En este artículo contaré y mostraré un ejemplo de cómo una persona con una mínima experiencia en Data Science pudo recopilar datos del foro y hacer modelos temáticos de publicaciones utilizando el modelo LDA, y reveló temas dolorosos para personas con intolerancia celíaca.El año pasado necesitaba mejorar urgentemente mi conocimiento en el campo del aprendizaje automático. Soy gerente de producto de Data Science, Machine Learning y AI, o de otra manera, Technical Product Manager AI / ML. Las habilidades comerciales y la capacidad de desarrollar productos, como suele ser el caso en proyectos destinados a usuarios que no están en el campo técnico, no son suficientes. Debe comprender los conceptos técnicos básicos de la industria de ML y, si es necesario, poder escribir un ejemplo usted mismo para demostrar el producto.Durante aproximadamente 5 años he estado desarrollando proyectos front-end, desarrollando aplicaciones web complejas en JS y React, pero nunca he tratado con el aprendizaje automático, las computadoras portátiles y los algoritmos. Por lo tanto, cuando vi las noticias de Otus de que estaban abriendo un curso experimental de cinco meses sobre Machine Learning , sin dudarlo, decidí someterme a una prueba de prueba y seguir el curso.Durante cinco meses, cada semana hubo conferencias de dos horas y tareas para ellos. Allí aprendí sobre los conceptos básicos de ML: varios algoritmos de regresión, clasificaciones, conjuntos de modelos, aumento de gradiente e incluso tecnologías en la nube ligeramente afectadas. En principio, si escuchas atentamente cada conferencia, entonces hay suficientes ejemplos y explicaciones para la tarea. Pero aún así, a veces, como en cualquier otro proyecto de codificación, tuve que recurrir a la documentación. Dado mi empleo a tiempo completo, era bastante conveniente estudiar, ya que siempre podía revisar el registro de una conferencia en línea.Al final de la capacitación de este curso, todos tuvieron que tomar el proyecto final. La idea para el proyecto surgió de manera bastante espontánea, en ese momento comencé a entrenarme en emprendimiento en Stanford, donde ingresé al equipo que trabajaba en el proyecto para personas con intolerancia celíaca. Durante la investigación de mercado, me interesó saber qué preocupaciones, de qué están hablando, de qué se quejan las personas con esta característica.A medida que avanzaba el estudio, encontré un foro en celiac.comcon una gran cantidad de material sobre la enfermedad celíaca. Era obvio que desplazarse manualmente y leer más de 100 mil publicaciones no era práctico. Entonces se me ocurrió la idea de aplicar el conocimiento que recibí en este curso: recopilar todas las preguntas y comentarios del foro sobre un tema determinado y hacer modelos temáticos con las palabras más comunes en cada uno de ellos.Paso 1. Recolección de datos del foro
El foro consta de muchos temas de varios tamaños. En total, este foro tiene alrededor de 115,000 temas y alrededor de un millón de publicaciones, con comentarios sobre ellos. Estaba interesado en el subtema específico "Hacer frente a la enfermedad celíaca" , que literalmente significa "Hacer frente a la enfermedad celíaca", si en ruso significa más "continuar viviendo con un diagnóstico de enfermedad celíaca y de alguna manera hacer frente a las dificultades". Este subtema contiene alrededor de 175,000 comentarios.La descarga de datos se produjo en dos etapas. Para empezar, tuve que revisar todas las páginas bajo el tema y recopilar todos los enlaces a todas las publicaciones, para que en el siguiente paso, ya pudiera recopilar un comentario.url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'
Como el foro resultó ser bastante antiguo, tuve mucha suerte y el sitio no tuvo ningún problema de seguridad, por lo que para recopilar los datos, fue suficiente usar la combinación Usuario-Agente de la biblioteca fake_useragent , Beautiful Soup para trabajar con el marcado html y conocer el número de páginas:
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)
Y luego descargue el DOM HTML de cada página para extraer datos de ellos de manera fácil y sencilla utilizando la biblioteca BeautifulSoup Python .
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
Para descargar los datos, necesitaba determinar los campos necesarios para el análisis: encontrar los valores de estos campos en el DOM y guardarlos en el diccionario. Yo mismo provenía del fondo de front-end, por lo que trabajar con el hogar y los objetos fue trivial para mí.def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
En total, reuní alrededor de 15,450 publicaciones en este tema.coping_posts_info = collect_post_info(coping_pages)
Ahora podrían transferirse al DataFrame para que permanecieran allí maravillosamente, y al mismo tiempo los guardó en un archivo csv para que no tuviera que esperar nuevamente cuando los datos se recopilaron del sitio si la computadora portátil se rompió accidentalmente o redefiní accidentalmente una variable donde.df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')
Después de recopilar una colección de publicaciones, procedí a recopilar los comentarios ellos mismos.def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
PASO 2 Análisis de datos y modelado temático
En el paso anterior, recopilamos datos del foro y recibimos los datos finales en forma de 153777 líneas de preguntas y comentarios.Pero solo los datos recopilados no son interesantes, por lo que lo primero que quería hacer era un análisis muy simple: derivaba estadísticas de los 30 temas más vistos y 30 temas más comentados.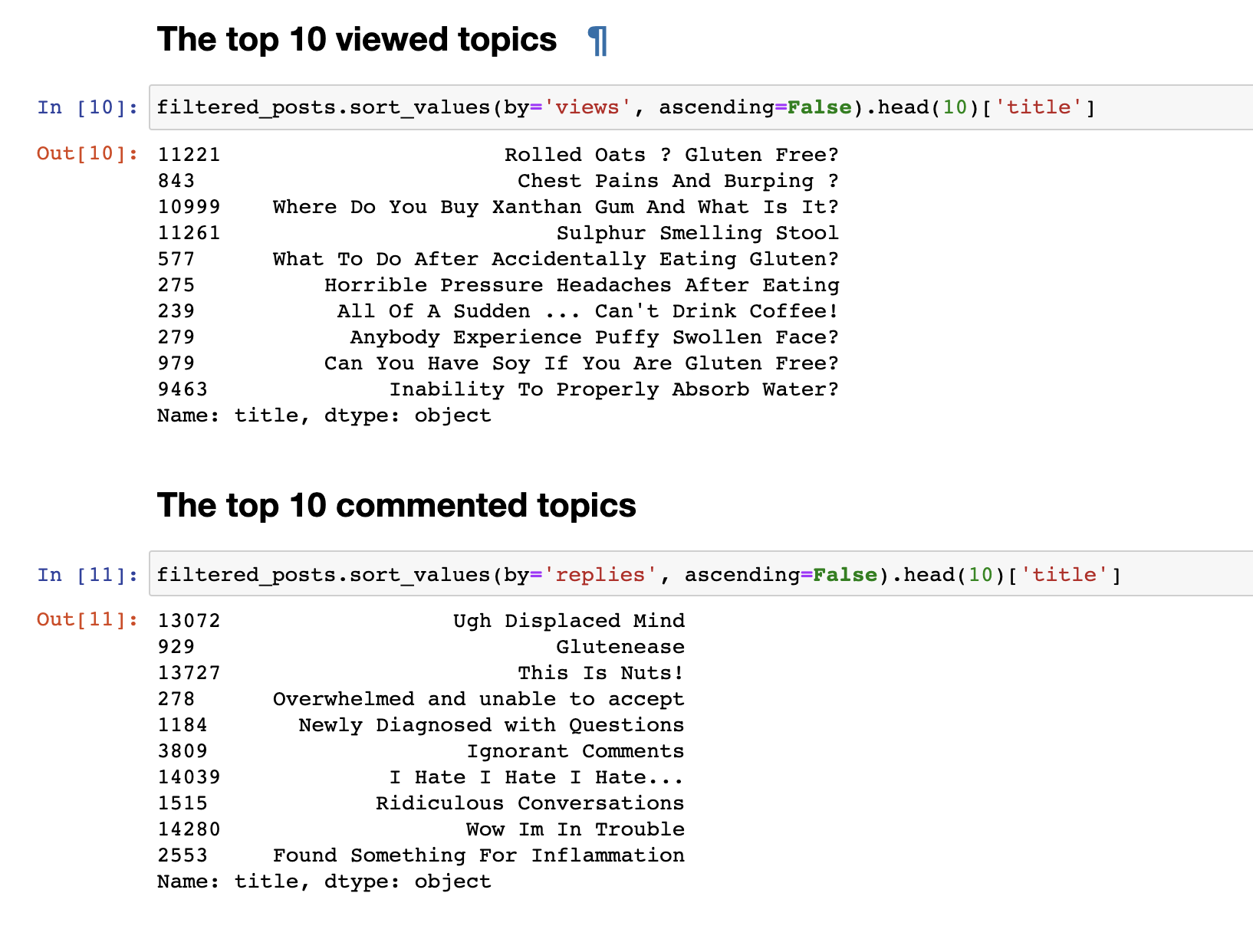 Las publicaciones más vistas no coincidieron con las más comentadas. Los títulos de las publicaciones comentadas, incluso a primera vista, son notables. Sus nombres son más emotivos: "Odio, odio, odio" o " Comentarios arrogantes" o "Guau, estoy en problemas" . Y los más vistos tienen un formato de pregunta: "¿Puedo comer soya?", "¿Por qué no puedo absorber el agua adecuadamente?"otro.Hicimos un análisis de texto simple. Para ir directamente a un análisis más complejo, debe preparar los datos antes de enviarlos a la entrada del modelo LDA para un desglose por tema. Para hacer esto, elimine los comentarios que contengan menos de 30 palabras, para filtrar el spam y los comentarios cortos sin sentido. Los llevamos a minúsculas.
Las publicaciones más vistas no coincidieron con las más comentadas. Los títulos de las publicaciones comentadas, incluso a primera vista, son notables. Sus nombres son más emotivos: "Odio, odio, odio" o " Comentarios arrogantes" o "Guau, estoy en problemas" . Y los más vistos tienen un formato de pregunta: "¿Puedo comer soya?", "¿Por qué no puedo absorber el agua adecuadamente?"otro.Hicimos un análisis de texto simple. Para ir directamente a un análisis más complejo, debe preparar los datos antes de enviarlos a la entrada del modelo LDA para un desglose por tema. Para hacer esto, elimine los comentarios que contengan menos de 30 palabras, para filtrar el spam y los comentarios cortos sin sentido. Los llevamos a minúsculas.
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()
Eliminar palabras innecesarias para borrar nuestra selección de textostop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)
También agregamos bigrams y formamos una bolsa de palabras para resaltar frases estables, por ejemplo, como gluten_free, support_group y otras frases que, cuando se agrupan, tienen un cierto significado.
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
Ahora finalmente estamos listos para entrenar directamente el modelo LDA.
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
Al final de la capacitación, finalmente obtenemos el resultado de los temas formados. Que adjunto al final de esta publicación.for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
Como puede ser notable, los temas resultaron ser muy distintos en contenido entre sí. Según ellos, queda claro de qué están hablando las personas con intolerancia celíaca. Básicamente, sobre alimentos, ir a restaurantes, alimentos contaminados con gluten, dolores terribles, tratamiento, ir a médicos, familiares, malentendidos y otras cosas que las personas tienen que enfrentar todos los días en relación con su problema.Eso es todo. Gracias a todos por su atención. Espero que encuentres este material interesante y útil. Y, sin embargo, como no soy un desarrollador de DS, no juzgue estrictamente. Si hay algo que agregar o mejorar, siempre agradezco las críticas constructivas, escriba.Para ver 30 temasPrecaución, muchas imágenes