En sistemas ERP complejos, muchas entidades tienen una naturaleza jerárquica , cuando los objetos homogéneos se alinean en un árbol de relación ancestro-descendiente : esta es la estructura organizativa de la empresa (todas estas ramas, departamentos y grupos de trabajo), y el catálogo de productos, áreas de trabajo y geografía. puntos de venta, ... De hecho, no existe una sola esfera de automatización empresarial en la que al menos alguna jerarquía no sea el resultado. Pero incluso si no trabaja "para negocios", puede encontrar fácilmente relaciones jerárquicas. A decir verdad, incluso su árbol genealógico o esquema de piso de las instalaciones en el centro comercial es la misma estructura. Hay muchas formas de almacenar dicho árbol en un DBMS, pero hoy nos centraremos en una sola opción:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid);
Y mientras observa las profundidades de la jerarquía, espera pacientemente cómo resultarán sus formas "ingenuas" de trabajar con tal estructura [no].Analicemos las tareas emergentes típicas, su implementación en SQL e intentemos mejorar su rendimiento.# 1 ¿Qué tan profundo es la madriguera del conejo?
Supongamos, definitivamente, que esta estructura reflejará la subordinación de los departamentos en la estructura de la organización: departamentos, divisiones, sectores, sucursales, grupos de trabajo ... como se llame.Primero, generamos nuestro 'árbol' de elementos de 10KINSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;
Comencemos con la tarea más simple: encontrar todos los empleados que trabajan dentro de un sector específico, o en términos de una jerarquía, para encontrar todos los descendientes de un nodo . También sería bueno obtener la "profundidad" del descendiente ... Todo esto puede ser necesario, por ejemplo, para construir algún tipo de selección compleja de la lista de ID de estos empleados .Todo estaría bien si estos descendientes solo hay un par de niveles y cuantitativamente dentro de una docena, pero si hay más de 5 niveles y ya hay docenas de descendientes, puede haber problemas. Veamos cómo se escriben (y funcionan) las opciones de búsqueda tradicionales "en el árbol". Pero primero, determinamos cuál de los nodos será el más interesante para nuestra investigación.Los subárboles "más profundos" :WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC;
id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...
Los subárboles "más anchos" :...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;
id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
Para estas consultas, usamos un JOIN recursivo típico :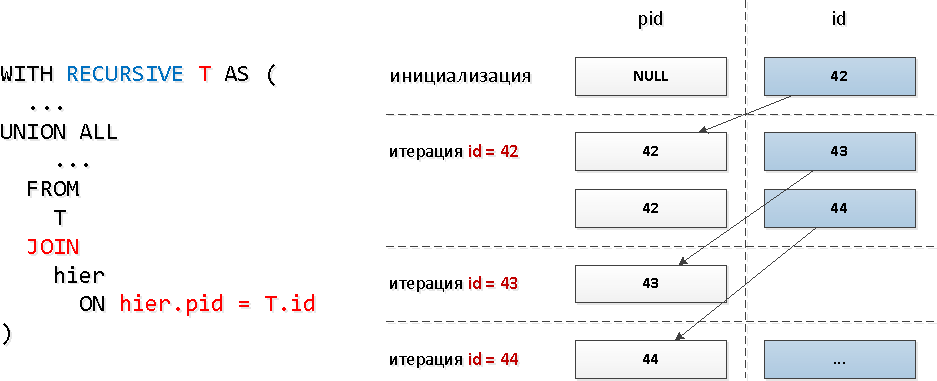 Obviamente, con este modelo de consulta, el número de iteraciones coincidirá con el número total de descendientes (y hay varias docenas de ellos), y esto puede requerir recursos bastante sustanciales y, como resultado, tiempo.Veamos el subárbol "más ancho":
Obviamente, con este modelo de consulta, el número de iteraciones coincidirá con el número total de descendientes (y hay varias docenas de ellos), y esto puede requerir recursos bastante sustanciales y, como resultado, tiempo.Veamos el subárbol "más ancho":WITH RECURSIVE T AS (
SELECT
id
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T;
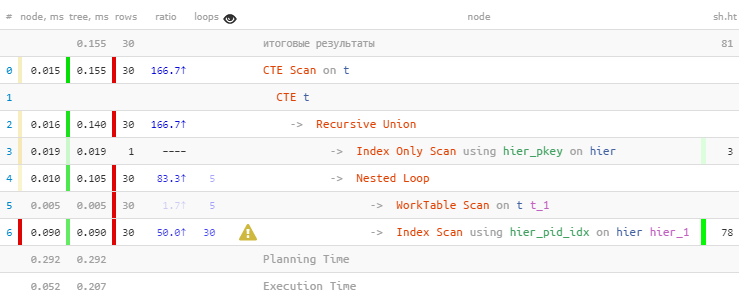 [mire explicar.tensor.ru]Como se esperaba, encontramos las 30 entradas. Pero gastaron el 60% del tiempo en esto, porque hicieron 30 búsquedas en el índice. Y menos, ¿es posible?
[mire explicar.tensor.ru]Como se esperaba, encontramos las 30 entradas. Pero gastaron el 60% del tiempo en esto, porque hicieron 30 búsquedas en el índice. Y menos, ¿es posible?Revisión masiva por índice
Y para cada nodo, ¿necesitamos hacer una solicitud de índice por separado? Resulta que no, podemos leer del índice en varias teclas a la vez con una sola llamada= ANY(array) .Y en cada grupo de identificadores podemos tomar todos los ID encontrados en el paso anterior por "nodos". Es decir, en cada próximo paso buscaremos inmediatamente a todos los descendientes de cierto nivel a la vez .Pero, es mala suerte, en una selección recursiva, no puede referirse a sí mismo en una subconsulta , pero solo tenemos que seleccionar de alguna manera exactamente lo que se encontró en el nivel anterior ... Resulta que no puede hacer una subconsulta a toda la muestra, sino a su campo específico: lata. Y este campo también puede ser una matriz, que es lo que necesitamos usarANY.Suena un poco salvaje, pero en el diagrama, todo es simple.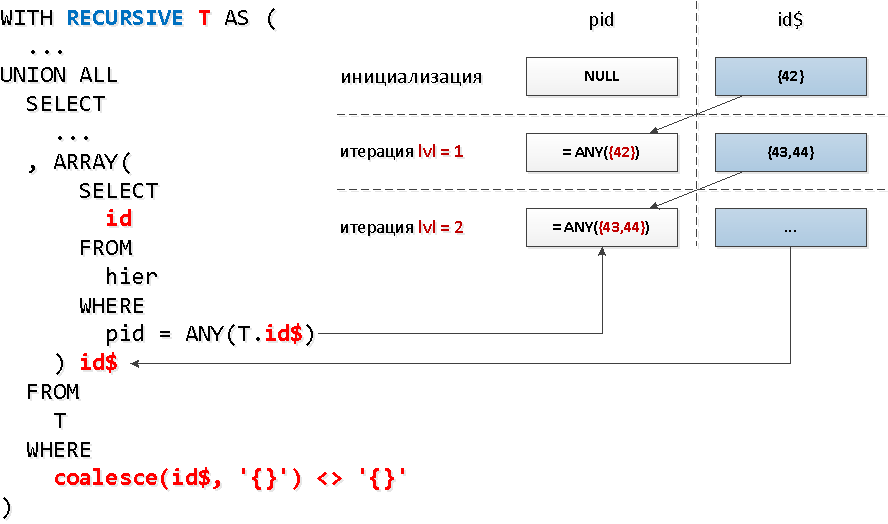
WITH RECURSIVE T AS (
SELECT
ARRAY[id] id$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
ARRAY(
SELECT
id
FROM
hier
WHERE
pid = ANY(T.id$)
) id$
FROM
T
WHERE
coalesce(id$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [mire explicar.tensor.ru] ¡Y aquí lo más importante es ni siquiera ganar 1.5 veces en el tiempo , sino que restamos menos buffers, ya que solo tenemos 5 llamadas al índice en lugar de 30!Una bonificación adicional es el hecho de que después de los identificadores finales no ordenados permanecerán ordenados por "niveles".
[mire explicar.tensor.ru] ¡Y aquí lo más importante es ni siquiera ganar 1.5 veces en el tiempo , sino que restamos menos buffers, ya que solo tenemos 5 llamadas al índice en lugar de 30!Una bonificación adicional es el hecho de que después de los identificadores finales no ordenados permanecerán ordenados por "niveles".Etiqueta de nodo
La siguiente consideración que ayudará a mejorar la productividad es que las "hojas" no pueden tener hijos , es decir, no necesitan mirar hacia abajo para nada. En la formulación de nuestra tarea, esto significa que si seguimos la cadena de departamentos y llegamos al empleado, entonces no hay necesidad de buscar más en esta rama.Vamos a introducir un campo adicionalboolean en nuestra tabla , que nos dirá de inmediato si esta entrada particular en nuestro árbol es un "nodo" , es decir , si puede tener hijos.ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
¡Multa! Resulta que solo un poco más del 30% de todos los elementos del árbol tienen descendientes.Ahora aplicaremos una mecánica ligeramente diferente, conectando a la parte recursiva LATERAL, lo que nos permitirá acceder inmediatamente a los campos de la "tabla" recursiva, y usar la función de agregado con la condición de filtrado basada en el nodo para reducir el conjunto de claves: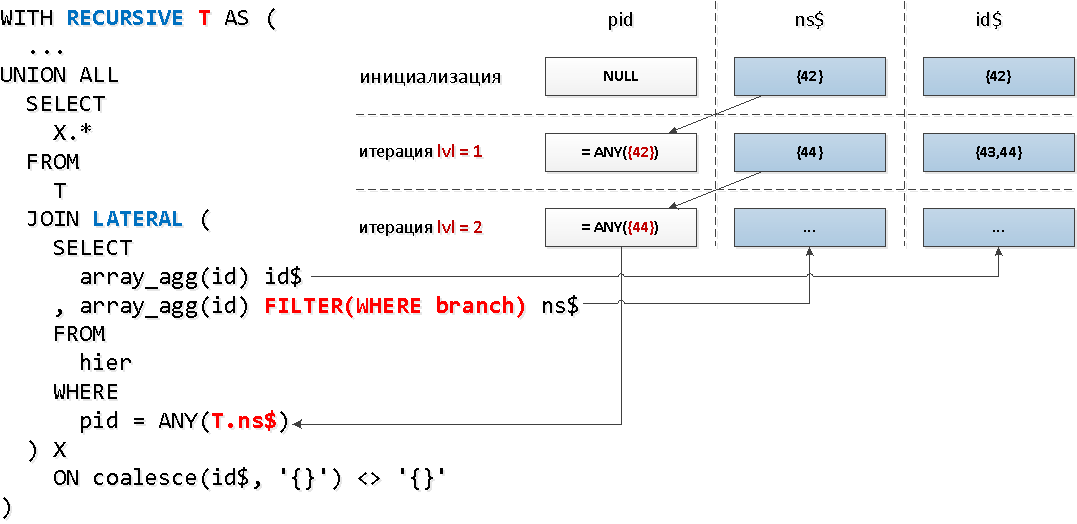
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [mire explicar.tensor.ru]Pudimos reducir otra apelación al índice y ganamos más de 2 veces en términos de la cantidad deducida.
[mire explicar.tensor.ru]Pudimos reducir otra apelación al índice y ganamos más de 2 veces en términos de la cantidad deducida.# 2 De vuelta a las raíces
Este algoritmo será útil si necesita recopilar registros para todos los elementos "arriba del árbol", mientras mantiene información sobre qué hoja de origen (y con qué indicadores) hizo que cayera en la muestra, por ejemplo, para generar un informe resumido con agregación a los nodos.El posterior debe tomarse exclusivamente como prueba de concepto, ya que la solicitud es muy engorrosa. Pero si domina su base de datos, vale la pena considerar el uso de tales técnicas.Comencemos con un par de declaraciones simples:- Es mejor leer el mismo registro de la base de datos solo una vez .
- Las entradas de la base de datos se leen más eficientemente en un "paquete" que individualmente.
Ahora intentemos diseñar la consulta que necesitamos.Paso 1
Obviamente, en la inicialización de la recursión (¡sin ella!) Tendremos que restar los registros de las hojas del conjunto de identificadores de origen:WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
...
Si a alguien le pareció extraño que el "conjunto" se almacenara en una cadena, no en una matriz, entonces hay una explicación simple. Para las cadenas, hay una función de "pegado" de agregación incorporada string_agg, pero para las matrices, no. Aunque no es difícil implementarlo usted mismo .Paso 2
Ahora obtendríamos un conjunto de ID de sección que será necesario restar más. Casi siempre, que se duplicarán en los diferentes registros del conjunto de fuente - por lo que haría grupo de ellos , manteniendo al mismo tiempo la información sobre las hojas de origen.Pero aquí nos esperan tres problemas:- La parte "sub-recursiva" de una consulta no puede contener funciones agregadas c
GROUP BY. - Una llamada a una "tabla" recursiva no puede estar en una subconsulta anidada.
- Una consulta en la parte recursiva no puede contener un CTE.
Afortunadamente, todos estos problemas se evitan fácilmente. Comencemos desde el final.CTE en la parte recursiva
Así no es como funciona:WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)
Y así funciona, ¡los corchetes deciden!WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)
Consulta anidada para "tabla" recursiva
Hmm ... Una llamada a un CTE recursivo no puede estar en una subconsulta. ¡Pero puede estar dentro del CTE! ¡Una solicitud secundaria ya puede referirse a este CTE!GROUP BY dentro de recursión
Es desagradable, pero ... ¡También tenemos una manera simple de simular GROUP BY usando DISTINCT ONfunciones de ventana!SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1
¡Y así funciona!SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
Ahora vemos por qué la identificación numérica se convirtió en texto, ¡para que se puedan pegar con una coma!Paso 3
Para el final, no nos queda nada:- leemos registros de "secciones" en un conjunto de ID agrupadas
- unir las secciones restadas con los "conjuntos" de hojas de origen
- "Expanda" la cadena establecida usando
unnest(string_to_array(chld, ',')::integer[])
WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
(
WITH prnt AS (
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
)
, nodes AS (
SELECT
rec
FROM
hier rec
WHERE
id = ANY(ARRAY(
SELECT
id
FROM
prnt
))
)
SELECT
nodes.rec
, prnt.chld
FROM
prnt
JOIN
nodes
ON (nodes.rec).id = prnt.id
)
)
SELECT
unnest(string_to_array(chld, ',')::integer[]) leaf
, (rec).*
FROM
tree;
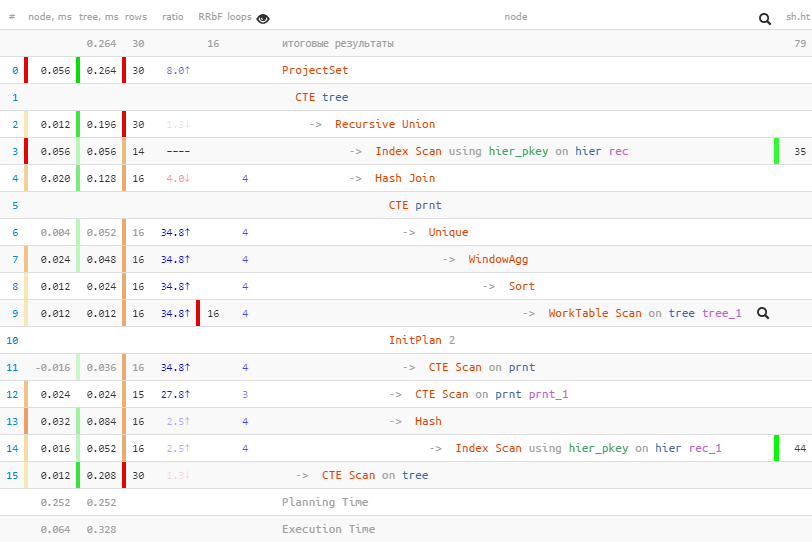 [ explain.tensor.ru]
[ explain.tensor.ru]