¡Hola a todos! Como ya sabe, en SE estamos comprometidos con el reconocimiento de texto (y no solo) en diferentes documentos. Hoy nos gustaría hablar sobre otro problema al reconocer texto sobre fondos complejos: sobre el reconocimiento de espacios. En general, hablaremos sobre el nombre en las tarjetas bancarias, pero primero, un ejemplo con un "fantasma" de la letra. Como puede ver, aquí, a la derecha de D, las distorsiones y el fondo se formaron bastante claros. Además, si muestra esta celda por separado de todo lo demás, la persona (o red neuronal) seguramente dirá que hay una carta.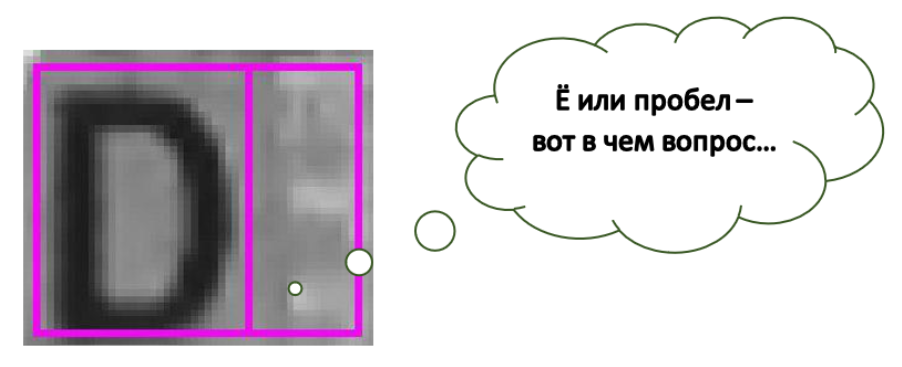 Como puede ver en la imagen, estamos trabajando en la imagen original con fondos complejos, por lo que nuestros espacios son muy diversos. Vienen en patrones, logotipos y, a veces, en texto. Por ejemplo, VISA o MAESTRO en tarjetas. Y estamos interesados en tales "espacios complejos", y no solo en rectángulos blancos. Y en nuestros sistemas consideramos precisamente cortar rectángulos de símbolos por separado [1].
Como puede ver en la imagen, estamos trabajando en la imagen original con fondos complejos, por lo que nuestros espacios son muy diversos. Vienen en patrones, logotipos y, a veces, en texto. Por ejemplo, VISA o MAESTRO en tarjetas. Y estamos interesados en tales "espacios complejos", y no solo en rectángulos blancos. Y en nuestros sistemas consideramos precisamente cortar rectángulos de símbolos por separado [1].¿Y cuál es la dificultad?
Un espacio es un símbolo sin signos especiales. En fondos complejos, como en una imagen, un espacio cortado por separado puede ser difícil de distinguir incluso para una persona.Por otro lado, en esencia, un espacio es diferente de otros personajes. Si ABIA se reconoce en el nombre en lugar de ASIA, existe la posibilidad de solucionarlo con el procesamiento posterior. Pero, si surge una IA allí, es poco probable que algo ayude.Métodos no utilizados por nosotros.
A menudo, los espacios se filtran utilizando estadísticas calculadas a partir de la imagen. Por ejemplo, consideran el valor absoluto promedio del gradiente en la imagen o la varianza de las intensidades de píxeles y dividen las imágenes en espacios y letras por el valor umbral. Sin embargo, como se puede ver en los gráficos, tales métodos no son adecuados para imágenes grises con fondos complejos. Y debido a la correlación explícita de valores, incluso una combinación de estos métodos no funcionará.La binarización favorita de todos tampoco ayudará aquí. Por ejemplo, en esta imagen:Entonces, ¿cómo se puede mejorar el reconocimiento?
Dado que una persona necesita un entorno de espacio para poder verlo, es lógico que la red muestre al menos dos personajes vecinos. No queremos aumentar la entrada de la red de reconocimiento, que, en general, funciona bien (y reconoce muchas lagunas). Entonces obtendremos otra red, más simple. La nueva red predecirá lo que está en la imagen: dos espacios, dos letras, un espacio y una letra, o una letra y un espacio. En consecuencia, dicha red se usa junto con una red de reconocimiento. La imagen muestra las arquitecturas utilizadas: a la izquierda está la arquitectura de la red de reconocimiento, a la derecha está la arquitectura de la red propuesta. La red de reconocimiento funciona en una imagen con un carácter, y la nueva funciona en una imagen de doble ancho que contiene dos caracteres adyacentes.¿Una prueba?
Para las pruebas, teníamos 4320 líneas con nombres que contenían 130,149 caracteres, de los cuales 68,246 espacios. Para empezar, tenemos dos métodos. El método básico: cortamos una cadena en caracteres y reconocemos cada carácter individualmente. Nuevo método: también cortamos una cadena de caracteres, buscamos todos los espacios con una nueva red y reconocemos los caracteres restantes como normales. La tabla muestra que la calidad del reconocimiento de los espacios, así como la calidad general, está creciendo, pero la calidad del reconocimiento de las letras está ligeramente hundida.Sin embargo, nuestra red central también reconoce espacios (aunque peor de lo que nos gustaría). Y podemos tratar de aprovechar esto. Veamos los errores de ambos métodos. Y también: en la calidad del nuevo método basado en errores básicos y viceversa.Para el método base:Para el nuevo método:De las últimas tres tablas se puede ver que para mejorar el sistema vale la pena usar una combinación equilibrada de clasificaciones de red. Al mismo tiempo, la calidad carácter por carácter es interesante, pero línea por línea es más interesante.Conclusión
Espacio: un gran problema en el camino hacia el 100% de la calidad del reconocimiento de documentos =) En el ejemplo de los espacios se ve claramente lo importante que es mirar no solo los caracteres individuales, sino también sus combinaciones. Sin embargo, no se apodere inmediatamente de artillería pesada y aprenda redes gigantes que procesan cadenas enteras. A veces, solo otra pequeña red es suficiente.Esta publicación se realizó utilizando materiales de un informe de la Conferencia Europea sobre Modelado ECMS 2015 (Bulgaria, Varna): Sheshkus, A. y Arlazarov, VL (2015). Detección de símbolo de espacio en fondo complejo utilizando contexto visual.Lista de fuentes utilizadas1. YS Chernyshova, AV Sheshkus y VV Arlazarov, “Marco CNN de dos pasos para el reconocimiento de líneas de texto en imágenes capturadas por cámara”, IEEE Access, vol. 8, pp. 32587-32600, 2020, DOI: 10.1109 / ACCESS.2020.2974051.