Hola a todos, mi nombre es Fedor Indukaev, trabajo como analista en Yandex.Routing. Hoy quiero contarles sobre la tarea de visualizar conjuntos que se cruzan y sobre el paquete Python de código abierto que creé para resolverlo. En el proceso, aprenderemos cómo difieren los diagramas de Venn y Euler, nos familiarizaremos con el servicio de distribución de pedidos y tocaremos tangencialmente un campo de la ciencia como la bioinformática. Pasaremos de lo simple a lo más complejo. ¡Vamos!¿De qué se trata y por qué se necesita?
Casi todos los que se dedicaron al análisis exploratorio de datos tuvieron que buscar una respuesta a preguntas de este tipo al menos una vez:- Hay un conjunto de datos con varias variables binarias independientes. ¿Cuáles de ellos a menudo se encuentran juntos?
- Hay varias tablas con objetos de la misma naturaleza que tienen ID. ¿Cómo se relacionan los conjuntos de ID de diferentes tablas: o cada tabla tiene su propia ID, o la misma en todas las tablas, o los conjuntos difieren, pero solo ligeramente?
- Hay varias especies ¿Qué organismos tienen conjuntos similares de genes o proteínas?
- ¿Cómo trazar como un gráfico circular si las categorías se superponen? (Es cierto, esto no se está convirtiendo en un problema para todos: vea los porcentajes en la figura a continuación).
Todas estas preguntas pueden reducirse a la misma redacción. Suena así: se dan algunos conjuntos finitos, posiblemente intersectados entre sí, y necesitamos evaluar su posición relativa, es decir, entender cómo se intersecan exactamente.Nos centraremos en visualizaciones y herramientas de software para ayudar a resolver este problema.diagramas de Venn
Tales dibujos con dos o tres círculos, creo, son familiares para todos y no requieren explicación:Una característica del diagrama de Venn es que es estático. Las figuras en él son iguales y están ubicadas simétricamente. La figura muestra todas las intersecciones posibles, incluso si la mayoría de ellas están realmente vacías. Dichos diagramas son adecuados para ilustrar conceptos o conjuntos abstractos cuyas dimensiones exactas son desconocidas o sin importancia. La información básica aquí no está contenida en el cronograma, sino en las firmas.
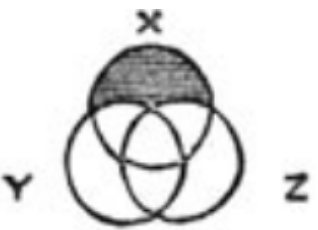 Así los concibió John Venn, un matemático y filósofo inglés. En su artículo de 1880.propuso diagramas para mostrar gráficamente proposiciones lógicas. Por ejemplo, la declaración "cualquier X es Y o Z" da un diagrama a la derecha (ilustración tomada del artículo original). El área que no satisface la declaración está sombreada con negro: aquellos X que no son Y ni Z. El mensaje principal del artículo es que los dibujos estáticos sin variar la forma y la disposición de las figuras son más adecuados para fines lógicos que los diagramas dinámicos de Euler, que se discuten iré abajoEstá claro que en el análisis de datos, el alcance de los diagramas de Venn es limitado. Proporcionan solo información cualitativa, pero no cuantitativa, y no reflejan ni el tamaño ni el vacío de las intersecciones. Si esto no lo detiene, tiene a su disposición el paquete venn , que construye dichos diagramas paraconjuntos. Para cada hay una o dos imágenes típicas, y solo las firmas serán diferentes:Si queremos algo que dependa más dinámicamente de los datos, debe prestar atención a otro enfoque: los diagramas de Euler.
Así los concibió John Venn, un matemático y filósofo inglés. En su artículo de 1880.propuso diagramas para mostrar gráficamente proposiciones lógicas. Por ejemplo, la declaración "cualquier X es Y o Z" da un diagrama a la derecha (ilustración tomada del artículo original). El área que no satisface la declaración está sombreada con negro: aquellos X que no son Y ni Z. El mensaje principal del artículo es que los dibujos estáticos sin variar la forma y la disposición de las figuras son más adecuados para fines lógicos que los diagramas dinámicos de Euler, que se discuten iré abajoEstá claro que en el análisis de datos, el alcance de los diagramas de Venn es limitado. Proporcionan solo información cualitativa, pero no cuantitativa, y no reflejan ni el tamaño ni el vacío de las intersecciones. Si esto no lo detiene, tiene a su disposición el paquete venn , que construye dichos diagramas paraconjuntos. Para cada hay una o dos imágenes típicas, y solo las firmas serán diferentes:Si queremos algo que dependa más dinámicamente de los datos, debe prestar atención a otro enfoque: los diagramas de Euler.Gráficos de Euler
A diferencia de los diagramas de Venn, la forma y la posición de las figuras en el plano aquí se eligen para mostrar la relación de conjuntos o conceptos. Si alguna intersección está vacía, las figuras tampoco se superponen siempre que sea posible, como en la figura sobre plantas y animales.Tenga en cuenta que el dibujo sobre la pregunta en la conferencia es diferente de los otros dos. Es importante no solo la posición de las figuras, sino también el tamaño de las intersecciones: todo el humor está encerrado en ellas.Esta idea puede ser utilizada para nuestra tarea. Tome dos o tres conjuntos y dibuje círculos con áreas proporcionales al tamaño de estos conjuntos. Y luego trataremos de organizar los círculos en el plano para que las áreas de superposición también sean proporcionales al tamaño de las intersecciones.Esto es exactamente lo que hace el paquete (a pesar de su nombre)matplotlib-venn :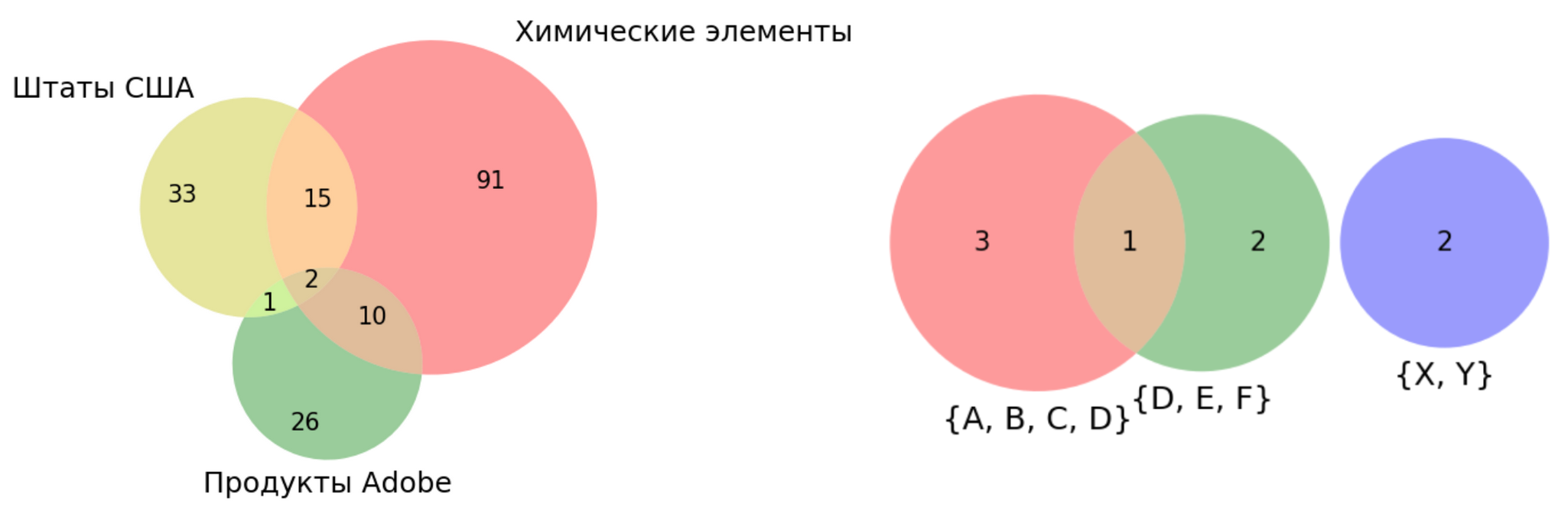 es fácil dibujar dos conjuntos con proporciones exactas. Pero ya a las tres, el método puede fallar. Supongamos, por ejemplo, que uno de los tres conjuntos sea exactamente la intersección de los otros dos:La imagen no se ve bien, apareció un área extraña con el número 0. Pero no hay nada de lo que sorprenderse, porque la intersección de dos círculos no puede representarse como un círculo.Y aquí hay un ejemplo aún más deprimente: dos conjuntos y su diferencia simétrica (unión menos intersección):Resultó ser algo completamente extraño: ¡preste atención a cuántos ceros hay!El primer ejemplo aún se puede guardar si tomamos rectángulos en lugar de círculos (la intersección de los rectángulos también es un rectángulo), mientras que el segundo requiere al menos formas no convexas. Bueno, más de tres conjuntos, este paquete no es compatible en principio.No conozco otras herramientas públicas para Python que desarrollen el enfoque de Euler-Venn, y la historia de mis propios experimentos irá más allá. Pero antes de continuar, haré una pequeña digresión para explicar por qué incluso asumí la tarea de visualizar conjuntos.
es fácil dibujar dos conjuntos con proporciones exactas. Pero ya a las tres, el método puede fallar. Supongamos, por ejemplo, que uno de los tres conjuntos sea exactamente la intersección de los otros dos:La imagen no se ve bien, apareció un área extraña con el número 0. Pero no hay nada de lo que sorprenderse, porque la intersección de dos círculos no puede representarse como un círculo.Y aquí hay un ejemplo aún más deprimente: dos conjuntos y su diferencia simétrica (unión menos intersección):Resultó ser algo completamente extraño: ¡preste atención a cuántos ceros hay!El primer ejemplo aún se puede guardar si tomamos rectángulos en lugar de círculos (la intersección de los rectángulos también es un rectángulo), mientras que el segundo requiere al menos formas no convexas. Bueno, más de tres conjuntos, este paquete no es compatible en principio.No conozco otras herramientas públicas para Python que desarrollen el enfoque de Euler-Venn, y la historia de mis propios experimentos irá más allá. Pero antes de continuar, haré una pequeña digresión para explicar por qué incluso asumí la tarea de visualizar conjuntos.Algunas palabras sobre la API para construir rutas óptimas
Como dije, nuestro departamento hace el enrutamiento Yandex. Uno de nuestros servicios ayuda a las tiendas en línea, los servicios de entrega y cualquier empresa cuyo negocio incluye logística para construir rutas óptimas para el transporte.Los clientes interactúan con el servicio enviando solicitudes de API. Cada solicitud contiene una lista de pedidos (puntos de entrega) con coordenadas, intervalos de entrega, etc., así como una lista de máquinas que necesitan entregar pedidos. Nuestro algoritmo digiere todos estos datos y produce rutas óptimas teniendo en cuenta los atascos, la capacidad del automóvil y mucho más.Tenemos cientos, no millones de clientes, como los populares servicios Yandex B2C. Por lo tanto, la felicidad de cada cliente es especialmente importante para nosotros, además, es posible prestarle más atención y profundizar en sus tareas. Para esto, en particular, es útil contar con herramientas que lo ayuden a comprender qué solicitudes nos envía el cliente.Daré un ejemplo. Supongamos que, en un día, se recibieron 24 solicitudes de Romashka. Esto puede significar que:- Trabajan en todo el país y han construido 24 conjuntos de rutas para 24 almacenes.
- Solo hay un almacén, pero el cliente recibe constantemente nuevos pedidos. Para tenerlos en cuenta, debe actualizar las rutas cada hora.
- Las solicitudes del cliente se forman con un error debido al cual no pudo obtener una buena solución para una sola tarea 24 veces seguidas.
A priori, no está completamente claro qué sucedió realmente. Pero si podemos comparar rápidamente 24 conjuntos de ID de pedidos, la situación se aclarará de inmediato. Si no se cruzan en absoluto, este es el primer caso (24 almacenes). Si los conjuntos fluyen de uno a otro, el segundo (actualización programada de rutas). Bueno, 24 conjuntos casi idénticos son una posible señal de que el cliente necesita ayuda.Simplifica la tarea: de círculos a rayas
Durante algún tiempo utilicé el paquete matplotlib-venn, pero la restricción de "dos juegos y medio", por supuesto, fue frustrante. Al reflexionar sobre diferentes enfoques del problema, decidí tratar de pasar de círculos y generalmente primitivas bidimensionales a rayas horizontales unidimensionales. Las intersecciones se pueden representar verticalmente superpuestas de esta manera:El ojo percibe las dimensiones lineales mejor que los cuadrados, la trigonometría compleja no es necesaria para la construcción y el espaciado de los conjuntos a lo largo del eje Y hace que el gráfico esté menos sobrecargado. Además, nuestro primer ejemplo fallido (dos conjuntos y su intersección como el tercero) mejora por sí mismo:El problema con la diferencia simétrica todavía está aquí. Pero lo trataremos como Alejandro Magno con el nudo gordiano: si es necesario, cortemos uno de los conjuntos en dos partes:El conjunto rojo se representa en dos franjas en lugar de una, pero eso no tiene nada de malo. Ambos están a la misma altura y tienen el mismo color, por lo que su unidad es visualmente bien leída.Es fácil verificar que de esta manera, con la observancia exacta de las proporciones, se puedan representar tres conjuntos. Por lo tanto, el problema paraigual a 2 o 3 puede considerarse resuelto.Otra ventaja de este enfoque es que es fácil de aplicar a cualquier cantidad de conjuntos, lo que haremos muy pronto. Todo lo que se necesita es resolver no uno, sino un número arbitrario de saltos de línea. Pero primero, un poco de combinatoria simple.Un poco de aritmética
Miremos el diagrama de Venn con tres círculos y calculemos cuántas áreas se dividen entre sí:Cada área está determinada por si se encuentra dentro o fuera de cada uno de los tres círculos, pero el área externa es superflua. Total que obtenemos. Otras ubicaciones de los tres círculos pueden dar menos áreas hasta 1, cuando todos los círculos coinciden.Transfiriendo este argumento de círculos a conjuntos, obtenemos que cualquier conjuntos se rompen entre sí no más de tales partes elementales. Es importante que cada una de estas partes esté totalmente incluida o no incluida en ninguno de estos conjuntos. En nuestros nuevos diagramas, las columnas son partes tan elementales.Más juegos!
Entonces, queremos generalizar estos esquemas al caso :por establece obtenemos una cuadrícula con líneas y columnas, como acabamos de calcular. Queda por recorrer cada línea y completar las celdas correspondientes a las partes elementales incluidas en este conjunto.Para ilustrar, tome un ejemplo de modelo de cinco conjuntos:programming_languages = {'python', 'r', 'c', 'c++', 'java', 'julia'}
geographic_places = {'java', 'buffalo', 'turkey', 'moscow'}
letters = {'a', 'r', 'c', 'i', 'z'}
human_names = {'robin', 'julia', 'alice', 'bob', 'conrad'}
animals = {'python', 'buffalo', 'turkey', 'cat', 'dog', 'robin'}
Actuando como se describió anteriormente, obtenemos la siguiente figura:Se lee mal: hay demasiados espacios en las líneas, todos los conjuntos están cortados en col. Pero como no nos gustan los descansos, ¿por qué no establecer directamente la tarea de minimizarlos? Después de todo, el orden de las columnas es insignificante, nada nos impide reorganizarlas como queremos. Llegamos a este problema: encuentre una permutación de las columnas de una matriz dada de ceros y unas con un número mínimo de espacios entre unidades en filas.Como me dijeron más tarde, esta es prácticamente la tarea de un vendedor ambulante en la métrica de Hamming ; es NP-complete . Si hay pocas columnas (digamos, no más de 12), puede encontrar la permutación necesaria mediante una búsqueda exhaustiva, de lo contrario, debe recurrir a ciertas heurísticas.Aplicamos un algoritmo codicioso simple. Llamemos a la similitud de dos columnas el número de posiciones en las que coinciden los valores en estas columnas. Toma las dos columnas más similares, únelas. A continuación, desarrollaremos con entusiasmo la secuencia en ambos lados de este par. Entre las columnas restantes, encontramos la que más se parece a una de las dos, adjúntela, y así sucesivamente con el resto de las columnas.Aquí están las cifras antes y después de aplicar el algoritmo:Se ha vuelto mucho mejor. Fue en esta etapa que sentí que algo útil estaba saliendo. Después de experimentar, noté que el algoritmo tiende a mantenerse en los mínimos locales. Fue posible tratar esto bien con una aleatorización simple: cambiamos ligeramente la similitud de las columnas, ejecutamos el algoritmo, repetimos 1000 veces, elegimos la mejor de 1000 soluciones.El resultado ya es una herramienta bastante funcional, pero puede agregarle información más útil. Hice dos gráficos adicionales: los tamaños de los conjuntos originales se muestran a la derecha, y el superior para cada intersección muestra en cuántos de nuestros conjuntos se encuentra. De hecho, esto no es más que la suma de nuestra matriz binaria en filas (a la derecha) y en columnas (en la parte superior):También agregué la opción de ordenar los conjuntos (es decir, filas) de acuerdo con el mismo principio que las columnas: minimizando el número de saltos. Como resultado, se agrupan conjuntos similares:Aplicación en el trabajo
Naturalmente, antes que nada, comencé a usar la nueva herramienta para la tarea para la cual fue creada: examinar las solicitudes de los clientes para nuestra API. Los resultados me complacieron. Así, por ejemplo, el día de trabajo de uno de los clientes parecía. Cada línea es una solicitud a la API (muchas ID de los pedidos incluidos en ella), y la firma en el medio es el momento de enviar las solicitudes:Todo el día a la vista. A las 10:49 un cliente logístico con un intervalo de 23 segundos envió dos solicitudes idénticas con 129 pedidos. De 11:25 a 15:53 hubo tres solicitudes con un conjunto diferente de 152 pedidos. A las 16:43 llegó una tercera solicitud única con 114 pedidos. Para resolver esta solicitud, el logístico luego aplicó cuatro ediciones manuales (esto se puede hacer a través de nuestra interfaz de usuario).Y así es como se ve un día ideal: todas las tareas independientes se resolvieron una vez, no se requirieron correcciones ni selección de parámetros:Y aquí hay un ejemplo de un cliente que envía solicitudes cada 15-30 minutos para tener en cuenta los pedidos recibidos en tiempo real:Incluso en 50 series, el algoritmo reveló claramente la estructura oculta en los datos. Puede ver cómo las órdenes antiguas se eliminaron de las solicitudes y se reemplazaron por otras nuevas a medida que se ejecutaban.En una palabra, logré cerrar por completo mi necesidad de trabajo con la herramienta creada.Plátano para escala (no realmente)
Mientras estudiaba los enfoques existentes, me encontré varias veces con un dibujo de la revista Nature , que compara los genomas del plátano y otras cinco plantas:Observe cómo los tamaños de las regiones se relacionan con 13 y 149 elementos (indicados por flechas): el segundo es varias veces más pequeño. Por lo tanto, no se trata de ninguna proporcionalidad.Por supuesto, quería probar suerte con esos datos, pero el resultado no me gustó:El gráfico se ve desordenado. La razón es que, en primer lugar, casi todas las intersecciones (62 de 63 posibles) no están vacías, y en segundo lugar, sus tamaños difieren en tres órdenes de magnitud. Como resultado, las anotaciones numéricas se llenan mucho.Para que mi herramienta sea conveniente para dichos datos, agregué varios parámetros. Uno le permite alinear parcialmente los anchos de columna, el otro oculta las anotaciones si el ancho de la columna es menor que un valor especificado.Esta opción se lee bastante bien, pero por eso tuve que sacrificar la proporcionalidad exacta del tamaño.Al final resultó que, prestando atención al campo de la bioinformática, tenía razón. Envié una publicación sobre mi herramienta a Reddit en r / visualización , r / datascience y r / bioinformática , fue en este último que fue mejor recibido, las críticas fueron realmente entusiastas.Conversión de producto
Al final, me di cuenta de que resultó ser una buena herramienta que puede ser útil para muchos. Por lo tanto, la idea nació para convertirlo en un paquete completo de código abierto. Por supuesto, el consentimiento de los líderes era necesario, pero a los muchachos no solo no les importó, sino que también me apoyaron, por lo que muchas gracias a ellos.Trabajando principalmente los fines de semana, comencé a llevar gradualmente el código a la comercialización, escribir pruebas y lidiar con el sistema de paquetes en Python. Este es mi primer proyecto de este tipo, por lo que me llevó varios meses.Encontrar un buen nombre también fue una tarea difícil, y lo manejé mal. Nombre seleccionado (super venn) no se puede llamar exitoso, porque toda la sal de los diagramas de Venn está en su naturaleza estática, pero, por el contrario, traté de mostrar con precisión las dimensiones reales. Pero cuando me di cuenta de esto, el proyecto ya estaba publicado y ya era demasiado tarde para cambiar el nombre.Análogos
Por supuesto, no fui el primero en utilizar este enfoque para la visualización de conjuntos: la idea, en general, radica en la superficie. Hay dos aplicaciones web similares en acceso abierto: RainBio y Linear Diagram Generator , el segundo usa exactamente el mismo principio que el mío. (Los autores también escribieron un artículo en 40 páginas , que comparó experimentalmente lo que se percibe mejor: líneas horizontales o verticales, delgadas o gruesas, etc. Incluso me pareció que el artículo era primordial para ellos, y la herramienta en sí misma era solo una adición a él .)Para comparar estas dos aplicaciones con mi paquete, nuevamente usamos el ejemplo con palabras. Puede decidir por sí mismo qué opción es más legible e informativa.RainbioGenerador de diagrama linealsupervennOtros enfoques
Uno no puede dejar de mencionar el proyecto UpSet , que existe como una aplicación web y paquetes para R y Python. El principio básico se puede entender observando la visualización de los datos del genoma del banano. El gráfico se recorta a la derecha, solo se muestran 30 intersecciones de 62:Curiosamente, si usa supervenn para ordenar las columnas por ancho y hacer que las columnas sean iguales usando la opción de alineación de ancho, obtendrá casi lo mismo, aunque esto no se nota de inmediato. Todo lo que falta son líneas verticales con tamaños de intersección, en lugar de ellas solo hay números en la parte inferior del gráfico:Mientras escribía este texto, intenté usar la versión Python de UpSet, pero descubrí que el paquete no se ha actualizado desde 2016, la documentación no describe el formato de entrada de ninguna manera, y el caso de prueba falla con un error. La versión web está funcionando, tiene muchas funciones auxiliares útiles, pero trabajar con ella es bastante difícil debido a la forma complicada de ingresar datos.Finalmente, una visión general interesante de las técnicas de visualización de conjuntos está disponible en línea . No todos se implementan como herramientas de software. Aquí hay algunas fotos para llamar su atención:Estaba particularmente interesado en el método de Conjuntos de burbujas (fila inferior), que le permite mostrar pequeños conjuntos encima de una disposición dada de elementos en un plano. Esto puede ser conveniente, por ejemplo, cuando los elementos están unidos al eje de tiempo (a) o al mapa (b). Hasta ahora, este método se ha implementado solo en Java y JavaScript (los enlaces están en la página de autores), y sería genial si alguien se comprometiera a portarlo a Python.Envié cartas con una breve descripción del proyecto a los autores de UpSet y la revisión y recibí buenas críticas. Dos de ellos incluso prometieron incluir a supervenn en sus conferencias sobre visualización de sets.Conclusión
Si desea utilizar el paquete, está disponible en GitHub y en PyPI: pip install supervenn . Estaré agradecido por cualquier comentario sobre el código y el uso del paquete, por ideas y críticas. Me complacerá especialmente leer recomendaciones sobre cómo mejorar el algoritmo de permutación de columna para grandes, y consejos sobre cómo escribir pruebas para las funciones de gráficos.¡Gracias por la atención!Referencias
1. John Venn. Sobre la representación esquemática y mecánica de proposiciones y razonamientos . The London, Edinburgh and Dublin Philosophical Magazine, julio de 1880.2. J.-B. Lamy y R. Tsopra. RainBio: visualización proporcional de grandes conjuntos en biología . IEEE Transactions on Visualization and Computer Graphics, doi: 10.1109 / TVCG.2019.2921544.3. Peter Rodgers, Gem Stapleton y Peter Chapman. Visualización de conjuntos con diagramas lineales . ACM Transactions on Computer Human Interaction 22 (6) págs. 27: 1-27: 39 de septiembre de 2015. doi: 10.1145 / 2810012.4. Alexander Lex, Nils Gehlenborg, Hendrik Strobelt, Romain Vuillemot, Hanspeter PfisterUpSet: visualización de conjuntos de intersección. IEEE Transactions on Visualization and Computer Graphics (InfoVis'14), 2014.5. Bilal Alsallakh, Luana Micallef, Wolfgang Aigner, Helwig Hauser, Silvia Miksch y Peter Rodgers. El estado del arte de la visualización de conjuntos . Foro de gráficos por computadora. Volumen 00 (2015), número 0 pp. 1–27 10.1111 / cgf.12722.6. Christopher Collins, Gerald Penn y Sheelagh Carpendale. Conjuntos de burbujas: revelando relaciones de conjuntos con isocontornos sobre visualizaciones existentes . IEEE Trans. sobre Visualización y Gráficos de Computadora (Proceso de la Conf. IEEE sobre Visualización de Información), vol. 15, iss. 6, pp. 1009-1016, 2009.