Hola de nuevo. Hoy continuamos con la serie de traducciones en previsión del inicio del curso básico "Matemáticas para la ciencia de datos" .
En un artículo reciente , hablamos sobre cómo crear un detector de anomalías en Power BI integrando PyCaret en él, y ayudar a los analistas y analistas de datos a agregar el aprendizaje automático a los informes y paneles sin demasiado esfuerzo.En este artículo, veremos cómo realizar análisis de clúster utilizando PyCaret y Power BI. Si no ha escuchado nada sobre PyCaret antes, puede comenzar a familiarizarse con él aquí .Lo que discutiremos en la guía de hoy:- ¿Qué es la agrupación? Tipos de agrupamiento.
- Aprender sin un maestro e implementar un modelo de clustering en Power BI.
- Análisis de los resultados y visualización de información en el tablero.
- ¿Cómo implementar un modelo de clustering en producción en Power BI?
Antes de que comencemos ...
Si ya ha usado Python anteriormente, lo más probable es que ya tenga Anaconda en su computadora. Si no, puede descargar la distribución Anaconda desde Python 3.7 o superior desde aquí .Configuración del entorno
Antes de comenzar a utilizar las funciones de aprendizaje automático de PyCaret en Power BI, debe crear un entorno virtual e instalarlo en él pycaret. Para hacer esto, debemos realizar tres pasos:Paso 1: crear un entorno virtualAbra el símbolo del sistema Anaconda e ingrese lo siguiente:conda create --name myenv python=3.7
Paso 2: instalar PyCaretEjecute el siguiente comando en el símbolo del sistema de Anaconda:pip install pycaret
La instalación puede demorar entre 15 y 20 minutos. Si encuentra algún problema durante la instalación, puede familiarizarse con su solución en nuestra página en GitHub .Paso 3: indique en Power BI dónde está instalado Python.El entorno virtual creado debe estar asociado con Power BI. Puede hacerlo utilizando la Configuración global en Power BI Desktop (Archivo -> Opciones -> Global -> Script de Python). El entorno de Anaconda se coloca en el directorio de forma predeterminada:C:\Users\username\AppData\Local\Continuum\anaconda3\envs\myenv
¿Qué es la agrupación?
La agrupación es un método para dividir datos en grupos de acuerdo con características similares. Dichos grupos pueden ser útiles para estudiar datos, identificar patrones y analizar subconjuntos de datos. La agrupación de datos ayuda a identificar las estructuras de datos subyacentes, lo cual es útil en muchas industrias. Estos son algunos usos comunes para la agrupación en empresas:- Marketing segmentación de clientes.
- Análisis del comportamiento del consumidor para promociones y descuentos.
- Identificación de geoclusters durante un brote, como, por ejemplo, COVID-19.
Tipos de agrupamiento
Dada la naturaleza subjetiva de las tareas de agrupamiento, existen varios algoritmos que son más adecuados para resolver ciertos tipos de tareas. Cada algoritmo tiene sus propias características y justificación matemática, que subyace a la distribución de los clústeres.En el tutorial de hoy, estamos hablando del análisis de conglomerados en Power BI usando una biblioteca de Python llamada PyCaret y no profundizaremos en las matemáticas. Hoy usaremos el método k-means, uno de los métodos de enseñanza más simples y populares sin un maestro. Puede encontrar más información sobre el método k-means aquí .
Hoy usaremos el método k-means, uno de los métodos de enseñanza más simples y populares sin un maestro. Puede encontrar más información sobre el método k-means aquí .Contexto empresarial
En esta guía, utilizaremos un conjunto de datos prefabricado de la base de datos de Gastos de Salud Global de la Organización Mundial de la Salud. Contiene los gastos en salud como porcentaje del PIB nacional de más de 200 países entre 2000 y 2017.Nuestra tarea es encontrar patrones y grupos en estos datos utilizando el método k-means.Los datos se pueden encontrar aquí .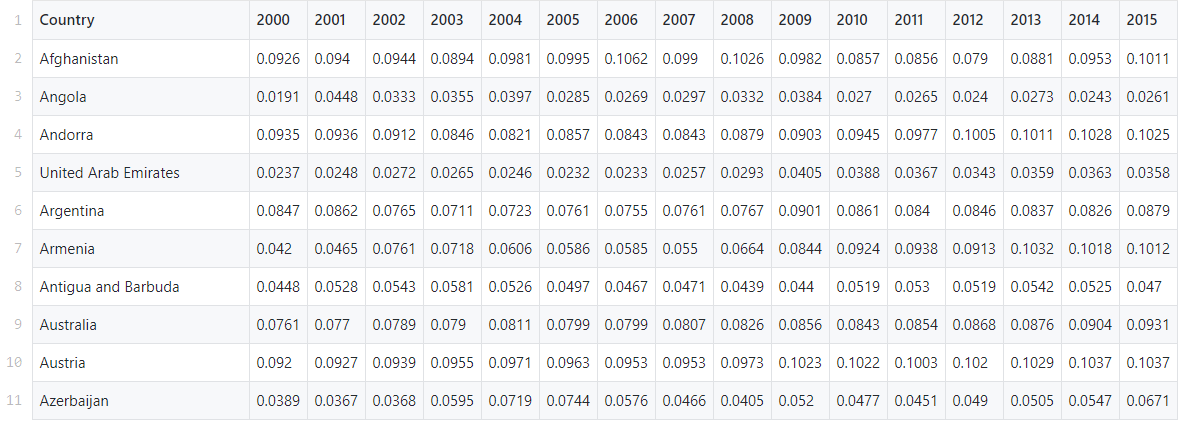
Vamos a empezar
Ahora que ha configurado el entorno Anaconda, instalado PyCaret, comprende los conceptos básicos del análisis de clúster y el contexto empresarial, es hora de ponerse manos a la obra.1. Adquisición de datos
El primer paso es importar el conjunto de datos en Power BI Desktop. Puede descargar datos utilizando el conector web. (Power BI Desktop → Obtener datos → De la web ). Enlace al archivo csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .
Enlace al archivo csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .2. Entrenamiento modelo
Para aprender el modelo de agrupación en Power BI, necesitamos ejecutar un script de Python en el Power Query Editor ( Power Query Editor → Transform → Run python script ). Use el siguiente código como script:from pycaret.clustering import *
dataset = get_clusters(dataset, num_clusters=5, ignore_features=['Country'])
 Ignoramos la columna "País" del conjunto utilizando el parámetro
Ignoramos la columna "País" del conjunto utilizando el parámetro ignore_features. Hay muchas razones por las que es posible que deba excluir ciertas columnas para entrenar mejor el modelo de aprendizaje automático.PyCaret le permite ocultar columnas innecesarias en lugar de eliminarlas, ya que puede necesitarlas en el futuro para un análisis posterior. Por ejemplo, en este momento no queríamos usar "País" para la capacitación y pasamos esta columna a ignore_features.Hay 8 algoritmos de aprendizaje automático listos para usar en PyCaret. Por defecto, PyCaret entrena el modelo de agrupación de k-means en cuatro agrupaciones. Pero los valores predeterminados se pueden cambiar fácilmente:
Por defecto, PyCaret entrena el modelo de agrupación de k-means en cuatro agrupaciones. Pero los valores predeterminados se pueden cambiar fácilmente:- Para cambiar el tipo de modelo, use el parámetro modelo en
get_clusters(). - Para cambiar el número de grupos, utilice la opción
num_clusters.
Por ejemplo, así es como puede hacer k-means clustering en 6 clusters.from pycaret.clustering import *
dataset = get_clusters(dataset, model='kmodes', num_clusters=6, ignore_features=['Country'])
Conclusión:
 se agrega otra columna con una etiqueta de clúster al conjunto de datos original. Luego, todos los valores de la columna del año se utilizan para normalizar los datos y visualizarlos más en Power BI.Así es como se verá el resultado final en Power BI.
se agrega otra columna con una etiqueta de clúster al conjunto de datos original. Luego, todos los valores de la columna del año se utilizan para normalizar los datos y visualizarlos más en Power BI.Así es como se verá el resultado final en Power BI.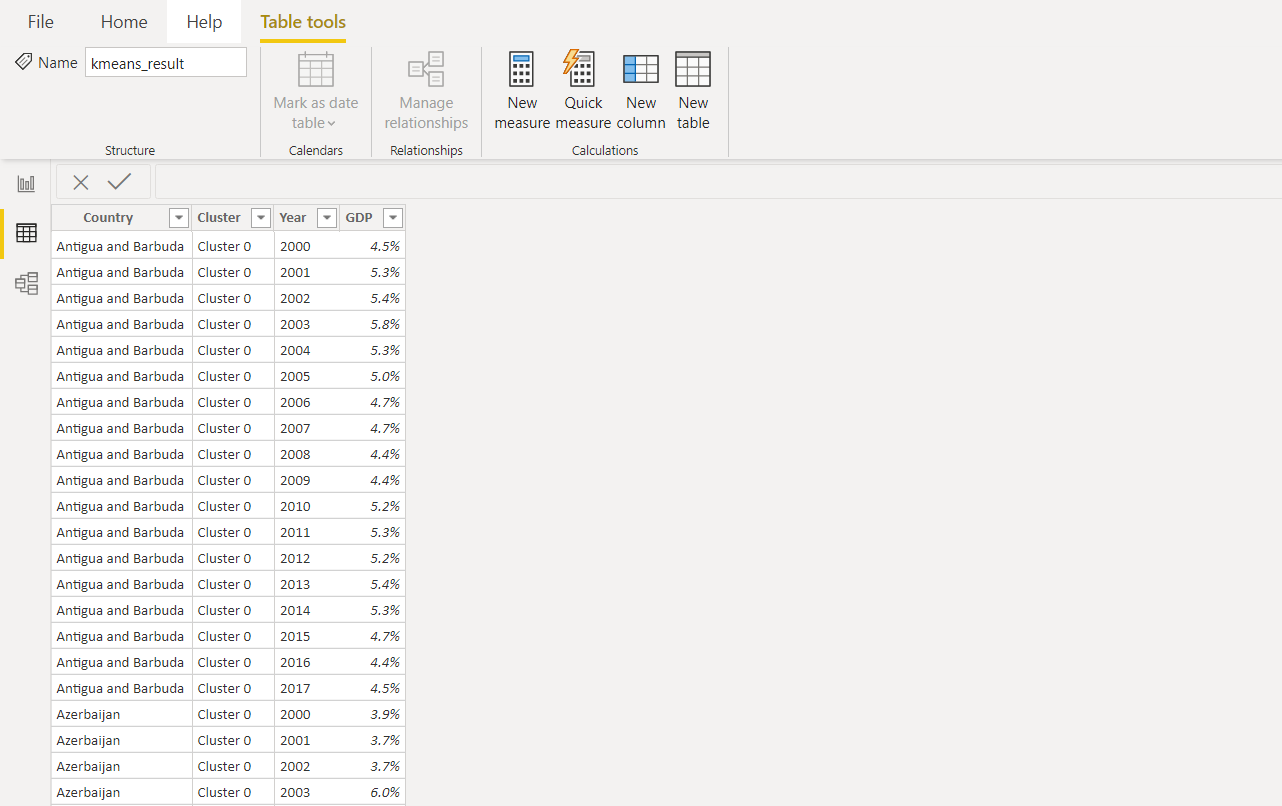
3. Tablero
Cuando haya adquirido etiquetas de clúster en Power BI, puede visualizarlas en el panel de control de Power BI para análisis: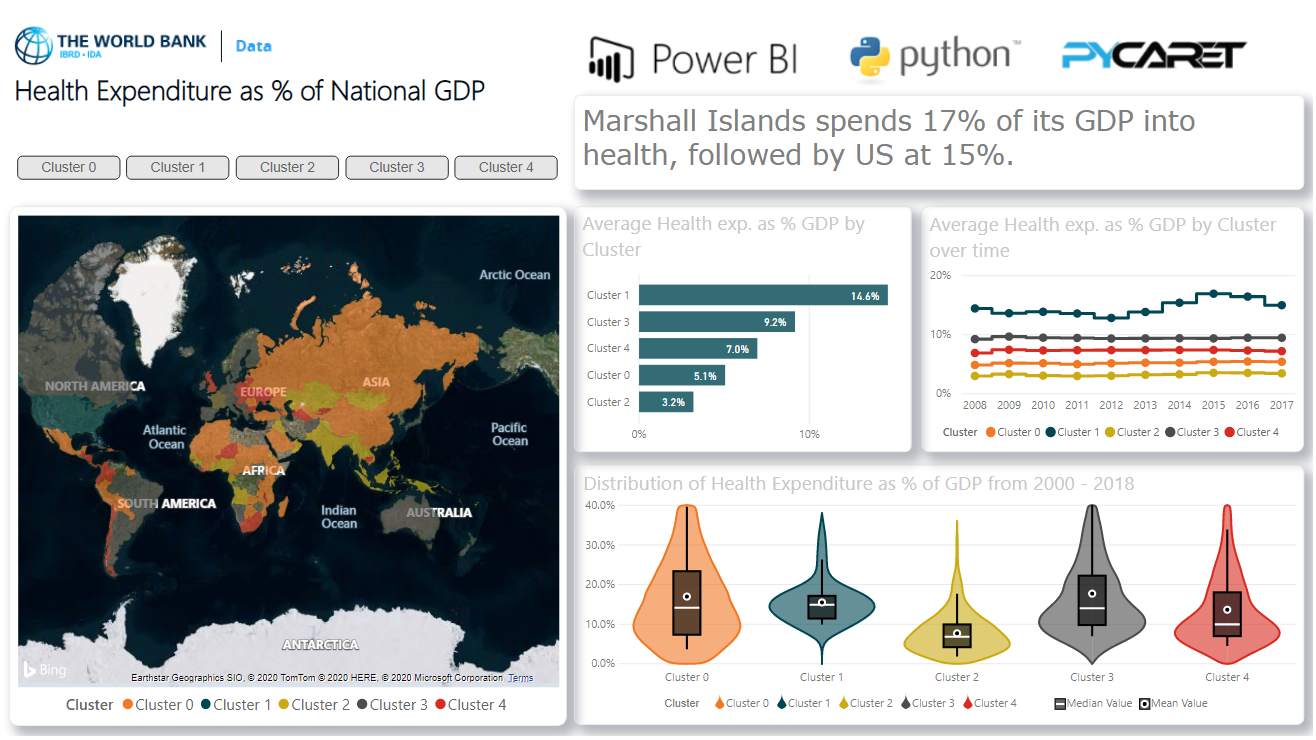
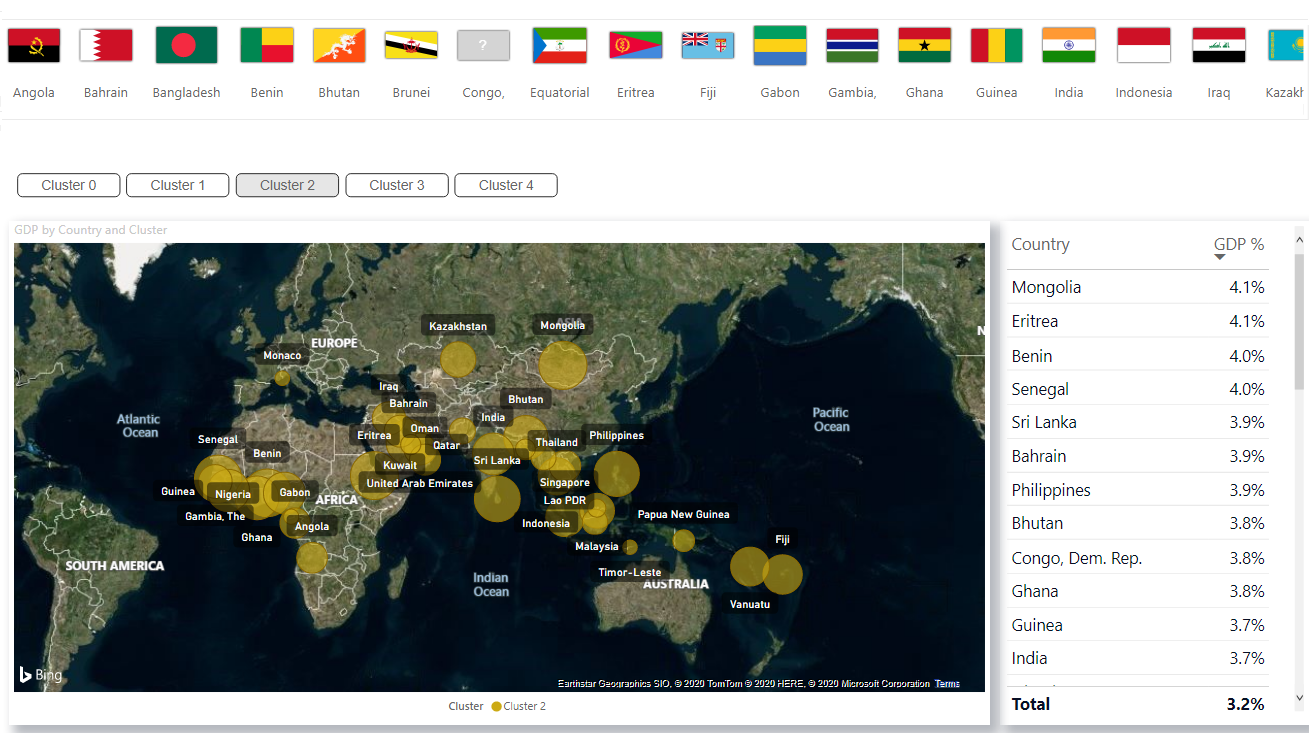 puede descargar el archivo PBIX y el conjunto de datos de GitHub .
puede descargar el archivo PBIX y el conjunto de datos de GitHub .Implementación de agrupamiento
Arriba, demostramos la implementación de agrupamiento más simple en Power BI. Observo que este método entrena el modelo de agrupamiento cada vez que se actualiza un conjunto de datos en Power BI. Esto puede ser un problema por las siguientes razones:- Cuando el modelo se vuelve a entrenar con los nuevos datos, las etiquetas del clúster pueden cambiar (es decir, si antes se asignaron algunos puntos de datos al primer grupo, luego, cuando se vuelven a entrenar, se pueden asignar al segundo grupo);
- No querrás pasar varias horas cada vez que vuelvas a entrenar el modelo.
Una forma más efectiva de implementar la agrupación en clúster en Power BI en lugar de volver a aprender una y otra vez es utilizar un modelo previamente capacitado para crear etiquetas de agrupación.Entrenamiento modelo avanzado
Puede usar cualquier entorno de desarrollo integrado (IDE) o Notebook para entrenar el modelo. En este ejemplo, hemos entrenado el modelo de agrupación en Visual Studio Code.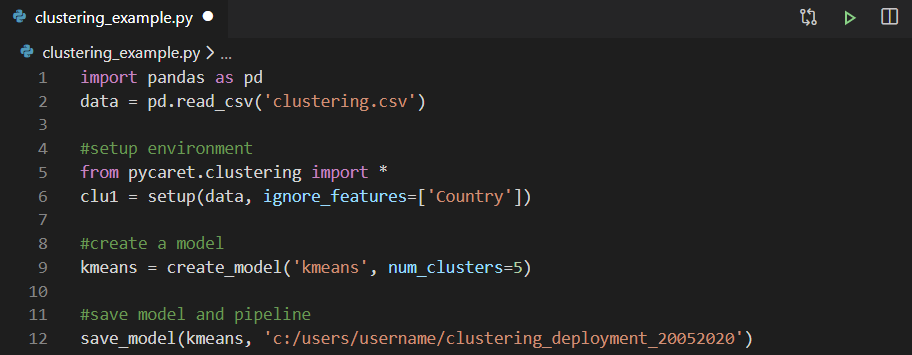 Luego, el modelo entrenado se guarda como un archivo pickle y se importa a Power Query para generar etiquetas de clúster.
Luego, el modelo entrenado se guarda como un archivo pickle y se importa a Power Query para generar etiquetas de clúster. Si desea obtener más información sobre la implementación del análisis de clúster en el cuaderno Jupyter con PyCaret, vea este video de dos minutos.
Si desea obtener más información sobre la implementación del análisis de clúster en el cuaderno Jupyter con PyCaret, vea este video de dos minutos.Usando el modelo pre-entrenado
Ejecute el siguiente código para generar etiquetas a partir del modelo previamente entrenado:from pycaret.clustering import *
dataset = predict_model('c:/.../clustering_deployment_20052020, data = dataset)
El resultado será el mismo que observamos anteriormente. La única diferencia es que cuando se usa el modelo previamente entrenado, las etiquetas se generarán en función del nuevo conjunto de datos que usa el modelo anterior, y no en el modelo que se ha vuelto a entrenar.Trabajar con el servicio Power BI
Después de cargar el archivo .pbix en el servicio Power BI, deberá seguir algunos pasos más para garantizar una integración fluida de la canalización de aprendizaje automático en su canalización de datos. Los pasos serán los siguientes:- Active la actualización programada del conjunto de datos: esto le permitirá programar el libro de trabajo con su conjunto de datos para que se actualice utilizando un script de Python; consulte la sección Configuración de actualización programada , que también contiene información sobre Personal Gateway.
- Instalar Puerta de enlace personal: necesitará una Puerta de enlace personal, que debe instalarse en el mismo directorio donde está instalado Python. El servicio Power BI debe tener acceso al entorno Python. Aquí puede obtener más información sobre cómo instalar y configurar Personal Gateway.
Si desea obtener más información sobre el análisis de conglomerados, puede familiarizarse con nuestra guía en este cuaderno .
Súbete al curso.