 Hola habrozhiteli! Paul y Harvey Daytels ofrecen una nueva mirada a Python y utilizan un enfoque único para resolver rápidamente los problemas que enfrentan las personas modernas de TI.A su disposición más de quinientas tareas reales, desde fragmentos hasta 40 escenarios grandes y ejemplos con implementación completa. IPython con Jupyter Notebooks le permite aprender rápidamente modismos modernos de programación de Python. Los capítulos 1–5 y los fragmentos de los capítulos 6–7 harán ejemplos claros de resolución de problemas de inteligencia artificial de los capítulos 11–16. Aprenderá sobre el procesamiento del lenguaje natural, el análisis de emociones en Twitter, la computación cognitiva de IBM Watson, el aprendizaje automático con un maestro en problemas de clasificación y regresión, el aprendizaje automático sin un maestro en agrupamiento, el reconocimiento de patrones con aprendizaje profundo y redes neuronales convolucionales, redes neuronales recurrentes, grandes datos de Hadoop, Spark y NoSQL, IoT y más. Trabajará (directa o indirectamente) con servicios en la nube, incluidos Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub, etc.
Hola habrozhiteli! Paul y Harvey Daytels ofrecen una nueva mirada a Python y utilizan un enfoque único para resolver rápidamente los problemas que enfrentan las personas modernas de TI.A su disposición más de quinientas tareas reales, desde fragmentos hasta 40 escenarios grandes y ejemplos con implementación completa. IPython con Jupyter Notebooks le permite aprender rápidamente modismos modernos de programación de Python. Los capítulos 1–5 y los fragmentos de los capítulos 6–7 harán ejemplos claros de resolución de problemas de inteligencia artificial de los capítulos 11–16. Aprenderá sobre el procesamiento del lenguaje natural, el análisis de emociones en Twitter, la computación cognitiva de IBM Watson, el aprendizaje automático con un maestro en problemas de clasificación y regresión, el aprendizaje automático sin un maestro en agrupamiento, el reconocimiento de patrones con aprendizaje profundo y redes neuronales convolucionales, redes neuronales recurrentes, grandes datos de Hadoop, Spark y NoSQL, IoT y más. Trabajará (directa o indirectamente) con servicios en la nube, incluidos Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub, etc.9.12.2. Lectura de archivos CSV en la colección DataFrame de la biblioteca de pandas
Las secciones de "Introducción a la ciencia de datos" de los dos capítulos anteriores introdujeron los conceptos básicos del trabajo con pandas. Ahora demostraremos las herramientas de pandas para descargar archivos CSV y luego realizaremos las operaciones básicas de análisis de datos.Conjuntos de datos
En ejemplos prácticos de ciencia de datos, se utilizarán varios conjuntos de datos gratuitos y abiertos para demostrar los conceptos de aprendizaje automático y procesamiento del lenguaje natural. Una gran variedad de conjuntos de datos gratuitos están disponibles en Internet. El popular repositorio Rdatasets contiene enlaces a más de 1,100 conjuntos de datos CSV gratuitos. Estos kits se suministraron originalmente con el lenguaje de programación R para simplificar el estudio y el desarrollo de programas estadísticos, sin embargo, no están relacionados con el lenguaje R. Ahora estos conjuntos de datos están disponibles en GitHub en:https://vincentarelbundock.imtqy.com/Rdatasets/ datasets.htmlEste repositorio es tan popular que hay un módulo pydataset diseñado específicamente para acceder a Rdatasets. Para obtener instrucciones sobre cómo instalar pydataset y acceder a los conjuntos de datos, vaya a:https://github.com/iamaziz/PyDataset
Otra gran fuente de conjuntos de datos:https://github.com/awesomedata/awesome-public-datasetsUn conjunto de datos de aprendizaje automático comúnmente utilizado para principiantes es el conjunto de datos del accidente del Titanic, que enumera a todos los pasajeros y si sobrevivieron cuando el Titanic chocó con un iceberg y se hundió del 14 al 15 de abril de 1912. Utilizaremos este conjunto para mostrar cómo cargar un conjunto de datos, ver sus datos y derivar estadísticas descriptivas. Otros conjuntos de datos populares se explorarán en los capítulos de ejemplos de ciencia de datos más adelante en este libro.Trabajar con archivos CSV localesPara cargar un conjunto de datos CSV en un DataFrame, puede usar la función read_csv de la biblioteca de pandas. El siguiente fragmento descarga y muestra el archivo CSV accounts.csv que se creó anteriormente en este capítulo:In [1]: import pandas as pd
In [2]: df = pd.read_csv('accounts.csv',
...: names=['account', 'name', 'balance'])
...:
In [3]: df
Out[3]:
account name balance
0 100 Jones 24.98
1 200 Doe 345.67
2 300 White 0.00
3 400 Stone -42.16
4 500 Rich 224.62
El argumento de nombres especifica los nombres de columna del DataFrame. Sin este argumento, read_csv considera que la primera línea del archivo CSV contiene una lista de nombres de columna separados por comas.Para guardar los datos de DataFrame en un archivo CSV, llame al método to_csv de la colección DataFrame:In [4]: df.to_csv('accounts_from_dataframe.csv', index=False)
El argumento clave index = False significa que los nombres de fila (0–4 en el lado izquierdo de la salida del DataFrame en el fragmento [3]) no deben escribirse en el archivo. La primera línea del archivo resultante contiene los nombres de columna:account,name,balance
100,Jones,24.98
200,Doe,345.67
300,White,0.0
400,Stone,-42.16
500,Rich,224.62
9.12.3. Lectura del conjunto de datos de desastres del Titanic
El conjunto de datos de desastres de Titanic es uno de los conjuntos de datos de aprendizaje automático más populares y está disponible en muchos formatos, incluido CSV.Descargue el Titanic Disaster Dataset en la URL
Si tiene una URL que representa un conjunto de datos en formato CSV, puede cargarlo en un DataFrame con la función read_csv, digamos desde GitHub:In [1]: import pandas as pd
In [2]: titanic = pd.read_csv('https://vincentarelbundock.imtqy.com/' +
...: 'Rdatasets/csv/carData/TitanicSurvival.csv')
...:
Visualización de algunas filas del conjunto de datos del desastre del Titanic El conjunto de datoscontiene más de 1300 líneas, cada línea representa un pasajero. Según Wikipedia, había aproximadamente 1317 pasajeros a bordo, y 815 de ellos murieron1. Para conjuntos de datos grandes, solo se muestran las primeras 30 líneas cuando se emite el DataFrame, luego se muestran los puntos suspensivos "..." y las últimas 30 líneas. Para ahorrar espacio, revisaremos las primeras y últimas cinco filas utilizando los métodos head y tail de la colección DataFrame. Ambos métodos devuelven cinco líneas de forma predeterminada, pero el número de líneas que se muestran se puede pasar en el argumento:En [3]: pd.set_option ('precisión', 2) # Formato para valores de punto flotanteTenga en cuenta que los pandas ajustan el ancho de cada columna en función del valor más ancho en la columna o el nombre de la columna (según cuál tenga el ancho más grande); en la columna de edad de la fila 1305 aparece NaN, un signo de un valor faltante en el conjunto de datos.Configuración de nombres de columnaEl nombre de la primera columna en el conjunto de datos parece bastante extraño ('Sin nombre: 0'). Este problema se puede resolver personalizando los nombres de columna. Reemplace 'Sin nombre: 0' con 'nombre' y reduzca 'passengerClass' a 'clase':

9.12.4. Análisis de datos simple utilizando el conjunto de datos de desastres del Titanic como ejemplo
Ahora usaremos pandas para realizar un análisis de datos simple usando algunas características de estadísticas descriptivas como ejemplo. Cuando llama a describe para una colección de DataFrame que contiene columnas numéricas y no numéricas, describe calcula las características estadísticas solo para columnas numéricas, en este caso, solo para la columna de edad: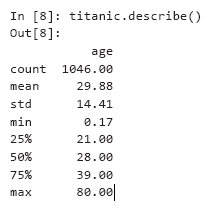 Tenga en cuenta las diferencias en el recuento (1046) y el número de filas de datos en el conjunto de datos (1309 - al llamar a tail, el índice de la última fila era 1308). Solo 1046 filas de datos (valor de conteo) contenían un valor de edad. Faltaban el resto de los resultados y estaban marcados con NaN, como en la línea 1305. Al realizar los cálculos, la biblioteca de pandas ignora los datos faltantes (NaN) por defecto. Para 1046 pasajeros con una edad válida, la edad promedio (expectativa) fue de 29.88 años. El pasajero más joven (min) tenía solo dos meses (0.17 * 12 da 2.04), y el mayor (max) tenía 80 años. La mediana de edad fue de 28 años (indicado por un cuartil del 50 por ciento). El cuartil del 25 por ciento describe la edad promedio en la primera mitad de los pasajeros (clasificada por edad),y el 75 por ciento del cuartil es la mediana en la segunda mitad de los pasajeros.Suponga que desea calcular estadísticas sobre los pasajeros sobrevivientes. Podemos comparar la columna sobrevivida con el valor 'sí' para obtener una nueva colección de Series con valores Verdadero / Falso, y luego usar describe para describir los resultados:
Tenga en cuenta las diferencias en el recuento (1046) y el número de filas de datos en el conjunto de datos (1309 - al llamar a tail, el índice de la última fila era 1308). Solo 1046 filas de datos (valor de conteo) contenían un valor de edad. Faltaban el resto de los resultados y estaban marcados con NaN, como en la línea 1305. Al realizar los cálculos, la biblioteca de pandas ignora los datos faltantes (NaN) por defecto. Para 1046 pasajeros con una edad válida, la edad promedio (expectativa) fue de 29.88 años. El pasajero más joven (min) tenía solo dos meses (0.17 * 12 da 2.04), y el mayor (max) tenía 80 años. La mediana de edad fue de 28 años (indicado por un cuartil del 50 por ciento). El cuartil del 25 por ciento describe la edad promedio en la primera mitad de los pasajeros (clasificada por edad),y el 75 por ciento del cuartil es la mediana en la segunda mitad de los pasajeros.Suponga que desea calcular estadísticas sobre los pasajeros sobrevivientes. Podemos comparar la columna sobrevivida con el valor 'sí' para obtener una nueva colección de Series con valores Verdadero / Falso, y luego usar describe para describir los resultados:In [9]: (titanic.survived == 'yes').describe()
Out[9]:
count 1309
unique 2
top False
freq 809
Name: survived, dtype: object
Para datos no numéricos, describe muestra varias características de estadísticas descriptivas:- cuenta - el número total de elementos en el resultado;
- único: el número de valores únicos (2) como resultado: verdadero (el pasajero sobrevivió) o falso (el pasajero murió);
- top: el valor encontrado con mayor frecuencia como resultado;
- freq: el número de ocurrencias del valor top.
9.12.5. Gráfico de barras de las edades de los pasajeros.
La visualización es una buena manera de conocer mejor los datos. Pandas contiene muchas herramientas de visualización integradas basadas en Matplotlib. Para usarlos, primero habilite el soporte de Matplotlib en IPython:In [10]: %matplotlib
El histograma muestra claramente la distribución de datos numéricos en un rango de valores. El método hist de la colección DataFrame analiza automáticamente los datos de cada columna numérica y crea el histograma correspondiente. Para ver los histogramas de cada columna numérica de datos, llame a hist para su colección de DataFrame:In [11]: histogram = titanic.hist()
El conjunto de datos del desastre del Titanic contiene solo una columna numérica de datos, por lo que el gráfico muestra un histograma para la distribución por edad. Para conjuntos de datos con múltiples columnas numéricas, hist crea un histograma separado para cada columna numérica.»Se puede encontrar más información sobre el libro en el sitio web del editor» Contenido» Extracto deKhabrozhiteley 25% de descuento en el cupón - PythonTras el pago de la versión en papel del libro (fecha de lanzamiento - 5 de junio ), se envía un libro electrónico.