Nuage catastrophique: comment cela fonctionne
Bonjour, Habr!Après les vacances du Nouvel An, nous avons redémarré un cloud résistant aux catastrophes basé sur deux sites. Aujourd'hui, nous allons vous expliquer comment cela fonctionne et montrer ce qui arrive aux machines virtuelles clientes lorsque des éléments de cluster individuels échouent et que tout le site tombe en panne (spoiler - tout va bien avec eux). Stockage cloud résistant aux catastrophes sur le site OST.
Stockage cloud résistant aux catastrophes sur le site OST.Ce qu'il y a dedans
Sous le capot du cluster se trouvent des serveurs Cisco UCS avec hyperviseur VMware ESXi, deux systèmes de stockage INFINIDAT InfiniBox F2240, un équipement réseau Cisco Nexus, ainsi que des commutateurs SAN Brocade. Le cluster est réparti sur deux sites - OST et NORD, c'est-à-dire que dans chaque centre de données un ensemble d'équipements identique. En fait, cela le rend catastrophique.Au sein d'une même plateforme, les principaux éléments sont également dupliqués (hôtes, commutateurs SAN, carte réseau).Deux sites sont reliés par des chemins de fibre optique dédiés, également réservés.Quelques mots sur le stockage. Le premier cloud résistant aux catastrophes que nous avons construit sur NetApp. INFINIDAT a été choisi ici, et voici pourquoi:- Option de réplication active-active. Il permet à la machine virtuelle de rester opérationnelle même si l'un des systèmes de stockage tombe complètement en panne. Je vous en dirai plus sur la réplication plus tard.
- Trois contrôleurs de disque pour une meilleure résilience du système. Il y en a généralement deux.
- Solution prête. Un rack déjà assemblé nous est parvenu, qui n'a besoin que d'être connecté au réseau et configuré.
- Support technique attentif. Les ingénieurs INFINIDAT analysent en permanence les journaux et les événements des systèmes de stockage, installent de nouvelles versions dans le micrologiciel et aident à la configuration.
Voici quelques photos de déballage:

Comment ça marche
Le cloud est déjà résilient en lui-même. Il protège le client contre les pannes matérielles et logicielles uniques. Une catastrophe aidera à protéger contre les pannes de masse au sein d'un même site: par exemple, la défaillance du système de stockage (ou du cluster SDS, ce qui arrive souvent :)), les erreurs de masse dans le réseau de stockage et plus encore. Eh bien et le plus important: un tel nuage enregistre lorsqu'un site entier devient inaccessible en raison d'un incendie, d'une panne de courant, d'une capture de voleur, d'atterrissages étrangers.Dans tous ces cas, les machines virtuelles clientes continuent de fonctionner, et voici pourquoi.Le schéma de cluster est conçu pour que tout hôte ESXi avec des machines virtuelles clientes puisse accéder à l'un des deux systèmes de stockage. Si le stockage sur le site OST échoue, les machines virtuelles continueront de fonctionner: les hôtes sur lesquels elles travaillent accéderont au stockage sur NORD pour les données. Voici à quoi ressemble le diagramme de connexion dans le cluster.Cela est possible du fait qu’une liaison inter-commutateurs est configurée entre les usines SAN des deux sites: le commutateur Fabric A OST SAN est connecté au commutateur Fabric A NORD SAN, de la même manière que les commutateurs Fabric B SAN.Eh bien, pour que toutes ces subtilités des usines SAN aient un sens, la réplication Active-Active est configurée entre les deux systèmes de stockage: les informations sont écrites presque simultanément sur les systèmes de stockage local et distant, RPO = 0. Il s'avère que sur un SHD les données originales sont stockées, sur l'autre - leur réplique. Les données sont répliquées au niveau du volume de stockage et les données de la machine virtuelle (ses disques, fichier de configuration, fichier d'échange, etc.) y sont déjà stockées.L'hôte ESXi considère le volume principal et sa réplique comme un seul périphérique de stockage. Il existe 24 chemins depuis l'hôte ESXi vers chaque périphérique de disque:12 chemins l'associent au stockage local (chemins optimaux) et les 12 autres - au distant (chemins non optimaux). Dans une situation normale, ESXi accède aux données sur le stockage local en utilisant des chemins «optimaux». Si ce système de stockage tombe en panne, ESXi perd ses chemins optimaux et passe à des chemins «non optimaux». Voici à quoi cela ressemble dans le diagramme.
Voici à quoi ressemble le diagramme de connexion dans le cluster.Cela est possible du fait qu’une liaison inter-commutateurs est configurée entre les usines SAN des deux sites: le commutateur Fabric A OST SAN est connecté au commutateur Fabric A NORD SAN, de la même manière que les commutateurs Fabric B SAN.Eh bien, pour que toutes ces subtilités des usines SAN aient un sens, la réplication Active-Active est configurée entre les deux systèmes de stockage: les informations sont écrites presque simultanément sur les systèmes de stockage local et distant, RPO = 0. Il s'avère que sur un SHD les données originales sont stockées, sur l'autre - leur réplique. Les données sont répliquées au niveau du volume de stockage et les données de la machine virtuelle (ses disques, fichier de configuration, fichier d'échange, etc.) y sont déjà stockées.L'hôte ESXi considère le volume principal et sa réplique comme un seul périphérique de stockage. Il existe 24 chemins depuis l'hôte ESXi vers chaque périphérique de disque:12 chemins l'associent au stockage local (chemins optimaux) et les 12 autres - au distant (chemins non optimaux). Dans une situation normale, ESXi accède aux données sur le stockage local en utilisant des chemins «optimaux». Si ce système de stockage tombe en panne, ESXi perd ses chemins optimaux et passe à des chemins «non optimaux». Voici à quoi cela ressemble dans le diagramme. Le schéma d'un cluster résistant aux catastrophes.Tous les réseaux clients sont établis sur les deux sites via une usine de réseau commune. Provider Edge (PE) s'exécute sur chaque site, sur lequel les réseaux clients sont terminés. Les PE sont combinés en un seul cluster. Si PE échoue sur un site, tout le trafic est redirigé vers le deuxième site. Grâce à cela, les machines virtuelles du site sans PE restent disponibles sur le réseau pour le client.Voyons maintenant ce qui arrivera aux machines virtuelles clientes en cas de pannes diverses. Commençons par les options les plus légères et terminons par les plus graves - la défaillance de l'ensemble du site. Dans les exemples, le site principal sera OST et la sauvegarde, avec des répliques de données, sera NORD.
Le schéma d'un cluster résistant aux catastrophes.Tous les réseaux clients sont établis sur les deux sites via une usine de réseau commune. Provider Edge (PE) s'exécute sur chaque site, sur lequel les réseaux clients sont terminés. Les PE sont combinés en un seul cluster. Si PE échoue sur un site, tout le trafic est redirigé vers le deuxième site. Grâce à cela, les machines virtuelles du site sans PE restent disponibles sur le réseau pour le client.Voyons maintenant ce qui arrivera aux machines virtuelles clientes en cas de pannes diverses. Commençons par les options les plus légères et terminons par les plus graves - la défaillance de l'ensemble du site. Dans les exemples, le site principal sera OST et la sauvegarde, avec des répliques de données, sera NORD.Qu'advient-il d'une machine virtuelle cliente si ...
Échec du lien de réplication. La réplication entre les systèmes de stockage des deux sites s'arrête.ESXi ne fonctionnera qu'avec des périphériques de disque locaux (le long des chemins optimaux).Les machines virtuelles continuent de fonctionner. Il y a un écart ISL (Inter-Switch Link). L'affaire est peu probable. Sauf si une excavatrice folle creuse plusieurs routes optiques à la fois, qui passent par des routes indépendantes et sont amenées sur les sites par différentes entrées. Mais peu importe. Dans ce cas, les hôtes ESXi perdent la moitié de leur chemin d'accès et ne peuvent accéder qu'à leur stockage local. Les répliques sont collectées, mais les hôtes ne pourront pas y accéder.Les machines virtuelles fonctionnent normalement.
Il y a un écart ISL (Inter-Switch Link). L'affaire est peu probable. Sauf si une excavatrice folle creuse plusieurs routes optiques à la fois, qui passent par des routes indépendantes et sont amenées sur les sites par différentes entrées. Mais peu importe. Dans ce cas, les hôtes ESXi perdent la moitié de leur chemin d'accès et ne peuvent accéder qu'à leur stockage local. Les répliques sont collectées, mais les hôtes ne pourront pas y accéder.Les machines virtuelles fonctionnent normalement. Refuse un commutateur SAN sur l'un des sites.Les hôtes ESXi perdent certains de leurs chemins de stockage. Dans ce cas, les hôtes du site où le commutateur a échoué ne fonctionneront que via leur propre HBA.Dans le même temps, les machines virtuelles continuent de fonctionner normalement.
Refuse un commutateur SAN sur l'un des sites.Les hôtes ESXi perdent certains de leurs chemins de stockage. Dans ce cas, les hôtes du site où le commutateur a échoué ne fonctionneront que via leur propre HBA.Dans le même temps, les machines virtuelles continuent de fonctionner normalement. Tous les commutateurs SAN sur l'un des sites échouent. Disons qu'une telle catastrophe s'est produite sur le site de l'OST. Dans ce cas, les hôtes ESXi sur ce site perdront tous les chemins d'accès à leurs périphériques de disque. Le mécanisme standard de VMware vSphere HA entre en jeu: il redémarrera toutes les machines virtuelles de la plateforme OST dans NORD après un maximum de 140 secondes.Les machines virtuelles exécutées sur les hôtes du site NORD fonctionnent normalement.
Tous les commutateurs SAN sur l'un des sites échouent. Disons qu'une telle catastrophe s'est produite sur le site de l'OST. Dans ce cas, les hôtes ESXi sur ce site perdront tous les chemins d'accès à leurs périphériques de disque. Le mécanisme standard de VMware vSphere HA entre en jeu: il redémarrera toutes les machines virtuelles de la plateforme OST dans NORD après un maximum de 140 secondes.Les machines virtuelles exécutées sur les hôtes du site NORD fonctionnent normalement.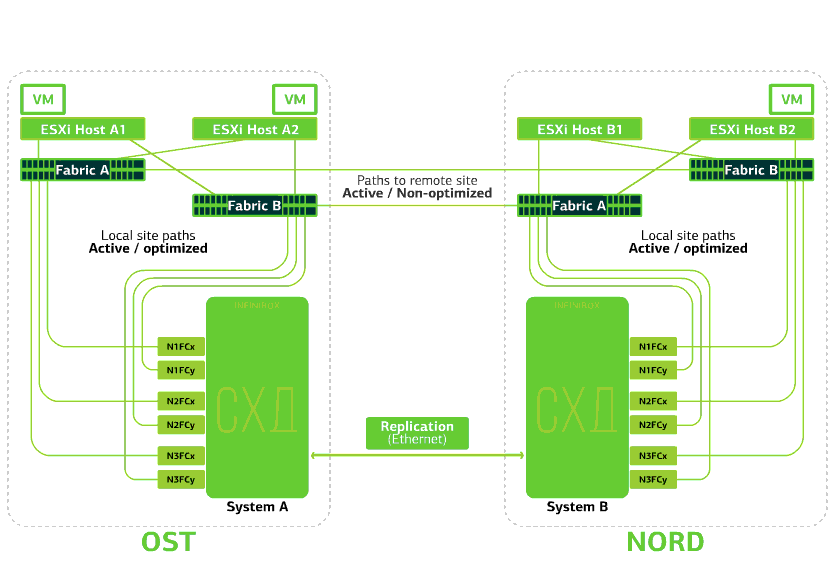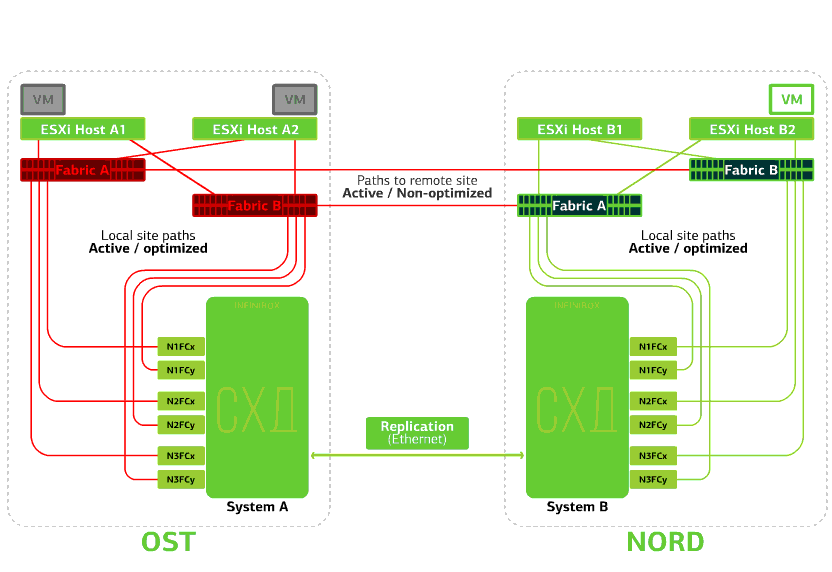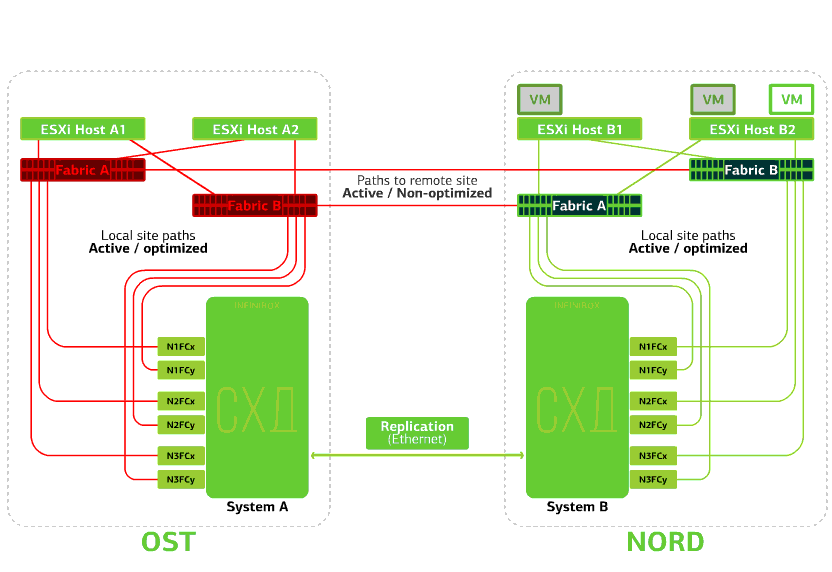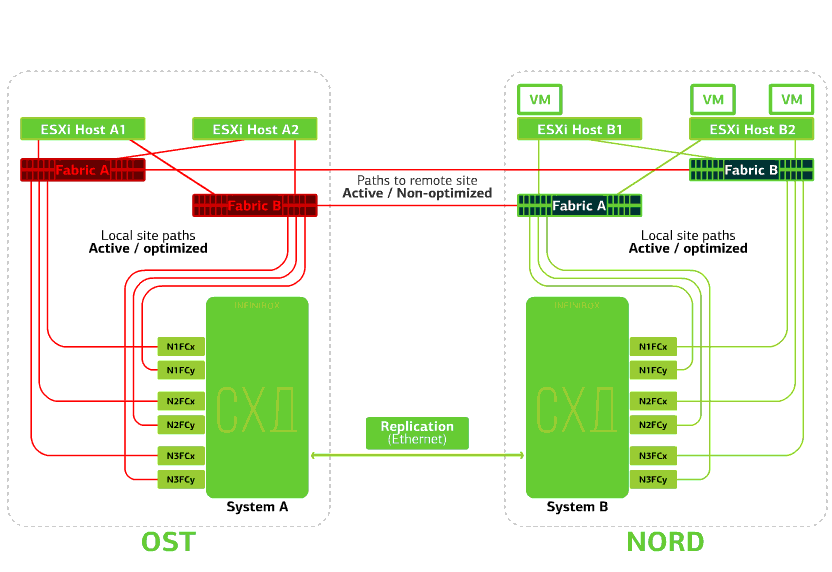 Refuse l'hôte ESXi sur un seul site.Ici, le mécanisme vSphere HA fonctionne à nouveau: les machines virtuelles d'un hôte défaillant sont redémarrées sur d'autres hôtes - sur le même site ou sur un site distant. Le temps de redémarrage de la machine virtuelle peut aller jusqu'à 1 minute.Si tous les hôtes ESXi de la plate-forme OST échouent, il n'y a pas d'options: les VM redémarrent sur un autre. L'heure de redémarrage est la même.
Refuse l'hôte ESXi sur un seul site.Ici, le mécanisme vSphere HA fonctionne à nouveau: les machines virtuelles d'un hôte défaillant sont redémarrées sur d'autres hôtes - sur le même site ou sur un site distant. Le temps de redémarrage de la machine virtuelle peut aller jusqu'à 1 minute.Si tous les hôtes ESXi de la plate-forme OST échouent, il n'y a pas d'options: les VM redémarrent sur un autre. L'heure de redémarrage est la même.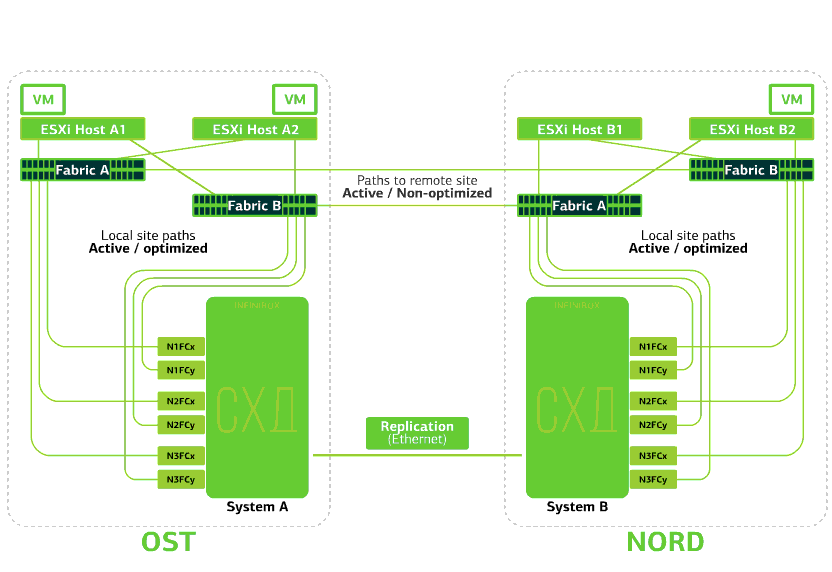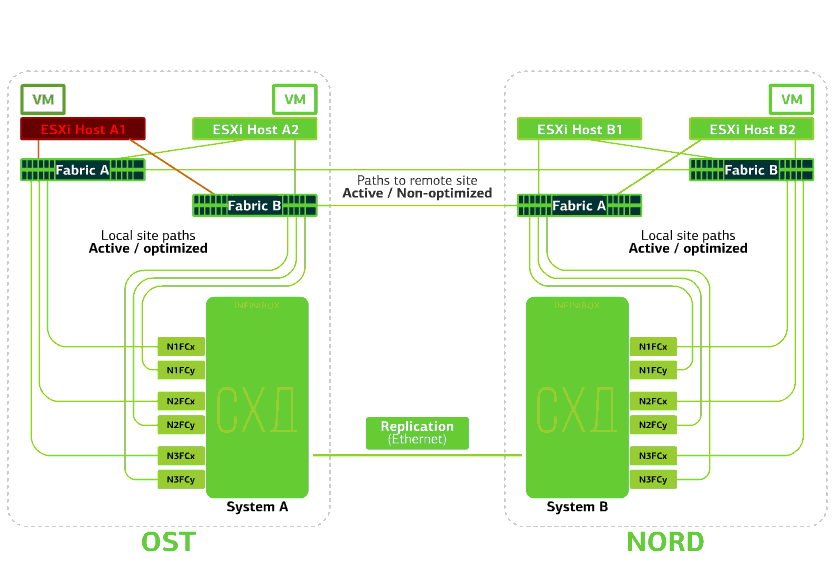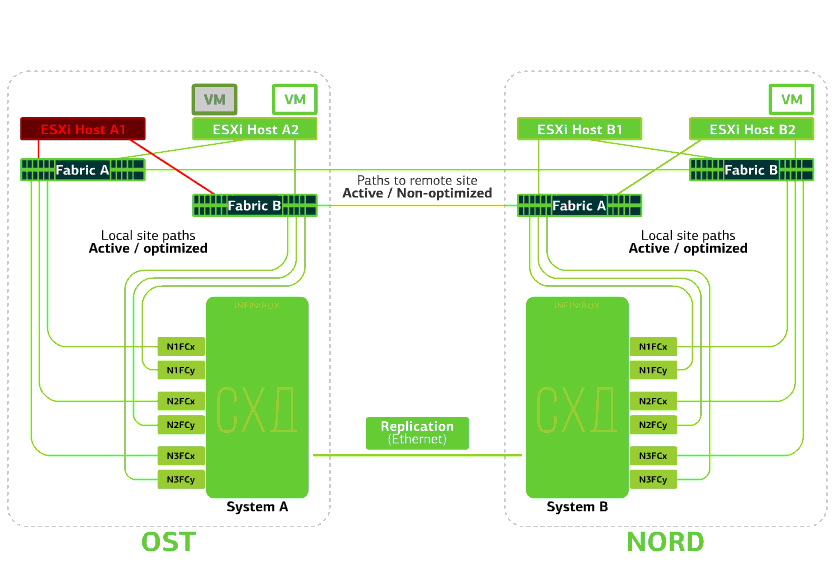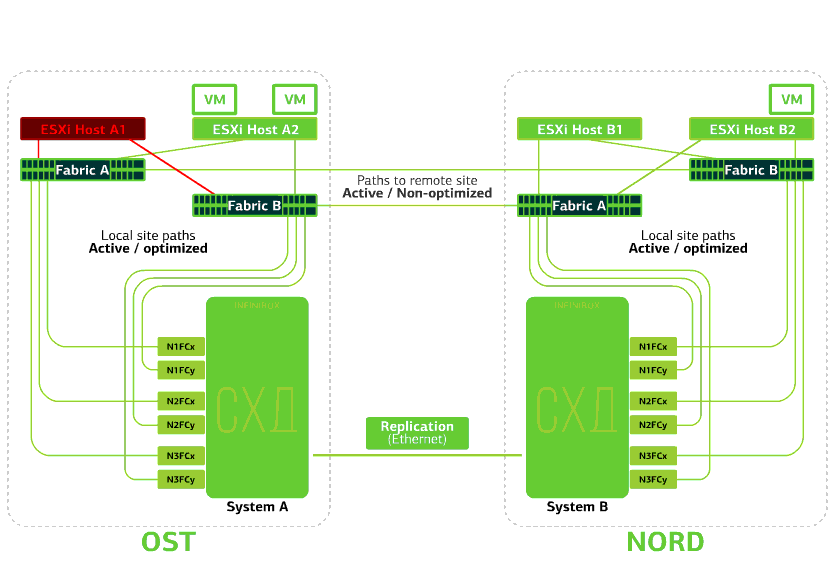 Refuse le stockage sur le même site. Disons que le système de stockage a refusé sur le site OST. Ensuite, les hôtes OST ESXi basculent pour fonctionner avec des répliques de stockage dans NORD. Après le retour du système de stockage défaillant sur le système, une réplication forcée aura lieu, les hôtes OST ESXi recommenceront à contacter le système de stockage local.Les machines virtuelles ont fonctionné tout ce temps.
Refuse le stockage sur le même site. Disons que le système de stockage a refusé sur le site OST. Ensuite, les hôtes OST ESXi basculent pour fonctionner avec des répliques de stockage dans NORD. Après le retour du système de stockage défaillant sur le système, une réplication forcée aura lieu, les hôtes OST ESXi recommenceront à contacter le système de stockage local.Les machines virtuelles ont fonctionné tout ce temps. Échoue l'un des sites.Dans ce cas, toutes les machines virtuelles redémarreront sur le site de sauvegarde via le mécanisme vSphere HA. Temps de redémarrage de la machine virtuelle - 140 secondes. Dans ce cas, tous les paramètres réseau de la machine virtuelle sont enregistrés et restent disponibles pour le client sur le réseau.Pour redémarrer les machines sur le site de sauvegarde sans problème, chaque site n'est qu'à moitié plein. La seconde moitié est la réserve au cas où toutes les machines virtuelles seraient déplacées du deuxième site endommagé.
Échoue l'un des sites.Dans ce cas, toutes les machines virtuelles redémarreront sur le site de sauvegarde via le mécanisme vSphere HA. Temps de redémarrage de la machine virtuelle - 140 secondes. Dans ce cas, tous les paramètres réseau de la machine virtuelle sont enregistrés et restent disponibles pour le client sur le réseau.Pour redémarrer les machines sur le site de sauvegarde sans problème, chaque site n'est qu'à moitié plein. La seconde moitié est la réserve au cas où toutes les machines virtuelles seraient déplacées du deuxième site endommagé.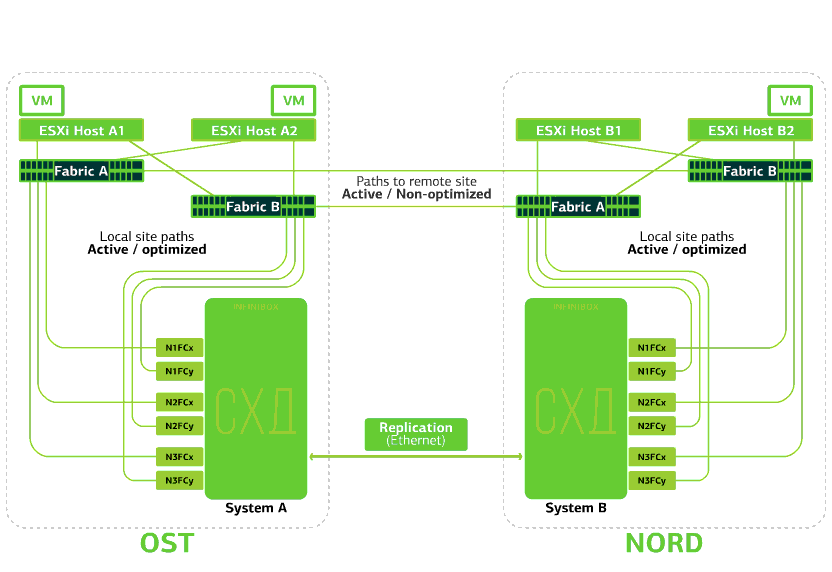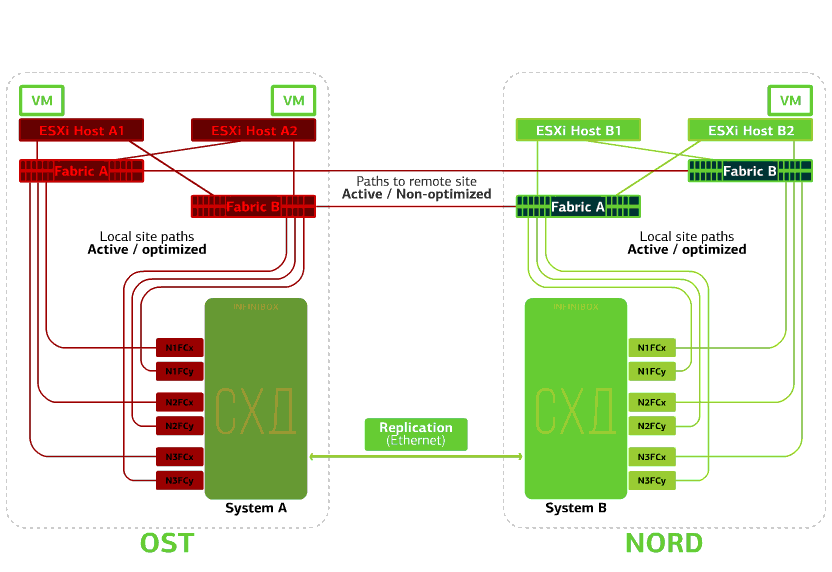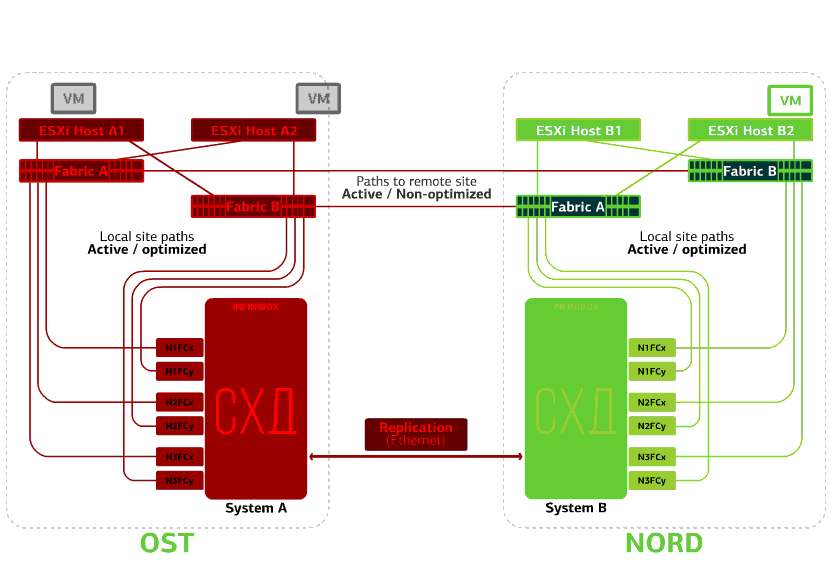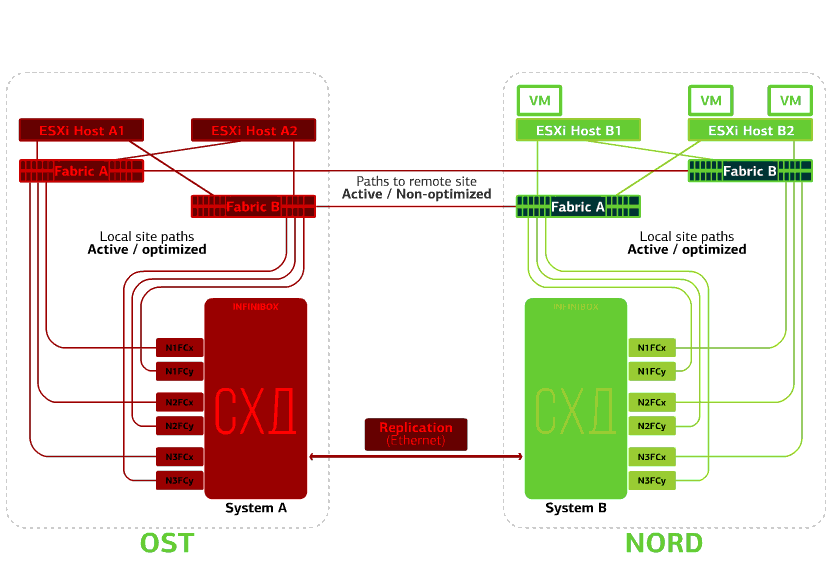 Un cloud à l'épreuve des catastrophes basé sur deux centres de données protège contre de telles pannes.Ce plaisir n'est pas bon marché, car, en plus des principales ressources, il faut une réserve sur le deuxième site. Par conséquent, ils placent les services essentiels à l'entreprise dans un tel cloud, dont le long temps d'indisponibilité entraîne des pertes financières et de réputation importantes, ou si des exigences de tolérance aux catastrophes sont imposées au système d'information par les régulateurs ou les règlements internes de l'entreprise.Sources:
Un cloud à l'épreuve des catastrophes basé sur deux centres de données protège contre de telles pannes.Ce plaisir n'est pas bon marché, car, en plus des principales ressources, il faut une réserve sur le deuxième site. Par conséquent, ils placent les services essentiels à l'entreprise dans un tel cloud, dont le long temps d'indisponibilité entraîne des pertes financières et de réputation importantes, ou si des exigences de tolérance aux catastrophes sont imposées au système d'information par les régulateurs ou les règlements internes de l'entreprise.Sources:- www.infinidat.com/sites/default/files/resource-pdfs/DS-INFBOX-190331-US_0.pdf
- support.infinidat.com/hc/en-us/articles/207057109-InfiniBox-best-practices-guides
Source: https://habr.com/ru/post/undefined/
All Articles