En un artículo anterior, donde hablé sobre el monitoreo de una base de datos PostgreSQL , había una frase así:Crecer wait: la aplicación se ha "apoyado" en las cerraduras de alguien . Si se trata de una anomalía pasada, una ocasión para comprender el motivo original.
Esta situación es una de las más desagradables para el DBA:- a primera vista, la base está funcionando
- no se agotaron los recursos del servidor
- ... pero algunas de las solicitudes "se ralentizan"
 Las posibilidades de atrapar las cerraduras "en el momento" son extremadamente pequeñas, y pueden durar solo unos segundos, pero empeoran el tiempo de ejecución planificado de la solicitud decenas de veces. Pero simplemente no quiere sentarse y ver lo que está sucediendo en línea, sino en una atmósfera relajada para descubrir
Las posibilidades de atrapar las cerraduras "en el momento" son extremadamente pequeñas, y pueden durar solo unos segundos, pero empeoran el tiempo de ejecución planificado de la solicitud decenas de veces. Pero simplemente no quiere sentarse y ver lo que está sucediendo en línea, sino en una atmósfera relajada para descubrir cuál de los desarrolladores castigó cuál era exactamente el problema: quién, con quién y por qué recurso de la base de datos entró en conflicto.¿Pero cómo? De hecho, en contraste con la solicitud con su plan, que le permite comprender en detalle a qué se dedicaron los recursos y cuánto tiempo tomó, el bloqueo no deja rastros tan obvios ...A menos que se ingrese un registro breve: ¡ Pero tratemos de atraparlo!process ... still waiting for ...
Atrapamos la cerradura en el registro
Pero incluso para que al menos esta línea aparezca en el registro, el servidor debe estar configurado correctamente:log_lock_waits = 'on'
... y establezca un borde mínimo para nuestro análisis:deadlock_timeout = '100ms'
Cuando el parámetro está habilitado log_lock_waits, este parámetro también determina a qué hora se escribirán en el registro del servidor los mensajes sobre espera de bloqueo. Si está intentando investigar los retrasos causados por las cerraduras, tiene sentido reducirlo en comparación con el valor habitual deadlock_timeout.
Todos los puntos muertos que no tienen tiempo para "desatarse" durante este tiempo se romperán. Y aquí están las cerraduras "habituales", volcadas en el registro por varias entradas:2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 still waiting for ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 100.047 ms
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest DETAIL: Process holding the lock: 38154. Wait queue: 38162.
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest CONTEXT: SQL statement "SELECT pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer )"
PL/pgSQL function inline_code_block line 2 at PERFORM
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest STATEMENT: DO $$ BEGIN
PERFORM pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer );
EXCEPTION
WHEN query_canceled THEN RETURN;
END; $$;
…
2019-03-27 00:06:46.077 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 acquired ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 150.741 ms
Este ejemplo muestra que solo teníamos 50 ms desde el momento en que apareció el bloqueo en el registro hasta el momento de su resolución. Solo en este intervalo podemos obtener al menos algo de información al respecto, y cuanto más rápido podamos hacerlo, más bloqueos podemos analizar.Aquí la información más importante para nosotros es el PID del proceso que está esperando el bloqueo. Es allí donde podemos comparar información entre el registro y el estado de la base de datos. Y al mismo tiempo, para descubrir qué tan problemático era un bloqueo en particular, es decir, cuánto tiempo se "colgó".Para hacer esto, solo necesitamos un par de RegExp en el LOGregistro de contenido :const RE_lock_detect = /^process (\d+) still waiting for (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
const RE_lock_acquire = /^process (\d+) acquired (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
Llegamos al registro
En realidad, sigue siendo un poco: tomar el registro, aprender a monitorearlo y responder en consecuencia.Ya tenemos todo para esto: un analizador de registros en línea y una conexión de base de datos preactivada, de lo que hablé en un artículo sobre nuestro sistema de monitoreo PostgreSQL :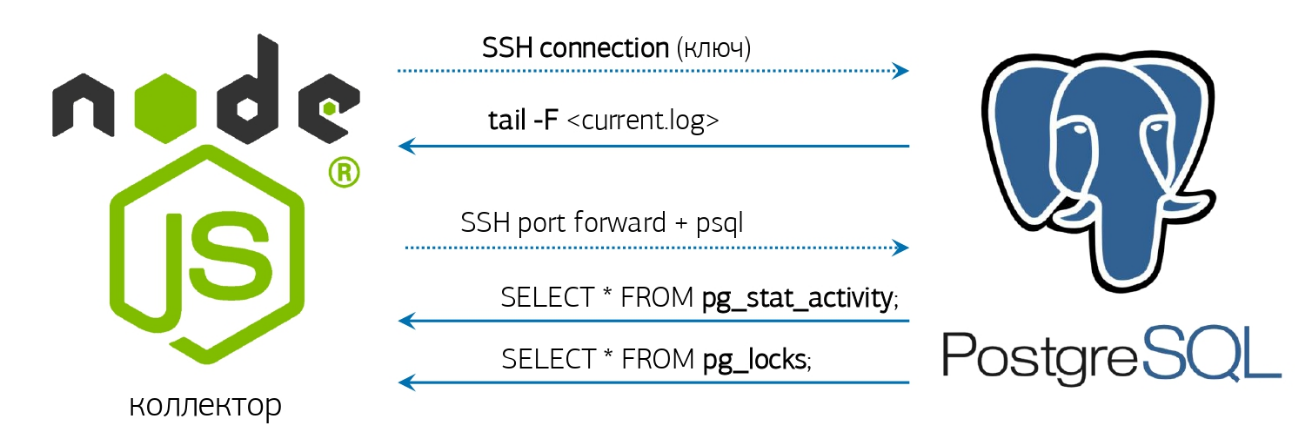 Pero si no tiene un sistema similar implementado, entonces está bien, haremos todo "Directamente desde la consola"!Si la versión instalada de PostgreSQL 10 y superior es afortunada, porque la función pg_current_logfile () ha aparecido allí , lo que explícitamente da el nombre del archivo de registro actual. Conseguirlo desde la consola será bastante fácil:
Pero si no tiene un sistema similar implementado, entonces está bien, haremos todo "Directamente desde la consola"!Si la versión instalada de PostgreSQL 10 y superior es afortunada, porque la función pg_current_logfile () ha aparecido allí , lo que explícitamente da el nombre del archivo de registro actual. Conseguirlo desde la consola será bastante fácil:psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) <> '/' THEN current_setting('data_directory') ELSE '' END || '/' || pg_current_logfile()"
Si la versión es repentinamente más joven, todo resultará, pero un poco más complicado:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}'
Obtenemos tail -fel nombre de archivo completo, el cual cedemos y capturaremos la apariencia allí 'still waiting for'.Bueno, tan pronto como surgió algo en este hilo, llamamos ...Solicitud de análisis
Por desgracia, el objeto de bloqueo en el registro no siempre es el recurso que causó el conflicto. Por ejemplo, si intenta crear un índice del mismo nombre en paralelo, solo habrá algo así en el registro still waiting for ExclusiveLock on transaction 12345.Por lo tanto, tendremos que eliminar el estado de todos los bloqueos de la base de datos para el proceso que nos interese. Y la información solo sobre un par de procesos (quién pone el bloqueo / quién lo espera) no es suficiente, porque a menudo hay una "cadena" de expectativas de diferentes recursos entre las transacciones:tx1 [resA] -> tx2 [resA]
tx2 [resB] -> tx3 [resB]
...
Clásico: "Abuelo para nabo, abuela para abuelo, nieta para abuela, ..."Por lo tanto, escribiremos una solicitud que nos dirá exactamente quién se convirtió en la causa principal de los problemas a lo largo de toda la cadena de cerraduras para un PID específico:WITH RECURSIVE lm AS (
SELECT
rn
, CASE
WHEN lm <> 'Share' THEN row_number() OVER(PARTITION BY lm <> 'Share' ORDER BY rn)
END rx
, lm || 'Lock' lm
FROM (
SELECT
row_number() OVER() rn
, lm
FROM
unnest(
ARRAY[
'AccessShare'
, 'RowShare'
, 'RowExclusive'
, 'ShareUpdateExclusive'
, 'Share'
, 'ShareRowExclusive'
, 'Exclusive'
, 'AccessExclusive'
]
) T(lm)
) T
)
, lt AS (
SELECT
row_number() OVER() rn
, lt
FROM
unnest(
ARRAY[
'relation'
, 'extend'
, 'page'
, 'tuple'
, 'transactionid'
, 'virtualxid'
, 'object'
, 'userlock'
, 'advisory'
, ''
]
) T(lt)
)
, lmx AS (
SELECT
lr.rn lrn
, lr.rx lrx
, lr.lm lr
, ld.rn ldn
, ld.rx ldx
, ld.lm ld
FROM
lm lr
JOIN
lm ld ON
ld.rx > (SELECT max(rx) FROM lm) - lr.rx OR
(
(lr.rx = ld.rx) IS NULL AND
(lr.rx, ld.rx) IS DISTINCT FROM (NULL, NULL) AND
ld.rn >= (SELECT max(rn) FROM lm) - lr.rn
)
)
, lcx AS (
SELECT DISTINCT
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
pg_locks ld
JOIN
pg_locks lr ON
lr.pid <> ld.pid AND
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) IS NOT DISTINCT FROM (ld.locktype, ld.database, ld.relation, ld.page, ld.tuple, ld.virtualxid, ld.transactionid::text::bigint, ld.classid, ld.objid, ld.objsubid) AND
(lr.granted, ld.granted) = (TRUE, FALSE)
JOIN
lmx ON
(lmx.lr, lmx.ld) = (lr.mode, ld.mode)
WHERE
(ld.pid, ld.granted) = ($1::integer, FALSE)
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN ARRAY[relation::text]
WHEN 'extend' THEN ARRAY[relation::text]
WHEN 'page' THEN ARRAY[relation, page]::text[]
WHEN 'tuple' THEN ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN ARRAY[transactionid::text]
WHEN 'virtualxid' THEN regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN ARRAY[classid::text]
WHEN 'advisory' THEN ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp "locked"
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, (lc.locktype, lc.database, lc.relation, lc.page, lc.tuple, lc.virtualxid, lc.transactionid::text::bigint, lc.classid, lc.objid, lc.objsubid) IS NOT DISTINCT FROM lcx.target "conflict"
FROM
lcx
JOIN
pg_locks lc ON
lc.pid IN (lcx.ldp, lcx.lrp);
Problema # 1 - Inicio lento
Como puede ver en el ejemplo del registro, al lado de la línea que indica la aparición de un bloqueo ( LOG), hay 3 líneas más ( DETAIL, CONTEXT, STATEMENT) que informan información extendida.Primero, esperamos la formación de un "paquete" completo de las 4 entradas y solo después de eso recurrimos a la base de datos. Pero podemos completar la formación del paquete solo cuando llegue el siguiente (¡ya 5to!) Registro, con los detalles de otro proceso, o por tiempo de espera. Está claro que ambas opciones provocan esperas innecesarias.Para deshacernos de estos retrasos, cambiamos al procesamiento continuo de registros de bloqueo. Es decir, ahora pasamos a la base de datos de destino tan pronto como clasificamos el primer registro y nos damos cuenta de que era el bloqueo descrito allí.Problema # 2 - solicitud lenta
Pero aún así, algunas de las cerraduras no tuvieron tiempo de ser analizadas. Comenzaron a profundizar más y descubrieron que en algunos servidores nuestra solicitud de análisis se ejecuta durante 15-20 ms .La razón resultó ser común: el número total de bloqueos activos en la base, llegando a varios miles: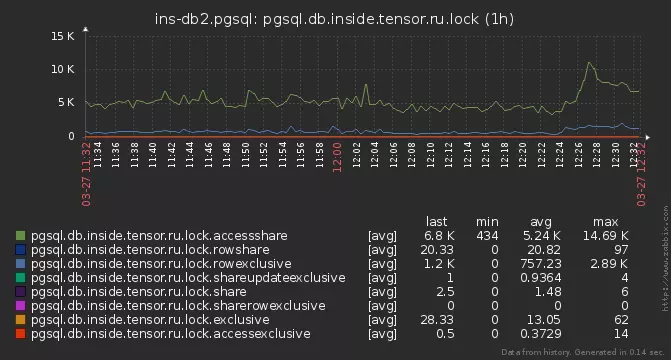
pg_locks
Aquí debe tenerse en cuenta que los bloqueos en PostgreSQL no se "almacenan" en ninguna parte, sino que se presentan solo en la vista del sistema pg_locks , que es un reflejo directo de la función pg_lock_status. ¡Y en nuestra solicitud leímos tres veces ! Mientras tanto, leemos estos miles de instancias de bloqueo y descartamos aquellos que no están relacionados con nuestro PID, el bloqueo en sí mismo se "resolvió" ... Lasolución fue "materializar" el estado de pg_locks en el CTE ; después de eso, puede ejecutarlo tantas veces como lo desee, ya es no cambia. Además, después de utilizar el algoritmo, fue posible reducir todo a solo dos de sus escaneos.Dinámica Excesiva
Y si miramos un poco más de cerca la consulta anterior, podemos ver que el CTE lmy lmxde ninguna manera está vinculado a los datos, sino que simplemente calculamos siempre la misma definición de matriz "estática" de conflicto entre modos de bloqueo . Así que configurémoslo como una calidad VALUES.Problema # 3 - vecinos
Pero parte de las cerraduras todavía se saltaron. Por lo general, esto sucedió de acuerdo con el siguiente esquema: alguien bloqueó un recurso popular, y varios procesos se encontraron rápidamente a lo largo de una cadena .Como resultado, capturamos el primer PID, fuimos a la base objetivo (y para no sobrecargarlo, mantenemos solo una conexión), hicimos el análisis, regresamos con el resultado, tomamos el siguiente PID ... Pero la vida no vale la pena en la base, y el bloqueo PID # 2 ya se ha ido!En realidad, ¿por qué necesitamos ir a la base de datos para cada PID por separado, si todavía filtramos los bloqueos de la lista general en la solicitud? Tomemos inmediatamente la lista completa de procesos en conflicto directamente de la base de datos y distribuya sus bloqueos en todos los PID que cayeron durante la ejecución de la solicitud:WITH lm(ld, lr) AS (
VALUES
('AccessShareLock', '{AccessExclusiveLock}'::text[])
, ('RowShareLock', '{ExclusiveLock,AccessExclusiveLock}'::text[])
, ('RowExclusiveLock', '{ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareUpdateExclusiveLock', '{ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareRowExclusiveLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ExclusiveLock', '{RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('AccessExclusiveLock', '{AccessShareLock,RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
)
, locks AS (
SELECT
(
locktype
, database
, relation
, page
, tuple
, virtualxid
, transactionid::text::bigint
, classid
, objid
, objsubid
) target
, *
FROM
pg_locks
)
, ld AS (
SELECT
*
FROM
locks
WHERE
NOT granted
)
, lr AS (
SELECT
*
FROM
locks
WHERE
target::text = ANY(ARRAY(
SELECT DISTINCT
target::text
FROM
ld
)) AND
granted
)
, lcx AS (
SELECT DISTINCT
lr.target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
ld
JOIN
lr
ON lr.pid <> ld.pid AND
lr.target IS NOT DISTINCT FROM ld.target
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN
ARRAY[relation::text]
WHEN 'extend' THEN
ARRAY[relation::text]
WHEN 'page' THEN
ARRAY[relation, page]::text[]
WHEN 'tuple' THEN
ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN
ARRAY[transactionid::text]
WHEN 'virtualxid' THEN
regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN
ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN
ARRAY[classid::text]
WHEN 'advisory' THEN
ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp as locked
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, lc.target IS NOT DISTINCT FROM lcx.target as conflict
FROM
lcx
JOIN
locks lc
ON lc.pid IN (lcx.ldp, lcx.lrp);
Ahora tenemos tiempo para analizar incluso los bloqueos que existen solo 1-2 ms después de ingresar al registro.Analiza esto
En realidad, ¿por qué lo intentamos tanto? ¿Qué nos da esto como resultado? ..type | target | locked | pid | mode | granted | conflict
---------------------------------------------------------------------------------------
relation | {225388639} | f | 216547 | AccessShare | t | f
relation | {423576026} | f | 216547 | AccessShare | t | f
advisory | {225386226,194303167,2} | t | 24964 | Exclusive | f | t
relation | {341894815} | t | 24964 | AccessShare | t | f
relation | {416441672} | f | 216547 | AccessShare | t | f
relation | {225964322} | f | 216547 | AccessShare | t | f
...
En esta placa, los valores targetcon un tipo son útiles para nosotros relation, porque cada uno de esos valores es un OID de una tabla o índice . Ahora queda muy poco: aprender a interrogar la base de datos para OID aún desconocidos para traducirlos a una forma legible para humanos:SELECT $1::oid::regclass;
Ahora, conociendo la "matriz" completa de las cerraduras y todos los objetos en los que fueron superpuestas por cada una de las transacciones, podemos concluir "qué sucedió en absoluto" , y qué recurso causó el conflicto, incluso si la solicitud fue bloqueada, éramos desconocidos. Esto puede suceder fácilmente, por ejemplo, cuando el tiempo de ejecución de una solicitud de bloqueo no es lo suficientemente largo como para llegar al registro, pero la transacción estuvo activa después de su finalización y creó problemas durante mucho tiempo. Pero sobre esto, en otro artículo.
Pero sobre esto, en otro artículo."Todo por sí mismo"
Mientras tanto, recopilaremos la versión completa de "monitoreo", que eliminará automáticamente el estado de los bloqueos de nuestro archivo tan pronto como aparezca algo sospechoso en el registro:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}' \
| xargs -l -I{} tail -f {} \
| stdbuf -o0 grep 'still waiting for' \
| xargs -l -I{} date '+%Y%m%d-%H%M%S.%N' \
| xargs -l -I{} psql -U postgres postgres -f detect-lock.sql -o {}-lock.log
Y al lado para detect-lock.sqlponer la última solicitud. Ejecute y obtenga un montón de archivos con el contenido deseado dentro:# cat 20200526-181433.331839375-lock.log
type | target | locked | pid | mode | granted | conflict
---------------+----------------+--------+--------+--------------+---------+----------
relation | {279588430} | t | 136325 | RowExclusive | t | f
relation | {279588422} | t | 136325 | RowExclusive | t | f
relation | {17157} | t | 136325 | RowExclusive | t | f
virtualxid | {110,12171420} | t | 136325 | Exclusive | t | f
relation | {279588430} | f | 39339 | RowExclusive | t | f
relation | {279588422} | f | 39339 | RowExclusive | t | f
relation | {17157} | f | 39339 | RowExclusive | t | f
virtualxid | {360,11744113} | f | 39339 | Exclusive | t | f
virtualxid | {638,4806358} | t | 80553 | Exclusive | t | f
advisory | {1,1,2} | t | 80553 | Exclusive | f | t
advisory | {1,1,2} | f | 80258 | Exclusive | t | t
transactionid | {3852607686} | t | 136325 | Exclusive | t | f
extend | {279588422} | t | 136325 | Exclusive | f | t
extend | {279588422} | f | 39339 | Exclusive | t | t
transactionid | {3852607712} | f | 39339 | Exclusive | t | f
(15 rows)
Bueno, entonces, siéntate y analiza ...