Nota perev. : Aunque esta revisión no pretende ser el estado de una comparación técnica cuidadosamente desarrollada de soluciones existentes para el almacenamiento permanente de datos en Kubernetes, puede ser un buen punto de partida para los administradores que son relevantes para este problema. Se prestó la mayor atención a la solución Piraeus, cuya familiaridad beneficiará no solo a los amantes de Linstor, sino también a aquellos que no han oído hablar de estos proyectos. Esta es una descripción no científica de las soluciones de almacenamiento para Kubernetes. Declaración del problema: requiere la capacidad de crear un volumen persistente en los discos del nodo, cuyos datos se guardarán en caso de daño o reinicio del nodo.La motivación para esta comparación es la necesidad de migrar la flota de servidores de la compañía de múltiples servidores dedicados al núcleo de Kubernetes.Mi empresa es una startup brasileña Escavador con enormes necesidades informáticas (principalmente CPU) y un presupuesto muy limitado. Desarrollamos soluciones de PNL para estructurar datos legales.
Esta es una descripción no científica de las soluciones de almacenamiento para Kubernetes. Declaración del problema: requiere la capacidad de crear un volumen persistente en los discos del nodo, cuyos datos se guardarán en caso de daño o reinicio del nodo.La motivación para esta comparación es la necesidad de migrar la flota de servidores de la compañía de múltiples servidores dedicados al núcleo de Kubernetes.Mi empresa es una startup brasileña Escavador con enormes necesidades informáticas (principalmente CPU) y un presupuesto muy limitado. Desarrollamos soluciones de PNL para estructurar datos legales. Debido a la crisis con COVID-19, el real brasileño cayó a un mínimo histórico frente al dólar estadounidense.Nuestra moneda nacional está realmente muy subestimada, por lo que el salario promedio de un desarrollador senior es de solo 2000 USD por mes. Por lo tanto, no podemos permitirnos el lujo de gastar cantidades significativas en servicios en la nube. La última vez que hice los cálculos, [gracias a usar mis servidores] ahorramos un 75% en comparación con lo que tendría que pagar por AWS. En otras palabras, se puede contratar a otro desarrollador por el dinero ahorrado. Creo que este es un uso mucho más racional de los fondos.Inspirado por una serie de publicaciones de Vito Botta, decidí crear un clúster K8 usando Rancher (y hasta ahora tan bueno ...). Vito también realizó un excelente análisis de varias soluciones de almacenamiento. El claro ganador fue Linstor (incluso lo destacó enliga especial ). Spoiler: estoy de acuerdo con él.Hace tiempo que sigo el tráfico alrededor de Kubernetes, pero recientemente decidí participar en él. Esto se debe principalmente al hecho de que el proveedor tiene una nueva línea de procesadores Ryzen. Y luego me sorprendió mucho ver que muchas soluciones aún están en desarrollo o en estado inmaduro (especialmente para clústeres de metal desnudo: virtualización VM, MetalLB, etc.). Las bóvedas en metal desnudo todavía están en sus etapas maduras, aunque están representadas por una multitud de soluciones comerciales y de código abierto. Decidí comparar las principales soluciones prometedoras y gratuitas (probar simultáneamente un producto comercial para entender lo que estoy perdiendo). Gama de soluciones de
Debido a la crisis con COVID-19, el real brasileño cayó a un mínimo histórico frente al dólar estadounidense.Nuestra moneda nacional está realmente muy subestimada, por lo que el salario promedio de un desarrollador senior es de solo 2000 USD por mes. Por lo tanto, no podemos permitirnos el lujo de gastar cantidades significativas en servicios en la nube. La última vez que hice los cálculos, [gracias a usar mis servidores] ahorramos un 75% en comparación con lo que tendría que pagar por AWS. En otras palabras, se puede contratar a otro desarrollador por el dinero ahorrado. Creo que este es un uso mucho más racional de los fondos.Inspirado por una serie de publicaciones de Vito Botta, decidí crear un clúster K8 usando Rancher (y hasta ahora tan bueno ...). Vito también realizó un excelente análisis de varias soluciones de almacenamiento. El claro ganador fue Linstor (incluso lo destacó enliga especial ). Spoiler: estoy de acuerdo con él.Hace tiempo que sigo el tráfico alrededor de Kubernetes, pero recientemente decidí participar en él. Esto se debe principalmente al hecho de que el proveedor tiene una nueva línea de procesadores Ryzen. Y luego me sorprendió mucho ver que muchas soluciones aún están en desarrollo o en estado inmaduro (especialmente para clústeres de metal desnudo: virtualización VM, MetalLB, etc.). Las bóvedas en metal desnudo todavía están en sus etapas maduras, aunque están representadas por una multitud de soluciones comerciales y de código abierto. Decidí comparar las principales soluciones prometedoras y gratuitas (probar simultáneamente un producto comercial para entender lo que estoy perdiendo). Gama de soluciones de almacenamiento en CNCF LandscapePero antes que nada, quiero advertirte que soy nuevo en los K8.Para los experimentos, se utilizaron 4 trabajadores con la siguiente configuración: procesador Ryzen 3700X, memoria ECC de 64 GB, tamaño NVMe de 2 TB. Los puntos de referencia se realizaron utilizando la imagen
almacenamiento en CNCF LandscapePero antes que nada, quiero advertirte que soy nuevo en los K8.Para los experimentos, se utilizaron 4 trabajadores con la siguiente configuración: procesador Ryzen 3700X, memoria ECC de 64 GB, tamaño NVMe de 2 TB. Los puntos de referencia se realizaron utilizando la imagen sotoaster/dbench:latest(en fio) con la bandera O_DIRECT.Longhorn
Realmente me gustó Longhorn. Está completamente integrado con Rancher y puede instalarlo a través de Helm con un solo clic. Instalación de Longhorn desde RancherEsta es una herramienta de código abierto con el estado de un proyecto de sandbox de la Cloud Native Computing Foundation (CNCF). Su desarrollo está financiado por Rancher, una empresa bastante exitosa con un producto [epónimo] muy conocido.
Instalación de Longhorn desde RancherEsta es una herramienta de código abierto con el estado de un proyecto de sandbox de la Cloud Native Computing Foundation (CNCF). Su desarrollo está financiado por Rancher, una empresa bastante exitosa con un producto [epónimo] muy conocido. También está disponible una excelente interfaz gráfica : todo se puede hacer desde ella. Con el rendimiento, todo está en orden. El proyecto aún está en beta, lo que se confirma por problemas en GitHub.Al probar, lancé un punto de referencia con 2 réplicas y Longhorn 0.8.0:
También está disponible una excelente interfaz gráfica : todo se puede hacer desde ella. Con el rendimiento, todo está en orden. El proyecto aún está en beta, lo que se confirma por problemas en GitHub.Al probar, lancé un punto de referencia con 2 réplicas y Longhorn 0.8.0:- Lectura / escritura aleatoria, IOPS: 28.2k / 16.2k;
- Ancho de banda de lectura / escritura: 205 Mb / s / 108 Mb / s;
- Latencia promedio de lectura / escritura (usec): 593.27 / 644.27;
- Lectura / escritura secuencial: 201 Mb / s / 108 Mb / s;
- Lectura / escritura aleatoria mixta, IOPS: 14.7k / 4904.
Openebs
Este proyecto también tiene estado de caja de arena CNCF. Con una gran cantidad de estrellas en GitHub, parece una solución muy prometedora. En su revisión, Vito Botta se quejó de un rendimiento insuficiente. Esto es lo que el CEO de Mayadata le respondió :La información está muy desactualizada. OpenEBS solía admitir 3, pero ahora es compatible con 4 motores, si habilita el aprovisionamiento dinámico y la orquestación local de PV, que puede ejecutarse a velocidades NVMe. Además, el motor MayaStor ahora está abierto y ya está recibiendo críticas positivas (aunque tiene estado alfa).
En la página del proyecto OpenEBS hay una explicación sobre su estado:OpenEBS — Kubernetes. OpenEBS sandbox- CNCF 2019- , - (local, nfs, zfs, nvme) on-premise, . OpenEBS - stateful- — Litmus Project, — OpenEBS. OpenEBS production 2018 ; 2,5 docker pull'.
Tiene muchos motores, y el último parece bastante prometedor en términos de rendimiento: "MayaStor - motor alfa con NVMe sobre Fabrics". Por desgracia, no lo probé debido al estado de la versión alfa.En las pruebas, se utilizó la versión 1.8.0 en el motor jiva. Además, verifiqué previamente cStor, pero no guardé los resultados, que, sin embargo, resultaron ser un poco más lentos que jiva. Para el punto de referencia, se instaló un gráfico de Helm con todas las configuraciones predeterminadas y openebs-jiva-defaultse utilizó la Clase de almacenamiento, creada de forma estándar por Helm ( ). El rendimiento resultó ser la peor de todas las soluciones consideradas (agradecería los consejos para mejorarlo).OpenEBS 1.8.0 con motor jiva (¿3 réplicas?):- Lectura / escritura aleatoria, IOPS: 2182/1527;
- Ancho de banda de lectura / escritura: 65.0 Mb / s / 41.9 Mb / s;
- / (usec): 1825.49 / 2612.87;
- /: 95.5 / / 37.8 /;
- /, IOPS: 2607 / 856.
. Evan Powell, OpenEBS ( , StackStorm Nexenta):, Bruno! OpenEBS . Jiva, ARM overhead' . Bloomberg DynamicLocal PV OpenEBS. Elastic , . , OpenEBS Director (https://account.mayadata.io/signup). — , .
StorageOS
Esta es una solución comercial que es gratuita cuando se utilizan hasta 110 GB de espacio. Se puede obtener una licencia de desarrollador gratuita registrándose a través de la interfaz de usuario del producto; Da hasta 500 GB de espacio. En Rancher, aparece como socio, por lo que la instalación con Helm fue fácil y sin preocupaciones.Al usuario se le ofrece un panel de control básico. La prueba de este producto fue limitada porque es comercial y no nos conviene en valor. Pero aún así quería ver de qué son capaces los proyectos comerciales.La prueba utiliza la clase de almacenamiento existente llamada "Rápido" (Plantilla 0.2.19, 1 ¿Maestro + 0 Réplica?). Los resultados fueron asombrosos. Superaron significativamente las soluciones anteriores.- Lectura / escritura aleatoria, IOPS: 117k / 90.4k;
- Ancho de banda de lectura / escritura: 2124 Mb / s / 457 Mb / s;
- Latencia promedio de lectura / escritura (usec): 63.44 / 86.52;
- Lectura / escritura secuencial: 1907 Mb / s / 448 Mb / s;
- Lectura / escritura aleatoria mixta, IOPS: 81.9k / 27.3k.
Pireo (basado en Linstor)
Licencia: GPLv3El ya mencionado Vito Botta finalmente se decidió por Linstor, lo cual fue una razón adicional para probar esta solución. A primera vista, el proyecto parece bastante extraño. Casi no hay estrellas en GitHub, un nombre inusual y ni siquiera existe en CNCF Landscape. Pero después de una inspección más cercana, todo no da tanto miedo, porque:- DRBD se utiliza como mecanismo básico de replicación (de hecho, fue desarrollado por las mismas personas). Al mismo tiempo, DRBD 8.x ha sido parte del núcleo oficial de Linux durante más de 10 años. Y estamos hablando de tecnología que ha sido perfeccionada por más de 20 años.
- Los medios están controlados por LINSTOR, también una tecnología madura de la misma compañía. La primera versión del servidor Linstor apareció en GitHub en febrero de 2018. Es compatible con varias tecnologías / sistemas como Proxmox, OpenNebula y OpenStack.
- Aparentemente, Linbit está desarrollando activamente el proyecto, introduciendo constantemente nuevas características y mejoras en él. La décima versión de DRBD todavía tiene estado alfa , pero ya cuenta con algunas características únicas, como la codificación de borrado (análoga a la funcionalidad de RAID5 / 6 - aprox. Transl.) .
- La compañía toma ciertas medidas para convertirse en uno de los proyectos de CNCF.
De acuerdo, el proyecto parece lo suficientemente convincente como para confiarle sus preciosos datos. ¿Pero es capaz de reproducir alternativas? Echemos un vistazo.Instalación
Vito habla sobre instalar Linstor aquí . Sin embargo, en los comentarios, uno de los desarrolladores de Linstor recomienda un nuevo proyecto llamado Pireo. Según tengo entendido, Pireo se está convirtiendo en el proyecto de código abierto de Linbit, que combina todo lo relacionado con los K8. El equipo está trabajando en el operador apropiado , pero por ahora, Piraeus se puede instalar usando este archivo YAML:kubectl apply -f https://raw.githubusercontent.com/bratao/piraeus/master/deploy/all.yaml
¡Atención! Recoges configuraciones de mi repositorio personal. ¡Mira el repositorio oficial! Actualicé la versión de las imágenes para resolver el error que ocurre cuando se usa en Ubuntu.El repositorio oficial de Piraeus está disponible aquí .También puede usar el repositorio de kvaps (parece aún más dinámico que el repositorio oficial de piraeus): https://github.com/kvaps/kube-linstor (aproveche esta oportunidad para saludar a Andreykvaps- aprox. perev.) . Todos los nodos funcionan después de la instalación.
Todos los nodos funcionan después de la instalación.Administración
La administración se lleva a cabo utilizando la línea de comando. El acceso a él es posible desde el shell de comandos del nodo piraeus-controller. El nodo del controlador está ejecutando linstor-server. Es una capa de abstracción sobre drbd, capaz de gestionar toda la flota de nodos. La captura de pantalla siguiente muestra algunos comandos útiles para las tareas más populares, por ejemplo:
El nodo del controlador está ejecutando linstor-server. Es una capa de abstracción sobre drbd, capaz de gestionar toda la flota de nodos. La captura de pantalla siguiente muestra algunos comandos útiles para las tareas más populares, por ejemplo:linstor node list - mostrar una lista de nodos conectados y su estado;linstor volume list - mostrar una lista de los volúmenes creados y su ubicación;linstor node info - Muestra las capacidades de cada nodo.
 Comandos de Linstor Unalista completa de comandos está disponible en la documentación oficial: Guía del usuario LINSTOR .En el caso de situaciones como cerebro dividido, se puede acceder a drbd directamente a través de los nodos.
Comandos de Linstor Unalista completa de comandos está disponible en la documentación oficial: Guía del usuario LINSTOR .En el caso de situaciones como cerebro dividido, se puede acceder a drbd directamente a través de los nodos.Recuperación de desastres
Hice todo lo posible para soltar mi clúster, incluido el restablecimiento completo en los nodos. Pero Linstor era sorprendentemente tenaz.Drbd reconoce perfectamente un problema llamado cerebro dividido. En mi situación, el nodo secundario se cayó de la replicación.Split brain — , - , - Primary, «» . , . , , .
Split brain DRBD , , Heartbeat.
Los detalles se pueden encontrar en la documentación oficial de drbd . El nodo secundario se cayó de la replicación.En mi caso, para resolver el problema, eliminé los datos secundarios y comencé la sincronización con el nodo primario. Como prefiero las interfaces gráficas, utilicé la utilidad drbdtop para esto. Con su ayuda, puede monitorear visualmente el estado y ejecutar comandos dentro de los nodos.Necesitaba ir a la consola en el nodo problemático piratas (era
El nodo secundario se cayó de la replicación.En mi caso, para resolver el problema, eliminé los datos secundarios y comencé la sincronización con el nodo primario. Como prefiero las interfaces gráficas, utilicé la utilidad drbdtop para esto. Con su ayuda, puede monitorear visualmente el estado y ejecutar comandos dentro de los nodos.Necesitaba ir a la consola en el nodo problemático piratas (era worker2-gpu): ir al nodoAllí instalé drdbtop. Descargue esta utilidad aquí:
ir al nodoAllí instalé drdbtop. Descargue esta utilidad aquí:wget https://github.com/LINBIT/drbdtop/releases/download/v0.2.2/drbdtop-linux-amd64
chmod +x drbdtop-linux-amd64
./drbdtop-linux-amd64
 Ejecución de la utilidad drbdtopEche un vistazo al panel inferior. Hay comandos que se pueden usar para reparar el cerebro dividido:
Ejecución de la utilidad drbdtopEche un vistazo al panel inferior. Hay comandos que se pueden usar para reparar el cerebro dividido: después de eso, los nodos se conectan y sincronizan automáticamente.
después de eso, los nodos se conectan y sincronizan automáticamente.¿Cómo aumentar la velocidad?
Por defecto, Piraeus / Linstor / drbd muestran un excelente rendimiento (puede ver esto a continuación). La configuración predeterminada es razonable y segura. Sin embargo, la velocidad de escritura fue bastante débil. Dado que los servidores en mi caso están dispersos en diferentes centros de datos (aunque físicamente están relativamente cerca), decidí intentar ajustar su rendimiento.El punto de partida para la optimización es definir un protocolo de replicación. Por defecto, se utiliza el Protocolo C, que espera la confirmación de escritura en el nodo secundario remoto. La siguiente es una descripción de los posibles protocolos:- Protocol A — . , , TCP- . , TCP . .
- Protocol B — . , , .
- Protocol C ( ) — . .
Debido a esto, en Linstor también uso el protocolo asíncrono (admite la replicación síncrona / semisíncrona / asíncrona). Puede habilitarlo con el siguiente comando:linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 1085760 --rcvbuf-size 1085760 --c-max-rate 4194304 --c-fill-target 1048576
El resultado de su implementación será la activación del protocolo asincrónico y un aumento en el búfer de hasta 1 MB. Es relativamente seguro O puede usar el siguiente comando (ignora las descargas de disco y aumenta significativamente el búfer):linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 10485760 --rcvbuf-size 10485760 --disk-barrier no --disk-flushes no --c-max-rate 4194304 --c-fill-target 1048576
Tenga en cuenta que si el nodo primario falla, es posible que una pequeña porción de los datos no llegue a las réplicas.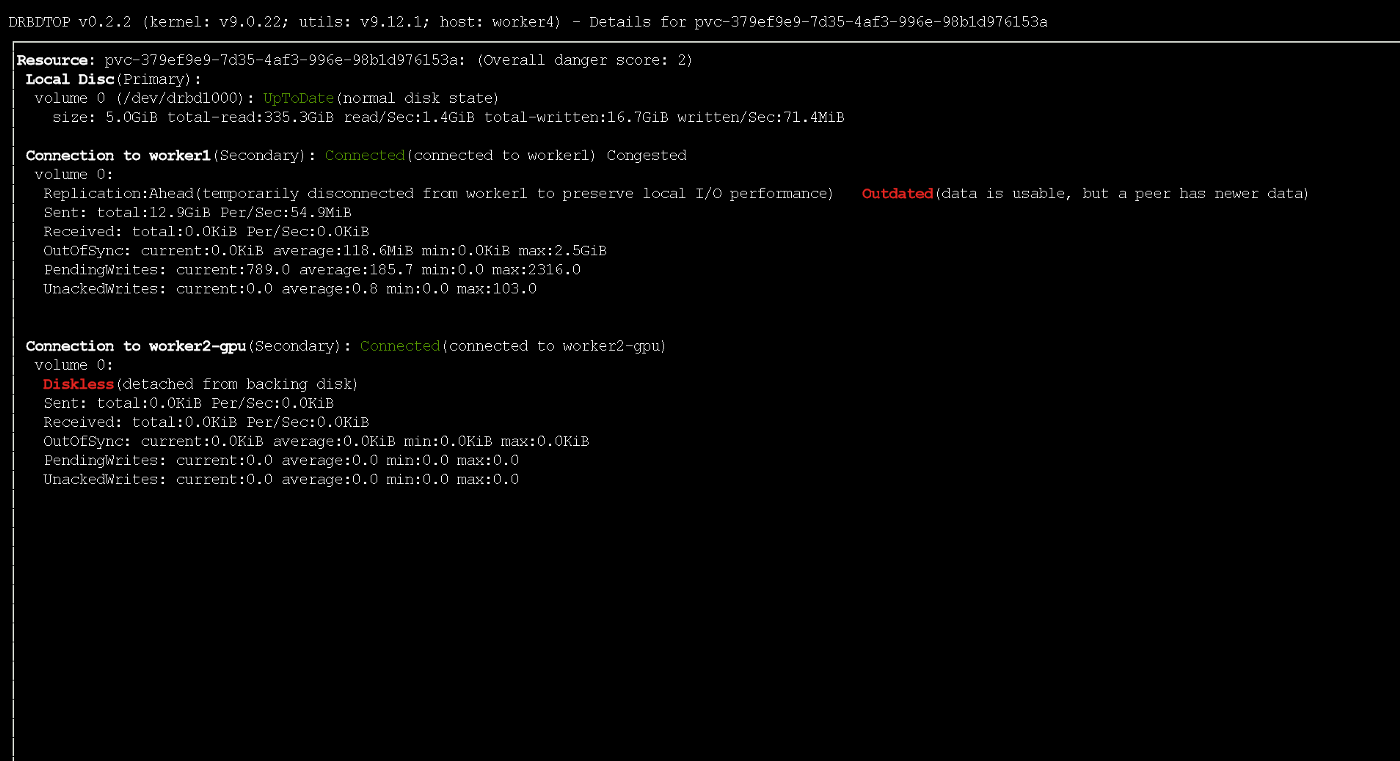 Durante la grabación activa, el nodo recibió temporalmente el estado desactualizado utilizando el protocolo ASYNC
Durante la grabación activa, el nodo recibió temporalmente el estado desactualizado utilizando el protocolo ASYNCPruebas
Todos los puntos de referencia se realizaron utilizando el siguiente trabajo:kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench
spec:
storageClassName: STORAGE_CLASS
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: dbench
spec:
template:
spec:
containers:
- name: dbench
image: sotoaster/dbench:latest
imagePullPolicy: IfNotPresent
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: FIO_SIZE
value: 1G
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench
backoffLimit: 4
El retardo entre las máquinas es como sigue: ttl=61 time=0.211 ms. El rendimiento medido entre ellos fue de 943 Mbps. Todos los nodos están ejecutando Ubuntu 18.04. Resultados ( tabla en sheetu.com )
Como se puede ver en la tabla, Piraeus y StorageOS mostraron los mejores resultados. El líder era Pireo con dos réplicas y un protocolo asincrónico.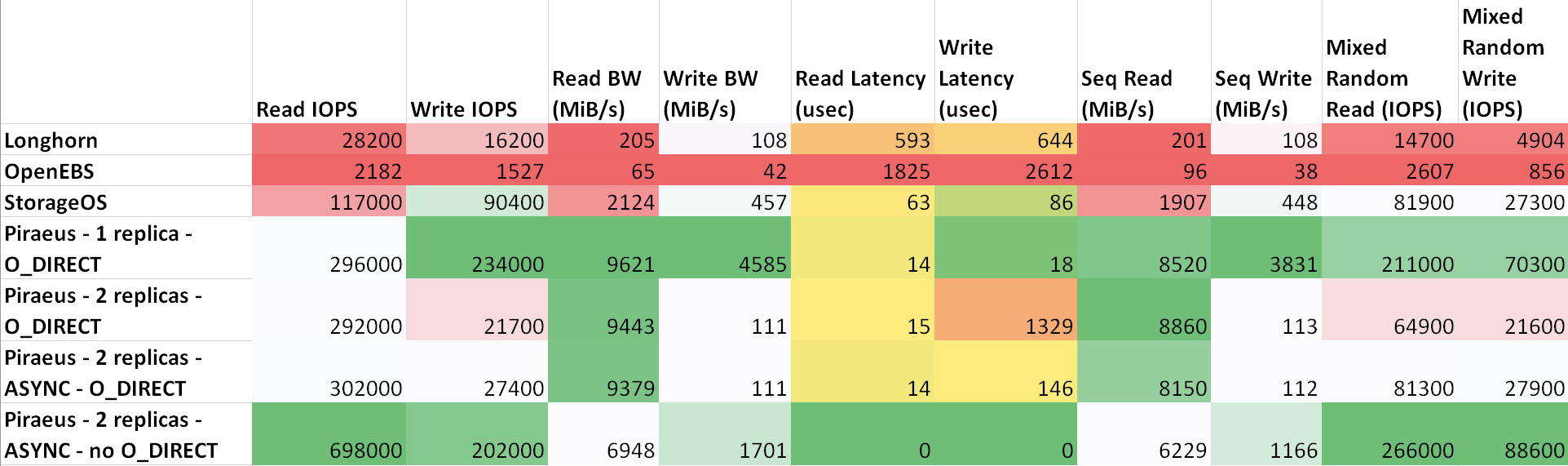
recomendaciones
Hice una comparación simple y quizás no demasiado correcta de algunas soluciones de almacenamiento en Kubernetes.Sobre todo me gustó Longhorn debido a su buena interfaz gráfica de usuario y su integración con Rancher. Sin embargo, los resultados no son inspiradores. Obviamente, los desarrolladores se centran principalmente en la seguridad y la corrección, dejando la velocidad para más adelante.Hace tiempo que uso Linstor / Piraeus en los entornos de producción de algunos proyectos. Hasta ahora, todo estaba bien: se crearon y eliminaron discos, los nodos se reiniciaron sin tiempo de inactividad ...En mi opinión, Piraeus está bastante listo para su uso en producción, pero necesita ser mejorado. Escribí sobre algunos errores en el canal del proyecto en Slack, pero en respuesta solo me aconsejaron que enseñara Kubernetes (y esto es correcto, ya que todavía no lo entiendo bien). Después de una pequeña correspondencia, todavía logré convencer a los autores de que había un error en su script de inicio. Ayer, después de actualizar el kernel y reiniciar, el nodo se negó a arrancar. Resultó que la compilación del script que integra el módulo drbd en el núcleo falló . Volver a la versión anterior del kernel resolvió el problema.Eso, en general, es todo. Dado que lo implementaron sobre drbd, resultó ser una solución muy confiable con un excelente rendimiento. En caso de problemas, puede contactar directamente con la administración de drbd y solucionarlo. En Internet hay muchas preguntas y ejemplos sobre este tema.Si hice algo mal, si algo se puede mejorar o necesita ayuda, contácteme en Twitter o en GitHub .PD del traductor
Lea también en nuestro blog: