Sucede que los sistemas tienen errores, se ralentizan, se descomponen. Cuanto más grande es el sistema, más difícil es encontrar la causa. Para averiguar por qué algo no funciona como se esperaba, para solucionar o prevenir problemas futuros, debe mirar dentro. Para esto, los sistemas deben poseer la propiedad de observabilidad , que se logra mediante instrumentación en el sentido amplio de la palabra.En HighLoad ++, Peter Zaitsev (Percona) revisó la infraestructura disponible para el rastreo en Linux y habló sobre bpfTrace, que (como su nombre lo indica) ofrece muchas ventajas. Creamos una versión de texto del informe, por lo que sería conveniente para usted revisar los detalles y los materiales adicionales siempre estuvieron a la mano.La instrumentación se puede dividir en dos grandes bloques:- Estático , cuando la recopilación de información está conectada al código: registro de registros, contadores, tiempo, etc.
- Dinámico , cuando el código no está instrumentado por sí mismo, pero es posible hacerlo cuando sea necesario.
Otra opción de clasificación se basa en el enfoque para registrar datos:- Seguimiento : los eventos se generan si un determinado código ha funcionado.
- Muestreo : se verifica el estado del sistema, por ejemplo, 100 veces por segundo y determina lo que está sucediendo en él.
La instrumentación estática ha existido durante muchos años y está en casi todo. En Linux, muchas herramientas estándar como Vmstat o top lo usan. Leen datos de procfs, donde, en términos generales, se escriben diferentes temporizadores y contadores desde el código del núcleo.Pero no puede insertar muchos de estos contadores; no puede cubrir todo en el mundo con ellos. Por lo tanto, la instrumentación dinámica puede ser útil, lo que le permite ver exactamente lo que necesita. Por ejemplo, si hay algún problema con la pila TCP / IP, puede profundizar e instruir detalles específicos.
Dtrace
DTrace es uno de los primeros marcos de seguimiento dinámico conocidos creados por Sun Microsystems. Comenzó a fabricarse en 2001 y, por primera vez, se lanzó en Solaris 10 en 2005. El enfoque resultó ser muy popular y luego entró en muchas otras distribuciones.Curiosamente, DTrace le permite instrumentar tanto el espacio del kernel como el espacio del usuario. Puede colocar rastreos en cualquier llamada a funciones e instruir específicamente a los programas: introduzca puntos de rastreo DTrace especiales, que para los usuarios pueden ser más comprensibles que los nombres de funciones.Esto fue especialmente importante para Solaris, porque no es un sistema operativo abierto. No fue posible simplemente mirar el código y comprender que el punto de rastreo debe ponerse en una función como ahora se puede hacer en el nuevo software Linux de código abierto.Una de las características únicas, especialmente en ese momento, de DTrace es que si bien el rastreo no está habilitado, no cuesta nada . Funciona de tal manera que simplemente reemplaza algunas instrucciones de la CPU con una llamada DTrace, que ejecuta estas instrucciones cuando regresa.En DTrace, la instrumentación está escrita en un lenguaje D especial, similar a C y Awk.Más tarde, DTrace apareció en casi todas partes, excepto Linux: en MacOS en 2007, en FreeBSD en 2008, en NetBSD en 2010. Oracle en 2011 incluyó DTrace en Oracle Unbreakable Linux. Pero pocas personas usan Oracle Linux, y DTrace nunca ingresó al Linux principal.Curiosamente, en 2017, Oracle finalmente otorgó la licencia de DTrace bajo GPLv2, lo que en principio permitió incluirlo en Linux principal sin dificultades de licencia, pero ya era demasiado tarde. En ese momento, Linux tenía un buen BPF, que se usaba principalmente para la estandarización.DTrace incluso se incluirá en Windows; ahora está disponible en algunas versiones de prueba.Rastreo de Linux
¿Qué hay en Linux en lugar de DTrace? De hecho, en Linux hay muchas cosas en la mejor (o peor) manifestación del espíritu de código abierto, a lo largo de este tiempo se han acumulado varios marcos de rastreo diferentes. Por lo tanto, descubrir qué es lo que no es tan simple.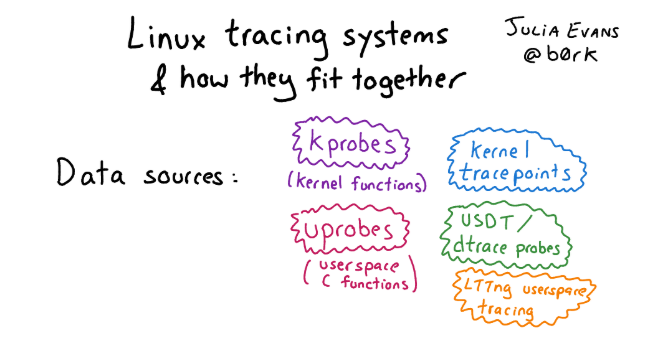 Si desea familiarizarse con esta variedad y está interesado en la historia, consulte el artículo con imágenes y una descripción detallada de los enfoques para el rastreo en Linux.Si hablamos de la infraestructura para el rastreo en Linux en general, hay tres niveles:
Si desea familiarizarse con esta variedad y está interesado en la historia, consulte el artículo con imágenes y una descripción detallada de los enfoques para el rastreo en Linux.Si hablamos de la infraestructura para el rastreo en Linux en general, hay tres niveles:- Interfaz para instrumentación de kernel: Kprobe, Uprobe, sonda Dtrace, etc.
- «», . , probe, , user space . : , user space, Kernel Module, - , eBPF.
- -, , : Perf, SystemTap, SysDig, BCC .. bpfTtrace , , .
eBPF — Linux
Con todos estos marcos, eBPF se ha convertido en el estándar en Linux en los últimos años. Esta es una herramienta más avanzada, altamente flexible y efectiva que permite casi todo.¿Qué es eBPF y de dónde vino? De hecho, eBPF es un filtro de paquetes de Berkeley extendido, y BPF se desarrolló en 1992 como una máquina virtual para el filtrado eficiente de paquetes por un firewall. Inicialmente, no tenía relación con el monitoreo, la observabilidad o el rastreo.En versiones más modernas, eBPF se ha ampliado (de ahí la palabra extendida), como un marco común para el manejo de eventos . Las versiones actuales están integradas con el compilador JIT para una mayor eficiencia.Diferencias de eBPF de BPF clásico:- registros agregados;
- ha aparecido una pila;
- Hay estructuras de datos adicionales (mapas).
 Ahora la gente olvida con mayor frecuencia que había un BPF antiguo, y eBPF simplemente se llama BPF. En la mayoría de las expresiones modernas, eBPF y BPF son lo mismo. Por lo tanto, la herramienta se llama bpfTrace, no eBpfTrace.eBPF se ha incluido en la línea principal de Linux desde 2014 y se incluye gradualmente en muchas herramientas de Linux, incluidas Perf, SystemTap, SysDig. Hay una estandarización.Curiosamente, el desarrollo aún está en marcha. Los núcleos modernos soportan eBPF cada vez mejor.
Ahora la gente olvida con mayor frecuencia que había un BPF antiguo, y eBPF simplemente se llama BPF. En la mayoría de las expresiones modernas, eBPF y BPF son lo mismo. Por lo tanto, la herramienta se llama bpfTrace, no eBpfTrace.eBPF se ha incluido en la línea principal de Linux desde 2014 y se incluye gradualmente en muchas herramientas de Linux, incluidas Perf, SystemTap, SysDig. Hay una estandarización.Curiosamente, el desarrollo aún está en marcha. Los núcleos modernos soportan eBPF cada vez mejor.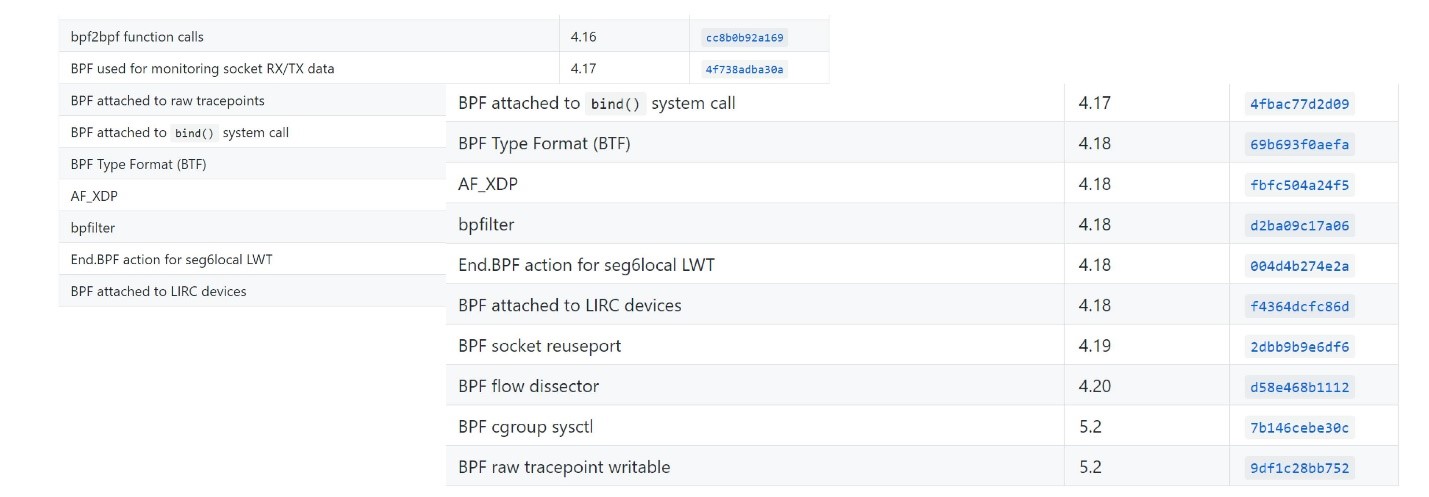 Puedes ver qué versiones modernas del kernel han aparecido aquí .
Puedes ver qué versiones modernas del kernel han aparecido aquí .Programas EBPF
Entonces, ¿qué es eBPF y por qué es interesante?eBPF es un programa en su código de bytes especial , que se incluye directamente en el núcleo y realiza el procesamiento de eventos de rastreo. Además, el hecho de que esté hecho en un código de bytes especial permite que el núcleo realice cierta verificación de que el código es bastante seguro. Por ejemplo, verifique que no use bucles, porque el bucle en la sección crítica del núcleo puede colgar todo el sistema.Pero esto no permite ser completamente seguro. Por ejemplo, si escribe un programa eBPF muy complejo, insértelo en un evento en el núcleo que ocurra 10 millones de veces por segundo, entonces todo se puede ralentizar mucho. Pero al mismo tiempo, eBPF es mucho más seguro que el enfoque anterior, cuando solo se insertaron algunos módulos de kernel a través de insmod, y cualquier cosa podría estar en estos módulos. Si alguien cometió un error, o simplemente debido a la incompatibilidad binaria, todo el núcleo podría caerse.LLVM Clang puede compilar el código eBPF, es decir, en general, usar un subconjunto de C para crear programas eBPF, lo que, por supuesto, es bastante complicado. Y es importante que la compilación dependa del núcleo: los encabezados se usan para comprender qué estructuras se usan y para qué se usan, etc. Esto no es muy conveniente en el sentido de que algunos módulos relacionados con un núcleo específico siempre se suministran o necesitan ser recompilados.El diagrama muestra cómo funciona eBPF. http://www.brendangregg.com/ebpf.htmlEl usuario crea un programa eBPF. Además, el núcleo, por su parte, lo comprueba y lo carga. Después de eso, eBPF puede conectarse a varias herramientas para rastrear, procesar información, guardarla en mapas (estructura de datos para almacenamiento temporal). Luego, el programa de usuario puede leer estadísticas, recibir eventos de rendimiento, etc.Muestra qué características de eBPF en qué versiones de kernels de Linux.
http://www.brendangregg.com/ebpf.htmlEl usuario crea un programa eBPF. Además, el núcleo, por su parte, lo comprueba y lo carga. Después de eso, eBPF puede conectarse a varias herramientas para rastrear, procesar información, guardarla en mapas (estructura de datos para almacenamiento temporal). Luego, el programa de usuario puede leer estadísticas, recibir eventos de rendimiento, etc.Muestra qué características de eBPF en qué versiones de kernels de Linux.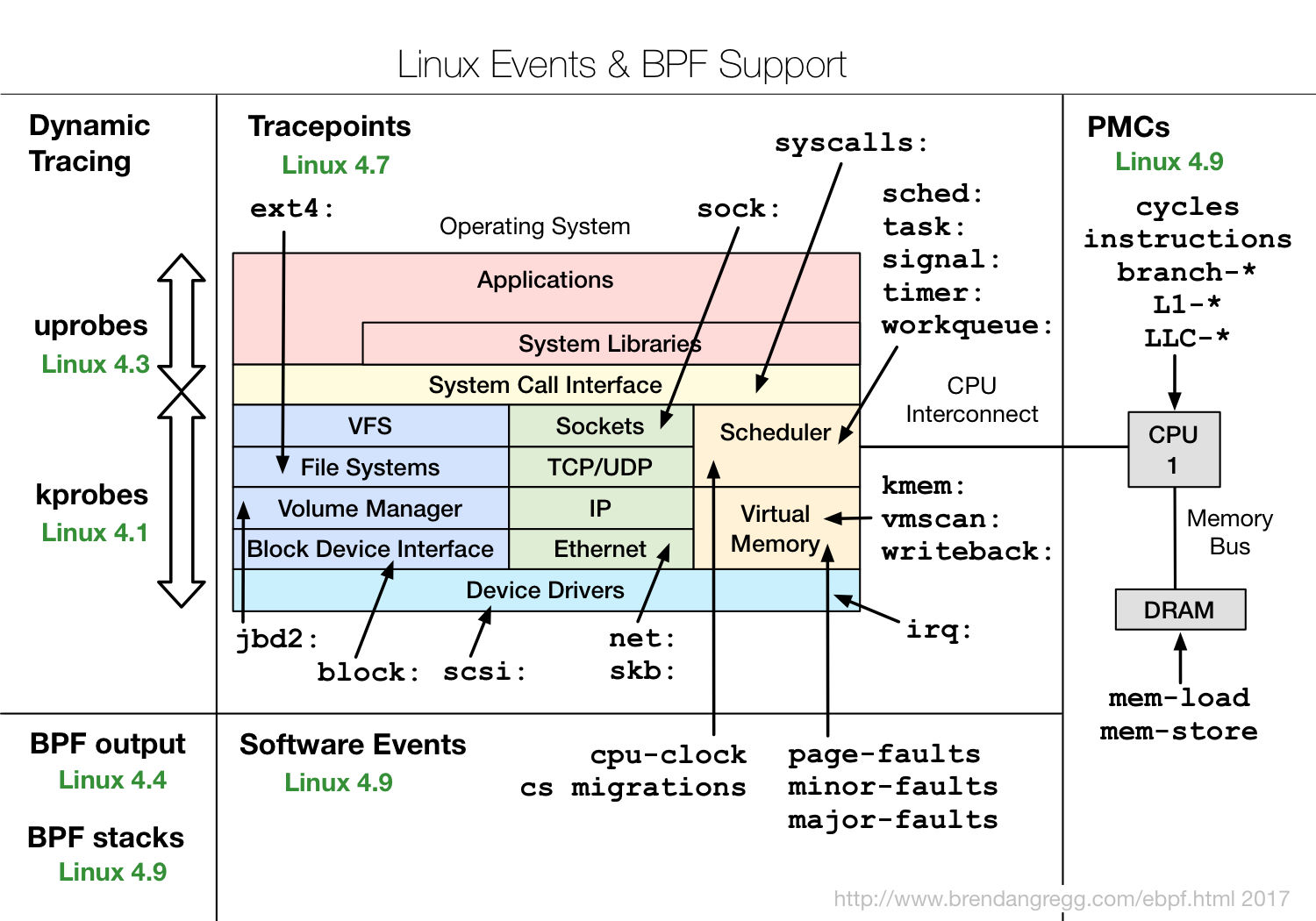 Se puede ver que casi todos los subsistemas del kernel de Linux están cubiertos, además de que hay una buena integración con los datos del hardware, eBPF tiene acceso a todo tipo de predicción de pérdida de caché o de rama, etc.Si está interesado en eBPF, consulte el proyecto IO Visor, contiene la mayoría de las herramientas. La compañía IO Visor se dedica a su desarrollo, tendrán las últimas versiones y muy buena documentación. Cada vez aparecen más herramientas eBPF en las distribuciones de Linux, por lo que recomendaría que siempre use las últimas versiones disponibles.
Se puede ver que casi todos los subsistemas del kernel de Linux están cubiertos, además de que hay una buena integración con los datos del hardware, eBPF tiene acceso a todo tipo de predicción de pérdida de caché o de rama, etc.Si está interesado en eBPF, consulte el proyecto IO Visor, contiene la mayoría de las herramientas. La compañía IO Visor se dedica a su desarrollo, tendrán las últimas versiones y muy buena documentación. Cada vez aparecen más herramientas eBPF en las distribuciones de Linux, por lo que recomendaría que siempre use las últimas versiones disponibles.Rendimiento EBPF
En términos de rendimiento, eBPF es bastante efectivo. Para comprender cuánto y si hay gastos generales, puede agregar una sonda, que se mueve varias veces por segundo, y verificar cuánto tiempo se tarda en ejecutarla.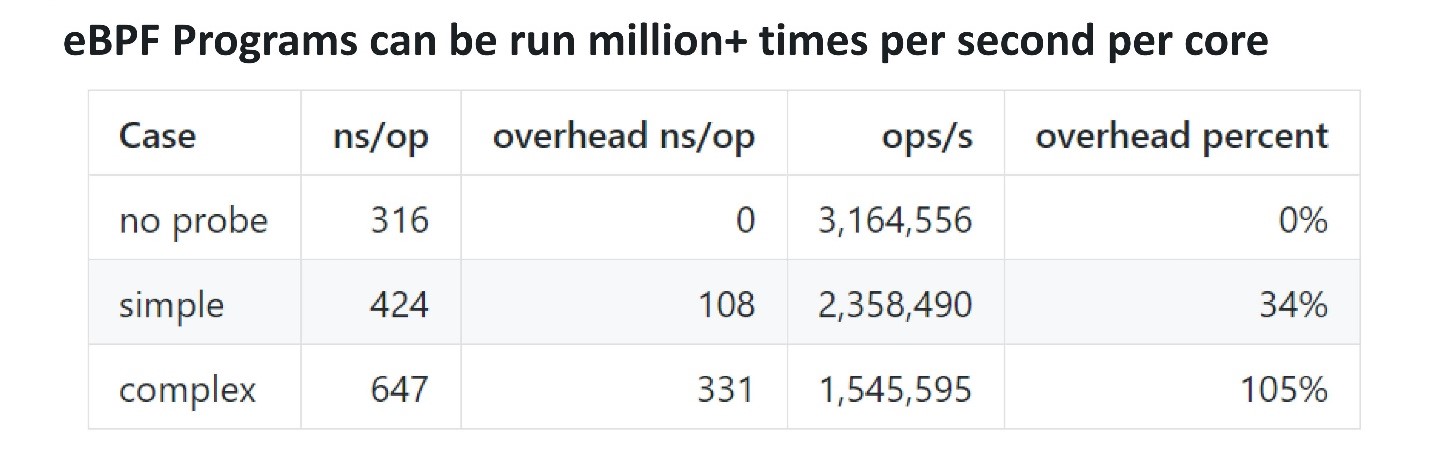 Los chicos de Cloudflare hicieron un punto de referencia . Una simple sonda eBPF les tomó alrededor de 100 ns, mientras que una más compleja tomó 300 ns. Esto significa que incluso una sonda compleja puede activarse en un solo núcleo aproximadamente 3 millones de veces por segundo. Si la sonda se mueve 100 mil o un millón de veces por segundo en un procesador multinúcleo, esto no afectará demasiado el rendimiento.
Los chicos de Cloudflare hicieron un punto de referencia . Una simple sonda eBPF les tomó alrededor de 100 ns, mientras que una más compleja tomó 300 ns. Esto significa que incluso una sonda compleja puede activarse en un solo núcleo aproximadamente 3 millones de veces por segundo. Si la sonda se mueve 100 mil o un millón de veces por segundo en un procesador multinúcleo, esto no afectará demasiado el rendimiento.Frontend para eBPF
Si está interesado en eBPF y el tema de la Observabilidad en general, probablemente haya oído hablar de Brendan Gregg. Escribe y habla mucho sobre esto e hizo una imagen tan hermosa que muestra herramientas para eBPF. Aquí puede ver que, por ejemplo, puede usar Raw BPF, solo escriba bytecode, esto le dará una gama completa de características, pero será muy difícil trabajar con él. Raw BPF trata sobre cómo escribir una aplicación web en ensamblador; en principio, es posible, pero sin la necesidad de hacerlo.Curiosamente, bpfTrace, por un lado, le permite obtener casi todo de BCC y BPF sin procesar, pero es mucho más fácil de usar.En mi opinión, dos herramientas son las más útiles:
Aquí puede ver que, por ejemplo, puede usar Raw BPF, solo escriba bytecode, esto le dará una gama completa de características, pero será muy difícil trabajar con él. Raw BPF trata sobre cómo escribir una aplicación web en ensamblador; en principio, es posible, pero sin la necesidad de hacerlo.Curiosamente, bpfTrace, por un lado, le permite obtener casi todo de BCC y BPF sin procesar, pero es mucho más fácil de usar.En mi opinión, dos herramientas son las más útiles:- BCC A pesar del hecho de que de acuerdo con el esquema de Gregg, BCC es complejo, incluye muchas funciones listas para usar que simplemente se pueden iniciar desde la línea de comandos.
- BpfTrace . Le permite simplemente escribir su propio kit de herramientas o usar soluciones preparadas.
Puedes imaginar lo fácil que es escribir en bpfTrace si miras el código de la misma herramienta en dos versiones.
DTrace vs bpfTrace
En general, DTrace y bpfTrace se usan para lo mismo. http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlLa diferencia es que también hay un BCC en el ecosistema BPF que puede usarse para herramientas complejas. No hay un equivalente de BCC en DTrace, por lo tanto, para hacer kits de herramientas complejos, generalmente use el paquete Shell + DTrace.Al crear bpfTrace, no había tarea para emular completamente DTrace. Es decir, no puede tomar un script DTrace y ejecutarlo en bpfTrace. Pero esto no tiene mucho sentido, porque la lógica en las herramientas de nivel inferior es bastante simple. Por lo general, es más importante comprender a qué puntos de rastreo necesita conectarse, y los nombres de las llamadas al sistema y lo que hacen directamente a un nivel bajo difieren en Linux, Solaris, FreeBSD. Ahí es donde surge la diferencia.En este caso, bpfTrace se realiza 15 años después de DTrace. Tiene algunas características adicionales que DTrace no tiene. Por ejemplo, puede hacer rastros de pila.Pero, por supuesto, mucho se hereda de DTrace. Por ejemplo, los nombres de funciones y la sintaxis son similares , aunque no completamente equivalentes.Los scripts DTrace y bpfTrace tienen un tamaño de código cercano y una complejidad similar y capacidades de lenguaje similares.
http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlLa diferencia es que también hay un BCC en el ecosistema BPF que puede usarse para herramientas complejas. No hay un equivalente de BCC en DTrace, por lo tanto, para hacer kits de herramientas complejos, generalmente use el paquete Shell + DTrace.Al crear bpfTrace, no había tarea para emular completamente DTrace. Es decir, no puede tomar un script DTrace y ejecutarlo en bpfTrace. Pero esto no tiene mucho sentido, porque la lógica en las herramientas de nivel inferior es bastante simple. Por lo general, es más importante comprender a qué puntos de rastreo necesita conectarse, y los nombres de las llamadas al sistema y lo que hacen directamente a un nivel bajo difieren en Linux, Solaris, FreeBSD. Ahí es donde surge la diferencia.En este caso, bpfTrace se realiza 15 años después de DTrace. Tiene algunas características adicionales que DTrace no tiene. Por ejemplo, puede hacer rastros de pila.Pero, por supuesto, mucho se hereda de DTrace. Por ejemplo, los nombres de funciones y la sintaxis son similares , aunque no completamente equivalentes.Los scripts DTrace y bpfTrace tienen un tamaño de código cercano y una complejidad similar y capacidades de lenguaje similares.
bpfTrace
Veamos con más detalle qué hay en bpfTrace, cómo se puede usar y qué se necesita para esto.Requisitos de Linux para usar bpfTrace: Para usar todas las funciones, necesita una versión de al menos 4.9. BpfTrace le permite hacer muchas sondas diferentes, comenzando con uprobe para instrumentar una llamada de función en una aplicación de usuario, sondas de kernel, etc.
Para usar todas las funciones, necesita una versión de al menos 4.9. BpfTrace le permite hacer muchas sondas diferentes, comenzando con uprobe para instrumentar una llamada de función en una aplicación de usuario, sondas de kernel, etc. Curiosamente, hay una sonda de uret equivalente para una función de levantamiento personalizada. Para kernel, lo mismo es kprobe y kretprobe. Esto significa que, de hecho, en el marco de seguimiento puede generar eventos cuando se llama a la función y una vez completada esta función, esto se usa a menudo para la temporización. O puede analizar los valores que devolvió la función y agruparlos de acuerdo con los parámetros con los que se llamó a la función. Si captura una llamada de función y regresa de ella, puede hacer muchas cosas interesantes.Dentro de bpfTrace funciona así: escribimos un programa bpf que se analiza, se convierte a C, luego se procesa a través de Clang, que genera el código de byte bpf, luego de lo cual se carga el programa.
Curiosamente, hay una sonda de uret equivalente para una función de levantamiento personalizada. Para kernel, lo mismo es kprobe y kretprobe. Esto significa que, de hecho, en el marco de seguimiento puede generar eventos cuando se llama a la función y una vez completada esta función, esto se usa a menudo para la temporización. O puede analizar los valores que devolvió la función y agruparlos de acuerdo con los parámetros con los que se llamó a la función. Si captura una llamada de función y regresa de ella, puede hacer muchas cosas interesantes.Dentro de bpfTrace funciona así: escribimos un programa bpf que se analiza, se convierte a C, luego se procesa a través de Clang, que genera el código de byte bpf, luego de lo cual se carga el programa. El proceso es bastante difícil, por lo que hay limitaciones. En servidores potentes, bpfTrace funciona bien. Pero arrastrar Clang a un pequeño dispositivo integrado para descubrir qué está pasando no es una buena idea. Ply es adecuado para esto . Por supuesto, no tiene todas las características de bpfTrace, pero genera bytecode directamente.
El proceso es bastante difícil, por lo que hay limitaciones. En servidores potentes, bpfTrace funciona bien. Pero arrastrar Clang a un pequeño dispositivo integrado para descubrir qué está pasando no es una buena idea. Ply es adecuado para esto . Por supuesto, no tiene todas las características de bpfTrace, pero genera bytecode directamente.Soporte de Linux
Hace aproximadamente un año se lanzó una versión estable de bpfTrace, por lo que no está disponible en distribuciones de Linux anteriores. Es mejor tomar paquetes o compilar la última versión que distribuye IO Visor.Curiosamente, el último Ubuntu LTS 18.04 no tiene bpfTrace, pero puede entregarse usando el paquete snap. Por un lado, esto es conveniente, pero por otro lado, debido a la forma en que se hacen y aíslan los paquetes a presión, no todas las funciones funcionarán. Para el rastreo del kernel, un paquete con snap funciona bien; para el rastreo del usuario, puede que no funcione correctamente.
Ejemplo de rastreo de procesos
Considere el ejemplo más simple que le permite obtener estadísticas sobre las solicitudes de E / S:bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
Aquí nos conectamos a la función vfs_read, tanto kretprobe como kprobe. Además, para cada ID de subproceso (tid), es decir, para cada solicitud, rastreamos el comienzo y el final de su ejecución. Los datos se pueden agrupar no solo por la totalidad del sistema completo, sino también por diferentes procesos. A continuación se muestra la salida IO para MySQL. La distribución de E / S bimodal clásica es visible. Una gran cantidad de solicitudes rápidas son datos que se leen del caché. El segundo pico es leer datos del disco, donde la latencia es mucho mayor.Puede guardar esto como un script (generalmente se usa la extensión bt), escribir comentarios, formatearlo y simplemente usarlo más
La distribución de E / S bimodal clásica es visible. Una gran cantidad de solicitudes rápidas son datos que se leen del caché. El segundo pico es leer datos del disco, donde la latencia es mucho mayor.Puede guardar esto como un script (generalmente se usa la extensión bt), escribir comentarios, formatearlo y simplemente usarlo más #bpftrace read.bt.// read.bt file
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid]/
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}
El concepto general del lenguaje es bastante simple.- Sintaxis: seleccione la sonda para conectar
probe[,probe,...] /filter/ { action }. - Filtro: especifique un filtro, por ejemplo, solo datos en un proceso dado de un Pid dado.
- Acción: un mini programa que se convierte directamente en un programa bpf y se ejecuta cuando se llama a bpfTrace.
Más detalles se pueden encontrar aquí .Herramientas bpftrace
BpfTrace también tiene una caja de herramientas. Muchas herramientas bastante simples en BCC ahora se implementan en bpfTrace. La colección aún es pequeña, pero hay algo que no está en el BCC. Por ejemplo, killsnoop le permite rastrear las señales causadas por kill ().Si está interesado en mirar el código bpf, en bpfTrace puede
La colección aún es pequeña, pero hay algo que no está en el BCC. Por ejemplo, killsnoop le permite rastrear las señales causadas por kill ().Si está interesado en mirar el código bpf, en bpfTrace puede -vver el código de byte generado. Esto es útil si desea comprender una sonda pesada o no. Después de mirar el código y solo haber estimado su tamaño (una o dos páginas), puedes entender lo complicado que es.
Ejemplo de rastreo de MySQL
Déjame mostrarte un ejemplo de MySQL, cómo funciona. MySQL tiene una función dispatch_commanden la cual ocurren todas las ejecuciones de consultas MySQL.bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
failed to stat uprobe target file /usr/sbin/mysqld: No such file or directory
Solo quería conectar un uprobe para imprimir el texto de las consultas que llegan a MySQL, una tarea primitiva. Tengo un problema: dice que no existe tal archivo. Como no cuando aquí está:root@mysql1:/# ls -la /usr/sbin/mysqld
-rwxr-xr-x 1 root root 60718384 Oct 25 09:19 /usr/sbin/mysqld
Estas son solo sorpresas con snap. Si se establece mediante snap, puede haber problemas a nivel de aplicación.Luego instalé a través de la versión apt, una nueva Ubuntu, comencé de nuevo:root@mysql1:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
Could not resolve symbol: /usr/sbin/mysqld:dispatch_command
"No hay tal símbolo" - ¿cómo no? Miro nmsi hay tal símbolo o no:root@mysql1:~# nm -D /usr/sbin/mysqld | grep dispatch_command
00000000005af770 T
_Z16dispatch_command19enum_server_commandP3THDPcjbb
root@localhost:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcjbb { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
select @@version_comment limit 1
select 1
Existe dicho símbolo, pero dado que MySQL se compila a partir de C ++, allí se usa la manipulación. De hecho, el nombre actual de la función que se utiliza en esta orden, los siguientes: _Z16dispatch_command19enum_server_commandP3THDPcjbb. Si lo usa en una función, puede conectarse y obtener el resultado. En el ecosistema de perf, muchas herramientas hacen que la eliminación automática se realice automáticamente, y bpfTrace aún no es capaz.También preste atención a la bandera -Dpara nm. Es importante porque MySQL, y ahora muchos otros paquetes, vienen sin símbolos dinámicos (símbolos de depuración); vienen en otros paquetes. Si desea utilizar estos caracteres, necesita una bandera -D, de lo contrario nm no los verá.: ++ 25–26 , . , , .
: ++ Online . 5 900 , , -.
: DevOpsConf 2019 HighLoad++ 2019 — , .
— , .