Continuación de la primera parte del artículo "IoT donde no esperó. Desarrollo y pruebas (parte 1) " no se hizo esperar. Esta vez le diré cuál era la arquitectura del proyecto y qué tipo de rastrillo pisamos cuando comenzamos a probar nuestra solución.Descargo de responsabilidad: ni un solo cubo de basura fue golpeado con fuerza.
Arquitectura del proyecto
Tenemos un proyecto típico de microservicio. La capa de microservicios del "nivel inferior" recibe datos de dispositivos y sensores, los almacena en Kafka, después de lo cual los microservicios orientados a los negocios pueden trabajar con los datos recibidos de Kafka para mostrar el estado actual de los dispositivos, crear análisis y ajustar sus modelos.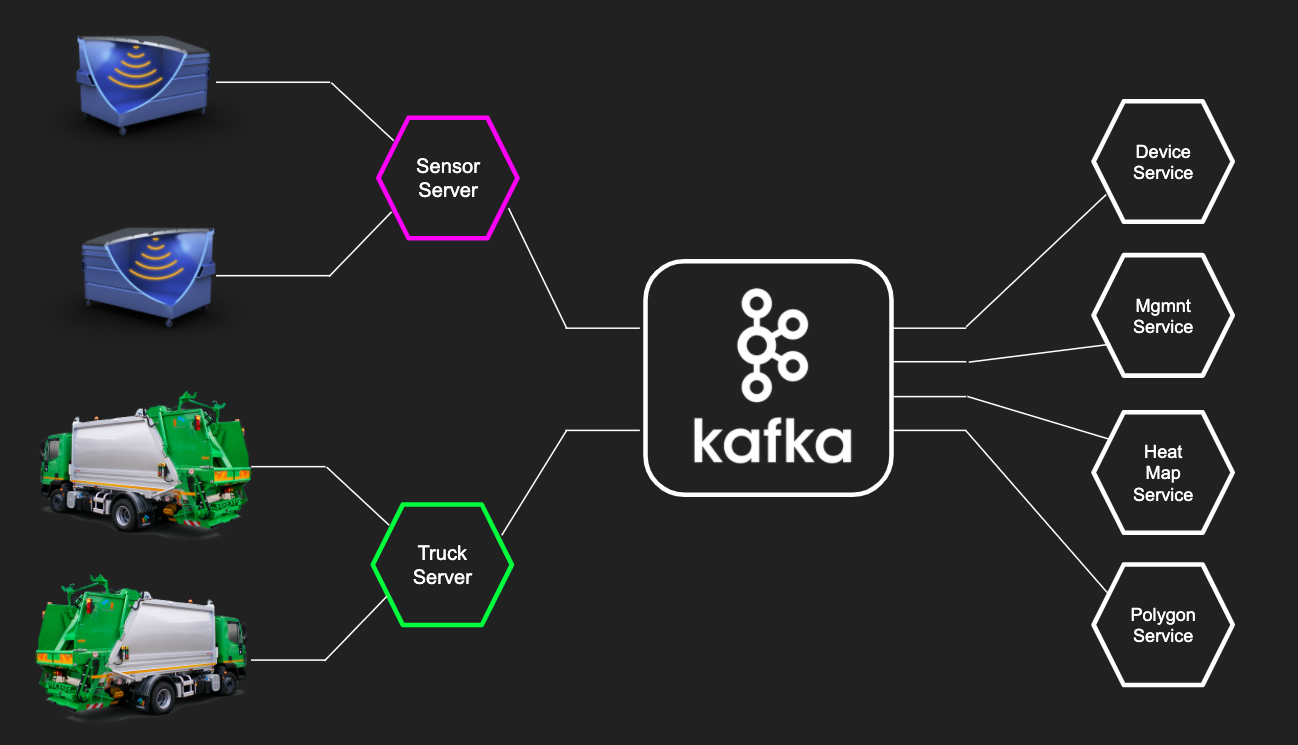 Kafka en el proyecto IoT fue genial. En comparación con otros sistemas como RabbitMQ, Kafka tiene varias ventajas:
Kafka en el proyecto IoT fue genial. En comparación con otros sistemas como RabbitMQ, Kafka tiene varias ventajas:- Trabajar con flujos : los datos sin procesar de los sensores se pueden procesar para obtener un flujo. Y con las transmisiones, puede configurar de manera flexible lo que desea filtrar en ellas, y es fácil hacer transmisiones (crear nuevas transmisiones de datos)
- : Kafka , , , . - , - , . , Kafka , . , , , .
Backend
Primero, echemos un vistazo al backend que nos es familiar, toda la capa empresarial de la aplicación está construida en la misma pila Java y Spring. Para probar aplicaciones de microservicios en un entorno real, utilizamos la biblioteca de contenedores de prueba. Le permite implementar fácilmente enlaces externos (Kafka, PostgreSQL, MongoDB, etc.) en Docker.Primero, levantamos el contenedor requerido en Docker, iniciamos la aplicación y en la instancia real ya estamos ejecutando datos de prueba.Sobre exactamente cómo hacemos esto, hablé en detalle en el Heisenbug 2019 Piter en el informe "Microservice Wars: JUnit Episodio 5 - TestContainers Strikes Back":Veamos un pequeño ejemplo de cómo se veía. El servicio de nivel inferior toma datos de los dispositivos y los arroja a Kafka. Y el servicio Heat Map de la parte comercial toma datos de kafka y crea un mapa de calor. Probemos la recepción de datos con el servicio Heat Map (a través de Kafka)
Probemos la recepción de datos con el servicio Heat Map (a través de Kafka)@KafkaTestContainer
@SpringBootTest
class KafkaIntegrationTest {
@Autowired
private KafkaTemplate kafkaTemplate;
@Test
void sendTest() {
kafkaTemplate.send(TOPIC_NAME, MEASSAGE_BODY)
}
}
Estamos escribiendo una prueba de integración SpringBoot regular, sin embargo, difiere en el estilo basado en anotaciones de la configuración del entorno de prueba. Se @KafkaTestContainernecesita una anotación para criar a Kafka. Para usarlo, debe conectar la biblioteca:spring-test-kafkaCuando se inicia la aplicación, Spring comienza y el contenedor Kafka comienza en Docker. Luego, en la prueba, la usamos kafkaTemplate, la inyectamos en el caso de prueba y enviamos los datos a Kafka para probar la lógica de procesar nuevos datos del tema.Todo esto sucede en una instancia normal de Kafka, sin opciones integradas, sino solo la versión que gira en producción. El servicio Heat Map utiliza MongoDB como almacenamiento, y la prueba para MongoDB es similar:
El servicio Heat Map utiliza MongoDB como almacenamiento, y la prueba para MongoDB es similar:@MongoDbDataTest
class SensorDataRecordServiceTest {
@Autowired
private SensorDataRecordRepository repository;
@Test
@MongoDataSet(value ="sensor_data.json")
void findSingle() {
var log = repository.findAllByDeviceId("001");
assertThat(log).hasSize(1);
...
}
}
La anotación @MongoDbDataTestlanza MongoDB en Docker de manera similar a Kafka. Después de que se haya lanzado la aplicación, podemos usar el repositorio para trabajar con MongoDB.Para usar esta funcionalidad en sus pruebas, todo lo que necesita es conectar la biblioteca:spring-test-mongoPor cierto, hay muchas otras utilidades allí, por ejemplo, puede cargar la base de datos en la base de datos a través de la anotación antes de ejecutar la prueba, @MongoDataSetcomo en el ejemplo anterior, o usando la anotación, @ExpectedMongoDataSetverifique que después de completar el caso de prueba en la base de datos, haya aparecido el conjunto de datos exactos que esperamos.Te contaré más sobre cómo trabajar con datos de prueba en el Heisenbug 2020 Piter , que se realizará en línea del 15 al 18 de junio.
Probar cosas específicas de IoT
Si la parte comercial es un backend típico, trabajar con datos de dispositivos contenía muchos rastrillos y detalles relacionados con el hardware.Tienes un dispositivo y necesitas emparejarlo. Para esto necesitarás documentación. Es bueno cuando tienes una pieza de hierro y muelles. Sin embargo, todo comenzó de una manera diferente: solo había documentación y el dispositivo todavía estaba en camino. Filmamos una pequeña aplicación, que en teoría debería haber funcionado, pero tan pronto como llegaron los dispositivos reales, nuestras expectativas se enfrentaron a la realidad.Pensamos que la entrada sería un formato binario, y el dispositivo comenzó a arrojarnos algún archivo XML. Y en una forma tan difícil, nació la primera regla para el proyecto IoT:¡Nunca creas en la documentación!
En principio, los datos recibidos del dispositivo eran más o menos claros: Timeesta es la marca de tiempo, DevEUIel identificador del dispositivo LrrLATy LrrLONlas coordenadas. Pero que es eso
Pero que es eso payload_hex? Vemos 8 dígitos, ¿qué puede haber en ellos? ¿Es la distancia a la basura, el voltaje del sensor, el nivel de señal, el ángulo de inclinación, la temperatura o todos juntos? En algún momento, pensamos que los fabricantes chinos de estos dispositivos conocían algún tipo de archivo de Feng Shui y pudieron empaquetar todo lo que era posible en 8 dígitos. Pero si mira arriba, puede ver que el tiempo está escrito en una línea regular y contiene 3 veces más bits, es decir, bytes obviamente nadie guardó. Como resultado, resultó que específicamente en este firmware, la mitad de los sensores en el dispositivo simplemente están apagados, y debe esperar un nuevo firmware.Mientras esperaban, hicimos un banco de pruebas en la oficina, que, de hecho, era una caja de cartón normal. Adjuntamos el dispositivo a su cubierta y arrojamos cualquier material de oficina a la caja. También necesitábamos una copia de prueba del automóvil del transportista, y su papel fue desempeñado por la máquina de uno de los desarrolladores del proyecto.Ahora vimos en el mapa dónde estaban las cajas de cartón, y sabíamos a dónde viajaba el desarrollador (spoiler: trabajo-hogar, y nadie canceló el bar los viernes por la noche). Sin embargo, el sistema con bancos de prueba no duró mucho, porque existen grandes diferencias con los contenedores reales. Por ejemplo, si hablamos del acelerómetro, giramos la caja de lado a lado y recibimos lecturas del sensor, y todo parecía funcionar. Pero en realidad hay algunas limitaciones.
Sin embargo, el sistema con bancos de prueba no duró mucho, porque existen grandes diferencias con los contenedores reales. Por ejemplo, si hablamos del acelerómetro, giramos la caja de lado a lado y recibimos lecturas del sensor, y todo parecía funcionar. Pero en realidad hay algunas limitaciones. En las primeras versiones del dispositivo, el ángulo no se midió en valores absolutos, sino en valores relativos. Y cuando la caja se inclinó más que el delta fijado en el firmware, el sensor comenzó a funcionar incorrectamente o incluso no pudo arreglar el giro.
En las primeras versiones del dispositivo, el ángulo no se midió en valores absolutos, sino en valores relativos. Y cuando la caja se inclinó más que el delta fijado en el firmware, el sensor comenzó a funcionar incorrectamente o incluso no pudo arreglar el giro. Por supuesto, todos estos errores fueron corregidos en el proceso, pero al principio las diferencias entre la caja y el contenedor trajeron muchos problemas. Y perforamos el tanque desde todos los lados, mientras decidíamos cómo colocar el sensor en el contenedor, de modo que al levantar el tanque con el auto del transportista, registramos con precisión que la basura estaba descargada.Además del problema con el ángulo de inclinación, al principio no tomamos en cuenta cuál será la basura real en el contenedor. Y si arrojamos poliestireno y almohadas en esa caja, entonces, en realidad, la gente pone todo en un recipiente, incluso cemento y arena. Y como resultado, una vez que el sensor mostró que el contenedor estaba vacío, aunque en realidad estaba lleno. Al final resultó que, durante la reparación, alguien arrojó un material frío que absorbe el sonido, que amortiguó las señales del sensor.En este punto, decidimos acordar con el propietario del centro de negocios donde se encuentra la oficina para instalar sensores en sus contenedores de basura. Equipamos el sitio frente a la oficina, y desde ese momento la vida y la vida cotidiana de los desarrolladores del proyecto cambiaron drásticamente. Por lo general, al comienzo de la jornada laboral, desea tomar un café, leer las noticias y aquí tiene toda la cinta llena de basura, literalmente:
Por supuesto, todos estos errores fueron corregidos en el proceso, pero al principio las diferencias entre la caja y el contenedor trajeron muchos problemas. Y perforamos el tanque desde todos los lados, mientras decidíamos cómo colocar el sensor en el contenedor, de modo que al levantar el tanque con el auto del transportista, registramos con precisión que la basura estaba descargada.Además del problema con el ángulo de inclinación, al principio no tomamos en cuenta cuál será la basura real en el contenedor. Y si arrojamos poliestireno y almohadas en esa caja, entonces, en realidad, la gente pone todo en un recipiente, incluso cemento y arena. Y como resultado, una vez que el sensor mostró que el contenedor estaba vacío, aunque en realidad estaba lleno. Al final resultó que, durante la reparación, alguien arrojó un material frío que absorbe el sonido, que amortiguó las señales del sensor.En este punto, decidimos acordar con el propietario del centro de negocios donde se encuentra la oficina para instalar sensores en sus contenedores de basura. Equipamos el sitio frente a la oficina, y desde ese momento la vida y la vida cotidiana de los desarrolladores del proyecto cambiaron drásticamente. Por lo general, al comienzo de la jornada laboral, desea tomar un café, leer las noticias y aquí tiene toda la cinta llena de basura, literalmente: Al probar el sensor de temperatura, como en el caso del acelerómetro, la realidad presentaba nuevos escenarios. El valor umbral para la temperatura es bastante difícil de elegir, por lo que sabemos a tiempo que el sensor está encendido y no le decimos adiós. Por ejemplo, en verano, los contenedores se calientan mucho bajo el sol, y establecer un umbral de temperatura demasiado bajo está lleno de notificaciones constantes del sensor. Y si el dispositivo realmente se quema, y alguien comienza a extinguirlo, entonces debe prepararse para llenar el tanque con agua hasta la parte superior, entonces alguien lo dejará caer y se apagará en el piso. En este escenario, el sensor obviamente no sobrevivirá.
Al probar el sensor de temperatura, como en el caso del acelerómetro, la realidad presentaba nuevos escenarios. El valor umbral para la temperatura es bastante difícil de elegir, por lo que sabemos a tiempo que el sensor está encendido y no le decimos adiós. Por ejemplo, en verano, los contenedores se calientan mucho bajo el sol, y establecer un umbral de temperatura demasiado bajo está lleno de notificaciones constantes del sensor. Y si el dispositivo realmente se quema, y alguien comienza a extinguirlo, entonces debe prepararse para llenar el tanque con agua hasta la parte superior, entonces alguien lo dejará caer y se apagará en el piso. En este escenario, el sensor obviamente no sobrevivirá.
Por lo tanto, la segunda regla: lea la primera regla. Es decir, nunca confíes en la documentación.
¿Qué se puede hacer? Por ejemplo, haga ingeniería inversa: nos sentamos con la consola, recopilamos datos, giramos el sensor, colocamos algo delante, tratamos de identificar patrones. Para que pueda aislar la distancia, el estado del contenedor y la suma de verificación. Sin embargo, algunos de los datos fueron difíciles de interpretar, porque nuestros fabricantes de dispositivos chinos aparentemente adoran las bicicletas. Y para empacar un número de coma flotante en formato binario para interpretar el ángulo de inclinación, decidieron tomar dos bytes y dividir entre 35. Y en toda esta historia, nos ayudó mucho que la capa inferior de servicios que trabaja con dispositivos estaba aislada de la parte superior, y todos los datos fueron vertidos a través de kafka, cuyos contratos fueron acordados y asegurados.Esto ayudó mucho en términos de desarrollo, porque si el nivel inferior se rompió, entonces vimos silenciosamente los servicios comerciales, porque el contrato está rígidamente fijado en ellos. Por lo tanto, esta segunda regla para desarrollar proyectos de IoT es aislar servicios y usar contratos.
Y en toda esta historia, nos ayudó mucho que la capa inferior de servicios que trabaja con dispositivos estaba aislada de la parte superior, y todos los datos fueron vertidos a través de kafka, cuyos contratos fueron acordados y asegurados.Esto ayudó mucho en términos de desarrollo, porque si el nivel inferior se rompió, entonces vimos silenciosamente los servicios comerciales, porque el contrato está rígidamente fijado en ellos. Por lo tanto, esta segunda regla para desarrollar proyectos de IoT es aislar servicios y usar contratos.El informe fue aún mucho más interesante: simulación, pruebas de carga y, en general, le recomendaría que vea este informe.
En la tercera parte hablaré sobre un modelo de simulación, ¡estad atentos!