NiFi está ganando cada vez más popularidad y con cada nueva versión obtiene cada vez más herramientas para trabajar con datos. Sin embargo, puede ser necesario tener su propia herramienta para resolver un problema específico. Apache Nifi tiene más de 300 procesadores en su paquete base. Procesador Nifi Es el bloque de construcción principal para crear flujo de datos en el ecosistema NiFi. Los procesadores proporcionan una interfaz a través de la cual NiFi proporciona acceso al archivo de flujo, sus atributos y contenido. El propio procesador personalizado ahorrará energía, tiempo y atención del usuario, porque en lugar de muchos elementos simples del procesador, solo se mostrará uno en la interfaz y solo se ejecutará uno (bueno, o cuánto escribes). Al igual que los procesadores estándar, un procesador personalizado le permite realizar varias operaciones y procesar el contenido de un archivo de flujo. Hoy hablaremos sobre herramientas estándar para ampliar la funcionalidad.
Es el bloque de construcción principal para crear flujo de datos en el ecosistema NiFi. Los procesadores proporcionan una interfaz a través de la cual NiFi proporciona acceso al archivo de flujo, sus atributos y contenido. El propio procesador personalizado ahorrará energía, tiempo y atención del usuario, porque en lugar de muchos elementos simples del procesador, solo se mostrará uno en la interfaz y solo se ejecutará uno (bueno, o cuánto escribes). Al igual que los procesadores estándar, un procesador personalizado le permite realizar varias operaciones y procesar el contenido de un archivo de flujo. Hoy hablaremos sobre herramientas estándar para ampliar la funcionalidad.ExecuteScript
ExecuteScript es un procesador universal diseñado para implementar la lógica empresarial en un lenguaje de programación (Groovy, Jython, Javascript, JRuby). Este enfoque le permite obtener rápidamente la funcionalidad deseada. Para proporcionar acceso a los componentes de NiFi en un script, es posible utilizar las siguientes variables:Sesión : una variable de tipo org.apache.nifi.processor.ProcessSession. La variable le permite realizar operaciones con el archivo de flujo, como create (), putAttribute () y Transfer (), así como read () y write ().Contexto : org.apache.nifi.processor.ProcessContext. Se puede usar para obtener propiedades del procesador, relaciones, servicios de controlador y StateManager.REL_SUCCESS : Relación "éxito".REL_FAILURE : Relación de fallaPropiedades dinámicas : las propiedades dinámicas definidas en ExecuteScript se pasan al motor de script como variables, establecidas como PropertyValue. Esto le permite obtener el valor de la propiedad, convertir el valor al tipo de datos apropiado, por ejemplo, lógico, etc.Para usar, simplemente seleccione Script Enginey especifique la ubicación del archivo Script Filecon nuestro script o el script en sí Script Body.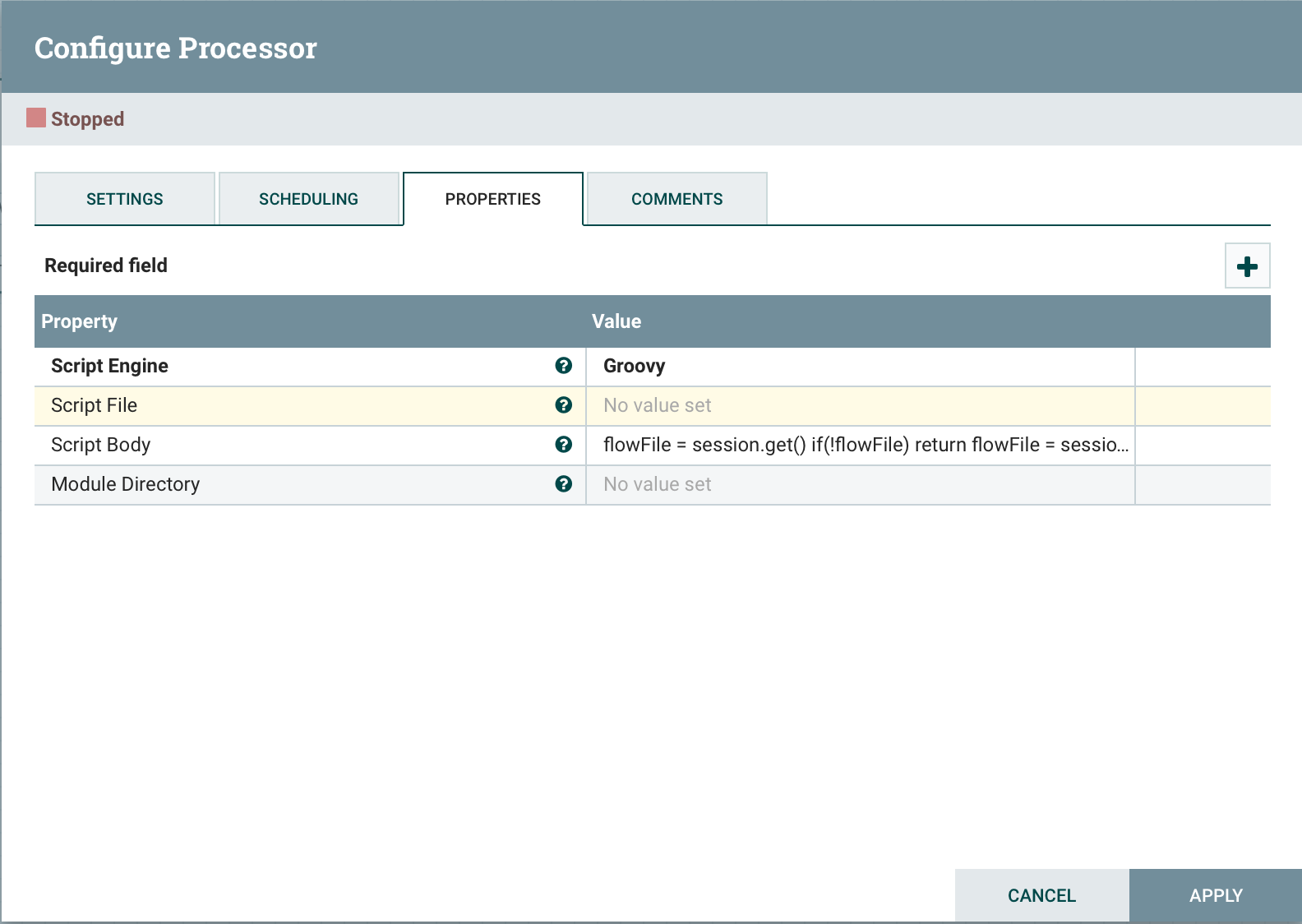 Veamos un par de ejemplos:obtenga un archivo continuo de la cola
Veamos un par de ejemplos:obtenga un archivo continuo de la colaflowFile = session.get()
if(!flowFile) return
Genere un nuevo FlowFileflowFile = session.create()
// Additional processing here
Agregar atributo a FlowFileflowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
Extraer y procesar todos los atributos.flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
Registradorlog.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
Puede usar funciones avanzadas en ExecuteScript, más sobre esto se puede encontrar en el artículo ExecuteScript Cookbook.ExecuteGroovyScript
ExecuteGroovyScript tiene la misma funcionalidad que ExecuteScript, pero en lugar de un zoológico de lenguajes válidos, puede usar solo uno: maravilloso. La principal ventaja de este procesador es su uso más conveniente de los servicios de servicio. Además del conjunto estándar de variables Sesión, Contexto, etc. Puede definir propiedades dinámicas con el prefijo CTL y SQL. A partir de la versión 1.11, apareció el soporte para RecordReader y Record Writer. Todas las propiedades son HashMap, que utiliza el "Nombre del servicio" como clave, y el valor es un objeto específico según la propiedad:RecordWriter HashMap<String,RecordSetWriterFactory>
RecordReader HashMap<String,RecordReaderFactory>
SQL HashMap<String,groovy.sql.Sql>
CTL HashMap<String,ControllerService>
Esta información ya hace la vida más fácil. podemos buscar en las fuentes o encontrar documentación para una clase en particular.Trabajar con la base de datosSi definimos la propiedad SQL.DB y enlazamos DBCPService, accederemos a la propiedad desde el código. SQL.DB.rows('select * from table') El procesador acepta automáticamente una conexión del servicio dbcp antes de la ejecución y procesa la transacción. Las transacciones de la base de datos se revierten automáticamente cuando se produce un error y se confirman si tienen éxito. En ExecuteGroovyScript, puede interceptar eventos de inicio y detención mediante la implementación de los métodos estáticos apropiados.
El procesador acepta automáticamente una conexión del servicio dbcp antes de la ejecución y procesa la transacción. Las transacciones de la base de datos se revierten automáticamente cuando se produce un error y se confirman si tienen éxito. En ExecuteGroovyScript, puede interceptar eventos de inicio y detención mediante la implementación de los métodos estáticos apropiados.import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS << flowFile
InvokeScriptedProcessor
Otro procesador interesante. Para usarlo, debe declarar una clase que implemente la interfaz de implementos y definir una variable de procesador. Puede definir cualquier PropertyDescriptor o Relación, también acceder al ComponentLog padre y definir los métodos void onScheduled (contexto ProcessContext) y void onStopped (contexto ProcessContext). Se llamará a estos métodos cuando ocurra un evento de inicio programado en NiFi (onScheduled) y cuando se detenga (onScheduled).class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
La lógica debe implementarse en el método void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) @Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
No es necesario describir todos los métodos declarados en la interfaz, así que vamos a ver una clase abstracta en la que declaramos el siguiente método:abstract void executeScript(ProcessContext context, ProcessSession session)
El método que llamaremosvoid onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set<Relationship> relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Ahora declaramos una clase sucesora BaseGroovyProcessory describimos nuestro executeScript, también agregamos RELSUCCESS y RELFAILURE.import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
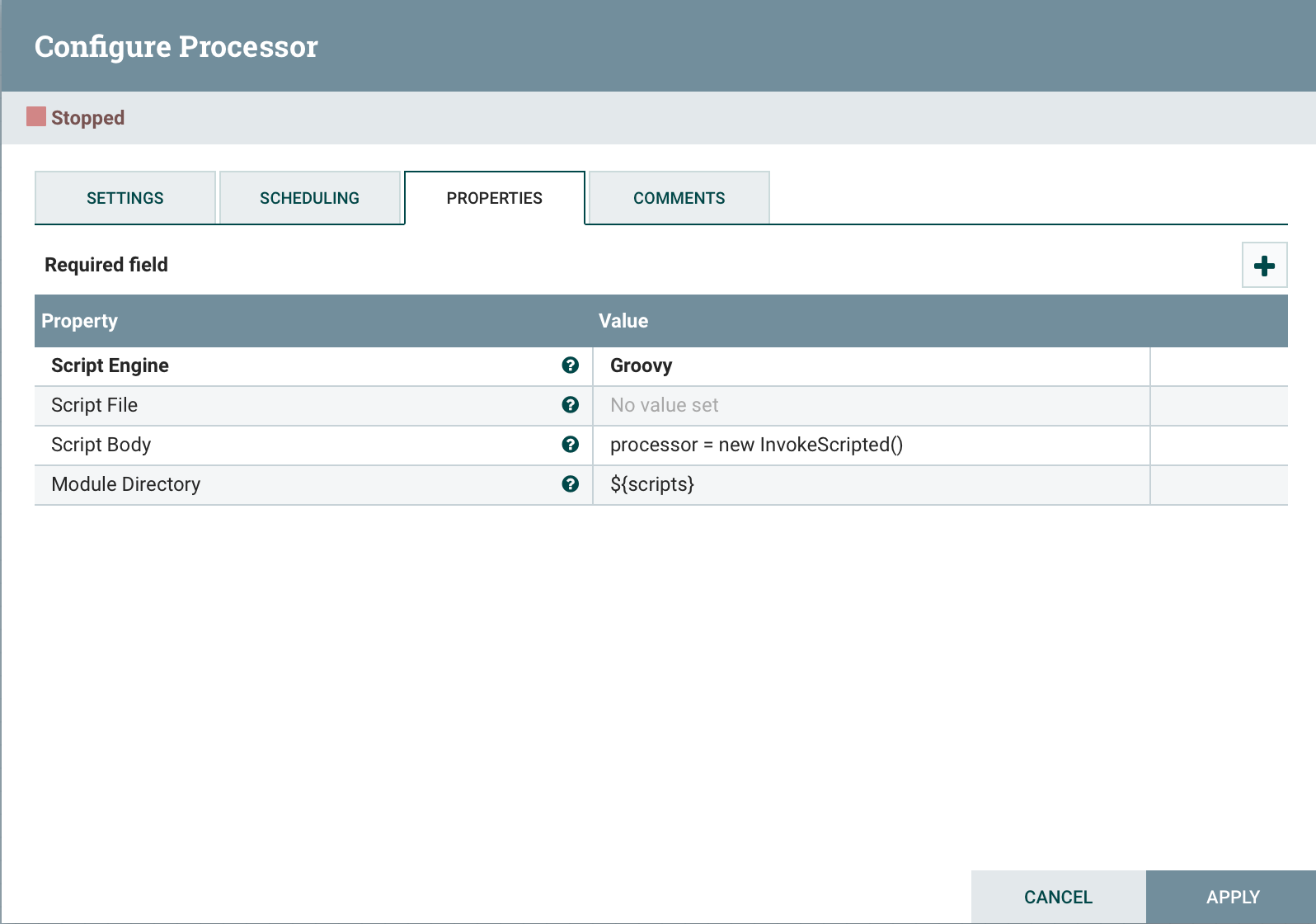 Agregue al final del código.
Agregue al final del código. processor = new InvokeScripted()Este enfoque es similar a la creación de un procesador personalizado.Conclusión
Crear un procesador personalizado no es lo más fácil: por primera vez tienes que trabajar duro para resolverlo, pero los beneficios de esta acción son innegables.Publicación preparada por el equipo de gestión de datos de Rostelecom