Se preparó una traducción del artículo antes del comienzo del curso "C # ASP.NET Core Developer" .
C # es un gran lenguaje , y .NET Framework también es muy bueno. La escritura fuerte en C # ayuda a reducir la cantidad de errores que puede provocar, en comparación con otros lenguajes. Además, su diseño intuitivo general también ayuda mucho, en comparación con algo como JavaScript (donde verdadero es falso ). Sin embargo, cada idioma tiene su propio rastrillo que es fácil de pisar, junto con ideas erróneas sobre el comportamiento esperado del idioma y la infraestructura. Trataré de describir algunos de estos errores en detalle.1. No entiendo la ejecución retrasada (perezosa)
Creo que los desarrolladores experimentados son conscientes de este mecanismo .NET, pero puede sorprender a colegas menos conocedores. En pocas palabras, los métodos / operadores que devuelven IEnumerable<T>yieldpara devolver cada resultado no se ejecutan en la línea de código que realmente los llama: se ejecutan cuando se accede a la colección resultante de alguna manera *. Tenga en cuenta que la mayoría de las expresiones LINQ finalmente devuelven sus resultados con rendimiento .Como ejemplo, considere la prueba de unidad atroz a continuación.[TestMethod]
[ExpectedException(typeof(ArgumentNullException))]
public void Ensure_Null_Exception_Is_Thrown()
{
var result = RepeatString5Times(null);
}
[TestMethod]
[ExpectedException(typeof(InvalidOperationException))]
public void Ensure_Invalid_Operation_Exception_Is_Thrown()
{
var result = RepeatString5Times("test");
var firstItem = result.First();
}
private IEnumerable<string> RepeatString5Times(string toRepeat)
{
if (toRepeat == null)
throw new ArgumentNullException(nameof(toRepeat));
for (int i = 0; i < 5; i++)
{
if (i == 3)
throw new InvalidOperationException("3 is a horrible number");
yield return $"{toRepeat} - {i}";
}
}
Ambas pruebas fallarán. La primera prueba fallará porque el resultado no se usa en ninguna parte, por lo que el cuerpo del método nunca se ejecutará. La segunda prueba fallará por otra razón, ligeramente más no trivial. Ahora obtenemos el primer resultado de llamar a nuestro método para garantizar que el método realmente se ejecute. Sin embargo, el mecanismo de ejecución retrasada saldrá del método tan pronto como sea posible; en este caso usamos solo el primer elemento, por lo tanto, tan pronto como pasemos la primera iteración, el método detiene su ejecución (por lo tanto, i == 3 nunca será cierto).La ejecución retrasada es en realidad un mecanismo interesante, especialmente porque facilita la cadena de consultas LINQ, recuperando datos solo cuando su consulta está lista para su uso.2. , Dictionary ,
Esto es especialmente desagradable, y estoy seguro de que en algún lugar tengo un código que se basa en esta suposición. Cuando agrega elementos a la lista List<T>Dictionary<TKey,TValue>
segundovar dict = new Dictionary<string, object>();
dict.Add("first", new object());
dict.Add("second", new object());
dict.Remove("first");
dict.Add("third", new object());
foreach (var entry in dict)
{
Console.WriteLine(entry.Key);
}
¿No me creas? Consulte aquí en línea usted mismo .3. No tenga en cuenta la seguridad del flujo
Multithreading es excelente, si se implementa correctamente, puede mejorar significativamente el rendimiento de su aplicación. Sin embargo, tan pronto como ingrese el subprocesamiento múltiple, debe tener mucho cuidado con cualquier objeto que modifique, porque puede comenzar a encontrar errores aparentemente aleatorios si no tiene el cuidado suficiente.En pocas palabras, muchas clases base en la biblioteca .NET no son seguras para subprocesos.- Esto significa que Microsoft no garantiza que pueda usar esta clase en paralelo usando múltiples hilos. Esto no sería un gran problema si pudiera encontrar de inmediato cualquier problema asociado con esto, pero la naturaleza del subprocesamiento múltiple implica que cualquier problema que surja es muy inestable e impredecible, lo más probable es que no haya dos ejecuciones que produzcan el mismo resultado.Por ejemplo, considere este bloque de código que utiliza simple, pero no apta para subprocesos, List<T>var items = new List<int>();
var tasks = new List<Task>();
for (int i = 0; i < 5; i++)
{
tasks.Add(Task.Run(() => {
for (int k = 0; k < 10000; k++)
{
items.Add(i);
}
}));
}
Task.WaitAll(tasks.ToArray());
Console.WriteLine(items.Count);
Por lo tanto, agregamos números del 0 al 4 a la lista 10,000 veces cada uno, lo que significa que la lista debería contener 50,000 elementos. ¿Debería? Bueno, hay una pequeña posibilidad de que al final lo sea, pero a continuación se muestran los resultados de 5 de mis diferentes inicios:28191
23536
44346
40007
40476
Puede verificarlo usted mismo en línea aquí .De hecho, esto se debe a que el método Add no es atómico, lo que implica que el hilo puede interrumpir el método, lo que finalmente puede cambiar el tamaño de la matriz mientras otro hilo está en proceso de agregar o agregar un elemento con el mismo índice como el otro hilo. La excepción IndexOutOfRange se me ocurrió un par de veces, probablemente porque el tamaño de la matriz cambió durante la adición. Entonces, ¿qué hacemos aquí? Podemos usar la palabra clave de bloqueo para garantizar que solo un hilo pueda agregar un elemento (Agregar) a la lista a la vez, pero esto puede afectar significativamente el rendimiento. Microsoft, siendo buena gente, ofrece algunas colecciones geniales queSon seguros para subprocesos y altamente optimizados en términos de rendimiento. Ya he publicado un artículo que describe cómo puede usarlos .4. Abuso de carga diferida (diferida) en LINQ
La carga diferida es una gran característica para LINQ to SQL y LINQ to Entities (Entity Framework), que le permite cargar filas de tablas relacionadas según sea necesario. En uno de mis otros proyectos, tengo una tabla de "Módulos" y una tabla de "Resultados" con una relación de uno a muchos (un módulo puede tener muchos resultados).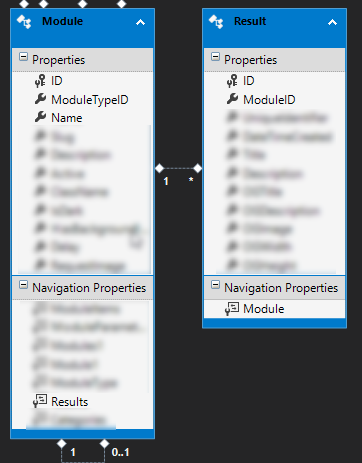 ¡Cuando quiero obtener un módulo específico, ciertamente no quiero que Entity Framework devuelva todos los Resultados que tiene la tabla Módulos! Por lo tanto, es lo suficientemente inteligente como para ejecutar una consulta para obtener resultados solo cuando lo necesito. Por lo tanto, el siguiente código ejecutará 2 consultas: una para obtener el módulo y la otra para obtener los resultados (para cada módulo),
¡Cuando quiero obtener un módulo específico, ciertamente no quiero que Entity Framework devuelva todos los Resultados que tiene la tabla Módulos! Por lo tanto, es lo suficientemente inteligente como para ejecutar una consulta para obtener resultados solo cuando lo necesito. Por lo tanto, el siguiente código ejecutará 2 consultas: una para obtener el módulo y la otra para obtener los resultados (para cada módulo),using (var db = new DBEntities())
{
var modules = db.Modules;
foreach (var module in modules)
{
var moduleType = module.Results;
}
}
Sin embargo, ¿qué pasa si tengo cientos de módulos? ¡Esto significa que se ejecutará una consulta SQL separada para recibir registros de resultados para cada módulo! Obviamente, esto presionará al servidor y ralentizará significativamente su aplicación. En Entity Framework, la respuesta es muy simple: puede especificar que incluya un conjunto específico de resultados en su consulta. Consulte el código modificado a continuación, donde solo se ejecutará una consulta SQL, que incluirá cada módulo y cada resultado para este módulo (combinado en una consulta, que Entity Framework muestra de forma inteligente en su modelo),using (var db = new DBEntities())
{
var modules = db.Modules.Include(b => b.Results);
foreach (var module in modules)
{
var moduleType = module.Results;
}
}
5. No entiendo cómo LINQ to SQL / Entity Frameworks traduce las consultas
Dado que tocamos el tema LINQ, creo que vale la pena mencionar cuán diferente se ejecutará su código si está dentro de una consulta LINQ. Explicando a un alto nivel, todo su código dentro de una consulta LINQ se traduce a SQL usando expresiones ; esto parece obvio, pero es muy, muy fácil olvidar el contexto en el que se encuentra y finalmente introducir problemas en su base de código. A continuación, he compilado una lista para describir algunos obstáculos típicos que puede encontrar.La mayoría de las llamadas a métodos no funcionarán.Entonces, imagine que tiene la siguiente consulta para separar el nombre de todos los módulos con dos puntos y capturar la segunda parte.var modules = from m in db.Modules
select m.Name.Split(':')[1];
Obtendrá una excepción en la mayoría de los proveedores de LINQ: no hay traducción SQL para el método Split, algunos métodos pueden ser compatibles, por ejemplo, agregar días a una fecha, pero todo depende de su proveedor.Aquellos que funcionan pueden producir resultados inesperados ...Tome la expresión LINQ a continuación (no tengo idea de por qué haría esto en la práctica, pero imagínese que esta es una solicitud razonable).int modules = db.Modules.Sum(a => a.ID);
Si tiene alguna fila en la tabla del módulo, le dará la suma de los identificadores. Suena bien! ¿Pero qué pasa si lo ejecutas usando LINQ to Objects? Podemos hacer esto convirtiendo la colección de módulos en una lista antes de ejecutar nuestro método Sum.int modules = db.Modules.ToList().Sum(a => a.ID);
Choque, horror: ¡hará exactamente lo mismo! Sin embargo, ¿qué sucede si no tiene filas en la tabla del módulo? LINQ to Objects devuelve 0, y la versión Entity Framework / LINQ to SQL arroja una InvalidOperationException , que dice que no puede convertir "int?" en "int" ... tal. Esto se debe a que cuando ejecuta SUM en SQL para un conjunto vacío, se devuelve NULL en lugar de 0; por lo tanto, en su lugar, intenta devolver un int anulable. Aquí hay algunos consejos para solucionar esto si encuentra un problema .Sepa cuándo solo necesita usar el viejo y bueno SQL.Si está ejecutando una solicitud extremadamente compleja, entonces su solicitud traducida puede terminar pareciendo algo escupido, comido una y otra vez. Desafortunadamente, no tengo ejemplos para demostrar, pero a juzgar por la opinión predominante, realmente me gusta usar vistas anidadas, lo que hace que el mantenimiento del código sea una pesadilla.Además, si encuentra cuellos de botella en el rendimiento, será difícil solucionarlos porque no tiene control directo sobre el SQL generado. ¡Hazlo en SQL o delegalo al administrador de la base de datos, si tú o tu empresa tienen uno!6. redondeo incorrecto
Ahora sobre algo un poco más simple que los párrafos anteriores, pero siempre lo olvidé y terminé con errores desagradables (y, si está relacionado con las finanzas, un enojado director de aleta / gen)..NET Framework incluye un excelente método estático en la clase Math llamado Round , que toma un valor numérico y lo redondea al lugar decimal especificado. Funciona perfecto la mayor parte del tiempo, pero ¿qué hacer cuando intentas redondear 2,25 al primer decimal? Supongo que probablemente espere que se redondee a 2.3, eso es a lo que todos estamos acostumbrados, ¿verdad? Bueno, en la práctica, resulta que .NET usa redondeo bancarioque redondea el ejemplo dado a 2.2! Esto se debe al hecho de que los banqueros se redondean al número par más cercano si el número está en el "punto medio". Afortunadamente, esto se puede anular fácilmente en el método Math.Round.Math.Round(2.25,1, MidpointRounding.AwayFromZero)
7. Clase horrible 'DBNull'
Esto puede causar recuerdos desagradables para algunos: ORM nos oculta esta inmundicia, pero si profundiza en el mundo de ADO.NET desnudo (SqlDataReader y similares) se encontrará con DBNull.Value.No estoy 100% seguro de la razón por la cualLos valores NULL de la base de datos se procesan de la siguiente manera (¡comente a continuación si lo sabe!), Pero Microsoft decidió presentarlos con un tipo especial DBNull (con un valor de campo estático). Puedo dar una de las ventajas de esto: no obtendrá ninguna NullReferenceException desagradable cuando acceda a un campo de base de datos que sea NULL. Sin embargo, no solo debe admitir la forma secundaria de verificar los valores NULL (que es fácil de olvidar, lo que puede conducir a errores graves), sino que pierde cualquiera de las excelentes características de C # que lo ayudan a trabajar con nulo. ¿Qué podría ser tan simple comoreader.GetString(0) ?? "NULL";
lo que eventualmente se convierte ...reader.GetString(0) != DBNull.Value ? reader.GetString(0) : "NULL";
UghNota
Estos son solo algunos de los "rastrillos" no triviales que he encontrado en .NET. Si sabe más, me gustaría saber de usted a continuación.
ASP.NET Core: