HighLoad ++, Mikhail Makurov, Maxim Chernetsov (Intersvyaz): Zabbix, 100kNVPS sur un serveur
La prochaine conférence HighLoad ++ se tiendra les 6 et 7 avril 2020 à Saint-Pétersbourg, détails et billets ici . HighLoad ++ Moscou 2018. Salle de Moscou. 9 novembre, 15 h Résumés et présentation . * Surveillance - en ligne et analytique.* Les principales limitations de la plateforme ZABBIX.* Solution pour faire évoluer le stockage analytique.* Optimisation du serveur ZABBIX.* Optimisation de l'interface utilisateur.* Expérience dans le fonctionnement du système avec des charges de plus de 40 000 NVPS.* Brièvement conclusions.Mikhail Makurov (ci-après - MM): - Bonjour à tous!Maxim Chernetsov (ci-après - MCH): - Bonjour!MM: - Permettez-moi de vous présenter Maxim. Max est un ingénieur talentueux, le meilleur réseauteur que je connaisse. Maxim s'occupe des réseaux et des services, de leur développement et de leur fonctionnement.
* Surveillance - en ligne et analytique.* Les principales limitations de la plateforme ZABBIX.* Solution pour faire évoluer le stockage analytique.* Optimisation du serveur ZABBIX.* Optimisation de l'interface utilisateur.* Expérience dans le fonctionnement du système avec des charges de plus de 40 000 NVPS.* Brièvement conclusions.Mikhail Makurov (ci-après - MM): - Bonjour à tous!Maxim Chernetsov (ci-après - MCH): - Bonjour!MM: - Permettez-moi de vous présenter Maxim. Max est un ingénieur talentueux, le meilleur réseauteur que je connaisse. Maxim s'occupe des réseaux et des services, de leur développement et de leur fonctionnement. MCH: - Et je voudrais parler de Michael. Michael est un développeur C. Il a écrit des solutions de traitement du trafic très chargées pour notre entreprise. Nous vivons et travaillons dans l'Oural, dans la ville des paysans sévères de Tcheliabinsk, dans la société Intersvyaz. Notre entreprise est un fournisseur de services Internet et de télévision par câble pour un million de personnes dans 16 villes.MM:- Et il vaut la peine de dire qu'Intersvyaz est bien plus qu'un simple fournisseur, c'est une entreprise informatique. La plupart de nos décisions sont prises par notre service informatique.R: des serveurs qui traitent le trafic au centre d'appels et à l'application mobile. Le service informatique compte environ 80 personnes aux compétences très, très diverses.
MCH: - Et je voudrais parler de Michael. Michael est un développeur C. Il a écrit des solutions de traitement du trafic très chargées pour notre entreprise. Nous vivons et travaillons dans l'Oural, dans la ville des paysans sévères de Tcheliabinsk, dans la société Intersvyaz. Notre entreprise est un fournisseur de services Internet et de télévision par câble pour un million de personnes dans 16 villes.MM:- Et il vaut la peine de dire qu'Intersvyaz est bien plus qu'un simple fournisseur, c'est une entreprise informatique. La plupart de nos décisions sont prises par notre service informatique.R: des serveurs qui traitent le trafic au centre d'appels et à l'application mobile. Le service informatique compte environ 80 personnes aux compétences très, très diverses.À propos de Zabbix et de son architecture
MCH: - Et maintenant, je vais essayer d'établir un record personnel et dire en une minute ce qu'est Zabbix (ci-après - "Zabbiks").Zabbix se positionne comme un système de surveillance «prêt à l'emploi» au niveau de l'entreprise. Il possède de nombreuses fonctionnalités simplifiant la vie: règles avancées d'escalade, API pour l'intégration, le regroupement et la détection automatique des hôtes et des métriques. Dans Zabbix, il existe ce que l'on appelle des outils de mise à l'échelle - des proxys. Zabbix est un système open source.Brièvement sur l'architecture. On peut dire qu'il se compose de trois éléments: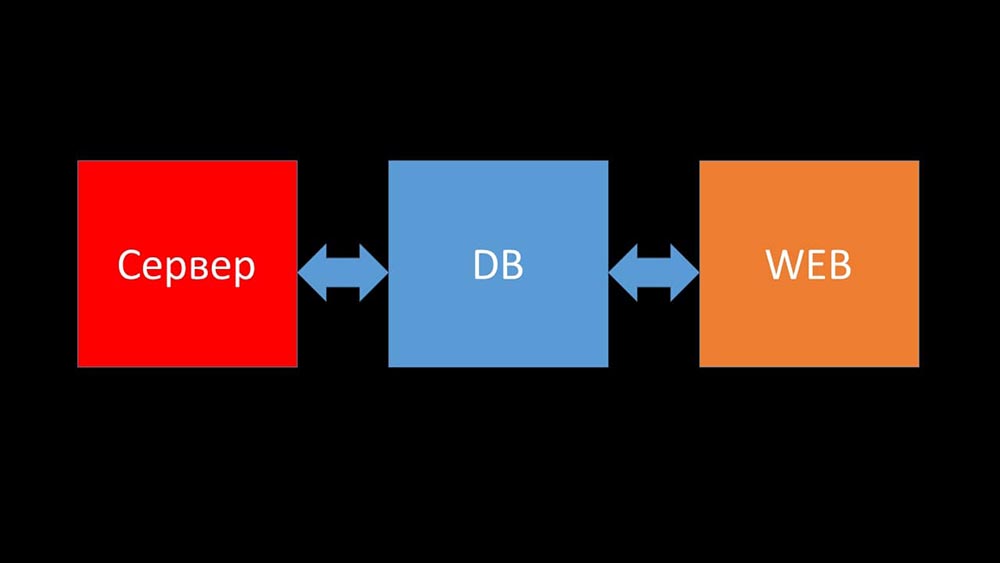
- Serveur. Il est écrit en C. Avec un traitement et une transmission des informations assez compliqués entre les flux. Tout le traitement y a lieu: de la réception à l'enregistrement dans la base de données.
- Toutes les données sont stockées dans la base de données. Zabbix prend en charge MySQL, PostreSQL et Oracle.
- L'interface Web est écrite en PHP. Sur la plupart des systèmes, il est livré avec un serveur Apache, mais fonctionne plus efficacement dans le bundle nginx + php.
Aujourd'hui, nous aimerions raconter de la vie de notre entreprise une histoire liée à Zabbix ...Histoire de vie de la société Intersvyaz. De quoi disposons-nous et de quoi avons-nous besoin?
 Il y a 5 ou 6 mois. Une fois après le travail ...MCH: - Misha, bonjour! Heureux d'avoir réussi à vous attraper - il y a une conversation. Nous avons de nouveau eu des problèmes de surveillance. Lors d'un accident majeur, tout a ralenti et il n'y avait aucune information sur l'état du réseau. Malheureusement, ce n'est pas la première fois répété. J'ai besoin de ton aide. Faisons en sorte que notre surveillance fonctionne en toutes circonstances!MM: - Mais synchronisons d'abord. Je n'y ai pas cherché depuis quelques années. Pour autant que je m'en souvienne, nous avons refusé Nagios et sommes passés à Zabbix il y a 8 ans. Et maintenant, il semble que nous ayons 6 serveurs puissants et une douzaine de serveurs proxy. Suis-je confus?MCH:- Presque. 15 serveurs, dont certains sont des machines virtuelles. Plus important encore, cela ne nous sauve pas au moment où nous en avons le plus besoin. Comme un accident - les serveurs ralentissent et rien n'est visible. Nous avons essayé d'optimiser la configuration, mais cela ne donne pas le gain de performances optimal.MM: - Je vois. Avez-vous regardé quelque chose, avez-vous trouvé quelque chose dans le diagnostic?MCH:- La première chose à laquelle vous devez faire face est simplement la base de données. MySQL est donc constamment chargé, préservant de nouvelles métriques, et lorsque Zabbix commence à générer un tas d'événements, la base de données entre littéralement pendant plusieurs heures. Je vous ai déjà parlé de l'optimisation de la configuration, mais littéralement cette année, nous avons mis à jour le matériel: il y a plus d'une centaine de gigaoctets de mémoire sur les serveurs et les baies de disques sur SSD RAID-ahs - cela n'a pas de sens de le développer de manière linéaire. Qu'est-ce qu'on fait?MM: - Je vois. En général, MySQL est une base de données LTP. Apparemment, il ne convient plus pour stocker une archive de métriques de notre taille. Voyons cela.MCH: - Allez!
Il y a 5 ou 6 mois. Une fois après le travail ...MCH: - Misha, bonjour! Heureux d'avoir réussi à vous attraper - il y a une conversation. Nous avons de nouveau eu des problèmes de surveillance. Lors d'un accident majeur, tout a ralenti et il n'y avait aucune information sur l'état du réseau. Malheureusement, ce n'est pas la première fois répété. J'ai besoin de ton aide. Faisons en sorte que notre surveillance fonctionne en toutes circonstances!MM: - Mais synchronisons d'abord. Je n'y ai pas cherché depuis quelques années. Pour autant que je m'en souvienne, nous avons refusé Nagios et sommes passés à Zabbix il y a 8 ans. Et maintenant, il semble que nous ayons 6 serveurs puissants et une douzaine de serveurs proxy. Suis-je confus?MCH:- Presque. 15 serveurs, dont certains sont des machines virtuelles. Plus important encore, cela ne nous sauve pas au moment où nous en avons le plus besoin. Comme un accident - les serveurs ralentissent et rien n'est visible. Nous avons essayé d'optimiser la configuration, mais cela ne donne pas le gain de performances optimal.MM: - Je vois. Avez-vous regardé quelque chose, avez-vous trouvé quelque chose dans le diagnostic?MCH:- La première chose à laquelle vous devez faire face est simplement la base de données. MySQL est donc constamment chargé, préservant de nouvelles métriques, et lorsque Zabbix commence à générer un tas d'événements, la base de données entre littéralement pendant plusieurs heures. Je vous ai déjà parlé de l'optimisation de la configuration, mais littéralement cette année, nous avons mis à jour le matériel: il y a plus d'une centaine de gigaoctets de mémoire sur les serveurs et les baies de disques sur SSD RAID-ahs - cela n'a pas de sens de le développer de manière linéaire. Qu'est-ce qu'on fait?MM: - Je vois. En général, MySQL est une base de données LTP. Apparemment, il ne convient plus pour stocker une archive de métriques de notre taille. Voyons cela.MCH: - Allez!Intégration de Zabbix et Clickhouse à la suite d'un hackathon
Après un certain temps, nous avons reçu des données intéressantes: la majeure partie de l'espace dans notre base de données était occupée par l'archive des métriques et moins de 1% était utilisé pour la configuration, les modèles et les paramètres. À ce moment-là, nous exploitions depuis plus d'un an la solution Big data basée sur Clickhouse. La direction du mouvement était évidente pour nous. Lors de notre Hackathon de printemps, il a écrit l'intégration de Zabbix avec Clickhouse pour le serveur et le frontend. À cette époque, Zabbix avait déjà un support pour ElasticSearch, et nous avons décidé de les comparer.
majeure partie de l'espace dans notre base de données était occupée par l'archive des métriques et moins de 1% était utilisé pour la configuration, les modèles et les paramètres. À ce moment-là, nous exploitions depuis plus d'un an la solution Big data basée sur Clickhouse. La direction du mouvement était évidente pour nous. Lors de notre Hackathon de printemps, il a écrit l'intégration de Zabbix avec Clickhouse pour le serveur et le frontend. À cette époque, Zabbix avait déjà un support pour ElasticSearch, et nous avons décidé de les comparer.
Comparez Clickhouse et Elasticsearch
MM: - A titre de comparaison, nous avons généré la même charge que le serveur Zabbix fournit et regardé comment les systèmes se comporteraient. Nous avons écrit des données par lots de 1 000 lignes, en utilisant CURL. Nous avions précédemment suggéré que le Clickhouse serait plus efficace pour le profil de charge que fait Zabbix. Les résultats ont même dépassé nos attentes: dans les mêmes conditions de test, le Clickhouse a écrit trois fois plus de données. Dans le même temps, les deux systèmes ont consommé très efficacement (une petite quantité de ressources) lors de la lecture des données. Mais «Elastix» nécessitait une grande quantité de processeur lors de l'enregistrement:Au total, Clickhouse a largement dépassé Elastix en termes de consommation et de vitesse du processeur. En même temps, en raison de la compression des données, «Clickhouse» utilise 11 fois moins sur le disque dur et fait environ 30 fois moins d'opérations sur le disque:
dans les mêmes conditions de test, le Clickhouse a écrit trois fois plus de données. Dans le même temps, les deux systèmes ont consommé très efficacement (une petite quantité de ressources) lors de la lecture des données. Mais «Elastix» nécessitait une grande quantité de processeur lors de l'enregistrement:Au total, Clickhouse a largement dépassé Elastix en termes de consommation et de vitesse du processeur. En même temps, en raison de la compression des données, «Clickhouse» utilise 11 fois moins sur le disque dur et fait environ 30 fois moins d'opérations sur le disque: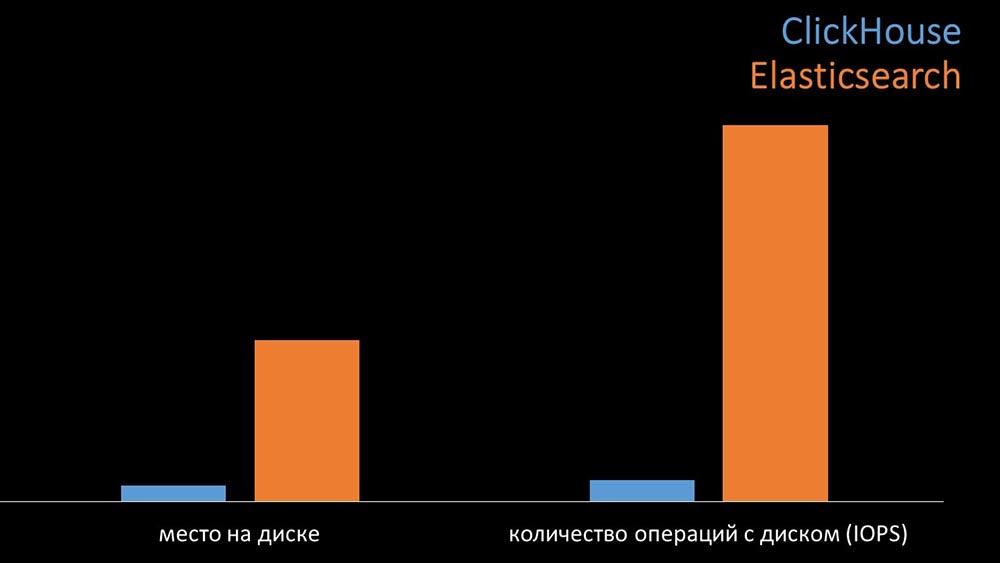 MCH: - Oui, travailler avec le sous-système de disque à «Clickhouse» est très efficace. Sous les bases, vous pouvez utiliser d'énormes disques SATA et obtenir une vitesse d'écriture de centaines de milliers de lignes par seconde. Le système "prêt à l'emploi" prend en charge le sharding, la réplication, il est très facile à configurer. Nous sommes plus que satisfaits de son fonctionnement depuis un an.Pour optimiser les ressources, vous pouvez installer "Clickhouse" à côté de la base principale existante et ainsi économiser beaucoup de temps processeur et d'opérations sur le disque. Nous avons retiré l'archive des métriques des clusters «Clickhouse» existants:
MCH: - Oui, travailler avec le sous-système de disque à «Clickhouse» est très efficace. Sous les bases, vous pouvez utiliser d'énormes disques SATA et obtenir une vitesse d'écriture de centaines de milliers de lignes par seconde. Le système "prêt à l'emploi" prend en charge le sharding, la réplication, il est très facile à configurer. Nous sommes plus que satisfaits de son fonctionnement depuis un an.Pour optimiser les ressources, vous pouvez installer "Clickhouse" à côté de la base principale existante et ainsi économiser beaucoup de temps processeur et d'opérations sur le disque. Nous avons retiré l'archive des métriques des clusters «Clickhouse» existants: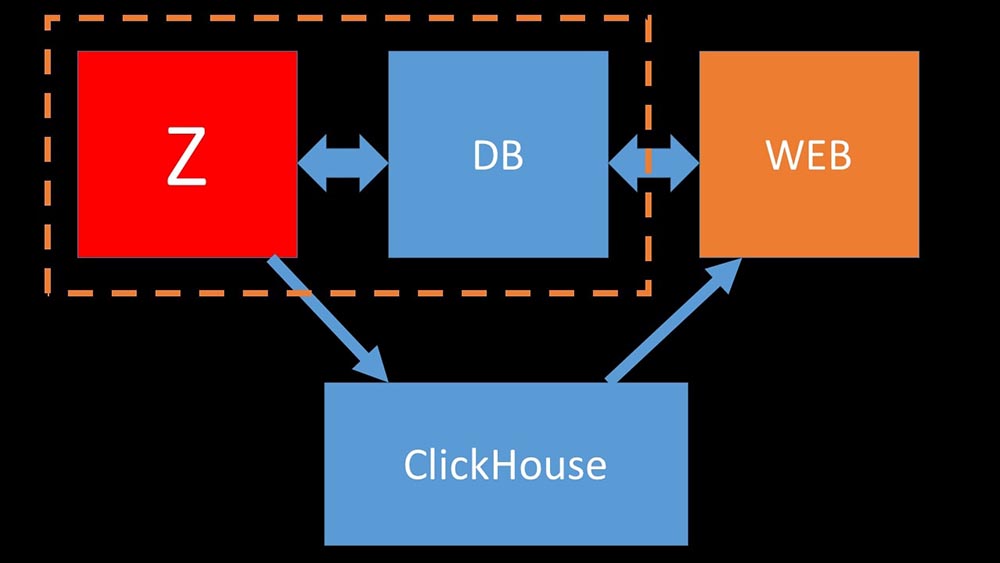 Nous avons tellement déchargé la base de données MySQL principale que nous avons pu la combiner sur la même machine avec le serveur Zabbix et abandonner le serveur dédié pour MySQL.
Nous avons tellement déchargé la base de données MySQL principale que nous avons pu la combiner sur la même machine avec le serveur Zabbix et abandonner le serveur dédié pour MySQL.Comment fonctionne le sondage dans Zabbix?
Il y a 4 moisMM: - Eh bien, vous pouvez oublier les problèmes avec la base?MCH: - C'est sûr! Un autre problème que nous devons résoudre est la collecte lente des données. Désormais, nos 15 procurations sont surchargées de processus SNMP et d'interrogation. Et il n'y a rien d'autre que la mise en place de nouveaux et nouveaux serveurs.MM: - Génial. Mais d'abord, dites-moi comment fonctionne le sondage dans Zabbix.MCH: - En bref, il existe 20 types de métriques et une douzaine de façons de les obtenir. Zabbix peut collecter des données soit en mode "demande-réponse", soit attendre de nouvelles données via "l'interface de trappeur". Il convient de noter que dans le Zabbix d'origine, cette méthode (Trapper) est la plus rapide.Il existe des proxys pour l'équilibrage de charge:
Il convient de noter que dans le Zabbix d'origine, cette méthode (Trapper) est la plus rapide.Il existe des proxys pour l'équilibrage de charge: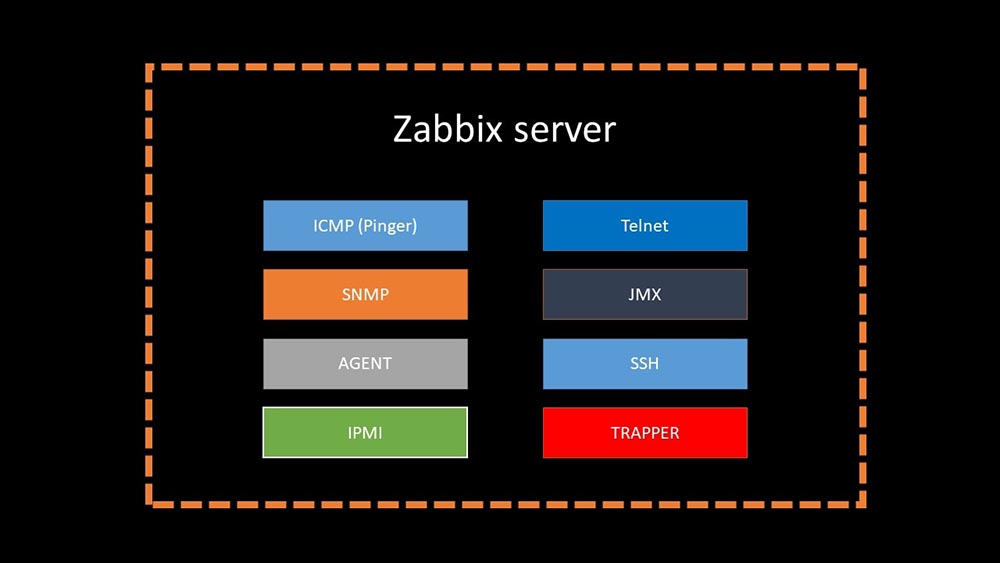 Les proxys peuvent exécuter les mêmes fonctions de collecte que le serveur Zabbix, en recevant des tâches de celui-ci et en envoyant des métriques collectées via l'interface Trapper. Il s'agit de la méthode d'équilibrage de charge officiellement recommandée. De plus, les proxys sont utiles pour surveiller une infrastructure distante qui fonctionne via NAT ou un canal lent:
Les proxys peuvent exécuter les mêmes fonctions de collecte que le serveur Zabbix, en recevant des tâches de celui-ci et en envoyant des métriques collectées via l'interface Trapper. Il s'agit de la méthode d'équilibrage de charge officiellement recommandée. De plus, les proxys sont utiles pour surveiller une infrastructure distante qui fonctionne via NAT ou un canal lent: MM: - Tout est clair avec l'architecture. Il faut regarder la source ...Quelques jours plus tard
MM: - Tout est clair avec l'architecture. Il faut regarder la source ...Quelques jours plus tardRécit de la victoire de nmap fping
MM: - Il semble que j'ai déterré quelque chose.MCH: - Dis-moi!MM: - J'ai trouvé que lors des vérifications de disponibilité, Zabbix vérifie jusqu'à 128 hôtes à la fois. J'ai essayé d'augmenter ce chiffre à 500 et j'ai supprimé l'intervalle entre les paquets dans leur ping (ping) - cela a augmenté les performances d'un facteur deux. Mais je voudrais de gros chiffres.MCH: - Dans ma pratique, je dois parfois vérifier la disponibilité de milliers d'hôtes, et je n'ai rien vu de plus rapide que nmap. Je suis sûr que c'est le moyen le plus rapide. Essayons! Vous devez augmenter considérablement le nombre d'hôtes en une seule itération.MM: - Vérifiez plus de cinq cents? 600?MCH: - Au moins quelques milliers.MM:- D'accord. La chose la plus importante que je voulais dire: j'ai trouvé que la plupart des sondages dans Zabbix se faisaient de manière synchrone. Nous devons le refaire de manière asynchrone. Ensuite, nous pouvons augmenter considérablement le nombre de métriques collectées par les sondeurs, surtout si nous augmentons le nombre de métriques en une seule itération.MCH: - Génial! Et quand?MM: - Comme d'habitude, hier.MCH: - Nous avons comparé les deux versions de fping et nmap: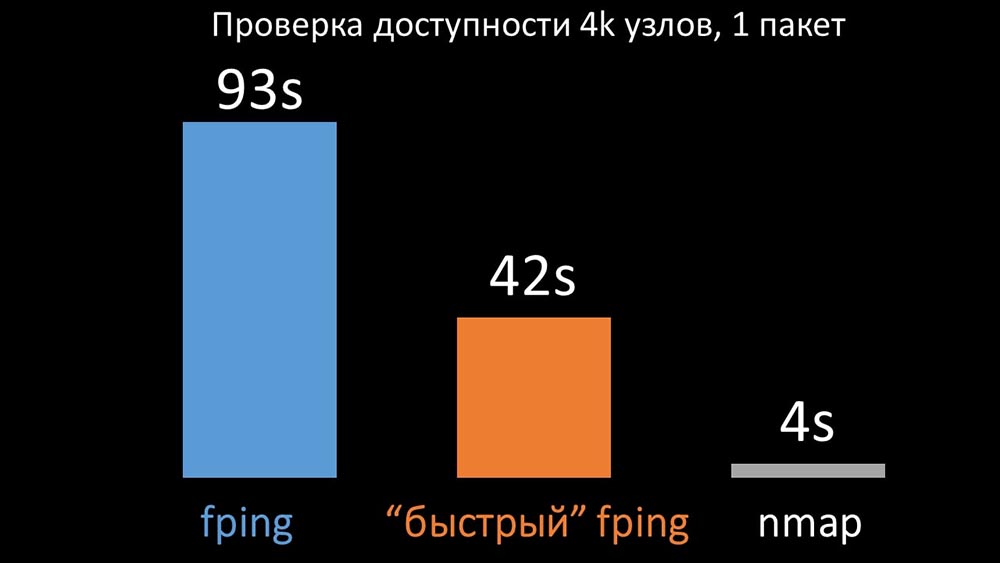 Sur un grand nombre d'hôtes, nmap devait être jusqu'à cinq fois plus efficace. Étant donné que nmap vérifie uniquement le fait de la disponibilité et du temps de réponse, nous avons transféré le calcul de la perte aux déclencheurs et réduit considérablement les intervalles de contrôle de disponibilité. Nous avons trouvé le nombre optimal d'hôtes pour nmap dans la région de 4 000 par itération. Nmap nous a permis de réduire les coûts du processeur pour les contrôles de disponibilité de trois fois et de réduire l'intervalle de 120 secondes à 10.
Sur un grand nombre d'hôtes, nmap devait être jusqu'à cinq fois plus efficace. Étant donné que nmap vérifie uniquement le fait de la disponibilité et du temps de réponse, nous avons transféré le calcul de la perte aux déclencheurs et réduit considérablement les intervalles de contrôle de disponibilité. Nous avons trouvé le nombre optimal d'hôtes pour nmap dans la région de 4 000 par itération. Nmap nous a permis de réduire les coûts du processeur pour les contrôles de disponibilité de trois fois et de réduire l'intervalle de 120 secondes à 10.Optimisation de l'interrogation
MM: - Ensuite, nous sommes allés chercher des sondeurs. Nous étions principalement intéressés par l'élimination et les agents SNMP. À Zabbix, l'interrogation a été effectuée de manière synchrone et des mesures spéciales ont été prises afin d'augmenter l'efficacité du système. En mode synchrone, l'indisponibilité de l'hôte entraîne une dégradation importante de l'interrogation. Il y a tout un système d'états, il y a des processus spéciaux - les pollers dits inaccessibles, qui ne fonctionnent qu'avec des hôtes inaccessibles: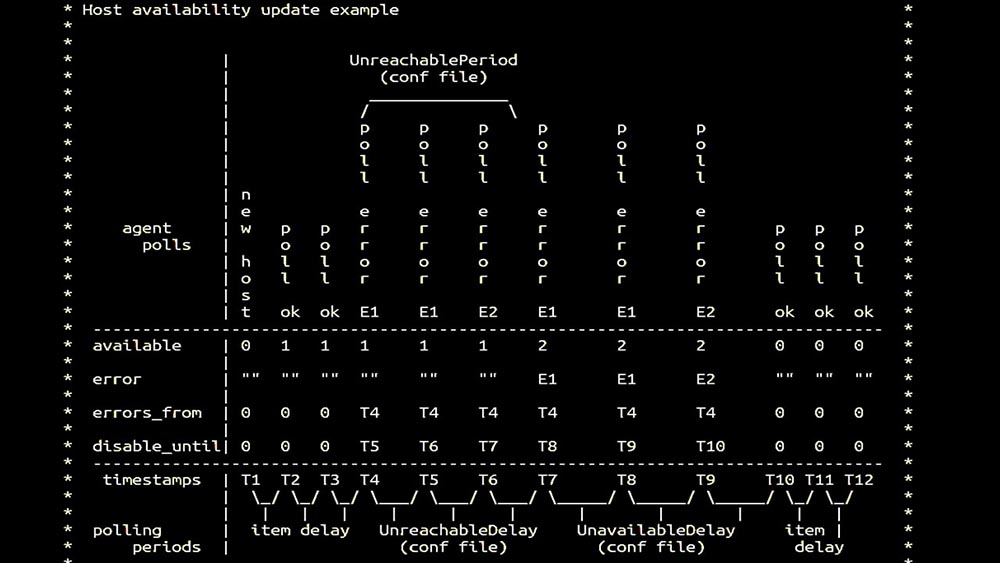 c'est un commentaire qui montre la matrice d'état, la complexité du système de transition qui est nécessaire pour que le système reste efficace. De plus, l'interrogation synchrone elle-même est plutôt lente:
c'est un commentaire qui montre la matrice d'état, la complexité du système de transition qui est nécessaire pour que le système reste efficace. De plus, l'interrogation synchrone elle-même est plutôt lente: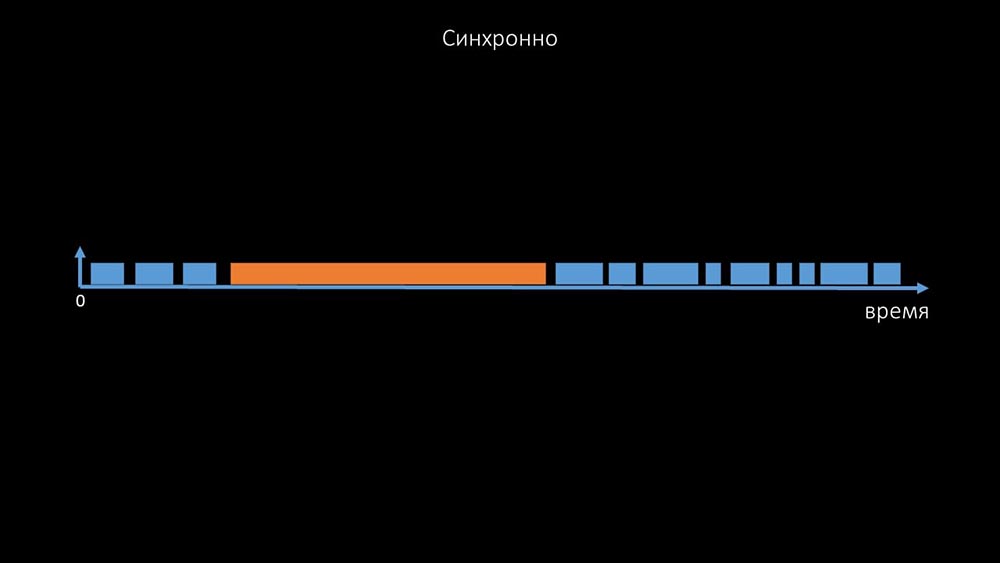 C'est pourquoi des milliers de fils d'interrogation sur une douzaine de procurations n'ont pas pu collecter la quantité de données nécessaire pour nous. L'implémentation asynchrone a résolu non seulement les problèmes avec le nombre de threads, mais a également considérablement simplifié le système d'état des hôtes inaccessibles, car pour tout nombre vérifié dans une itération d'interrogation, le temps d'attente maximal était de 1 timeout: En
C'est pourquoi des milliers de fils d'interrogation sur une douzaine de procurations n'ont pas pu collecter la quantité de données nécessaire pour nous. L'implémentation asynchrone a résolu non seulement les problèmes avec le nombre de threads, mais a également considérablement simplifié le système d'état des hôtes inaccessibles, car pour tout nombre vérifié dans une itération d'interrogation, le temps d'attente maximal était de 1 timeout: En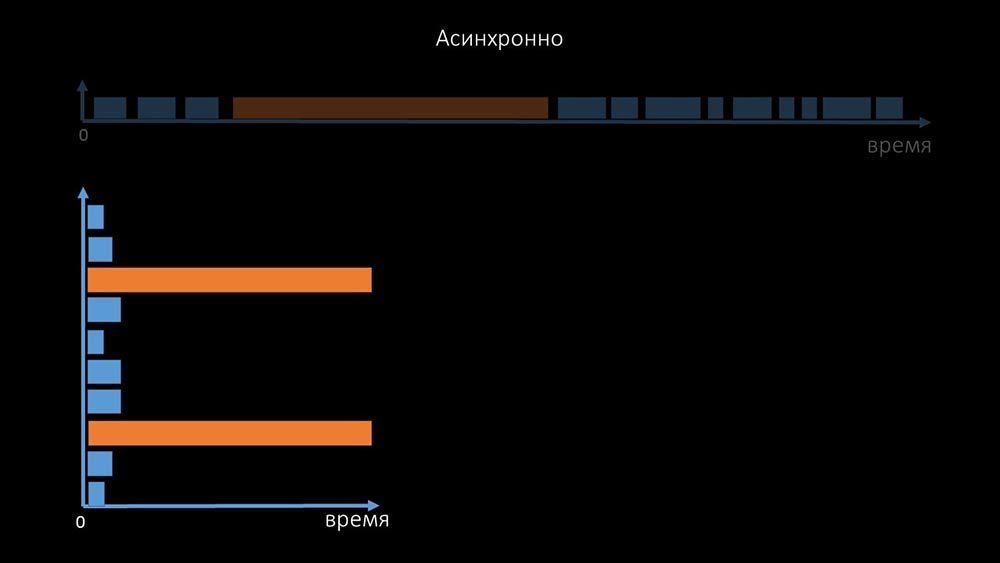 outre, nous avons modifié et amélioré le système d'interrogation pour SNMP- requêtes. Le fait est que la plupart ne peuvent pas répondre à plusieurs demandes SNMP en même temps. Par conséquent, nous avons créé un mode hybride lorsque l'interrogation SNMP du même hôte se fait de manière asynchrone:
outre, nous avons modifié et amélioré le système d'interrogation pour SNMP- requêtes. Le fait est que la plupart ne peuvent pas répondre à plusieurs demandes SNMP en même temps. Par conséquent, nous avons créé un mode hybride lorsque l'interrogation SNMP du même hôte se fait de manière asynchrone: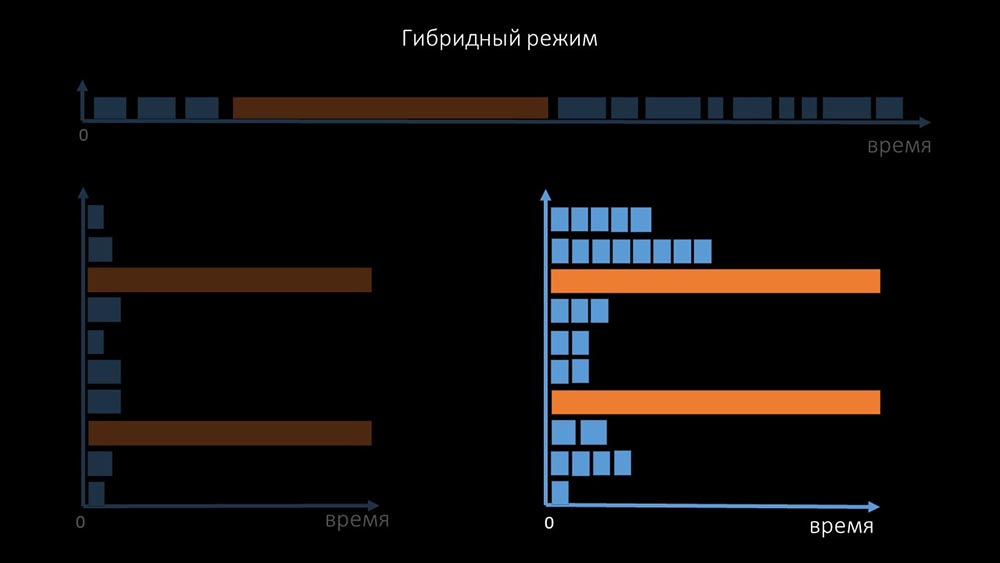 cela se fait pour l'ensemble du groupe d'hôtes. Ce mode n'est finalement pas plus lent que complètement asynchrone, car l'interrogation d'une centaine et demi de valeurs SNMP est encore beaucoup plus rapide qu'un délai d'expiration.Nos expériences ont montré que le nombre optimal de demandes en une itération est d'environ 8 000 avec l'interrogation SNMP. Au total, le passage en mode asynchrone a permis d'accélérer les performances d'interrogation de 200 fois, plusieurs centaines de fois.MCH: - Les optimisations d'interrogation obtenues ont montré que nous pouvons non seulement nous débarrasser de tous les mandataires, mais également réduire les intervalles pour de nombreux contrôles, et les mandataires ne seront pas nécessaires pour partager la charge.Il y a environ trois mois
cela se fait pour l'ensemble du groupe d'hôtes. Ce mode n'est finalement pas plus lent que complètement asynchrone, car l'interrogation d'une centaine et demi de valeurs SNMP est encore beaucoup plus rapide qu'un délai d'expiration.Nos expériences ont montré que le nombre optimal de demandes en une itération est d'environ 8 000 avec l'interrogation SNMP. Au total, le passage en mode asynchrone a permis d'accélérer les performances d'interrogation de 200 fois, plusieurs centaines de fois.MCH: - Les optimisations d'interrogation obtenues ont montré que nous pouvons non seulement nous débarrasser de tous les mandataires, mais également réduire les intervalles pour de nombreux contrôles, et les mandataires ne seront pas nécessaires pour partager la charge.Il y a environ trois moisChangez l'architecture - augmentez la charge!
MM: - Eh bien, Max, est-il temps d'être productif? J'ai besoin d'un serveur puissant et d'un bon ingénieur.MCH: - Eh bien, nous planifions. Il est temps de décoller à 5 000 métriques par seconde.Le matin après la mise à niveau deMCH: - Misha, nous avons mis à jour, mais avons reculé le matin ... Devinez quelle vitesse vous avez atteint?MM: - Mille 20 maximum.MCH: - Ouais, 25 ans! Malheureusement, nous sommes là où nous avons commencé.MM: - Et alors? Avez-vous reçu des diagnostics?MCH: - Oui, bien sûr! Voici, par exemple, un top intéressant: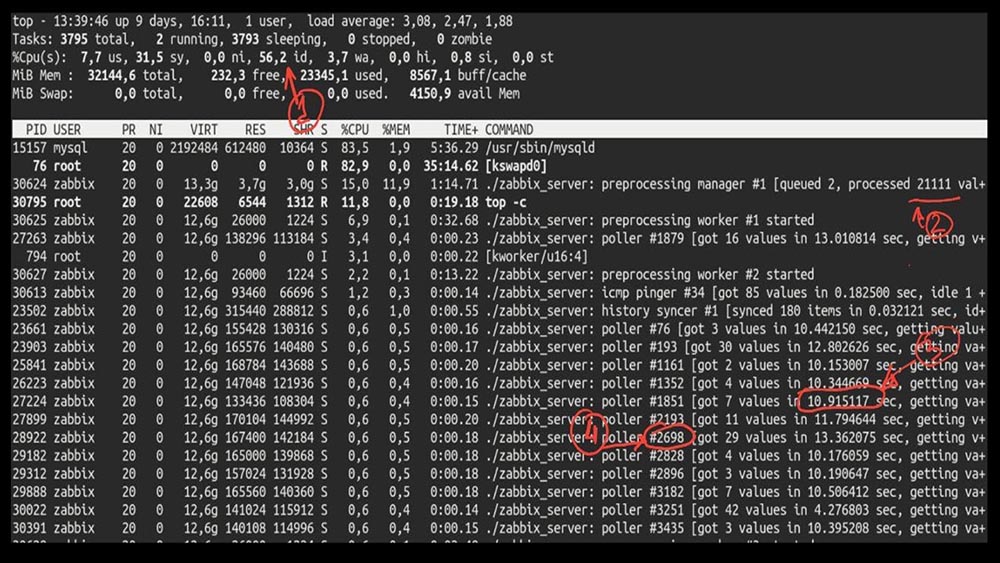 MM: - Voyons voir. Je vois que nous avons essayé un grand nombre de fils d'interrogation:
MM: - Voyons voir. Je vois que nous avons essayé un grand nombre de fils d'interrogation: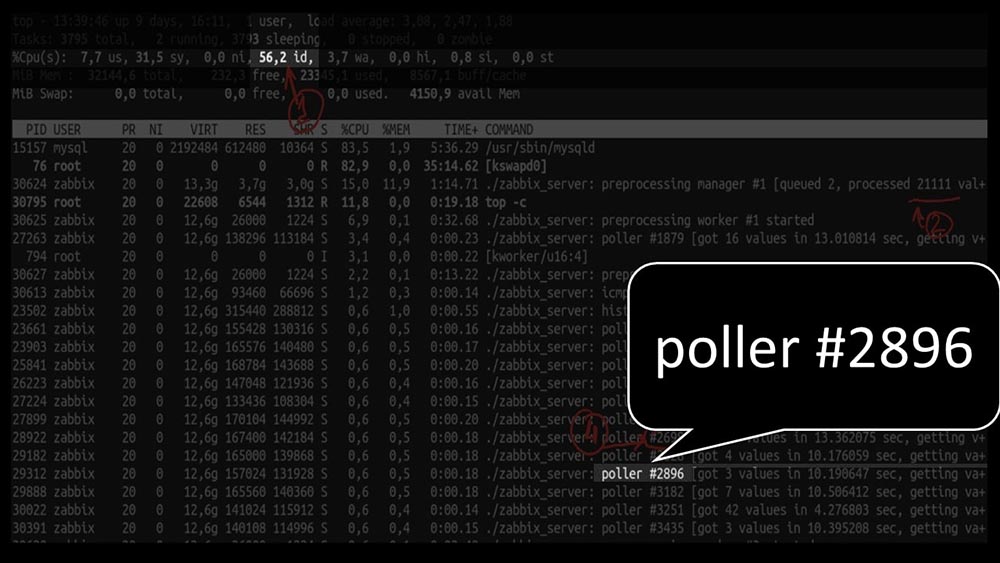 mais en même temps, nous n'avons pas pu utiliser le système même à mi-chemin:
mais en même temps, nous n'avons pas pu utiliser le système même à mi-chemin: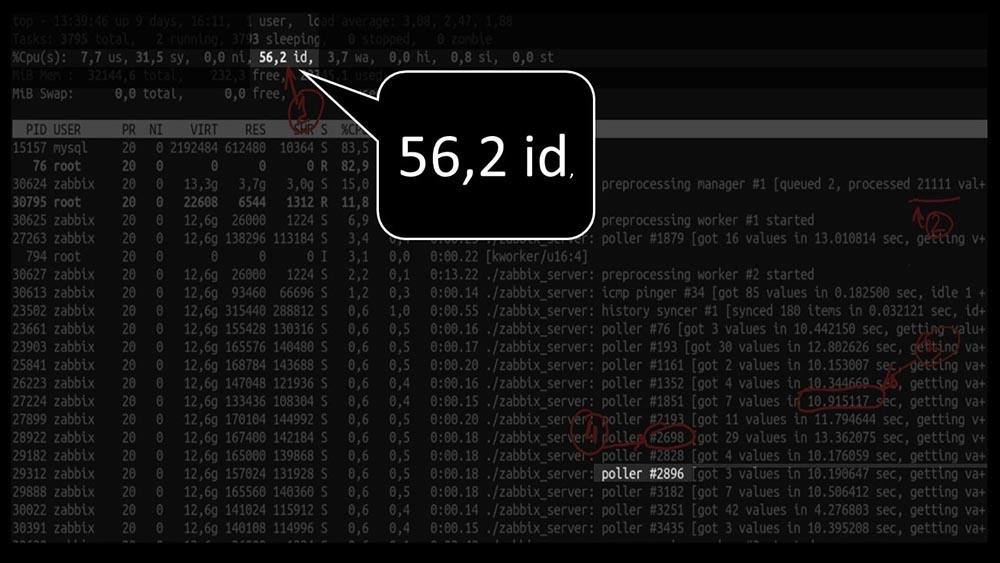 Et les performances globales sont assez faibles, environ 4 000 métriques par seconde:
Et les performances globales sont assez faibles, environ 4 000 métriques par seconde: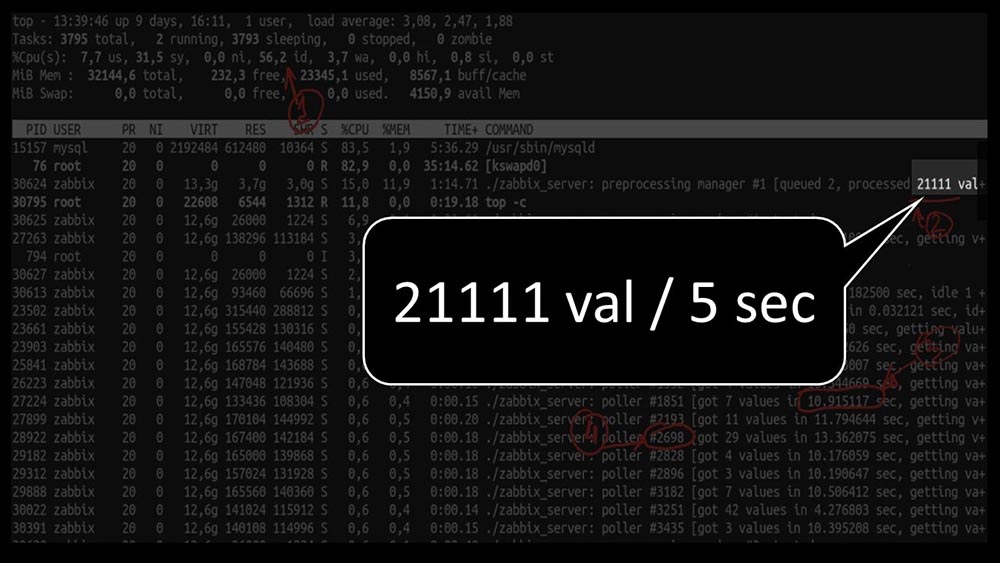 y a-t-il autre chose?MCH: - Oui, strace d'un des scrutateurs:
y a-t-il autre chose?MCH: - Oui, strace d'un des scrutateurs: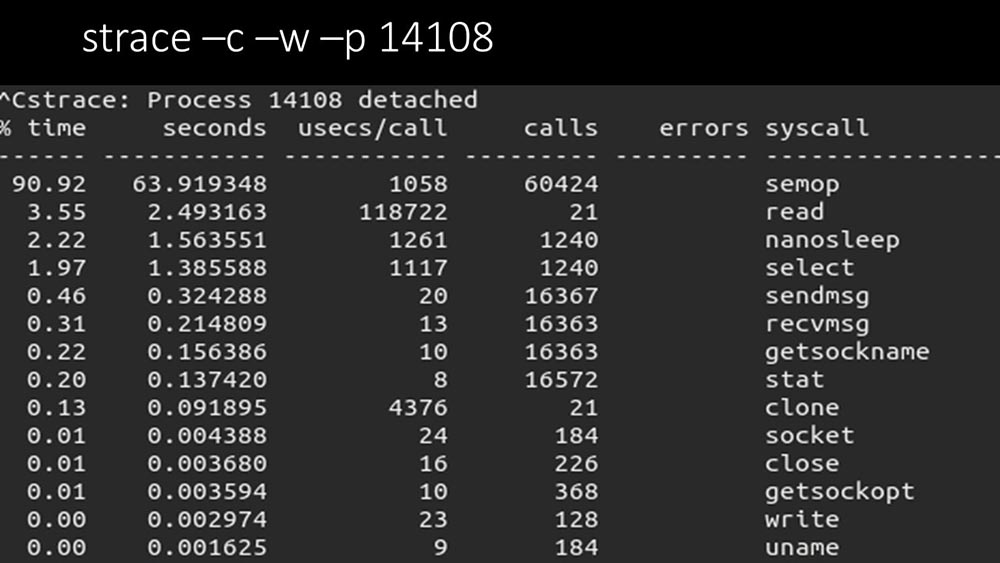 MM: - On voit clairement ici que le processus de sondage attend des «sémaphores». Ce sont des serrures:
MM: - On voit clairement ici que le processus de sondage attend des «sémaphores». Ce sont des serrures: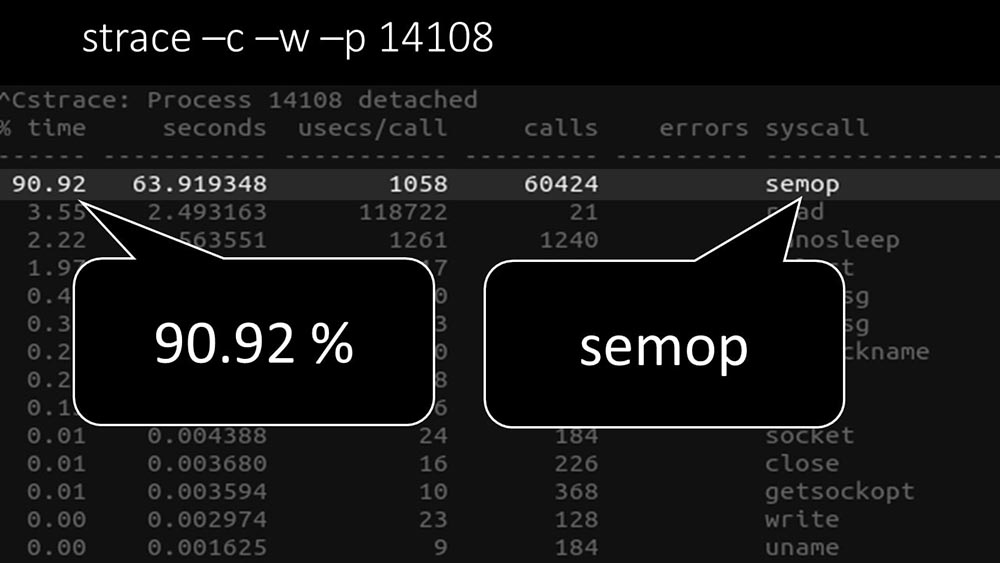 MCH: - Ce n'est pas clair.MM: - Regardez, c'est comme une situation où un tas de threads essaient de travailler avec des ressources avec lesquelles un seul peut travailler à la fois. Ensuite, tout ce qu'ils peuvent faire, c'est partager cette ressource dans le temps:
MCH: - Ce n'est pas clair.MM: - Regardez, c'est comme une situation où un tas de threads essaient de travailler avec des ressources avec lesquelles un seul peut travailler à la fois. Ensuite, tout ce qu'ils peuvent faire, c'est partager cette ressource dans le temps: Et la productivité totale de travailler avec une telle ressource est limitée par la vitesse d'un cœur: Il
Et la productivité totale de travailler avec une telle ressource est limitée par la vitesse d'un cœur: Il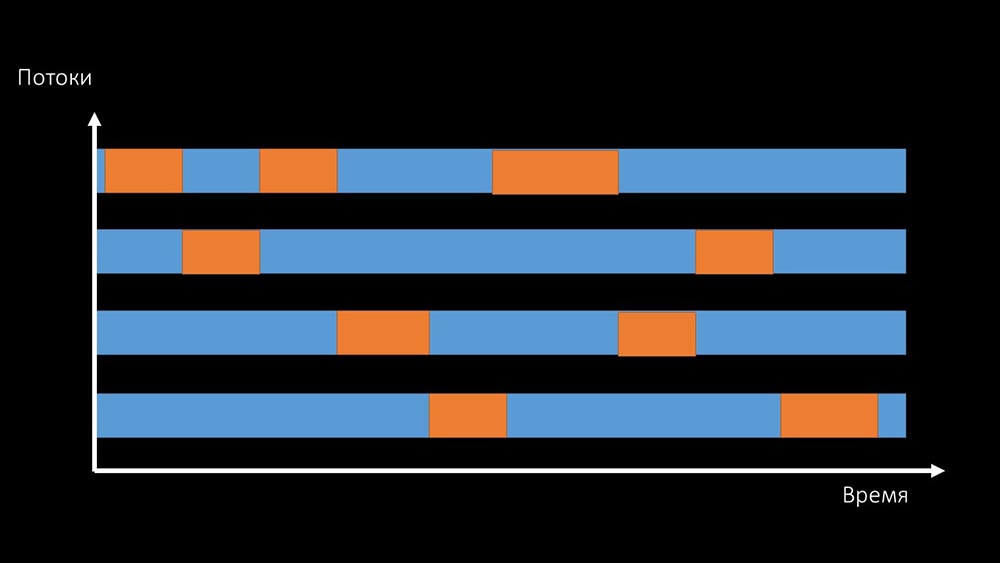 existe deux façons de résoudre ce problème.Mettez à niveau le fer de la machine, passez à des noyaux plus rapides:
existe deux façons de résoudre ce problème.Mettez à niveau le fer de la machine, passez à des noyaux plus rapides: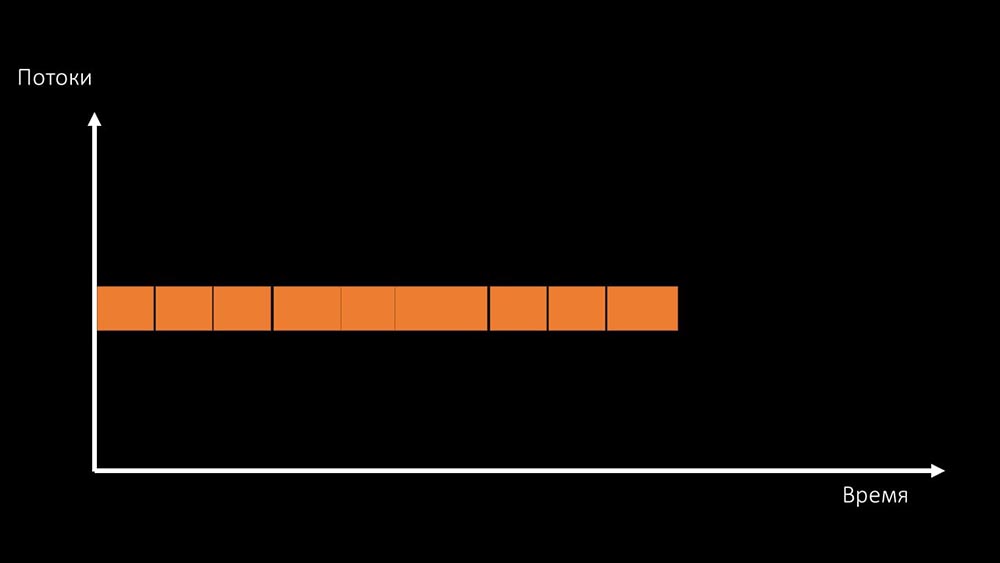 Ou changez l'architecture et , en même temps , la charge:
Ou changez l'architecture et , en même temps , la charge: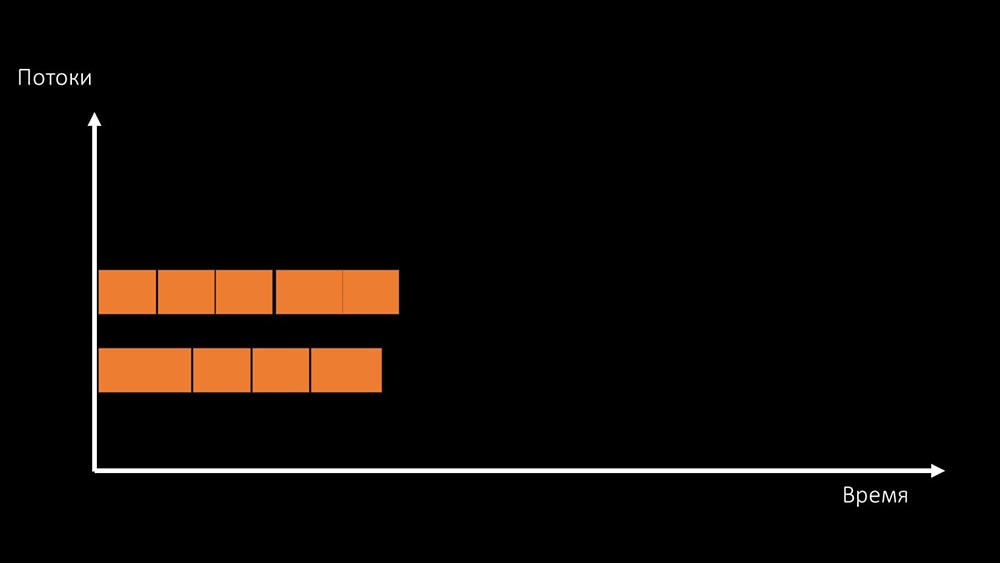 MCH: - Soit dit en passant, nous utiliserons moins de cœurs sur une machine de test que sur une machine de combat, mais ils seront 1,5 fois plus rapides en fréquence par cœur!MM: - C'est clair? Il est nécessaire de regarder le code du serveur.
MCH: - Soit dit en passant, nous utiliserons moins de cœurs sur une machine de test que sur une machine de combat, mais ils seront 1,5 fois plus rapides en fréquence par cœur!MM: - C'est clair? Il est nécessaire de regarder le code du serveur.Chemin de données dans le serveur Zabbix
MCH: - Pour comprendre, nous avons commencé à analyser comment les données sont transmises à l'intérieur du serveur Zabbix: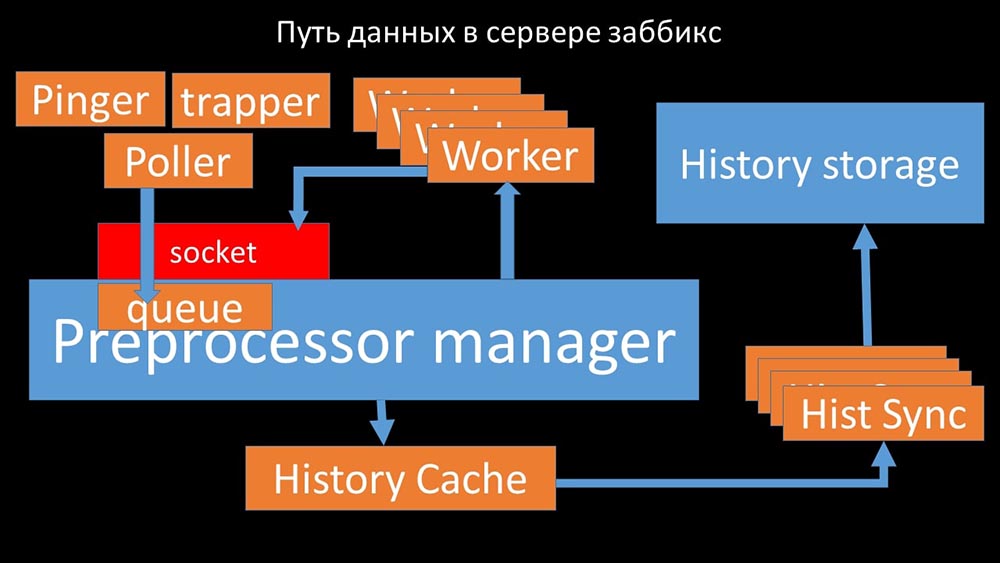 Image sympa, non? Passons en revue pas à pas pour clarifier plus ou moins. Il existe des flux et des services chargés de collecter les données:
Image sympa, non? Passons en revue pas à pas pour clarifier plus ou moins. Il existe des flux et des services chargés de collecter les données: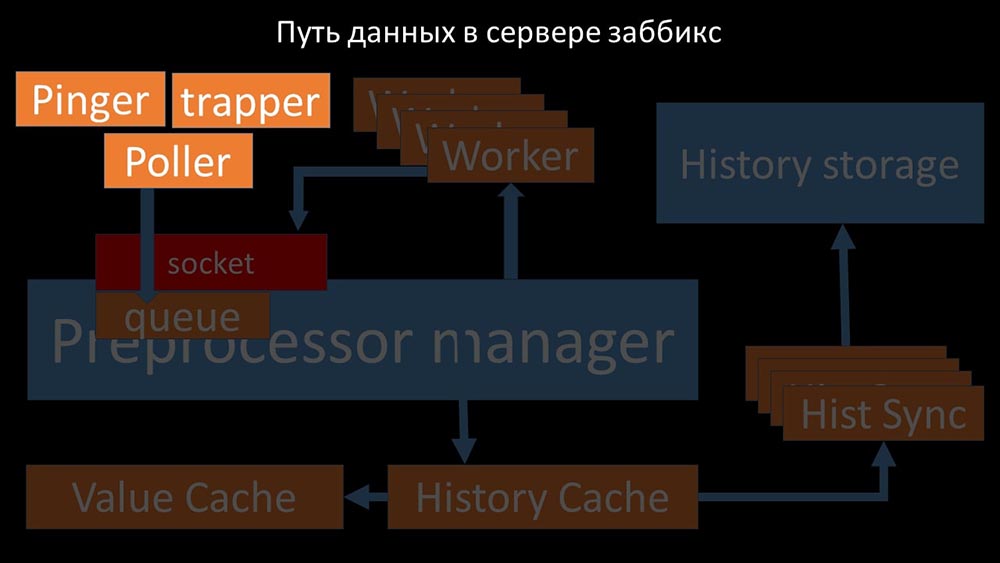 ils transfèrent les métriques collectées via le socket au gestionnaire de préprocesseur, où ils sont mis en file d'attente: le
ils transfèrent les métriques collectées via le socket au gestionnaire de préprocesseur, où ils sont mis en file d'attente: le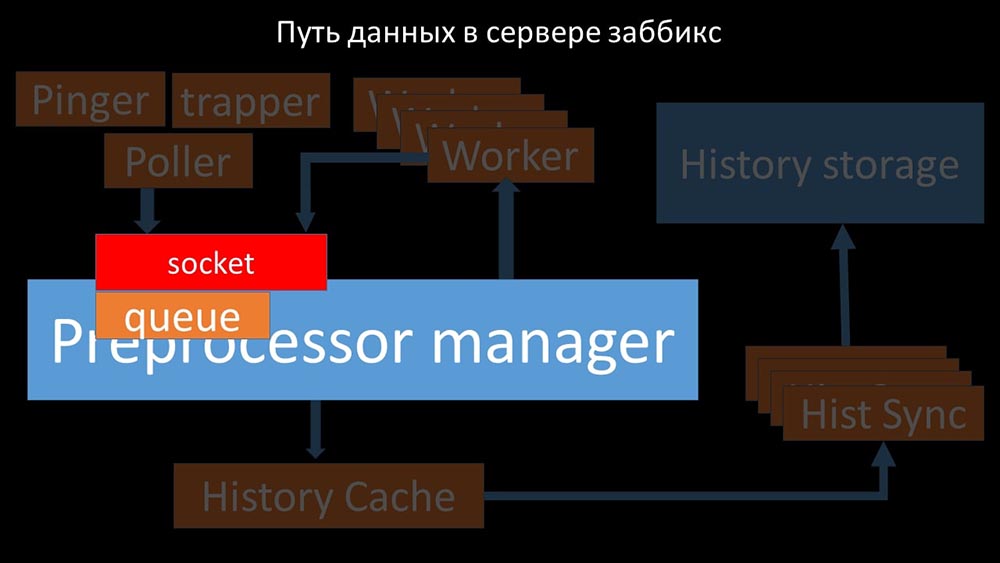 gestionnaire de préprocesseur »transfère les données à ses employés qui exécutent les instructions de prétraitement et les renvoient via le même socket:
gestionnaire de préprocesseur »transfère les données à ses employés qui exécutent les instructions de prétraitement et les renvoient via le même socket: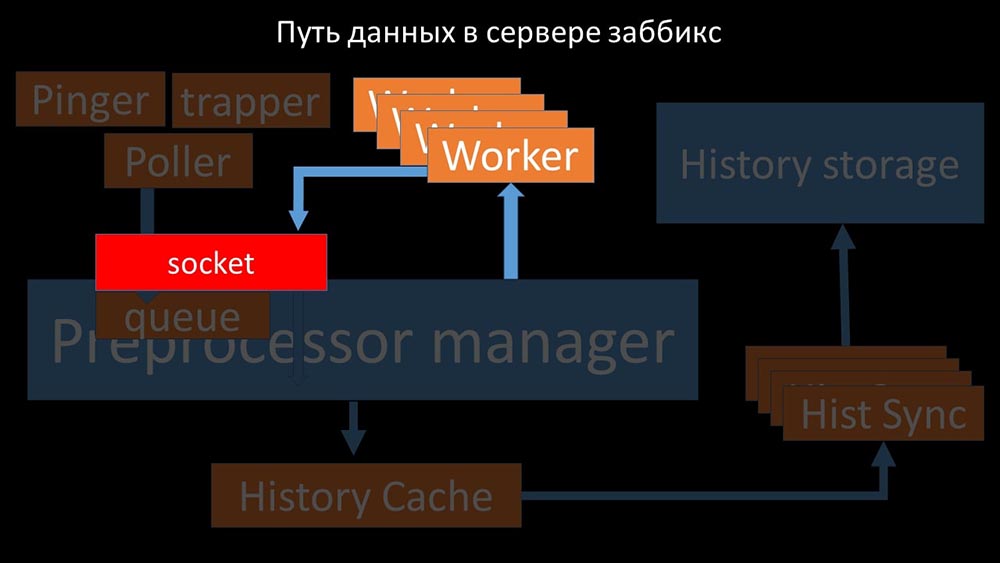 après cela, le préprocesseur -manager les enregistre dans le cache historique:
après cela, le préprocesseur -manager les enregistre dans le cache historique: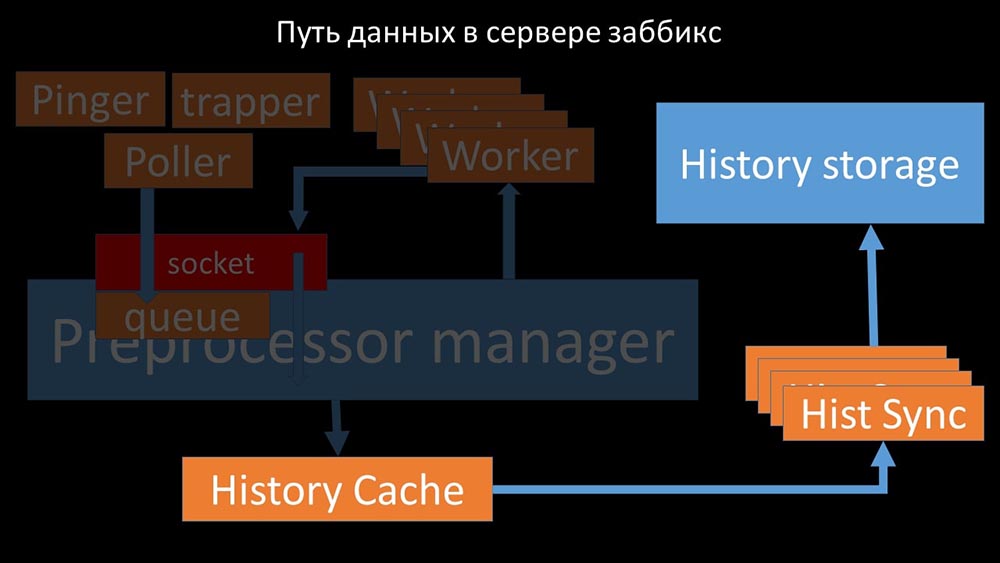 À partir de là, ils sont pris par des synchroniseurs historiques qui remplissent de nombreuses fonctions: par exemple, calculer des déclencheurs, remplir le cache de valeurs et, surtout, enregistrer des métriques dans le magasin d'historique. En général, le processus est complexe et très déroutant.
À partir de là, ils sont pris par des synchroniseurs historiques qui remplissent de nombreuses fonctions: par exemple, calculer des déclencheurs, remplir le cache de valeurs et, surtout, enregistrer des métriques dans le magasin d'historique. En général, le processus est complexe et très déroutant. MM: - La première chose que nous avons vue est que la plupart des threads rivalisent pour le soi-disant «cache de configuration» (une zone de mémoire où toutes les configurations de serveur sont stockées). En particulier, de nombreux verrous sont effectués par les flux responsables de la collecte de données:
MM: - La première chose que nous avons vue est que la plupart des threads rivalisent pour le soi-disant «cache de configuration» (une zone de mémoire où toutes les configurations de serveur sont stockées). En particulier, de nombreux verrous sont effectués par les flux responsables de la collecte de données: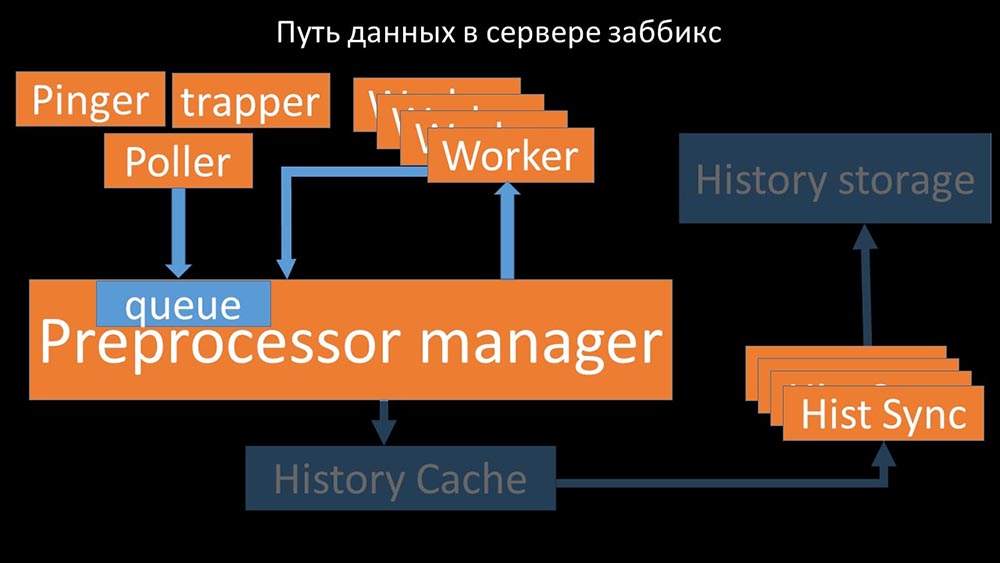 ... car la configuration stocke non seulement des métriques avec leurs paramètres, mais également des files d'attente, à partir desquelles les sondeurs prennent des informations sur ce qu'il faut faire ensuite. Lorsqu'il y a beaucoup de pollers, et que l'un bloque la configuration, les autres attendent des requêtes:
... car la configuration stocke non seulement des métriques avec leurs paramètres, mais également des files d'attente, à partir desquelles les sondeurs prennent des informations sur ce qu'il faut faire ensuite. Lorsqu'il y a beaucoup de pollers, et que l'un bloque la configuration, les autres attendent des requêtes:
Les scrutateurs ne doivent pas entrer en conflit
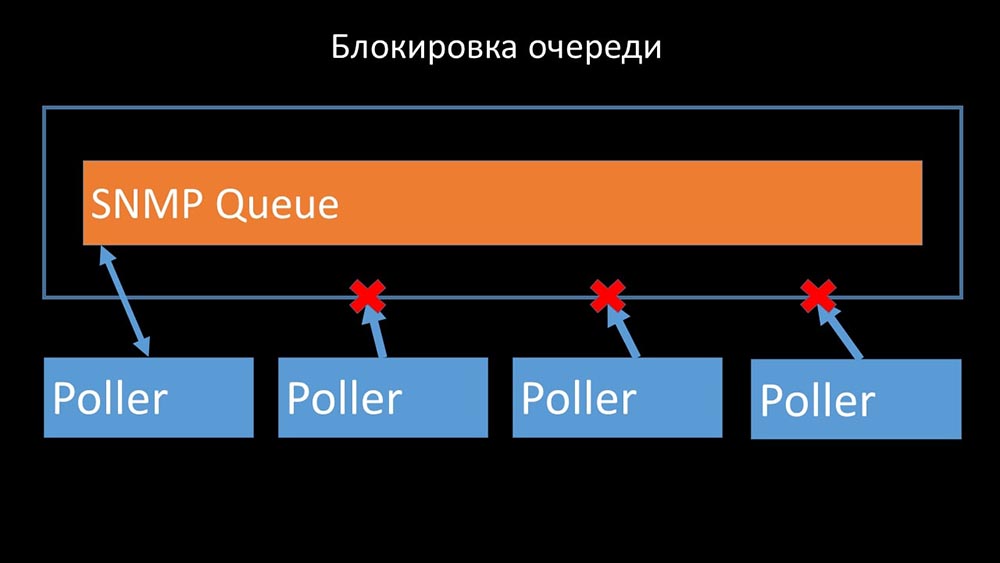 Par conséquent, la première chose que nous avons faite a été de diviser la file d'attente en 4 parties et de permettre aux scrutateurs de bloquer en toute sécurité ces files d'attente, ces parties en même temps:
Par conséquent, la première chose que nous avons faite a été de diviser la file d'attente en 4 parties et de permettre aux scrutateurs de bloquer en toute sécurité ces files d'attente, ces parties en même temps: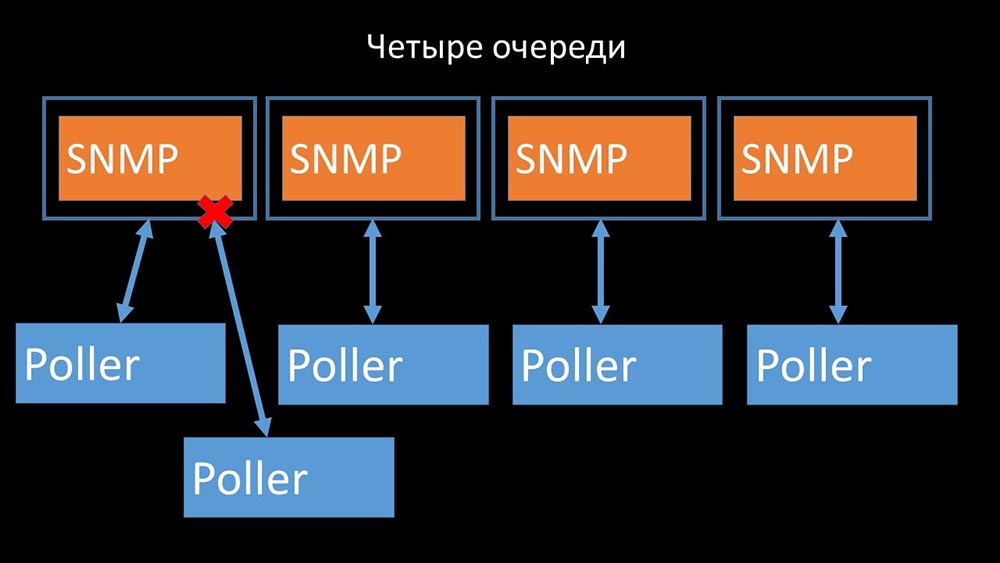 cela a supprimé la concurrence pour le cache de configuration et la vitesse des pollers a augmenté de manière significative. Mais ensuite, nous avons été confrontés au fait que le gestionnaire de préprocesseur a commencé à accumuler une file d'attente de travaux:
cela a supprimé la concurrence pour le cache de configuration et la vitesse des pollers a augmenté de manière significative. Mais ensuite, nous avons été confrontés au fait que le gestionnaire de préprocesseur a commencé à accumuler une file d'attente de travaux:
Le gestionnaire de préprocesseur doit être capable de prioriser
Cela s'est produit lorsqu'il manquait de productivité. Ensuite, tout ce qu'il pouvait faire était d'accumuler les demandes des processus de collecte de données et d'ajouter leur tampon jusqu'à ce qu'il mange toute la mémoire et se bloque: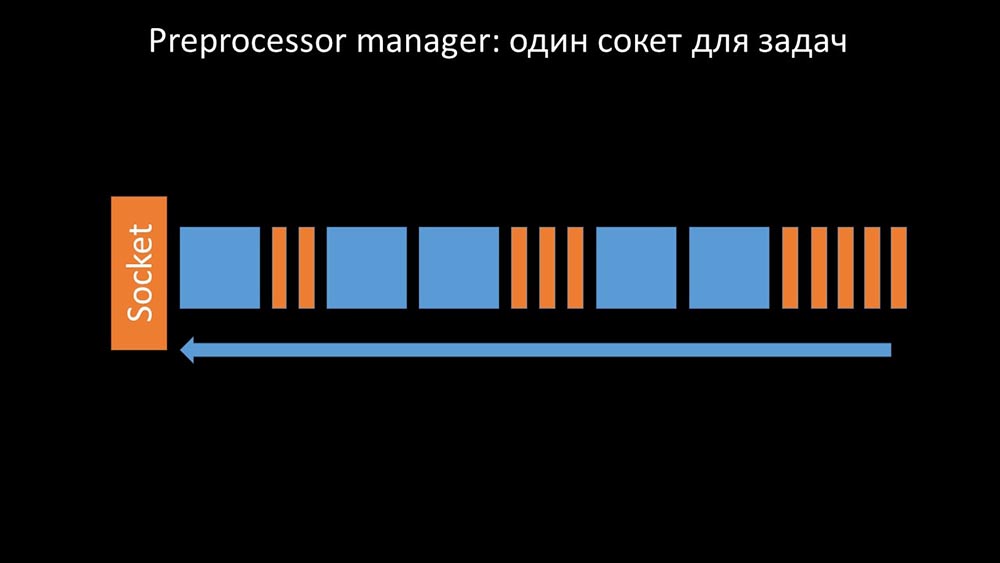 Pour résoudre ce problème, nous avons ajouté un deuxième socket, qui a été alloué spécifiquement pour les travailleurs:
Pour résoudre ce problème, nous avons ajouté un deuxième socket, qui a été alloué spécifiquement pour les travailleurs: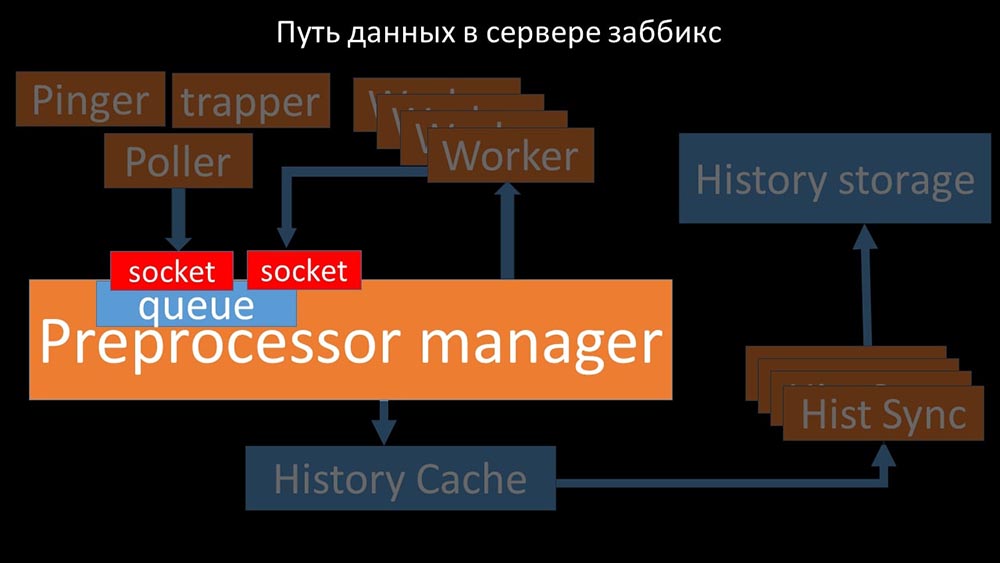 Ainsi , le gestionnaire du préprocesseur a eu l'occasion de prioriser son travail et dans le cas où le tampon augmente, la tâche est de ralentir la consommation, donnant aux travailleurs la possibilité de récupérer ce tampon:
Ainsi , le gestionnaire du préprocesseur a eu l'occasion de prioriser son travail et dans le cas où le tampon augmente, la tâche est de ralentir la consommation, donnant aux travailleurs la possibilité de récupérer ce tampon: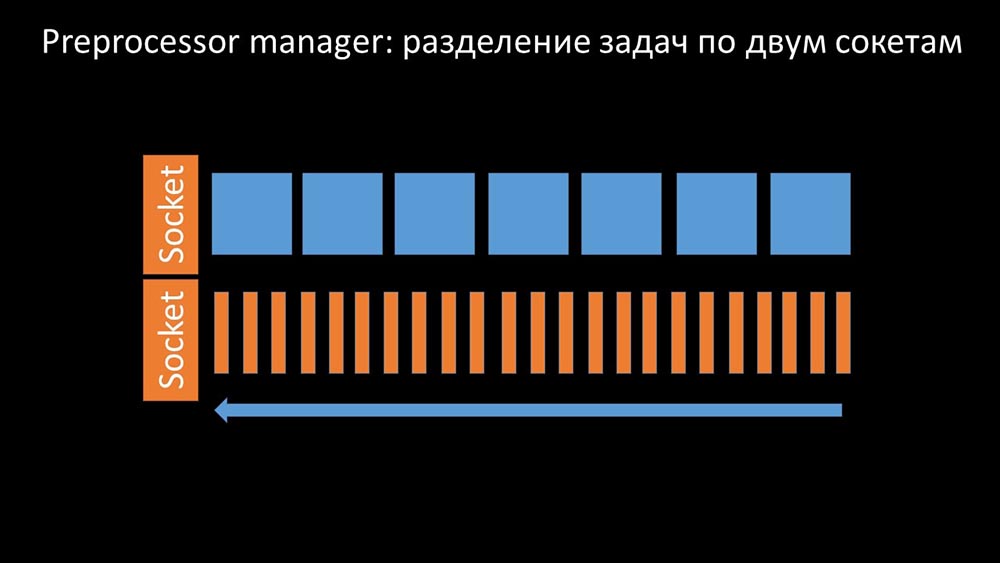 Ensuite, nous avons constaté que l'une des raisons du ralentissement était parce que les travailleurs eux-mêmes étaient en concurrence pour ressource vitale pour leur travail. Nous avons enregistré ce problème avec un bug-fix, et dans les nouvelles versions de Zabbix il a déjà été résolu:
Ensuite, nous avons constaté que l'une des raisons du ralentissement était parce que les travailleurs eux-mêmes étaient en concurrence pour ressource vitale pour leur travail. Nous avons enregistré ce problème avec un bug-fix, et dans les nouvelles versions de Zabbix il a déjà été résolu: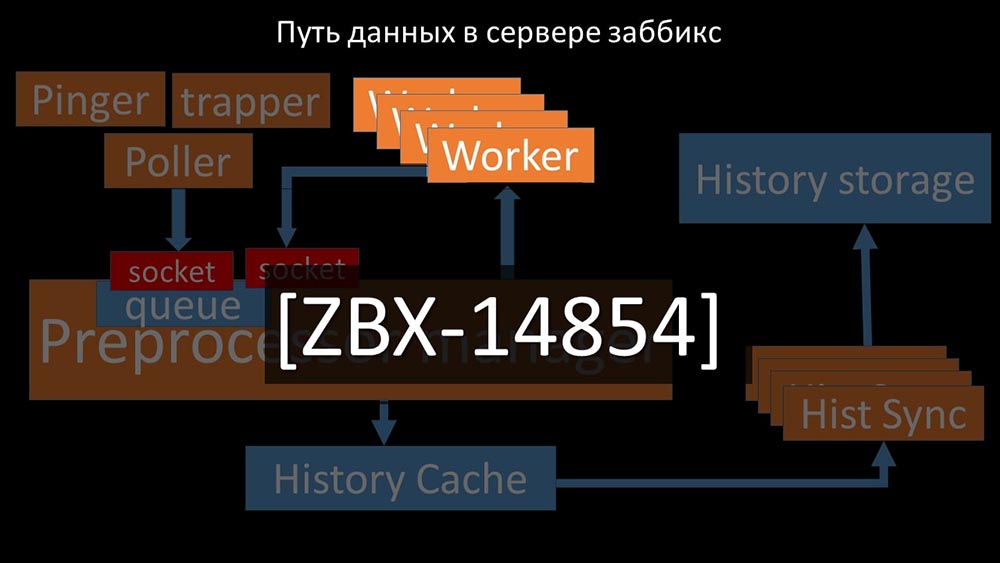
Nous augmentons le nombre de prises - nous obtenons le résultat
En outre, le gestionnaire de préprocesseur lui-même est devenu un lien étroit, car il s'agit d'un seul thread. Elle reposait sur la vitesse du noyau, donnant une vitesse maximale d'environ 70 000 métriques par seconde: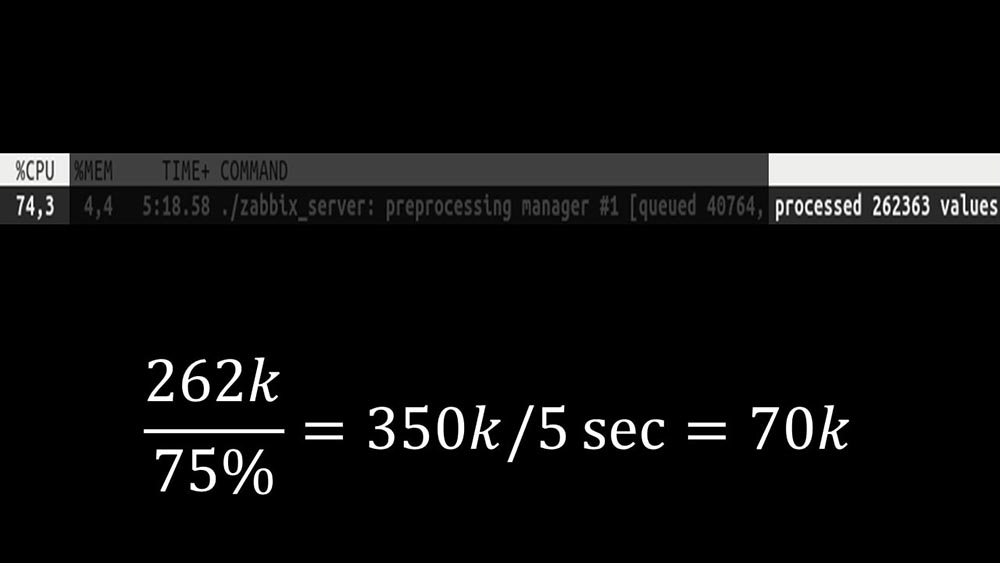 Par conséquent, nous en avons fait quatre, avec quatre ensembles de sockets, des travailleurs:
Par conséquent, nous en avons fait quatre, avec quatre ensembles de sockets, des travailleurs: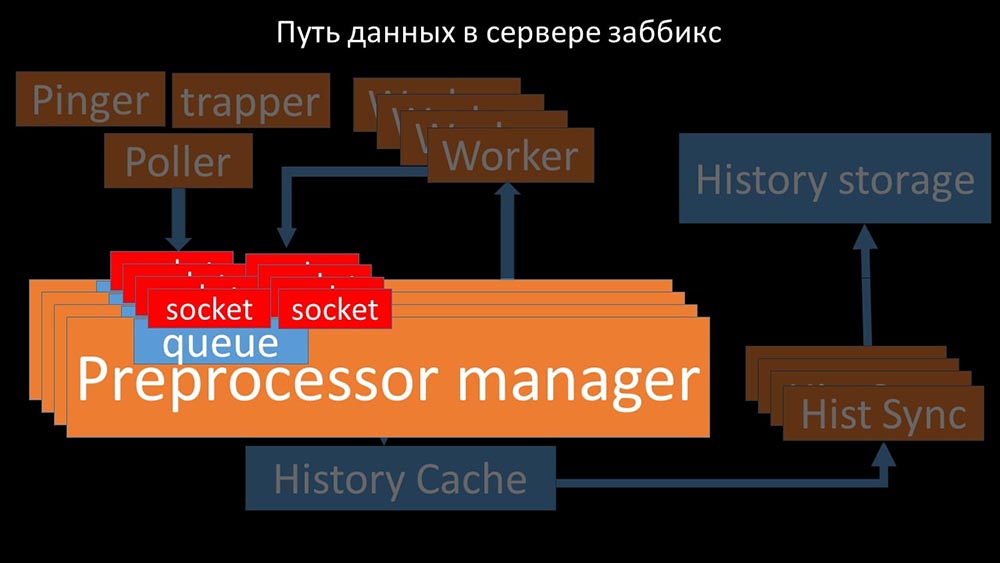 Et cela nous a permis d'augmenter la vitesse à environ 130 000 métriques: La
Et cela nous a permis d'augmenter la vitesse à environ 130 000 métriques: La non-linéarité de la croissance s'explique par le fait qu'il y avait une concurrence pour le cache histoires. Pour lui, 4 gestionnaires de préprocesseurs et synkers historiques ont concouru. À ce stade, nous avons reçu environ 130 000 métriques par seconde sur une machine de test, en l'utilisant à environ 95% sur le processeur: il y a
non-linéarité de la croissance s'explique par le fait qu'il y avait une concurrence pour le cache histoires. Pour lui, 4 gestionnaires de préprocesseurs et synkers historiques ont concouru. À ce stade, nous avons reçu environ 130 000 métriques par seconde sur une machine de test, en l'utilisant à environ 95% sur le processeur: il y a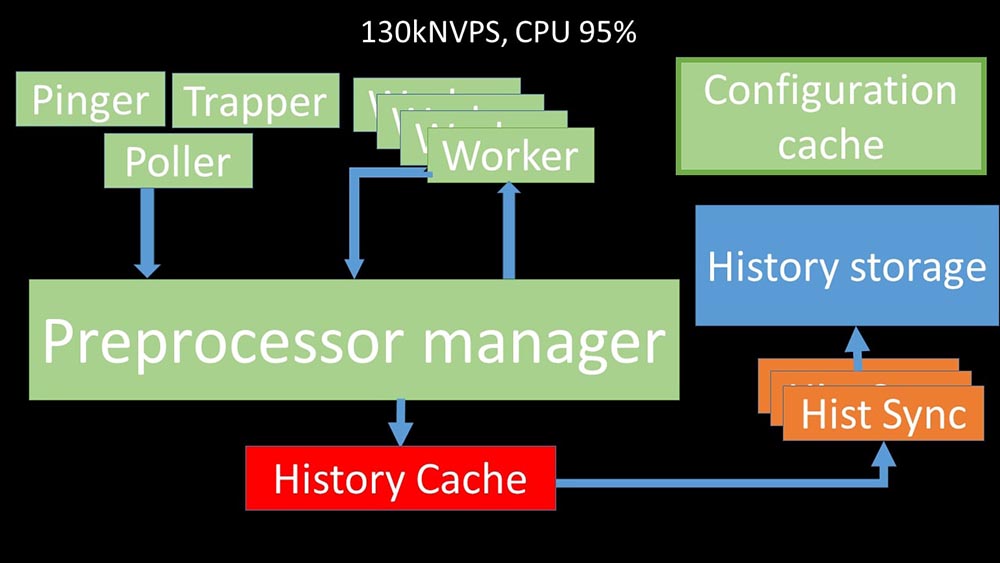 environ 2,5 mois
environ 2,5 moisLe refus de la communauté snmp a augmenté les NVP d'une fois et demie
MM: - Max, j'ai besoin d'une nouvelle machine de test! Nous ne rentrons plus dans l'actuel.MCH: - Et maintenant?MM: - Maintenant - 130 000 NVP et un processeur «plateau».MCH: - Wow! Cool! Attendez, j'ai deux questions. Selon mes calculs, notre besoin est de l'ordre de 15 à 20 000 métriques par seconde. Pourquoi en avons-nous besoin de plus?MM: - Je veux terminer le travail jusqu'à la fin. Je veux voir combien nous pouvons tirer de ce système.MCH: - Mais ...MM: - Mais c'est inutile pour les affaires.MCH: - Je vois. Et la deuxième question: qu'est-ce que nous avons maintenant, pouvons-nous nous soutenir, sans l'aide d'un développeur?MM:- Je ne pense pas. La modification du cache de configuration est un problème. Il traite des changements dans la plupart des threads et est difficile à maintenir. Très probablement, la soutenir sera très difficile.MCH: - Alors vous avez besoin d'une sorte d'alternative.MM: - Il existe une telle option. On peut passer à des cœurs rapides, tout en abandonnant le nouveau système de verrouillage. Nous obtenons toujours les performances de 60 à 80 000 métriques. Dans ce cas, nous pouvons laisser le reste du code. Clickhouse, l'interrogation asynchrone fonctionnera. Et ce sera facile à entretenir.MCH: - Génial! Je propose de m'attarder là-dessus.Après avoir optimisé le côté serveur, nous avons finalement pu exécuter le nouveau code dans le productif. Nous avons abandonné une partie des changements en faveur du passage à une machine à noyaux rapides et à la minimisation du nombre de changements dans le code. Nous avons également simplifié la configuration et, si possible, abandonné les macros dans les éléments de données, car elles sont à l'origine de verrous supplémentaires. Par exemple, le rejet de la macro snmp-community, qui se trouve souvent dans la documentation et les exemples, dans notre cas nous a permis d'accélérer en outre les NVP d'environ 1,5 fois.Après deux jours de production
Par exemple, le rejet de la macro snmp-community, qui se trouve souvent dans la documentation et les exemples, dans notre cas nous a permis d'accélérer en outre les NVP d'environ 1,5 fois.Après deux jours de productionSupprimer les fenêtres contextuelles d'historique des incidents
MCH: - Misha, nous utilisons le système pendant deux jours, et tout fonctionne. Mais seulement quand tout fonctionne! Nous avions prévu de travailler avec le transfert d'un segment suffisamment important du réseau, et encore une fois avec nos mains nous avons vérifié qu'il avait augmenté, qu'il ne l'avait pas fait.MM: - Ça ne peut pas être! Nous avons tout vérifié 10 fois. Le serveur traite instantanément l'inaccessibilité complète du réseau.MCH: - Oui, je comprends tout: serveur, base de données, top, austat, logs - tout est rapide ... Mais on regarde l'interface web, et là on a le processeur "en rayon" sur le serveur et ça: MM: - Je vois. Regardons le Web. Nous avons constaté que dans une situation où il y avait un grand nombre d'incidents actifs, la plupart des widgets opérationnels ont commencé à fonctionner très lentement:
MM: - Je vois. Regardons le Web. Nous avons constaté que dans une situation où il y avait un grand nombre d'incidents actifs, la plupart des widgets opérationnels ont commencé à fonctionner très lentement: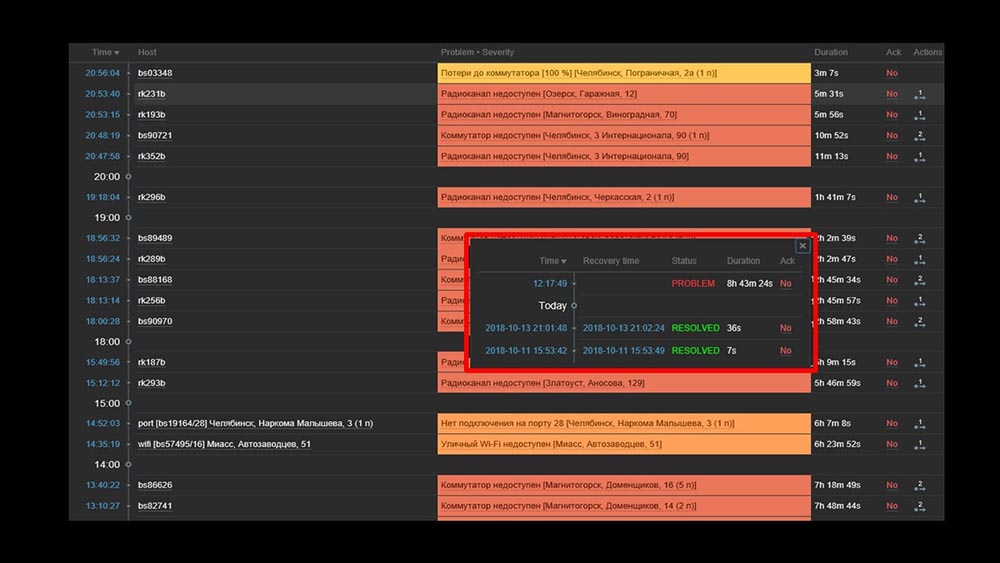 La raison en était la génération de fenêtres contextuelles avec un historique des incidents générés pour chaque élément de la liste. Par conséquent, nous avons refusé de générer ces fenêtres (commenté 5 lignes dans le code), et cela a résolu nos problèmes.Le temps de chargement du widget, même lorsqu'il est complètement inaccessible, a été réduit de quelques minutes à 10 à 15 secondes pour nous, et l'historique peut toujours être consulté en cliquant sur l'heure:
La raison en était la génération de fenêtres contextuelles avec un historique des incidents générés pour chaque élément de la liste. Par conséquent, nous avons refusé de générer ces fenêtres (commenté 5 lignes dans le code), et cela a résolu nos problèmes.Le temps de chargement du widget, même lorsqu'il est complètement inaccessible, a été réduit de quelques minutes à 10 à 15 secondes pour nous, et l'historique peut toujours être consulté en cliquant sur l'heure: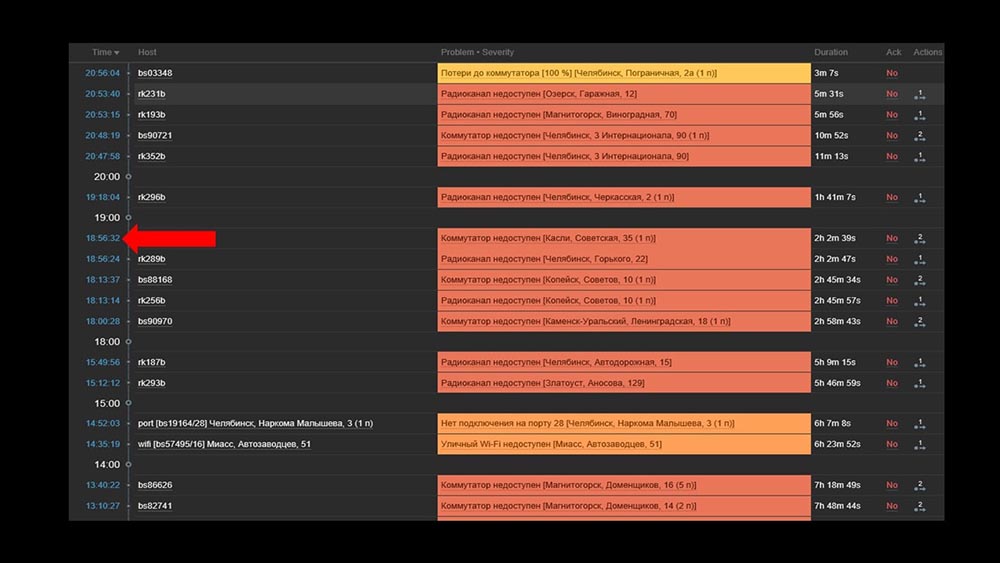 Après le travail. Il y a 2 moisMCH: - Misha, tu pars? Il faut qu'on parle.MM: - Je ne vais pas. Encore une fois quelque chose avec Zabbix?MCH: - Oh non, détends-toi! Je voulais juste dire: tout fonctionne, merci! Bière avec moi.
Après le travail. Il y a 2 moisMCH: - Misha, tu pars? Il faut qu'on parle.MM: - Je ne vais pas. Encore une fois quelque chose avec Zabbix?MCH: - Oh non, détends-toi! Je voulais juste dire: tout fonctionne, merci! Bière avec moi.Zabbix est efficace
Zabbix est un système et une fonction assez polyvalents et riches. Il peut être utilisé pour de petites installations hors de la boîte, mais avec la croissance des besoins, il doit être optimisé. Pour stocker une grande archive de métriques, utilisez le stockage approprié:- Vous pouvez utiliser les outils intégrés sous forme d'intégration avec Elastixerch ou de téléchargement de l'historique dans des fichiers texte (disponible à partir de la quatrième version);
- Vous pouvez profiter de notre expérience et de notre intégration avec Clickhouse.
Pour augmenter considérablement la vitesse de collecte des métriques, collectez-les de manière asynchrone et transférez-les via l'interface de trappeur vers le serveur Zabbix; ou vous pouvez utiliser le correctif pour les sondeurs asynchrones de Zabbix lui-même.Zabbix est écrit en C et est assez efficace. La solution de plusieurs endroits architecturaux étroits permet d'augmenter encore sa productivité et, selon notre expérience, de recevoir plus de 100 000 métriques sur une machine à processeur unique.
Le même patch Zabbix
MM: - Je veux ajouter quelques points. L'ensemble du rapport actuel, tous les tests, les numéros sont donnés pour la configuration qui est utilisée avec nous. Nous en tirons maintenant environ 20 000 mesures par seconde. Si vous essayez de comprendre si cela fonctionnera pour vous - vous pouvez comparer. Ce dont ils ont parlé aujourd'hui est publié sur GitHub sous forme de correctif: github.com/miklert/zabbix Le correctif comprend:
Le correctif comprend:- intégration complète avec Clickhouse (serveur Zabbix et frontend);
- résoudre les problèmes avec le gestionnaire de préprocesseur;
- interrogation asynchrone.
Le patch est compatible avec toutes les versions 4, y compris les lts. Très probablement, avec des changements minimes, cela fonctionnera sur la version 3.4.Merci pour l'attention.Des questions
Question du public (ci-après - A): - Bonjour! Dites-moi s'il vous plaît, avez-vous des plans pour une interaction intensive avec l'équipe Zabbix, ou ont-ils avec vous pour que ce ne soit pas un patch, mais le comportement normal de Zabbix?MM: - Oui, nous allons certainement engager une partie des changements. Quelque chose sera, quelque chose restera dans le patch.R: - Merci beaucoup pour l'excellent rapport! Dites-moi, s'il vous plaît, après avoir appliqué le patch, le support du côté de Zabbix restera et comment continuer la mise à niveau vers des versions supérieures? Sera-t-il possible de mettre à jour Zabbix après votre patch en 4.2, 5.0?MM:- Je ne peux pas parler de support. Si j'étais le support technique de Zabbix, je dirais probablement non, car c'est le code de quelqu'un d'autre. Quant à la base de code 4.2, notre position est la suivante: "Nous irons avec le temps, et nous serons mis à jour sur la prochaine version." Par conséquent, pendant un certain temps, nous téléchargerons le correctif dans des versions mises à jour. Je l'ai déjà dit dans le rapport: le nombre de changements avec les versions est encore assez faible. Je pense que le passage de la 3.4 à la 4. nous a pris, semble-t-il, environ 15 minutes. Quelque chose a changé, mais pas très important.R: - Vous prévoyez donc de maintenir votre correctif et vous pouvez le mettre en production en toute sécurité, à l'avenir, obtenir des mises à jour d'une manière ou d'une autre?MM: - Nous le recommandons fortement. Cela résout beaucoup de problèmes pour nous.MCH:- Encore une fois, je voudrais souligner que les changements qui ne concernent pas l'architecture et ne concernent pas les verrous, les files d'attente - ils sont modulaires, ils sont dans des modules séparés. Même seuls avec des changements mineurs, ils peuvent être maintenus assez facilement.MM: - Si les détails sont intéressants, alors «Clickhouse» utilise la soi-disant bibliothèque historique. Il n'est pas lié - il s'agit d'une copie du support d'Elastic, c'est-à-dire qu'il est configurable. L'interrogation modifie uniquement les interrogateurs. Nous pensons que cela fonctionnera longtemps.R: - Merci beaucoup. Mais dites-moi, existe-t-il une documentation des modifications apportées? MM:- La documentation est un patch. De toute évidence, avec l'introduction de «Clickhouse», avec l'introduction de nouveaux types de sondeurs, de nouvelles options de configuration apparaissent. Le lien de la dernière diapositive contient une brève description de son utilisation.
MM:- La documentation est un patch. De toute évidence, avec l'introduction de «Clickhouse», avec l'introduction de nouveaux types de sondeurs, de nouvelles options de configuration apparaissent. Le lien de la dernière diapositive contient une brève description de son utilisation.À propos du remplacement de fping par nmap
R: - Comment avez-vous finalement mis cela en œuvre? Pouvez-vous donner des exemples spécifiques: s'agit-il de vos strappers et d'un script externe? Qu'est-ce qui permet de vérifier si rapidement tant d'hôtes? Comment obtenez-vous ces hôtes? Nmap a-t-il besoin de les nourrir, de les récupérer quelque part, de les mettre, de commencer quelque chose? ..MM:- Cool. Question très correcte! Le point est le suivant. Nous avons modifié la bibliothèque (ping ICMP, partie de Zabbix) pour les vérifications ICMP, qui indiquent le nombre de paquets - unité (1), et le code essaie d'utiliser nmap. Autrement dit, c'est le travail interne de Zabbix, il est devenu le travail interne du pinger. En conséquence, aucune synchronisation ou utilisation d'un trappeur n'est requise. Cela a été fait délibérément afin de laisser le système cohérent et de ne pas s'engager dans la synchronisation de deux systèmes de base: que vérifier, remplir via le poller, et si le remplissage s'est cassé en nous? .. C'est beaucoup plus simple.R: - Ça marche aussi pour un proxy?MM: - Oui, mais nous n'avons pas vérifié. Le code d'interrogation est le même dans Zabbix et sur le serveur. Devrait marcher. J'insiste à nouveau: les performances du système sont telles que nous n'avons pas besoin de proxy.MCH: - La bonne réponse à la question est: "Pourquoi avez-vous besoin d'un proxy avec un tel système?" Uniquement à cause de NAT'a ou pour surveiller via un canal lent certains ...R: - Et vous utilisez Zabbix comme allergène, si je comprends bien. Ou les graphiques (où est la couche d'archives) que vous avez laissés pour un autre système, tel que Grafana? Ou n'utilisez-vous pas cette fonctionnalité?MM: - Je soulignerai encore une fois: nous avons fait une intégration complète. Nous versons l'histoire dans «Clickhouse», mais en même temps nous avons changé le frontend php. Php-frontend va à «Clickhouse» et fait tous les graphiques à partir de là. Dans le même temps, pour être honnête, nous avons une partie qui se construit à partir du même «Clickhouse», à partir des mêmes données Zabbix, des données dans d'autres systèmes d'affichage graphique.MCH: - Dans "Grafan" également.Comment la décision d'allouer des ressources a-t-elle été prise?
R: - Partagez une petite cuisine intérieure. Comment a-t-on décidé que les ressources devraient être allouées à une transformation sérieuse des produits? Ce sont, en général, certains risques. Et dites-moi, dans le contexte du fait que vous allez soutenir de nouvelles versions: comment cette décision est-elle justifiée d'un point de vue managérial?MM: - Apparemment, nous n'avons pas très bien raconté le drame de l'histoire. Nous nous sommes retrouvés dans une situation où quelque chose devait être fait, et sommes allés essentiellement deux commandes parallèles:- L'une était engagée dans le lancement d'un système de surveillance utilisant de nouvelles méthodes: la surveillance en tant que service, un ensemble standard de solutions open source que nous combinons et essayons ensuite de changer le processus métier afin de travailler avec le nouveau système de surveillance.
- En parallèle, nous avions un programmeur enthousiaste qui faisait ça (à propos de lui). Il se trouve qu'il a gagné.
R: - Et quelle est la taille de l'équipe?MCH: - Elle est devant vous.R: - C'est, comme toujours, un passionné est nécessaire?MM: - Je ne sais pas ce qu'est un passionné.R: - Dans ce cas, apparemment, vous. Merci beaucoup, vous êtes cool.MM: - Merci.À propos des correctifs pour Zabbix
R: - Pour un système qui utilise des proxys (par exemple, dans certains systèmes distribués), est-il possible pour votre décision d'adapter et de patcher, disons, des pollers, des proxys et partiellement le préprocesseur de Zabbix lui-même; et leur interaction? Est-il possible d'optimiser les développements existants pour un système à plusieurs mandataires?MM: - Je sais que le serveur Zabbix est assemblé à l'aide d'un proxy (il compile et le code est obtenu). Nous n'avons pas testé cela dans le produit. Je ne suis pas sûr de cela, mais, à mon avis, le gestionnaire de préprocesseur n'est pas utilisé dans le proxy. La tâche du proxy est de prendre un ensemble de métriques de Zabbix, de les remplir (il écrit également la configuration, la base de données locale) et de le renvoyer au serveur Zabbix. Ensuite, le serveur lui-même effectuera le prétraitement lorsqu'il le recevra.L'intérêt pour les procurations est compréhensible. Nous allons vérifier cela. C'est un sujet intéressant.R: - L'idée était la suivante: si vous pouvez patcher des pollers, ils peuvent être patchés sur des proxys et patcher l'interaction avec le serveur, et le préprocesseur ne peut être adapté à ces fins que sur le serveur.MM: - Je pense que tout est encore plus simple. Vous prenez le code, appliquez le correctif, puis configurez-le selon vos besoins - collectez les serveurs proxy (par exemple, avec ODBC) et distribuez le code corrigé aux systèmes. Si nécessaire - collectez des procurations, si nécessaire - serveur.R: - De plus, vous n'aurez pas à patcher la transmission proxy au serveur, très probablement?MCH: - Non, c'est standard.MM:- En fait, une des idées ne sonnait pas. Nous avons toujours maintenu un équilibre entre une explosion d'idées et le nombre de changements, la facilité d'accompagnement.Un peu de publicité :)
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en recommandant à vos amis des VPS basés sur le cloud pour les développeurs à partir de 4,99 $ , un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur les VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbit / s à partir de 19 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! En savoir plus sur la création d'un bâtiment d'infrastructure. classe c utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou? Source: https://habr.com/ru/post/undefined/
All Articles