¡Hola!En este artículo, le diré cómo hacer una página en Atlassian Confluence con una tabla, cuyos datos provendrán de una solicitud REST.Crearemos una página en Confluence con una tabla que contendrá datos del proyecto en Jira. Obtendremos estos datos de Jira utilizando el método del proyecto de la API estándar REST de Jira.Puedes ver el video de este artículo aquí .Instalar Power Scripts para Confluence
Realizaremos una llamada a la API REST de Jira utilizando el complemento Power Scripts for Confluence . Este es un complemento gratuito, por lo que esta solución no le costará nada.Bueno, lo primero que debemos hacer es instalar el complemento Power Scripts for Confluence en nuestra Confluence. Las instrucciones detalladas sobre cómo hacer esto se pueden encontrar aquí .Escribe un guion
Ahora vaya al elemento del menú de ajustes -> Administrar aplicaciones -> SIL Manager. Cree el archivo getProjects.sil con el siguiente código:
Cree el archivo getProjects.sil con el siguiente código:struct Project {
string key;
string name;
string projectTypeKey;
}
HttpRequest request;
HttpHeader authHeader = httpBasicAuthHeader("admin", "admin");
request.headers += authHeader;
Project [] projects = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
runnerLog(projects);
return projects;
Cambie la dirección de host.docker.internal : 8080 / a la dirección de su instancia de Jira.Ejecute el script para verificar que los datos estén seleccionados de Jira: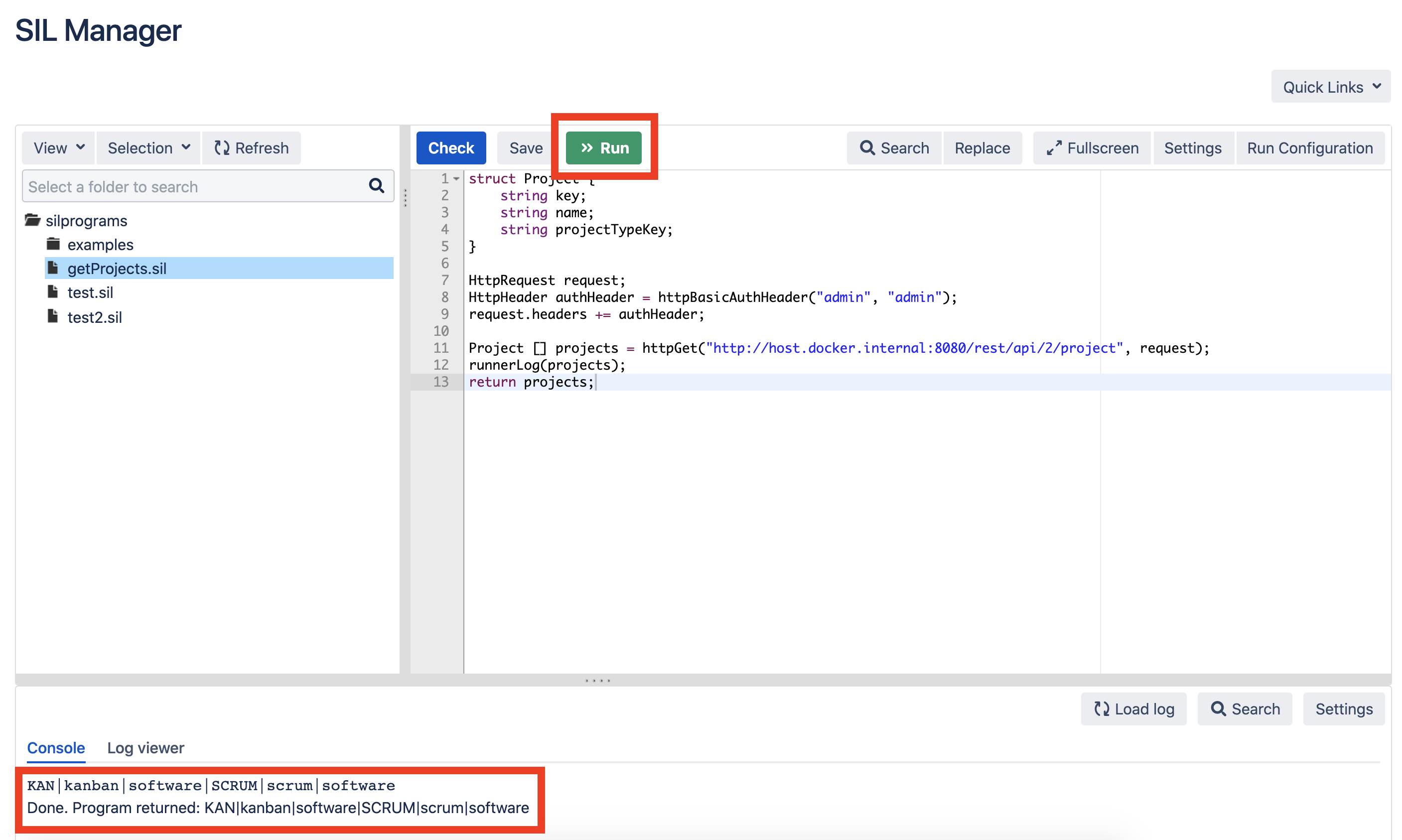
Crea una página en Confluence
Ahora cree una página en Confluence con la macro de la tabla SIL . En el campo de scripts, ingrese el nombre de nuestro script getProjects.sil: publique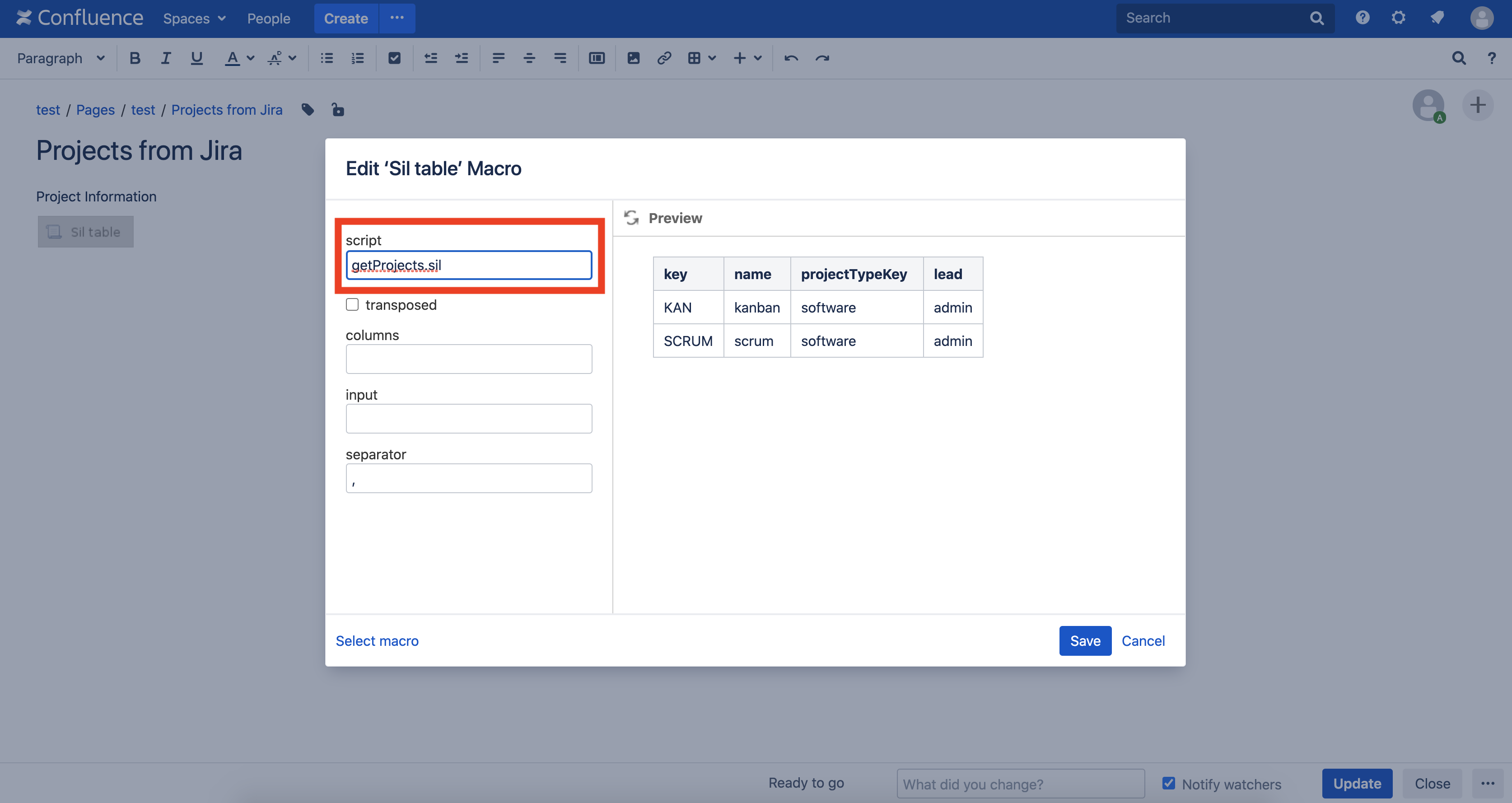 la página y verá este resultado:
la página y verá este resultado: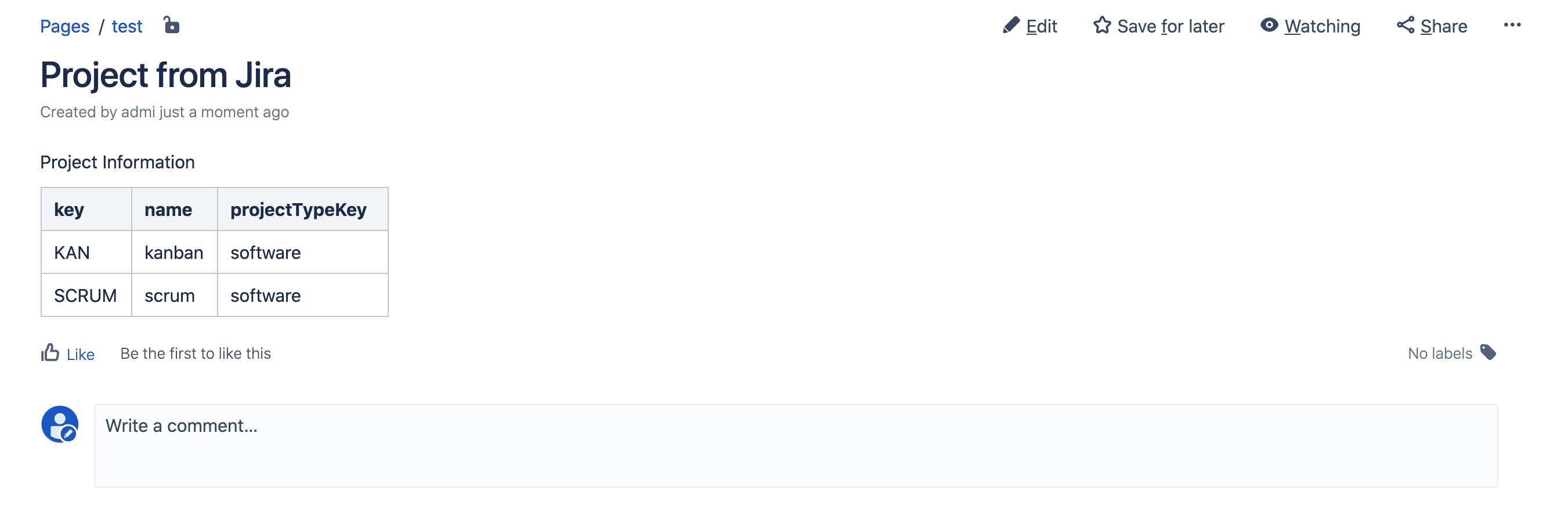
Vamos a complicar la tarea.
Agregue la siguiente funcionalidad a la tabla:- mostrar información sobre el gerente del proyecto
- dar a los campos nombres más comprensibles y preferiblemente en ruso
Primero, realice cambios en el script getProjects.sil.Al mismo tiempo, refactorizamos un poco.Esto es lo que hará nuestro script:- obtener datos del proyecto de Jira a través de una llamada a la API REST de Jira
- Convertimos los datos recibidos del proyecto en una vista tabular
- imprimir el resultado
Así es como se ve en el código:Project [] projects = getProjectData();
TableRow [] tableRows = convertProjectDataToTableData(projects);
return tableRows;
Ahora especifiquemos cómo obtenemos los datos del proyecto:- crear una solicitud
- crear un encabezado en la solicitud con información sobre el usuario que recibe datos de Jira
- Agregue el parámetro expandir a nuestra consulta. Necesitamos seleccionar datos sobre el gerente del proyecto, pero en la respuesta predeterminada no hay tales datos. Por lo tanto, debemos decirle a Jira que queremos ver los datos sobre el gerente del proyecto en la respuesta. Para esto, se utiliza el parámetro de expansión.
- ejecutar la solicitud
- devolver datos
Pero las palabras se convirtieron en código:function getProjectData() {
HttpRequest request;
HttpHeader authHeader = httpBasicAuthHeader("admin", "admin");
request.headers += authHeader;
HttpQueryParam param = httpCreateParameter("expand", "description,lead,url,projectKeys");
request.parameters += param;
Project[] projects = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
return projects;
}
Ahora definamos estructuras de datos para nuestros proyectos.Aquí está la respuesta que el método del proyecto devuelve de la API REST de Jira (eliminé datos innecesarios para hacer la respuesta más corta y, por lo tanto, más legible):[
{
"key":"KAN",
"lead":{
"name":"admin",
"displayName":"Alexey Matveev",
},
"name":"kanban",
"projectTypeKey":"software"
},
{
"key":"SCRUM",
"description":"",
"lead":{
"name":"admin",
"displayName":"Alexey Matveev",
},
"name":"scrum",
"projectTypeKey":"software"
}
]
Como podemos ver, los valores para los campos clave, nombre y projectTypeKey se definen en el primer nivel de nuestro json. Pero para el campo principal, en lugar del valor, vemos json. Y este json ya contiene los valores de los campos de nombre y displayName. Por lo tanto, primero creamos una estructura para json en el campo lead (Lead):struct Lead {
string name;
string displayName;
}
Ahora estamos listos para hacer la estructura para el primer nivel de nuestro json (Proyecto):struct Project {
string key;
string name;
string projectTypeKey;
Lead lead;
}
Pero el problema es que la macro de la tabla SIL solo puede funcionar con json con un nivel de anidamiento, por lo que debemos convertir nuestra estructura con dos niveles de anidamiento (Proyecto) en una estructura con un nivel de anidamiento (estructura plana). Pero primero, cree una estructura plana (TableRow):struct TableRow {
string key;
string name;
string projectTypeKey;
string lead;
string leadDisplayName;
}
Y ahora escribiremos una función para convertir los datos en la estructura del Proyecto a la estructura TableRow:function convertProjectDataToTableData(Project [] projectData) {
TableRow [] tableRows;
for (Project project in projectData) {
TableRow tableRow;
tableRow.key = project.key;
tableRow.name = project.name;
tableRow.projectTypeKey = project.projectTypeKey;
tableRow.lead = project.lead.name;
tableRow.leadDisplayName = project.lead.displayName;
tableRows = arrayAddElement(tableRows, tableRow);
}
return tableRows;
}
Todas. ¡El guión está listo!Aquí está el código getProjects.sil final:struct Lead {
string name;
string displayName;
}
struct Project {
string key;
string name;
string projectTypeKey;
Lead lead;
}
struct TableRow {
string key;
string name;
string projectTypeKey;
string lead;
string leadDisplayName;
}
function getProjectData() {
HttpRequest request;
HttpHeader authHeader = httpBasicAuthHeader("admin", "admin");
request.headers += authHeader;
HttpQueryParam param = httpCreateParameter("expand", "description,lead,url,projectKeys");
request.parameters += param;
string pp = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
runnerLog(pp);
Project[] projects = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
return projects;
}
function convertProjectDataToTableData(Project [] projectData) {
TableRow [] tableRows;
for (Project project in projectData) {
TableRow tableRow;
tableRow.key = project.key;
tableRow.name = project.name;
tableRow.projectTypeKey = project.projectTypeKey;
tableRow.lead = project.lead.name;
tableRow.leadDisplayName = project.lead.displayName;
tableRows = arrayAddElement(tableRows, tableRow);
}
return tableRows;
}Project [] projects = getProjectData();
TableRow [] tableRows = convertProjectDataToTableData(projects);
return tableRows;
Ahora actualizamos la página en Confluence y vemos que nuestros datos sobre el administrador del proyecto se abrieron: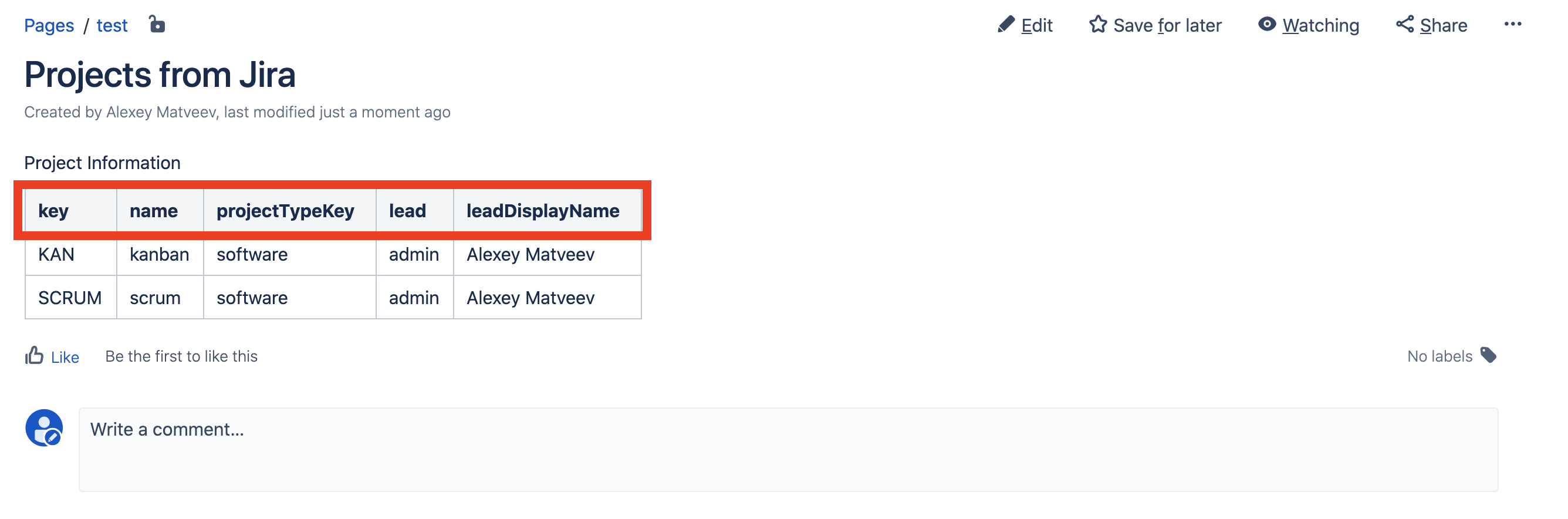 Pero los nombres de las columnas son algo oscuros. Demos más nombres bonitos.Editamos la página, editamos la macro de la tabla SIL e ingresamos “Clave del proyecto, Nombre del proyecto, Tipo de proyecto, Administrador del proyecto, Nombre del Administrador del proyecto” en el campo de columnas:
Pero los nombres de las columnas son algo oscuros. Demos más nombres bonitos.Editamos la página, editamos la macro de la tabla SIL e ingresamos “Clave del proyecto, Nombre del proyecto, Tipo de proyecto, Administrador del proyecto, Nombre del Administrador del proyecto” en el campo de columnas: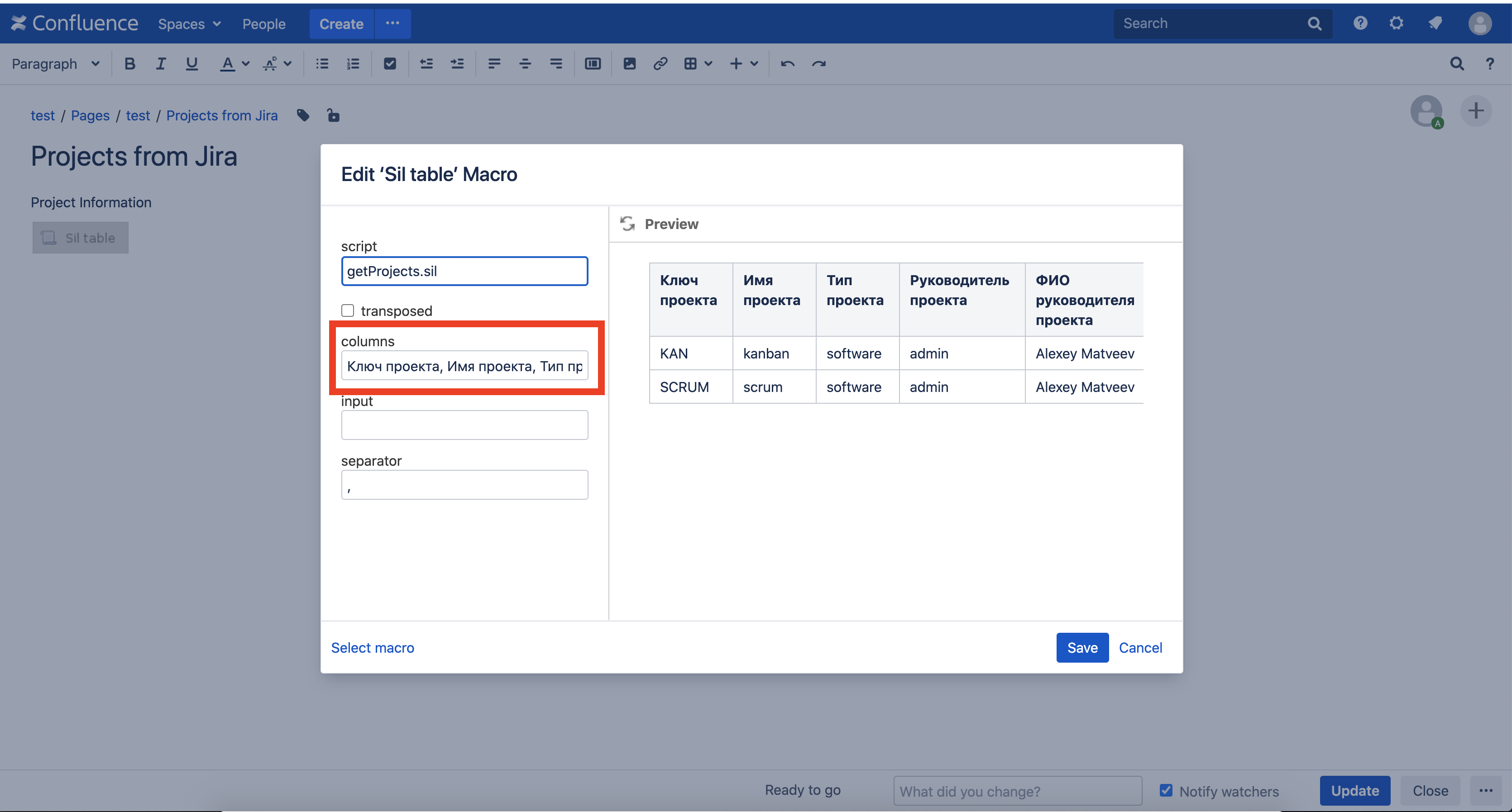 Guarde la página y aquí está el resultado: ¡
Guarde la página y aquí está el resultado: ¡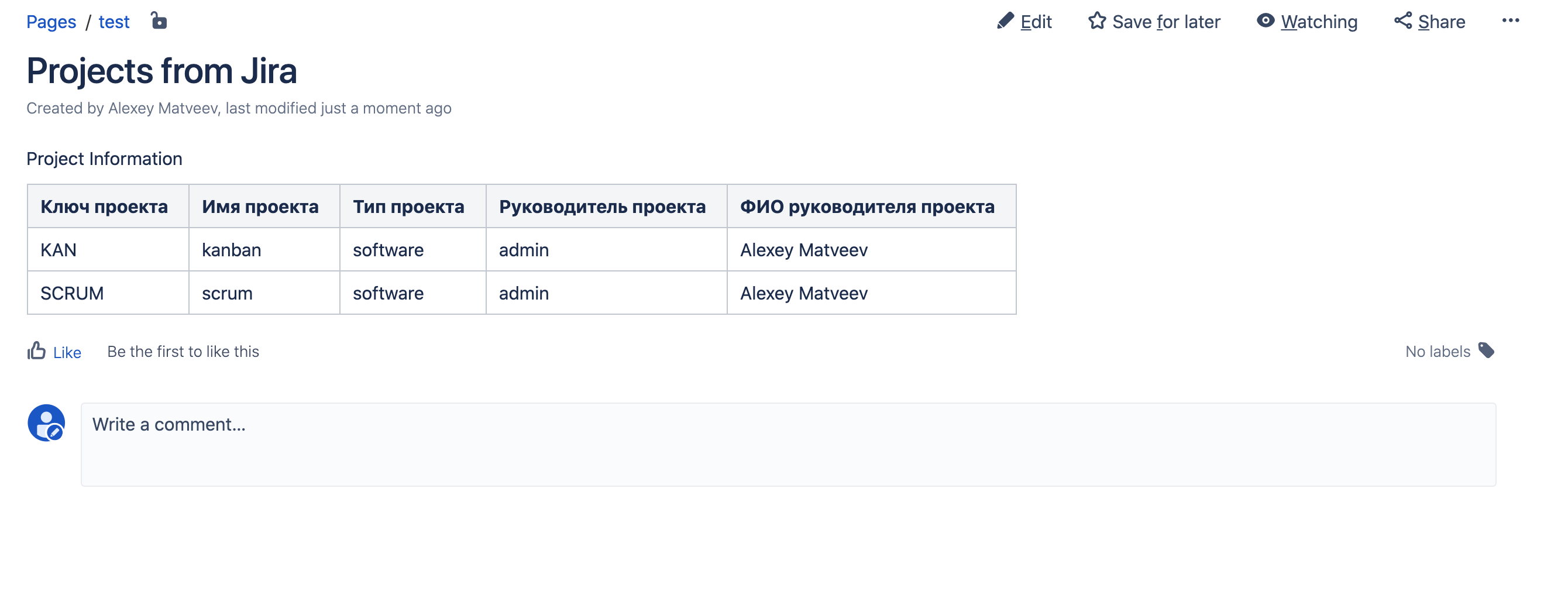 Todo resultó!
Todo resultó!