Dans un article précédent, nous avons examiné le mécanisme d'attention, une méthode extrêmement courante dans les modèles modernes d'apprentissage en profondeur qui peut améliorer les indicateurs de performance des applications de traduction automatique de neurones. Dans cet article, nous examinerons Transformer, un modèle qui utilise le mécanisme d'attention pour augmenter la vitesse d'apprentissage. De plus, pour un certain nombre de tâches, les Transformers surpassent le modèle de traduction automatique neuronale de Google. Cependant, le plus grand avantage des transformateurs est leur haute efficacité dans les conditions de parallélisation. Même Google Cloud recommande d'utiliser Transformer comme modèle lorsque vous travaillez sur Cloud TPU . Essayons de comprendre en quoi consiste le modèle et quelles fonctions il remplit.
Le modèle Transformer a d'abord été proposé dans l'article Attention is All You Need . Une implémentation sur TensorFlow est disponible dans le cadre du package Tensor2Tensor , en outre, un groupe de chercheurs en PNL de Harvard a créé une annotation guide de l'article avec une implémentation sur PyTorch . Dans ce même guide, nous essaierons d'énoncer le plus simplement et de manière cohérente les principales idées et concepts, ce qui, nous l'espérons, aidera les personnes qui n'ont pas une connaissance approfondie du sujet à comprendre ce modèle.
Examen de haut niveau
Regardons le modèle comme une sorte de boîte noire. Dans les applications de traduction automatique, il accepte une phrase dans une langue en entrée et affiche une phrase dans une autre.

, , , .
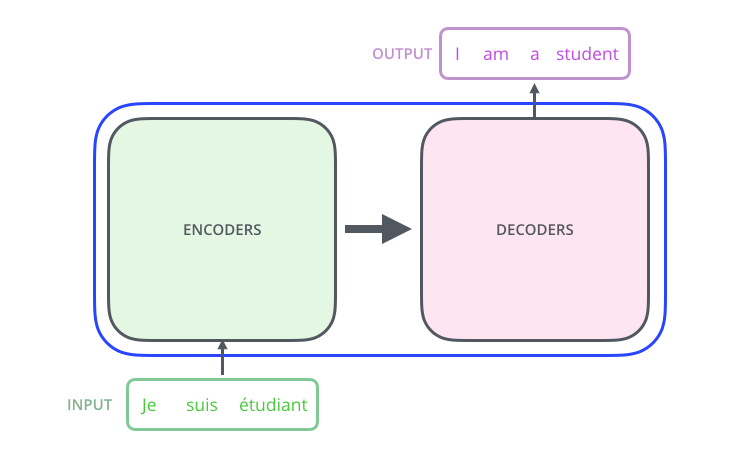
– ; 6 , ( 6 , ). – , .
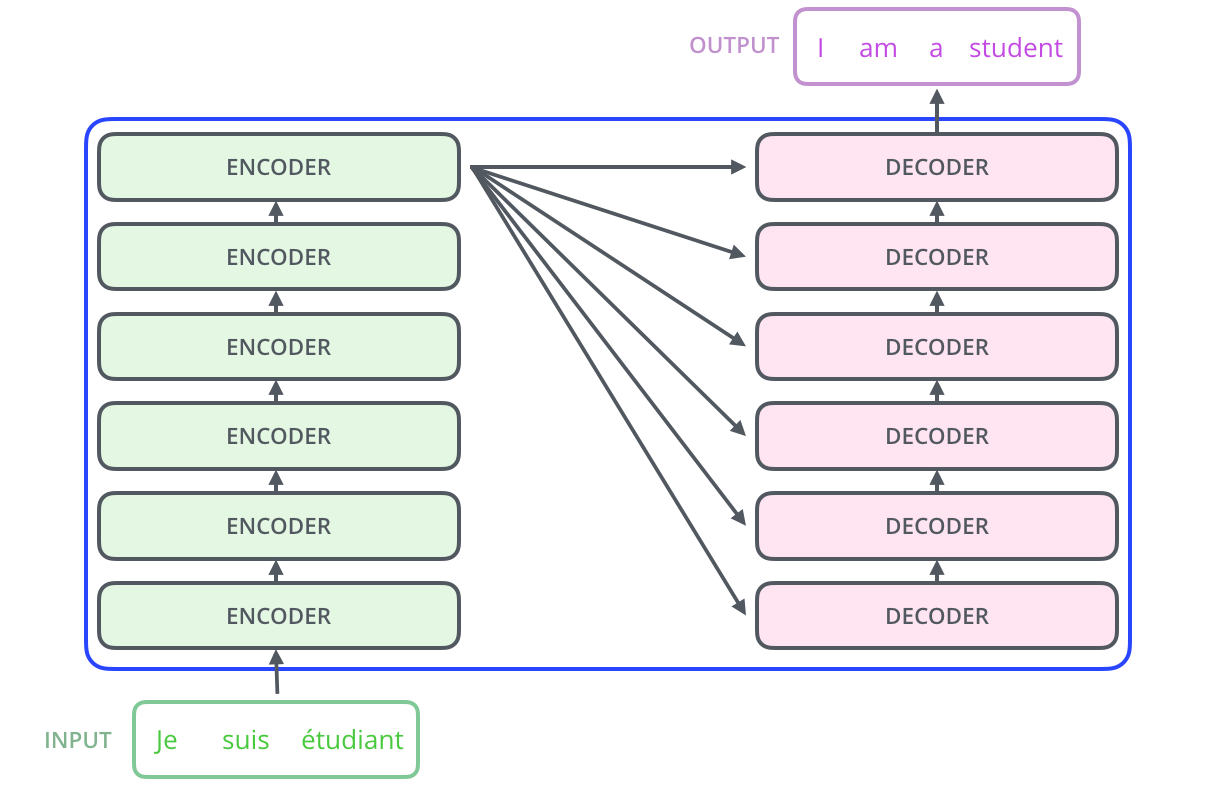
, . :
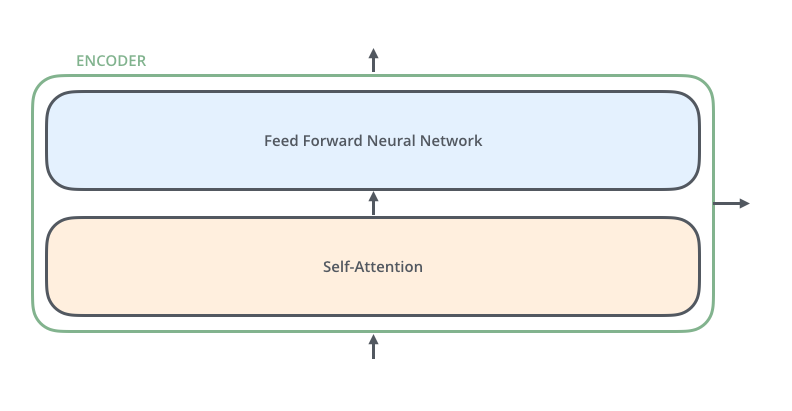
, , (self-attention), . .
(feed-forward neural network). .
, , ( , seq2seq).
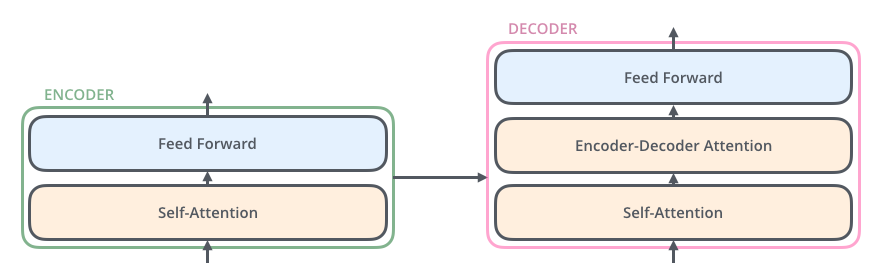
, , /, , .
NLP-, , , (word embeddings).

512. .
. , , : 512 ( , – ). , , , , .
, .
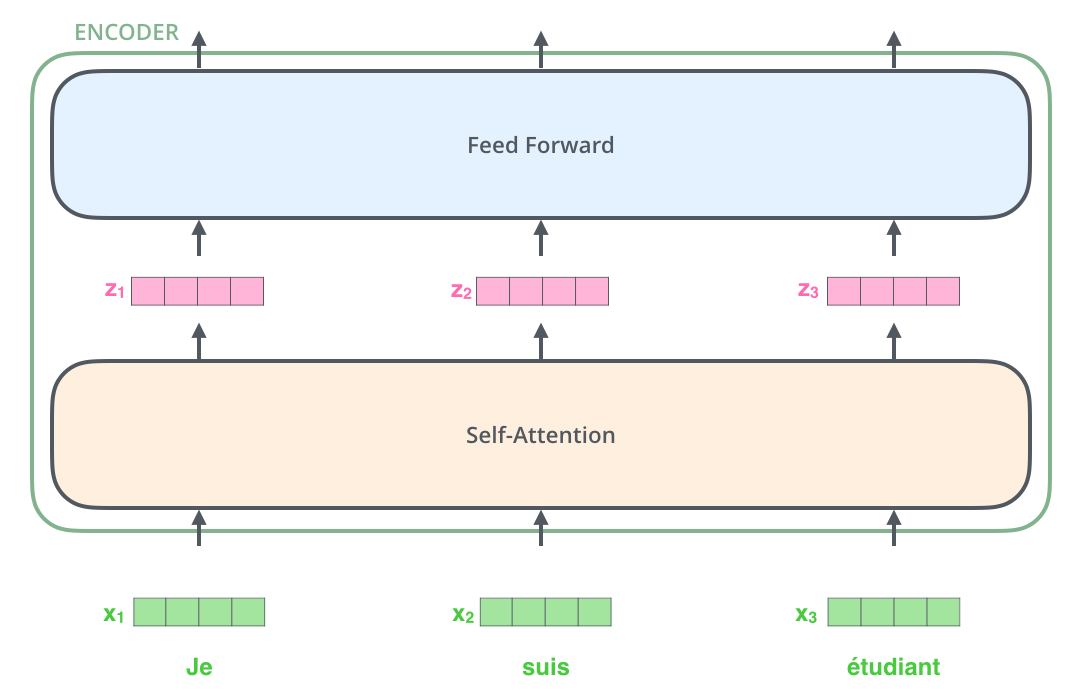
: . , , , .
, .
!
, , – , , , .
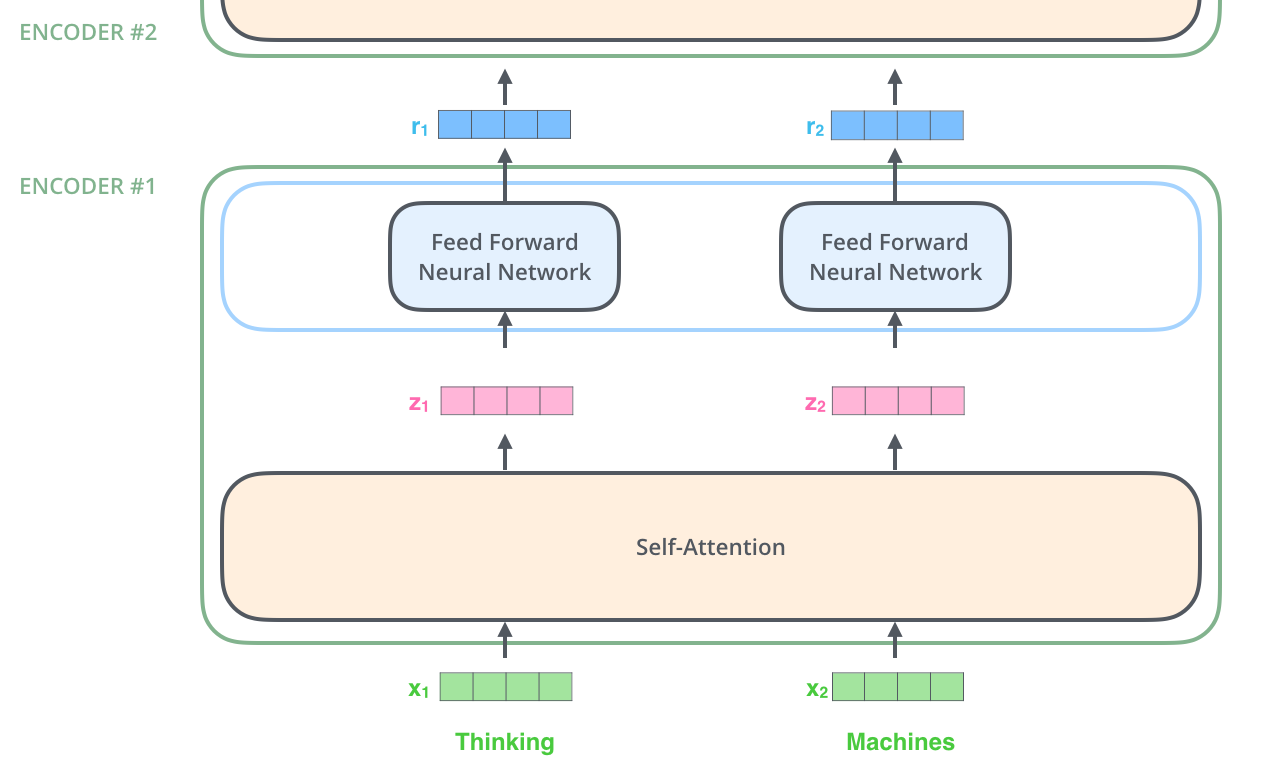
. , .
, « » -, . , «Attention is All You Need». , .
– , :
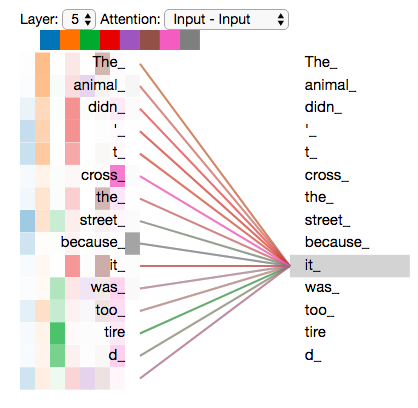
”The animal didn't cross the street because it was too tired”
«it» ? (street) (animal)? .
«it», , «it» «animal».
( ), , .
(RNN), , RNN /, , . – , , «» .

«it» #5 ( ), «The animal» «it».
Tensor2Tensor, , .
, , , .
– ( – ): (Query vector), (Key vector) (Value vector). , .
, , . 64, / 512. , (multi-head attention) .
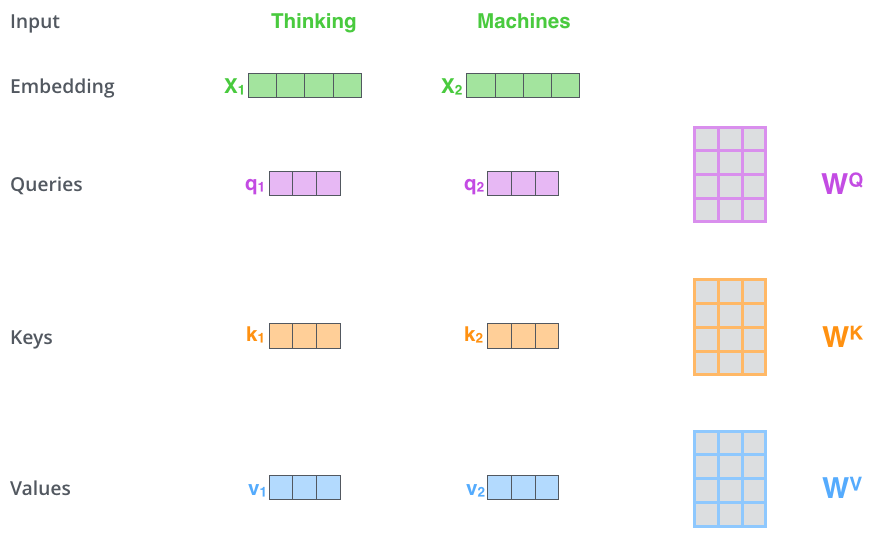
x1 WQ q1, «», . «», «» «» .
«», «» «»?
, . , , , .
– (score). , – «Thinking». . , .
. , #1, q1 k1, — q1 k2.
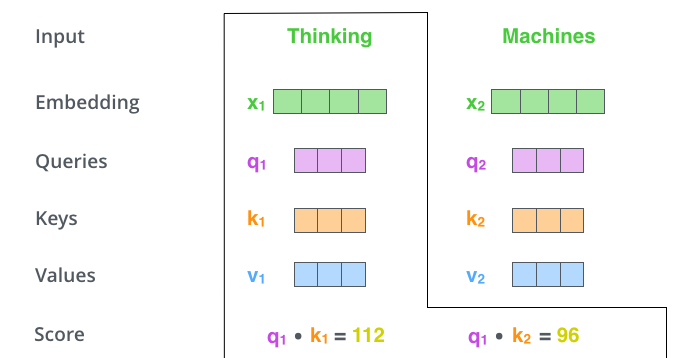
– 8 ( , – 64; , ), (softmax). , 1.
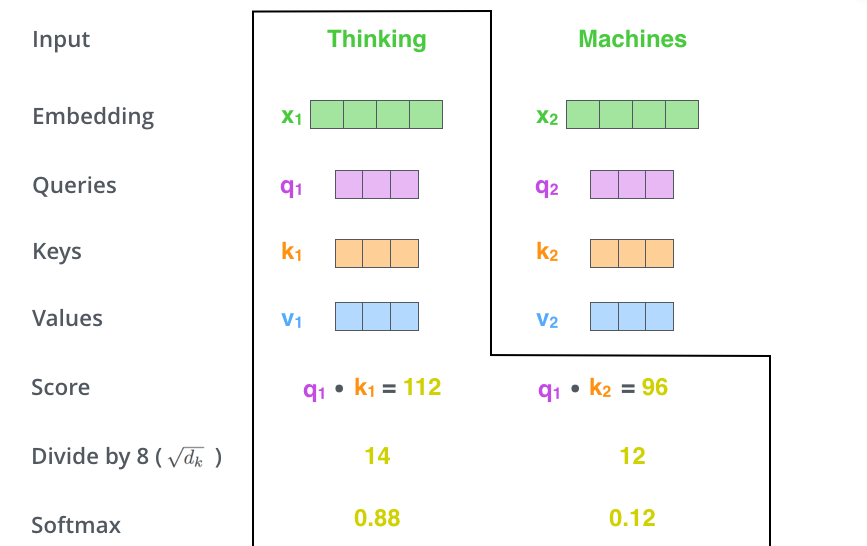
- (softmax score) , . , -, , .
– - ( ). : , , ( , , 0.001).
– . ( ).
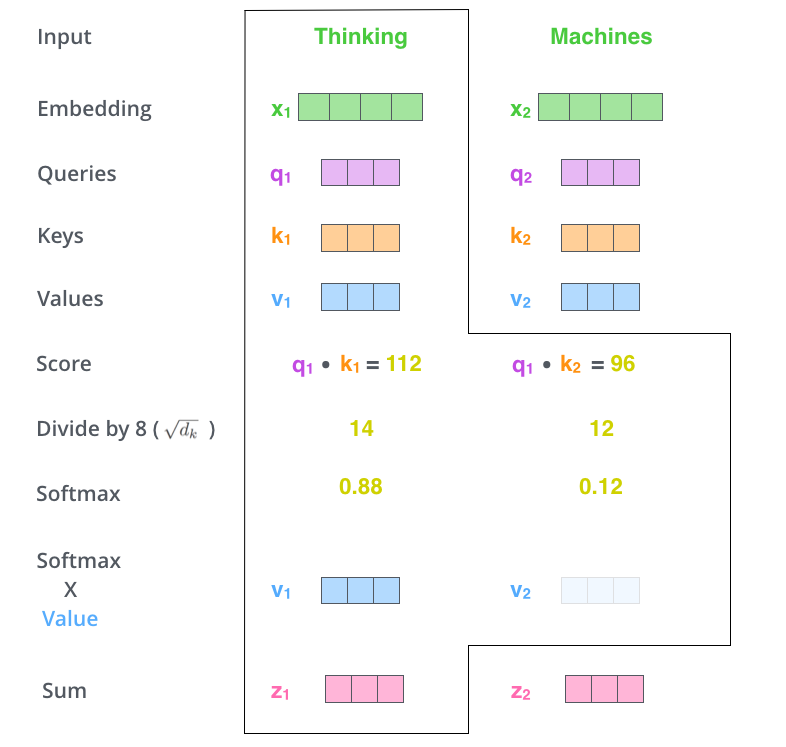
. , . , , . , , .
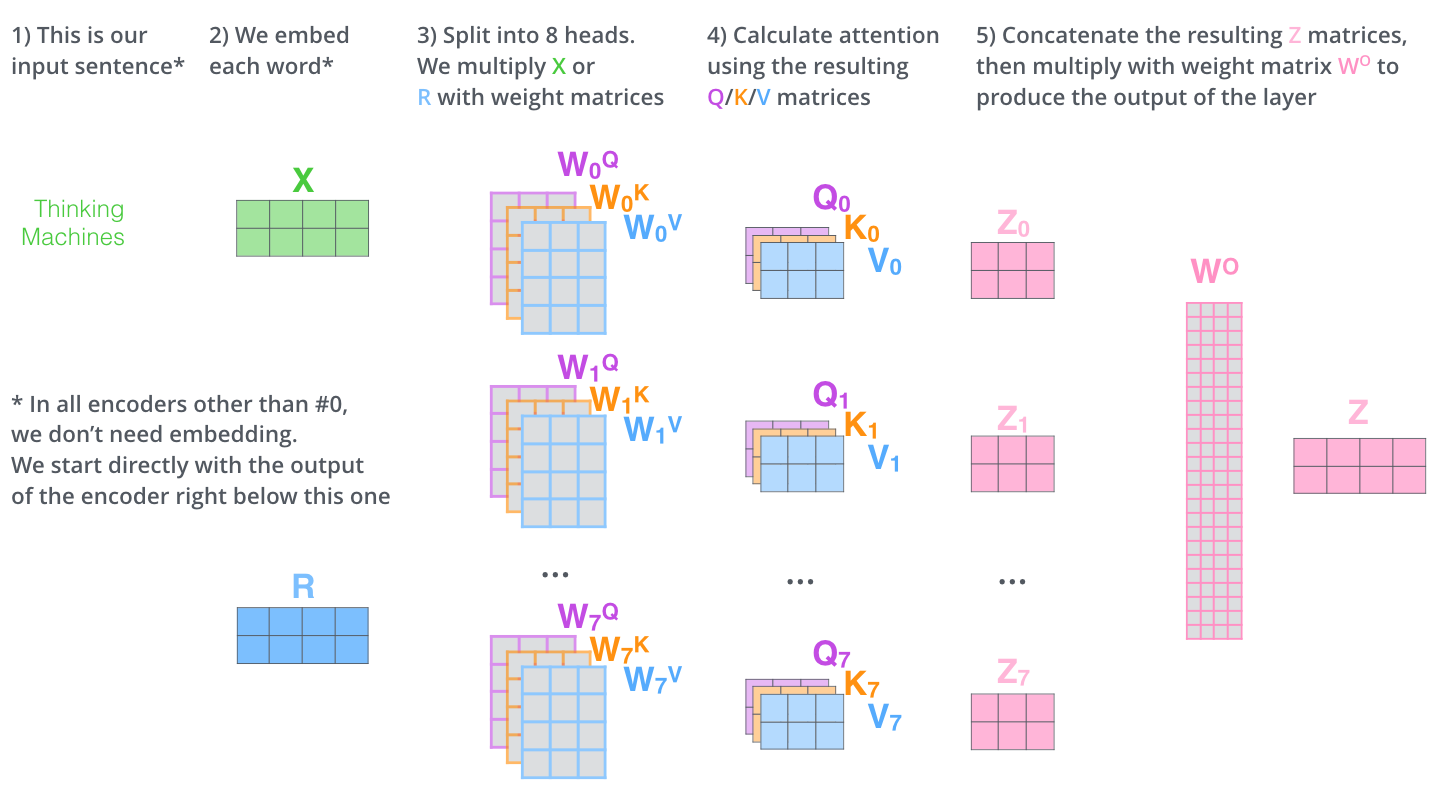
– , . X , (WQ, WK, WV).

. (512, 4 ) q/k/v (64, 3 ).
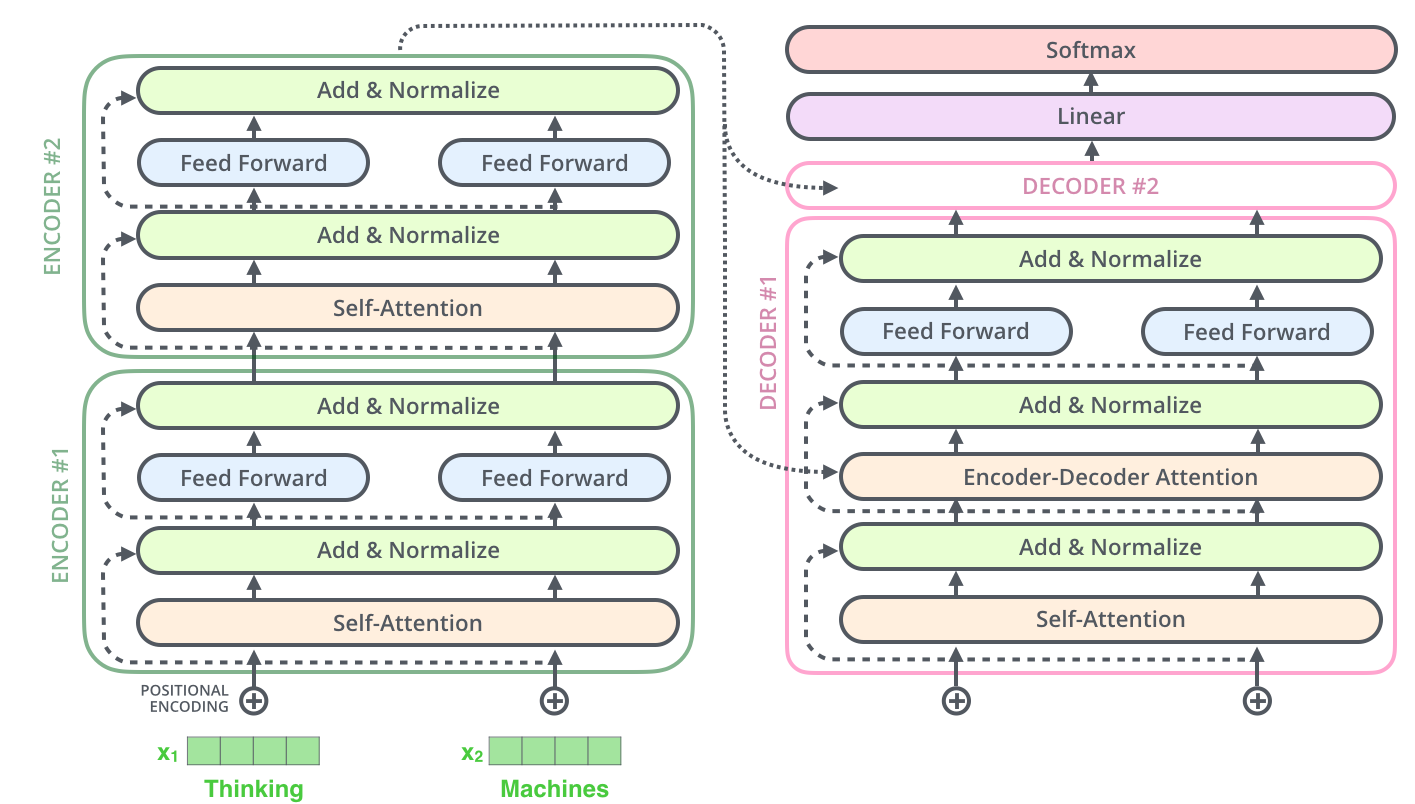
, , 2-6 .
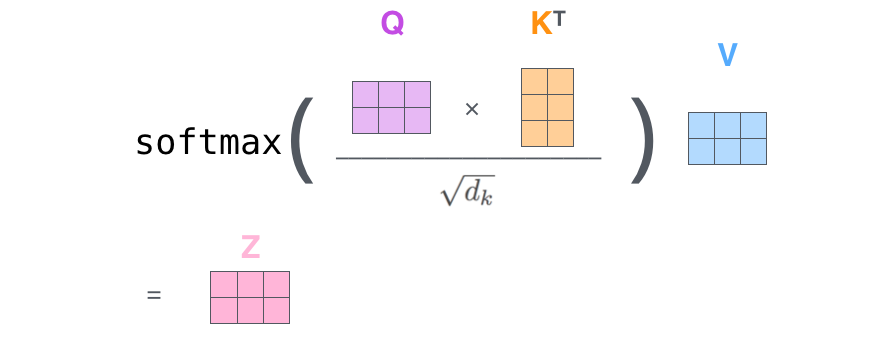
.
, (multi-head attention). :
- . , , z1 , . «The animal didn’t cross the street because it was too tired», , «it».
- « » (representation subspaces). , , // ( 8 «» , 8 /). . ( /) .
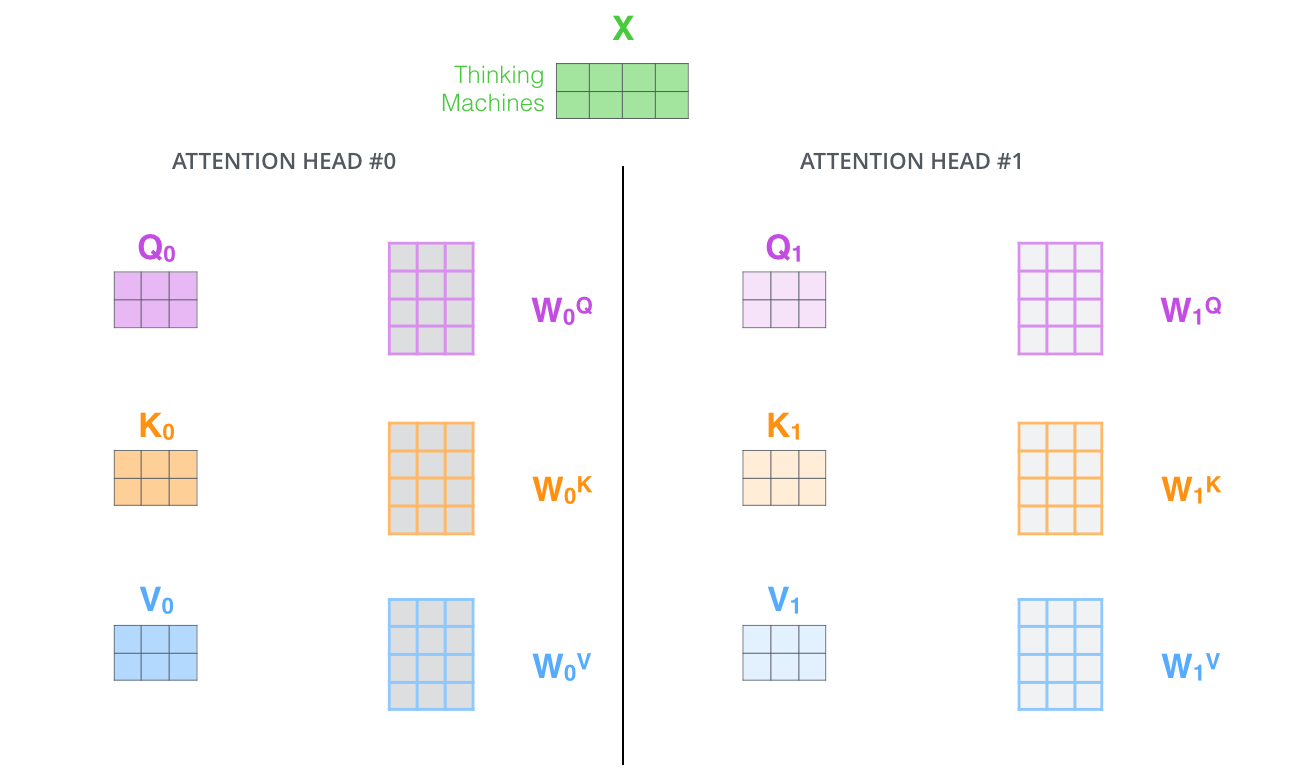
, WQ/WK/WV «», Q/K/V . , WQ/WK/WV Q/K/V .
, , 8 , 8 Z .
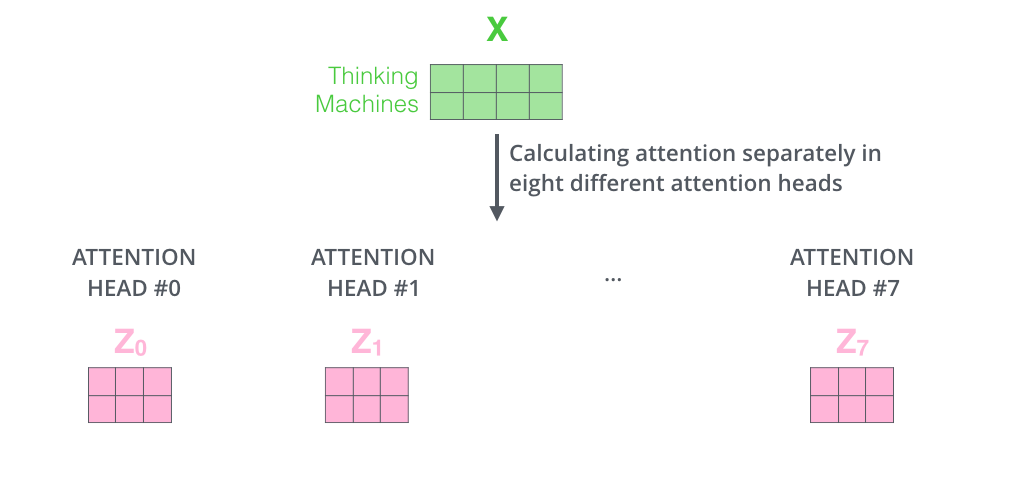
. , 8 – ( ), Z .
? WO.
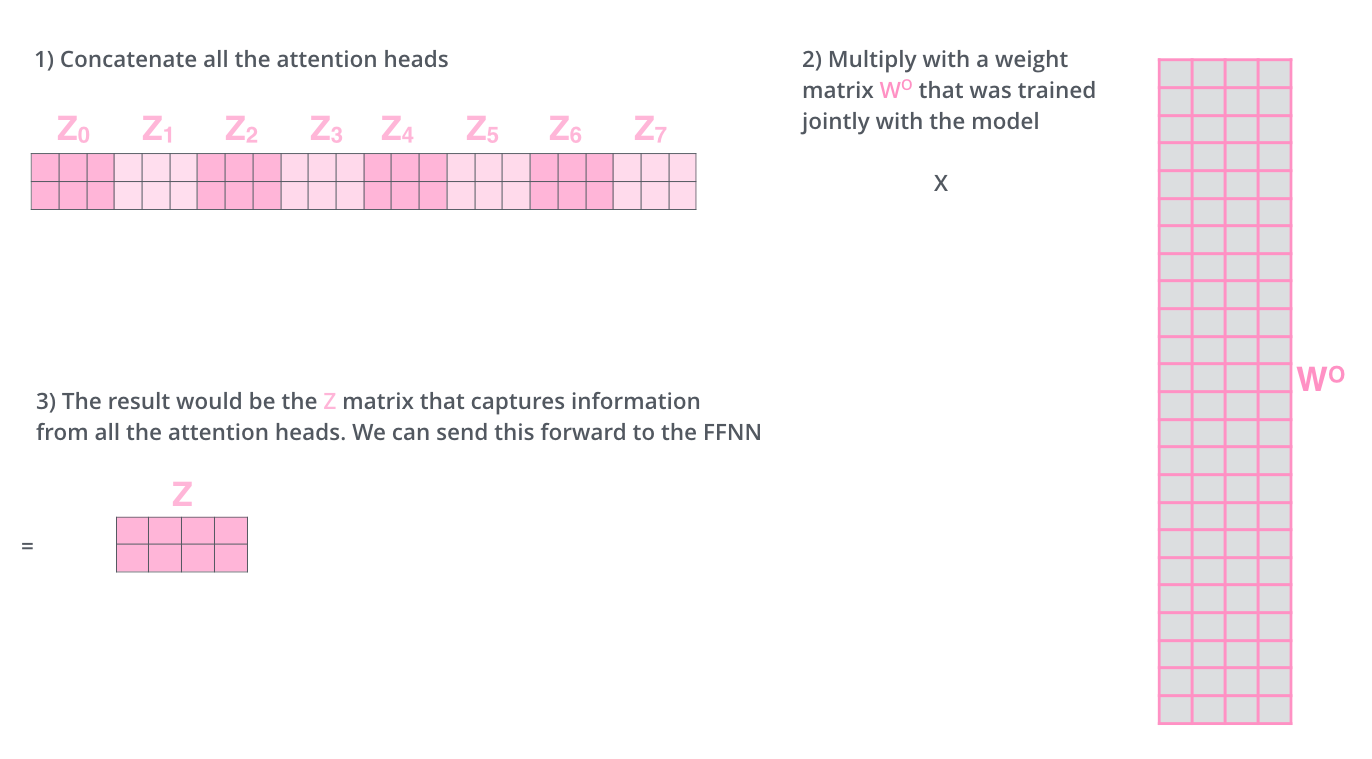
, , . , . , .
, «» , , , «» «it» :

«it», «» «the animal», — «tired». , «it» «animal» «tired».
«» , , .
— .
. , . , Q/K/V .
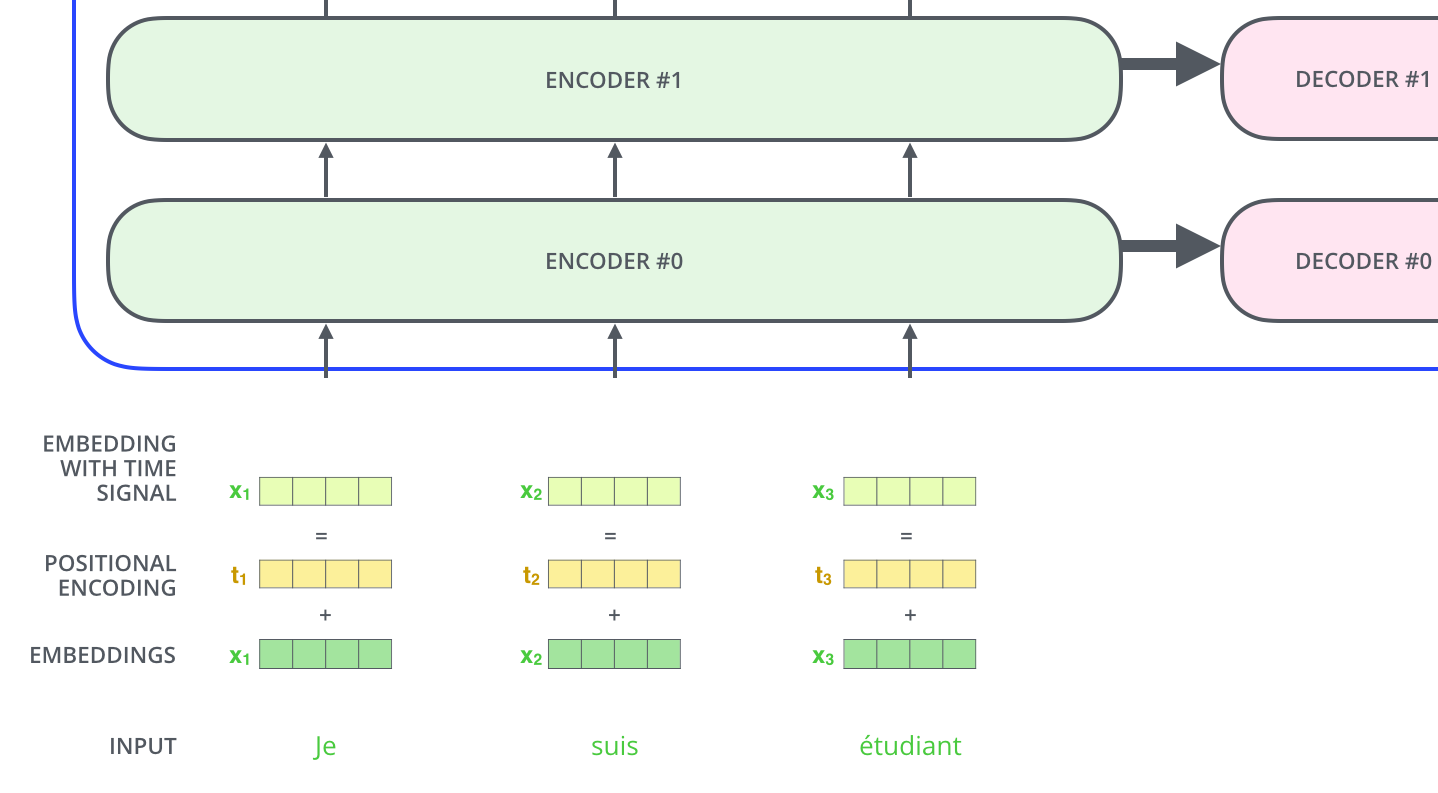
, , , .
, 4, :
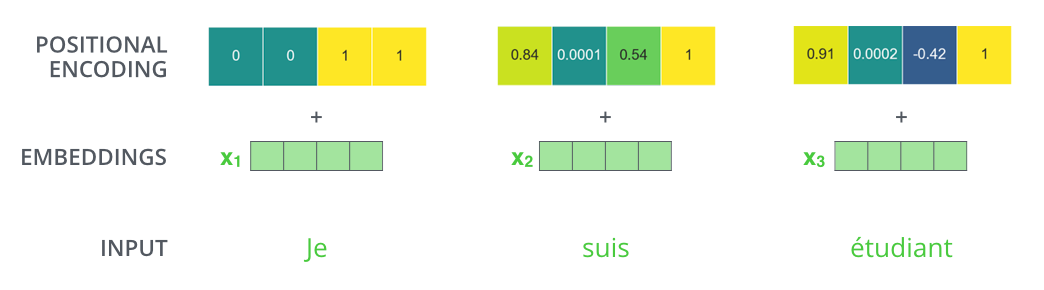
?
: , , , — .. 512 -1 1. , .
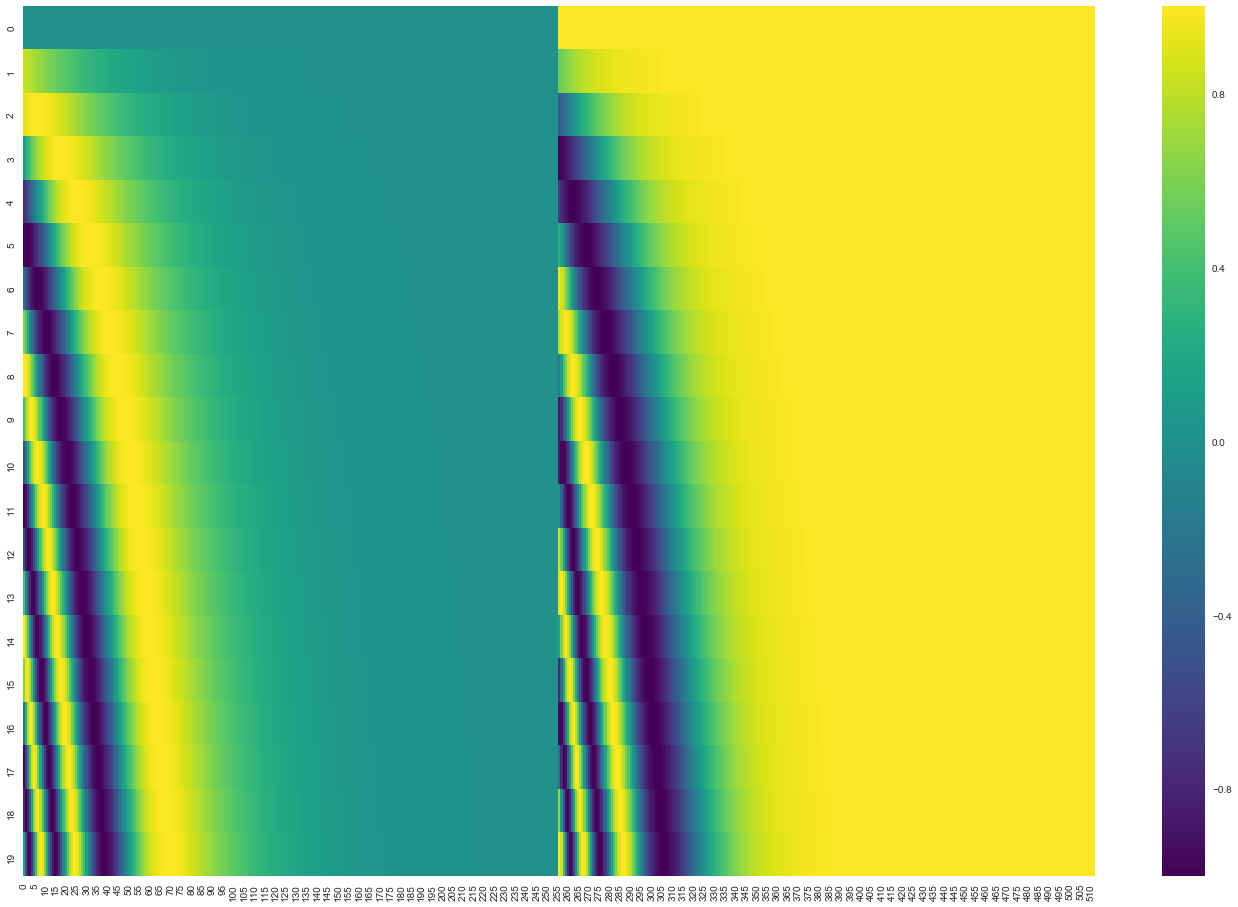
20 () 512 (). , : ( ), – ( ). .
( 3.5). get_timing_signal_1d(). , , (, , , ).
, , , , ( , ) , (layer-normalization step).
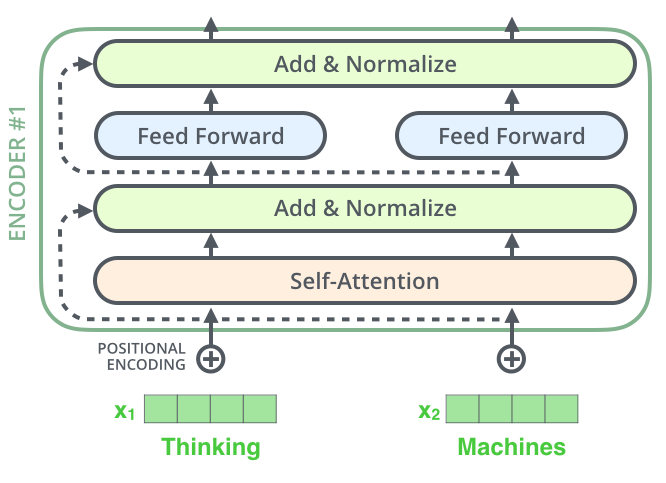
, , :
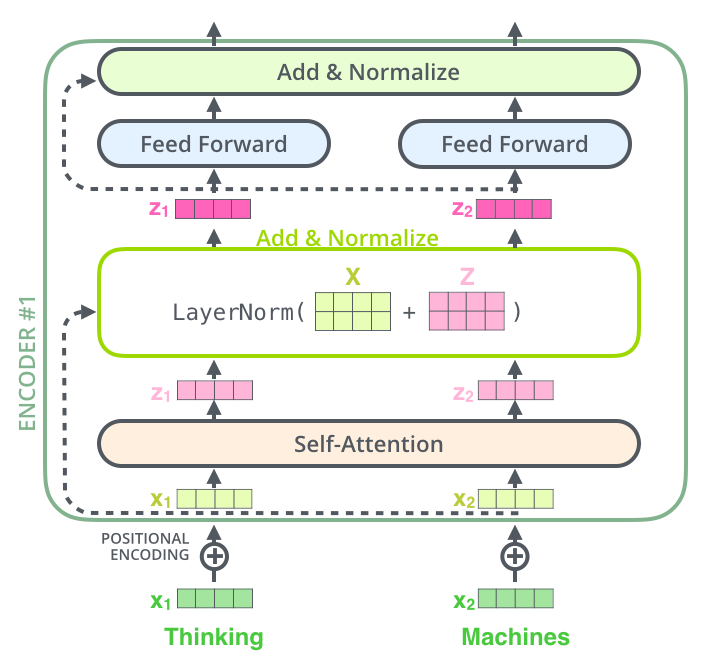
. , :
, , , . , .
. K V. «-» , :
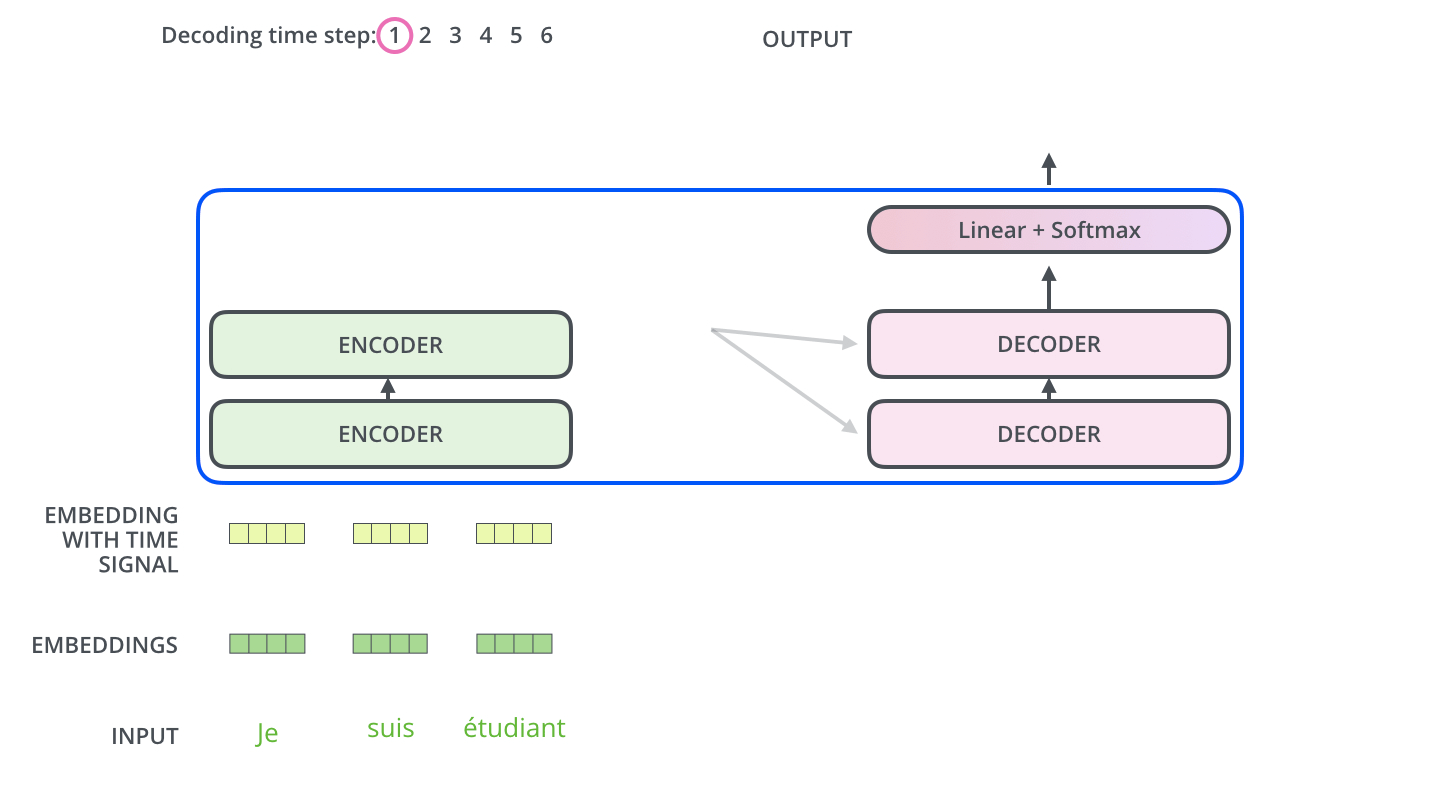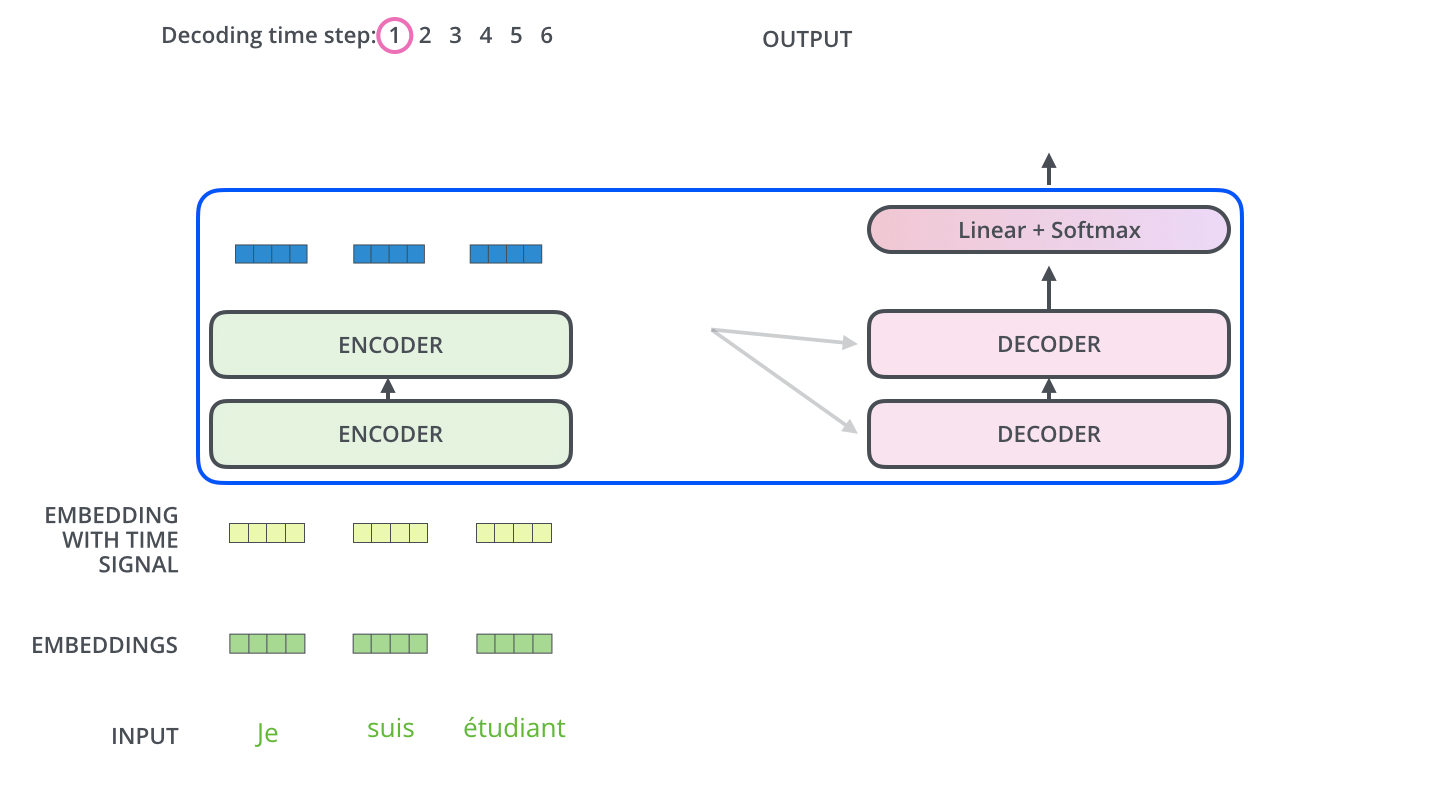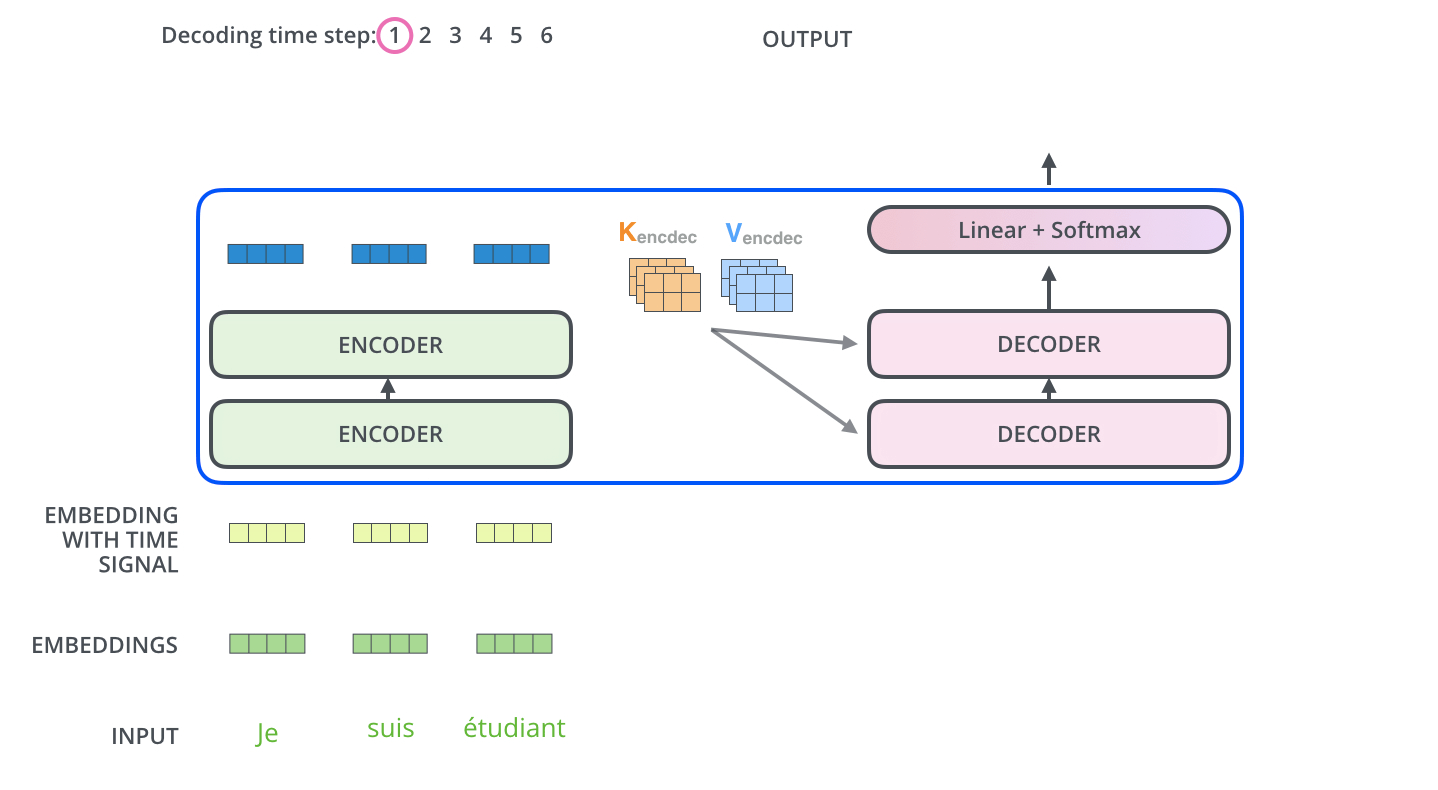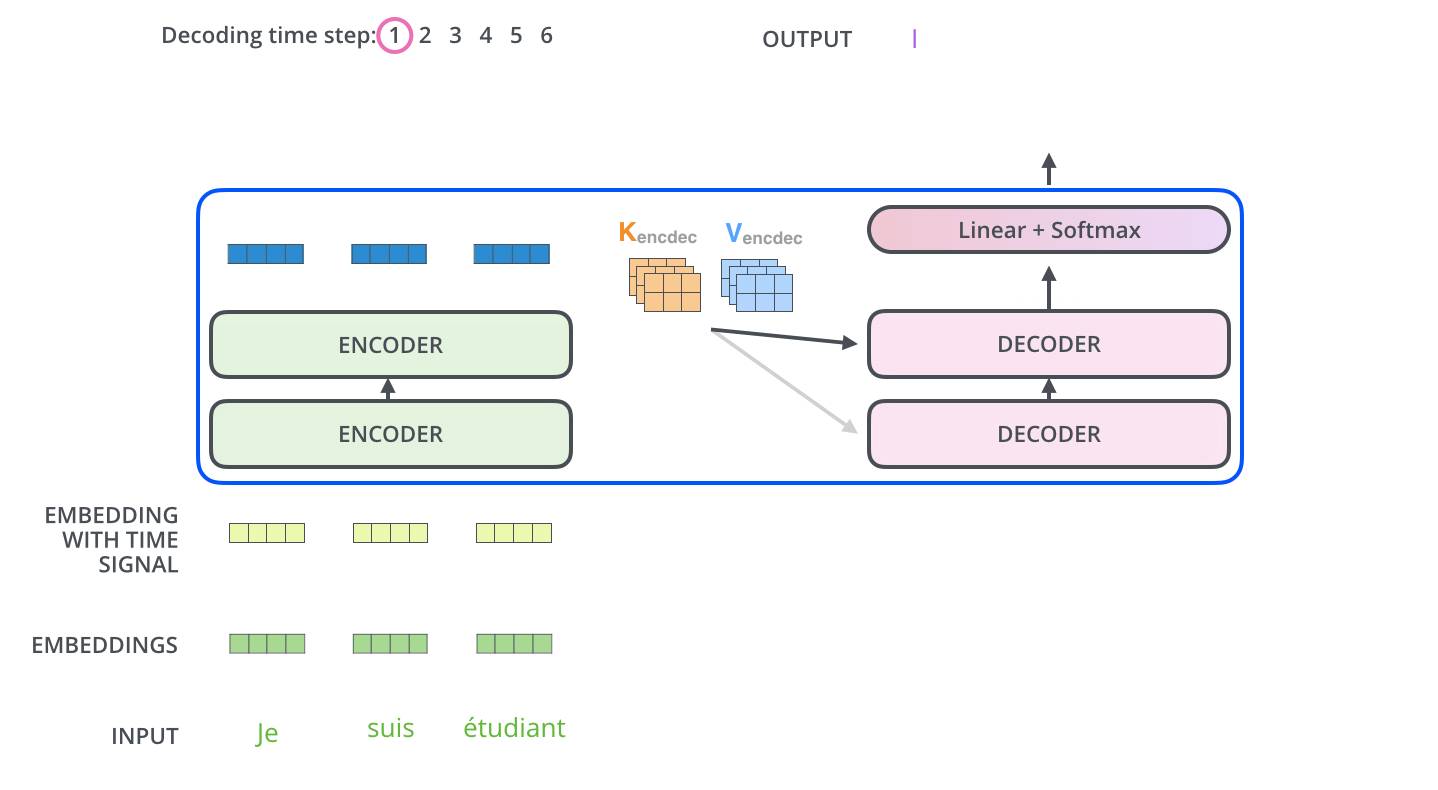
. ( – ).
, , . , , . , , , .
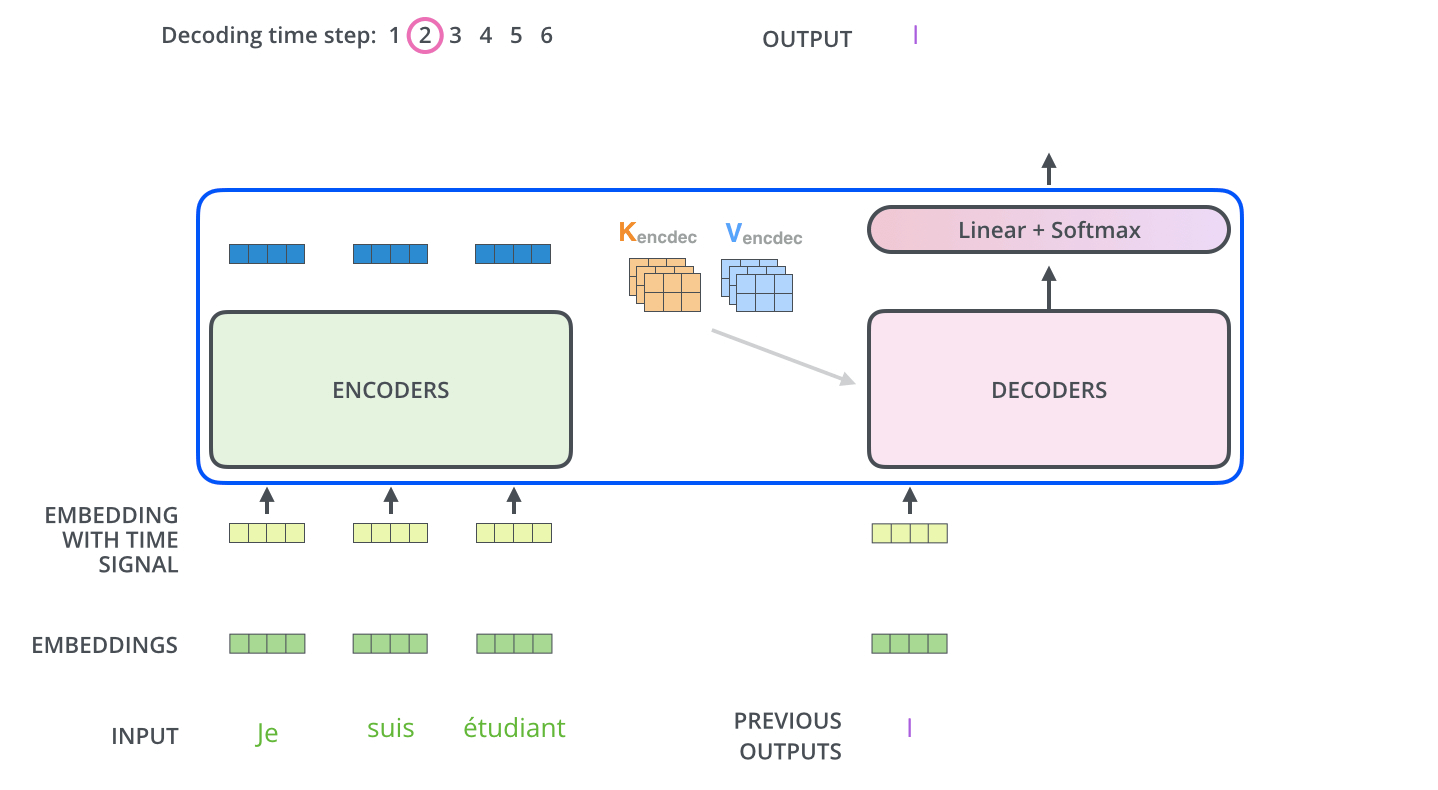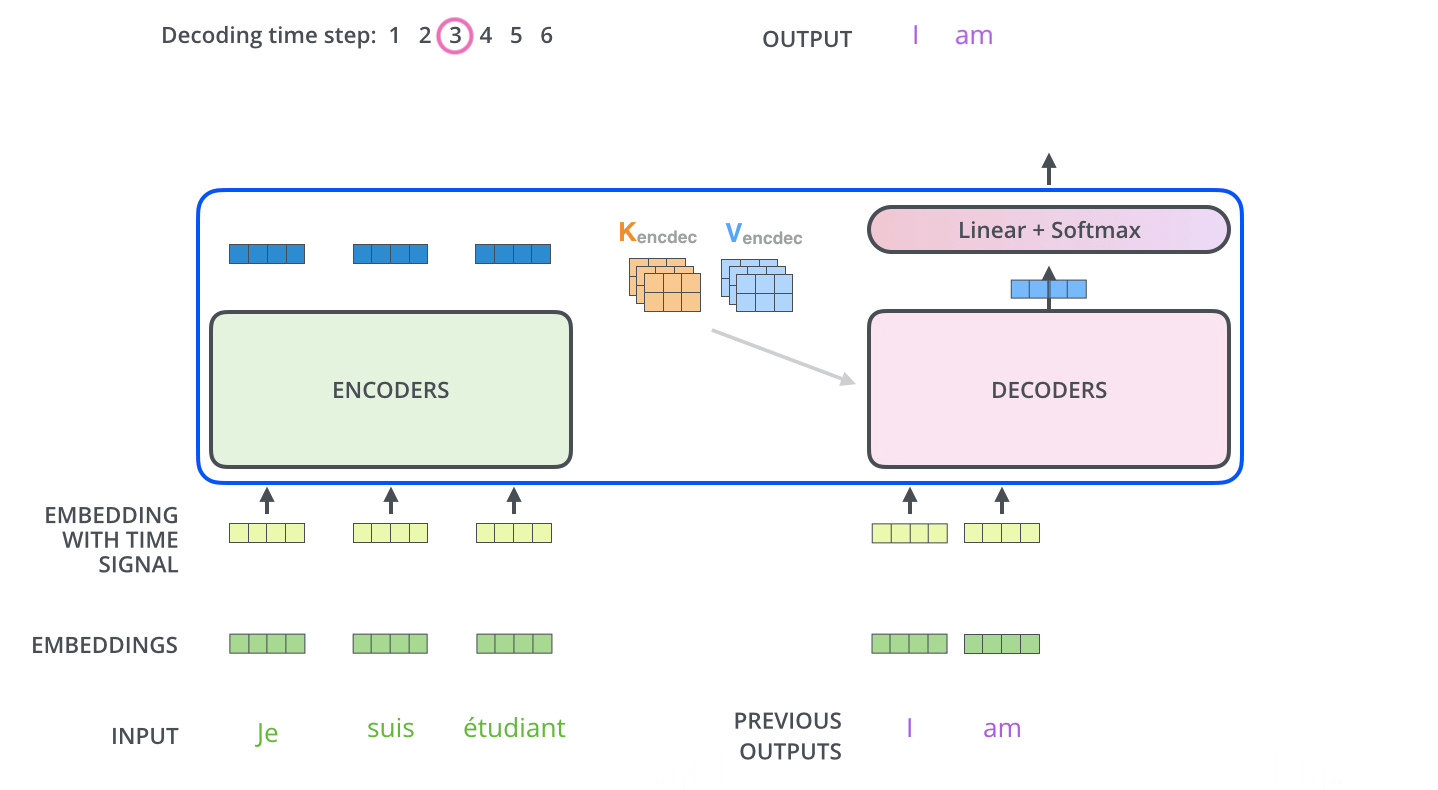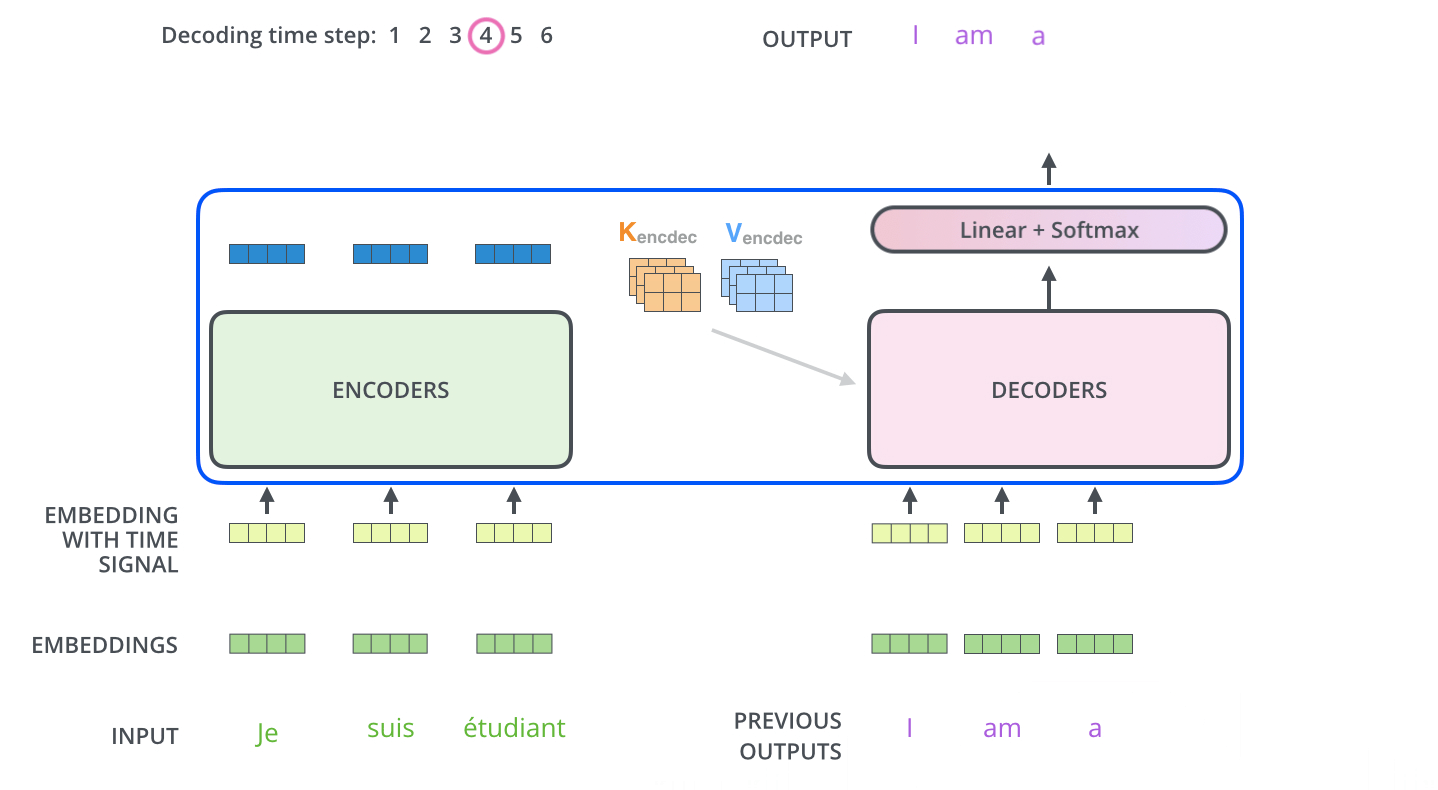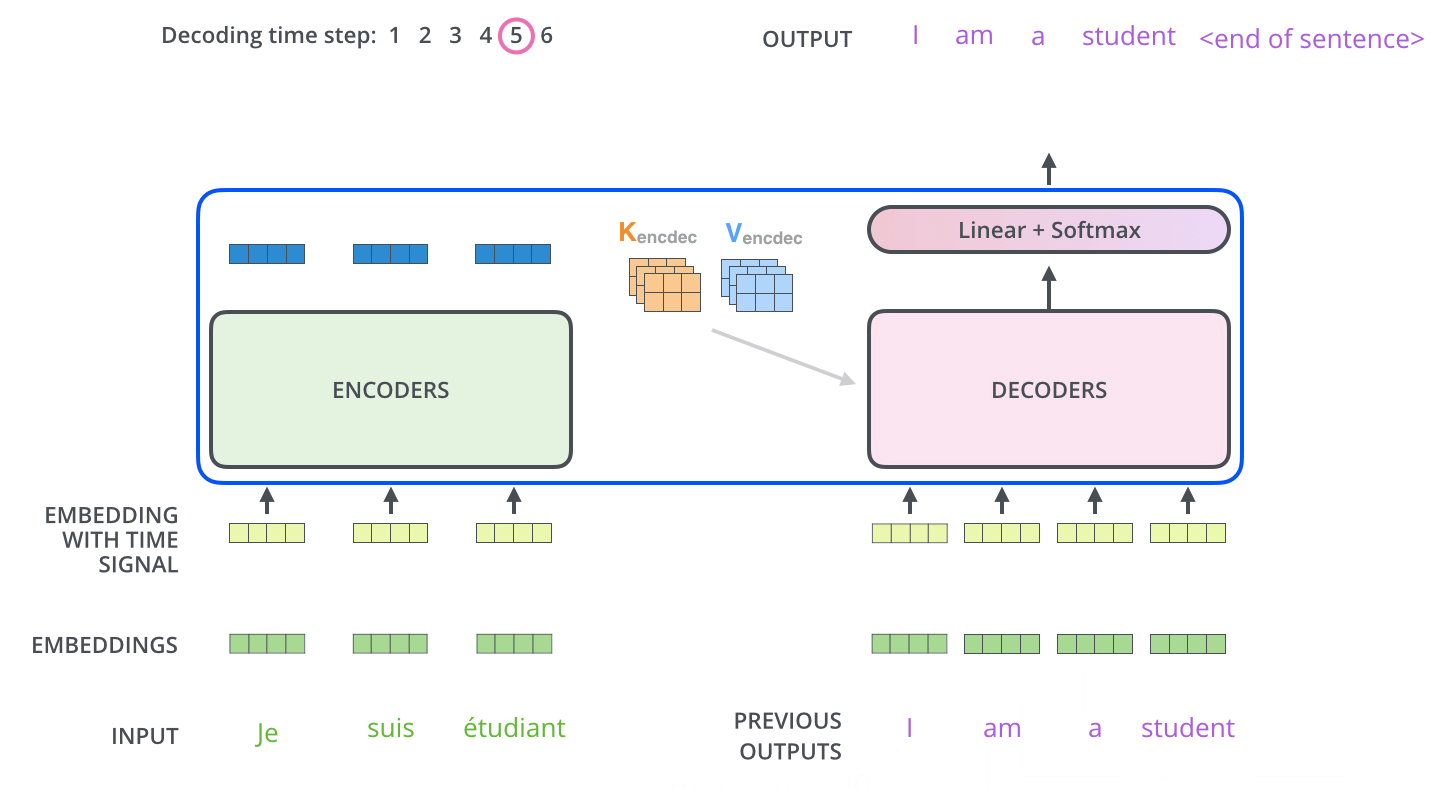
.
. ( –inf) .
«-» , , , , .
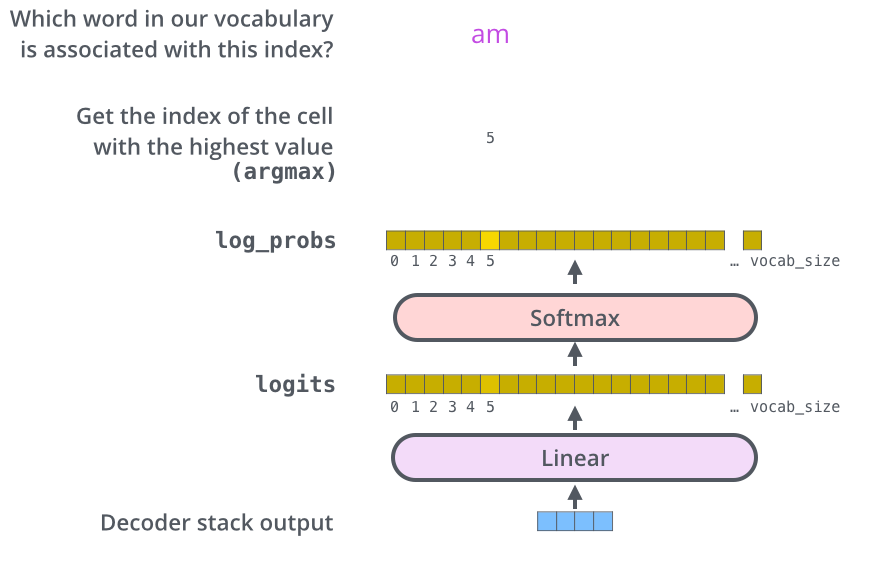
. ? .
– , , , , (logits vector).
10 (« » ), . , 10 000 – . .
( , 1). .
, , .
, , , , .
, . .. , .
, 6 («a», «am», «i», «thanks», «student» «<eos>» (« »).
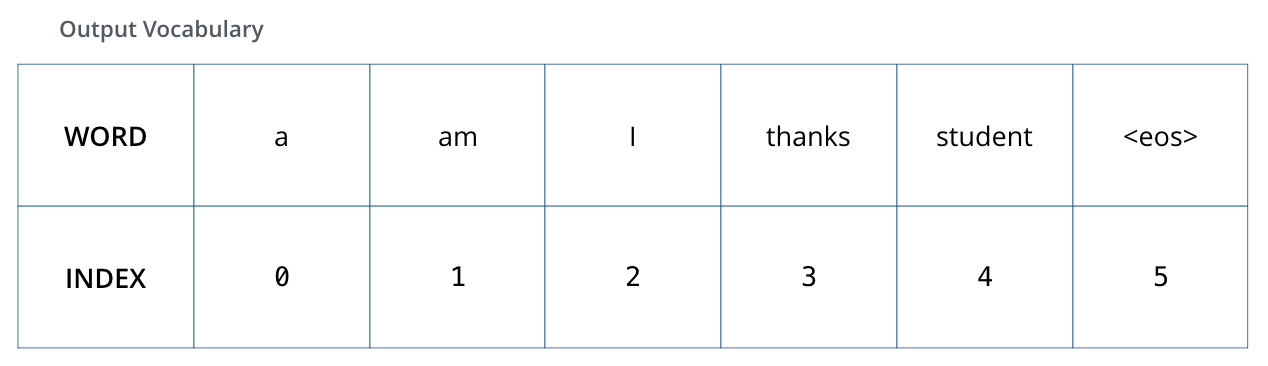
.
, (, one-hot-). , «am», :
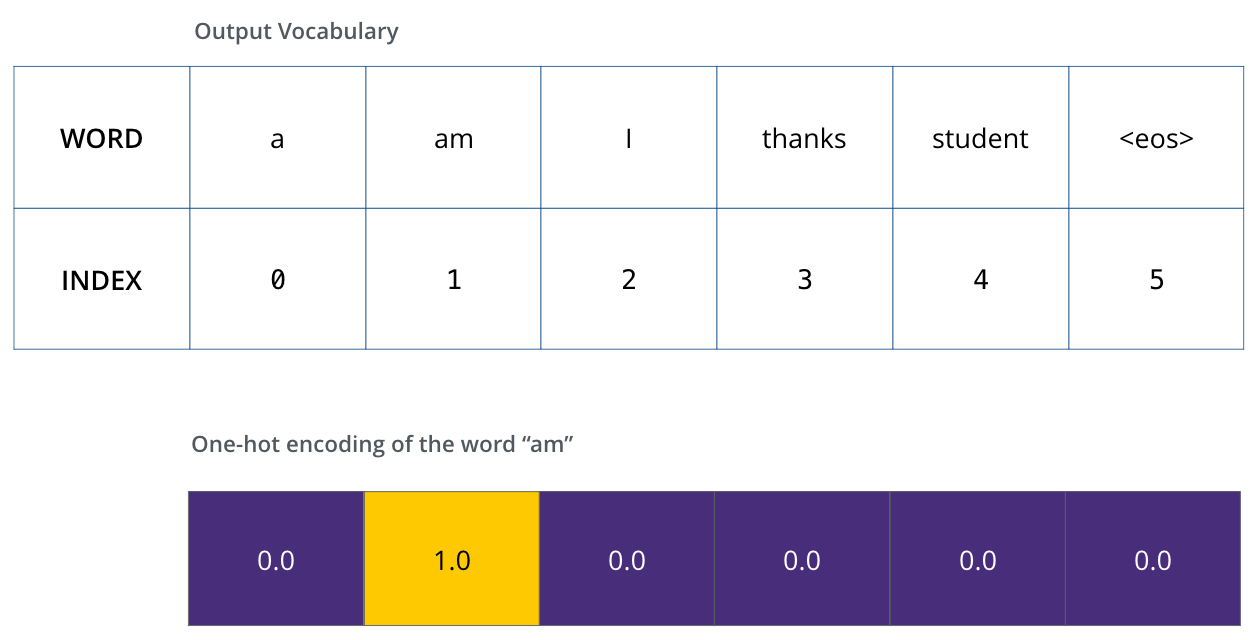
: one-hot- .
(loss function) – , , , .
, . – «merci» «thanks».
, , , «thanks». .. , .
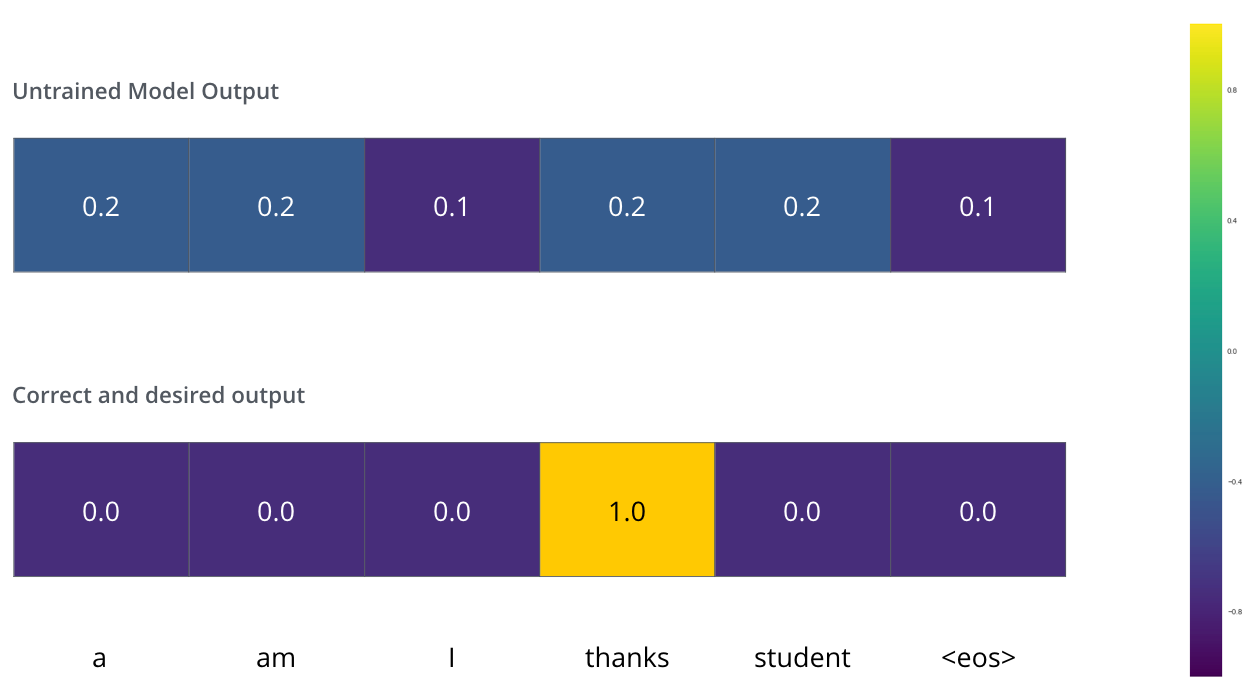
() , /. , , , .
? . , . -.
, . . , «je suis étudiant» – «I am a student». , , , :
- (6 , – 3000 10000);
- , «i»;
- , «am»;
- .. , .
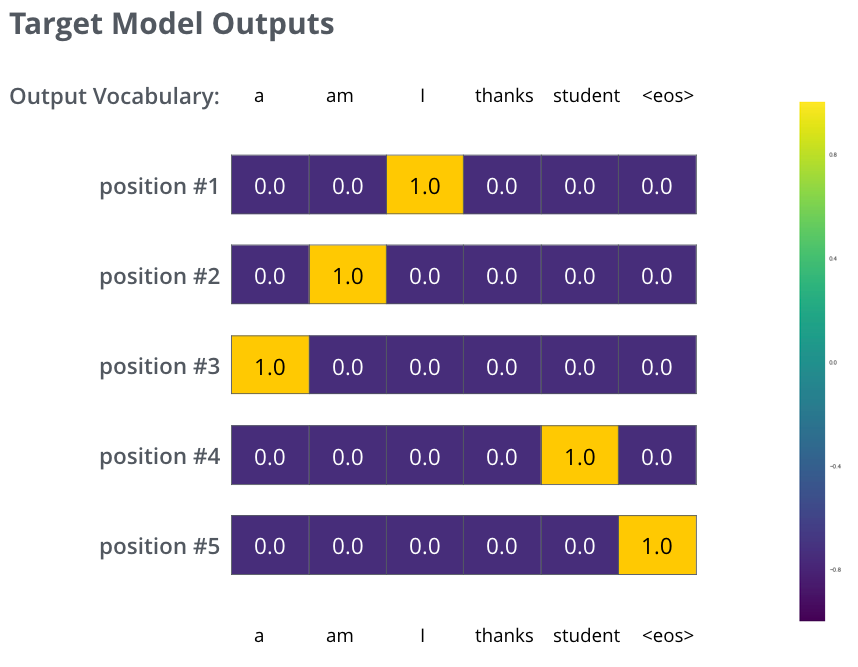
, :
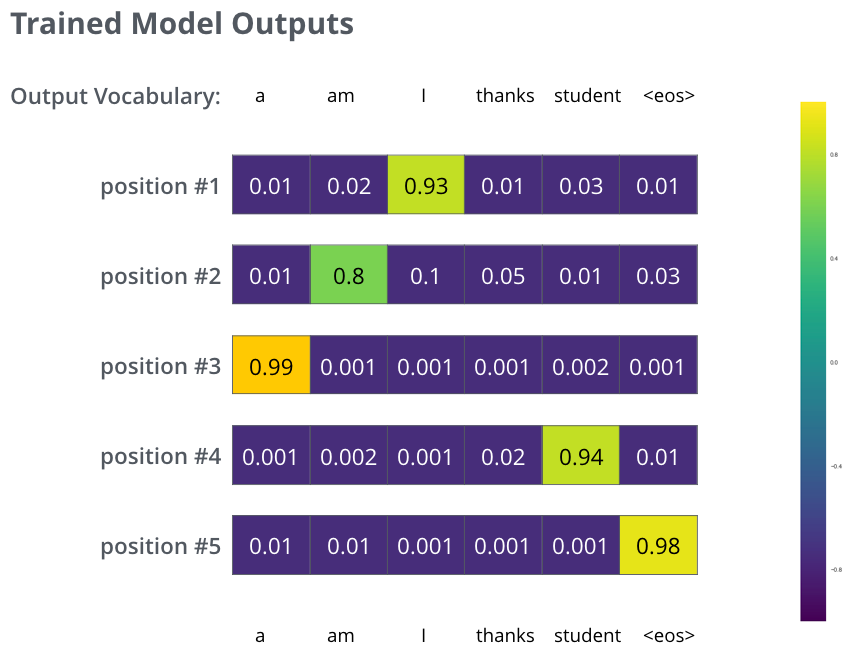
, . , , (.: ). , , , – , .
, , , , . , (greedy decoding). – , , 2 ( , «I» «a») , , : , «I», , , «a». , , . #2 #3 .. « » (beam search). (beam_size) (.. #1 #2), - (top_beams) ( ). .
, . , :
:
Auteurs