Acceder a la GPU desde Java revela un tremendo poder. Describe cómo funciona la GPU y cómo acceder desde Java.La programación de GPU es un mundo altísimo para los programadores de Java. Esto es comprensible ya que las tareas normales de Java no son adecuadas para la GPU. Sin embargo, las GPU tienen teraflops de rendimiento, así que exploremos sus capacidades.Para que el tema sea accesible, pasaré un tiempo explicando la arquitectura de la GPU junto con un poco de historia que facilitará una inmersión en la programación de hierro.Una vez que se me muestren las diferencias entre la GPU y la informática de la CPU, mostraré cómo usar la GPU en el mundo de Java. Finalmente, describiré los principales marcos y bibliotecas disponibles para escribir código Java y ejecutarlos en la GPU, y daré algunos ejemplos de código.Un poco de trasfondo
La GPU se popularizó por primera vez por NVIDIA en 1999. Es un procesador especial diseñado para procesar datos gráficos antes de transferirlos a la pantalla. En muchos casos, esto permite que algunos cálculos descarguen la CPU, liberando recursos de la CPU que aceleran estos cálculos descargados. El resultado es que la entrada de gran tamaño puede procesarse y presentarse con una resolución de salida más alta, lo que hace que la presentación visual sea más atractiva y la velocidad de fotogramas sea más suave.La esencia del procesamiento 2D / 3D está principalmente en la manipulación de matrices, esto puede controlarse utilizando un enfoque distribuido. ¿Cuál será un enfoque efectivo para el procesamiento de imágenes? Para responder a esto, comparemos la arquitectura estándar de la CPU (que se muestra en la Figura 1) y la GPU.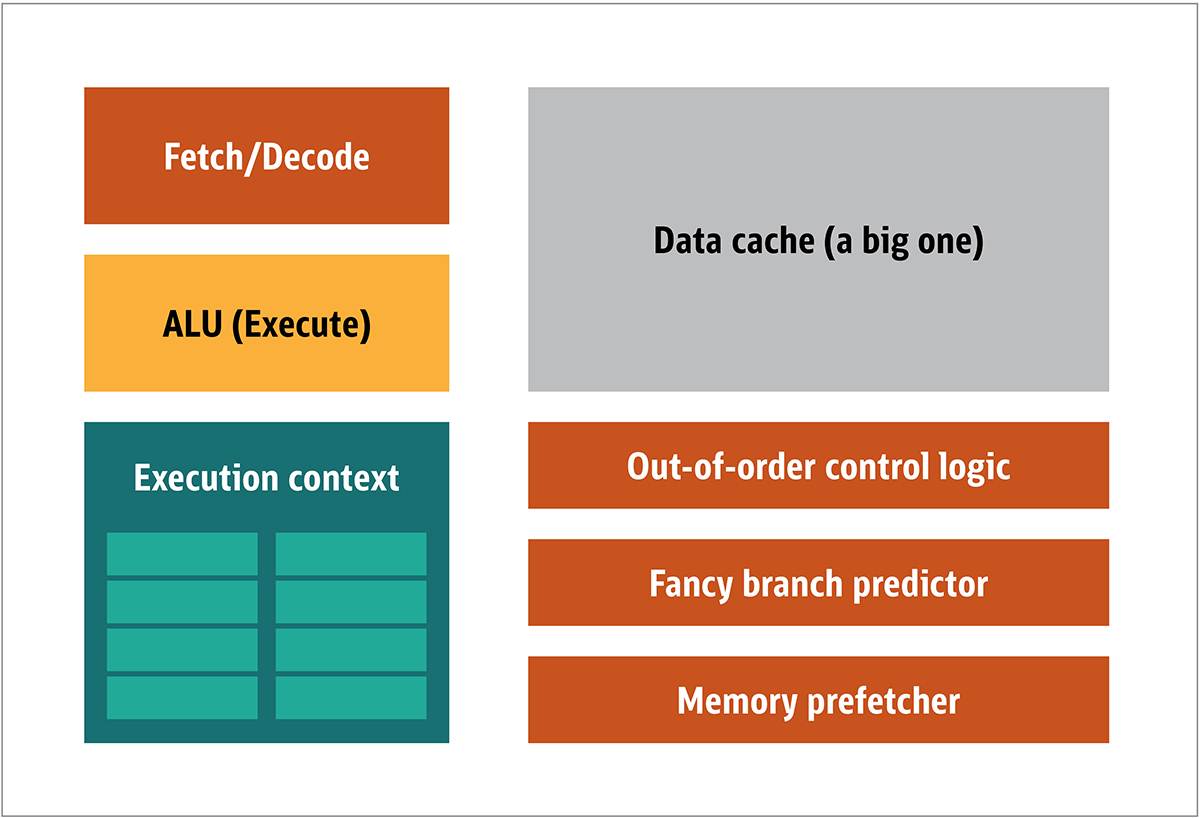 Higo. 1. Bloques de arquitectura de CPUEn la CPU, los elementos de procesamiento reales (registros, unidad de lógica aritmética (ALU) y contextos de ejecución) son solo pequeñas partes de todo el sistema. Para acelerar los pagos irregulares que llegan en un orden impredecible, hay un caché grande, rápido y costoso; varios tipos de coleccionistas; y predictores de rama.No necesita todo esto en la GPU, porque los datos se reciben de manera predecible, y la GPU realiza un conjunto muy limitado de operaciones en los datos. Por lo tanto, es posible hacerlos muy pequeños y un procesador económico con una arquitectura de bloque similar a este se muestra en la Fig. 2.
Higo. 1. Bloques de arquitectura de CPUEn la CPU, los elementos de procesamiento reales (registros, unidad de lógica aritmética (ALU) y contextos de ejecución) son solo pequeñas partes de todo el sistema. Para acelerar los pagos irregulares que llegan en un orden impredecible, hay un caché grande, rápido y costoso; varios tipos de coleccionistas; y predictores de rama.No necesita todo esto en la GPU, porque los datos se reciben de manera predecible, y la GPU realiza un conjunto muy limitado de operaciones en los datos. Por lo tanto, es posible hacerlos muy pequeños y un procesador económico con una arquitectura de bloque similar a este se muestra en la Fig. 2.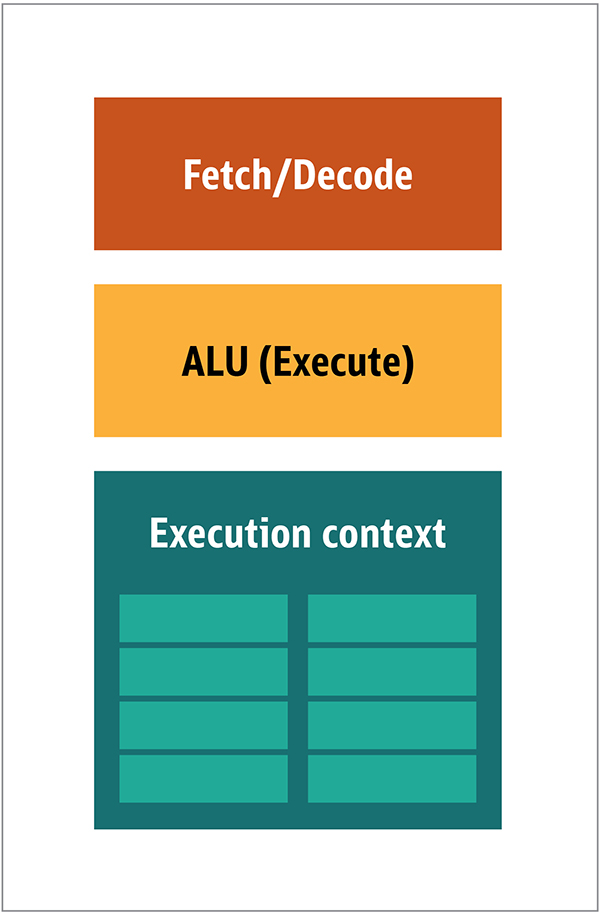 Fig. 2. Arquitectura de bloque para un núcleo de GPU simpleDebido a que dichos procesadores son más baratos y los datos procesados en ellos en fragmentos paralelos, es simple hacer que muchos de ellos funcionen en paralelo. Está diseñado con referencia a múltiples instrucciones, múltiples datos o MIMD (pronunciado "mim-dee").El segundo enfoque se basa en el hecho de que a menudo se aplica una sola instrucción a múltiples datos. Esto se conoce como una sola instrucción, múltiples datos o SIMD (pronunciado "sim-dee"). En este diseño, una sola GPU contiene múltiples ALU y contextos de ejecución, pequeñas áreas transferidas a datos de contexto compartidos, como se muestra en la Figura 3.
Fig. 2. Arquitectura de bloque para un núcleo de GPU simpleDebido a que dichos procesadores son más baratos y los datos procesados en ellos en fragmentos paralelos, es simple hacer que muchos de ellos funcionen en paralelo. Está diseñado con referencia a múltiples instrucciones, múltiples datos o MIMD (pronunciado "mim-dee").El segundo enfoque se basa en el hecho de que a menudo se aplica una sola instrucción a múltiples datos. Esto se conoce como una sola instrucción, múltiples datos o SIMD (pronunciado "sim-dee"). En este diseño, una sola GPU contiene múltiples ALU y contextos de ejecución, pequeñas áreas transferidas a datos de contexto compartidos, como se muestra en la Figura 3.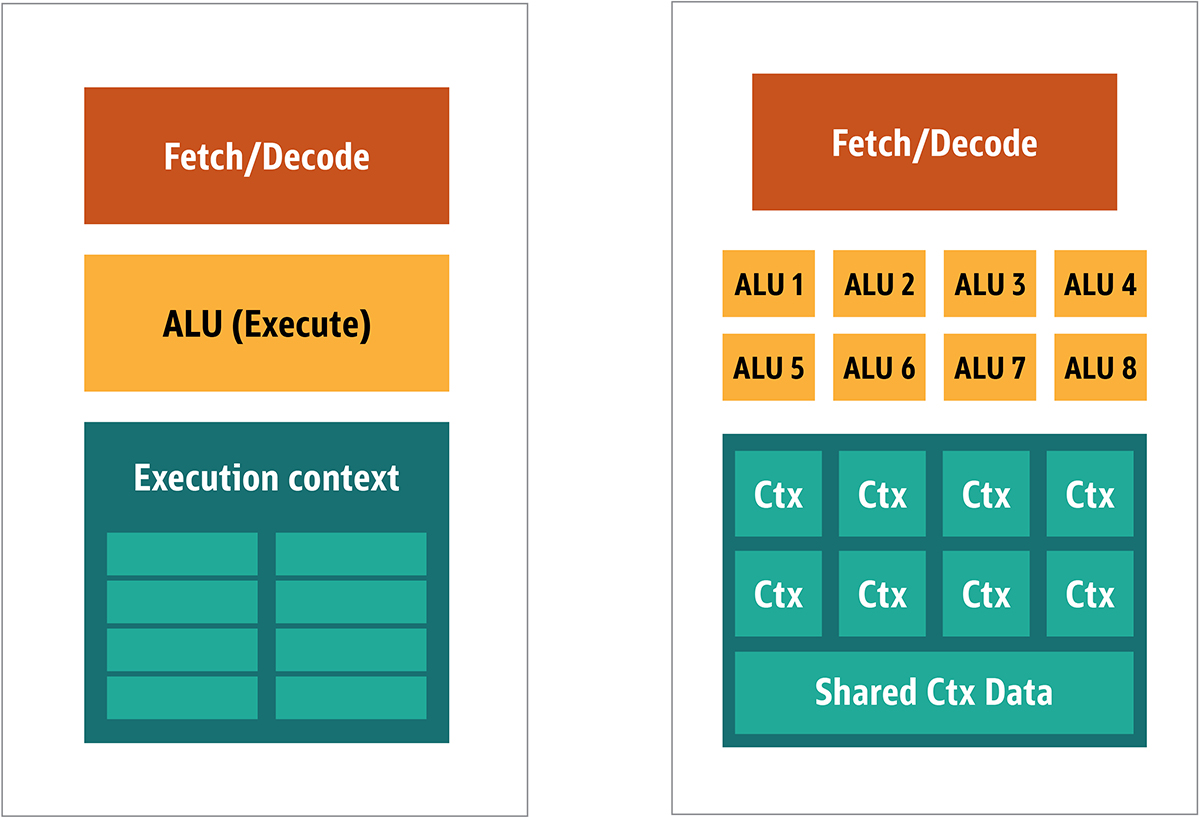 Fig. 3. Comparación de la arquitectura de estilo MIMD de los bloques de GPU (desde la izquierda), con el diseño SIMD (desde la derecha)La mezcla de procesamiento SIMD y MIMD proporciona el ancho de banda máximo que omitiré. En este diseño, tiene múltiples procesadores SIMD ejecutándose en paralelo, como en la Figura 4.
Fig. 3. Comparación de la arquitectura de estilo MIMD de los bloques de GPU (desde la izquierda), con el diseño SIMD (desde la derecha)La mezcla de procesamiento SIMD y MIMD proporciona el ancho de banda máximo que omitiré. En este diseño, tiene múltiples procesadores SIMD ejecutándose en paralelo, como en la Figura 4. Fig. 4. Trabajando múltiples procesadores SIMD en paralelo; hay 16 núcleos con 128 ALUDado que tiene un montón de procesadores pequeños y simples, puede programarlos para obtener un efecto especial en la salida.
Fig. 4. Trabajando múltiples procesadores SIMD en paralelo; hay 16 núcleos con 128 ALUDado que tiene un montón de procesadores pequeños y simples, puede programarlos para obtener un efecto especial en la salida.Ejecutar programas en la GPU
La mayoría de los primeros efectos gráficos en los juegos eran realmente pequeños programas codificados que se ejecutaban en la GPU y se aplicaban a los flujos de datos desde la CPU.Esto era obvio, incluso cuando los algoritmos codificados eran insuficientes, especialmente en el diseño de juegos, donde los efectos visuales son una de las principales direcciones mágicas. En respuesta, los grandes vendedores abrieron el acceso a la GPU, y luego los desarrolladores externos pudieron programarlos.Un enfoque típico era escribir un pequeño programa llamado sombreadores en un lenguaje especial (generalmente una subespecie de C) y compilarlos usando compiladores especiales para la arquitectura deseada. Se eligió el término sombreadores porque los sombreadores a menudo se usan para controlar los efectos de luz y sombra, pero esto no significa que puedan controlar otros efectos especiales.Cada proveedor de GPU tenía su propio lenguaje de programación e infraestructura para crear sombreadores para su arquitectura. En este enfoque, se han creado muchas plataformas.Los principales son:- DirectCompute: lenguaje / API de sombreador privado de Microsoft que forma parte de Direct3D, comenzando con DirectX 10.
- AMD FireStream: tecnologías privadas de ATI / Radeon que AMD está desactualizado.
- OpenACC: Consorcio de múltiples proveedores, solución de computación paralela
- ++ AMP: Microsoft C++
- CUDA: Nvidia,
- OpenL: , Apple, Khronos Group
La mayoría de las veces, trabajar con la GPU es una programación de bajo nivel. Para hacer esto un poco más comprensible para los desarrolladores, para la codificación, se proporcionaron varias abstracciones. El más famoso es DirectX, de Microsoft, y OpenGL, del Grupo Khronos. Estas son API para escribir código de alto nivel, que luego se puede simplificar para la GPU, más semánticamente, para el programador.Hasta donde sé, no hay infraestructura Java para DirectX, pero hay una buena solución para OpenGL. JSR 231 comenzó en 2002 y está dirigido a programadores de GPU, pero fue abandonado en 2008 y solo es compatible con OpenGL 2.0.El soporte de OpenGL continúa en el proyecto JOCL independiente (que también es compatible con OpenCL) y está disponible para la audiencia. Por lo tanto, el famoso juego de Minecraft fue escrito usando JOCL.GPGPU viene
Hasta ahora, Java y la GPU no han tenido puntos en común, aunque deberían serlo. Java se usa a menudo en empresas, en ciencia de datos y en el sector financiero, donde hay mucha informática y donde se necesita mucha potencia informática. Así es como es la idea de la GPU de propósito general (GPGPU). La idea de usar la GPU a lo largo de este camino comenzó cuando los fabricantes de adaptadores de video comenzaron a dar acceso al búfer de cuadros del programa, lo que permitió a los desarrolladores leer el contenido. Algunos hackers han determinado que pueden usar toda la potencia de la GPU para la informática universal.La receta era así:- Codificar datos como una matriz ráster.
- Escribe sombreadores para manejarlos.
- Envíelos a ambos a la tarjeta gráfica.
- Obtener resultado del frame buffer
- Decodificar datos de una matriz ráster.
Esta es una explicación muy simple. No estoy seguro de si esto funcionará en la producción, pero realmente funciona.Luego, numerosos estudios del Instituto Stanford comenzaron a simplificar el uso de GPU. En 2005, hicieron BrookGPU, que era un pequeño ecosistema que incluía un lenguaje de programación, compilador y tiempo de ejecución.BrookGPU compiló programas escritos en el lenguaje de programación de subprocesos Brook, que era una variante ANSI C. Puede apuntar a OpenGL v1.3 +, DirectX v9 + o AMD Close to Metal para la parte informática del servidor, y se ejecuta en Microsoft Windows y Linux. Para la depuración, BrookGPU también puede simular una tarjeta gráfica virtual en la CPU.Sin embargo, esto no despegó, debido al equipo disponible en ese momento. En el mundo GPGPU, debe copiar datos al dispositivo (en este contexto, el dispositivo se refiere a la GPU y al dispositivo en el que se encuentra), esperar a que la GPU calcule los datos y luego copiar los datos nuevamente al programa de control. Esto crea muchos retrasos. Y a mediados de la década de 2000, cuando el proyecto estaba en desarrollo activo, estos retrasos también excluyeron el uso intensivo de la GPU para la informática básica.Sin embargo, muchas compañías han visto el futuro en esta tecnología. Varios desarrolladores de adaptadores de video comenzaron a proporcionar GPGPU con sus tecnologías patentadas, y otras alianzas formadas proporcionaron modelos de programación menos básicos y versátiles que funcionaban con una gran cantidad de hierro.Ahora que le he contado todo, echemos un vistazo a las dos tecnologías informáticas de GPU más exitosas: OpenCL y CUDA, veamos también cómo funciona Java con ellas.OpenCL y Java
Al igual que otros paquetes de infraestructura, OpenCL proporciona una implementación básica en C. Esto está técnicamente disponible utilizando la Interfaz nativa de Java (JNI) o el Acceso nativo de Java (JNA), pero este enfoque será demasiado difícil para la mayoría de los desarrolladores.Afortunadamente, este trabajo ya lo han realizado varias bibliotecas: JOCL, JogAmp y JavaCL. Desafortunadamente, JavaCL se ha convertido en un proyecto muerto. Pero el proyecto JOCL está vivo y muy adaptado. Lo usaré para los siguientes ejemplos.Pero primero tengo que explicar qué es OpenCL. Mencioné anteriormente que OpenCL proporciona un modelo muy básico adecuado para programar todo tipo de dispositivos, no solo GPU y CPU, sino incluso procesadores DSP y FPGA.Veamos el ejemplo más simple: los vectores plegables son probablemente el ejemplo más brillante y simple. Tiene dos conjuntos de números para sumar y uno para el resultado. Toma un elemento de la primera matriz y un elemento de la segunda matriz, y luego coloca la suma en la matriz de resultados, como se muestra en la Fig. 5.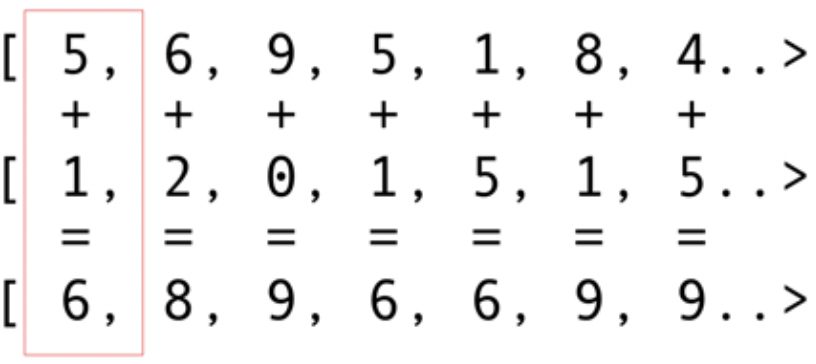 Fig. 5. Agregar los elementos de dos matrices y almacenar la suma en la matriz resultanteComo puede ver, la operación es muy consistente y no obstante distribuida. Puede insertar cada operación de adición en diferentes GPU centrales. Esto significa que si tiene 2048 núcleos, como en el Nvidia 1080, puede realizar 2048 operaciones de adición al mismo tiempo. Esto significa que aquí te esperan los potenciales teraflops de potencia de la computadora. Este código para una matriz de 10 millones de números se tomó del sitio web de JOCL:
Fig. 5. Agregar los elementos de dos matrices y almacenar la suma en la matriz resultanteComo puede ver, la operación es muy consistente y no obstante distribuida. Puede insertar cada operación de adición en diferentes GPU centrales. Esto significa que si tiene 2048 núcleos, como en el Nvidia 1080, puede realizar 2048 operaciones de adición al mismo tiempo. Esto significa que aquí te esperan los potenciales teraflops de potencia de la computadora. Este código para una matriz de 10 millones de números se tomó del sitio web de JOCL:public class ArrayGPU {
private static String programSource =
"__kernel void "+
"sampleKernel(__global const float *a,"+
" __global const float *b,"+
" __global float *c)"+
"{"+
" int gid = get_global_id(0);"+
" c[gid] = a[gid] + b[gid];"+
"}";
public static void main(String args[])
{
int n = 10_000_000;
float srcArrayA[] = new float[n];
float srcArrayB[] = new float[n];
float dstArray[] = new float[n];
for (int i=0; i<n; i++)
{
srcArrayA[i] = i;
srcArrayB[i] = i;
}
Pointer srcA = Pointer.to(srcArrayA);
Pointer srcB = Pointer.to(srcArrayB);
Pointer dst = Pointer.to(dstArray);
final int platformIndex = 0;
final long deviceType = CL.CL_DEVICE_TYPE_ALL;
final int deviceIndex = 0;
CL.setExceptionsEnabled(true);
int numPlatformsArray[] = new int[1];
CL.clGetPlatformIDs(0, null, numPlatformsArray);
int numPlatforms = numPlatformsArray[0];
cl_platform_id platforms[] = new cl_platform_id[numPlatforms];
CL.clGetPlatformIDs(platforms.length, platforms, null);
cl_platform_id platform = platforms[platformIndex];
cl_context_properties contextProperties = new cl_context_properties();
contextProperties.addProperty(CL.CL_CONTEXT_PLATFORM, platform);
int numDevicesArray[] = new int[1];
CL.clGetDeviceIDs(platform, deviceType, 0, null, numDevicesArray);
int numDevices = numDevicesArray[0];
cl_device_id devices[] = new cl_device_id[numDevices];
CL.clGetDeviceIDs(platform, deviceType, numDevices, devices, null);
cl_device_id device = devices[deviceIndex];
cl_context context = CL.clCreateContext(
contextProperties, 1, new cl_device_id[]{device},
null, null, null);
cl_command_queue commandQueue =
CL.clCreateCommandQueue(context, device, 0, null);
cl_mem memObjects[] = new cl_mem[3];
memObjects[0] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcA, null);
memObjects[1] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcB, null);
memObjects[2] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_WRITE,
Sizeof.cl_float * n, null, null);
cl_program program = CL.clCreateProgramWithSource(context,
1, new String[]{ programSource }, null, null);
CL.clBuildProgram(program, 0, null, null, null, null);
cl_kernel kernel = CL.clCreateKernel(program, "sampleKernel", null);
CL.clSetKernelArg(kernel, 0,
Sizeof.cl_mem, Pointer.to(memObjects[0]));
CL.clSetKernelArg(kernel, 1,
Sizeof.cl_mem, Pointer.to(memObjects[1]));
CL.clSetKernelArg(kernel, 2,
Sizeof.cl_mem, Pointer.to(memObjects[2]));
long global_work_size[] = new long[]{n};
long local_work_size[] = new long[]{1};
CL.clEnqueueNDRangeKernel(commandQueue, kernel, 1, null,
global_work_size, local_work_size, 0, null, null);
CL.clEnqueueReadBuffer(commandQueue, memObjects[2], CL.CL_TRUE, 0,
n * Sizeof.cl_float, dst, 0, null, null);
CL.clReleaseMemObject(memObjects[0]);
CL.clReleaseMemObject(memObjects[1]);
CL.clReleaseMemObject(memObjects[2]);
CL.clReleaseKernel(kernel);
CL.clReleaseProgram(program);
CL.clReleaseCommandQueue(commandQueue);
CL.clReleaseContext(context);
}
private static String getString(cl_device_id device, int paramName) {
long size[] = new long[1];
CL.clGetDeviceInfo(device, paramName, 0, null, size);
byte buffer[] = new byte[(int)size[0]];
CL.clGetDeviceInfo(device, paramName, buffer.length, Pointer.to(buffer), null);
return new String(buffer, 0, buffer.length-1);
}
}
Este código no es como el código Java, pero lo es. Explicaré más el código; No pierda mucho tiempo ahora, porque hablaré brevemente sobre soluciones complejas.El código será documentado, pero hagamos un pequeño recorrido. Como puede ver, el código es muy similar al código en C. Esto es normal porque JOCL es simplemente OpenCL. Al principio, aquí hay un código en la línea, y este código es la parte más importante: se compila usando OpenCL y luego se envía a la tarjeta de video, donde se ejecuta. Este código se llama Kernel. No confunda este término con OC Kernel; Este es el código del dispositivo. Este código está escrito en un subconjunto de C.Después de que el kernel viene el código Java para instalar y configurar el dispositivo, dividir los datos y crear los búferes de memoria apropiados para los datos resultantes.Para resumir: aquí está el "código de host", que generalmente es un enlace de idioma (en nuestro caso, en Java), y el "código del dispositivo". Siempre resalta lo que funcionará en el host y lo que debería funcionar en el dispositivo, porque el host controla el dispositivo.El código anterior debe mostrar la GPU equivalente a "¡Hola mundo!" Como puede ver, la mayor parte es enorme.No nos olvidemos de las funciones SIMD. Si su dispositivo admite la extensión SIMD, puede hacer que el código aritmético sea más rápido. Por ejemplo, echemos un vistazo al código de multiplicación de la matriz del núcleo. Este código está en una línea Java simple en la aplicación.__kernel void MatrixMul_kernel_basic(int dim,
__global float *A,
__global float *B,
__global float *C){
int iCol = get_global_id(0);
int iRow = get_global_id(1);
float result = 0.0;
for(int i=0; i< dim; ++i)
{
result +=
A[iRow*dim + i]*B[i*dim + iCol];
}
C[iRow*dim + iCol] = result;
}
Técnicamente, este código funcionará en datos que el marco de OpenCL instaló para usted, con instrucciones que llamó en la parte preparatoria.Si su tarjeta de video admite instrucciones SIMD y puede procesar un vector de cuatro números de punto flotante, las pequeñas optimizaciones pueden convertir el código anterior en el siguiente:#define VECTOR_SIZE 4
__kernel void MatrixMul_kernel_basic_vector4(
size_t dim,
const float4 *A,
const float4 *B,
float4 *C)
{
size_t globalIdx = get_global_id(0);
size_t globalIdy = get_global_id(1);
float4 resultVec = (float4){ 0, 0, 0, 0 };
size_t dimVec = dim / 4;
for(size_t i = 0; i < dimVec; ++i) {
float4 Avector = A[dimVec * globalIdy + i];
float4 Bvector[4];
Bvector[0] = B[dimVec * (i * 4 + 0) + globalIdx];
Bvector[1] = B[dimVec * (i * 4 + 1) + globalIdx];
Bvector[2] = B[dimVec * (i * 4 + 2) + globalIdx];
Bvector[3] = B[dimVec * (i * 4 + 3) + globalIdx];
resultVec += Avector[0] * Bvector[0];
resultVec += Avector[1] * Bvector[1];
resultVec += Avector[2] * Bvector[2];
resultVec += Avector[3] * Bvector[3];
}
C[dimVec * globalIdy + globalIdx] = resultVec;
}
Con este código puede duplicar el rendimiento.Frio. ¡Acabas de abrir la GPU para el mundo Java! Pero como desarrollador de Java, ¿realmente quieres hacer todo este trabajo sucio, con código C y trabajando con detalles de tan bajo nivel? No quiero. Pero ahora que tiene algún conocimiento de cómo se usa la GPU, veamos otra solución que es diferente del código JOCL que acabo de presentar.CUDA y Java
CUDA es la solución de Nvidia para este problema de programación. CUDA proporciona muchas más bibliotecas listas para usar para operaciones estándar de GPU, como matrices, histogramas e incluso redes neuronales profundas. Ya ha aparecido una lista de bibliotecas con un montón de soluciones listas para usar. Todo esto es del proyecto JCuda:- JCublas: todo para matrices
- JCufft: Transformada rápida de Fourier
- JCurand: todo para números aleatorios
- JCusparse: matrices raras
- JCusolver: factorización de números
- JNvgraph: todo para gráficos
- JCudpp: biblioteca CUDA de datos paralelos primitivos y algunos algoritmos de clasificación
- JNpp: procesamiento de imágenes GPU
- JCudnn: biblioteca de redes neuronales profundas
Estoy considerando usar JCurand, que genera números aleatorios. Puede usar esto desde el código Java sin otro lenguaje Kernel especial. Por ejemplo:...
int n = 100;
curandGenerator generator = new curandGenerator();
float hostData[] = new float[n];
Pointer deviceData = new Pointer();
cudaMalloc(deviceData, n * Sizeof.FLOAT);
curandCreateGenerator(generator, CURAND_RNG_PSEUDO_DEFAULT);
curandSetPseudoRandomGeneratorSeed(generator, 1234);
curandGenerateUniform(generator, deviceData, n);
cudaMemcpy(Pointer.to(hostData), deviceData,
n * Sizeof.FLOAT, cudaMemcpyDeviceToHost);
System.out.println(Arrays.toString(hostData));
curandDestroyGenerator(generator);
cudaFree(deviceData);
...
Utiliza una GPU para crear una gran cantidad de números aleatorios de muy alta calidad, basados en matemáticas muy sólidas.En JCuda, también puede escribir código genérico CUDA y llamarlo desde Java llamando a algún archivo JAR en su classpath. Consulte la documentación de JCuda para obtener excelentes ejemplos.Manténgase por encima del código de bajo nivel
Todo se ve muy bien, pero hay demasiado código, demasiada instalación, demasiados idiomas diferentes para ejecutarlo todo. ¿Hay alguna manera de usar la GPU al menos parcialmente?¿Qué pasa si no quieres pensar en todo este OpenCL, CUDA y otras cosas innecesarias? ¿Qué pasa si solo quieres programar en Java y no pensar en todo lo que no es obvio? El proyecto Aparapi puede ayudar. Aparapi se basa en una "API paralela". Lo considero una parte de Hibernate para la programación de GPU que usa OpenCL bajo el capó. Echemos un vistazo a un ejemplo de suma de vectores.public static void main(String[] _args) {
final int size = 512;
final float[] a = new float[size];
final float[] b = new float[size];
for (int i = 0; i < size; i++){
a[i] = (float) (Math.random() * 100);
b[i] = (float) (Math.random() * 100);
}
final float[] sum = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
I int gid = getGlobalId();
sum[gid] = a[gid] + b[gid];
}
};
kernel.execute(Range.create(size));
for(int i = 0; i < size; i++) {
System.out.printf("%6.2f + %6.2f = %8.2f\n", a[i], b[i], sum[i])
}
kernel.dispose();
}
Aquí hay código Java puro (tomado de la documentación de Aparapi), también aquí y allá, puede ver un cierto término Kernel y getGlobalId. Aún necesita comprender cómo programar la GPU, pero puede usar el enfoque GPGPU de una manera más parecida a Java. Además, Aparapi proporciona una manera fácil de usar el contexto OpenGL en la capa OpenCL, lo que permite que los datos permanezcan completamente en la tarjeta gráfica, y así evitar problemas de latencia de memoria.Si necesita hacer muchos cálculos independientes, mire Aparapi. Hay muchos ejemplos de cómo usar la computación paralela.Además, hay un proyecto llamado TornadoVM: transfiere automáticamente los cálculos apropiados de la CPU a la GPU, lo que proporciona una optimización masiva de fábrica.recomendaciones
Hay muchas aplicaciones en las que las GPU pueden aportar algunas ventajas, pero se podría decir que todavía hay algunos obstáculos. Sin embargo, Java y la GPU pueden hacer grandes cosas juntos. En este artículo, solo toqué este extenso tema. Tenía la intención de mostrar varias opciones de alto y bajo nivel para acceder a la GPU desde Java. Explorar esta área proporcionará enormes beneficios de rendimiento, especialmente para tareas complejas que requieren múltiples cálculos que se pueden realizar en paralelo.Enlace fuente