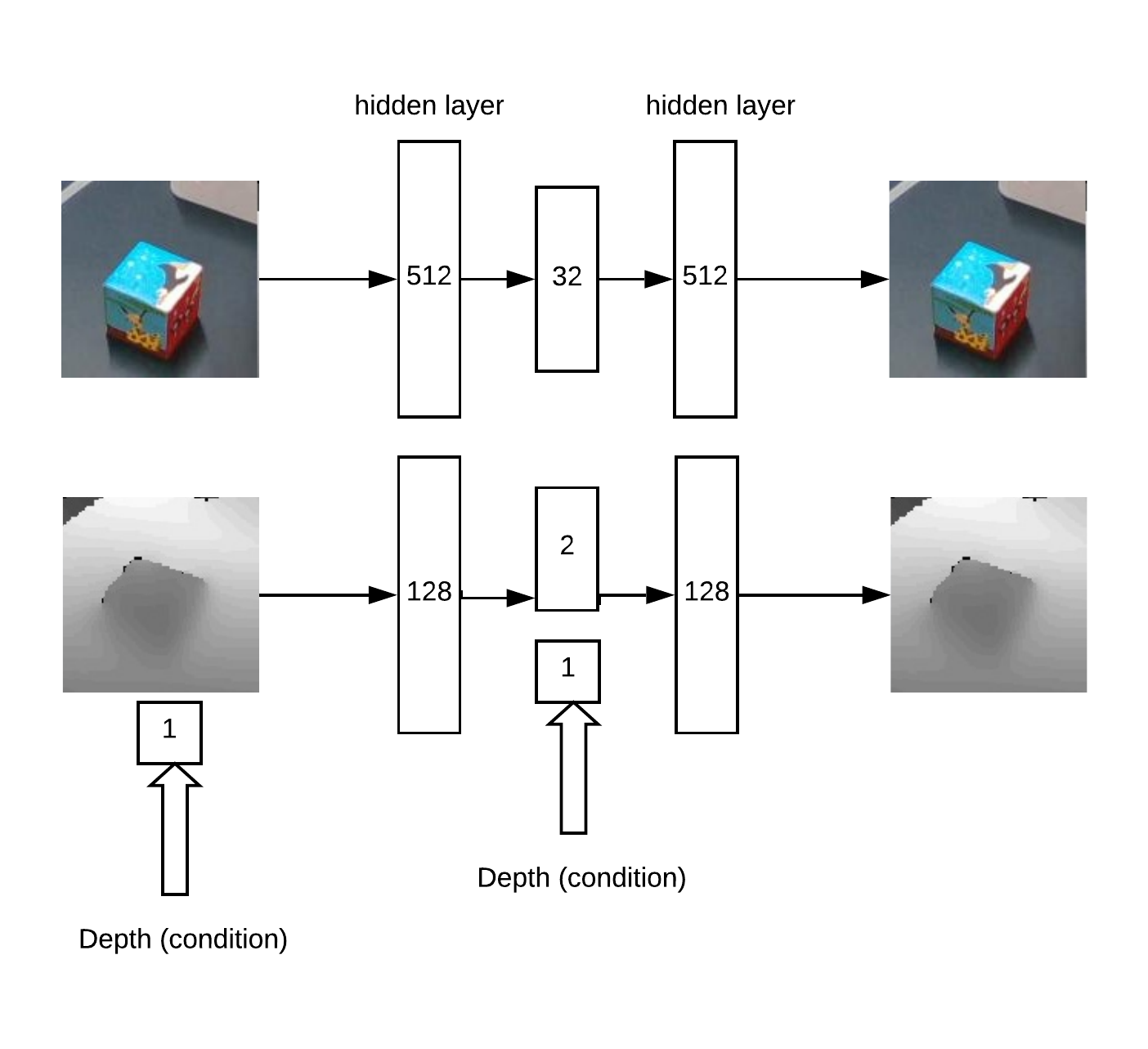 En conséquence, la logique de travail:
En conséquence, la logique de travail:- rechercher un maximum sur la «heat map» (déterminer les coordonnées angulaires u = x / zv = y / z de l'objet) qui dépasse le seuil
- puis l'auto-encodeur reconstruit le voisinage du point trouvé pour toutes les hypothèses en profondeur (avec un pas donné de min_depth à max_depth) et sélectionne la profondeur à laquelle l'écart entre la reconstruction et l'entrée est minime
- Ayant les coordonnées angulaires u, v et la profondeur, vous pouvez obtenir les coordonnées x, y, z
Un exemple de reconstruction d'auto-encodeur d'une carte de profondeurs de cube avec une profondeur correctement définie: En partie, l'idée d'une méthode de recherche de profondeur est basée sur un article sur les ensembles d'auto-encodeurs .Cette approche fonctionne bien pour des objets de formes diverses.Mais, en général, il existe de nombreuses approches différentes pour trouver un objet XYZ à partir d'une image RGBD. Bien entendu, il est nécessaire en pratique et sur une grande quantité de données de choisir la méthode la plus précise.Il y avait aussi la tâche de détecter les anomalies, pour cela nous avons besoin d'un réseau convolutionnel de segmentation pour apprendre des masques disponibles. Ensuite, selon ce masque, vous pouvez évaluer la précision de la reconstruction de l'encodeur automatique dans la carte de profondeur et RVB. En raison de cet écart, on peut décider de la présence d'une anomalie.Grâce à cette méthode, il est possible de détecter l'apparition d'objets précédemment invisibles dans la trame, qui sont néanmoins détectés par l'algorithme de recherche principal.
En partie, l'idée d'une méthode de recherche de profondeur est basée sur un article sur les ensembles d'auto-encodeurs .Cette approche fonctionne bien pour des objets de formes diverses.Mais, en général, il existe de nombreuses approches différentes pour trouver un objet XYZ à partir d'une image RGBD. Bien entendu, il est nécessaire en pratique et sur une grande quantité de données de choisir la méthode la plus précise.Il y avait aussi la tâche de détecter les anomalies, pour cela nous avons besoin d'un réseau convolutionnel de segmentation pour apprendre des masques disponibles. Ensuite, selon ce masque, vous pouvez évaluer la précision de la reconstruction de l'encodeur automatique dans la carte de profondeur et RVB. En raison de cet écart, on peut décider de la présence d'une anomalie.Grâce à cette méthode, il est possible de détecter l'apparition d'objets précédemment invisibles dans la trame, qui sont néanmoins détectés par l'algorithme de recherche principal.Manifestation
La vérification et le débogage de l'ensemble de la plateforme logicielle créée ont été effectués sur le stand:- Caméra 3D Realsense D435
- 4 coordonnées Dobot Magicien
- Casque VR HTC Vive
- Serveurs sur Yandex Cloud (réduit la latence par rapport au cloud AWS)
Dans la vidéo, nous enseignons comment trouver un cube dans une scène 3D en effectuant une tâche dans VR pick & place. Une cinquantaine d'exemples suffisaient pour s'entraîner sur un cube. Ensuite, l'objet change et environ 30 autres exemples sont affichés. Après le recyclage, le robot peut trouver un nouvel objet.L'ensemble du processus a pris environ 15 minutes, dont environ la moitié du poids du modèle d'entraînement.Et dans cette vidéo, YuMi contrôle en VR. Pour apprendre à manipuler des objets, vous devez évaluer l'orientation et l'emplacement de l'outil. Les mathématiques reposent sur un principe similaire, mais en sont maintenant au stade des tests et du développement.Conclusion
Le Big Data et le Deep Learning ne sont pas tout.Nous modifions l'approche de l'apprentissage, évoluant vers la façon dont les gens apprennent de nouvelles choses - en répétant ce qu'ils voient.L'appareil mathématique «sous le capot», que nous développerons sur des applications réelles, vise le problème de l'interprétation et du contrôle contextuels. Le contexte ici est des informations naturelles disponibles à partir de capteurs de robot ou des informations externes sur le processus actuel.Et, plus nous maîtrisons les processus technologiques, plus la structure du «cerveau dans les nuages» sera développée et ses parties individuelles seront formées.Points forts de cette approche:- la possibilité d'apprendre à manipuler des objets variables
- apprendre dans un environnement en évolution (par exemple, robots mobiles)
- tâches mal structurées
- délai de mise sur le marché court; Vous pouvez effectuer la cible même en mode manuel en utilisant les opérateurs
Limitation:- besoin d'Internet fiable et bon
- des méthodes supplémentaires sont nécessaires pour atteindre une grande précision, par exemple, des caméras dans le manipulateur lui-même
Nous travaillons actuellement sur l'application de notre approche à la tâche de sélection et de placement standard de divers objets. Mais il nous semble (naturellement!) Qu'il est capable de plus. Avez-vous d'autres idées pour vous essayer?Merci de votre attention!