O la buena programación dinámica antigua sin estas de sus redes neuronales.Hace un año y medio, participé en una competencia corporativa (con fines de entretenimiento) al escribir un bot para el juego Lode Runner. Hace 20 años, resolví diligentemente todos los problemas de programación dinámica en el curso correspondiente, pero prácticamente olvidé todo y no tenía experiencia en la programación de bots de juegos. Tenía que recordar que tenía poco tiempo, experimentar sobre la marcha y pisar independientemente el rastrillo. Pero, de repente, todo salió muy bien, así que decidí sistematizar de alguna manera el material y no ahogar al lector con matan.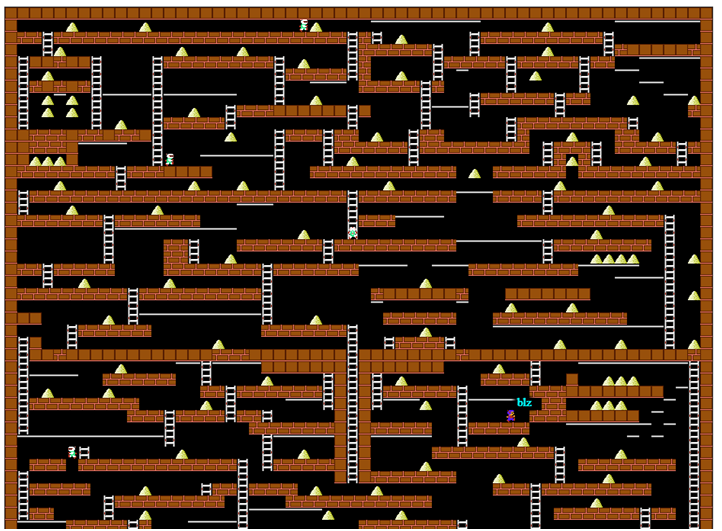 Pantalla del juego del servidor del proyecto CodenjoyPara comenzar, describiremos un poco las reglas del juego : el jugador se mueve horizontalmente a lo largo del piso o a través de tuberías, sabe subir y bajar escaleras, cae si no hay piso debajo de él. También puede cortar un agujero a la izquierda o a la derecha de sí mismo, pero no todas las superficies se pueden cortar, condicionalmente es posible un piso de "madera" y el concreto no.Los monstruos corren tras el jugador, caen en los agujeros cortados y mueren en ellos. Pero lo más importante, el jugador debe recolectar oro, por el primer oro recolectado recibe 1 punto de ganancia, por el N-ésimo recibe N puntos. Después de la muerte, el beneficio total permanece, pero por el primer oro nuevamente dan 1 punto. Esto sugiere que lo principal es mantenerse con vida el mayor tiempo posible, y recolectar oro es de alguna manera secundario.Dado que hay lugares en el mapa que el jugador no puede salir de sí mismo, se introdujo un suicidio gratuito en el juego, que al azar colocó al jugador en algún lugar, pero de hecho rompió todo el juego: el suicidio no interrumpió el crecimiento en el valor del oro encontrado. Pero no abusaremos de esta característica.Todos los ejemplos del juego se darán en una pantalla simplificada, que se utilizó en los registros del programa:
Pantalla del juego del servidor del proyecto CodenjoyPara comenzar, describiremos un poco las reglas del juego : el jugador se mueve horizontalmente a lo largo del piso o a través de tuberías, sabe subir y bajar escaleras, cae si no hay piso debajo de él. También puede cortar un agujero a la izquierda o a la derecha de sí mismo, pero no todas las superficies se pueden cortar, condicionalmente es posible un piso de "madera" y el concreto no.Los monstruos corren tras el jugador, caen en los agujeros cortados y mueren en ellos. Pero lo más importante, el jugador debe recolectar oro, por el primer oro recolectado recibe 1 punto de ganancia, por el N-ésimo recibe N puntos. Después de la muerte, el beneficio total permanece, pero por el primer oro nuevamente dan 1 punto. Esto sugiere que lo principal es mantenerse con vida el mayor tiempo posible, y recolectar oro es de alguna manera secundario.Dado que hay lugares en el mapa que el jugador no puede salir de sí mismo, se introdujo un suicidio gratuito en el juego, que al azar colocó al jugador en algún lugar, pero de hecho rompió todo el juego: el suicidio no interrumpió el crecimiento en el valor del oro encontrado. Pero no abusaremos de esta característica.Todos los ejemplos del juego se darán en una pantalla simplificada, que se utilizó en los registros del programa:
Poco de teoría
Para implementar el bot usando algún tipo de matemática, necesitamos establecer alguna función objetiva que describa los logros del bot y encontrarle acciones que lo maximicen. Por ejemplo, para recolectar oro obtenemos +100, para la muerte -100500, por lo que ninguna colección de oro matará la posible muerte.Una pregunta separada, y sobre qué determinamos exactamente la función objetivo, es decir ¿Cuál es el estado del juego? En el caso más simple, las coordenadas del jugador son suficientes, pero en el nuestro todo es mucho más complicado:- coordenadas del jugador
- Las coordenadas de todos los agujeros perforados por todos los jugadores.
- Las coordenadas de todo el oro en el mapa (o las coordenadas del oro recientemente comido)
- coordenadas de todos los otros jugadores
Se ve aterrador. Por lo tanto, simplifiquemos un poco la tarea y hasta que recordemos el oro que comemos (volveremos a esto más adelante), tampoco recordaremos las coordenadas de otros jugadores y monstruos.Por lo tanto, el estado actual del juego es:- coordenadas del jugador
- coordenadas de todos los pozos
Las acciones del jugador cambian de estado de una manera comprensible:- Los comandos de movimiento cambian una de las coordenadas correspondientes
- El equipo de excavación de pozos agrega un nuevo pozo
- La caída de un jugador sin soporte reduce la coordenada vertical
- La inacción del jugador parado en el soporte no cambia el estado
Ahora necesitamos entender cómo maximizar la función en sí. Uno de los métodos clásicos venerables para calcular el juego que N avanza es la programación dinámica. Es imposible prescindir de las fórmulas, por lo tanto, las daré de forma simplificada. Tendrás que introducir mucha notación primero.Para simplificar, mantendremos el informe de tiempo del movimiento actual, es decir El movimiento actual es t = 0.Denotamos el estado del juego durante el curso de t por.Un montón de denotará todas las acciones válidas del bot (en un estado específico, pero por simplicidad no escribiremos el índice de estado), a través de denotamos una acción específica en el curso t (omitimos el índice).condición Bajo la influencia entra en estado .Gana cuando la acción a está en estado lo denotamos como . Al calcularlo, suponemos que si comimos oro, entonces es igual a G = 100, si murieron, entonces D = -100500, de lo contrario 0.DejarEsta es la función de pago para el juego óptimo de un bot que está en estado x en el tiempo t. Entonces solo necesitamos encontrar una acción que maximice.Ahora escribimos la primera fórmula, que es muy importante y al mismo tiempo casi correcta:
O por un punto arbitrario en el tiempo
Parece bastante torpe, pero el significado es simple: la solución óptima para el movimiento actual consiste en la solución óptima para el siguiente movimiento y la ganancia en el movimiento actual. Este es el principio de optimización torcidamente formulado de Bellman. No sabemos nada sobre los valores óptimos en el paso 1, pero si los supiéramos, encontraríamos una acción que maximiza la función simplemente iterando sobre todas las acciones del bot. La belleza de las relaciones recurrentes es que podemos encontrar, aplicando el principio de optimización, expresándolo exactamente en la misma fórmula a través de . También podemos expresar fácilmente la función de pago en cualquier paso.Parece que el problema está resuelto, pero aquí nos enfrentamos al problema de que si en cada paso tuviéramos que clasificar las acciones de 6 jugadores, en el paso N de recursión tendríamos que clasificar las opciones 6 ^ N, que para N = 8 ya es un número bastante decente ~ 1.6 millones de casos Por otro lado, tenemos microprocesadores de gigahercios que no tienen nada que hacer, y parece que harán frente completamente a la tarea, y limitaremos la profundidad de búsqueda a ellos con exactamente 8 movimientos.Y así, nuestro horizonte de planificación es de 8 movimientos, pero dónde obtener los valores? Y aquí solo se nos ocurre la idea de que de alguna manera podemos analizar las perspectivas de la posición y asignarle algún valor en función de sus consideraciones más altas. Permitirdónde Esta es una función de la estrategia, en la versión más simple es solo una matriz de la que seleccionamos el valor de acuerdo con las coordenadas geométricas del bot. Podemos decir que los primeros 8 movimientos fue una táctica, y luego comienza la estrategia. De hecho, nadie nos restringe a la hora de elegir una estrategia, y nos ocuparemos de ella más tarde, pero por ahora, para no ser como un búho de una broma sobre liebres y erizos, pasaremos a la táctica.Esquema general
Y así, decidimos el algoritmo. En cada paso, resolvemos el problema de optimización, encontramos la acción óptima para el paso, lo completamos, después de lo cual el juego pasa al siguiente paso.Es necesario resolver un nuevo problema en cada paso, porque con cada curso del juego la tarea cambia un poco, aparece nuevo oro, alguien se come a alguien, los jugadores se mueven ...Pero no piense que nuestro ingenioso algoritmo puede proporcionar todo. Después de resolver el problema de optimización, definitivamente debe agregar un controlador que verifique las situaciones desagradables:- Colocar el bot en su lugar durante mucho tiempo
- Caminata continua izquierda-derecha
- Falta de ingresos por mucho tiempo
Todo esto puede requerir un cambio radical de estrategia, suicidio o alguna otra acción fuera del marco del algoritmo de optimización. La naturaleza de estas situaciones puede ser diferente. A veces, las contradicciones entre la estrategia y las tácticas conducen a la congelación de bots en un punto que parece estratégicamente importante para él, que fue descubierto por antiguos botánicos llamados Buridanov Donkey. Tus oponentes pueden congelarse y cerrar tu corto camino hacia el codiciado oro. Nos ocuparemos de todo esto más adelante.
Tus oponentes pueden congelarse y cerrar tu corto camino hacia el codiciado oro. Nos ocuparemos de todo esto más adelante.La lucha contra la procrastinación.
Considere el caso simple cuando un oro se encuentra a la derecha del bot y no hay más celdas de oro en un radio de 8. ¿Qué paso tomará el bot, guiado por nuestra fórmula? De hecho, absolutamente cualquiera. Por ejemplo, todas estas soluciones dan exactamente el mismo resultado incluso para tres movimientos:- paso a la izquierda - paso a la derecha - paso a la derecha
- paso a la derecha - inacción - inacción
- inacción - inacción - paso a la derecha
Las tres opciones dan una victoria igual a 100, el bot puede elegir la opción con inacción, en el siguiente paso resolver el mismo problema nuevamente, elegir la inacción nuevamente ... y quedarse quieto para siempre. Necesitamos modificar la fórmula para calcular las ganancias para estimular al bot a actuar lo antes posible:
multiplicamos la ganancia futura en el siguiente paso por el "coeficiente de inflación" E, que debe elegirse por debajo de 1. Podemos experimentar con seguridad con valores de 0.95 o 0.9. Pero no lo elija demasiado pequeño, por ejemplo, con un valor de E = 0.5, el oro comido en el octavo movimiento traerá solo 0.39 puntos.Y así, redescubrimos el principio de "No pospongas hasta mañana lo que puedas comer hoy".La seguridad
Recopilar oro es ciertamente bueno, pero aún debe pensar en la seguridad. Tenemos dos tareas:- Enseña al bot a cavar agujeros si el monstruo está en una posición adecuada
- Enseña al bot a huir de los monstruos
Pero no le decimos al bot qué hacer, establecemos el valor de la función de ganancias y el algoritmo de optimización elegirá los pasos apropiados. Otro problema es que no calculamos exactamente dónde puede estar un monstruo en un movimiento en particular. Por lo tanto, por simplicidad, asumimos que los monstruos están en su lugar, y simplemente no necesitamos acercarnos a ellos.Si comienzan a acercarse a nosotros, el robot comenzará a huir de ellos, porque será multado por estar demasiado cerca de ellos (una especie de autoaislamiento). Y entonces, presentamos dos reglas:- Si llegamos al monstruo a una distancia d y d <= 3, entonces se nos impone una multa de 100,500 * (4-d) / 4
- Si el monstruo se acercó lo suficiente, está en la misma línea con nosotros y hay un agujero entre nosotros, entonces obtenemos alguna ganancia P
El concepto de "se acercó al monstruo a una distancia d" lo abriremos un poco más tarde, pero por ahora, pasemos a la estrategia.Vamos alrededor de los gráficos
Matemáticamente, el problema de la elusión óptima del oro es un problema resuelto desde hace mucho tiempo de un vendedor ambulante, cuya solución no es un placer. Pero antes de resolver tales problemas, debe pensar en una pregunta simple, pero ¿cómo encuentra la distancia entre dos puntos en el juego? O en una forma un poco más útil: para un oro dado y para cualquier punto del mapa, encuentre el número mínimo de movimientos para los cuales el jugador alcanzará el punto desde el oro. Durante algún tiempo nos olvidaremos de cavar agujeros y saltar dentro de ellos, dejaremos solo movimientos naturales por 1 celda. Solo caminaremos en la dirección opuesta: desde el oro y a través del mapa.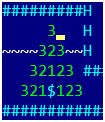 En el primer paso, seleccionamos todas las celdas desde las cuales podemos obtener oro en un solo movimiento y las asignamos a 1. En el segundo paso, seleccionamos todas las celdas de las que caemos en unas en un solo paso y las asignamos a 2. La imagen muestra el caso de 3 pasos. Ahora intentemos escribir todo formalmente, en una forma adecuada para la programación.Necesitaremos:
En el primer paso, seleccionamos todas las celdas desde las cuales podemos obtener oro en un solo movimiento y las asignamos a 1. En el segundo paso, seleccionamos todas las celdas de las que caemos en unas en un solo paso y las asignamos a 2. La imagen muestra el caso de 3 pasos. Ahora intentemos escribir todo formalmente, en una forma adecuada para la programación.Necesitaremos:- La distancia de matriz numérica bidimensional [x, y], en la que almacenaremos el resultado. Inicialmente, para las coordenadas de oro, contiene 0, para los puntos restantes -1.
- La matriz oldBorder, en la que almacenaremos los puntos desde los que nos moveremos, inicialmente tiene un punto con coordenadas doradas
- Array newBorder, en el que almacenaremos los puntos encontrados en el paso actual
- Para cada punto p de oldBorder, encontramos todos los puntos p_a desde los cuales podemos alcanzar p en un paso (más precisamente, solo tomamos todos los pasos posibles desde p en la dirección opuesta, por ejemplo, volando hacia arriba en ausencia de soporte) y la distancia [p_a] = - 1
- Colocamos cada uno de estos puntos p_a en la matriz newBorder, a la distancia [p_a] escribimos el número de iteración
- Después de completar todos los puntos:
- Cambie las matrices de oldBorder y newBorder, después de lo cual borramos newBorder
- Si oldBorder está vacío, termine el algoritmo; de lo contrario, vaya al paso 1.
Lo mismo en pseudocódigo:iter=1;
newBorder.clear();
distance.fill(-1);
distance[gold]=0;
oldBorder.push(gold);
while(oldBorder.isNotEmpty()) {
for (p: oldBorder){
for (p_a: backMove(p)) {
if (distance[p_a]==-1) {
newBorder.push(p_a);
distance[p_a]=iter;
}
}
}
Swap(newBorder, oldBorder);
newBorder.clear();
iter++;
}
A la salida del algoritmo, tendremos un mapa de distancia con el valor de la distancia desde cada punto de todo el campo del juego hasta el oro. Además, para los puntos desde los cuales el oro es inalcanzable, el valor de la distancia es -1. Los matemáticos llaman a este paseo por el campo de juego (que forma un gráfico con vértices en puntos en el campo y bordes que conectan los vértices accesibles en un solo movimiento) "caminar el gráfico en ancho". Si implementamos la recursividad, en lugar de dos conjuntos de bordes, esto se llamaría "dar la vuelta al gráfico en profundidad", pero dado que la profundidad puede ser bastante grande (varios cientos), le aconsejo que evite los algoritmos recursivos al atravesar gráficos.El algoritmo real será un poco más complicado debido a cavar un hoyo y saltar dentro de él; resulta que en 4 movimientos movemos una celda hacia los lados y dos hacia abajo (ya que nos movemos en la dirección opuesta, luego hacia arriba), pero una ligera modificación del algoritmo resuelve el problema.Complementé la imagen con números, incluso teniendo en cuenta cavar un hoyo y saltar a él: ¿Qué nos recuerda esto?
¿Qué nos recuerda esto? El olor a oro! Y nuestro bot buscará este olor, como Rocky para queso (pero al mismo tiempo no pierde el cerebro y esquiva a los monstruos, e incluso cava agujeros para ellos). Hagamos de él una estrategia codiciosa simple:
El olor a oro! Y nuestro bot buscará este olor, como Rocky para queso (pero al mismo tiempo no pierde el cerebro y esquiva a los monstruos, e incluso cava agujeros para ellos). Hagamos de él una estrategia codiciosa simple:- Para cada oro, construimos un mapa de distancia y encontramos la distancia al jugador.
- Elige el oro más cercano al jugador y toma su carta para calcular la estrategia.
- Para cada celda del mapa, denote por d su distancia al oro, luego el valor estratégico
Dónde este es un valor imaginario del oro, es deseable que se valore varias veces menos que el presente, y Este es un coeficiente de inflación <1, porque cuanto más lejos está el oro imaginario, más barato es. La relación de los coeficientes E yconstituye un problema sin resolver del milenio y deja espacio para la creatividad.No pienses que nuestro bot siempre correrá al oro más cercano. Supongamos que tenemos un oro a la izquierda a una distancia de 5 celdas y luego vacío, y a la derecha dos de oro a una distancia de 6 y 7. Como el oro real es más valioso de lo imaginado, el bot irá a la derecha.Antes de pasar a estrategias más interesantes, haremos otra mejora. En el juego, la gravedad tira al jugador hacia abajo, y solo puede subir las escaleras. Entonces, el oro que es más alto debe valorarse más. Si la altura se informa desde la línea superior hacia abajo, puede multiplicar el valor del oro (con coordenada vertical y) por. Para coeficiente El nuevo término "tasa de inflación vertical" fue acuñado, al menos no es utilizado por los economistas y refleja bien la esencia.Estrategias complicadas
Con un oro resuelto, debes hacer algo con todo el oro, y no me gustaría atraer matemáticas pesadas. Existe una solución muy elegante, simple e incorrecta (en el sentido estricto): si un oro crea un "campo" de valor a su alrededor, simplemente agreguemos todos los campos de valor de todas las celdas con oro en una matriz y utilícelos como estrategia. Sí, esta no es una solución óptima, pero varias unidades de oro en la distancia media pueden ser más valiosas que una cercana.Sin embargo, una nueva solución crea nuevos problemas: una nueva matriz de valores puede contener máximos locales, cerca de los cuales no hay oro. Debido a que nuestro bot puede entrar en ellos y no quiere salir, significa que necesitamos agregar un controlador que verifique que el bot esté en el máximo local de la estrategia y permanezca en su lugar de acuerdo con los resultados del movimiento. Y ahora tenemos una herramienta para combatir las congelaciones: cancele esta estrategia con N movimientos y regrese temporalmente a la estrategia del oro más cercano.Es bastante divertido ver cómo un bot atascado cambia su estrategia y comienza a descender continuamente, comiendo todo el oro más cercano, en los pisos inferiores del mapa el bot vuelve a sus sentidos e intenta subir. Una especie de Dr. Jekyll y Mr. Hyde.La estrategia no está de acuerdo con las tácticas.
Aquí nuestro robot llega al oro debajo del piso: ya cae en el algoritmo de optimización, queda dar 3 pasos a la derecha, cortar un agujero a la derecha y saltar hacia él, y luego la gravedad hará todo por sí mismo. Algo como esto:
ya cae en el algoritmo de optimización, queda dar 3 pasos a la derecha, cortar un agujero a la derecha y saltar hacia él, y luego la gravedad hará todo por sí mismo. Algo como esto: Pero el bot se congela en su lugar. La depuración mostró que no había ningún error: el bot decidió que la estrategia óptima era esperar un movimiento, y luego seguir la ruta especificada y tomar el oro en el último paso analizado. En el primer caso, recibe una ganancia del oro recibido y una ganancia del oro imaginario (en la última iteración analizada es solo en la celda donde estaba el oro), y en el segundo, solo del oro real (aunque un turno antes), pero la ganancia ya no hay ninguna estrategia, porque el lugar debajo del oro está podrido y no es prometedor. Bueno, en el siguiente movimiento, él decide tomarse un descanso una vez más, ya hemos resuelto esos problemas.Tuve que modificar la estrategia, ya que memorizamos todo el oro que se comió en la etapa de análisis, restando las tarjetas de valor del oro comido de la matriz total de valor estratégico, por lo tanto, la estrategia tuvo en cuenta el logro de las tácticas (fue posible calcular el valor de manera diferente, agregando matrices solo para oro entero, pero es computacionalmente más complicado, porque hay mucho más oro en el mapa del que podemos comer en 8 movimientos).Pero esto no terminó con nuestro tormento. Suponga que la matriz de valor estratégico tiene un máximo local y el bot se acercó a ella para 7 movimientos. ¿El robot irá a congelarse? No, porque para cualquier ruta en la que el bot llegue al máximo local en 8 movimientos, la victoria será la misma. Buena vieja dilación. La razón es que la ganancia estratégica no depende del momento en que nos encontramos en la celda. Lo primero que viene a la mente es multar al bot por uno simple, pero esto no ayuda de ninguna manera al caminar de izquierda a derecha sin sentido. Es necesario tratar la causa raíz: tener en cuenta la ganancia estratégica en cada giro (como la diferencia entre el valor estratégico de los estados nuevos y actuales), reduciéndolo con el tiempo en un factor.Aquellos. introduce un término adicional en la expresión para ganar:
Pero el bot se congela en su lugar. La depuración mostró que no había ningún error: el bot decidió que la estrategia óptima era esperar un movimiento, y luego seguir la ruta especificada y tomar el oro en el último paso analizado. En el primer caso, recibe una ganancia del oro recibido y una ganancia del oro imaginario (en la última iteración analizada es solo en la celda donde estaba el oro), y en el segundo, solo del oro real (aunque un turno antes), pero la ganancia ya no hay ninguna estrategia, porque el lugar debajo del oro está podrido y no es prometedor. Bueno, en el siguiente movimiento, él decide tomarse un descanso una vez más, ya hemos resuelto esos problemas.Tuve que modificar la estrategia, ya que memorizamos todo el oro que se comió en la etapa de análisis, restando las tarjetas de valor del oro comido de la matriz total de valor estratégico, por lo tanto, la estrategia tuvo en cuenta el logro de las tácticas (fue posible calcular el valor de manera diferente, agregando matrices solo para oro entero, pero es computacionalmente más complicado, porque hay mucho más oro en el mapa del que podemos comer en 8 movimientos).Pero esto no terminó con nuestro tormento. Suponga que la matriz de valor estratégico tiene un máximo local y el bot se acercó a ella para 7 movimientos. ¿El robot irá a congelarse? No, porque para cualquier ruta en la que el bot llegue al máximo local en 8 movimientos, la victoria será la misma. Buena vieja dilación. La razón es que la ganancia estratégica no depende del momento en que nos encontramos en la celda. Lo primero que viene a la mente es multar al bot por uno simple, pero esto no ayuda de ninguna manera al caminar de izquierda a derecha sin sentido. Es necesario tratar la causa raíz: tener en cuenta la ganancia estratégica en cada giro (como la diferencia entre el valor estratégico de los estados nuevos y actuales), reduciéndolo con el tiempo en un factor.Aquellos. introduce un término adicional en la expresión para ganar:
el valor de la función objetivo en este último generalmente se toma como cero: . Dado que la ganancia se deprecia con cada movimiento multiplicando por un coeficiente, esto hará que nuestro bot gane una ganancia estratégica más rápida y eliminará el problema observado.Estrategia no probada
No he probado esta estrategia en la práctica, pero parece prometedor.- Como conocemos todas las distancias entre los puntos de oro y las distancias entre el oro y el jugador, podemos encontrar la cadena de celdas de oro jugador-N (donde N es pequeño, por ejemplo 5 o 6) con la longitud más corta. Incluso la búsqueda más simple del tiempo es suficiente.
- Seleccione el primer oro en esta cadena y use su campo de valor como matriz de estrategia.
En este caso, es deseable acercar el costo del oro real y el del oro imaginario para que el bot no se precipite al sótano al oro más cercano.Mejoras finales
Después de que hayamos aprendido a "expandirnos" en el mapa, hagamos una "propagación" similar de cada monstruo para varios movimientos y busquemos todas las celdas en las que el monstruo pueda terminar, junto con el número de movimientos para los que lo hará. Esto permitirá al jugador gatear a través de la tubería sobre la cabeza del monstruo de manera completamente segura.Y el último momento: al calcular la estrategia y el valor imaginario del oro, no tomamos en cuenta la posición de los otros jugadores, simplemente los "borramos" al analizar el mapa. Resulta que los caparazones colgantes individuales pueden bloquear el acceso a regiones enteras, por lo que se agregó un controlador adicional para rastrear a los oponentes congelados y reemplazarlos con bloques de concreto durante el análisis.Características de implementación
Dado que el algoritmo principal es recursivo, debemos poder cambiar rápidamente los objetos de estado y devolverlos a sus objetos originales para una modificación posterior. Utilicé Java, un lenguaje con recolección de basura, probar millones de cambios relacionados con la creación de objetos de corta duración puede causar varias recolecciones de basura en un turno del juego, lo que puede ser fatal en términos de velocidad. Por lo tanto, uno debe ser extremadamente cuidadoso en las estructuras de datos utilizadas, utilicé solo matrices y listas. Bueno, o use el proyecto Valgala bajo su propio riesgo y riesgo :)Código fuente y servidor de juegos
El código fuente se puede encontrar aquí en el github . No juzgues estrictamente, se ha hecho mucho a toda prisa. El servidor de juegos codenjoy proporcionará la infraestructura para lanzar bots y monitorear el juego. En el momento de la creación, la revisión era relevante, se utilizó la revisión 1.0.26.Puede iniciar el servidor con la siguiente línea:call mvn -DMAVEN_OPTS=-Xmx1024m -Dmaven.test.skip=true clean jetty:run-war -Dcontext=another-context -Ploderunner
El proyecto en sí es extremadamente curioso, ofrece juegos para todos los gustos.Conclusión
Si has leído todo esto hasta el final sin una preparación preliminar y has entendido todo, entonces eres un tipo raro.