Hola Habr! Hoy hablaremos en gran detalle sobre puntos no obvios en una operación aparentemente simple: corregir distorsiones proyectivas en la imagen. Como sucede a menudo en la vida, tuvimos que elegir cuál es más importante: calidad o velocidad. Y para lograr un cierto equilibrio, recordamos los algoritmos que estudiamos activamente en los años 80-90 como parte de la tarea de renderizar estructuras, y desde entonces raramente recordamos en el contexto del procesamiento de imágenes. Si está interesado, ¡mire debajo del gato! El modelo de cámara estenopeica, que en la práctica también trae cámaras de primeros planos de teléfonos móviles bastante bien, nos dice que cuando la cámara gira, las imágenes de un objeto plano se interconectan mediante transformación proyectiva. La visión general de la transformación proyectiva es la siguiente:
El modelo de cámara estenopeica, que en la práctica también trae cámaras de primeros planos de teléfonos móviles bastante bien, nos dice que cuando la cámara gira, las imágenes de un objeto plano se interconectan mediante transformación proyectiva. La visión general de la transformación proyectiva es la siguiente:
Dónde matriz de transformación proyectiva, y coordenadas en la fuente y las imágenes convertidas.Conversión de imagen geométrica
La transformación de imagen proyectiva es una de las posibles transformaciones geométricas de imágenes (tales transformaciones en las que los puntos de la imagen original van a los puntos de la imagen final de acuerdo con una determinada ley).Para comprender cómo resolver el problema de la transformación geométrica de una imagen digital, debe considerar el modelo de su formación a partir de una imagen óptica en la matriz de la cámara. Según G. Wahlberg [1], nuestro algoritmo debe aproximarse al siguiente proceso:- Recuperar imagen óptica de digital.
- Transformación geométrica de la imagen óptica.
- Muestreo de la imagen convertida.
Una imagen óptica es una función de dos variables definidas en un conjunto continuo de puntos. Este proceso es difícil de reproducir directamente, porque tenemos que establecer analíticamente el tipo de imagen óptica y procesarla. Para simplificar este proceso, generalmente se usa el método de mapeo inverso:- En el plano de la imagen final, se selecciona una cuadrícula de muestreo: los puntos por los cuales evaluaremos los valores de píxeles de la imagen final (este puede ser el centro de cada píxel, o quizás algunos puntos por píxel).
- Usando la transformación geométrica inversa, esta cuadrícula se transfiere al espacio de la imagen original.
- Para cada muestra de cuadrícula, se estima su valor. Como no necesariamente aparece en un punto con coordenadas enteras, necesitamos alguna interpolación del valor de la imagen, por ejemplo, la interpolación por píxeles vecinos.
- Según los informes de la cuadrícula, estimamos los valores de píxeles de la imagen final.
Aquí, el paso 3 corresponde a la restauración de la imagen óptica, y los pasos 1 y 4 corresponden al muestreo.Interpolación
Aquí consideramos solo tipos simples de interpolación, aquellos que pueden representarse como una convolución de la imagen con el núcleo de interpolación. En el contexto del procesamiento de imágenes, los algoritmos de interpolación adaptativa que preservan los límites claros de los objetos serían mejores, pero su complejidad computacional es mucho mayor y, por lo tanto, no nos interesa.Consideraremos los siguientes métodos de interpolación:- por el píxel más cercano
- bilineal
- bicúbico
- B-spline cúbico
- estría ermitaña cúbica, 36 puntos.
La interpolación también tiene un parámetro tan importante como la precisión. Si suponemos que la imagen digital se obtuvo del método óptico mediante muestreo puntual en el centro del píxel y creemos que la imagen original era continua, entonces el filtro de paso bajo con una frecuencia de ½ será una función de reconstrucción ideal (ver el teorema de Kotelnikov ).Por lo tanto, comparamos los espectros de Fourier de nuestros núcleos de interpolación con un filtro de paso bajo (las cifras son para el caso unidimensional).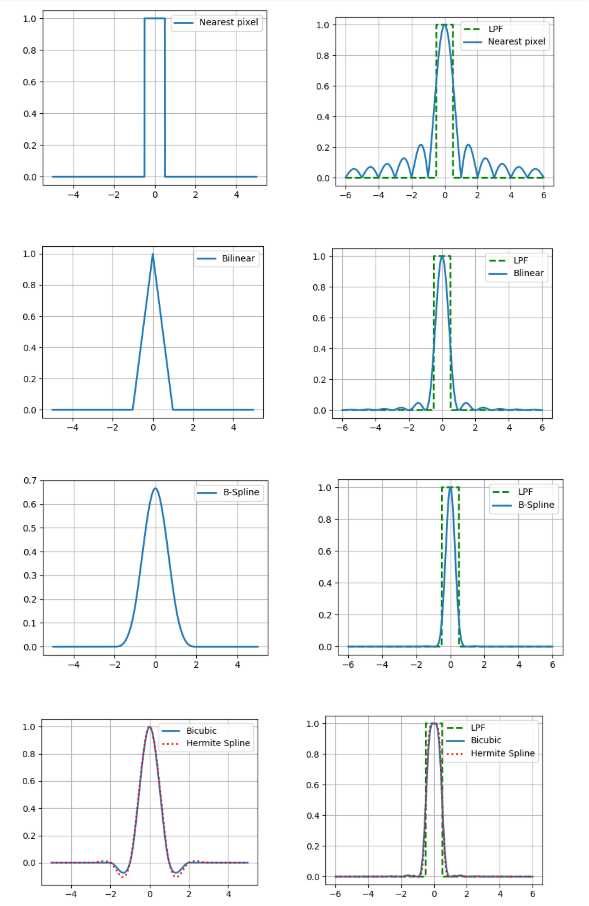 ¿Y qué, puede simplemente tomar un kernel con un espectro bastante bueno y obtener resultados relativamente precisos? En realidad no, porque hicimos dos supuestos arriba: que hay un valor de píxel de la imagen y la continuidad de esta imagen. Al mismo tiempo, ni uno ni el otro son parte de un buen modelo de formación de imágenes, porque los sensores en la matriz de la cámara no son puntuales, y en la imagen, mucha información lleva los límites de los objetos: huecos. Por lo tanto, por desgracia, debe entenderse que el resultado de la interpolación siempre será diferente de la imagen óptica original.Pero aún debe hacer algo, por lo que describiremos brevemente las ventajas y desventajas de cada uno de los métodos considerados desde un punto de vista práctico. La forma más fácil de ver esto es cuando amplía la imagen (en este ejemplo, 10 veces).
¿Y qué, puede simplemente tomar un kernel con un espectro bastante bueno y obtener resultados relativamente precisos? En realidad no, porque hicimos dos supuestos arriba: que hay un valor de píxel de la imagen y la continuidad de esta imagen. Al mismo tiempo, ni uno ni el otro son parte de un buen modelo de formación de imágenes, porque los sensores en la matriz de la cámara no son puntuales, y en la imagen, mucha información lleva los límites de los objetos: huecos. Por lo tanto, por desgracia, debe entenderse que el resultado de la interpolación siempre será diferente de la imagen óptica original.Pero aún debe hacer algo, por lo que describiremos brevemente las ventajas y desventajas de cada uno de los métodos considerados desde un punto de vista práctico. La forma más fácil de ver esto es cuando amplía la imagen (en este ejemplo, 10 veces).Interpolación de píxeles más cercana
Sin embargo, el más simple y rápido conduce a artefactos fuertes.Interpolación bilineal
Mejor en calidad, pero requiere más cómputo y además difumina los límites de los objetos.Interpolación bicúbica
Aún mejor en áreas continuas, pero en el borde hay un efecto de halo (una franja más oscura a lo largo del borde oscuro del borde y luz a lo largo de la luz). Para evitar este efecto, debe usar un núcleo de convolución no negativo como una b-spline cúbica.Interpolación de spline B
El b-spline tiene un espectro muy estrecho, lo que significa una fuerte imagen de "desenfoque" (pero también una buena reducción de ruido, que puede ser útil).Interpolación basada en una spline cúbica de Hermite
Tal spline requiere una estimación de las derivadas parciales en cada píxel de la imagen. Si, por aproximación, elegimos un esquema de diferencia de 2 puntos, entonces obtenemos el núcleo de la interpolación bicúbica, por lo que aquí usamos uno de 4 puntos.También comparamos estos métodos en términos de la cantidad de accesos a la memoria (la cantidad de píxeles de la imagen original para la interpolación en un punto) y la cantidad de multiplicación por punto.Se puede ver que los últimos 3 métodos son significativamente más costosos computacionalmente que los primeros 2.Muestreo
Este es el paso al que recientemente se le ha prestado muy poca atención inmerecidamente. La forma más fácil de realizar una transformación de imagen proyectiva es evaluar el valor de cada píxel de la imagen final por el valor que se obtiene invirtiendo su centro en el plano de la imagen original (teniendo en cuenta el método de interpolación seleccionado). A este enfoque lo llamamos discretización píxel por píxel . Sin embargo, en áreas donde la imagen está comprimida, esto puede conducir a artefactos significativos causados por el problema de la superposición de espectros a una frecuencia de muestreo insuficiente.Demostraremos claramente los artefactos de compresión en una muestra del pasaporte ruso y su campo individual: lugar de nacimiento (ciudad de Arkhangelsk), comprimido mediante muestreo píxel por píxel o el algoritmo FAST, que consideraremos a continuación.Se puede ver que el texto en la imagen izquierda se ha vuelto ilegible. Así es, ¡porque tomamos solo un punto de toda una región de la imagen fuente!Como no pudimos estimar en un píxel, ¿por qué no elegir más muestras por píxel y promediar los valores obtenidos? Este enfoque se llama supermuestreo . Realmente aumenta la calidad, pero al mismo tiempo, la complejidad computacional aumenta en proporción al número de muestras por píxel.Se inventaron métodos computacionalmente más eficientes a fines del siglo pasado, cuando los gráficos por computadora resolvieron el problema de renderizar texturas superpuestas en objetos planos. Uno de estos métodos es la conversión usando mip-mapestructura. Mip-map es una pirámide de imágenes que consta de la imagen original en sí misma, así como sus copias reducidas en 2, 4, 8, etc. Para cada píxel, evaluamos el grado de compresión característico del mismo y, de acuerdo con este grado, seleccionamos el nivel deseado de la pirámide, como la imagen de origen. Hay diferentes formas de evaluar el nivel apropiado de mip-map (ver detalles [2]). Aquí usaremos el método basado en la estimación de derivadas parciales con respecto a la conocida matriz de transformación proyectiva. Sin embargo, para evitar artefactos en áreas de la imagen final donde un nivel de la estructura del mapa MIP va a otro, generalmente se usa la interpolación lineal entre dos niveles adyacentes de la pirámide (esto no aumenta en gran medida la complejidad computacional, porque las coordenadas de los puntos en los niveles vecinos están conectados de manera única).Sin embargo, el mapa MIP no tiene en cuenta el hecho de que la compresión de imágenes puede ser anisotrópica (alargada en alguna dirección). Este problema puede resolverse parcialmente mediante rip-map . Una estructura en la que las imágenes se comprimen veces horizontalmente y veces verticalmente. En este caso, después de determinar los coeficientes de compresión horizontal y vertical en un punto dado de la imagen final, se realiza la interpolación entre los resultados de 4 copias de la imagen original comprimidas en el número deseado de veces. Pero este método no es ideal, porque no tiene en cuenta que la dirección de la anisotropía difiere de las direcciones paralelas a los límites de la imagen original.En parte, este problema puede resolverse mediante el algoritmo FAST (Footprint Area Sampled Texturing) [3]. Combina las ideas de mip-map y supersampling. Estimamos el grado de compresión basado en el eje de menor anisotropía y seleccionamos el número de muestras en proporción a la relación de las longitudes del eje más pequeño al más grande.Antes de comparar estos enfoques en términos de complejidad computacional, hacemos una reserva de que para acelerar el cálculo de la transformación proyectiva inversa, es racional realizar el siguiente cambio:Dónde , Es la matriz de la transformación proyectiva inversa. Como y funciones de un argumento, podemos calcularlas previamente por un tiempo proporcional al tamaño lineal de la imagen. Luego, para calcular las coordenadas de la imagen inversa de un punto de la imagen final, solo se requieren 1 división y 2 multiplicaciones. Se puede realizar un truco similar con derivadas parciales, que se utilizan para determinar el nivel en la estructura mip-map o rip-map.Ahora estamos listos para comparar los resultados en términos de complejidad computacional.Y compare visualmente (de muestreo de píxel a píxel de izquierda a derecha, supermuestreo de 49 muestras, mip-map, rip-map, FAST).
Experimentar
Ahora, comparemos nuestros resultados experimentalmente. Compusimos un algoritmo de transformación proyectiva que combina cada uno de 5 métodos de interpolación y 5 métodos de discretización (25 opciones en total). Tome 20 imágenes de documentos recortados a 512x512 píxeles, genere 10 conjuntos de 3 matrices de transformación proyectiva, de modo que cada conjunto sea generalmente equivalente a la transformación idéntica, y compararemos el PSNR entre la imagen original y la convertida. Recordemos que PSNR esdónde este es el máximo en la imagen original a - la desviación estándar de la final del original. Cuanto más PSNR, mejor. También mediremos el tiempo de funcionamiento de la conversión proyectiva a ODROID-XU4 con un procesador ARM Cortex-A15 (2000 MHz y 2 GB de RAM).Mesa monstruosa con los resultados:¿Qué conclusiones se pueden sacar?
- El uso de la interpolación por el píxel más cercano o el muestreo píxel por píxel da como resultado una mala calidad (era obvio en los ejemplos anteriores).
- 36 — .
- b- , , .
- Rip-map FAST , 9 ( , ?).
- mip-map b- PSNR , .
Si desea una buena calidad con una velocidad no demasiado baja, debe considerar la interpolación bilineal en combinación con la discretización mediante mip-map o FAST. Sin embargo, si se sabe con certeza que la distorsión proyectiva es muy débil, para aumentar la velocidad, puede usar la discretización de píxel por píxel emparejada con interpolación bilineal o incluso interpolación por el píxel más cercano. Y si necesita alta calidad y un tiempo de ejecución no muy limitado, puede usar interpolación bicúbica o adaptativa combinada con un supermuestreo moderado (por ejemplo, también adaptativo, dependiendo de la relación de compresión local).PD La publicación se basa en el informe: A. Trusov y E. Limonova, "El análisis de algoritmos de transformación proyectiva para el reconocimiento de imágenes en dispositivos móviles", ICMV 2019, 11433 ed., Wolfgang Osten, Dmitry Nikolaev, Jianhong Zhou, Ed., SPIE , Ene. 2020, vol. 11433, ISSN 0277-786X, ISBN 978-15-10636-43-9, vol. 11433, 11433 0Y, págs. 1-8, 2020, DOI: 10.1117 / 12.2559732.Lista de fuentes utilizadas- G. Wolberg, Digital image warping, vol. 10662, IEEE computer society press Los Alamitos, CA (1990).
- J. P. Ewins, M. D. Waller, M. White, and P. F. Lister, “Mip-map level selection for texture mapping,” IEEE Transactions on Visualization and Computer Graphics4(4), 317–329 (1998).
- B. Chen, F. Dachille, and A. E. Kaufman, “Footprint area sampled texturing,” IEEE Transactions on Visualizationand Computer Graphics10(2), 230–240 (2004).