Como ya dije en la última parte , al desarrollar un proyecto de IoT, los protocolos para interactuar con los dispositivos son bastante inestables, y las posibilidades de perder el contacto con los dispositivos de prueba después de actualizar el firmware eran bastante grandes. Varios equipos participaron en el desarrollo, y había un requisito estricto: no perder la capacidad de probar la capa empresarial de la aplicación, incluso si la actualización de los dispositivos interrumpe todo el flujo de trabajo con sensores. Para que los analistas de negocios prueben sus hipótesis en datos más o menos similares a la realidad, creamos un modelo de simulación del dispositivo. Por lo tanto, si el dispositivo se descompuso debido a un nuevo firmware y los datos debían recibirse con urgencia, lanzamos un modelo de simulación en lugar de un dispositivo real en la red, que, según el formato anterior, condujo los datos y produjo el resultado.Además, la ventaja del modelo era que la empresa nunca compraría un gran lote de dispositivos solo para probar una hipótesis. Por ejemplo, el equipo de análisis de negocios decidió que predecir el tiempo de llenado del contenedor debería funcionar de manera diferente. Y para probar su hipótesis, nadie correrá a comprar 10,000 sensores.
Para que los analistas de negocios prueben sus hipótesis en datos más o menos similares a la realidad, creamos un modelo de simulación del dispositivo. Por lo tanto, si el dispositivo se descompuso debido a un nuevo firmware y los datos debían recibirse con urgencia, lanzamos un modelo de simulación en lugar de un dispositivo real en la red, que, según el formato anterior, condujo los datos y produjo el resultado.Además, la ventaja del modelo era que la empresa nunca compraría un gran lote de dispositivos solo para probar una hipótesis. Por ejemplo, el equipo de análisis de negocios decidió que predecir el tiempo de llenado del contenedor debería funcionar de manera diferente. Y para probar su hipótesis, nadie correrá a comprar 10,000 sensores.Desarrollo de un modelo de simulación.
El modelo de simulación en sí era el siguiente: una máquina de estado normal describe el estado y el comportamiento del bote de basura. Primero, inicializamos la máquina de estado con el estado `VACÍO (nivel = 0)` y podemos realizar algunas acciones en ella, es decir, tirar basura al contenedor. Ahora necesitamos determinar si el contenedor permanece vacío `(nivel? MAX_LEVEL)` o está lleno` (nivel> = MAX_LEVEL) `. Si es el segundo, el estado cambia a `FULL`.Alguien puede descargar la basura de un contenedor lleno, o el conserje ha venido a limpiar su desorden, y debemos decidir a qué estado cambiar. El estado `CHOICE` es responsable de elegir una acción, en la terminología de una máquina de estados, algo similar a un bloque if.Se puede quemar otro contenedor, y luego el estado de la máquina de estado cambia a 'FUEGO'. Además, el contenedor puede caerse y su condición se convierte en 'FALL' (en el informe que hablé sobre las razones inesperadas que pueden causar las gotas del contenedor). Pero hay otro estado `PERDIDO`, que es válido desde cualquier otro estado: se establece cuando se pierde la conexión.Tal máquina de estado describe casi todo el comportamiento del contenedor y el sensor en él. Pero esto no es suficiente para hacer un modelo de simulación, porque sabemos de los posibles estados y transiciones a partir de ellos, pero no sabemos cuál es la probabilidad de estos eventos y cuándo ocurrirán.De hecho, resultó que la probabilidad de eventos dependía de la hora del día, porque:
una máquina de estado normal describe el estado y el comportamiento del bote de basura. Primero, inicializamos la máquina de estado con el estado `VACÍO (nivel = 0)` y podemos realizar algunas acciones en ella, es decir, tirar basura al contenedor. Ahora necesitamos determinar si el contenedor permanece vacío `(nivel? MAX_LEVEL)` o está lleno` (nivel> = MAX_LEVEL) `. Si es el segundo, el estado cambia a `FULL`.Alguien puede descargar la basura de un contenedor lleno, o el conserje ha venido a limpiar su desorden, y debemos decidir a qué estado cambiar. El estado `CHOICE` es responsable de elegir una acción, en la terminología de una máquina de estados, algo similar a un bloque if.Se puede quemar otro contenedor, y luego el estado de la máquina de estado cambia a 'FUEGO'. Además, el contenedor puede caerse y su condición se convierte en 'FALL' (en el informe que hablé sobre las razones inesperadas que pueden causar las gotas del contenedor). Pero hay otro estado `PERDIDO`, que es válido desde cualquier otro estado: se establece cuando se pierde la conexión.Tal máquina de estado describe casi todo el comportamiento del contenedor y el sensor en él. Pero esto no es suficiente para hacer un modelo de simulación, porque sabemos de los posibles estados y transiciones a partir de ellos, pero no sabemos cuál es la probabilidad de estos eventos y cuándo ocurrirán.De hecho, resultó que la probabilidad de eventos dependía de la hora del día, porque:- los transportistas no trabajan de noche;
- la gente tira más basura a ciertas horas (en la mañana antes del trabajo y en la noche).
Por lo tanto, hicimos posible que el equipo de análisis empresarial personalizara el comportamiento de simulación. Fue posible establecer la probabilidad de un evento en un momento determinado del día.Prueba de esfuerzo simple e intuitiva
La imitación en sí misma tiene muchas ventajas, y una de ellas es la prueba de carga barata. Es barato porque la imitación es, de hecho, un hilo separado que inicia la máquina de estado, le aplica eventos y los eventos mismos se envían al servidor real.Por lo tanto, la simulación para el backend no es diferente del sensor real. Y si necesitamos ejecutar 1000 sensores, ejecutar 1000 hilos y trabajar. Además, la simulación se escala perfectamente.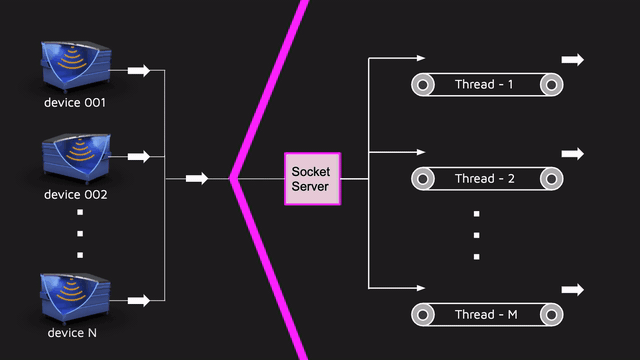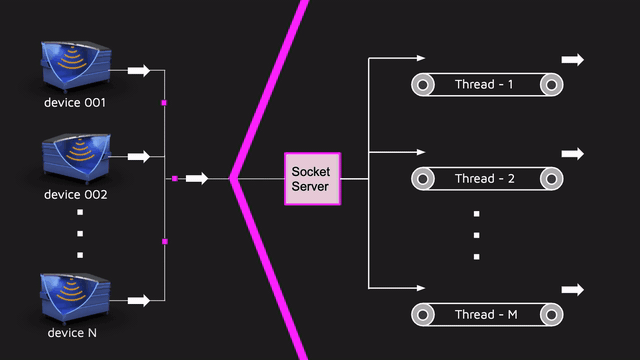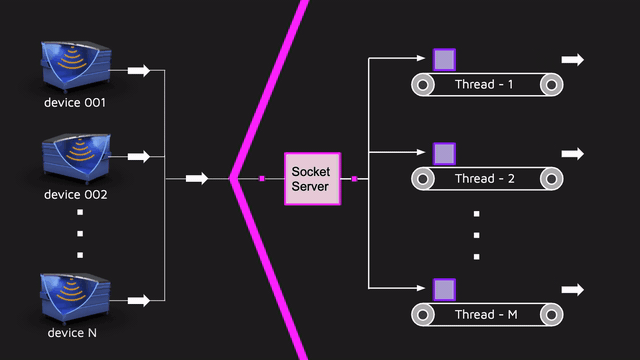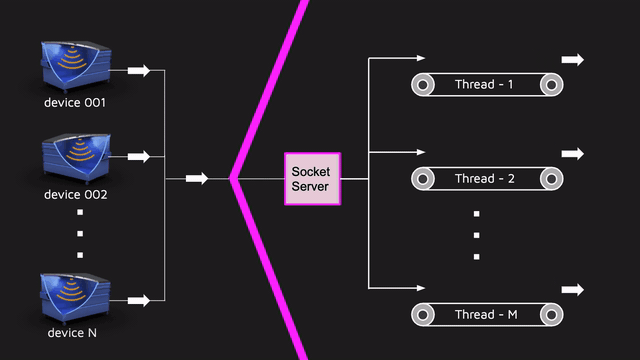 Por un lado, es bastante grosero probar la carga, pero por otro lado, la simulación permitió conducir una gran cantidad de datos cerca de la realidad para todo el proyecto. Y no se olvide de los desarrolladores chinos dotados que ignoraron los protocolos estándar como MQTT y cortaron su protocolo en la parte superior de los sockets. Por lo tanto, tuvimos que hacer nuestra propia implementación de un servidor que acepta datos en sockets bajo este protocolo propietario.Dicho servidor tenía que ser multiproceso, ya que hay muchos sensores de entrada. y esta parte también debe probarse por separado mediante pruebas de rendimiento. Puede tomar JMeter (escribir un script de prueba típico), JMH / JCStress (probar partes aisladas y hacer un punto de referencia más delgado) o algo más propio. Cuando toma una decisión en una situación similar, le aconsejo que escuche a profesionales, por ejemplo, Alexei Shipilev. En JPoint 2017, habló muy fríamente sobre cómo comparar diferentes cosas y sobre lo que debe pensar al hacer pruebas de rendimiento.Elegimos la opción de hacer algo por nuestra cuenta, ya que el proyecto tenía un enfoque atípico para el control de calidad: no contamos con un equipo de prueba por separado, y el equipo de back-end probó la funcionalidad. Es decir, la persona que escribió el servidor de socket tuvo que cubrir el código con unidades ordinarias, pruebas de integración y rendimiento.Teníamos una pequeña herramienta que nos permitía describir rápidamente el escenario de carga y ejecutarlo en la cantidad correcta de subprocesos paralelos:
Por un lado, es bastante grosero probar la carga, pero por otro lado, la simulación permitió conducir una gran cantidad de datos cerca de la realidad para todo el proyecto. Y no se olvide de los desarrolladores chinos dotados que ignoraron los protocolos estándar como MQTT y cortaron su protocolo en la parte superior de los sockets. Por lo tanto, tuvimos que hacer nuestra propia implementación de un servidor que acepta datos en sockets bajo este protocolo propietario.Dicho servidor tenía que ser multiproceso, ya que hay muchos sensores de entrada. y esta parte también debe probarse por separado mediante pruebas de rendimiento. Puede tomar JMeter (escribir un script de prueba típico), JMH / JCStress (probar partes aisladas y hacer un punto de referencia más delgado) o algo más propio. Cuando toma una decisión en una situación similar, le aconsejo que escuche a profesionales, por ejemplo, Alexei Shipilev. En JPoint 2017, habló muy fríamente sobre cómo comparar diferentes cosas y sobre lo que debe pensar al hacer pruebas de rendimiento.Elegimos la opción de hacer algo por nuestra cuenta, ya que el proyecto tenía un enfoque atípico para el control de calidad: no contamos con un equipo de prueba por separado, y el equipo de back-end probó la funcionalidad. Es decir, la persona que escribió el servidor de socket tuvo que cubrir el código con unidades ordinarias, pruebas de integración y rendimiento.Teníamos una pequeña herramienta que nos permitía describir rápidamente el escenario de carga y ejecutarlo en la cantidad correcta de subprocesos paralelos:StressTestRunner.test()
.mode(ExecutionMode.EXECUTOR_MODE)
.threads(THREADS_COUNT)
.iterations(MESSAGES_COUNT)
.timeout(5, TimeUnit.SECONDS)
.run(() -> sensor.send(MESSAGE));
Awaitility.await()
.atMost(5, TimeUnit.SECONDS)
.untilAsserted(() ->
verifyReceived(MESSAGES_COUNT)
);
Decimos cuántos hilos necesita ejecutar, cuántos mensajes enviar, cuánto tiempo debería tomar y enviar datos al socket en cada hilo. Solo queda esperar a que nuestro servidor procese correctamente todos estos datos. Solo se han lanzado unas pocas líneas de código que pueden ser escritas por cualquier desarrollador de back-end.Emulación de problemas de red.
Con la ayuda de la imitación, pudimos simular trabajos de baja calidad y específicos con sockets. Las tarjetas SIM GSM en los sensores no tienen direcciones IP "blancas", y podríamos recibir datos de diferentes IP 50 veces al día. Y a menudo sucedió que se abrió la conexión, comenzamos a transferir datos, luego la dirección IP cambia y el servidor abre una nueva conexión sin cerrar la anterior. Si no tomáramos esto en cuenta, en un par de días nos quedaríamos sin puertos libres en el servidor.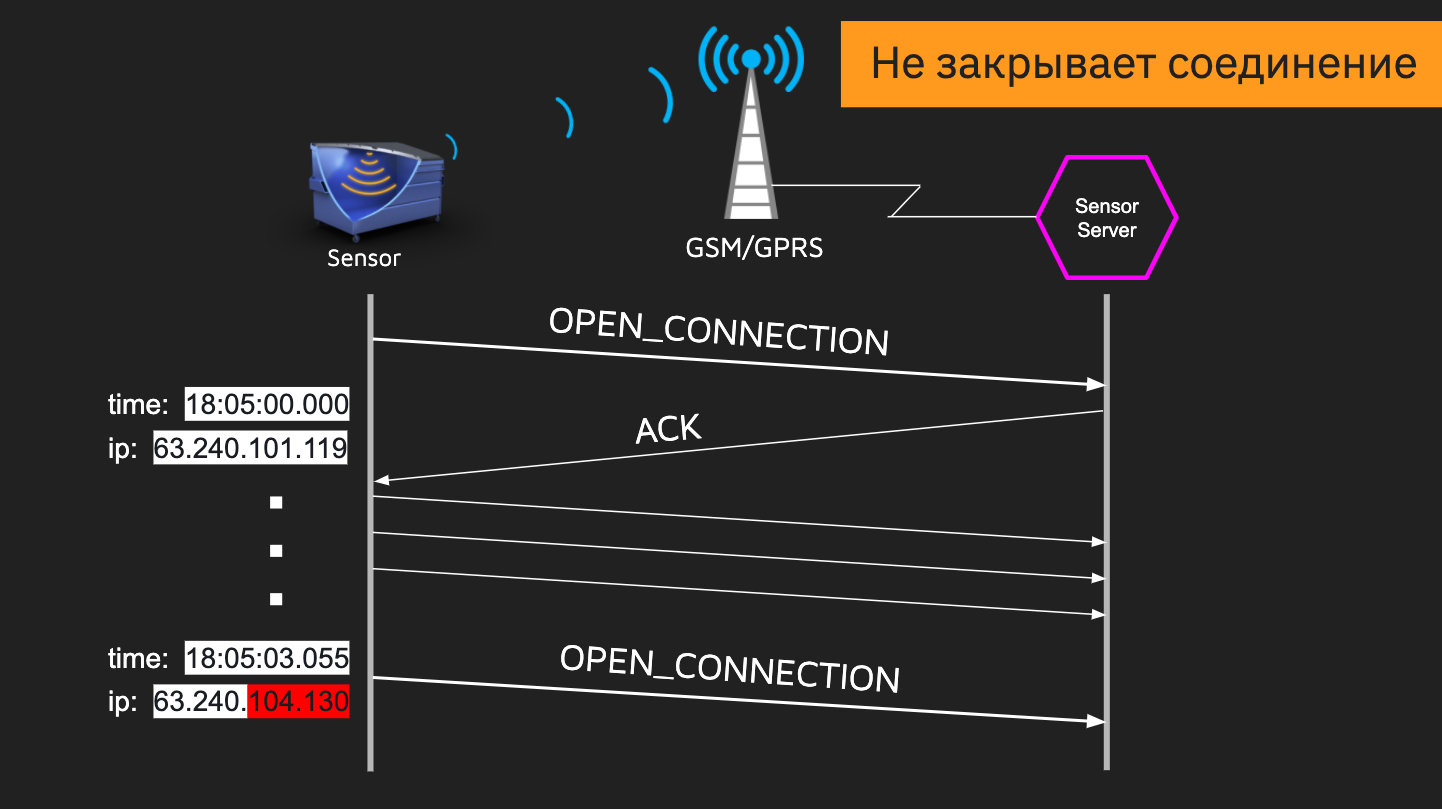 También hubo un problema con diferentes sensores de velocidad. Un dispositivo lento puede abrir una conexión y congelarse por un tiempo, mientras que un dispositivo rápido enviará algo. Y todo esto necesita ser procesado correctamente. En imitación, simular una situación similar es fácil usando pausas.
También hubo un problema con diferentes sensores de velocidad. Un dispositivo lento puede abrir una conexión y congelarse por un tiempo, mientras que un dispositivo rápido enviará algo. Y todo esto necesita ser procesado correctamente. En imitación, simular una situación similar es fácil usando pausas. Esto es solo una parte de los escenarios que se pueden incorporar al modelo.
Esto es solo una parte de los escenarios que se pueden incorporar al modelo.recomendaciones
Me parece que es precisamente la posibilidad de simulación lo que distingue fuertemente a IoT de otros proyectos. Simular el comportamiento del dispositivo es más fácil que el comportamiento humano. En la entrada, obtenemos valores deterministas que se correlacionan bien con nuestro modelo, y no con acciones humanas aleatorias. Debido a que el comportamiento de los dispositivos es lógicamente más fácil de describir que el comportamiento de las personas, y probar el sistema se vuelve más fácil.Analizamos bastantes aspectos diferentes del desarrollo en IoT. Si omitió las dos partes anteriores de este artículo, puede encontrarlas aquí:IoT donde no esperó (Parte 1) - El área temática y los problemas deIoT donde no esperó (Parte 2) - Arquitectura de la aplicación y prueba de IoT de cosas específicasGithub con las herramientas de prueba en cuestión.
Si omitió las dos partes anteriores de este artículo, puede encontrarlas aquí:IoT donde no esperó (Parte 1) - El área temática y los problemas deIoT donde no esperó (Parte 2) - Arquitectura de la aplicación y prueba de IoT de cosas específicasGithub con las herramientas de prueba en cuestión.. , Heisenbug , IoT. , ! JPoint, . Heisenbug JPoint 6 . !