 Los últimos años en mi tiempo libre he estado haciendo triatlón. Este deporte es muy popular en muchos países del mundo, especialmente en los Estados Unidos, Australia y Europa. Actualmente gana popularidad en Rusia y los países de la CEI. Se trata de involucrar a los aficionados, no a los profesionales. A diferencia de solo nadar en la piscina, andar en bicicleta y trotar por la mañana, un triatlón implica participar en competiciones y preparación sistemática para ellos, incluso sin ser un profesional. Seguramente entre tus amigos ya hay al menos un "hombre de hierro" o alguien que planea convertirse en uno. Masividad, una variedad de distancias y condiciones, tres deportes en uno: todo esto tiene el potencial para la formación de una gran cantidad de datos. Cada año, varios cientos de competiciones de triatlón tienen lugar en el mundo, en el que participan varios cientos de miles de personas.Los concursos son realizados por varios organizadores. Cada uno de ellos, por supuesto, publica los resultados por derecho propio. Pero para los atletas de Rusia y algunos países de la CEI, el equipotristats.ru recopila todos los resultados en un solo lugar: en su sitio web del mismo nombre. Esto hace que sea muy conveniente buscar resultados, tanto los tuyos como los de tus amigos y rivales, o incluso tus ídolos. Pero para mí también me dio la oportunidad de analizar una gran cantidad de resultados mediante programación. Resultados publicados en trilife: leer .Este fue mi primer proyecto de este tipo, porque solo recientemente comencé a hacer análisis de datos en principio, así como a usar Python. Por lo tanto, quiero contarles sobre la implementación técnica de este trabajo, especialmente porque en el proceso, surgieron varios matices, que a veces requieren un enfoque especial. Se tratará de desguace, análisis, conversión de tipos y formatos, restauración de datos incompletos, creación de una muestra representativa, visualización, vectorización e incluso computación paralela.El volumen resultó ser grande, así que dividí todo en cinco partes para poder dosificar la información y recordar por dónde empezar después del descanso.Antes de continuar, es mejor leer primero mi artículo con los resultados del estudio, porque aquí esencialmente se describe la cocina para su creación. Tarda entre 10 y 15 minutos.¿Has leído? ¡Entonces vamos!
Los últimos años en mi tiempo libre he estado haciendo triatlón. Este deporte es muy popular en muchos países del mundo, especialmente en los Estados Unidos, Australia y Europa. Actualmente gana popularidad en Rusia y los países de la CEI. Se trata de involucrar a los aficionados, no a los profesionales. A diferencia de solo nadar en la piscina, andar en bicicleta y trotar por la mañana, un triatlón implica participar en competiciones y preparación sistemática para ellos, incluso sin ser un profesional. Seguramente entre tus amigos ya hay al menos un "hombre de hierro" o alguien que planea convertirse en uno. Masividad, una variedad de distancias y condiciones, tres deportes en uno: todo esto tiene el potencial para la formación de una gran cantidad de datos. Cada año, varios cientos de competiciones de triatlón tienen lugar en el mundo, en el que participan varios cientos de miles de personas.Los concursos son realizados por varios organizadores. Cada uno de ellos, por supuesto, publica los resultados por derecho propio. Pero para los atletas de Rusia y algunos países de la CEI, el equipotristats.ru recopila todos los resultados en un solo lugar: en su sitio web del mismo nombre. Esto hace que sea muy conveniente buscar resultados, tanto los tuyos como los de tus amigos y rivales, o incluso tus ídolos. Pero para mí también me dio la oportunidad de analizar una gran cantidad de resultados mediante programación. Resultados publicados en trilife: leer .Este fue mi primer proyecto de este tipo, porque solo recientemente comencé a hacer análisis de datos en principio, así como a usar Python. Por lo tanto, quiero contarles sobre la implementación técnica de este trabajo, especialmente porque en el proceso, surgieron varios matices, que a veces requieren un enfoque especial. Se tratará de desguace, análisis, conversión de tipos y formatos, restauración de datos incompletos, creación de una muestra representativa, visualización, vectorización e incluso computación paralela.El volumen resultó ser grande, así que dividí todo en cinco partes para poder dosificar la información y recordar por dónde empezar después del descanso.Antes de continuar, es mejor leer primero mi artículo con los resultados del estudio, porque aquí esencialmente se describe la cocina para su creación. Tarda entre 10 y 15 minutos.¿Has leído? ¡Entonces vamos!Parte 1. Raspado y análisis
Dado: Sitio web tristats.ru . Hay dos tipos de tablas que nos interesan. Esta es en realidad una tabla resumen de todas las razas y un protocolo de los resultados de cada una de ellas.
 La tarea número uno era obtener estos datos mediante programación y guardarlos para su posterior procesamiento. Dio la casualidad de que en ese momento era nuevo en las tecnologías web y, por lo tanto, no sabía de inmediato cómo hacerlo. Empecé de acuerdo con lo que sabía: mira el código de la página. Esto se puede hacer usando el botón derecho del mouse o la tecla F12 .
La tarea número uno era obtener estos datos mediante programación y guardarlos para su posterior procesamiento. Dio la casualidad de que en ese momento era nuevo en las tecnologías web y, por lo tanto, no sabía de inmediato cómo hacerlo. Empecé de acuerdo con lo que sabía: mira el código de la página. Esto se puede hacer usando el botón derecho del mouse o la tecla F12 . El menú en Chrome contiene dos opciones: Ver código de página y Ver código . No es la división más obvia. Naturalmente, dan resultados diferentes. El que ve el código, es lo mismo que F12 : la representación html directamente textual de lo que se muestra en el navegador es de elementos.
El menú en Chrome contiene dos opciones: Ver código de página y Ver código . No es la división más obvia. Naturalmente, dan resultados diferentes. El que ve el código, es lo mismo que F12 : la representación html directamente textual de lo que se muestra en el navegador es de elementos.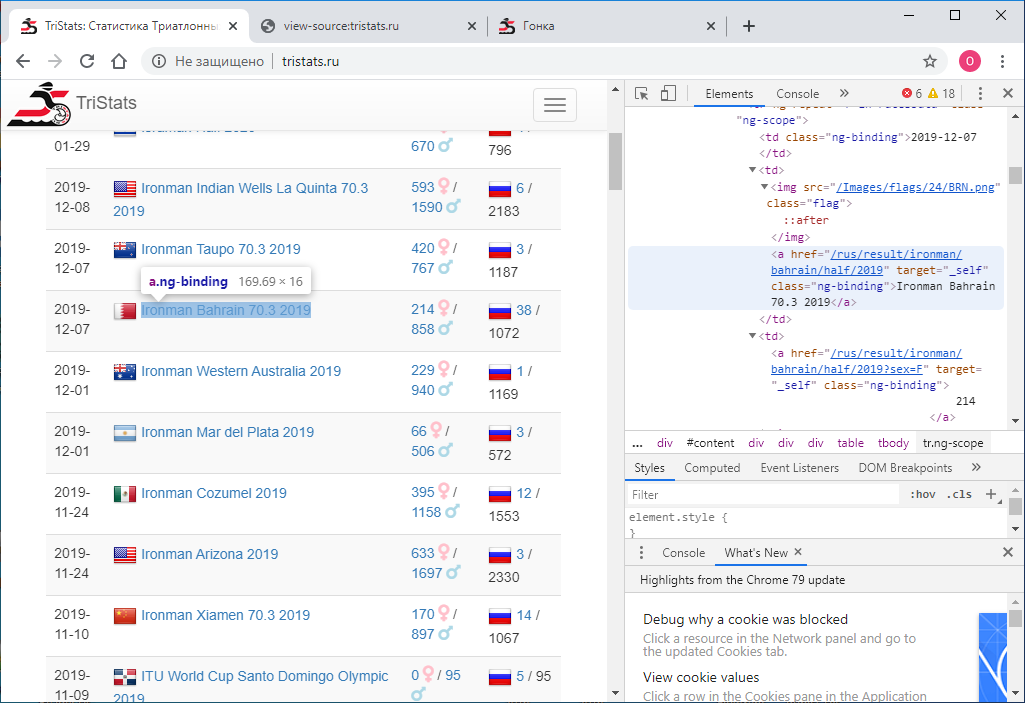 A su vez, ver el código de la página proporciona el código fuente de la página. También html , pero no hay datos allí, solo los nombres de los scripts JS que los descargan. Bueno.
A su vez, ver el código de la página proporciona el código fuente de la página. También html , pero no hay datos allí, solo los nombres de los scripts JS que los descargan. Bueno. Ahora tenemos que entender cómo usar Python para guardar el código de cada página como un archivo de texto separado. Intento esto:
Ahora tenemos que entender cómo usar Python para guardar el código de cada página como un archivo de texto separado. Intento esto:import requests
r = requests.get(url='http://tristats.ru/')
print(r.content)
Y consigo ... el código fuente. Pero necesito el resultado de su ejecución. Después de estudiar, buscar y preguntar, me di cuenta de que necesitaba una herramienta para automatizar las acciones del navegador, por ejemplo, selenio . Lo puse. Y también ChromeDriver para trabajar con Google Chrome . Luego lo usé de la siguiente manera:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
print(driver.page_source)
driver.quit()
Este código inicia una ventana del navegador y abre una página en la URL especificada. Como resultado, obtenemos el código html con los datos deseados. Pero hay un inconveniente. El resultado son solo 100 entradas, y el número total de carreras es casi 2000. ¿Cómo es eso? El hecho es que inicialmente solo se muestran las primeras 100 entradas en el navegador, y solo si se desplaza hasta el final de la página, se cargan las siguientes 100, y así sucesivamente. Por lo tanto, es necesario implementar el desplazamiento mediante programación. Para hacer esto, use el comando:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
Y con cada desplazamiento, verificaremos si el código de la página cargada ha cambiado o no. Si no ha cambiado, verificaremos la confiabilidad varias veces, por ejemplo 10, luego se carga toda la página y puede detenerse. Entre los pergaminos, establecemos el tiempo de espera en un segundo para que la página tenga tiempo de cargarse. (Incluso si no tiene tiempo, tenemos una reserva, otros nueve segundos).Y el código completo se verá así:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
prev_html = ''
scroll_attempt = 0
while scroll_attempt < 10:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
if prev_html == driver.page_source:
scroll_attempt += 1
else:
prev_html = driver.page_source
scroll_attempt = 0
with open(r'D:\tri\summary.txt', 'w') as f:
f.write(prev_html)
driver.quit()
Entonces, tenemos un archivo html con una tabla resumen de todas las razas. Necesito analizarlo. Para hacer esto, use la biblioteca lxml .from lxml import html
Primero encontramos todas las filas de la tabla. Para determinar el signo de una cadena, solo mira el archivo html en un editor de texto. Puede ser, por ejemplo, “tr ng-repeat = 'r in racingData' class = 'ng-scope'” o algún fragmento que ya no se puede encontrar en ninguna etiqueta.
Puede ser, por ejemplo, “tr ng-repeat = 'r in racingData' class = 'ng-scope'” o algún fragmento que ya no se puede encontrar en ninguna etiqueta.with open(r'D:\tri\summary.txt', 'r') as f:
sum_html = f.read()
tree = html.fromstring(sum_html)
rows = tree.findall(".//*[@ng-repeat='r in racesData']")
entonces comenzamos el marco de datos de pandas y cada elemento de cada fila de la tabla se escribe en este marco de datos.import pandas as pd
rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows)))
Para averiguar dónde está oculto cada elemento específico, solo necesita mirar el código html de uno de los elementos de nuestras filas en el mismo editor de texto.<tr ng-repeat="r in racesData" class="ng-scope">
<td class="ng-binding">2015-04-26</td>
<td>
<img src="/Images/flags/24/USA.png" class="flag">
<a href="/rus/result/ironman/texas/half/2015" target="_self" class="ng-binding">Ironman Texas 70.3 2015</a>
</td>
<td>
<a href="/rus/result/ironman/texas/half/2015?sex=F" target="_self" class="ng-binding">605</a>
<i class="fas fa-venus fa-lg" style="color:Pink"></i>
/
<a href="/rus/result/ironman/texas/half/2015?sex=M" target="_self" class="ng-binding">1539</a>
<i class="fas fa-mars fa-lg" style="color:LightBlue"></i>
</td>
<td class="ng-binding">
<img src="/Images/flags/24/rus.png" class="flag">
<a ng-if="r.CountryCount > 0" href="/rus/result/ironman/texas/half/2015?country=rus" target="_self" class="ng-binding ng-scope">2</a>
/ 2144
</td>
</tr>
La forma más fácil de codificar la navegación para niños aquí es que no hay muchos de ellos.for i in range(len(rows)):
rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip()
rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip()
rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip()
rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip()
rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip()
rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip()
rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
Aquí está el resultado: guarde este marco de datos en un archivo. Yo uso pickle , pero podría ser csv u otra cosa.import pickle as pkl
with open(r'D:\tri\summary.pkl', 'wb') as f:
pkl.dump(df,f)
En esta etapa, todos los datos son de tipo cadena. Nos convertiremos más tarde. Lo más importante que necesitamos ahora es enlaces. Los usaremos para raspar protocolos de todas las razas. Lo hacemos a imagen y semejanza de cómo se hizo para la tabla dinámica. En el ciclo de todas las carreras para cada uno, abriremos la página por referencia, nos desplazaremos y obtendremos el código de la página. En la tabla de resumen tenemos información sobre el número total de participantes en la carrera - total, lo utilizaremos para comprender hasta qué punto necesita continuar desplazándose. Para hacer esto, directamente en el proceso de raspar cada página determinaremos el número de registros en la tabla y lo compararemos con el valor esperado del total. Tan pronto como sea igual, nos desplazamos hasta el final y puedes pasar a la próxima carrera. También establecemos un tiempo de espera de 60 segundos. Comimos durante este tiempo, no llegamos al total , vamos a la próxima carrera. El código de la página se guardará en un archivo. Guardaremos los archivos de todas las carreras en una carpeta y los nombraremos por el nombre de las carreras, es decir, por el valor en la columna de eventos en la tabla de resumen. Para evitar un conflicto de nombres, es necesario que todas las razas tengan nombres diferentes en la tabla dinámica. Mira esto:df[df.duplicated(subset = 'event', keep=False)]
service.start()
driver = webdriver.Remote(service.service_url)
timeout = 60
for index, row in df.iterrows():
try:
driver.get('http://www.tristats.ru' + row['link'])
start = time.time()
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
race_html = driver.page_source
tree = html.fromstring(race_html)
race_rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
if len(race_rows) == int(row['total']):
break
if time.time() - start > timeout:
print('timeout')
break
with open(os.path.join(r'D:\tri\races', row['event'] + '.txt'), 'w') as f:
f.write(race_html)
except:
traceback.print_exc()
time.sleep(1)
driver.quit()
Este es un proceso largo. Pero cuando todo está configurado y este mecanismo pesado comienza a girar, agregando archivos de datos uno tras otro, surge una sensación de emoción agradable. Solo se cargan unos tres protocolos por minuto, muy lentamente. Se fue a girar por la noche. Tomó alrededor de 10 horas. Por la mañana, la mayoría de los protocolos fueron cargados. Como suele suceder cuando se trabaja con una red, algunos fallan. Los reanudó rápidamente con un segundo intento.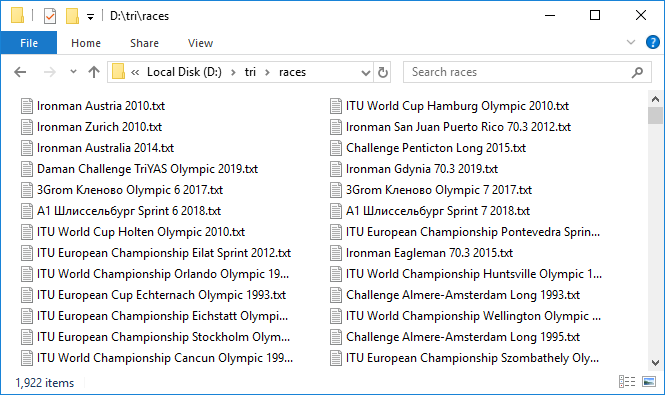 Entonces, tenemos 1,922 archivos con una capacidad total de casi 3 GB. ¡Frio! Pero manejar casi 300 carreras terminó en un tiempo de espera. ¿Cuál es el problema? Verificación selectiva, resulta que de hecho el valor total de la tabla dinámica y el número de entradas en el protocolo de carrera que verificamos pueden no coincidir. Esto es triste porque no está claro cuál es la razón de esta discrepancia. O esto se debe al hecho de que no todos terminarán, o algún tipo de error en la base de datos. En general, la primera señal de imperfección de datos. En cualquier caso, verificamos aquellos en los que el número de entradas es 100 o 0, estos son los candidatos más sospechosos. Había ocho de ellos. Descárguelos nuevamente bajo control cercano. Por cierto, en dos de ellos hay en realidad 100 entradas.Bueno, tenemos todos los datos. Pasamos al análisis. Nuevamente, en un ciclo recorreremos cada carrera, leeremos el archivo y guardaremos el contenido en un DataFrame de pandas . Combinaremos estos marcos de datos en un dict , en el que los nombres de las carreras son las claves, es decir, los valores del evento de la tabla dinámica o los nombres de los archivos con el código html de las páginas de la carrera, coinciden.
Entonces, tenemos 1,922 archivos con una capacidad total de casi 3 GB. ¡Frio! Pero manejar casi 300 carreras terminó en un tiempo de espera. ¿Cuál es el problema? Verificación selectiva, resulta que de hecho el valor total de la tabla dinámica y el número de entradas en el protocolo de carrera que verificamos pueden no coincidir. Esto es triste porque no está claro cuál es la razón de esta discrepancia. O esto se debe al hecho de que no todos terminarán, o algún tipo de error en la base de datos. En general, la primera señal de imperfección de datos. En cualquier caso, verificamos aquellos en los que el número de entradas es 100 o 0, estos son los candidatos más sospechosos. Había ocho de ellos. Descárguelos nuevamente bajo control cercano. Por cierto, en dos de ellos hay en realidad 100 entradas.Bueno, tenemos todos los datos. Pasamos al análisis. Nuevamente, en un ciclo recorreremos cada carrera, leeremos el archivo y guardaremos el contenido en un DataFrame de pandas . Combinaremos estos marcos de datos en un dict , en el que los nombres de las carreras son las claves, es decir, los valores del evento de la tabla dinámica o los nombres de los archivos con el código html de las páginas de la carrera, coinciden.rd = {}
for e in rs['event']:
place = []
... sex = [], name=..., country, group, place_in_group, swim, t1, bike, t2, run
result = []
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r')
race_html = f.read()
tree = html.fromstring(race_html)
rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
for j in range(len(rows)):
row = rows[j]
parts = row.text_content().split('\n')
parts = [r.strip() for r in parts if r.strip() != '']
place.append(parts[0])
if len([a for a in row.findall('.//i')]) > 0:
sex.append([a for a in row.findall('.//i')][0].attrib['ng-if'][10:-1])
else:
sex.append('')
name.append(parts[1])
if len(parts) > 10:
country.append(parts[2].strip())
k=0
else:
country.append('')
k=1
group.append(parts[3-k])
... place_in_group.append(...), swim.append ..., t1, bike, t2, run
result.append(parts[10-k])
race = pd.DataFrame()
race['place'] = place
... race['sex'] = sex, race['name'] = ..., 'country', 'group', 'place_in_group', 'swim', ' t1', 'bike', 't2', 'run'
race['result'] = result
rd[e] = race
with open(r'D:\tri\details.pkl', 'wb') as f:
pkl.dump(rd,f)
for index, row in rs.iterrows():
e = row['event']
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') as f:
race_html = f.read()
tree = html.fromstring(race_html)
header_elem = [tb for tb in tree.findall('.//tbody') if tb.getchildren()[0].getchildren()[0].text == ''][0]
location = header_elem.getchildren()[1].getchildren()[1].text.strip()
rs.loc[index, 'loc'] = location
with open(r'D:\tri\summary1.pkl', 'wb') as f:
pkl.dump(df,f)
Parte 2. Tipo de fundición y formato
Entonces, descargamos todos los datos y los colocamos en los marcos de datos. Sin embargo, todos los valores son de tipo str . Esto se aplica a la fecha, a los resultados, a la ubicación y a todos los demás parámetros. Todos los parámetros deben convertirse a los tipos apropiados.Comencemos con la tabla dinámica.fecha y hora
event , loc y link se dejarán como están. date convert a pandas datetime de la siguiente manera:rs['date'] = pd.to_datetime(rs['date'])
El resto se convierte a un tipo entero:cols = ['males', 'females', 'rus', 'total']
rs[cols] = rs[cols].astype(int)
Todo salió bien, no surgieron errores. Así que todo está bien, guarde:with open(r'D:\tri\summary2.pkl', 'wb') as f:
pkl.dump(rs, f)
Ahora carreras de marcos de datos. Dado que todas las carreras son más convenientes y más rápidas de procesar a la vez, y no una a la vez, las recopilaremos en un marco de datos ar grande (abreviatura de todos los registros ) utilizando el método concat .ar = pd.concat(rd)
ar contiene 1.416.365 entradas.Ahora convierta lugar y lugar en grupo a un valor entero.ar[['place', 'place in group']] = ar[['place', 'place in group']].astype(int))
A continuación, procesamos las columnas con valores temporales. Los lanzaremos en el tipo Timedelta de pandas . Pero para que la conversión tenga éxito, debe preparar adecuadamente los datos. Puede ver que algunos valores que son menos de una hora pasan sin especificar la punta. Necesito agregarlo.for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
strlen = ar[col].str.len()
ar.loc[strlen==5, col] = '0:' + ar.loc[strlen==5, col]
ar.loc[strlen==4, col] = '0:0' + ar.loc[strlen==4, col]
Ahora, las cadenas restantes aún se ven así: Convertir a Timedelta :for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
ar[col] = pd.to_timedelta(ar[col])
Suelo
Siga adelante. Comprueba que en la columna de sexo solo hay valores de M y F :ar['sex'].unique()
Out: ['M', 'F', '']
De hecho, todavía hay una cadena vacía, es decir, el género no está especificado. Veamos cuántos de estos casos:len(ar[ar['sex'] == ''])
Out: 2538
No tanto es bueno. En el futuro, intentaremos reducir aún más este valor. Mientras tanto, deje la columna de sexo tal como está en forma de líneas. Guardaremos el resultado antes de pasar a transformaciones más serias y riesgosas. Para mantener la continuidad entre los archivos, transformamos el marco de datos combinado ar nuevamente en el diccionario de marcos de datos rd :for event in ar.index.get_level_values(0).unique():
rd[event] = ar.loc[event]
with open(r'D:\tri\details1.pkl', 'wb') as f:
pkl.dump(rd,f)
Por cierto, debido a la conversión de los tipos de algunas columnas, el tamaño de los archivos disminuyó de 367 KB a 295 KB para la tabla dinámica y de 251 MB a 168 MB para los protocolos de carreras.Código de país
Ahora veamos el país.ar['country'].unique()
Out: ['CRO', 'CZE', 'SLO', 'SRB', 'BUL', 'SVK', 'SWE', 'BIH', 'POL', 'MK', 'ROU', 'GRE', 'FRA', 'HUN', 'NOR', 'AUT', 'MNE', 'GBR', 'RUS', 'UAE', 'USA', 'GER', 'URU', 'CRC', 'ITA', 'DEN', 'TUR', 'SUI', 'MEX', 'BLR', 'EST', 'NED', 'AUS', 'BGI', 'BEL', 'ESP', 'POR', 'UKR', 'CAN', 'IRL', 'JPN', 'HKG', 'JEY', 'SGP', 'BRA', 'QAT', 'LUX', 'RSA', 'NZL', 'LAT', 'PHI', 'KSA', 'SEY', 'MAS', 'OMA', 'ARG', 'ECU', 'THA', 'JOR', 'BRN', 'CIV', 'FIN', 'IRN', 'BER', 'LBA', 'KUW', 'LTU', 'SRI', 'HON', 'INA', 'LBN', 'PAN', 'EGY', 'MLT', 'WAL', 'ISL', 'CYP', 'DOM', 'IND', 'VIE', 'MRI', 'AZE', 'MLD', 'LIE', 'VEN', 'ALG', 'SYR', 'MAR', 'KZK', 'PER', 'COL', 'IRQ', 'PAK', 'CZK', 'KAZ', 'CHN', 'NEP', 'ISR', 'MKD', 'FRO', 'BAN', 'ARU', 'CPV', 'ALB', 'BIZ', 'TPE', 'KGZ', 'BNN', 'CUB', 'SNG', 'VTN', 'THI', 'PRG', 'KOR', 'RE', 'TW', 'VN', 'MOL', 'FRE', 'AND', 'MDV', 'GUA', 'MON', 'ARM', 'F.I.TRI.', 'BAHREIN', 'SUECIA', 'REPUBLICA CHECA', 'BRASIL', 'CHI', 'MDA', 'TUN', 'NDL', 'Danish(Dane)', 'Welsh', 'Austrian', 'Unknown', 'AFG', 'Argentinean', 'Pitcairn', 'South African', 'Greenland', 'ESTADOS UNIDOS', 'LUXEMBURGO', 'SUDAFRICA', 'NUEVA ZELANDA', 'RUMANIA', 'PM', 'BAH', 'LTV', 'ESA', 'LAB', 'GIB', 'GUT', 'SAR', 'ita', 'aut', 'ger', 'esp', 'gbr', 'hun', 'den', 'usa', 'sui', 'slo', 'cze', 'svk', 'fra', 'fin', 'isr', 'irn', 'irl', 'bel', 'ned', 'sco', 'pol', 'SMR', 'mex', 'STEEL T BG', 'KINO MANA', 'IVB', 'TCH', 'SCO', 'KEN', 'BAS', 'ZIM', 'Joe', 'PUR', 'SWZ', 'Mark', 'WLS', 'MYA', 'BOT', 'REU', 'NAM', 'NCL', 'BOL', 'GGY', 'ISV', 'TWN', 'GUM', 'FIJ', 'COK', 'NGR', 'IRI', 'GAB', 'ANT', 'GEO', 'COG', 'sue', 'SUD', 'BAR', 'CAY', 'BO', 'VE', 'AX', 'MD', 'PAR', 'UM', 'SEN', 'NIG', 'RWA', 'YEM', 'PLE', 'GHA', 'ITU', 'UZB', 'MGL', 'MAC', 'DMA', 'TAH', 'TTO', 'AHO', 'JAM', 'SKN', 'GRN', 'PRK', 'NFK', 'SOL', 'Sandy', 'SAM', 'PNG', 'SGS', 'Suchy, Jorg', 'SOG', 'GEQ', 'BVT', 'DJI', 'CHA', 'ANG', 'YUG', 'IOT', 'HAI', 'SJM', 'CUW', 'BHU', 'ERI', 'FLK', 'HMD', 'GUF', 'ESH', 'sandy', 'UMI', 'selsmark, 'Alise', 'Eddie', '31/3, Colin', 'CC', '', '', '', '', '', ' ', '', '', '', '-', '', 'GRL', 'UGA', 'VAT', 'ETH', 'ASA', 'PYF', 'ATA', 'ALA', 'MTQ', 'ZZ', 'CXR', 'AIA', 'TJK', 'GUY', 'KR', 'PF', 'BN', 'MO', 'LA', 'CAM', 'NCA', 'ZAM', 'MAD', 'TOG', 'VIR', 'ATF', 'VAN', 'SLE', 'GLP', 'SCG', 'LAO', 'IMN', 'BUR', 'IR', 'SY', 'CMR', 'GBS', 'SUR', 'MOZ', 'BLM', 'MSR', 'CAF', 'BEN', 'COD', 'CCK', 'TUV', 'TGA', 'GI', 'XKX', 'NRU', 'NC', 'LBR', 'TAN', 'VIN', 'SSD', 'GP', 'PS', 'IM', 'JE', '', 'MLI', 'FSM', 'LCA', 'GMB', 'MHL', 'NH', 'FL', 'CT', 'UT', 'AQ', 'Korea', 'Taiwan', 'NewCaledonia', 'Czech Republic', 'PLW', 'BRU', 'RUN', 'NIU', 'KIR', 'SOM', 'TKM', 'SPM', 'BDI', 'COM', 'TCA', 'SHN', 'DO2', 'DCF', 'PCN', 'MNP', 'MYT', 'SXM', 'MAF', 'GUI', 'AN', 'Slovak republic', 'Channel Islands', 'Reunion', 'Wales', 'Scotland', 'ica', 'WLF', 'D', 'F', 'I', 'B', 'L', 'E', 'A', 'S', 'N', 'H', 'R', 'NU', 'BES', 'Bavaria', 'TLS', 'J', 'TKL', 'Tirol"', 'P', '?????', 'EU', 'ES-IB', 'ES-CT', '', 'SOO', 'LZE', '', '', '', '', '', '']
412 valores únicos.Básicamente, un país se indica mediante un código de letra de tres dígitos en mayúsculas. Pero al parecer, no siempre. De hecho, existe una norma internacional ISO 3166 , en la que para todos los países, incluso aquellos que ya no existen, se prescriben los códigos correspondientes de tres y dos dígitos. Para python, una de las implementaciones de este estándar se puede encontrar en el paquete pycountry . Así es como funciona:import pycountry as pyco
pyco.countries.get(alpha_3 = 'RUS')
Out: Country(alpha_2='RU', alpha_3='RUS', name='Russian Federation', numeric='643')
Por lo tanto, verificaremos todos los códigos de tres dígitos, que llevan a mayúsculas, que dan una respuesta en country.get (...) e historic_countries.get (...) :valid_a3 = [c for c in ar['country'].unique() if pyco.countries.get(alpha_3 = c.upper()) != None or pyco.historic_countries.get(alpha_3 = c.upper()) != None])
Había 190 de 412 de ellos, es decir, menos de la mitad.Para los 222 restantes (denotamos su lista por tofix ), crearemos un diccionario de coincidencia de arreglos , en el que la clave será el nombre original, y el valor es un código de tres dígitos de acuerdo con el estándar ISO.tofix = list(set(ar['country'].unique()) - set(valid_a3))
Primero, verifique los códigos de dos dígitos con pycountry.countries.get (alpha_2 = ...) , lo que lleva a mayúsculas:for icc in tofix:
if pyco.countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.countries.get(alpha_2 = icc.upper()).alpha_3
else:
if pyco.historic_countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.historic_countries.get(alpha_2 = icc.upper()).alpha_3
Luego, los nombres completos a través de pycountry.countries.get (name = ...), pycountry.countries.get (common_name = ...) , llevándolos al formulario str.title () :for icc in tofix:
if pyco.countries.get(common_name = icc.title()) != None:
fix[icc] = pyco.countries.get(common_name = icc.title()).alpha_3
else:
if pyco.countries.get(name = icc.title()) != None:
fix[icc] = pyco.countries.get(name = icc.title()).alpha_3
else:
if pyco.historic_countries.get(name = icc.title()) != None:
fix[icc] = pyco.historic_countries.get(name = icc.title()).alpha_3
Por lo tanto, reducimos el número de valores no reconocidos a 190. Todavía bastante: puede notar que entre ellos todavía hay muchos códigos de tres dígitos, pero esto no es un ISO. ¿Entonces que? Resulta que hay otro estándar: olímpico . Desafortunadamente, su implementación no está incluida en pycountry y hay que buscar otra cosa. La solución se encontró en forma de un archivo csv en datahub.io . Coloque el contenido de este archivo en un DataFrame de pandas llamado cdf . ioc - Comité Olímpico Internacional (COI)['URU', '', 'PAR', 'SUECIA', 'KUW', 'South African', '', 'Austrian', 'ISV', 'H', 'SCO', 'ES-CT', ', 'GUI', 'BOT', 'SEY', 'BIZ', 'LAB', 'PUR', ' ', 'Scotland', '', '', 'TCH', 'TGA', 'UT', 'BAH', 'GEQ', 'NEP', 'TAH', 'ica', 'FRE', 'E', 'TOG', 'MYA', '', 'Danish (Dane)', 'SAM', 'TPE', 'MON', 'ger', 'Unknown', 'sui', 'R', 'SUI', 'A', 'GRN', 'KZK', 'Wales', '', 'GBS', 'ESA', 'Bavaria', 'Czech Republic', '31/3, Colin', 'SOL', 'SKN', '', 'MGL', 'XKX', 'WLS', 'MOL', 'FIJ', 'CAY', 'ES-IB', 'BER', 'PLE', 'MRI', 'B', 'KSA', '', '', 'LAT', 'GRE', 'ARU', '', 'THI', 'NGR', 'MAD', 'SOG', 'MLD', '?????', 'AHO', 'sco', 'UAE', 'RUMANIA', 'CRO', 'RSA', 'NUEVA ZELANDA', 'KINO MANA', 'PHI', 'sue', 'Tirol"', 'IRI', 'POR', 'CZK', 'SAR', 'D', 'BRASIL', 'DCF', 'HAI', 'ned', 'N', 'BAHREIN', 'VTN', 'EU', 'CAM', 'Mark', 'BUL', 'Welsh', 'VIN', 'HON', 'ESTADOS UNIDOS', 'I', 'GUA', 'OMA', 'CRC', 'PRG', 'NIG', 'BHU', 'Joe', 'GER', 'RUN', 'ALG', '', 'Channel Islands', 'Reunion', 'REPUBLICA CHECA', 'slo', 'ANG', 'NewCaledonia', 'GUT', 'VIE', 'ASA', 'BAR', 'SRI', 'L', '', 'J', 'BAS', 'LUXEMBURGO', 'S', 'CHI', 'SNG', 'BNN', 'den', 'F.I.TRI.', 'STEEL T BG', 'NCA', 'Slovak republic', 'MAS', 'LZE', '-', 'F', 'BRU', '', 'LBA', 'NDL', 'DEN', 'IVB', 'BAN', 'Sandy', 'ZAM', 'sandy', 'Korea', 'SOO', 'BGI', '', 'LTV', 'selsmark, Alise', 'TAN', 'NED', '', 'Suchy, Jorg', 'SLO', 'SUDAFRICA', 'ZIM', 'Eddie', 'INA', '', 'SUD', 'VAN', 'FL', 'P', 'ITU', 'ZZ', 'Argentinean', 'CHA', 'DO2', 'WAL']
len(([x for x in tofix if x.upper() in list(cdf['ioc'])]))
Out: 82
Entre los códigos de tres dígitos de tofix, se encontraron 82 IOC correspondientes. Agréguelos a nuestro diccionario correspondiente.for icc in tofix:
if icc.upper() in list(cdf['ioc']):
ind = cdf[cdf['ioc'] == icc.upper()].index[0]
fix[icc] = cdf.loc[ind, 'iso3']
Quedan 108 valores brutos. Se terminan manualmente, a veces recurriendo a Google para obtener ayuda. Pero incluso el control manual no resuelve completamente el problema. Quedan 49 valores que ya son imposibles de interpretar. La mayoría de estos valores son probablemente solo errores de datos.{'BGI': 'BRB', 'WAL': 'GBR', 'MLD': 'MDA', 'KZK': 'KAZ', 'CZK': 'CZE', 'BNN': 'BEN', 'SNG': 'SGP', 'VTN': 'VNM', 'THI': 'THA', 'PRG': 'PRT', 'MOL': 'MDA', 'FRE': 'FRA', 'F.I.TRI.': 'ITA', 'BAHREIN': 'BHR', 'SUECIA': 'SWE', 'REPUBLICA CHECA': 'CZE', 'BRASIL': 'BRA', 'NDL': 'NLD', 'Danish (Dane)': 'DNK', 'Welsh': 'GBR', 'Austrian': 'AUT', 'Argentinean': 'ARG', 'South African': 'ZAF', 'ESTADOS UNIDOS': 'USA', 'LUXEMBURGO': 'LUX', 'SUDAFRICA': 'ZAF', 'NUEVA ZELANDA': 'NZL', 'RUMANIA': 'ROU', 'sco': 'GBR', 'SCO': 'GBR', 'WLS': 'GBR', '': 'IND', '': 'IRL', '': 'ARM', '': 'BGR', '': 'SRB', ' ': 'BLR', '': 'GBR', '': 'FRA', '': 'HND', '-': 'CRI', '': 'AZE', 'Korea': 'KOR', 'NewCaledonia': 'FRA', 'Czech Republic': 'CZE', 'Slovak republic': 'SVK', 'Channel Islands': 'FRA', 'Reunion': 'FRA', 'Wales': 'GBR', 'Scotland': 'GBR', 'Bavaria': 'DEU', 'Tirol"': 'AUT', '': 'KGZ', '': 'BLR', '': 'BLR', '': 'BLR', '': 'RUS', '': 'BLR', '': 'RUS'}
unfixed = [x for x in tofix if x not in fix.keys()]
Out: ['', 'H', 'ES-CT', 'LAB', 'TCH', 'UT', 'TAH', 'ica', 'E', 'Unknown', 'R', 'A', '31/3, Colin', 'XKX', 'ES-IB','B','SOG','?????','KINO MANA','sue','SAR','D', 'DCF', 'N', 'EU', 'Mark', 'I', 'Joe', 'RUN', 'GUT', 'L', 'J', 'BAS', 'S', 'STEEL T BG', 'LZE', 'F', 'Sandy', 'DO2', 'sandy', 'SOO', 'LTV', 'selsmark, Alise', 'Suchy, Jorg' 'Eddie', 'FL', 'P', 'ITU', 'ZZ']
Estas claves tendrán una cadena vacía en el diccionario correspondiente.for cc in unfixed:
fix[cc] = ''
Finalmente, agregamos al diccionario códigos coincidentes que son válidos pero escritos en minúsculas.for cc in valid_a3:
if cc.upper() != cc:
fix[cc] = cc.upper()
Ahora es el momento de aplicar los reemplazos encontrados. Para guardar los datos iniciales para su posterior comparación, copiar el país columna de crudo del país . Luego, utilizando el diccionario de coincidencia creado, corregimos los valores en la columna del país que no corresponden a ISO.for cc in fix:
ind = ar[ar['country'] == cc].index
ar.loc[ind,'country'] = fix[cc]
Aquí, por supuesto, uno no puede prescindir de la vectorización, la tabla tiene casi un millón y medio de filas. Pero según el diccionario hacemos un ciclo, pero ¿de qué otra manera? Compruebe cuántos registros se modifican:len(ar[ar['country'] != ar['country raw']])
Out: 315955
es decir, más del 20% del total.ar[ar['country'] != ar['country raw']].sample(10)
len(ar[ar['country'] == ''])
Out: 3221
Este es el número de registros sin un país o con un país informal. El número de países únicos disminuyó de 412 a 250. Aquí están: ahora no hay desviaciones. Guardamos el resultado en un nuevo archivo details2.pkl , después de convertir el marco de datos combinado de nuevo en un diccionario de marcos de datos, como se hizo anteriormente.['', 'ABW', 'AFG', 'AGO', 'AIA', 'ALA', 'ALB', 'AND', 'ANT', 'ARE', 'ARG', 'ARM', 'ASM', 'ATA', 'ATF', 'AUS', 'AUT', 'AZE', 'BDI', 'BEL', 'BEN', 'BES', 'BGD', 'BGR', 'BHR', 'BHS', 'BIH', 'BLM', 'BLR', 'BLZ', 'BMU', 'BOL', 'BRA', 'BRB', 'BRN', 'BTN', 'BUR', 'BVT', 'BWA', 'CAF', 'CAN', 'CCK', 'CHE', 'CHL', 'CHN', 'CIV', 'CMR', 'COD', 'COG', 'COK', 'COL', 'COM', 'CPV', 'CRI', 'CTE', 'CUB', 'CUW', 'CXR', 'CYM', 'CYP', 'CZE', 'DEU', 'DJI', 'DMA', 'DNK', 'DOM', 'DZA', 'ECU', 'EGY', 'ERI', 'ESH', 'ESP', 'EST', 'ETH', 'FIN', 'FJI', 'FLK', 'FRA', 'FRO', 'FSM', 'GAB', 'GBR', 'GEO', 'GGY', 'GHA', 'GIB', 'GIN', 'GLP', 'GMB', 'GNB', 'GNQ', 'GRC', 'GRD', 'GRL', 'GTM', 'GUF', 'GUM', 'GUY', 'HKG', 'HMD', 'HND', 'HRV', 'HTI', 'HUN', 'IDN', 'IMN', 'IND', 'IOT', 'IRL', 'IRN', 'IRQ', 'ISL', 'ISR', 'ITA', 'JAM', 'JEY', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM', 'KIR', 'KNA', 'KOR', 'KWT', 'LAO', 'LBN', 'LBR', 'LBY', 'LCA', 'LIE', 'LKA', 'LTU', 'LUX', 'LVA', 'MAC', 'MAF', 'MAR', 'MCO', 'MDA', 'MDG', 'MDV', 'MEX', 'MHL', 'MKD', 'MLI', 'MLT', 'MMR', 'MNE', 'MNG', 'MNP', 'MOZ', 'MSR', 'MTQ', 'MUS', 'MYS', 'MYT', 'NAM', 'NCL', 'NER', 'NFK', 'NGA', 'NHB', 'NIC', 'NIU', 'NLD', 'NOR', 'NPL', 'NRU', 'NZL', 'OMN', 'PAK', 'PAN', 'PCN', 'PER', 'PHL', 'PLW', 'PNG', 'POL', 'PRI', 'PRK', 'PRT', 'PRY', 'PSE', 'PYF', 'QAT', 'REU', 'ROU', 'RUS', 'RWA', 'SAU', 'SCG', 'SDN', 'SEN', 'SGP', 'SGS', 'SHN', 'SJM', 'SLB', 'SLE', 'SLV', 'SMR', 'SOM', 'SPM', 'SRB', 'SSD', 'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SXM', 'SYC', 'SYR', 'TCA', 'TCD', 'TGO', 'THA', 'TJK', 'TKL', 'TKM', 'TLS', 'TON', 'TTO', 'TUN', 'TUR', 'TUV', 'TWN', 'TZA', 'UGA', 'UKR', 'UMI', 'URY', 'USA', 'UZB', 'VAT', 'VCT', 'VEN', 'VGB', 'VIR', 'VNM', 'VUT', 'WLF', 'WSM', 'YEM', 'YUG', 'ZAF', 'ZMB', 'ZWE']
Ubicación
Ahora recuerde que la mención de países también está en la tabla dinámica, en la columna loc . También debe llevarse a un aspecto estándar. Aquí hay una historia ligeramente diferente: ni los códigos ISO ni los códigos olímpicos son visibles. Todo se describe de forma bastante libre. La ciudad, el país y otros componentes de la dirección se enumeran con una coma y en orden aleatorio. En algún lugar en primer lugar, en algún lugar en el último. pycountry no ayudará aquí. Y hay muchos récords: para la carrera de 1922, 525 ubicaciones únicas (en su forma original). Pero aquí se encontró una herramienta adecuada. Esto es geopy , es decir, el geolocalizador Nominatim . Funciona así:from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='triathlon results researcher')
geolocator.geocode(' , , ', language='en')
Out: Location( , – , , Altaysky District, Altai Krai, Siberian Federal District, Russia, (51.78897945, 85.73956296106752, 0.0))
A pedido, en forma aleatoria, proporciona una respuesta estructurada: dirección y coordenadas. Si configura el idioma, como aquí, inglés, entonces lo que pueda, se traducirá. En primer lugar, necesitamos el nombre estándar del país para su posterior traducción al código ISO. Solo toma el último lugar en la propiedad de la dirección . Como el geolocalizador envía una solicitud al servidor cada vez, este proceso no es rápido y toma 500 minutos para 500 registros. Además, sucede que la respuesta no llega. En este caso, una segunda solicitud a veces ayuda. En mi primera respuesta no llegó a 130 solicitudes. La mayoría de ellos fueron procesados con dos reintentos. Sin embargo, 34 nombres no fueron procesados incluso por varios intentos adicionales. Aquí están:['Tongyeong, Korea, Korea, South', 'Constanta, Mamaia, Romania, Romania', 'Weihai, China, China', '. , .', 'Odaiba Marin Park, Tokyo, Japan, Japan', 'Sweden, Smaland, Kalmar', 'Cholpon-Ata city, Resort Center "Kapriz", Kyrgyzstan', 'Luxembourg, Region Moselle, Moselle', 'Chita Peninsula, Japan', 'Kraichgau Region, Germany', 'Jintang, Chengdu, Sichuan Province, China, China', 'Madrid, Spain, Spain', 'North American Pro Championship, St. George, Utah, USA', 'Milan Idroscalo Linate, Italy', 'Dexing, Jiangxi Province, China, China', 'Mooloolaba, Australia, Australia', 'Nathan Benderson Park (NBP), 5851 Nathan Benderson Circle, Sarasota, FL 34235., United States', 'Strathclyde Country Park, North Lanarkshire, Glasgow, Great Britain', 'Quijing, China', 'United States of America , Hawaii, Kohala Coast', 'Buffalo City, East London, South Africa', 'Spain, Vall de Cardener', ', . ', 'Asian TriClub Championship, Hefei, China', 'Taizhou, Jiangsu Province, China, China', ', , «»', 'Buffalo, Gallagher Beach, Furhmann Blvd, United States', 'North American Pro Championship | St. George, Utah, USA', 'Weihai, Shandong, China, China', 'Tarzo - Revine Lago, Italy', 'Lausanee, Switzerland', 'Queenstown, New Zealand, New Zealand', 'Makuhari, Japan, Japan', 'Szombathlely, Hungary']
Se puede ver que en muchos hay una doble mención del país, y esto realmente interfiere. En general, tuve que procesar manualmente estos nombres restantes y se obtuvieron las direcciones estándar para todos. Además, de estas direcciones seleccioné un país y escribí este país en una nueva columna en la tabla dinámica. Como, como dije, trabajar con geopy no es rápido, decidí guardar de inmediato las coordenadas de ubicación: latitud y longitud. Serán útiles más tarde para su visualización en el mapa. Después de eso, usando pyco.countries.get (name = '...'). Alpha_3 buscó el país por nombre y le asignó un código de tres dígitos.Distancia
Otra acción importante que debe hacerse en la mesa pivote es determinar la distancia para cada carrera. Esto nos es útil para calcular velocidades en el futuro. En el triatlón, hay cuatro distancias principales: sprint, olímpico, semi-hierro y hierro. Puedes ver que en los nombres de las carreras generalmente hay una indicación de la distancia: estas son Sprint , Olympic , Half , Full Words . Además, diferentes organizadores tienen sus propias designaciones de distancias. La mitad de Ironman, por ejemplo, se designa como 70.3 - por el número de millas en la distancia, el Olímpico - 5150 por el número de kilómetros (51.5), y el hierro se puede designar como Completoo, en general, como una falta de explicación, por ejemplo, Ironman Arizona 2019 . Ironman: ¡él es hierro! En Challenge, la distancia de hierro se designa como Larga y la distancia de semi- hierro se designa como Media . Nuestro IronStar ruso significa lleno como 226 , y la mitad como 113 , por el número de kilómetros, pero generalmente las palabras Completo y Medio también están presentes. Ahora aplique todo este conocimiento y marque todas las carreras de acuerdo con las palabras clave presentes en los nombres.sprints = rs.loc[[i for i in rs.index if 'sprint' in rs.loc[i, 'event'].lower()]]
olympics1 = rs.loc[[i for i in rs.index if 'olympic' in rs.loc[i, 'event'].lower()]]
olympics2 = rs.loc[[i for i in rs.index if '5150' in rs.loc[i, 'event'].lower()]]
olympics = pd.concat([olympics1, olympics2])
rsd = pd.concat([sprints, olympics, halfs, fulls])
En RSD resultó 1 925 registros, es decir, tres más que el número total de carreras, por lo que una parte cayó bajo dos criterios. Echemos un vistazo a ellos:rsd[rsd.duplicated(keep=False)]['event'].sort_index()
olympics.drop(65)
Haremos lo mismo con la intersección de Ironman Dun Laoghaire Full Swim 70.3 2019 Aquí es el mejor horario 4:00. Esto es típico para la mitad. Eliminar el registro con el índice 85 de los completos .fulls.drop(85)
Ahora escribiremos la información de distancia en el marco de datos principal y veremos qué sucedió:rs['dist'] = ''
rs.loc[sprints.index,'dist'] = 'sprint'
rs.loc[olympics.index,'dist'] = 'olympic'
rs.loc[halfs.index,'dist'] = 'half'
rs.loc[fulls.index,'dist'] = 'full'
rs.sample(10)
len(rs[rs['dist'] == ''])
Out: 0
Y echa un vistazo a nuestros problemáticos y ambiguos:rs.loc[[38,65,82],['event','dist']]
pkl.dump(rs, open(r'D:\tri\summary5.pkl', 'wb'))
Grupos de edad
Ahora volvamos a los protocolos de carreras.Ya hemos analizado el género, el país y los resultados del participante, y los hemos llevado a una forma estándar. Pero quedaban dos columnas más: el grupo y, de hecho, el nombre mismo. Comencemos con los grupos. En el triatlón, se acostumbra dividir a los participantes por grupos de edad. Un grupo de profesionales también a menudo se destaca. De hecho, la compensación se encuentra en cada grupo por separado: se otorgan los primeros tres lugares en cada grupo. En grupos, la calificación se está seleccionando para campeonatos, por ejemplo, en Konu.Combine todos los registros y vea qué grupos existen generalmente.rd = pkl.load(open(r'D:\tri\details2.pkl', 'rb'))
ar = pd.concat(rd)
ar['group'].unique()
Resultó que había una gran cantidad de grupos: 581. Cien seleccionados al azar se ven así: Veamos cuáles de ellos son los más numerosos:['MSenior', 'FAmat.', 'M20', 'M65-59', 'F25-29', 'F18-22', 'M75-59', 'MPro', 'F24', 'MCORP M', 'F21-30', 'MSenior 4', 'M40-50', 'FAWAD', 'M16-29', 'MK40-49', 'F65-70', 'F65-70', 'M12-15', 'MK18-29', 'M50up', 'FSEMIFINAL 2 PRO', 'F16', 'MWhite', 'MOpen 25-29', 'F', 'MPT TRI-2', 'M16-24', 'FQUALIFIER 1 PRO', 'F15-17', 'FSEMIFINAL 2 JUNIOR', 'FOpen 60-64', 'M75-80', 'F60-69', 'FJUNIOR A', 'F17-18', 'FAWAD BLIND', 'M75-79', 'M18-29', 'MJUN19-23', 'M60-up', 'M70', 'MPTS5', 'F35-40', "M'S PT1", 'M50-54', 'F65-69', 'F17-20', 'MP4', 'M16-29', 'F18up', 'MJU', 'MPT4', 'MPT TRI-3', 'MU24-39', 'MK35-39', 'F18-20', "M'S", 'F50-55', 'M75-80', 'MXTRI', 'F40-45', 'MJUNIOR B', 'F15', 'F18-19', 'M20-29', 'MAWAD PC4', 'M30-37', 'F21-30', 'Mpro', 'MSEMIFINAL 1 JUNIOR', 'M25-34', 'MAmat.', 'FAWAD PC5', 'FA', 'F50-60', 'FSenior 1', 'M80-84', 'FK45-49', 'F75-79', 'M<23', 'MPTS3', 'M70-75', 'M50-60', 'FQUALIFIER 3 PRO', 'M9', 'F31-40', 'MJUN16-19', 'F18-19', 'M PARA', 'F35-44', 'MParaathlete', 'F18-34', 'FA', 'FAWAD PC2', 'FAll Ages', 'M PARA', 'F31-40', 'MM85', 'M25-39']
ar['group'].value_counts()[:30]
Out:
M40-44 199157
M35-39 183738
M45-49 166796
M30-34 154732
M50-54 107307
M25-29 88980
M55-59 50659
F40-44 48036
F35-39 47414
F30-34 45838
F45-49 39618
MPRO 38445
F25-29 31718
F50-54 26253
M18-24 24534
FPRO 23810
M60-64 20773
M 12799
F55-59 12470
M65-69 8039
F18-24 7772
MJUNIOR 6605
F60-64 5067
M20-24 4580
FJUNIOR 4105
M30-39 3964
M40-49 3319
F 3306
M70-74 3072
F20-24 2522
Puede ver que estos son grupos de cinco años, por separado para hombres y por separado para mujeres, así como grupos profesionales MPRO y FPRO .Entonces nuestro estándar será:ag = ['MPRO', 'M18-24', 'M25-29', 'M30-34', 'M35-39', 'M40-44', 'M45-49', 'M50-54', 'M55-59', 'M60-64', 'M65-69', 'M70-74', 'M75-79', 'M80-84', 'M85-90', 'FPRO', 'F18-24', 'F25-29', 'F30-34', 'F35-39', 'F40-44', 'F45-49', 'F50-54', 'F55-59', 'F60-64', 'F65-69', 'F70-74', 'F75-79', 'F80-84', 'F85-90']
Este conjunto cubre casi el 95% de todos los finalizadores.Por supuesto, no podremos llevar a todos los grupos a este estándar. Pero buscamos aquellos que son similares a ellos y dan al menos una parte. Primero, llevaremos a mayúsculas y eliminaremos los espacios. Esto es lo que sucedió: conviértalos a nuestros estándares.['F25-29F', 'F30-34F', 'F30-34-34', 'F35-39F', 'F40-44F', 'F45-49F', 'F50-54F', 'F55-59F', 'FAG:FPRO', 'FK30-34', 'FK35-39', 'FK40-44', 'FK45-49', 'FOPEN50-54', 'FOPEN60-64', 'MAG:MPRO', 'MK30-34', 'MK30-39', 'MK35-39', 'MK40-44', 'MK40-49', 'MK50-59', 'M40-44', 'MM85-89', 'MOPEN25-29', 'MOPEN30-34', 'MOPEN35-39', 'MOPEN40-44', 'MOPEN45-49', 'MOPEN50-54', 'MOPEN70-74', 'MPRO:', 'MPROM', 'M0-44"']
fix = { 'F25-29F': 'F25-29', 'F30-34F' : 'F30-34', 'F30-34-34': 'F30-34', 'F35-39F': 'F35-39', 'F40-44F': 'F40-44', 'F45-49F': 'F45-49', 'F50-54F': 'F50-54', 'F55-59F': 'F55-59', 'FAG:FPRO': 'FPRO', 'FK30-34': 'F30-34', 'FK35-39': 'F35-39', 'FK40-44': 'F40-44', 'FK45-49': 'F45-49', 'FOPEN50-54': 'F50-54', 'FOPEN60-64': 'F60-64', 'MAG:MPRO': 'MPRO', 'MK30-34': 'M30-34', 'MK30-39': 'M30-39', 'MK35-39': 'M35-39', 'MK40-44': 'M40-44', 'MK40-49': 'M40-49', 'MK50-59': 'M50-59', 'M40-44': 'M40-44', 'MM85-89': 'M85-89', 'MOPEN25-29': 'M25-29', 'MOPEN30-34': 'M30-34', 'MOPEN35-39': 'M35-39', 'MOPEN40-44': 'M40-44', 'MOPEN45-49': 'M45-49', 'MOPEN50-54': 'M50-54', 'MOPEN70-74': 'M70- 74', 'MPRO:' :'MPRO', 'MPROM': 'MPRO', 'M0-44"' : 'M40-44'}
Ahora aplicamos nuestra transformación al marco de datos principal ar , pero primero guardamos los valores del grupo original en la nueva columna sin procesar del grupo .ar['group raw'] = ar['group']
En la columna del grupo , dejamos solo aquellos valores que cumplen con nuestro estándar.Ahora podemos apreciar nuestros esfuerzos:len(ar[(ar['group'] != ar['group raw'])&(ar['group']!='')])
Out: 273
Solo un poco al nivel de un millón y medio. Pero no lo sabrás hasta que lo intentes.Los 10 seleccionados se ven así: guarde la nueva versión del marco de datos, después de convertirla nuevamente al diccionario rd .pkl.dump(rd, open(r'D:\tri\details3.pkl', 'wb'))
Nombre
Ahora cuidemos los nombres. Veamos selectivamente 100 nombres de diferentes razas:list(ar['name'].sample(100))
Out: ['Case, Christine', 'Van der westhuizen, Wouter', 'Grace, Scott', 'Sader, Markus', 'Schuller, Gunnar', 'Juul-Andersen, Jeppe', 'Nelson, Matthew', ' ', 'Westman, Pehr', 'Becker, Christoph', 'Bolton, Jarrad', 'Coto, Ricardo', 'Davies, Luke', 'Daniltchev, Alexandre', 'Escobar Labastida, Emmanuelle', 'Idzikowski, Jacek', 'Fairaislova Iveta', 'Fisher, Kulani', 'Didenko, Viktor', 'Osborne, Jane', 'Kadralinov, Zhalgas', 'Perkins, Chad', 'Caddell, Martha', 'Lynaire PARISH', 'Busing, Lynn', 'Nikitin, Evgeny', 'ANSON MONZON, ROBERTO', 'Kaub, Bernd', 'Bank, Morten', 'Kennedy, Ian', 'Kahl, Stephen', 'Vossough, Andreas', 'Gale, Karen', 'Mullally, Kristin', 'Alex FRASER', 'Dierkes, Manuela', 'Gillett, David', 'Green, Erica', 'Cunnew, Elliott', 'Sukk, Gaspar', 'Markina Veronika', 'Thomas KVARICS', 'Wu, Lewen', 'Van Enk, W.J.J', 'Escobar, Rosario', 'Healey, Pat', 'Scheef, Heike', 'Ancheta, Marlon', 'Heck, Andreas', 'Vargas Iii, Raul', 'Seferoglou, Maria', 'chris GUZMAN', 'Casey, Timothy', 'Olshanikov Konstantin', 'Rasmus Nerrand', 'Lehmann Bence', 'Amacker, Kirby', 'Parks, Chris', 'Tom, Troy', 'Karlsson, Ulf', 'Halfkann, Dorothee', 'Szabo, Gergely', 'Antipov Mikhail', 'Von Alvensleben, Alvo', 'Gruber, Peter', 'Leblanc, Jean-Philippe', 'Bouchard, Jean-Francois', 'Marchiotto MASSIMO', 'Green, Molly', 'Alder, Christoph', 'Morris, Huw', 'Deceur, Marc', 'Queenan, Derek', 'Krause, Carolin', 'Cockings, Antony', 'Ziehmer Chris', 'Stiene, John', 'Chmet Daniela', 'Chris RIORDAN', 'Wintle, Mel', ' ', 'GASPARINI CHRISTIAN', 'Westbrook, Christohper', 'Martens, Wim', 'Papson, Chris', 'Burdess, Shaun', 'Proctor, Shane', 'Cruzinha, Pedro', 'Hamard, Jacques', 'Petersen, Brett', 'Sahyoun, Sebastien', "O'Connell, Keith", 'Symoshenko, Zhan', 'Luternauer, Jan', 'Coronado, Basil', 'Smith, Alex', 'Dittberner, Felix', 'N?sman, Henrik', 'King, Malisa', 'PUHLMANN Andre']
Es complicado. Hay una variedad de opciones para las entradas: Nombre Apellido, Apellido Nombre, Apellido, Nombre, Apellido, Nombre , etc. Es decir, un orden diferente, un registro diferente, en algún lugar hay un separador, una coma. También hay muchos protocolos en los que va Cirílico. Tampoco existe uniformidad, y se pueden encontrar dichos formatos: "Apellido Nombre", "Nombre Apellido", "Nombre Segundo nombre Apellido", "Apellido Nombre Segundo nombre". Aunque, de hecho, el segundo nombre también se encuentra en la ortografía latina. Y aquí, por cierto, surge un problema más: la transliteración. También debe tenerse en cuenta que incluso cuando no hay un segundo nombre, el registro no puede limitarse a dos palabras. Por ejemplo, para los hispanos, el nombre más el apellido generalmente consta de tres o cuatro palabras. Los holandeses tienen el prefijo Van, los chinos y los coreanos también tienen nombres compuestos generalmente de tres palabras. En general, necesita de alguna manera desentrañar todo este acertijo y estandarizarlo al máximo. Como regla general, dentro de una carrera, el formato del nombre es el mismo para todos, pero incluso aquí hay errores que, sin embargo, no manejaremos. Comencemos almacenando los valores existentes en el nuevo nombre de columna sin procesar :ar['name raw'] = ar['name']
La gran mayoría de los protocolos están en latín, por lo que lo primero que me gustaría hacer es transliterar. Veamos qué caracteres se pueden incluir en el nombre del participante.set( ''.join(ar['name'].unique()))
Out: [' ', '!', '"', '#', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', 'µ', '¶', '·', '»', '', 'І', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', 'є', 'і', 'ў', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
¡Qué hay allí solo! Además de las letras y espacios reales, todavía hay un montón de caracteres extravagantes diferentes. De estos, el período '.', El guión '-' y el apóstrofe “'” pueden considerarse válidos, es decir, no presentes por error. Además, se observó que en muchos nombres y apellidos alemanes y noruegos hay un signo de interrogación '?'. Ellos, aparentemente, están reemplazando los caracteres del alfabeto latino extendido - '?', 'A', 'o', 'u',? y otros. Aquí hay ejemplos: la coma, aunque ocurre muy a menudo, es solo un separador, adoptado en ciertas carreras, por lo que también caerá en la categoría de inaceptable. Los números tampoco deberían aparecer en los nombres.Pierre-Alexandre Petit, Jean-louis Lafontaine, Faris Al-Sultan, Jean-Francois Evrard, Paul O'Mahony, Aidan O'Farrell, John O'Neill, Nick D'Alton, Ward D'Hulster, Hans P.J. Cami, Luis E. Benavides, Maximo Jr. Rueda, Prof. Dr. Tim-Nicolas Korf, Dr. Boris Scharlowsk, Eberhard Gro?mann, Magdalena Wei?, Gro?er Axel, Meyer-Szary Krystian, Morten Halkj?r, RASMUSSEN S?ren Balle
bs = [s for s in symbols if not (s.isalpha() or s in " . - ' ? ,")]
bs
Out: ['!', '"', '#', '&', '(', ')', '*', '+', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '@', '[', '\\', ']', '^', '_', '`', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', '¶', '·', '»', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Eliminaremos temporalmente todos estos caracteres para averiguar cuántas entradas están presentes:for s in bs:
ar['name'] = ar['name'].str.replace(s, '')
corr = ar[ar['name'] != ar['name raw']]
Hay 2,184 de esos registros, es decir, solo el 0.15% del número total, muy pocos. Echemos un vistazo a 100 de ellos:list(corr['name raw'].sample(100))
Out: ['Scha¶ffl, Ga?nter', 'Howard, Brian &', 'Chapiewski, Guilherme (Gc)', 'Derkach 1svd_mail_ru', 'Parker H1 Lauren', 'Leal le?n, Yaneri', 'TencA, David', 'Cortas La?pez, Alejandro', 'Strid, Bja¶rn', '(Crutchfield) Horan, Katie', 'Vigneron, Jean-Michel.Vigneron@gmail.Com', '\xa0', 'Telahr, J†rgen', 'St”rmer, Melanie', 'Nagai B1 Keiji', 'Rinc?n, Mariano', 'Arkalaki, Angela (Evangelia)', 'Barbaro B1 Bonin Anna G:Charlotte', 'Ra?esch, Ja¶rg', "CAVAZZI NICCOLO\\'", 'D„nzel, Thomas', 'Ziska, Steffen (Gerhard)', 'Kobilica B1 Alen', 'Mittelholcz, Bala', 'Jimanez Aguilar, Juan Antonio', 'Achenza H1 Giovanni', 'Reppe H2 Christiane', 'Filipovic B2 Lazar', 'Machuca Ka?hnel, Ruban Alejandro', 'Gellert (Silberprinz), Christian', 'Smith (Guide), Matt', 'Lenatz H1 Benjamin', 'Da¶llinger, Christian', 'Mc Carthy B1 Patrick Donnacha G:Bryan', 'Fa¶llmer, Chris', 'Warner (Rivera), Lisa', 'Wang, Ruijia (Ray)', 'Mc Carthy B1 Donnacha', 'Jones, Nige (Paddy)', 'Sch”ler, Christoph', '\xa0', 'Holthaus, Adelhard (Allard)', 'Mi;Arro, Ana', 'Dr: Koch Stefan', '\xa0', '\xa0', 'Ziska, Steffen (Gerhard)', 'Albarraca\xadn Gonza?lez, Juan Francisco', 'Ha¶fling, Imke', 'Johnston, Eddie (Edwin)', 'Mulcahy, Bob (James)', 'Gottschalk, Bj”rn', '\xa0', 'Gretsch H2 Kendall', 'Scorse, Christopher (Chris)', 'Kiel‚basa, Pawel', 'Kalan, Magnus', 'Roderick "eric" SIMBULAN', 'Russell;, Mark', 'ROPES AND GRAY TEAM 3', 'Andrade, H?¦CTOR DANIEL', 'Landmann H2 Joshua', 'Reyes Rodra\xadguez, Aithami', 'Ziska, Steffen (Gerhard)', 'Ziska, Steffen (Gerhard)', 'Heuza, Pierre', 'Snyder B1 Riley Brad G:Colin', 'Feldmann, Ja¶rg', 'Beveridge H1 Nic', 'FAGES`, perrine', 'Frank", Dieter', 'Saarema¤el, Indrek', 'Betancort Morales, Arida–y', 'Ridderberg, Marie_Louise', '\xa0', 'Ka¶nig, Johannes', 'W Van(der Klugt', 'Ziska, Steffen (Gerhard)', 'Johnson, Nick26', 'Heinz JOHNER03', 'Ga¶rg, Andra', 'Maruo B2 Atsuko', 'Moral Pedrero H1 Eva Maria', '\xa0', 'MATUS SANTIAGO Osc1r', 'Stenbrink, Bja¶rn', 'Wangkhan, Sm1.Thaworn', 'Pullerits, Ta¶nu', 'Clausner, 8588294149', 'Castro Miranda, Josa Ignacio', 'La¶fgren, Pontuz', 'Brown, Jann ( Janine )', 'Ziska, Steffen (Gerhard)', 'Koay, Sa¶ren', 'Ba¶hm, Heiko', 'Oleksiuk B2 Vita', 'G Van(de Grift', 'Scha¶neborn, Guido', 'Mandez, A?lvaro', 'Garca\xada Fla?rez, Daniel']
Como resultado, después de mucha investigación, se decidió: reemplazar todos los caracteres alfabéticos, así como un espacio, un guión, un apóstrofe y un signo de interrogación, con una coma, un punto y un símbolo y espacios '\ xa0', y reemplazar todos los demás caracteres con una cadena vacía, es decir, simplemente elimine.ar['name'] = ar['name raw']
for s in symbols:
if s.isalpha() or s in " - ? '":
continue
if s in ".,\xa0":
ar['name'] = ar['name'].str.replace(s, ' ')
else:
ar['name'] = ar['name'].str.replace(s, '')
Luego, elimine los espacios adicionales:ar['name'] = ar['name'].str.split().str.join(' ')
ar['name'] = ar['name'].str.strip()
Vamos a ver que pasó:ar.loc[corr.index].sample(10)
qmon = ar[(ar['name'].str.replace('?', '').str.strip() == '')&(ar['name']!='')]
Hay 3.429 de ellos. Se parece a esto: nuestro objetivo de llevar los nombres al mismo estándar es hacer que los mismos nombres se vean iguales, pero diferentes en diferentes formas. En el caso de los nombres que consisten solo en signos de interrogación, difieren solo en el número de caracteres, pero esto no da plena confianza de que los nombres con el mismo número sean realmente los mismos. Por lo tanto, los reemplazamos todos con una cadena vacía y no se considerarán en el futuro.ar.loc[qmon.index, 'name'] = ''
El número total de entradas donde el nombre es la cadena vacía es 3,454. No tanto, sobreviviremos. Ahora que nos hemos librado de los caracteres innecesarios, podemos proceder a la transliteración. Para hacer esto, primero ponga todo en minúsculas para no hacer doble trabajo.ar['name'] = ar['name'].str.lower()
A continuación, cree un diccionario:trans = {'':'a', '':'b', '':'v', '':'g', '':'d', '':'e', '':'e', '':'zh', '':'z', '':'i', '':'y', '':'k', '':'l', '':'m', '':'n', '':'o', '':'p', '':'r', '':'s', '':'t', '':'u', '':'f', '':'kh', '':'ts', '':'ch', '':'sh', '':'shch', '':'', '':'y', '':'', '':'e', '':'yu', '':'ya', 'є':'e', 'і': 'i','ў':'w','µ':'m'}
También incluía letras del llamado alfabeto cirílico extendido: 'є', 'і', 'ў' , que se usan en los idiomas bielorruso y ucraniano, así como la letra griega 'µ' . Aplica la transformación:for s in trans:
ar['name'] = ar['name'].str.replace(s, trans[s])
Ahora, en minúsculas, traduciremos todo al formato familiar, donde el nombre y apellido comienzan con una letra mayúscula:ar['name'] = ar['name'].str.title()
Vamos a ver que pasó.ar[ar['name raw'].str.lower().str[0].isin(trans.keys())].sample(10)
set( ''.join(ar['name'].unique()))
Out: [' ', "'", '-', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
Todo es correcto. Como resultado, las correcciones afectaron 1.253.882 o el 89% de los registros, el número de nombres únicos disminuyó de 660,207 a 599,186, es decir, en 61 mil o casi el 10%. ¡Guauu! Guarde en un archivo nuevo, después de traducir la unión de los registros ar nuevamente al diccionario de protocolo rd .pkl.dump(rd, open(r'D:\tri\details4.pkl', 'wb'))
Ahora necesitamos restaurar el orden. Es decir, que todos los registros se verían así: Nombre Apellido o Apellido Nombre . ¿Cuál debe ser determinado? Es cierto que, además del nombre y el apellido, algunos protocolos también contienen segundos nombres. Y puede suceder que la misma persona se escriba de manera diferente en diferentes protocolos, en algún lugar con un segundo nombre, en algún lugar sin él. Esto interferirá con su identificación, así que intente eliminar el segundo nombre. Los patronímicos para los hombres generalmente tienen el final "vih" , y para las mujeres - "vna" . Pero hay excepciones. Por ejemplo, Ilich, Ilinichna, Nikitich, Nikitichna. Es cierto que hay muy pocas excepciones de este tipo. Como ya se señaló, el formato de los nombres dentro de un protocolo puede considerarse permanente. Por lo tanto, para deshacerse de los patronímicos, debe encontrar la raza en la que están presentes. Para hacer esto, encuentre el número total de fragmentos "vich" y "vna" en el nombre de la columnay compárelos con el número total de entradas en cada protocolo. Si estos números están cerca, entonces hay un segundo nombre, de lo contrario no. No es razonable buscar una coincidencia estricta, porque Incluso en las carreras donde se registran los segundos nombres, por ejemplo, los extranjeros pueden participar, y se grabarán sin él. También sucede que el participante olvidó o no quiso indicar su segundo nombre. Por otro lado, también hay apellidos que terminan en "vich", hay muchos de ellos en Bielorrusia y otros países con los idiomas del grupo eslavo. Además, hicimos transliteración. Era posible hacer este análisis antes de la transliteración, pero luego existe la posibilidad de perder un protocolo en el que hay segundos nombres, pero inicialmente ya está en latín. Entonces todo está bien.Por lo tanto, buscaremos todos los protocolos en los que el número de fragmentos "vich" y "vna" en la columnanombre es más del 50% del número total de entradas en el protocolo.wp = {}
for e in rd:
nvich = (''.join(rd[e]['name'])).count('vich')
nvna = (''.join(rd[e]['name'])).count('vna')
if nvich + nvna > 0.5*len(rd[e]):
wp[e] = rd[e]
Existen 29 protocolos de este tipo. Uno de ellos es: Y es interesante que si en lugar del 50% tomamos el 20% o viceversa el 70%, el resultado no cambiará, todavía habrá 29. Así que tomamos la decisión correcta. En consecuencia, menos del 20%, el efecto de los apellidos, más del 70%, el efecto de los registros individuales sin segundo nombre. Habiendo revisado el país con la ayuda de una tabla dinámica, resultó que 25 de ellos estaban en Rusia, 4 en Abjasia. Hacia adelante. Solo procesaremos registros con tres componentes, es decir, aquellos donde haya (presumiblemente) un apellido, nombre, segundo nombre.sum_n3w = 0
sum_nnot3w = 0
for e in wp:
sum_n3w += len([n for n in wp[e]['name'] if len(n.split()) == 3])
sum_nnot3w += len(wp[e]) - n3w
La mayoría de dichos registros es del 86%. Ahora aquellos en los que los tres componentes se dividen en columnas nombre0, nombre1, nombre2 :for e in wp:
ind3 = [i for i in rd[e].index if len(rd[e].loc[i,'name'].split()) == 3]
rd[e]['name0'] = ''
rd[e]['name1'] = ''
rd[e]['name2'] = ''
rd[e].loc[ind3, 'name0'] = rd[e].loc[ind3,'name'].str.split().str[0]
rd[e].loc[ind3, 'name1'] = rd[e].loc[ind3,'name'].str.split().str[1]
rd[e].loc[ind3, 'name2'] = rd[e].loc[ind3,'name'].str.split().str[2]
Así es como se ve uno de los protocolos: aquí, en particular, está claro que la grabación de los dos componentes no se ha procesado. Ahora, para cada protocolo, debe determinar qué columna tiene un segundo nombre. Solo hay dos opciones : nombre1, nombre2 , porque no puede estar en primer lugar. Una vez determinado, recopilaremos un nuevo nombre que ya no tiene.for e in wp:
n1=(''.join(rd[e]['name1'])).count('vich')+(''.join(rd[e]['name1'])).count('vna')
n2=(''.join(rd[e]['name2'])).count('vich')+(''.join(rd[e]['name2'])).count('vna')
if (n1 > n2):
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name2']
else:
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name1']
for e in wp:
ind = rd[e][rd[e]['new name'].str.strip() != ''].index
rd[e].loc[ind, 'name'] = rd[e].loc[ind, 'new name']
rd[e] = rd[e].drop(columns = ['name0','name1','name2','new name'])
pkl.dump(rd, open(r'D:\tri\details5.pkl', 'wb'))
Ahora necesita llevar los nombres al mismo orden. Es decir, es necesario que en todos los protocolos el nombre seguido primero por el apellido, o viceversa, primero el apellido, luego el nombre, también en todos los protocolos. Depende de qué más, ahora lo descubriremos. La situación es un poco complicada por el hecho de que el nombre completo puede constar de más de dos palabras, incluso después de eliminar el segundo nombre.ar['nwin'] = ar['name'].str.count(' ') + 1
ar.loc[ar['name'] == '','nwin'] = 0
100*ar['nwin'].value_counts()/len(ar)
Número de palabras en un nombre Número de registros Porcentaje de registros (%) Por supuesto, la gran mayoría (91%) son dos palabras, solo un nombre y un apellido. Pero las entradas con tres y cuatro palabras también son muchas. Veamos la nacionalidad de tales registros:ar[ar['nwin'] >= 3]['country'].value_counts()[:12]
Out:
ESP 28435
MEX 10561
USA 7608
DNK 7178
BRA 6321
NLD 5748
DEU 4310
PHL 3941
ZAF 3862
ITA 3691
BEL 3596
FRA 3323
Bueno, en primer lugar está España, en segundo lugar: México, un país hispano, más allá de los Estados Unidos, donde históricamente también hay muchos hispanos. Brasil y Filipinas también son nombres españoles (y portugueses). Dinamarca, los Países Bajos, Alemania, Sudáfrica, Italia, Bélgica y Francia son otro asunto, simplemente a veces viene algún tipo de prefijo para el apellido, por lo tanto, hay más de dos palabras. En todos estos casos, sin embargo, generalmente el nombre en sí consiste en una palabra y el apellido de dos, tres. Por supuesto, hay excepciones a esta regla, pero ya no las procesaremos. Primero, para cada protocolo, debe determinar qué tipo de orden hay: nombre-apellido o viceversa. ¿Cómo hacerlo? Se me ocurrió la siguiente idea: en primer lugar, la variedad de apellidos suele ser mucho mayor que la variedad de nombres. Debería ser así incluso dentro del marco de un protocolo. En segundo lugar,la longitud del nombre generalmente es menor que la longitud del apellido (incluso para apellidos no compuestos). Utilizaremos una combinación de estos criterios para determinar el orden preliminar.Seleccione la primera y la última palabra en el nombre completo:ar['new name'] = ar['name']
ind = ar[ar['nwin'] < 2].index
ar.loc[ind, 'new name'] = '. .'
ar['wfin'] = ar['new name'].str.split().str[0]
ar['lwin'] = ar['new name'].str.split().str[-1]
Convierta el marco de datos ar combinado nuevamente al diccionario rd para que las nuevas columnas nwin, ns0, ns caigan en el marco de datos de cada raza. A continuación, determinamos el número de protocolos con el orden "Nombre Apellido" y el número de protocolos con el orden inverso de acuerdo con nuestro criterio. Consideraremos solo las entradas donde el nombre completo consta de dos palabras. Al mismo tiempo, guarde el nombre (nombre) en una nueva columna:name_surname = {}
surname_name = {}
for e in rd:
d = rd[e][rd[e]['nwin'] == 2]
if len(d['fwin'].unique()) < len(d['lwin'].unique()) and len(''.join(d['fwin'])) < len(''.join(d['lwin'])):
name_surname[e] = d
rd[e]['first name'] = rd[e]['fwin']
if len(d['fwin'].unique()) > len(d['lwin'].unique()) and len(''.join(d['fwin'])) > len(''.join(d['lwin'])):
surname_name[e] = d
rd[e]['first name'] = rd[e]['lwin']
Resultó lo siguiente: la orden Nombre Apellido Apellido - 244 protocolos, la orden Apellido Nombre - 1,508 protocolos.En consecuencia, llevaremos al formato que es más común. La suma resultó ser menor que la cantidad total, porque verificamos el cumplimiento de dos criterios al mismo tiempo, e incluso con una desigualdad estricta. Existen protocolos en los que solo se cumple uno de los criterios, o es posible, pero es poco probable que se produzca la igualdad. Pero esto no tiene importancia ya que el formato está definido.Ahora, suponiendo que hemos determinado el orden con una precisión suficientemente alta, sin olvidar que no es 100% exacto, utilizaremos esta información. Encuentre los nombres más populares de la columna de nombre :vc = ar['first name'].value_counts()
tome los que se han reunido más de cien veces:pfn=vc[vc>100]
hubo 1,673 de ellos. Aquí están los primeros cien de ellos, ordenados en orden descendente de popularidad: ahora, usando esta lista, revisaremos todos los protocolos y compararemos dónde hay más coincidencias, en la primera palabra del nombre o en la última. Consideraremos solo nombres de dos palabras. Si hay más coincidencias con la última palabra, entonces el orden es correcto, si con la primera, significa lo contrario. Además, aquí ya tenemos más confianza, por lo que puede usar este conocimiento, y agregaremos una lista de nombres de su próximo protocolo a la lista inicial de nombres populares con cada pase. Pre-ordenamos los protocolos por la frecuencia de aparición de nombres de la lista inicial para evitar errores aleatorios y preparamos una lista más extensa para aquellos protocolos en los que hay pocas coincidencias y que se procesarán cerca del final del ciclo.['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Patrick', 'Scott', 'Kevin', 'Stefan', 'Jason', 'Eric', 'Christopher', 'Alexander', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Andrea', 'Jonathan', 'Markus', 'Marco', 'Adam', 'Ryan', 'Jan', 'Tom', 'Marc', 'Carlos', 'Jennifer', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Sarah', 'Alex', 'Jose', 'Andrey', 'Benjamin', 'Sebastian', 'Ian', 'Anthony', 'Ben', 'Oliver', 'Antonio', 'Ivan', 'Sean', 'Manuel', 'Matthias', 'Nicolas', 'Dan', 'Craig', 'Dmitriy', 'Laura', 'Luis', 'Lisa', 'Kim', 'Anna', 'Nick', 'Rob', 'Maria', 'Greg', 'Aleksey', 'Javier', 'Michelle', 'Andre', 'Mario', 'Joseph', 'Christoph', 'Justin', 'Jim', 'Gary', 'Erik', 'Andy', 'Joe', 'Alberto', 'Roberto', 'Jens', 'Tobias', 'Lee', 'Nicholas', 'Dave', 'Tony', 'Olivier', 'Philippe']
sbpn = pd.DataFrame(columns = ['event', 'num pop names'], index=range(len(rd)))
for i in range(len(rd)):
e = list(rd.keys())[i]
sbpn.loc[i, 'event'] = e
sbpn.loc[i, 'num pop names'] = len(set(pfn).intersection(rd[e]['first name']))
sbnp=sbnp.sort_values(by = 'num pop names',ascending=False)
sbnp = sbnp.reset_index(drop=True)
tofix = []
for i in range(len(rd)):
e = sbpn.loc[i, 'event']
if len(set(list(rd[e]['fwin'])).intersection(pfn)) > len(set(list(rd[e]['lwin'])).intersection(pfn)):
tofix.append(e)
pfn = list(set(pfn + list(rd[e]['fwin'])))
else:
pfn = list(set(pfn + list(rd[e]['lwin'])))
Había 235 protocolos. Es decir, casi lo mismo que sucedió en la primera aproximación (244). Para estar seguro, miré selectivamente los primeros tres registros de cada uno, me aseguré de que todo estuviera correcto. Verifique también que la primera etapa de clasificación proporcionó 36 entradas falsas del Apellido del nombre de la clase y 2 falsas del Nombre del nombre de la clase . Miré los primeros tres registros de cada uno, de hecho, la segunda etapa funcionó perfectamente. Ahora, de hecho, queda por arreglar aquellos protocolos donde se encuentra el orden incorrecto:for e in tofix:
ind = rd[e][rd[e]['nwin'] > 1].index
rd[e].loc[ind,'name'] = rd[e].loc[ind,'name'].str.split(n=1).str[1] + ' ' + rd[e].loc[ind,'name'].str.split(n=1).str[0]
Aquí en la división, limitamos el número de piezas usando el parámetro n . La lógica es esta: un nombre es una palabra, la primera en un nombre completo. Todo lo demás es un apellido (puede constar de varias palabras). Solo cámbialos.Ahora nos deshacemos de las columnas innecesarias y guardamos:for e in rd:
rd[e] = rd[e].drop(columns = ['new name', 'first name', 'fwin','lwin', 'nwin'])
pkl.dump(rd, open(r'D:\tri\details6.pkl', 'wb'))
Comprueba el resultado. Una docena aleatoria de registros fijos: se repararon un total de 108 mil registros. El número de nombres completos únicos disminuyó de 598 a 547 mil. ¡Multa! Con formateo hecho.Parte 3. Recuperación de datos incompletos.
Ahora pase a recuperar los datos faltantes. Y los hay.País
Comencemos con el país. Encuentra todos los registros en los que el país no está indicado:arnc = ar[ar['country'] == '']
Hay 3,221 de ellos. Aquí hay 10 al azar:nnc = arnc['name'].unique()
El número de nombres únicos entre registros sin país es 3 051. Veamos si este número se puede reducir.El hecho es que en el triatlón las personas rara vez se limitan a una sola carrera, generalmente participan en competiciones periódicamente, varias veces por temporada, año tras año, entrenando constantemente. Por lo tanto, para muchos nombres en los datos, lo más probable es que haya más de un registro. Para restaurar la información sobre el país, intente buscar registros con el mismo nombre entre aquellos en los que se indica el país.arwc = ar[ar['country'] != '']
nwc = arwc['name'].unique()
tofix = set(nnc).intersection(nwc)
Out: ['Kleber-Schad Ute Cathrin', 'Sellner Peter', 'Pfeiffer Christian', 'Scholl Thomas', 'Petersohn Sandra', 'Marchand Kurt', 'Janneck Britta', 'Angheben Riccardo', 'Thiele Yvonne', 'Kie?Wetter Martin', 'Schymik Gerhard', 'Clark Donald', 'Berod Brigitte', 'Theile Markus', 'Giuliattini Burbui Margherita', 'Wehrum Alexander', 'Kenny Oisin', 'Schwieger Peter', 'Grosse Bianca', 'Schafter Carsten', 'Breck Dirk', 'Mautes Christoph', 'Herrmann Andreas', 'Gilbert Kai', 'Steger Peter', 'Jirouskova Jana', 'Jehrke Michael', 'Valentine David', 'Reis Michael', 'Wanka Michael', 'Schomburg Jonas', 'Giehl Caprice', 'Zinser Carsten', 'Schumann Marcus', 'Magoni Livio', 'Lauden Yann', 'Mayer Dieter', 'Krisa Stefan', 'Haberecht Bernd', 'Schneider Achim', 'Gibanel Curto Antonio', 'Miranda Antonio', 'Juarez Pedro', 'Prelle Gerrit', 'Wuste Kay', 'Bullock Graeme', 'Hahner Martin', 'Kahl Maik', 'Schubnell Frank', 'Hastenteufel Marco', …]
Había 2.236 de ellos, es decir, casi tres cuartos. Ahora, para cada nombre de esta lista, debe determinar el país por los registros donde está. Pero sucede que el mismo nombre se encuentra en varios registros y en diferentes países. Este es el homónimo, o tal vez la persona se mudó. Por lo tanto, primero procesamos aquellos donde todo es único.fix = {}
for n in tofix:
nr = arwc[arwc['name'] == n]
if len(nr['country'].unique()) == 1:
fix[n] = nr['country'].iloc[0]
Hecho en un bucle. Pero, francamente, funciona durante mucho tiempo, unos tres minutos. Si hubiera un orden de magnitud más entradas, probablemente tendría que encontrar una implementación vectorial. Hubo 2,013 entradas, o el 90% del potencial.Los nombres para los que pueden aparecer diferentes países en diferentes registros, toman el país que ocurre con más frecuencia.if n not in fix:
nr = arwc[arwc['name'] == n]
vc = nr['country'].value_counts()
if vc[0] > vc[1]:
fix[n] = vc.index[0]
Por lo tanto, se encontraron coincidencias para 2,208 nombres, o el 99% de todos los posibles. Aplicamos estas correspondencias:{'Kleber-Schad Ute Cathrin': 'DEU', 'Sellner Peter': 'AUT', 'Pfeiffer Christian': 'AUT', 'Scholl Thomas': 'DEU', 'Petersohn Sandra': 'DEU', 'Marchand Kurt': 'BEL', 'Janneck Britta': 'DEU', 'Angheben Riccardo': 'ITA', 'Thiele Yvonne': 'DEU', 'Kie?Wetter Martin': 'DEU', 'Clark Donald': 'GBR', 'Berod Brigitte': 'FRA', 'Theile Markus': 'DEU', 'Giuliattini Burbui Margherita': 'ITA', 'Wehrum Alexander': 'DEU', 'Kenny Oisin': 'IRL', 'Schwieger Peter': 'DEU', 'Schafter Carsten': 'DEU', 'Breck Dirk': 'DEU', 'Mautes Christoph': 'DEU', 'Herrmann Andreas': 'DEU', 'Gilbert Kai': 'DEU', 'Steger Peter': 'AUT', 'Jirouskova Jana': 'CZE', 'Jehrke Michael': 'DEU', 'Wanka Michael': 'DEU', 'Giehl Caprice': 'DEU', 'Zinser Carsten': 'DEU', 'Schumann Marcus': 'DEU', 'Magoni Livio': 'ITA', 'Lauden Yann': 'FRA', 'Mayer Dieter': 'DEU', 'Krisa Stefan': 'DEU', 'Haberecht Bernd': 'DEU', 'Schneider Achim': 'DEU', 'Gibanel Curto Antonio': 'ESP', 'Juarez Pedro': 'ESP', 'Prelle Gerrit': 'DEU', 'Wuste Kay': 'DEU', 'Bullock Graeme': 'GBR', 'Hahner Martin': 'DEU', 'Kahl Maik': 'DEU', 'Schubnell Frank': 'DEU', 'Hastenteufel Marco': 'DEU', 'Tedde Roberto': 'ITA', 'Minervini Domenico': 'ITA', 'Respondek Markus': 'DEU', 'Kramer Arne': 'DEU', 'Schreck Alex': 'DEU', 'Bichler Matthias': 'DEU', …}
for n in fix:
ind = arnc[arnc['name'] == n].index
ar.loc[ind, 'country'] = fix[n]
pkl.dump(rd, open(r'D:\tri\details7.pkl', 'wb'))
Suelo
Como en el caso de los países, existen registros en los que no se indica el género del participante.ar[ar['sex'] == '']
Hay 2,538 de ellos. Son relativamente pocos, pero nuevamente intentaremos ganar aún menos. Guarde los valores originales en una nueva columna.ar['sex raw'] =ar['sex']
A diferencia de los países donde recuperamos información por nombre de otros protocolos, aquí todo es un poco más complicado. El hecho es que los datos están llenos de errores y hay muchos nombres (un total de 2 101) que se encuentran con marcas de ambos sexos.arws = ar[(ar['sex'] != '')&(ar['name'] != '')]
snds = arws[arws.duplicated(subset='name',keep=False)]
snds = snds.drop_duplicates(subset=['name','sex'], keep = 'first')
snds = snds.sort_values(by='name')
snds = snds[snds.duplicated(subset = 'name', keep=False)]
snds
rss = [rd[e] for e in rd if len(rd[e][rd[e]['sex'] != '']['sex'].unique()) == 1]
Hay 633 de ellos. Parece que esto es bastante posible, solo un protocolo por separado para las mujeres, por separado para los hombres. Pero el hecho es que casi todos estos protocolos contienen grupos de edad de ambos sexos (los grupos de edad masculinos comienzan con la letra M , femenina, con la letra F ). Por ejemplo: se espera que el nombre del grupo de edad comience con la letra M para hombres y con la letra F para mujeres. En los dos ejemplos anteriores, a pesar de los errores en la columna de sexo'ITU World Cup Tiszaujvaros Olympic 2002'
, el nombre del grupo todavía parecía describir correctamente el género del miembro. Con base en varios ejemplos de muestra, asumimos que el grupo está indicado correctamente y que el género puede estar indicado erróneamente. Busque todas las entradas donde la primera letra del nombre del grupo no coincide con el género. Tomaremos el nombre inicial del grupo del grupo sin procesar , ya que durante la estandarización se dejaron muchos registros sin un grupo, pero ahora solo necesitamos la primera letra, por lo que el estándar no es importante.ar['grflc'] = ar['group raw'].str.upper().str[0]
grncs = ar[(ar['grflc'].isin(['M','F']))&(ar['sex']!=ar['grflc'])]
Hay 26 161 de esos registros. Bueno, corrijamos el género de acuerdo con el nombre del grupo de edad:ar.loc[grncs.index, 'sex'] = grncs['grflc']
Veamos el resultado: bien. ¿Cuántos registros quedan ahora sin género?ar[(ar['sex'] == '')&(ar['name'] != '')]
¡Resulta exactamente uno! Bueno, el grupo no está realmente indicado, pero, aparentemente, esta es una mujer. Emily es un nombre femenino, además de este participante (o su homónimo) terminó un año antes, y en ese protocolo se indican el género y el grupo. Restaura aquí manualmente * y sigue adelante.ar.loc[arns.index, 'sex'] = 'F'
Ahora todos los registros son con género.* En general, por supuesto, está mal hacer esto: con ejecuciones repetidas, si algo en la cadena cambia antes, por ejemplo, en la conversión de nombres, entonces puede haber más de un registro sin género, y no todos serán femeninos, se producirá un error. Por lo tanto, debe insertar una lógica pesada para buscar un participante con el mismo nombre y género en otros protocolos, como para restaurar un país y cómo probarlo, o, para no complicarlo innecesariamente, agregue a esta lógica una verificación de que solo se encuentra un registro y el nombre es tal y tal, de lo contrario, lanzará una excepción que detendrá toda la computadora portátil, puede notar una desviación del plan e intervenir.if len(arns) == 1 and arns['name'].iloc[0] == 'Stather Emily':
ar.loc[arns.index, 'sex'] = 'F'
else:
raise Exception('Different scenario!')
Parece que esto puede calmarse. Pero el hecho es que las correcciones se basan en el supuesto de que el grupo está indicado correctamente. Y de hecho lo es. Casi siempre. Casi. Aún así, se notaron accidentalmente varias inconsistencias, así que ahora tratemos de determinarlas todas, bien, o tanto como sea posible. Como ya se mencionó, en el primer ejemplo, fue precisamente el hecho de que el género no correspondía al nombre sobre la base de sus propias ideas sobre los nombres masculinos y femeninos que nos protegían.Encuentra todos los nombres en los registros masculinos y femeninos. Aquí, el nombre se entiende como el nombre, y no el nombre completo, es decir, sin apellido, lo que se llama el primer nombre en inglés .ar['fn'] = ar['name'].str.split().str[-1]
mfn = list(ar[ar['sex'] == 'M']['fn'].unique())
Se enumeran un total de 32,508 nombres masculinos. Aquí están los 50 más populares:['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Kevin', 'Patrick', 'Scott', 'Stefan', 'Jason', 'Eric', 'Alexander', 'Christopher', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Jonathan', 'Marco', 'Markus', 'Adam', 'Ryan', 'Tom', 'Jan', 'Marc', 'Carlos', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Andrey', 'Benjamin', 'Jose']
ffn = list(ar[ar['sex'] == 'F']['fn'].unique())
Menos mujeres - 14 423. Más popular: Bien, parece lógico. Veamos si hay intersecciones.['Jennifer', 'Sarah', 'Laura', 'Lisa', 'Anna', 'Michelle', 'Maria', 'Andrea', 'Nicole', 'Jessica', 'Julie', 'Elizabeth', 'Stephanie', 'Karen', 'Christine', 'Amy', 'Rebecca', 'Susan', 'Rachel', 'Anne', 'Heather', 'Kelly', 'Barbara', 'Claudia', 'Amanda', 'Sandra', 'Julia', 'Lauren', 'Melissa', 'Emma', 'Sara', 'Katie', 'Melanie', 'Kim', 'Caroline', 'Erin', 'Kate', 'Linda', 'Mary', 'Alexandra', 'Christina', 'Emily', 'Angela', 'Catherine', 'Claire', 'Elena', 'Patricia', 'Charlotte', 'Megan', 'Daniela']
mffn = set(mfn).intersection(ffn)
Ahi esta. Y hay 2.811 de ellos. Miremos más de cerca. Para empezar, descubrimos cuántos registros con estos nombres:armfn = ar[ar['fn'].isin(mffn)]
Hay 725 562. ¡Eso es la mitad! ¡Es asombroso! Hay casi 37,000 nombres únicos, pero la mitad de los registros tienen un total de 2,800. Veamos cuáles son estos nombres, que son los más populares. Para hacer esto, cree un nuevo marco de datos donde estos nombres serán índices:df = pd.DataFrame(armfn['fn'].value_counts())
df = df.rename(columns={'fn':'total'})
Calculamos cuántos registros masculinos y femeninos con cada uno de ellos.df['M'] = armfn[armfn['sex'] == 'M']['fn'].value_counts()
df['F'] = armfn[armfn['sex'] == 'F']['fn'].value_counts()
df.sort_values(by = 'F', ascending=False)
import gender_guesser.detector as gg
d = gg.Detector()
d.get_gender(u'Oleg')
Out: 'male'
d.get_gender(u'Evgeniya')
Out: 'female'
Todo está bien. Pero si revisas el nombre de Andrea , entonces él también da una hembra , lo cual no es del todo cierto. Es cierto, hay una salida. Si observa la propiedad de nombres del detector, entonces toda la ambigüedad se hace visible allí.d.names['Andrea']
Out: {'female': ' 4 4 3 4788 64 579 34 1 7 ',
'mostly_female': '5 6 7 ',
'male': ' 7 '}
Sí, es decir, get_gender solo te da la opción más probable, pero en realidad puede ser mucho más complicado. Verifica otros nombres:d.names['Maria']
Out: {'female': '686 6 A 85986 A BA 3B98A75457 6 ',
'mostly_female': ' BBC A 678A9 '}
d.names['Oleg']
Out: {'male': ' 6 2 99894737 3 '}
Es decir, la lista de nombres para cada nombre corresponde a uno o más pares clave-valor, donde la clave - es sexo: masculino, FEMENINO, mayormente_male, mayormente_female, andy , y el valor - la lista de valores del país correspondiente: 1,2,3 ... .. 9ABC . Los paises son:d.COUNTRIES
Out: ['great_britain', 'ireland', 'usa', 'italy', 'malta', 'portugal', 'spain', 'france', 'belgium', 'luxembourg', 'the_netherlands', 'east_frisia', 'germany', 'austria', 'swiss', 'iceland', 'denmark', 'norway', 'sweden', 'finland', 'estonia', 'latvia', 'lithuania', 'poland', 'czech_republic', 'slovakia', 'hungary', 'romania', 'bulgaria', 'bosniaand', 'croatia', 'kosovo', 'macedonia', 'montenegro', 'serbia', 'slovenia', 'albania', 'greece', 'russia', 'belarus', 'moldova', 'ukraine', 'armenia', 'azerbaijan', 'georgia', 'the_stans', 'turkey', 'arabia', 'israel', 'china', 'india', 'japan', 'korea', 'vietnam', 'other_countries']
No entendí completamente lo que significan específicamente los significados alfanuméricos o su ausencia en la lista. Pero esto no era importante, ya que decidí limitarme a usar solo aquellos nombres que tienen una interpretación inequívoca. Es decir, para el que solo hay un par clave-valor y la clave es masculina o femenina . Para cada nombre de nuestro marco de datos, escriba su interpretación de adivinador de género :df['sex from gg'] = ''
for n in df.index:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1 and options[0] == 'male':
df.loc[n, 'sex from gg'] = 'M'
if len(options) == 1 and options[0] == 'female':
df.loc[n, 'sex from gg'] = 'F'
Resultó 1.150 nombres. Aquí están los más populares que ya se han discutido anteriormente: Bueno, no está mal. Ahora aplique esta lógica a todos los registros.all_names = ar['fn'].unique()
male_names = []
female_names = []
for n in all_names:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1:
if options[0] == 'male':
male_names.append(n)
if options[0] == 'female':
female_names.append(n)
Encontrado 7 091 nombres masculinos y 5 054 femeninos. Aplica la transformación:tofixm = ar[ar['fn'].isin(male_names)]
ar.loc[tofixm.index, 'sex'] = 'M'
tofixf = ar[ar['fn'].isin(female_names)]
ar.loc[tofixf.index, 'sex'] = 'F'
Nos fijamos en el resultado:ar[ar['sex']!=ar['sex raw']]
30,352 entradas corregidas (junto con la corrección por el nombre del grupo). Como de costumbre, 10 aleatorios: ahora que estamos seguros de haber identificado correctamente el género, también alinearemos a los grupos estándar. Veamos dónde no coinciden:ar['gfl'] = ar['group'].str[0]
gncws = ar[(ar['sex'] != ar['gfl']) & (ar['group']!='')]
4,248 entradas. Reemplace la primera letra:ar.loc[gncws.index, 'group'] = ar.loc[gncws.index, 'sex'] + ar.loc[gncws.index, 'group'].str[1:].index, 'sex']
pkl.dump(rd, open(r'D:\tri\details8.pkl', 'wb'))
Eso es todo, con la recuperación de datos incompletos.Actualización del boletín
Queda por actualizar la tabla de resumen con datos actualizados sobre el número de hombres y mujeres, etc.rs['total raw'] = rs['total']
rs['males raw'] = rs['males']
rs['females raw'] = rs['females']
rs['rus raw'] = rs['rus']
for i in rs.index:
e = rs.loc[i,'event']
rs.loc[i,'total'] = len(rd[e])
rs.loc[i,'males'] = len(rd[e][rd[e]['sex'] == 'M'])
rs.loc[i,'females'] = len(rd[e][rd[e]['sex'] == 'F'])
rs.loc[i,'rus'] = len(rd[e][rd[e]['country'] == 'RUS'])
len(rs[rs['total'] != rs['total raw']])
Out: 288
len(rs[rs['males'] != rs['males raw']])
Out:962
len(rs[rs['females'] != rs['females raw']])
Out: 836
len(rs[rs['rus'] != rs['rus raw']])
Out: 8
pkl.dump(rs, open(r'D:\tri\summary6.pkl', 'wb'))
Parte 4. Muestreo
Ahora el triatlón es muy popular. Durante la temporada, hay muchas competiciones abiertas en las que participa un gran número de atletas, principalmente aficionados. Pero no siempre fue así. Hay registros en nuestros datos desde 1990. Al desplazarme por tristats.ru, noté que hay muchas más carreras en los últimos años y muy pocas en las primeras. Pero ahora que nuestros datos se han preparado, puede verlos más de cerca.Período de diez años
Cuente el número de carreras y finalistas en cada año:rs['year'] = pd.DatetimeIndex(rs['date']).year
years = range(rs['year'].min(),rs['year'].max())
rsy = pd.DataFrame(columns = ['races', 'finishers', 'rus', 'RUS'], index = years)
for y in rsy.index:
rsy.loc[y,'races'] = len(rs[rs['year'] == y])
rsy.loc[y,'finishers'] = sum(rs[rs['year'] == y]['total'])
rsy.loc[y,'rus'] = sum(rs[rs['year'] == y]['rus'])
rsy.loc[y,'RUS'] = len(rs[(rs['year'] == y)&(rs['country'] == 'RUS')])
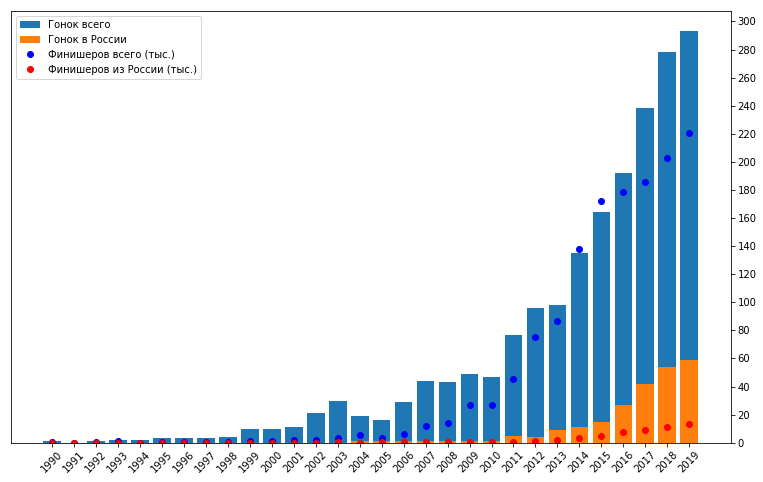 Se puede ver que el número de carreras y participantes al comienzo del período y al final es simplemente inconmensurable. Un aumento significativo en el número total de carreras comienza en 2011, mientras que el número de carreras en Rusia también aumenta. Además, se puede observar un aumento en el número de participantes en 2009. Esto puede indicar un mayor interés entre los participantes, es decir, una mayor demanda, después de lo cual dos años más tarde aumentó la oferta, es decir, el número de inicios. Sin embargo, no olvide que los datos pueden no estar completos y algunos, y posiblemente faltan muchas carreras. Incluso debido al hecho de que el proyecto para recopilar estos datos comenzó solo en 2010, lo que también puede explicar el salto significativo en el gráfico en este mismo momento. Incluyendo por lo tanto, para un análisis más detallado, decidí tomar los últimos 10 años. Este es un período bastante largo,con el fin de rastrear cualquier tendencia a lo largo de varios años, mientras sea lo suficientemente corta como para no llegar allí, principalmente competencias profesionales de los 90 y principios de los 2000.
Se puede ver que el número de carreras y participantes al comienzo del período y al final es simplemente inconmensurable. Un aumento significativo en el número total de carreras comienza en 2011, mientras que el número de carreras en Rusia también aumenta. Además, se puede observar un aumento en el número de participantes en 2009. Esto puede indicar un mayor interés entre los participantes, es decir, una mayor demanda, después de lo cual dos años más tarde aumentó la oferta, es decir, el número de inicios. Sin embargo, no olvide que los datos pueden no estar completos y algunos, y posiblemente faltan muchas carreras. Incluso debido al hecho de que el proyecto para recopilar estos datos comenzó solo en 2010, lo que también puede explicar el salto significativo en el gráfico en este mismo momento. Incluyendo por lo tanto, para un análisis más detallado, decidí tomar los últimos 10 años. Este es un período bastante largo,con el fin de rastrear cualquier tendencia a lo largo de varios años, mientras sea lo suficientemente corta como para no llegar allí, principalmente competencias profesionales de los 90 y principios de los 2000.rs = rs[(rs['year']>=2010)&(rs['year']<= 2019)]
 En el período seleccionado, por cierto, el 84% de las carreras y el 94% de los finalistas cayeron.
En el período seleccionado, por cierto, el 84% de las carreras y el 94% de los finalistas cayeron.Comienzo aficionado
Por lo tanto, la gran mayoría de los participantes en los inicios seleccionados son atletas aficionados, por lo que se pueden obtener buenas estadísticas de ellos. Honestamente, esto fue de gran interés para mí, ya que yo mismo participo en tales comienzos, pero en el nivel está muy lejos de los campeones olímpicos. Sin embargo, las competiciones profesionales obviamente también tuvieron lugar en el período seleccionado. Con el fin de no mezclar los indicadores para las carreras de aficionados y profesionales, se decidió eliminar este último de la consideración. ¿Cómo identificarlos? Por velocidad. Los calculamos En una de las etapas iniciales de preparación de datos, ya determinamos qué tipo de distancia había en cada carrera: sprint, olímpico, medio, hierro. Para cada uno de ellos, el kilometraje de las etapas está claramente definido: natación, ciclismo y carrera. Esto es 0.75 + 20 + 5 para el sprint, 1.5 + 40 + 10 para el Olímpico, 1.9 + 90 + 21.1 para la mitad y 3.8 + 180 + 42.2 para hierro. Por supuesto, de hecho, para cualquier tipo, los números reales pueden variar de una raza a otra condicionalmente hasta un uno por ciento, pero no hay información al respecto, por lo que asumiremos que todo fue correcto.rs['km'] = ''
rs.loc[rs['dist'] == 'sprint', 'km'] = 0.75+20+5
rs.loc[rs['dist'] == 'olympic', 'km'] = 1.5+40+10
rs.loc[rs['dist'] == 'half', 'km'] = 1.9+90+21.1
rs.loc[rs['dist'] == 'full', 'km'] = 3.8+180+42.2
Calculamos las velocidades medias y máximas para cada carrera. El máximo aquí se refiere a la velocidad promedio del atleta que ganó el primer lugar.for index, row in rs.iterrows():
e = row['event']
rd[e]['th'] = pd.TimedeltaIndex(rd[e]['result']).seconds/3600
rd[e]['v'] = rs.loc[i, 'km'] / rd[e]['th']
for index, row in rs.iterrows():
e = row['event']
rs.loc[index,'vmax'] = rd[e]['v'].max()
rs.loc[index,'vavg'] = rd[e]['v'].mean()
 Bueno, puede ver que la mayor parte de las velocidades se reunieron en montones entre aproximadamente 15 km / hy 30 km / h, pero hay una cierta cantidad de valores completamente "cósmicos". Ordene por velocidad promedio y vea cuántos de ellos:
Bueno, puede ver que la mayor parte de las velocidades se reunieron en montones entre aproximadamente 15 km / hy 30 km / h, pero hay una cierta cantidad de valores completamente "cósmicos". Ordene por velocidad promedio y vea cuántos de ellos:rs = rs.sort_values(by='vavg')
 Aquí cambiamos la escala y podemos estimar el rango con mayor precisión. Para velocidades medias es de aproximadamente 17 km / ha 27 km / h, para un máximo: de 18 km / ha 32 km / h. Además, hay "colas" con velocidades promedio muy bajas y muy altas. Las velocidades bajas probablemente corresponden a competiciones extremas como Norseman , y las altas velocidades pueden ser en el caso de natación cancelada, donde en lugar de un sprint hubo un súper sprint, o simplemente datos erróneos. Otro punto importante es el paso suave en el área 1200 a lo largo del eje X, y valores más altos de la velocidad promedio posterior. Allí puede ver una diferencia significativamente menor entre las velocidades promedio y máxima que en los primeros dos tercios del gráfico. Aparentemente, esta es una competencia profesional. Para distinguirlos más claramente, calculamos la relación entre la velocidad máxima y la media. En competiciones profesionales donde no hay personas aleatorias y todos los participantes tienen un nivel muy alto de condición física, esta proporción debe ser mínima.
Aquí cambiamos la escala y podemos estimar el rango con mayor precisión. Para velocidades medias es de aproximadamente 17 km / ha 27 km / h, para un máximo: de 18 km / ha 32 km / h. Además, hay "colas" con velocidades promedio muy bajas y muy altas. Las velocidades bajas probablemente corresponden a competiciones extremas como Norseman , y las altas velocidades pueden ser en el caso de natación cancelada, donde en lugar de un sprint hubo un súper sprint, o simplemente datos erróneos. Otro punto importante es el paso suave en el área 1200 a lo largo del eje X, y valores más altos de la velocidad promedio posterior. Allí puede ver una diferencia significativamente menor entre las velocidades promedio y máxima que en los primeros dos tercios del gráfico. Aparentemente, esta es una competencia profesional. Para distinguirlos más claramente, calculamos la relación entre la velocidad máxima y la media. En competiciones profesionales donde no hay personas aleatorias y todos los participantes tienen un nivel muy alto de condición física, esta proporción debe ser mínima.rs['vmdbva'] = rs['vmax']/rs['vavg']
rs = rs.sort_values(by='vmdbva')
 En este gráfico, el primer trimestre se destaca muy claramente: la relación entre la velocidad máxima y el promedio es pequeña, la velocidad promedio alta y una pequeña cantidad de participantes. Esta es una competencia profesional. El paso en la curva verde está alrededor de 1.2. Dejaremos solo registros con un valor de proporción mayor que 1.2 en nuestra muestra.
En este gráfico, el primer trimestre se destaca muy claramente: la relación entre la velocidad máxima y el promedio es pequeña, la velocidad promedio alta y una pequeña cantidad de participantes. Esta es una competencia profesional. El paso en la curva verde está alrededor de 1.2. Dejaremos solo registros con un valor de proporción mayor que 1.2 en nuestra muestra.rs = rs[rs['vmdbva'] > 1.2]
También eliminamos registros con velocidades atípicas bajas y altas. En ¿Cuáles son los "récords mundiales" de triatlón para cada distancia? Tiempos récord publicados de pasar diferentes distancias para 2019. Si los cuenta a velocidades medias, puede ver que no puede ser superior a 33 km / h, incluso para los más rápidos. Por lo tanto, consideraremos los protocolos donde las velocidades promedio son más altas, inválidas y las eliminaremos de la consideración.rs = rs[(rs['vavg'] > 17)&(rs['vmax'] < 33)]
Esto es lo que queda:
 ahora todo parece bastante homogéneo y no plantea preguntas. Como resultado de toda esta selección, perdimos 777 de los protocolos de 1922, o el 40%. Al mismo tiempo, el número total de finalistas no disminuyó tanto, solo en un 13%.Entonces, quedan 1,145 carreras con 1,231,772 finalistas. Esta muestra se convirtió en el material para mi análisis y visualización.
ahora todo parece bastante homogéneo y no plantea preguntas. Como resultado de toda esta selección, perdimos 777 de los protocolos de 1922, o el 40%. Al mismo tiempo, el número total de finalistas no disminuyó tanto, solo en un 13%.Entonces, quedan 1,145 carreras con 1,231,772 finalistas. Esta muestra se convirtió en el material para mi análisis y visualización.Parte 5. Análisis y visualización.
En este trabajo, el análisis y la visualización propiamente dicha fueron las partes más simples. La punta del iceberg, cuya parte submarina era solo la preparación de los datos. El análisis, de hecho, fue una simple operación aritmética en la serie pandas , calculando promedios, filtrando; todo esto lo hacen las herramientas de pandas elementales y el código anterior está lleno de ejemplos. La visualización, a su vez, se realizó principalmente utilizando el matplotlib más estándar . Parcela usada , barra, pastel . Sin embargo, en algunos lugares tuve que jugar con las firmas de los ejes, en el caso de las fechas y los pictogramas, pero esto no es algo que haga una descripción detallada aquí. De lo único que vale la pena hablar es de la presentación de geodatos. Al menos no esmatplotlib .Geodatos
Para cada carrera tenemos información sobre el lugar. Al principio, usando geopy, calculamos las coordenadas para cada ubicación. Muchas carreras se llevan a cabo anualmente en el mismo lugar. Una herramienta muy útil para renderizar geodatos en python es folium . Así es como funciona:import folium
m = folium.Map()
folium.Marker(['55.7522200', '37.6155600'], popup='').add_to(m)
Y obtenemos un mapa interactivo directamente en la computadora portátil Jupiter. Ahora, a nuestros datos. Primero, comenzaremos una nueva columna a partir de una combinación de nuestras coordenadas:
Ahora, a nuestros datos. Primero, comenzaremos una nueva columna a partir de una combinación de nuestras coordenadas:rs['coords'] = rs['latitude'].astype(str) + ', ' + rs['longitude'].astype(str)
Las coordenadas únicas de coordenadas son 291. Y la única ubicaciones loc son 324, lo que significa que algunos nombres son ligeramente diferentes, mientras que al mismo tiempo que corresponden al mismo punto. No da miedo, consideraremos la unicidad de los acordes . Calculamos cuántos eventos han pasado durante todo el tiempo en cada ubicación (con coordenadas únicas):vc = rs['coords'].value_counts()
vc
Out:
43.7009358, 7.2683912 22
43.5854823, 39.723109 20
29.03970805, -13.636291 16
47.3723941, 8.5423328 16
59.3110918, 24.420907 15
51.0834196, 10.4234469 15
54.7585694, 38.8818137 14
20.4317585, -86.9202745 13
52.3727598, 4.8936041 12
41.6132925, 2.6576102 12
... ...
Ahora cree un mapa y agregue marcadores en forma de círculos, cuyo radio dependerá de la cantidad de eventos realizados en la ubicación. Agregue marcadores con el nombre de la ubicación a los marcadores.m = folium.Map(location=[25,10], zoom_start=2)
for c in rs['coords'].unique():
row = [r[1] for r in rs.iterrows() if r[1]['coords'] == c][0]
folium.Circle([row['latitude'], row['longitude']],
popup=(row['location']+'\n('+str(vc[c])+' races)'),
radius = 10000*int(vc[c]),
color='darkorange',
fill=True,
stroke=True,
weight=1).add_to(m)
Hecho. Puedes ver el resultado:
Progreso de los participantes
De hecho, además de guiar, trabajar en otro horario también no era trivial. Este es el último gráfico de progreso de los participantes. Aquí está: analicémoslo , al mismo tiempo daré el código para renderizar, como un ejemplo del uso de matplotlib :
, al mismo tiempo daré el código para renderizar, como un ejemplo del uso de matplotlib :fig = plt.figure()
fig.set_size_inches(10, 6)
ax = fig.add_axes([0,0,1,1])
b = ax.bar(exp,numrecs, color = 'navajowhite')
ax1 = ax.twinx()
for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
p, = ax1.plot(exp, vpm, 'o-',markersize=8, linewidth=2, color='C0')
for i in range(len(exp)):
if i < len(exp)-1 and (vpm[i] < vpm[i+1]):
ax1.text(x = exp[i]+0.1, y = vpm[i]-0.2, s = '{0:3.1f}%'.format(vpm[i]),size=12)
else:
ax1.text(x = exp[i]+0.1, y = vpm[i]+0.1, s = '{0:3.1f}%'.format(vpm[i]),size=12)
ax.legend((b,p), (' ', ''),loc='center right')
ax.set_xlabel(' ')
ax.set_ylabel('')
ax1.set_ylabel('% ')
ax.set_xticks(np.arange(1, 11, step=1))
ax.set_yticks(np.arange(0, 230000, step=25000))
ax1.set_ylim(97.5,103.5)
ax.yaxis.set_label_position("right")
ax.yaxis.tick_right()
ax1.yaxis.set_label_position("left")
ax1.yaxis.tick_left()
plt.show()
Ahora sobre cómo se calcularon los datos para él. Primero, tenía que elegir los nombres de los participantes que terminaron al menos en dos carreras, y en diferentes años calendario, y al mismo tiempo no son profesionales.Primero, para cada protocolo, complete una nueva columna llamada fecha , que indicará la fecha de la carrera. También necesitaremos un año a partir de esta fecha, haremos el año de la columna . Dado que vamos a analizar la velocidad de cada atleta en relación con la velocidad promedio en la carrera, calculamos inmediatamente esta velocidad en la nueva columna vproc , la velocidad como un porcentaje del promedio.for index, row in rs.iterrows():
e = row['event']
rd[e]['date'] = row['date']
rd[e]['year'] = row['year']
rd[e]['vproc'] = 100 * rd[e]['v'] / rd[e]['v'].mean()
Así es como se ven ahora los protocolos: a continuación, combine todos los protocolos en un marco de datos.' Sprint 2019'ar = pd.concat(rd)
Para cada participante, dejaremos solo una entrada en cada año calendario:ar1 = ar.drop_duplicates(subset = ['name','year'], keep='first')
A continuación, de todos los nombres únicos de estas entradas, encontramos los que ocurren al menos dos veces:nvc = ar1['name'].value_counts()
names = list(nvc[nvc > 1].index)
hay 219.890 de ellos. Eliminemos los nombres de los deportistas profesionales de esta lista:pro_names = ar[ar['group'].isin(['MPRO','FPRO'])]['name'].unique()
names = list(set(names) - set(pro_names))
Además de los nombres de los atletas que comenzaron a realizar antes de 2010. Para hacer esto, cargue los datos que se guardaron antes de la muestra en los últimos 10 años. Póngalos en los objetos rsa (resumen de carreras) y rda (detalles de carrera todos).rdo = {}
for e in rda:
if rsa[rsa['event'] == e]['year'].iloc[0] < 2010:
rdo[e] = rda[e]
aro = pd.concat(rdo)
old_names = aro['name'].unique()
names = list(set(names) - set(old_names))
Y finalmente, encontramos nombres que aparecen más de una vez en el mismo día. Por lo tanto, minimizamos la presencia de homónimos completos en nuestra muestra.namesakes = ar[ar.duplicated(subset = ['name','date'], keep = False)]['name'].unique()
names = list(set(names) - set(namesakes))
Entonces quedan 198,075 nombres. De todo el conjunto de datos, seleccionamos solo los registros con los nombres encontrados:ars = ar[ar['name'].isin(names)]
Ahora, para cada registro, debe determinar a qué año de la carrera del atleta corresponde: el primero, segundo, tercero o décimo. Hacemos un bucle por todos los nombres y calculamos.ars['exp'] = ''
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
Aquí hay un ejemplo de lo que sucedió: Aparentemente, los homónimos aún permanecieron. Esto se espera, pero no da miedo, ya que promediaremos todo, y no debería haber tantos. A continuación, creamos matrices para el gráfico:exp = []
vpm = []
numrecs = []
for x in range(ars['exp'].min(), ars['exp'].max() + 1):
exp.append(x)
vpm.append(ars[ars['exp'] == x]['vproc'].mean())
numrecs.append(len(ars[ars['exp'] == x]))
Eso es todo, hay una base: ahora, para decorarlo con puntos que corresponden a resultados específicos, elegiremos 1000 nombres aleatorios y crearemos matrices con los resultados para ellos.
ahora, para decorarlo con puntos que corresponden a resultados específicos, elegiremos 1000 nombres aleatorios y crearemos matrices con los resultados para ellos.names_samp = random.sample(names,1000)
ars_samp = ars[ars['name'].isin(names_samp)]
ars_samp = ars_samp.reset_index(drop = True)
exp_samp = []
vproc_samp = []
for n in names_samp:
nr = ars_samp[ars_samp['name'] == n]
nr = nr.sort_values('exp')
exp_samp.append(list(nr['exp']))
vproc_samp.append(list(nr['vproc']))
Agregue un bucle para construir gráficos a partir de esta muestra aleatoria.for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
Ahora todo está listo: en general, no es difícil. Pero hay un problema. Para calcular la experiencia exp en un ciclo, todos los nombres, que son casi 200 mil, tardan ocho horas. Tuve que depurar el algoritmo en muestras pequeñas y luego ejecutar el cálculo para la noche. En principio, esto se puede hacer una vez, pero si encuentra algún tipo de error o desea cambiar algo, y necesita volver a contarlo, comienza a tensarse. Y así, cuando iba a publicar un informe por la noche, resultó que nuevamente era necesario volver a contar todo. Esperar hasta la mañana no era parte de mis planes, y comencé a buscar una manera de hacer el cálculo más rápido. Decidió paralelizar.En alguna parte encontré una manera de hacer esto con multiprocesamiento. Para trabajar en Windows, necesitábamos poner la lógica principal de cada tarea paralela en un archivo Workers.py separado :
en general, no es difícil. Pero hay un problema. Para calcular la experiencia exp en un ciclo, todos los nombres, que son casi 200 mil, tardan ocho horas. Tuve que depurar el algoritmo en muestras pequeñas y luego ejecutar el cálculo para la noche. En principio, esto se puede hacer una vez, pero si encuentra algún tipo de error o desea cambiar algo, y necesita volver a contarlo, comienza a tensarse. Y así, cuando iba a publicar un informe por la noche, resultó que nuevamente era necesario volver a contar todo. Esperar hasta la mañana no era parte de mis planes, y comencé a buscar una manera de hacer el cálculo más rápido. Decidió paralelizar.En alguna parte encontré una manera de hacer esto con multiprocesamiento. Para trabajar en Windows, necesitábamos poner la lógica principal de cada tarea paralela en un archivo Workers.py separado :import pickle as pkl
def worker(args):
names = args[0]
ars=args[1]
num=args[2]
ars = ars.sort_values(by='name')
ars = ars.reset_index(drop=True)
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
with open(r'D:\tri\par\prog' + str(num) + '.pkl', 'wb') as f:
pkl.dump(ars,f)
El procedimiento se transfiere a una parte de los nombres de los nombres , la parte datafreyma ar solo con estos nombres y el número de serie de tareas paralelas - num . Los cálculos se escriben en el marco de datos y, al final, el marco de datos se escribe en el archivo. En la computadora portátil que llama a este trabajador , preparamos los argumentos en consecuencia:num_proc = 8
args = []
for i in range(num_proc):
step = int(len(names_samp)/num_proc) + 1
names_i = names_samp[i*step:min((i+1)*step, len(names_samp))]
ars_i = ars[ars['name'].isin(names_i)]
args.append([names_i, ars_i, i])
Comenzamos la computación paralela:from multiprocessing import Pool
import workers
if __name__ == '__main__':
p=Pool(processes = num_proc)
p.map(workers.worker,args)
Y al final leemos los resultados de los archivos y recopilamos las piezas nuevamente en el marco de datos completo:ars=pd.DataFrame(columns = ars.columns)
for i in range(num_proc):
with open(r'D:\tri\par\prog'+str(i)+'.pkl', 'rb') as f:
arsi = pkl.load(f)
print(len(arsi))
ars = pd.concat([ars, arsi])
Por lo tanto, fue posible obtener una aceleración de 40 veces y, en lugar de 8 horas, completar el cálculo en 11 minutos y publicar un informe esa noche. Al mismo tiempo que aprendí a paralelizar en Python , creo que será útil. Aquí, la aceleración resultó ser incluso más de 8 veces el número de núcleos, debido al hecho de que cada tarea utilizaba un pequeño marco de datos, lo que acelera la búsqueda. En principio, los cálculos secuenciales podrían acelerarse de esta manera, pero la pregunta es, ¿cómo adivina?Sin embargo, no pude calmarme e incluso después de la publicación estaba constantemente pensando en cómo hacer el cálculo usando la vectorización, es decir, operaciones en columnas enteras del marco de datos de la serie pandas. Dichos cálculos son un orden de magnitud más rápido que cualquier ciclo paralelo, incluso en un supercúmulo. Y se le ocurrió. Resulta que para que cada nombre encuentre el año del comienzo de una carrera, es necesario, por el contrario, para cada año encontrar a los participantes que comenzaron en ella. Para hacer esto, primero debe determinar todos los nombres para el primer año de nuestra muestra, esto es 2010. Por consiguiente, procesamos todos los registros con estos nombres usando este año. A continuación, tomamos el próximo año - 2011.Nuevamente, encontramos todos los nombres con entradas este año, pero tomamos de ellos solo los no procesados, es decir, aquellos que no se cumplieron en 2010 y se procesan con ellos en 2011. Y así por el resto del año. El mismo ciclo, pero no doscientas mil iteraciones, sino nueve en total.for y in range(ars['year'].min(),ars['year'].max()):
arsynp = ars[(ars['exp'] == '') & (ars['year'] == y)]
namesy = arsynp['name'].unique()
ind = ars[ars['name'].isin(namesy)].index
ars.loc[ind, 'exp'] = ars.loc[ind,'year'] - y + 1
Este ciclo se cumple en solo un par de segundos. Y el código resultó ser mucho más conciso.Conclusión
Bueno, finalmente, se ha completado mucho trabajo. Para mí, este fue, de hecho, el primer proyecto de este tipo. Cuando lo tomé, el objetivo principal era practicar el uso de Python y sus bibliotecas. Esta tarea está más que completada. Y los resultados en sí mismos fueron bastante presentables. ¿Qué conclusiones saqué por mí mismo al finalizar?Primero: los datos son imperfectos. Esto probablemente sea cierto para casi cualquier tarea de análisis. Incluso si están completamente estructurados, y a menudo sucede de manera diferente, debe estar preparado para jugar con ellos antes de comenzar a calcular las características y buscar tendencias: encuentre errores, valores atípicos, desviaciones de los estándares, etc.Segundo:Cualquier tarea tiene una solución. Esto es más como un eslogan, pero a menudo lo es. Es solo que esta solución puede no ser tan obvia y no se encuentra en los datos en sí, sino fuera de la caja, por así decirlo. Como ejemplo: el procesamiento de los nombres de los participantes descritos anteriormente, o el raspado del sitio web.Tercero: el conocimiento del dominio es crucial. Esto permitirá preparar mejor los datos, eliminando datos obviamente no válidos o no estándar, evitar errores de interpretación, usar información que no esté en los datos, por ejemplo, distancias en este proyecto, presentar los resultados en el formulario aceptado en la comunidad, evitando conclusiones estúpidas e incorrectas.Cuarto: trabajar en pythonHay un rico conjunto de herramientas. A veces parece que vale la pena pensar en algo, comienzas a buscar, ya existe. ¡Esto es simplemente genial! Muchas gracias a los creadores por esta contribución, especialmente por las herramientas que fueron útiles aquí: selenio para raspar, pycountry para determinar el código de país de acuerdo con el estándar ISO, códigos de país (datahub) para códigos olímpicos, geopy para determinar las coordenadas en la dirección, folium - para visualización de geodatos, adivinador de género - para el análisis de nombres, multiprocesamiento - para computación paralela, matplotlib , numpy y, por supuesto, pandas - sin ella no hay a dónde ir.Quinto: la vectorización es nuestro todo. Es extremadamente importante poder utilizar las herramientas de pandas incorporadas , es muy efectivo. Supongo que, en la mayoría de los casos, cuando el número de registros se mide a partir de decenas de miles, esta habilidad se vuelve simplemente necesaria.Sexto:Manejar datos es una mala idea. Es necesario tratar de minimizar cualquier intervención manual; en primer lugar, no se escala, es decir, cuando la cantidad de datos aumenta varias veces, el tiempo para el procesamiento manual aumentará a valores inaceptables, y en segundo lugar, habrá poca repetibilidad: olvidará algo, cometerá un error en alguna parte . Todo es solo programático, si algo cae fuera del estándar general para una solución de software, bueno, está bien, puede sacrificar parte de los datos, aún habrá más ventajas.Séptimo:El código debe mantenerse en buen estado de funcionamiento. ¡Parece que podría ser más obvio! De hecho, cuando se trata de código para su propio uso, cuyo propósito es publicar los resultados de este código, aquí no todo es tan estricto. Trabajé en Jupiter Notebooks, y este entorno, en mi opinión, simplemente no tiene que crear productos de software integrales. Está configurado para línea por línea, lanzamiento por partes, esto tiene sus ventajas: es rápido: desarrollo, depuración y ejecución al mismo tiempo. Pero a menudo la tentación es simplemente editar alguna línea y obtener rápidamente un nuevo resultado, en lugar de duplicar o ajustar en def. Por supuesto, tal tentación debe ser evitada. Uno debe luchar por un buen código, incluso "para uno mismo", al menos porque incluso para un trabajo de análisis, el lanzamiento se realiza muchas veces, y la inversión de tiempo al principio seguramente dará sus frutos en el futuro. Y puede agregar pruebas, incluso en computadoras portátiles, en forma de comprobaciones de parámetros críticos y lanzar excepciones: es muy útil.Octavo: Ahorre más a menudo. En cada paso, guardé una nueva versión del archivo. En total, resultaron ser alrededor de 10. Esto es conveniente, ya que cuando se detecta un error, ayuda a determinar rápidamente en qué etapa se produjo. Además, guardé los datos de origen en las columnas marcadas sin procesar ; esto le permite verificar rápidamente el resultado y ver la discrepancia.Noveno:Es necesario medir la inversión de tiempo y el resultado. En algunos lugares, tardé mucho tiempo en restaurar los datos, que forman una fracción de un porcentaje del total. De hecho, esto no tenía sentido, solo había que tirarlos, y eso es todo. Y lo haría si fuera un proyecto comercial, no una capacitación automática. Esto le permitiría obtener el resultado mucho más rápido. El principio de Pareto funciona aquí: el 80% del resultado se logra en el 20% del tiempo.Y el último:Trabajar en tales proyectos amplía enormemente los horizontes. De buena gana, aprende algo nuevo, por ejemplo, los nombres de países extraños, como las Islas Pitcairn, que el código ISO para Suiza es CHE, del latín "Confoederatio Helvetica", que es el nombre español, bueno, en realidad sobre el triatlón en sí mismo - registros, sus propietarios, lugares de carreras, historia de eventos, etc.Quizás suficiente. Eso es todo. ¡Gracias a todos los que leyeron hasta el final!