De un editor de blogs de Google: ¿Alguna vez se preguntó cómo los ingenieros de Google Cloud Technical Solutions (TSE) manejan sus llamadas de soporte técnico? La responsabilidad de los ingenieros de soporte técnico de TSE es detectar y resolver las fuentes de problemas identificados por los usuarios. Algunos de estos problemas son bastante simples, pero a veces te encuentras con una apelación que requiere la atención de varios ingenieros a la vez. En este artículo, uno de los empleados de TSE nos contará sobre un problema muy complicado de su práctica reciente: el caso de paquetes DNS perdidos. En el curso de esta historia, veremos cómo los ingenieros lograron resolver la situación y qué cosas nuevas aprendieron al eliminar el error. Esperamos que esta historia no solo le cuente sobre un error profundamente enraizado, sino que también le brinde una comprensión de los procesos que ocurren al enviar una solicitud para admitir Google Cloud. La resolución de problemas es tanto una ciencia como un arte. Todo comienza con la construcción de una hipótesis sobre la causa del comportamiento no estándar del sistema, después de lo cual se prueba su resistencia. Sin embargo, antes de formular una hipótesis, debemos identificar claramente y formular con precisión el problema. Si la pregunta suena demasiado vaga, entonces debe analizar todo correctamente; Este es el "arte" de la solución de problemas.En el contexto de Google Cloud, estos procesos son complicados a veces, ya que Google Cloud está luchando por garantizar la privacidad de sus usuarios. Debido a esto, los ingenieros de TSE no tienen acceso para editar sus sistemas, ni la capacidad de ver configuraciones tan ampliamente como los usuarios. Por lo tanto, para probar cualquiera de nuestras hipótesis, nosotros (ingenieros) no podemos modificar rápidamente el sistema.Algunos usuarios creen que arreglaremos todo como si la mecánica en el servicio del automóvil, y simplemente nos envían la identificación de la máquina virtual, mientras que en realidad el proceso continúa en el formato de una conversación: recolectando información, generando y confirmando (o refutando) hipótesis y, en última instancia, resolviendo Los problemas se basan en la comunicación con el cliente.
La resolución de problemas es tanto una ciencia como un arte. Todo comienza con la construcción de una hipótesis sobre la causa del comportamiento no estándar del sistema, después de lo cual se prueba su resistencia. Sin embargo, antes de formular una hipótesis, debemos identificar claramente y formular con precisión el problema. Si la pregunta suena demasiado vaga, entonces debe analizar todo correctamente; Este es el "arte" de la solución de problemas.En el contexto de Google Cloud, estos procesos son complicados a veces, ya que Google Cloud está luchando por garantizar la privacidad de sus usuarios. Debido a esto, los ingenieros de TSE no tienen acceso para editar sus sistemas, ni la capacidad de ver configuraciones tan ampliamente como los usuarios. Por lo tanto, para probar cualquiera de nuestras hipótesis, nosotros (ingenieros) no podemos modificar rápidamente el sistema.Algunos usuarios creen que arreglaremos todo como si la mecánica en el servicio del automóvil, y simplemente nos envían la identificación de la máquina virtual, mientras que en realidad el proceso continúa en el formato de una conversación: recolectando información, generando y confirmando (o refutando) hipótesis y, en última instancia, resolviendo Los problemas se basan en la comunicación con el cliente.Tema bajo consideración
Hoy tenemos una historia con un buen final. Una de las razones para la solución exitosa del caso propuesto es una descripción muy detallada y precisa del problema. A continuación puede ver una copia del primer ticket (editado, para ocultar información confidencial): Este mensaje tiene mucha información útil para nosotros:
Este mensaje tiene mucha información útil para nosotros:- VM especificada
- Se indica el problema: DNS no funciona
- Se indica dónde se manifiesta el problema: VM y contenedor
- Se indican los pasos que el usuario tomó para identificar el problema.
La apelación se registró como “P1: Impacto crítico: servicio inutilizable en producción”, lo que significa un monitoreo constante de la situación las 24 horas del día, los 7 días de la semana, de acuerdo con el esquema “Follow the Sun” (el enlace se puede leer con más detalle sobre las prioridades de las llamadas de los usuarios ), con la transferencia de un equipo de soporte técnico al otro en cada cambio de zona horaria. De hecho, cuando el problema llegó a nuestro equipo en Zúrich, ella logró circunnavegar el mundo. En este momento, el usuario tomó medidas para reducir las consecuencias, sin embargo, temía que se repitiera la situación en la producción, ya que aún no se encontraba la razón principal.Para cuando el boleto llegó a Zurich, ya teníamos la siguiente información a mano:- Contenido
/etc/hosts - Contenido
/etc/resolv.conf - Conclusión
iptables-save - El
ngreparchivo pcap compilado por el comando
Con estos datos, estábamos listos para comenzar la fase de "investigación" y resolución de problemas.Nuestros primeros pasos
En primer lugar, verificamos los registros y el estado del servidor de metadatos y nos aseguramos de que funcione correctamente. El servidor de metadatos responde con la dirección IP 169.254.169.254 y, entre otras cosas, es responsable de controlar los nombres de dominio. También verificamos dos veces que el firewall funciona correctamente con VM y no bloquea los paquetes.Este fue un problema extraño: la prueba nmap refutó nuestra hipótesis principal sobre la pérdida de paquetes UDP, por lo que dedujimos mentalmente varias opciones y métodos más para verificarlos:- ¿Los paquetes desaparecen selectivamente? => Verifique las reglas de iptables
- ¿El MTU es demasiado pequeño ? => Verificar salida
ip a show - ¿El problema afecta solo a los paquetes UDP o TCP? => Conducir
dig +tcp - ¿Se devuelven los paquetes de excavación generados? => Conducir
tcpdump - ¿Libdns funciona correctamente? => Conduzca
stracepara verificar la transferencia de paquetes en ambas direcciones
Aquí decidimos llamar al usuario para solucionar problemas en vivo.Durante la llamada, logramos verificar varias cosas:- Después de varias verificaciones, excluimos las reglas de iptables de la lista de razones.
- Verificamos las interfaces de red y las tablas de enrutamiento, y verificamos dos veces la MTU
- Encontramos que
dig +tcp google.com(TCP) funciona como debería, pero dig google.com(UDP) no funciona - Habiendo
tcpdumpcorrido mientras funciona dig, encontramos que los paquetes UDP están siendo devueltos - Corremos
strace dig google.comy vemos cómo excavar correctamente las llamadas sendmsg()y recvms(), sin embargo, el segundo se ve interrumpido por el tiempo de espera
Desafortunadamente, el cambio está por terminar y nos vemos obligados a transferir el problema a la siguiente zona horaria. Sin embargo, la apelación despertó interés en nuestro equipo, y un colega sugiere crear el paquete DNS de origen con el módulo de Python scrapy.from scapy.all import *
answer = sr1(IP(dst="169.254.169.254")/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname="google.com")),verbose=0)
print ("169.254.169.254", answer[DNS].summary())
Este fragmento crea un paquete DNS y envía la solicitud al servidor de metadatos.El usuario ejecuta el código, se devuelve la respuesta DNS y la aplicación lo recibe, lo que confirma la ausencia de un problema a nivel de red.Después del próximo "viaje alrededor del mundo", la apelación regresa a nuestro equipo, y la traduzco completamente a mí mismo, creyendo que será más conveniente para el usuario si la apelación deja de circular de un lugar a otro.Mientras tanto, el usuario acepta amablemente proporcionar una instantánea de la imagen del sistema. Esta es una muy buena noticia: la capacidad de probar el sistema usted mismo acelera significativamente la resolución de problemas, porque ya no necesita pedirle al usuario que ejecute comandos, me envíe resultados y los analice, ¡puedo hacer todo por mí mismo!Los colegas comienzan a envidiarme un poco. Durante el almuerzo, discutimos la apelación, pero nadie tiene idea de lo que está sucediendo. Afortunadamente, el propio usuario ya ha tomado medidas de mitigación y no tiene prisa, por lo que tenemos tiempo para preparar el problema. Y como tenemos una imagen, podemos realizar cualquier prueba que nos interese. ¡Multa!Retrocediendo un paso
Una de las preguntas de entrevista más populares para un ingeniero de sistemas es: "¿Qué sucede cuando haces ping a www.google.com ?" La pregunta es elegante, porque el candidato debe describirse desde el shell al espacio del usuario, al núcleo del sistema y más allá de la red. Sonrío: a veces las preguntas de la entrevista también son útiles en la vida real ...Decido aplicar esta pregunta de eychar al problema actual. En términos generales, cuando intenta determinar el nombre DNS, sucede lo siguiente:- La aplicación llama a la biblioteca del sistema, por ejemplo libdns
- libdns verifica la configuración del sistema que servidor DNS debe usar (en el diagrama es 169.254.169.254, servidor de metadatos)
- libdns usa llamadas del sistema para crear un socket UDP (SOKET_DGRAM) y enviar paquetes UDP con una solicitud DNS en ambas direcciones
- Usando la interfaz sysctl, puede configurar la pila UDP a nivel de núcleo
- El núcleo interactúa con el hardware para transmitir paquetes a través de la red a través de una interfaz de red.
- El hipervisor captura y pasa el paquete al servidor de metadatos cuando entra en contacto con él.
- El servidor de metadatos determina el nombre DNS por su brujería y devuelve la respuesta de la misma manera.
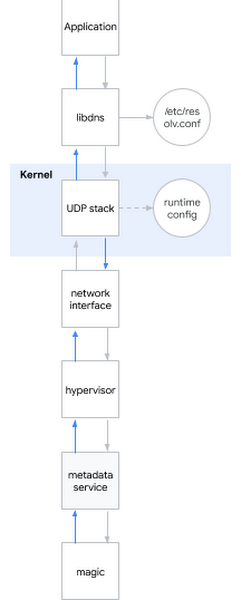 Permítame recordarle qué hipótesis ya hemos logrado considerar:Hipótesis: bibliotecas rotas
Permítame recordarle qué hipótesis ya hemos logrado considerar:Hipótesis: bibliotecas rotas- Prueba 1: ejecute strace en el sistema, verifique que la excavación provoque las llamadas correctas al sistema
- Resultado: se llaman las llamadas correctas al sistema
- Prueba 2: a través de la terapia para verificar si podemos determinar los nombres sin pasar por las bibliotecas del sistema
- Resultado: podemos
- Prueba 3: ejecute rpm –V en el paquete libdns y los archivos de la biblioteca md5sum
- Resultado: el código de la biblioteca es completamente idéntico al código del sistema operativo en funcionamiento
- Prueba 4: monte la imagen del sistema raíz del usuario en la VM sin este comportamiento, ejecute chroot, vea si DNS funciona
- Resultado: DNS funciona correctamente
Conclusión basada en pruebas: el problema no está en las bibliotecasHipótesis: hay un error en la configuración de DNS- Prueba 1: verifique tcpdump y vea si los paquetes DNS se envían y devuelven correctamente después de ejecutar dig
- Resultado: los paquetes se transmiten correctamente
- Prueba 2: vuelva a verificar en el servidor
/etc/nsswitch.confy/etc/resolv.conf - Resultado: todo es correcto
Sobre la base de la conclusión de la prueba: el problema no es la hipótesis de configuración de DNS: el núcleo está dañado- Prueba: instale un nuevo núcleo, verifique la firma, reinicie
- Resultado: comportamiento similar
Conclusión basada en pruebas: el núcleo no está dañadoHipótesis: comportamiento incorrecto de la red del usuario (o la interfaz de red del hipervisor)- Prueba 1: verifique la configuración del firewall
- Resultado: el cortafuegos pasa paquetes DNS tanto en el host como en GCP
- Prueba 2: intercepte el tráfico y realice un seguimiento de la corrección de la transferencia y la devolución de consultas DNS
- Resultado: tcpdump acusa recibo de los paquetes devueltos por el host
Conclusión basada en pruebas: el problema no está en la redHipótesis: el servidor de metadatos no funciona- Prueba 1: verifique los registros del servidor de metadatos en busca de anomalías
- Resultado: no hay anomalías en los registros
- Prueba 2: omita el servidor de metadatos a través de
dig @8.8.8.8 - Resultado: se viola el permiso incluso sin usar un servidor de metadatos
Conclusión basada en pruebas: el problema no está en el servidor de metadatos. En pocaspalabras: ¡probamos todos los subsistemas excepto la configuración de tiempo de ejecución!Zambullirse en la configuración del tiempo de ejecución del kernel
Para configurar el tiempo de ejecución del kernel, puede usar las opciones de línea de comandos (grub) o la interfaz sysctl. Miré /etc/sysctl.confy pensé solo, encontré algunas configuraciones personalizadas. Sintiendo como si me hubiera agarrado a algo, descarté todas las configuraciones que no son de red o que no son TCP, quedando de la configuración de la montaña net.core. Luego me dirigí al lugar donde la VM tiene permisos de host y comencé a aplicar una tras otra, una tras otra con una VM rota, hasta que llegué al criminal:net.core.rmem_default = 2147483647
¡Aquí está, una configuración de ruptura de DNS! Encontré un instrumento de crimen. Pero ¿por qué sucede esto? Todavía necesitaba un motivo.La configuración del tamaño base del búfer de paquetes DNS se realiza a través de net.core.rmem_default. Un valor típico varía en algún lugar dentro de 200 KB, sin embargo, si su servidor recibe muchos paquetes DNS, puede aumentar el tamaño del búfer. Si el búfer está lleno en el momento en que llega un nuevo paquete, por ejemplo, debido a que la aplicación no lo procesa lo suficientemente rápido, entonces comenzará a perder paquetes. Nuestro cliente aumentó correctamente el tamaño del búfer porque temía la pérdida de datos, porque utilizó la aplicación para recopilar métricas a través de paquetes DNS. El valor que estableció fue el máximo posible: 2 31 -1 (si establece 2 31 , el núcleo devolverá “ARGUMENTO NO VÁLIDO”).De repente, me di cuenta de por qué nmap y scapy funcionaban correctamente: ¡usaban sockets sin procesar! Los sockets sin procesar son diferentes de los sockets normales: funcionan sin pasar por iptables, ¡y no están almacenados en búfer!Pero, ¿por qué "un búfer demasiado grande" está causando problemas? Obviamente no funciona según lo previsto.En este punto, podría reproducir el problema en múltiples núcleos y múltiples distribuciones. El problema ya se manifestó en el núcleo 3.x y ahora también se manifestó en el núcleo 5.x.De hecho, al iniciosysctl -w net.core.rmem_default=$((2**31-1))
DNS ha dejado de funcionar.Comencé a buscar valores de trabajo a través de un algoritmo de búsqueda binaria simple y descubrí que el sistema funciona con 2147481343, sin embargo, este número era un conjunto de números sin sentido para mí. Invité al cliente a probar este número, y él respondió que el sistema funcionaba con google.com, pero aún así dio un error con otros dominios, así que continué mi investigación.Instalé Dropwatch , una herramienta que debería haberse usado antes: muestra exactamente dónde llega el paquete en el núcleo. La función era culpable udp_queue_rcv_skb. Descargué las fuentes del kernel y agregué varias funciones printk para rastrear dónde se encuentra específicamente el paquete. Encontré rápidamente la condición correctaif, y por un momento simplemente lo miró fijamente, porque fue entonces cuando todo finalmente se unió en una imagen completa: 2 31 -1, un número sin sentido, un dominio inactivo ... Era un código en __udp_enqueue_schedule_skb:if (rmem > (size + sk->sk_rcvbuf))
goto uncharge_drop;
Nota:rmem tiene tipo intsize es del tipo u16 (int. de 16 bits sin signo) y almacena el tamaño del paquetesk->sk_rcybuf es de tipo int y almacena el tamaño del búfer, que por definición es igual al valor en net.core.rmem_default
Al sk_rcvbufacercarse a 2 31 , la suma del tamaño del paquete puede conducir a un desbordamiento de enteros . Y dado que es un int, su valor se vuelve negativo, por lo que la condición se vuelve verdadera cuando debería ser falsa (se puede encontrar más sobre esto por referencia ).El error se corrige de manera trivial: enviando a unsigned int. Apliqué el parche y reinicié el sistema, después de lo cual el DNS comenzó a funcionar nuevamente.Sabor de la victoria
Envié mis hallazgos al cliente y envié el parche del kernel LKML . Estoy satisfecho: cada pieza del rompecabezas se unió en un solo conjunto, puedo explicar con precisión por qué observamos lo que observamos y, lo más importante, ¡pudimos encontrar una solución al problema trabajando juntos!Vale la pena reconocer que el caso resultó ser raro y, afortunadamente, rara vez recibimos llamadas tan complejas de parte de los usuarios.
